Re: Enabling Checksums
| Lists: | pgsql-hackers |
|---|
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Cc: | Greg Smith <gsmith(at)gregsmith(dot)com> |
| Subject: | Enabling Checksums |
| Date: | 2012-11-09 01:01:41 |
| Message-ID: | 1352422901.31259.28.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
As I understand it, the main part of the remaining work to be done for
the checksums patch (at least the first commit) is to have a better way
to enable/disable them.
For the sake of simplicity (implementation as well as usability), it
seems like there is agreement that checksums should be enabled or
disabled for the entire instance, not per-table.
I don't think a GUC entirely makes sense (in its current form, anyway).
We basically care about 3 states:
1. Off: checksums are not written, nor are they verified. Pages that
are newly dirtied have the checksum information in the header cleared.
2. Enabling: checksums are written for every dirty page, but only
verified for pages where the checksum is present (as determined by
information in the page header).
3. On: checksums are written for every dirty page, and verified for
every page that's read. If a page does not have a checksum, it's
corrupt.
Does it make sense to store this information in pg_control? That doesn't
require adding any new file, and it has the benefit that it's already
checksummed. It's available during recovery and can be made available
pretty easily in the places where we write data.
And the next question is what commands to add to change state. Ideas:
CHECKSUMS ENABLE; -- set state to "Enabling"
CHECKSUMS DISABLE; -- set state to "Off"
And then to get to the "On" state, you have to run a system-wide VACUUM
while in the "Enabling" state. Or, if the above syntax causes problems,
we can make all of these into VACUUM options.
Thoughts?
Regards,
Jeff Davis
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Greg Smith <gsmith(at)gregsmith(dot)com> |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 02:33:36 |
| Message-ID: | 20121109023335.GG7225@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Davis wrote:
> And the next question is what commands to add to change state. Ideas:
>
> CHECKSUMS ENABLE; -- set state to "Enabling"
> CHECKSUMS DISABLE; -- set state to "Off"
>
> And then to get to the "On" state, you have to run a system-wide VACUUM
> while in the "Enabling" state. Or, if the above syntax causes problems,
> we can make all of these into VACUUM options.
There's no such thing as a system-wide VACUUM. The most you can get is
a database-wide VACUUM, which means you'd have to store the state
per-database somewhere (presumably the pg_database catalog), and perhaps
pg_control could have it as a system-wide value that's computed as the
minimum of all database states (so it stays "enabling" until all
databases have upgraded to "on").
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
|---|---|
| To: | "'Jeff Davis'" <pgsql(at)j-davis(dot)com>, <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | "'Greg Smith'" <gsmith(at)gregsmith(dot)com> |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 05:05:43 |
| Message-ID: | 000001cdbe37$df23da80$9d6b8f80$@kapila@huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Friday, November 09, 2012 6:32 AM Jeff Davis wrote:
> As I understand it, the main part of the remaining work to be done for
> the checksums patch (at least the first commit) is to have a better way
> to enable/disable them.
>
> For the sake of simplicity (implementation as well as usability), it
> seems like there is agreement that checksums should be enabled or
> disabled for the entire instance, not per-table.
>
> I don't think a GUC entirely makes sense (in its current form, anyway).
> We basically care about 3 states:
> 1. Off: checksums are not written, nor are they verified. Pages that
> are newly dirtied have the checksum information in the header cleared.
> 2. Enabling: checksums are written for every dirty page, but only
> verified for pages where the checksum is present (as determined by
> information in the page header).
> 3. On: checksums are written for every dirty page, and verified for
> every page that's read. If a page does not have a checksum, it's
> corrupt.
>
> Does it make sense to store this information in pg_control? That doesn't
> require adding any new file, and it has the benefit that it's already
> checksummed. It's available during recovery and can be made available
> pretty easily in the places where we write data.
>
> And the next question is what commands to add to change state. Ideas:
>
> CHECKSUMS ENABLE; -- set state to "Enabling"
> CHECKSUMS DISABLE; -- set state to "Off"
>
> And then to get to the "On" state, you have to run a system-wide VACUUM
> while in the "Enabling" state. Or, if the above syntax causes problems,
> we can make all of these into VACUUM options.
I think one thing may needs to be taken care during such a VACUUM operation
is not to allow user to say
CHECKSUM DISABLE.
Also how about following ways :
1. Allow CHECKSUM Enable only during initdb as mentioned by Robert.
Allow user to only do CHECKSUM DISABLE after initdb.
2. Do the Checksum only for particular pages (SRLU) or to do for System
tables only.
With Regards,
Amit Kapila.
| From: | Jesper Krogh <jesper(at)krogh(dot)cc> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 05:18:13 |
| Message-ID: | 509C9215.2080303@krogh.cc |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 09/11/12 02:01, Jeff Davis wrote:
> As I understand it, the main part of the remaining work to be done for
> the checksums patch (at least the first commit) is to have a better way
> to enable/disable them.
>
> For the sake of simplicity (implementation as well as usability), it
> seems like there is agreement that checksums should be enabled or
> disabled for the entire instance, not per-table.
I can definately see that simplicity is an argument here, but
I can easily imagine that some performance hungry users
would prefer to be able to disable the functionality on a
per table level. UNCHECKSUMMED TABLES (similar to UNLOGGED TABLES).
I would definately stuff our system in state = 2 in your
description if it was available.
--
Jesper
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Greg Smith <gsmith(at)gregsmith(dot)com> |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 14:31:44 |
| Message-ID: | 509D13D0.8030605@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff,
On 11/09/2012 02:01 AM, Jeff Davis wrote:
> For the sake of simplicity (implementation as well as usability), it
> seems like there is agreement that checksums should be enabled or
> disabled for the entire instance, not per-table.
Agreed. I've quickly thought about making it a per-database setting, but
how about shared system catalogs... Let's keep it simple and have a
single per-cluster instance switch for now.
> I don't think a GUC entirely makes sense (in its current form, anyway).
> We basically care about 3 states:
> 1. Off: checksums are not written, nor are they verified. Pages that
> are newly dirtied have the checksum information in the header cleared.
> 2. Enabling: checksums are written for every dirty page, but only
> verified for pages where the checksum is present (as determined by
> information in the page header).
> 3. On: checksums are written for every dirty page, and verified for
> every page that's read. If a page does not have a checksum, it's
> corrupt.
Sounds sane, yes.
> And the next question is what commands to add to change state. Ideas:
>
> CHECKSUMS ENABLE; -- set state to "Enabling"
> CHECKSUMS DISABLE; -- set state to "Off"
Yet another SQL command doesn't feel like the right thing for such a
switch. Quick googling revealed that CHECKSUM is a system function in MS
SQL and MySQL knows a CHECKSUM TABLE command. And you never know what
the committee is coming up with next.
Apart from that, I'd like something more descriptive that just
"checksums". Block checksums? Heap checksums? Data checksums?
Regards
Markus Wanner
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Jesper Krogh <jesper(at)krogh(dot)cc> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 14:42:58 |
| Message-ID: | 509D1672.1080606@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/09/2012 06:18 AM, Jesper Krogh wrote:
> I would definately stuff our system in state = 2 in your
> description if it was available.
Hm.. that's an interesting statement.
What's probably worst when switching from OFF to ON is the VACUUM run
that needs to touch every page (provided you haven't ever turned
checksumming on before). Maybe you want to save that step and still get
the additional safety for newly dirtied pages, right?
A use case worth supporting?
Regards
Markus Wanner
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 17:57:04 |
| Message-ID: | 509D43F0.9040304@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff,
> I don't think a GUC entirely makes sense (in its current form, anyway).
> We basically care about 3 states:
Huh? Why would a GUC not make sense? How else would you make sure that
checksums where on when you started the system?
> 1. Off: checksums are not written, nor are they verified. Pages that
> are newly dirtied have the checksum information in the header cleared.
> 2. Enabling: checksums are written for every dirty page, but only
> verified for pages where the checksum is present (as determined by
> information in the page header).
> 3. On: checksums are written for every dirty page, and verified for
> every page that's read. If a page does not have a checksum, it's
> corrupt.
Well, large databases would tend to be stuck permanently in "Enabling",
becuase the user would never vacuum old cold partitions in order to
checksum them. So we need to be prepared for this to be the end state
for a lot of databases.
In fact, we'd need three settings for the checksum GUC:
OFF -- don't checksum anything, equal to state (1) above
WRITES -- checksum pages which are being written anyway, but ignore
tables which aren't touched. Permanent "Enabling" state.
ALL -- checksum everything you can. particularly, autovacuum would
checksum any table which was not already checksummed at the next vacuum
of that table. Goal is to get to state 3 above.
> Does it make sense to store this information in pg_control? That doesn't
> require adding any new file, and it has the benefit that it's already
> checksummed. It's available during recovery and can be made available
> pretty easily in the places where we write data.
>
> And the next question is what commands to add to change state. Ideas:
>
> CHECKSUMS ENABLE; -- set state to "Enabling"
> CHECKSUMS DISABLE; -- set state to "Off"
Don't like this, please make it a GUC.
> And then to get to the "On" state, you have to run a system-wide VACUUM
> while in the "Enabling" state. Or, if the above syntax causes problems,
> we can make all of these into VACUUM options.
As there's no such thing as system-wide vacuum, we're going to have to
track whether a table is "fully checksummed" in the system catalogs.
We'll also need:
VACUUM ( CHECKSUM ON )
... which would vacuum an entire table, skipping no pages and writing
checksums for every page, unless the table were marked fully checksummed
already, in which case it would do a regular vacuum.
Once a table was flagged as "all checksummed", then the system could
start producing errors (or warnings?) whenever a page with a missing
checksum was found.
Hmmm, better to have a 2nd GUC:
checksum_fail_action = WARNING | ERROR
... since some people want the write or read to fail, and others just
want to see it in the logs.
So, thinking about it, state (3) is never the state of an entire
installation; it's always the state of individual tables.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Markus Wanner <markus(at)bluegap(dot)ch> |
| Cc: | Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 18:53:38 |
| Message-ID: | 1352487218.6292.78.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2012-11-09 at 15:42 +0100, Markus Wanner wrote:
> On 11/09/2012 06:18 AM, Jesper Krogh wrote:
> > I would definately stuff our system in state = 2 in your
> > description if it was available.
>
> Hm.. that's an interesting statement.
>
> What's probably worst when switching from OFF to ON is the VACUUM run
> that needs to touch every page (provided you haven't ever turned
> checksumming on before). Maybe you want to save that step and still get
> the additional safety for newly dirtied pages, right?
>
> A use case worth supporting?
One problem is telling which pages are protected and which aren't. We
can have a couple bits in the header indicating that a checksum is
present, but it's a little disappointing to have only a few bits
protecting a 16-bit checksum.
Also, I think that people will want to have a way to protect their old
data somehow.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Greg Smith <gsmith(at)gregsmith(dot)com> |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 18:58:57 |
| Message-ID: | 1352487537.6292.80.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 2012-11-08 at 23:33 -0300, Alvaro Herrera wrote:
> There's no such thing as a system-wide VACUUM. The most you can get is
> a database-wide VACUUM, which means you'd have to store the state
> per-database somewhere (presumably the pg_database catalog), and perhaps
> pg_control could have it as a system-wide value that's computed as the
> minimum of all database states (so it stays "enabling" until all
> databases have upgraded to "on").
That's a good point. Maybe this should be done as an offline operation
using a command-line utility?
Regards,
Jeff Davis
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 19:48:12 |
| Message-ID: | 509D5DFC.8020006@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/09/2012 07:53 PM, Jeff Davis wrote:
> One problem is telling which pages are protected and which aren't. We
> can have a couple bits in the header indicating that a checksum is
> present, but it's a little disappointing to have only a few bits
> protecting a 16-bit checksum.
Given your description of option 2 I was under the impression that each
page already has a bit indicating whether or not the page is protected
by a checksum. Why do you need more bits than that?
> Also, I think that people will want to have a way to protect their old
> data somehow.
Well, given that specific set of users is not willing to go through a
rewrite of each and every page of its database, it's hard to see how we
can protect their old data better.
However, we certainly need to provide the option to go through the
rewrite for other users, who are well willing to bite that bullet.
From a users perspective, the trade-off seems to be: if you want your
old data to be covered by checksums, you need to go through such an
expensive VACUUM run that touches every page in your database.
If you don't want to or cannot do that, you can still turn on
checksumming for newly written pages. You won't get full protection and
it's hard to tell what data is protected and what not, but it's still
better than no checksumming at all. Especially for huge databases, that
might be a reasonable compromise.
One could even argue, that this just leads to a prolonged migration and
with time, the remaining VACUUM step becomes less and less frightening.
Do you see any real foot-guns or other show-stoppers for permanently
allowing that in-between-state?
Or do we have other viable options that prolong the migration and thus
spread the load better over time?
Regards
Markus Wanner
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Markus Wanner <markus(at)bluegap(dot)ch> |
| Cc: | Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-09 23:08:48 |
| Message-ID: | 1352502528.26644.9.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2012-11-09 at 20:48 +0100, Markus Wanner wrote:
> Given your description of option 2 I was under the impression that each
> page already has a bit indicating whether or not the page is protected
> by a checksum. Why do you need more bits than that?
The bit indicating that a checksum is present may be lost due to
corruption.
> However, we certainly need to provide the option to go through the
> rewrite for other users, who are well willing to bite that bullet.
That's the use case that I've been focusing on, but perhaps you are
right that it's not the only important one.
> Do you see any real foot-guns or other show-stoppers for permanently
> allowing that in-between-state?
The biggest problem that I see is a few bits indicating the presence of
a checksum may be vulnerable to more kinds of corruption.
Regards,
Jeff Davis
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-10 13:46:44 |
| Message-ID: | 6363139D-2757-4A78-993D-66F39F478D80@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Nov10, 2012, at 00:08 , Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Fri, 2012-11-09 at 20:48 +0100, Markus Wanner wrote:
>> Given your description of option 2 I was under the impression that each
>> page already has a bit indicating whether or not the page is protected
>> by a checksum. Why do you need more bits than that?
>
> The bit indicating that a checksum is present may be lost due to
> corruption.
Though that concern mostly goes away if instead of a separate bit we use a
special checksum value, say 0xDEAD, to indicate that the page isn't
checksummed, no?
If checksums were always enabled, the probability of a random corruption
going undetected is N/N^2 = 1/N where N is the number of distinct checksum
values, since out of the N^2 equally likely pairs of computed and stored
checksums values, N show two identical values.
With the 0xDEAD-scheme, the probability of a random corruption going
undetected is (N-1 + N)/N^2 = 2/N - 1/N^2, since there are (N-1) pairs
with identical values != 0xDEAD, and N pairs where the stored checksum
value is 0xDEAD.
So instead of a 1 in 65536 chance of a corruption going undetected, the
0xDEAD-schema gives (approximately) a chance of 1 in 32768, i.e the
strength of the checksum is reduced by one bit. That's still acceptable,
I'd say.
In practice, 0xDEAD may be a bad choice because of it's widespread use
as an uninitialized marker for blocks of memory. A randomly picked value
would probably be a better choice.
best regards,
Florian Pflug
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-11 18:27:28 |
| Message-ID: | 1352658448.3113.6.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, 2012-11-10 at 14:46 +0100, Florian Pflug wrote:
> > The bit indicating that a checksum is present may be lost due to
> > corruption.
>
> Though that concern mostly goes away if instead of a separate bit we use a
> special checksum value, say 0xDEAD, to indicate that the page isn't
> checksummed, no?
Right. But then we have an upgrade impact to set the checksum to 0xDEAD
on all existing pages, which seems to eliminate most of the possible
reason for it.
Also, we'd need to tweak the algorithm to make sure that it never landed
on that magic value. So if we think we might want this in the future, we
should reserve that magic value now.
But I can't think of many reasons for it, unless we expect people to be
turning checksums on and off repeatedly.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-11 19:56:39 |
| Message-ID: | 1352663799.3113.45.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2012-11-09 at 09:57 -0800, Josh Berkus wrote:
> Huh? Why would a GUC not make sense? How else would you make sure that
> checksums where on when you started the system?
If we stored the information in pg_control, you could check with
pg_controldata. We could have a separate utility, pg_checksums, that can
alter the state and/or do an offline verification. And initdb would take
an option that would start everything out fully protected with
checksums.
The problem with a GUC is that checksums aren't really something you can
change by just changing the variable and restarting, unless you are only
using checksums opportunistically (only write checksums when a page is
dirtied and only verify a checksum if the header indicates that it's
present).
There are also usability issues. If someone has a fully-protected
instance, and turns the GUC off, and starts the server, they'll lose the
"fully-protected" status on the first write, and have to re-read all the
data to get back to fully protected. That just doesn't seem right to me.
> Well, large databases would tend to be stuck permanently in "Enabling",
> becuase the user would never vacuum old cold partitions in order to
> checksum them. So we need to be prepared for this to be the end state
> for a lot of databases.
That may be true, but if that's the case, it's more like a 3-bit
checksum than a 16-bit checksum, because of the page-header corruption
problem. I don't know of any way to give those users more than that,
which won't be good enough for the set-at-initdb time users.
> In fact, we'd need three settings for the checksum GUC:
>
> OFF -- don't checksum anything, equal to state (1) above
>
> WRITES -- checksum pages which are being written anyway, but ignore
> tables which aren't touched. Permanent "Enabling" state.
>
> ALL -- checksum everything you can. particularly, autovacuum would
> checksum any table which was not already checksummed at the next vacuum
> of that table. Goal is to get to state 3 above.
That's slightly more eager, but it's basically the same as the WRITES
state. In order to get to the fully-protected state, you still need to
somehow make sure that all of the old data is checksummed.
And the "fully protected" state is important in my opinion, because
otherwise we aren't protected against corrupt page headers that say they
have no checksum (even when it really should have a checksum).
> > Does it make sense to store this information in pg_control? That doesn't
> > require adding any new file, and it has the benefit that it's already
> > checksummed. It's available during recovery and can be made available
> > pretty easily in the places where we write data.
> >
> > And the next question is what commands to add to change state. Ideas:
> >
> > CHECKSUMS ENABLE; -- set state to "Enabling"
> > CHECKSUMS DISABLE; -- set state to "Off"
>
> Don't like this, please make it a GUC.
I'll see if you have ideas about how to resolve the problems with a GUC
that I mentioned above. But if not, then what about using a utility,
perhaps called pg_checksums? That way we wouldn't need new syntax.
> As there's no such thing as system-wide vacuum, we're going to have to
> track whether a table is "fully checksummed" in the system catalogs.
It seems like this is going down the road of per-table checksums. I'm
not opposed to that, but that has a low chance of making 9.3.
Let's try to do something simpler now that leaves open the possibility
of more flexibility later. I'm inclined to agree with Robert that the
first patch should probably be an initdb-time option. Then, we can allow
a lazy mode (like your WRITES state) and an eager offline check with a
pg_checksums utility. Then we can work towards per-table checksums,
control via VACUUM, protecting the SLRU, treating zero pages as invalid,
protecting temp files (which can be a GUC), replication integration,
etc.
> Hmmm, better to have a 2nd GUC:
>
> checksum_fail_action = WARNING | ERROR
>
> ... since some people want the write or read to fail, and others just
> want to see it in the logs.
Checksums don't introduce new failure modes on writes, only on reads.
And for reads, I think we have a problem doing anything less than an
ERROR. If we allow the read to succeed, we either risk a crash (or
silently corrupting other buffers in shared memory), or we have to put a
zero page in its place. But we already have the zero_damaged_pages
option, which I think is better because reading corrupt data is only
useful for data recovery efforts.
> So, thinking about it, state (3) is never the state of an entire
> installation; it's always the state of individual tables.
That contradicts the idea of using a GUC then. It would make more sense
to have extra syntax or extra VACUUM modes to accomplish that per-table.
Unfortunately, I'm worried that the per-table approach will not be
completed by 9.3. Do you see something about my proposal that makes it
harder to get where we want to go in the future?
If we do ultimately get per-table checksums, then I agree that a flag in
pg_control may be a bit of a wart, but it's easy enough to remove later.
Regards,
Jeff Davis
| From: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-11 20:20:23 |
| Message-ID: | CAFj8pRA6q9BfDwbp9C=Y7F0WUkXYD5NA7QGH4krvKOT7zu+dEw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello
>
>> > Does it make sense to store this information in pg_control? That doesn't
>> > require adding any new file, and it has the benefit that it's already
>> > checksummed. It's available during recovery and can be made available
>> > pretty easily in the places where we write data.
>> >
>> > And the next question is what commands to add to change state. Ideas:
>> >
>> > CHECKSUMS ENABLE; -- set state to "Enabling"
>> > CHECKSUMS DISABLE; -- set state to "Off"
>>
>> Don't like this, please make it a GUC.
>
> I'll see if you have ideas about how to resolve the problems with a GUC
> that I mentioned above. But if not, then what about using a utility,
> perhaps called pg_checksums? That way we wouldn't need new syntax.
I don't think so GUC are good for this purpouse, but I don't like
single purpouse statements too.
what do you think about enhancing ALTER DATABASE statement
some like
ALTER DATABASE name ENABLE CHECKSUMS and ALTER DATABASE name DISABLE CHECKSUMS
Regards
Pavel
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-11 22:52:20 |
| Message-ID: | 1352674340.3113.50.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 2012-11-11 at 21:20 +0100, Pavel Stehule wrote:
> I don't think so GUC are good for this purpouse, but I don't like
> single purpouse statements too.
>
> what do you think about enhancing ALTER DATABASE statement
>
> some like
>
> ALTER DATABASE name ENABLE CHECKSUMS and ALTER DATABASE name DISABLE CHECKSUMS
Per-database does sound easier than per-table. I'd have to think about
how that would affect shared catalogs though.
For now, I'm leaning toward an offline utility to turn checksums on or
off, called pg_checksums. It could do so lazily (just flip a switch to
"enabling" in pg_control), or it could do so eagerly and turn it into a
fully-protected instance.
For the first patch, it might just be an initdb-time option for
simplicity.
Regards,
Jeff Davis
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-11 23:59:29 |
| Message-ID: | 50A03BE1.5040806@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/11/2012 05:52 PM, Jeff Davis wrote:
> On Sun, 2012-11-11 at 21:20 +0100, Pavel Stehule wrote:
>> I don't think so GUC are good for this purpouse, but I don't like
>> single purpouse statements too.
>>
>> what do you think about enhancing ALTER DATABASE statement
>>
>> some like
>>
>> ALTER DATABASE name ENABLE CHECKSUMS and ALTER DATABASE name DISABLE CHECKSUMS
> Per-database does sound easier than per-table. I'd have to think about
> how that would affect shared catalogs though.
>
> For now, I'm leaning toward an offline utility to turn checksums on or
> off, called pg_checksums. It could do so lazily (just flip a switch to
> "enabling" in pg_control), or it could do so eagerly and turn it into a
> fully-protected instance.
>
> For the first patch, it might just be an initdb-time option for
> simplicity.
>
+1
I haven't followed this too closely, but I did wonder several days ago
why this wasn't being made an initdb-time decision.
cheers
andrew
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 04:55:19 |
| Message-ID: | 50A08137.5090200@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/11/12 2:56 PM, Jeff Davis wrote:
> We could have a separate utility, pg_checksums, that can
> alter the state and/or do an offline verification. And initdb would take
> an option that would start everything out fully protected with
> checksums.
Adding an initdb option to start out with everything checksummed seems
an uncontroversial good first thing to have available. It seems like a
proper 9.3 target to aim at even if per-table upgrading gets bogged down
in details. I have an argument below that the area between initdb and
per-table upgrades is fundamentally uncertain and therefore not worth
chasing after, based on reasons you already started to outline. There's
not much useful middle ground there.
Won't a pg_checksums program just grow until it looks like a limited
version of vacuum though? It's going to iterate over most of the table;
it needs the same cost controls as autovacuum (and to respect the load
of concurrent autovacuum work) to keep I/O under control; and those cost
control values might change if there's a SIGHUP to reload parameters.
It looks so much like vacuum that I think there needs to be a really
compelling reason to split it into something new. Why can't this be yet
another autovacuum worker that does its thing?
> In order to get to the fully-protected state, you still need to
> somehow make sure that all of the old data is checksummed.
>
> And the "fully protected" state is important in my opinion, because
> otherwise we aren't protected against corrupt page headers that say
> they have no checksum (even when it really should have a checksum).
I think it's useful to step back for a minute and consider the larger
uncertainty an existing relation has, which amplifies just how ugly this
situation is. The best guarantee I think online checksumming can offer
is to tell the user "after transaction id X, all new data in relation R
is known to be checksummed". Unless you do this at initdb time, any
conversion case is going to have the possibility that a page is
corrupted before you get to it--whether you're adding the checksum as
part of a "let's add them while we're writing anyway" page update or the
conversion tool is hitting it.
That's why I don't think anyone will find online conversion really
useful until they've done a full sweep updating the old pages. And if
you accept that, a flexible checksum upgrade utility, one that co-exists
with autovacuum activity costs, becomes a must.
One of the really common cases I was expecting here is that conversions
are done by kicking off a slow background VACUUM CHECKSUM job that might
run in pieces. I was thinking of an approach like this:
-Initialize a last_checked_block value for each table
-Loop:
--Grab the next block after the last checked one
--When on the last block of the relation, grab an exclusive lock to
protect against race conditions with extension
--If it's marked as checksummed and the checksum matches, skip it
---Otherwise, add a checksum and write it out
--When that succeeds, update last_checked_block
--If that was the last block, save some state saying the whole table is
checkedsummed
With that logic, there is at least a forward moving pointer that removes
the uncertainty around whether pages have been updated or not. It will
keep going usefully if interrupted too. One obvious this way this can
fail is if:
1) A late page in the relation is updated and a checksummed page written
2) The page is corrupted such that the "is this checksummed?" bits are
not consistent anymore, along with other damage to it
3) The conversion process gets to this page eventually
4) The corruption of (2) isn't detected
But I think that this possibility--that a page might get quietly
corrupted after checked once, but still in the middle of checking a
relation--is both impossible to remove and a red herring. How do we
know that this page of the relation wasn't corrupted on disk before we
even started? We don't, and we can't.
The only guarantee I see that we can give for online upgrades is that
after a VACUUM CHECKSUM sweep is done, and every page is known to both
have a valid checksum on it and have its checksum bits set, *then* any
page that doesn't have both set bits and a matching checksum is garbage.
Until reaching that point, any old data is suspect. The idea of
operating in an "we'll convert on write but never convert old pages"
can't come up with any useful guarantees about data integrity that I can
see. As you say, you don't ever gain the ability to tell pages that
were checksummed but have since been corrupted from ones that were
corrupt all along in that path.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Jesper Krogh <jesper(at)krogh(dot)cc> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 05:55:54 |
| Message-ID: | 50A08F6A.6030601@krogh.cc |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/11/12 05:55, Greg Smith wrote:
> The only guarantee I see that we can give for online upgrades is that
> after a VACUUM CHECKSUM sweep is done, and every page is known to both
> have a valid checksum on it and have its checksum bits set, *then* any
> page that doesn't have both set bits and a matching checksum is
> garbage. Until reaching that point, any old data is suspect. The
> idea of operating in an "we'll convert on write but never convert old
> pages" can't come up with any useful guarantees about data integrity
> that I can see. As you say, you don't ever gain the ability to tell
> pages that were checksummed but have since been corrupted from ones
> that were corrupt all along in that path.
You're right about that, but I'd just like some rough guard against
hardware/OS related data corruption.
and that is more likely to hit data-blocks constantly flying in and out
of the system.
I'm currently running a +2TB database and the capabillity to just see
some kind of corruption earlier
rather than later is a major benefit by itself. Currently corruption can
go undetected if it just
happens to hit data-only parts of the database.
But I totally agree that the scheme described with integrating it into a
autovacuum process would
be very close to ideal, even on a database as the one I'l running.
--
Jesper
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jesper Krogh <jesper(at)krogh(dot)cc> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 06:20:17 |
| Message-ID: | 50A09521.4050902@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/12/12 12:55 AM, Jesper Krogh wrote:
> I'd just like some rough guard against
> hardware/OS related data corruption.
> and that is more likely to hit data-blocks constantly flying in and out
> of the system.
I get that. I think that some of the design ideas floating around since
this feature was first proposed have been innovating in the hope of
finding a clever halfway point here. Ideally we'd be able to get online
checksum conversion and up running easily, reliably, and without adding
a lot of code. I have given up on that now though.
The approach of doing a heavy per-table conversion with more state
information than we'd like seems unavoidable, if you want to do it right
and allow people to (slowly but surely) reach a trustworthy state. I
think we should stop searching for a clever way around and just do slog
through doing it. I've resigned myself to that now, and recently set
aside a good block of time to beat my head against that particular wall
over the next couple of months.
> But I totally agree that the scheme described with integrating it into a
> autovacuum process would
> be very close to ideal, even on a database as the one I'm running.
I am sadly all too familiar with how challenging it is to keep a 2TB
PostgreSQL database running reliably. One of my recent catch phrases
for talks is "if you have a big Postgres database, you also have a
vacuum problem". I think it's unreasonable to consider online
conversion solutions that don't recognize that, and allow coordinating
the work with the challenges of vacuuming larger systems too.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 08:44:23 |
| Message-ID: | 50A0B6E7.6060502@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff,
On 11/10/2012 12:08 AM, Jeff Davis wrote:
> The bit indicating that a checksum is present may be lost due to
> corruption.
Hm.. I see.
Sorry if that has been discussed before, but can't we do without that
bit at all? It adds a checksum switch to each page, where we just agreed
we don't event want a per-database switch.
Can we simply write a progress indicator to pg_control or someplace
saying that all pages up to X of relation Y are supposed to have valid
checksums?
That would mean having to re-calculate the checksums on pages that got
dirtied before VACUUM came along to migrate them to having a checksum,
but that seems acceptable. VACUUM could even detect that case and
wouldn't have to re-write it with the same contents.
I realize this doesn't support Jesper's use case of wanting to have the
checksums only for newly dirtied pages. However, I'd argue that
prolonging the migration to spread the load would allow even big shops
to go through this without much of an impact on performance.
Regards
Markus Wanner
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 09:26:11 |
| Message-ID: | 50A0C0B3.4060803@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/12/2012 05:55 AM, Greg Smith wrote:
> Adding an initdb option to start out with everything checksummed seems
> an uncontroversial good first thing to have available.
+1
So the following discussion really is for a future patch extending on
that initial checkpoint support.
> One of the really common cases I was expecting here is that conversions
> are done by kicking off a slow background VACUUM CHECKSUM job that might
> run in pieces. I was thinking of an approach like this:
>
> -Initialize a last_checked_block value for each table
> -Loop:
> --Grab the next block after the last checked one
> --When on the last block of the relation, grab an exclusive lock to
> protect against race conditions with extension
> --If it's marked as checksummed and the checksum matches, skip it
> ---Otherwise, add a checksum and write it out
> --When that succeeds, update last_checked_block
> --If that was the last block, save some state saying the whole table is
> checkedsummed
Perfect, thanks. That's the rough idea I had in mind as well, written
out in detail and catching the extension case.
> With that logic, there is at least a forward moving pointer that removes
> the uncertainty around whether pages have been updated or not. It will
> keep going usefully if interrupted too. One obvious this way this can
> fail is if:
>
> 1) A late page in the relation is updated and a checksummed page written
> 2) The page is corrupted such that the "is this checksummed?" bits are
> not consistent anymore, along with other damage to it
> 3) The conversion process gets to this page eventually
> 4) The corruption of (2) isn't detected
IMO this just outlines how limited the use of the "is this checksummed"
bit in the page itself is. It just doesn't catch all cases. Is it worth
having that bit at all, given your block-wise approach above?
It really only serves to catch corruptions to *newly* dirtied pages
*during* the migration phase that *keep* that single bit set. Everything
else is covered by the last_checked_block variable. Sounds narrow enough
to be negligible. Then again, it's just a single bit per page...
> The only guarantee I see that we can give for online upgrades is that
> after a VACUUM CHECKSUM sweep is done, and every page is known to both
> have a valid checksum on it and have its checksum bits set, *then* any
> page that doesn't have both set bits and a matching checksum is garbage.
From that point in time on, we'd theoretically better use that bit as an
additional checksum bit rather than requiring it to be set all times.
Really just theoretically, I'm certainly not advocating a 33 bit
checksum :-)
Regards
Markus Wanner
| From: | Craig Ringer <craig(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Markus Wanner <markus(at)bluegap(dot)ch> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 09:44:27 |
| Message-ID: | 50A0C4FB.6020007@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/12/2012 04:44 PM, Markus Wanner wrote:
> Jeff,
>
> On 11/10/2012 12:08 AM, Jeff Davis wrote:
>> The bit indicating that a checksum is present may be lost due to
>> corruption.
> Hm.. I see.
>
> Sorry if that has been discussed before, but can't we do without that
> bit at all? It adds a checksum switch to each page, where we just agreed
> we don't event want a per-database switch.
>
> Can we simply write a progress indicator to pg_control or someplace
> saying that all pages up to X of relation Y are supposed to have valid
> checksums?
That'll make it hard for VACUUM, hint-bit setting, etc to
opportunistically checksum pages whenever they're doing a page write anyway.
Is it absurd to suggest using another bitmap, like the FSM or visibility
map, to store information on page checksumming while checksumming is
enabled but incomplete? As a much smaller file the bitmap could its self
be very quickly generated in one pass when checksumming is enabled, with
its starting state showing no pages having checksums.
It perhaps its self have page checksums since presumably the persistent
maps like the FSM and visibility map will support them? Some way to
ensure the checksum map is valid would be needed.
--
Craig Ringer
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Craig Ringer <craig(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 10:13:43 |
| Message-ID: | 50A0CBD7.8070906@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/12/2012 10:44 AM, Craig Ringer wrote:
> That'll make it hard for VACUUM, hint-bit setting, etc to
> opportunistically checksum pages whenever they're doing a page write anyway.
It *is* a hard problem, yes. And the single bit doesn't really solve it.
So I'm arguing against opportunistically checksumming in general. Who
needs that anyway?
> Is it absurd to suggest using another bitmap, like the FSM or visibility
> map, to store information on page checksumming while checksumming is
> enabled but incomplete?
Not absurd. But arguably inefficient, because that bitmap may well
become a bottleneck itself. Plus there's the problem of making sure
those pages are safe against corruptions, so you'd need to checksum the
checksum bitmap... doesn't sound like a nice solution to me.
This has certainly been discussed before.
Regards
Markus Wanner
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 15:00:05 |
| Message-ID: | 20121112150004.GB4506@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Greg Smith wrote:
> On 11/11/12 2:56 PM, Jeff Davis wrote:
> >We could have a separate utility, pg_checksums, that can
> >alter the state and/or do an offline verification. And initdb would take
> >an option that would start everything out fully protected with
> >checksums.
>
> Adding an initdb option to start out with everything checksummed
> seems an uncontroversial good first thing to have available.
+1
> Won't a pg_checksums program just grow until it looks like a limited
> version of vacuum though? It's going to iterate over most of the
> table; it needs the same cost controls as autovacuum (and to respect
> the load of concurrent autovacuum work) to keep I/O under control;
> and those cost control values might change if there's a SIGHUP to
> reload parameters. It looks so much like vacuum that I think there
> needs to be a really compelling reason to split it into something
> new. Why can't this be yet another autovacuum worker that does its
> thing?
I agree that much of the things it's gonna do are going to be pretty
much the same as vacuum, but vacuum does so many other things that I
think it should be kept separate. Sure, we can make it be invoked from
autovacuum in background according to some (yet to be devised)
scheduling heuristics. But I don't see that it needs to share any
vacuum code.
A couple of thoughts about autovacuum: it's important to figure out
whether checksumming can run concurrently with vacuuming the same table;
if not, which one defers to the other in case of lock conflict. Also,
can checksumming be ignored by concurrent transactions when computing
Xmin (I don't see any reason not to ...)
> One of the really common cases I was expecting here is that
> conversions are done by kicking off a slow background VACUUM
> CHECKSUM job that might run in pieces. I was thinking of an
> approach like this:
>
> -Initialize a last_checked_block value for each table
> -Loop:
> --Grab the next block after the last checked one
> --When on the last block of the relation, grab an exclusive lock to
> protect against race conditions with extension
Note that we have a separate lock type for relation extension, so we can
use that to avoid a conflict here.
> --If it's marked as checksummed and the checksum matches, skip it
> ---Otherwise, add a checksum and write it out
> --When that succeeds, update last_checked_block
> --If that was the last block, save some state saying the whole table
> is checkedsummed
"Some state" can be a pg_class field that's updated per
heap_inplace_update.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Markus Wanner <markus(at)bluegap(dot)ch> |
| Cc: | Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 16:39:23 |
| Message-ID: | 1352738363.3113.55.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-11-12 at 09:44 +0100, Markus Wanner wrote:
> Can we simply write a progress indicator to pg_control or someplace
> saying that all pages up to X of relation Y are supposed to have valid
> checksums?
pg_control would not be the right place for that structure. It's
intended to be fixed-size (it's just a serialized C structure) and it
should be smaller than a sector so that it doesn't suffer from torn
pages.
Not a bad approach overall, but requires some kind of new structure. And
that increases the risk that it doesn't make 9.3.
Right now, I'm honestly just trying to get the simplest approach that
doesn't restrict these kinds of ideas if we want to do them later.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 17:52:25 |
| Message-ID: | 1352742745.3113.85.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 2012-11-11 at 23:55 -0500, Greg Smith wrote:
> Adding an initdb option to start out with everything checksummed seems
> an uncontroversial good first thing to have available.
OK, so here's my proposal for a first patch (changes from Simon's
patch):
* Add a flag to the postgres executable indicating that it should use
checksums on everything. This would only be valid if bootstrap mode is
also specified.
* Add a multi-state checksums flag in pg_control, that would have
three states: OFF, ENABLING, and ON. It would only be set to ON during
bootstrap, and in this first patch, it would not be possible to set
ENABLING.
* Remove GUC and use this checksums flag everywhere.
* Use the TLI field rather than the version field of the page header.
* Incorporate page number into checksum calculation (already done).
Does this satisfy the requirements for a first step? Does it interfere
with potential future work?
> Won't a pg_checksums program just grow until it looks like a limited
> version of vacuum though?
We can dig into the details of that later, but I don't think it's
useless, even if we do have per-table (or better) checksums. For
instance, it would be useful to verify backups offline.
I think it's a legitimate concern that we might reinvent some VACUUM
machinery. Ideally, we'd get better online migration tools for checksums
(perhaps using VACUUM) fast enough that nobody will bother introducing
that kind of bloat into pg_checksums.
> I think it's useful to step back for a minute and consider the larger
> uncertainty an existing relation has, which amplifies just how ugly this
> situation is. The best guarantee I think online checksumming can offer
> is to tell the user "after transaction id X, all new data in relation R
> is known to be checksummed".
It's slightly better than that. It's more like: "we can tell you if any
of your data gets corrupted after transaction X". If old data is
corrupted before transaction X, then there's nothing we can do. But if
it's corrupted after transaction X (even if it's old data), the
checksums should catch it.
> Unless you do this at initdb time, any
> conversion case is going to have the possibility that a page is
> corrupted before you get to it--whether you're adding the checksum as
> part of a "let's add them while we're writing anyway" page update or the
> conversion tool is hitting it.
Good point.
> That's why I don't think anyone will find online conversion really
> useful until they've done a full sweep updating the old pages.
I don't entirely agree. A lot of times, you just want to know whether
your disk is changing your data out from under you. Maybe you miss some
cases and maybe not all of your data is protected, but just knowing
which disks need to be replaced, and which RAID controllers not to buy
again, is quite valuable. And the more data you get checksummed the
faster you'll find out.
> One of the really common cases I was expecting here is that conversions
> are done by kicking off a slow background VACUUM CHECKSUM job that might
> run in pieces.
Right now I'm focused on the initial patch and other fairly immediate
goals, so I won't address this now. But I don't want to cut off the
conversation, either.
Regards,
Jeff Davis
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 19:44:02 |
| Message-ID: | 50A15182.8080802@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff,
On 11/12/2012 06:52 PM, Jeff Davis wrote:
> OK, so here's my proposal for a first patch (changes from Simon's
> patch):
>
> * Add a flag to the postgres executable indicating that it should use
> checksums on everything. This would only be valid if bootstrap mode is
> also specified.
> * Add a multi-state checksums flag in pg_control, that would have
> three states: OFF, ENABLING, and ON. It would only be set to ON during
> bootstrap, and in this first patch, it would not be possible to set
> ENABLING.
> * Remove GUC and use this checksums flag everywhere.
> * Use the TLI field rather than the version field of the page header.
> * Incorporate page number into checksum calculation (already done).
>
> Does this satisfy the requirements for a first step? Does it interfere
> with potential future work?
As described before in this thread, I think we might be able to do
without the "has checksum"-bit, as yet another simplification. But I
don't object to adding it, either.
> It's slightly better than that. It's more like: "we can tell you if any
> of your data gets corrupted after transaction X". If old data is
> corrupted before transaction X, then there's nothing we can do. But if
> it's corrupted after transaction X (even if it's old data), the
> checksums should catch it.
I (mis?)read that as Greg referring to the intermediate (enabling)
state, where pages with old data may or may not have a checksum, yet. So
I think it was an argument against staying in that state any longer than
necessary.
Regards
Markus Wanner
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Craig Ringer <craig(at)2ndQuadrant(dot)com> |
| Cc: | Markus Wanner <markus(at)bluegap(dot)ch>, Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-12 23:02:42 |
| Message-ID: | 50A18012.2080402@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/12/12 4:44 AM, Craig Ringer wrote:
> Is it absurd to suggest using another bitmap, like the FSM or visibility
> map, to store information on page checksumming while checksumming is
> enabled but incomplete?
I spent some time thinking about that last week. One problem with it is
that the bitmap structure itself has the same issues as every other
write here--how do we know it's going to disk accurately? The "put
'checksum on' bits on the page" idea and "put checksum on bits in a map"
have the same fundamental issue. Things might get out of sync in the
same way, you've just moved the potentially suspicious write to a new place.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Markus Wanner <markus(at)bluegap(dot)ch> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-13 00:17:43 |
| Message-ID: | 1352765863.14335.8.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-11-12 at 20:44 +0100, Markus Wanner wrote:
> As described before in this thread, I think we might be able to do
> without the "has checksum"-bit, as yet another simplification. But I
> don't object to adding it, either.
I see. For a first patch, I guess that's OK. Might as well make it as
simple as possible. We probably need to decide what to do there before
9.3 is released though.
Regards,
Jeff Davis
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Markus Wanner <markus(at)bluegap(dot)ch> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-13 00:22:03 |
| Message-ID: | 50A192AB.3070602@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/12/12 3:44 AM, Markus Wanner wrote:
> Sorry if that has been discussed before, but can't we do without that
> bit at all? It adds a checksum switch to each page, where we just agreed
> we don't event want a per-database switch.
Once you accept that eventually there need to be online conversion
tools, there needs to be some easy way to distinguish which pages have
been processed for several potential implementations. The options seem
to be adding some bits just for that or bumping the page format. I
would like to just bump the format, but that has a pile of its own
issues to cross. Rather not make that a requirement for this month's
requirements.
> Can we simply write a progress indicator to pg_control or someplace
> saying that all pages up to X of relation Y are supposed to have valid
> checksums?
All of the table-based checksum enabling ideas seem destined to add
metadata to pg_class or something related to it for this purpose. While
I think everyone agrees that this is a secondary priority to getting
basic cluster-level checksums going right now, I'd like to have at least
a prototype for that before 9.3 development ends. All of the
> I realize this doesn't support Jesper's use case of wanting to have the
> checksums only for newly dirtied pages. However, I'd argue that
> prolonging the migration to spread the load would allow even big shops
> to go through this without much of an impact on performance.
I'm thinking of this in some ways like the way creation of a new (but
not yet valid) foreign key works. Once that's active, new activity is
immediately protected moving forward. And eventually there's this
cleanup step needed, one that you can inch forward over a few days.
The main upper limit on load spreading here is that the conversion
program may need to grab a snapshot. In that case the conversion taking
too long will be a problem, as it blocks other vacuum activity past that
point. This is why I think any good solution to this problem needs to
incorporate restartable conversion. We were just getting complaints
recently about how losing a CREATE INDEX CONCURRENTLY session can cause
the whole process to end and need to be started over. The way
autovacuum runs right now it can be stopped and restarted later, with
only a small loss of duplicated work in many common cases. If it's
possible to maintain that property for the checksum conversion, that
would be very helpful to larger sites. It doesn't matter if adding
checksums to the old data takes a week if you throttle the load down, so
long as you're not forced to hold an open snapshot the whole time.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-13 00:42:57 |
| Message-ID: | 50A19791.2060000@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff,
> OK, so here's my proposal for a first patch (changes from Simon's
> patch):
>
> * Add a flag to the postgres executable indicating that it should use
> checksums on everything. This would only be valid if bootstrap mode is
> also specified.
> * Add a multi-state checksums flag in pg_control, that would have
> three states: OFF, ENABLING, and ON. It would only be set to ON during
> bootstrap, and in this first patch, it would not be possible to set
> ENABLING.
> * Remove GUC and use this checksums flag everywhere.
> * Use the TLI field rather than the version field of the page header.
> * Incorporate page number into checksum calculation (already done).
>
> Does this satisfy the requirements for a first step? Does it interfere
> with potential future work?
So the idea of this implementation is that checksums is something you
set at initdb time, and if you want checksums on an existing database,
it's a migration process (e.g. dump and reload)?
I think that's valid as a first cut at this.
We'll need interruptable VACUUM CHECKSUM later, but we don't have to
have it for the first version of the feature.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Markus Wanner <markus(at)bluegap(dot)ch> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-13 10:12:58 |
| Message-ID: | 50A21D2A.60703@bluegap.ch |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/13/2012 01:22 AM, Greg Smith wrote:
> Once you accept that eventually there need to be online conversion
> tools, there needs to be some easy way to distinguish which pages have
> been processed for several potential implementations.
Agreed. What I'm saying is that this identification doesn't need to be
as fine grained as a per-page bit. A single "horizon" or "border" is
enough, given an ordering of relations (for example by OID) and an
ordering of pages in the relations (obvious).
> All of the table-based checksum enabling ideas ...
This is not really one - it doesn't allow per-table switching. It's just
meant to be a more compact way of representing which pages have been
checksummed and which not.
> I'm thinking of this in some ways like the way creation of a new (but
> not yet valid) foreign key works. Once that's active, new activity is
> immediately protected moving forward. And eventually there's this
> cleanup step needed, one that you can inch forward over a few days.
I understand that. However, I question if users really care. If a
corruption is detected, the clever DBA tells his trainee immediately
check the file- and disk subsystem - no matter whether the corruption
was on old or new data.
You have a point in that pages with "newer" data are often more likely
to be re-read and thus getting checked. Where as the checksums written
to pages with old data might not be re-read any time soon. Starting to
write checksums from the end of the relation could mitigate this to some
extent, though.
Also keep in mind the "quietly corrupted after checked once, but still
in the middle of checking a relation" case. Thus a single bit doesn't
really give us the guarantee you ask for. Sure, we can add more than one
bit. And yeah, if done properly, adding more bits exponentially reduces
the likeliness of a corruption inadvertently turning off checksumming
for a page.
All that said, I'm not opposed to using a few bits of the page header. I
wanted to outline an alternative that I think is viable and less intrusive.
> This is why I think any good solution to this problem needs to
> incorporate restartable conversion.
I fully agree to that.
Regards
Markus Wanner
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-13 20:27:47 |
| Message-ID: | CA+TgmoYkza5fTgYC5N2eZhLM6vMRCM-q3a4R=_Z8fP33tF=ddA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Nov 11, 2012 at 5:52 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> Per-database does sound easier than per-table. I'd have to think about
> how that would affect shared catalogs though.
>
> For now, I'm leaning toward an offline utility to turn checksums on or
> off, called pg_checksums. It could do so lazily (just flip a switch to
> "enabling" in pg_control), or it could do so eagerly and turn it into a
> fully-protected instance.
>
> For the first patch, it might just be an initdb-time option for
> simplicity.
It'd be pretty easy to write a pg_checksums utilitys to turn checksums
on/off on a database that is shut down, since the hard part of all of
this is to change the state while the database is running. But I
think even that doesn't need to be part of the first patch. A small
patch that gets committed is better than a big one that doesn't.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Markus Wanner <markus(at)bluegap(dot)ch>, Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-13 20:46:25 |
| Message-ID: | CA+TgmoYLr_H0UiFURgoWrRD5uy83OMFS_c-io_F82fDyB9FqJg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Nov 12, 2012 at 4:44 AM, Craig Ringer <craig(at)2ndquadrant(dot)com> wrote:
> That'll make it hard for VACUUM, hint-bit setting, etc to
> opportunistically checksum pages whenever they're doing a page write anyway.
>
> Is it absurd to suggest using another bitmap, like the FSM or visibility
> map, to store information on page checksumming while checksumming is
> enabled but incomplete? As a much smaller file the bitmap could its self
> be very quickly generated in one pass when checksumming is enabled, with
> its starting state showing no pages having checksums.
Hmm... what if we took this a step further and actually stored the
checksums in a separate relation fork? That would make it pretty
simple to support enabling/disabling checksums for particular
relations. It would also allow us to have a wider checksum, like 32
or 64 bits rather than 16. I'm not scoffing at a 16-bit checksum,
because even that's enough to catch a very high percentage of errors,
but it wouldn't be terrible to be able to support a wider one, either.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-13 21:48:11 |
| Message-ID: | 904.1352843291@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> Hmm... what if we took this a step further and actually stored the
> checksums in a separate relation fork? That would make it pretty
> simple to support enabling/disabling checksums for particular
> relations. It would also allow us to have a wider checksum, like 32
> or 64 bits rather than 16. I'm not scoffing at a 16-bit checksum,
> because even that's enough to catch a very high percentage of errors,
> but it wouldn't be terrible to be able to support a wider one, either.
What happens when you get an I/O failure on the checksum fork? Assuming
you're using 8K pages there, that would mean you can no longer verify
the integrity of between one and four thousand pages of data.
Not to mention the race condition problems associated with trying to be
sure the checksum updates hit the disk at the same time as the data-page
updates.
I think you really have to store the checksums *with* the data they're
supposedly protecting.
regards, tom lane
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jeff Davis <pgsql(at)j-davis(dot)com>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 16:46:54 |
| Message-ID: | CA+Tgmoa6a7UgKKbrpFTSHUuDUiXt0_HwqGUHiwjW7rK3d9h+uQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Nov 13, 2012 at 4:48 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> What happens when you get an I/O failure on the checksum fork? Assuming
> you're using 8K pages there, that would mean you can no longer verify
> the integrity of between one and four thousand pages of data.
True... but you'll have succeeded in your central aim of determining
whether your hardware has crapped out. Answer: yes.
The existing code doesn't have any problem reporting back the user
those hardware failures which are reported to it by the OS. The only
reason for the feature is for the database to be able to detect
hardware failures in situations where the OS claims that everything is
working just fine.
> Not to mention the race condition problems associated with trying to be
> sure the checksum updates hit the disk at the same time as the data-page
> updates.
>
> I think you really have to store the checksums *with* the data they're
> supposedly protecting.
If torn pages didn't exist, I'd agree with you, but they do. Any
checksum feature is going to need to cope with the fact that, prior to
reaching consistency, there will be blocks on disk with checksums that
don't match, because 8kB writes are not atomic. We fix that by
unconditionally overwriting the possibly-torn pages with full-page
images, and we could simply update the checksum fork at the same time.
We don't have to do anything special to make sure that the next
checkpoint cycle successfully flushes both pages to disk before
declaring the checkpoint a success and moving the redo pointer; that
logic already exists.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 17:22:12 |
| Message-ID: | 20121114172212.GE13888@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Nov 12, 2012 at 04:42:57PM -0800, Josh Berkus wrote:
> Jeff,
>
> > OK, so here's my proposal for a first patch (changes from Simon's
> > patch):
> >
> > * Add a flag to the postgres executable indicating that it should use
> > checksums on everything. This would only be valid if bootstrap mode is
> > also specified.
> > * Add a multi-state checksums flag in pg_control, that would have
> > three states: OFF, ENABLING, and ON. It would only be set to ON during
> > bootstrap, and in this first patch, it would not be possible to set
> > ENABLING.
> > * Remove GUC and use this checksums flag everywhere.
> > * Use the TLI field rather than the version field of the page header.
> > * Incorporate page number into checksum calculation (already done).
> >
> > Does this satisfy the requirements for a first step? Does it interfere
> > with potential future work?
>
> So the idea of this implementation is that checksums is something you
> set at initdb time, and if you want checksums on an existing database,
> it's a migration process (e.g. dump and reload)?
>
> I think that's valid as a first cut at this.
pg_upgrade will need to check for the checksum flag and throw an error
if it is present in the new cluster but not the old one.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Peter Eisentraut <peter_e(at)gmx(dot)net> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 18:25:37 |
| Message-ID: | 50A3E221.60708@gmx.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/11/12 6:59 PM, Andrew Dunstan wrote:
> I haven't followed this too closely, but I did wonder several days ago
> why this wasn't being made an initdb-time decision.
One problem I see with this is that it would make regression testing
much more cumbersome. Basically, to do a proper job, you'd have to run
all the tests twice, once against each initdb setting. Either we
automate this, which would mean everyone's tests are now running almost
twice as long, or we don't, which would mean that some critical piece of
low-level code would likely not get wide testing.
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Peter Eisentraut <peter_e(at)gmx(dot)net> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 19:01:35 |
| Message-ID: | 20121114190135.GD10633@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Peter Eisentraut escribió:
> On 11/11/12 6:59 PM, Andrew Dunstan wrote:
> > I haven't followed this too closely, but I did wonder several days ago
> > why this wasn't being made an initdb-time decision.
>
> One problem I see with this is that it would make regression testing
> much more cumbersome. Basically, to do a proper job, you'd have to run
> all the tests twice, once against each initdb setting. Either we
> automate this, which would mean everyone's tests are now running almost
> twice as long, or we don't, which would mean that some critical piece of
> low-level code would likely not get wide testing.
We already have that problem with the isolation tests regarding
transaction isolation levels: the tests are only run with whatever is
the default_transaction_isolation setting, which is read committed in
all buildfarm installs; so repeatable read and serializable are only
tested when someone gets around to tweaking an installation manually. A
proposal has been floated to fix that, but it needs someone to actually
implement it.
I wonder if something similar could be used to handle this case as well.
I also wonder, though, if the existing test frameworks are really the
best mechanisms to verify block layer functionality.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Peter Eisentraut <peter_e(at)gmx(dot)net>, Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 19:12:09 |
| Message-ID: | 50A3ED09.6050004@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/14/2012 02:01 PM, Alvaro Herrera wrote:
> Peter Eisentraut escribió:
>> On 11/11/12 6:59 PM, Andrew Dunstan wrote:
>>> I haven't followed this too closely, but I did wonder several days ago
>>> why this wasn't being made an initdb-time decision.
>> One problem I see with this is that it would make regression testing
>> much more cumbersome. Basically, to do a proper job, you'd have to run
>> all the tests twice, once against each initdb setting. Either we
>> automate this, which would mean everyone's tests are now running almost
>> twice as long, or we don't, which would mean that some critical piece of
>> low-level code would likely not get wide testing.
> We already have that problem with the isolation tests regarding
> transaction isolation levels: the tests are only run with whatever is
> the default_transaction_isolation setting, which is read committed in
> all buildfarm installs; so repeatable read and serializable are only
> tested when someone gets around to tweaking an installation manually. A
> proposal has been floated to fix that, but it needs someone to actually
> implement it.
>
> I wonder if something similar could be used to handle this case as well.
> I also wonder, though, if the existing test frameworks are really the
> best mechanisms to verify block layer functionality.
There is nothing to prevent a buildfarm owner from using different
settings - there is a stanza in the config file that provides for them
to do so in fact.
Maybe a saner thing to do though would be to run the isolation tests two
or three times with different PGOPTIONS settings. Maybe we need two ro
three targets in the isolation test Makefile for that.
Regarding checksums, I can add an option for the initdb that the
buildfarm script runs. We already run different tests for different
encodings. Of course, constant expanding like this won't scale, so we
need to pick the options we want to exrecise carefully.
cheers
andrew
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Peter Eisentraut <peter_e(at)gmx(dot)net>, Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 20:06:00 |
| Message-ID: | 24644.1352923560@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
> Regarding checksums, I can add an option for the initdb that the
> buildfarm script runs. We already run different tests for different
> encodings. Of course, constant expanding like this won't scale, so we
> need to pick the options we want to exrecise carefully.
I thought the whole point of the buildfarm was to provide a scalable way
of exercising different combinations of options that individual
developers couldn't practically test. We might need a little more
coordination among buildfarm owners to ensure we get full coverage,
of course.
regards, tom lane
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Peter Eisentraut <peter_e(at)gmx(dot)net>, Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 20:21:29 |
| Message-ID: | 50A3FD49.2020405@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11/14/2012 03:06 PM, Tom Lane wrote:
> Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
>> Regarding checksums, I can add an option for the initdb that the
>> buildfarm script runs. We already run different tests for different
>> encodings. Of course, constant expanding like this won't scale, so we
>> need to pick the options we want to exrecise carefully.
> I thought the whole point of the buildfarm was to provide a scalable way
> of exercising different combinations of options that individual
> developers couldn't practically test. We might need a little more
> coordination among buildfarm owners to ensure we get full coverage,
> of course.
>
>
Yes, true. So lets' wait and see how the checksums thing works out and
then we can tackle the buildfarm end. At any rate, I don't think the
buildfarm is a reason not to have this as an initdb setting.
cheers
andrew
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-14 23:24:17 |
| Message-ID: | 1352935457.18557.16.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> Hmm... what if we took this a step further and actually stored the
> checksums in a separate relation fork? That would make it pretty
> simple to support enabling/disabling checksums for particular
> relations. It would also allow us to have a wider checksum, like 32
> or 64 bits rather than 16. I'm not scoffing at a 16-bit checksum,
> because even that's enough to catch a very high percentage of errors,
> but it wouldn't be terrible to be able to support a wider one, either.
I don't remember exactly why this idea was sidelined before, but I don't
think there were any showstoppers. It does have some desirable
properties; most notably the ability to add checksums without a huge
effort, so perhaps the idea can be revived.
But there are some practical issues, as Tom points out. Another one is
that it's harder for external utilities (like pg_basebackup) to verify
checksums.
And I just had another thought: these pages of checksums would be data
pages, with an LSN. But as you clean ordinary data pages, you need to
constantly bump the LSN of the very same checksum page (because it
represents 1000 ordinary data pages); making it harder to actually clean
the checksum page and finish a checkpoint. Is this a practical concern
or am I borrowing trouble?
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-15 01:40:58 |
| Message-ID: | 1352943658.18557.27.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2012-11-13 at 15:27 -0500, Robert Haas wrote:
> A small
> patch that gets committed is better than a big one that doesn't.
Here's a small patch (two, actually, because the TLI one is
uninteresting and noisy). It's based on Simon's patch, but with some
significant changes:
* I ripped out all of the handling for a mix of some checksummed and
some non-checksummed pages. No more control bits or page version stuff.
* I moved the checksum to the pd_tli field, and renamed it
pd_checksum.
* vm/fsm_extend were not setting the verification information for some
reason. I'm not sure why, but since it's now on/off for the entire
system, they need to do the same thing.
* Added a flag to pg_control called data_checksums. It is set by
initdb when the "-k"/"--data-checksums" option is specified (open for
discussion).
* Added a function in xlog.c that is a simple reader of the control
file flag.
* Got rid of page_checksums GUC.
* Incorporated the page number into the checksum calculation, to
detect pages that are transposed.
I'll do another pass to make sure I update all of the comments, and try
to self review it. So, slightly rough in some places.
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| checksums.patch.gz | application/x-gzip | 17.3 KB |
| replace-tli-with-checksums.patch.gz | application/x-gzip | 7.4 KB |
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-15 02:22:41 |
| Message-ID: | CA+TgmoZWLYnGxDqJ1t5KZpOeO4yDO=99osTxGU0iaA9QP5mu=g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Nov 14, 2012 at 6:24 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
>> Hmm... what if we took this a step further and actually stored the
>> checksums in a separate relation fork? That would make it pretty
>> simple to support enabling/disabling checksums for particular
>> relations. It would also allow us to have a wider checksum, like 32
>> or 64 bits rather than 16. I'm not scoffing at a 16-bit checksum,
>> because even that's enough to catch a very high percentage of errors,
>> but it wouldn't be terrible to be able to support a wider one, either.
>
> I don't remember exactly why this idea was sidelined before, but I don't
> think there were any showstoppers. It does have some desirable
> properties; most notably the ability to add checksums without a huge
> effort, so perhaps the idea can be revived.
>
> But there are some practical issues, as Tom points out. Another one is
> that it's harder for external utilities (like pg_basebackup) to verify
> checksums.
>
> And I just had another thought: these pages of checksums would be data
> pages, with an LSN. But as you clean ordinary data pages, you need to
> constantly bump the LSN of the very same checksum page (because it
> represents 1000 ordinary data pages); making it harder to actually clean
> the checksum page and finish a checkpoint. Is this a practical concern
> or am I borrowing trouble?
Well, I think the invariant we'd need to maintain is as follows: every
page for which the checksum fork might be wrong must have an FPI
following the redo pointer. So, at the time we advance the redo
pointer, we need the checksum fork to be up-to-date for all pages for
which a WAL record was written after the old redo pointer except for
those for which a WAL record has again been written after the new redo
pointer. In other words, the checksum pages we write out don't need
to be completely accurate; the checksums for any blocks we know will
get clobbered anyway during replay don't really matter.
However, reading your comments, I do see one sticking point. If we
don't update the checksum page until a buffer is written out, which of
course makes a lot of sense, then during a checkpoint, we'd have to
flush all of the regular pages first and then all the checksum pages
afterward. Otherwise, the checksum pages wouldn't be sufficiently
up-to-date at the time we write them. There's no way to make that
happen just by fiddling with the LSN; rather, we'd need some kind of
two-pass algorithm over the buffer pool. That doesn't seem
unmanageable, but it's more complicated than what we do now.
I'm not sure we'd actually bother setting the LSN on the checksum
pages, because the action that prompts an update of a checksum page is
the decision to write out a non-checksum page, and that's not a
WAL-loggable action, so there's no obvious LSN to apply, and no
obvious need to apply one at all.
I'm also not quite sure what happens with full_page_writes=off. I
don't really see how to make this scheme work at all in that
environment. Keeping the checksum in the page seems to dodge quite a
few problems in that case ... as long as you assume that 8kB writes
really are atomic.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-15 19:44:45 |
| Message-ID: | 1353008685.14335.15.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2012-11-14 at 21:22 -0500, Robert Haas wrote:
> > But there are some practical issues, as Tom points out. Another one is
> > that it's harder for external utilities (like pg_basebackup) to verify
> > checksums.
> Well, I think the invariant we'd need to maintain is as follows: every
> page for which the checksum fork might be wrong must have an FPI
> following the redo pointer. So, at the time we advance the redo
> pointer, we need the checksum fork to be up-to-date for all pages for
> which a WAL record was written after the old redo pointer except for
> those for which a WAL record has again been written after the new redo
> pointer. In other words, the checksum pages we write out don't need
> to be completely accurate; the checksums for any blocks we know will
> get clobbered anyway during replay don't really matter.
The issue about external utilities is a bigger problem than I realized
at first. Originally, I thought that it was just a matter of code to
associate the checksum with the data.
However, an external utility will never see a torn page while the system
is online (after recovery); but it *will* see an inconsistent view of
the checksum and the data if they are issued in separate write() calls.
So, the hazard of storing the checksum in a different place is not
equivalent to the existing hazard of a torn page.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-18 20:04:30 |
| Message-ID: | 1353269070.10198.97.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2012-11-14 at 17:40 -0800, Jeff Davis wrote:
> I'll do another pass to make sure I update all of the comments, and try
> to self review it.
Updated patches attached (the TLI patch wasn't changed though, only the
main checksums patch).
Changes:
* A lot of cleanup
* More testing
* Added check during pg_upgrade to make sure the checksum settings
match.
* Fixed output of pg_resetxlog to include information about checksums.
* fixed contrib/pageinspect, and included upgrade script for it
* removed code to skip the page hole during the checksum calculation.
We can reconsider if we think performance will be a real problem.
* I added the header bits back in, because we will need them when we
want to support enabling/disabling checksums when the system is online.
I also did quite a bit more testing, although it could use some
performance testing. I'll also probably do another review pass myself,
but I think it's in good shape.
Also, if performance of the checksum calculation itself turns out to be
a problem, we might consider modifying the algorithm to do multiple
bytes at a time.
One purpose of this patch is to establish the on-disk format for
checksums, so we shouldn't defer decisions that would affect that (e.g.
doing checksum calculation in larger chunks, ignoring the page hole, or
using a different scheme for the bits in the header).
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| replace-tli-with-checksums-20121118.patch.gz | application/x-gzip | 7.4 KB |
| checksums-20121118.patch.gz | application/x-gzip | 19.9 KB |
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-19 16:48:52 |
| Message-ID: | CA+TgmoZZ0cZrPCjM+LutKRCswq-CO5NeeaALAmxHLKV=5K3jOw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Nov 15, 2012 at 2:44 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> The issue about external utilities is a bigger problem than I realized
> at first. Originally, I thought that it was just a matter of code to
> associate the checksum with the data.
>
> However, an external utility will never see a torn page while the system
> is online (after recovery); but it *will* see an inconsistent view of
> the checksum and the data if they are issued in separate write() calls.
> So, the hazard of storing the checksum in a different place is not
> equivalent to the existing hazard of a torn page.
I agree that the hazards are not equivalent, but I'm not sure I agree
that an external utility will never see a torn page while the system
is on-line. We have a bunch of code that essentially forces
full_page_writes=on during a base backup even if it's normally off. I
think that's necessary precisely because neither the 8kB write() nor
the unknown-sized-read used by the external copy program are
guaranteed to be atomic.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-19 17:22:45 |
| Message-ID: | 1353345765.10198.116.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-11-19 at 11:48 -0500, Robert Haas wrote:
> I agree that the hazards are not equivalent, but I'm not sure I agree
> that an external utility will never see a torn page while the system
> is on-line. We have a bunch of code that essentially forces
> full_page_writes=on during a base backup even if it's normally off. I
> think that's necessary precisely because neither the 8kB write() nor
> the unknown-sized-read used by the external copy program are
> guaranteed to be atomic.
This seems like a standards question that we should be able to answer
definitively:
Is it possible for a reader to see a partial write if both use the same
block size?
Maybe the reason we need full page writes during base backup is because
we don't know the block size of the reader, but if we did know that it
was the same, it would be fine?
If that is not true, then I'm concerned about replicating corruption, or
backing up corrupt blocks over good ones. How do we prevent that? It
seems like a pretty major hole if we can't, because it means the only
safe replication is streaming replication; a base-backup is essentially
unsafe. And it means that even an online background checking utility
would be quite hard to do properly.
Regards,
Jeff Davis
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-19 17:30:04 |
| Message-ID: | 20121119173004.GB3252@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2012-11-19 09:22:45 -0800, Jeff Davis wrote:
> On Mon, 2012-11-19 at 11:48 -0500, Robert Haas wrote:
> > I agree that the hazards are not equivalent, but I'm not sure I agree
> > that an external utility will never see a torn page while the system
> > is on-line. We have a bunch of code that essentially forces
> > full_page_writes=on during a base backup even if it's normally off. I
> > think that's necessary precisely because neither the 8kB write() nor
> > the unknown-sized-read used by the external copy program are
> > guaranteed to be atomic.
>
> This seems like a standards question that we should be able to answer
> definitively:
>
> Is it possible for a reader to see a partial write if both use the same
> block size?
Yes, definitely.
> If that is not true, then I'm concerned about replicating corruption, or
> backing up corrupt blocks over good ones. How do we prevent that? It
> seems like a pretty major hole if we can't, because it means the only
> safe replication is streaming replication; a base-backup is essentially
> unsafe. And it means that even an online background checking utility
> would be quite hard to do properly.
I am not sure I see the danger in the base backup case here? Why would
we have corrupted backup blocks? While postgres is running we won't see
such torn pages because its all done under proper locks...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-19 18:35:45 |
| Message-ID: | 1353350145.10198.130.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-11-19 at 18:30 +0100, Andres Freund wrote:
> Yes, definitely.
OK. I suppose that makes sense for large writes.
> > If that is not true, then I'm concerned about replicating corruption, or
> > backing up corrupt blocks over good ones. How do we prevent that? It
> > seems like a pretty major hole if we can't, because it means the only
> > safe replication is streaming replication; a base-backup is essentially
> > unsafe. And it means that even an online background checking utility
> > would be quite hard to do properly.
>
> I am not sure I see the danger in the base backup case here? Why would
> we have corrupted backup blocks? While postgres is running we won't see
> such torn pages because its all done under proper locks...
Yes, the blocks written *after* the checkpoint might have a bad checksum
that will be fixed during recovery. But the blocks written *before* the
checkpoint should have a valid checksum, but if they don't, then
recovery doesn't know about them.
So, we can't verify the checksums in the base backup because it's
expected that some blocks will fail the check, and they can be fixed
during recovery. That gives us no protection for blocks that were truly
corrupted and written long before the last checkpoint.
I suppose if we could somehow differentiate the blocks, that might work.
Maybe look at the LSN and only validate blocks written before the
checkpoint? But of course, that's a problem because a corrupt block
might have the wrong LSN (in fact, it's likely, because garbage is more
likely to make the LSN too high than too low).
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Craig Ringer <craig(at)2ndquadrant(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Jesper Krogh <jesper(at)krogh(dot)cc>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-19 21:46:23 |
| Message-ID: | 1353361583.1102.18.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-11-19 at 10:35 -0800, Jeff Davis wrote:
> Yes, the blocks written *after* the checkpoint might have a bad checksum
> that will be fixed during recovery. But the blocks written *before* the
> checkpoint should have a valid checksum, but if they don't, then
> recovery doesn't know about them.
>
> So, we can't verify the checksums in the base backup because it's
> expected that some blocks will fail the check, and they can be fixed
> during recovery. That gives us no protection for blocks that were truly
> corrupted and written long before the last checkpoint.
>
> I suppose if we could somehow differentiate the blocks, that might work.
> Maybe look at the LSN and only validate blocks written before the
> checkpoint? But of course, that's a problem because a corrupt block
> might have the wrong LSN (in fact, it's likely, because garbage is more
> likely to make the LSN too high than too low).
It might be good enough here to simply retry the checksum verification
if it fails for any block. Postgres shouldn't be issuing write()s for
the same block very frequently, and they shouldn't take very long, so
the chances of failing several times seems vanishingly small unless it's
a real failure.
Through a suitably complex mechanism, I think we can be more sure. The
external program could wait for a checkpoint (or force one manually),
and then recalculate the checksum for that page. If checksum is the same
as the last time, then we know the block is bad (because the checkpoint
would have waited for any writes in progress). If the checksum does
change, then we assume postgres must have modified it since the backup
started, so we can assume that we have a full page image to fix it. (A
checkpoint is a blunt tool here, because all we need to do is wait for
the write() call to finish, but it suffices.)
That complexity is probably not required, and simply retrying a few
times is probably much more practical. But it still bothers me a little
to think that the external tool could falsely indicate a checksum
failure, however remote that chance.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-11-26 02:32:46 |
| Message-ID: | 1353897166.10198.146.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Updated both patches.
Changes:
* Moved the changes to pageinspect into the TLI patch, because it
makes more sense to be a part of that patch and it also reduces the size
of the main checksums patch.
* Fix off-by-one bug in checksum calculation
* Replace "VerificationInfo" in the function names with "Checksum",
which is shorter.
* Make the checksum algorithm process 4 bytes at a time and sum into a
signed 64-bit int, which is faster than byte-at-a-time. Also, forbid
zero in either byte of the checksum, because that seems like a good
idea.
I've done quite a bit of testing at this point, and everything seems
fine to me. I've tested various kinds of errors (bytes being modified or
zeroed at various places of the header and data areas, transposed pages)
at 8192 and 32768 page sizes. I also looked at the distribution of
checksums in various ways (group by checksum % <prime> for various
primes, and not seeing any skew), and I didn't see any worrying
patterns.
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| replace-tli-with-checksums-20121125.patch.gz | application/x-gzip | 8.8 KB |
| checksums-20121125.patch.gz | application/x-gzip | 18.9 KB |
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-03 09:56:51 |
| Message-ID: | CA+U5nMKiDnH8OVx+UCWhSCEMtbwDvBr2sR59fCyWxq-QA_Rzxg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26 November 2012 02:32, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> Updated both patches.
>
> Changes:
> * Moved the changes to pageinspect into the TLI patch, because it
> makes more sense to be a part of that patch and it also reduces the size
> of the main checksums patch.
> * Fix off-by-one bug in checksum calculation
> * Replace "VerificationInfo" in the function names with "Checksum",
> which is shorter.
> * Make the checksum algorithm process 4 bytes at a time and sum into a
> signed 64-bit int, which is faster than byte-at-a-time. Also, forbid
> zero in either byte of the checksum, because that seems like a good
> idea.
>
> I've done quite a bit of testing at this point, and everything seems
> fine to me. I've tested various kinds of errors (bytes being modified or
> zeroed at various places of the header and data areas, transposed pages)
> at 8192 and 32768 page sizes. I also looked at the distribution of
> checksums in various ways (group by checksum % <prime> for various
> primes, and not seeing any skew), and I didn't see any worrying
> patterns.
I think the way forwards for this is...
1. Break out the changes around inCommit flag, since that is just
uncontroversial refactoring. I can do that. That reduces the noise
level in the patch and makes it easier to understand the meaningful
changes.
2. Produce an SGML docs page that describes how this works, what the
limitations and tradeoffs are. "Reliability & the WAL" could use an
extra section2 header called Checksums (wal.sgml). This is essential
for users AND reviewers to ensure everybody has understood this (heck,
I can't remember everything about this either...)
3. I think we need an explicit test of this feature (as you describe
above), rather than manual testing. corruptiontester?
4. We need some general performance testing to show whether this is
insane or not.
But this looks in good shape for commit otherwise.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-03 13:16:36 |
| Message-ID: | CA+U5nMK_WSz774-nPSqbZWG0k5ewsyokz4+c3XeU5RhDbLK7xA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3 December 2012 09:56, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> I think the way forwards for this is...
>
> 1. Break out the changes around inCommit flag, since that is just
> uncontroversial refactoring. I can do that. That reduces the noise
> level in the patch and makes it easier to understand the meaningful
> changes.
Done.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-03 13:18:52 |
| Message-ID: | CA+U5nMKG_4xXWV7oui9sGj9QuAbxySwfDwkhbk7m6CxLJm3DCQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26 November 2012 02:32, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> * Make the checksum algorithm process 4 bytes at a time and sum into a
> signed 64-bit int, which is faster than byte-at-a-time. Also, forbid
> zero in either byte of the checksum, because that seems like a good
> idea.
Like that, especially the bit where we use the blocknumber as the seed
for the checksum, so it will detect transposed pages. That's also a
really neat way of encrypting the data for anybody that tries to
access things via direct anonymous file access.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-04 08:11:46 |
| Message-ID: | 1354608706.2638.2.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-12-03 at 13:16 +0000, Simon Riggs wrote:
> On 3 December 2012 09:56, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>
> > I think the way forwards for this is...
> >
> > 1. Break out the changes around inCommit flag, since that is just
> > uncontroversial refactoring. I can do that. That reduces the noise
> > level in the patch and makes it easier to understand the meaningful
> > changes.
>
> Done.
Thank you.
One minor thing I noticed: it looks like nwaits is a useless variable.
Your original checksums patch used it to generate a warning, but now
that is gone. It's not throwing a compiler warning for some reason.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-04 09:03:36 |
| Message-ID: | 1354611816.28666.7.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-12-03 at 09:56 +0000, Simon Riggs wrote:
> 1. Break out the changes around inCommit flag, since that is just
> uncontroversial refactoring. I can do that. That reduces the noise
> level in the patch and makes it easier to understand the meaningful
> changes.
Done by you.
> 2. Produce an SGML docs page that describes how this works, what the
> limitations and tradeoffs are. "Reliability & the WAL" could use an
> extra section2 header called Checksums (wal.sgml). This is essential
> for users AND reviewers to ensure everybody has understood this (heck,
> I can't remember everything about this either...)
Agreed. It looks like it would fit best under the Reliability section,
because it's not directly related to WAL. I'll write something up.
> 3. I think we need an explicit test of this feature (as you describe
> above), rather than manual testing. corruptiontester?
I agree, but I'm not 100% sure how to proceed. I'll look at Kevin's
tests for SSI and see if I can do something similar, but suggestions are
welcome. A few days away, at the earliest.
> 4. We need some general performance testing to show whether this is
> insane or not.
My understanding is that Greg Smith is already working on tests here, so
I will wait for his results.
> But this looks in good shape for commit otherwise.
Great!
For now, I rebased the patches against master, and did some very minor
cleanup.
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| checksums-20121203.patch.gz | application/x-gzip | 14.6 KB |
| replace-tli-with-checksums-20121203.patch.gz | application/x-gzip | 8.8 KB |
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-04 23:17:41 |
| Message-ID: | 1354663061.4530.64.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2012-12-04 at 01:03 -0800, Jeff Davis wrote:
> > 3. I think we need an explicit test of this feature (as you describe
> > above), rather than manual testing. corruptiontester?
>
> I agree, but I'm not 100% sure how to proceed. I'll look at Kevin's
> tests for SSI and see if I can do something similar, but suggestions are
> welcome. A few days away, at the earliest.
I looked into this. The SSI tests still use pg_regress to start/stop the
server, and make use of a lot more of the pg_regress framework.
pg_regress doesn't fit what I need to do, at all.
For me, each test involves a fresh initdb, followed by a small data load
(at least a few pages). Then, I shut down the server, inject the faults
under test, and start the server back up. Then, I count the table and
expect an error. Then I throw away the data directory. (I can shortcut
some of the initdb and load time by keeping a good copy of the table
throughout the whole set of tests and copying it back, but that's just a
detail.)
So, I could try to write a test framework in C that would be a candidate
to include with the main distribution and be run by the buildfarm, but
that would be a lot of work. Even then, I couldn't easily abstract away
these kinds of tests into text files, unless I invent a language that is
suitable for describing disk faults to inject.
Or, I could write up a test framework in ruby or python, using the
appropriate pg driver, and some not-so-portable shell commands to start
and stop the server. Then, I can publish that on this list, and that
would at least make it easier to test semi-manually and give greater
confidence in pre-commit revisions.
Suggestions?
Regards,
Jeff Davis
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-05 23:40:47 |
| Message-ID: | CA+Tgmobb9ynO+7DfPp3qVogS9eSrPGBWHtcwjpibSd2K261Abw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Dec 4, 2012 at 6:17 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> Or, I could write up a test framework in ruby or python, using the
> appropriate pg driver, and some not-so-portable shell commands to start
> and stop the server. Then, I can publish that on this list, and that
> would at least make it easier to test semi-manually and give greater
> confidence in pre-commit revisions.
That latter approach is similar to what happened with SSI's isolation
tester. It started out in Python, and then Heikki rewrote it in C.
If Python/Ruby code is massively simpler to write than the C code,
that might be a good way to start out. It'll be an aid to reviewers
even if neither it nor any descendent gets committed.
Frankly, I think some automated testing harness (written in C or Perl)
that could do fault-injection tests as part of the buildfarm would be
amazingly awesome. I'm drooling just thinking about it. But I guess
that's getting ahead of myself.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-05 23:49:42 |
| Message-ID: | CA+U5nM+HEJkgOA2PgmDpYg0-UYxafvvgbV8hbg=MxBZ8pS3TZQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 5 December 2012 23:40, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> On Tue, Dec 4, 2012 at 6:17 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
>> Or, I could write up a test framework in ruby or python, using the
>> appropriate pg driver, and some not-so-portable shell commands to start
>> and stop the server. Then, I can publish that on this list, and that
>> would at least make it easier to test semi-manually and give greater
>> confidence in pre-commit revisions.
>
> That latter approach is similar to what happened with SSI's isolation
> tester. It started out in Python, and then Heikki rewrote it in C.
> If Python/Ruby code is massively simpler to write than the C code,
> that might be a good way to start out. It'll be an aid to reviewers
> even if neither it nor any descendent gets committed.
>
> Frankly, I think some automated testing harness (written in C or Perl)
> that could do fault-injection tests as part of the buildfarm would be
> amazingly awesome. I'm drooling just thinking about it. But I guess
> that's getting ahead of myself.
Agreed, though we can restrict that to a few things at first.
* Zeroing pages, making pages all 1s
* Transposing pages
* Moving chunks of data sideways in a block
* Flipping bits randomly
* Flipping data endianness
* Destroying particular catalog tables or structures
etc
As a contrib module, so we can be sure to never install it. ;-)
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-12 22:52:17 |
| Message-ID: | 50C90AA1.4030005@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/5/12 6:49 PM, Simon Riggs wrote:
> * Zeroing pages, making pages all 1s
> * Transposing pages
> * Moving chunks of data sideways in a block
> * Flipping bits randomly
> * Flipping data endianness
> * Destroying particular catalog tables or structures
I can take this on, as part of the QA around checksums working as
expected. The result would be a Python program; I don't have quite
enough time to write this in C or re-learn Perl to do it right now. But
this won't be a lot of code. If it's tossed one day as simply a
prototype for something more permanent, I think it's still worth doing now.
The UI I'm thinking of for what I'm going to call pg_corrupt is a CLI
that asks for:
-A relation name
-Corruption type (an entry from this list)
-How many blocks to touch
I'll just loop based on the count, randomly selecting a block each time
and messing with it in that way.
The randomness seed should be printed as part of the output, so that
it's possible re-create the damage exactly later. If the server doesn't
handle it correctly, we'll want to be able to replicate the condition it
choked on exactly later, just based on the tool's log output.
Any other requests?
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-14 20:00:24 |
| Message-ID: | 1355515224.15663.89.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2012-12-12 at 17:52 -0500, Greg Smith wrote:
> I can take this on, as part of the QA around checksums working as
> expected. The result would be a Python program; I don't have quite
> enough time to write this in C or re-learn Perl to do it right now. But
> this won't be a lot of code. If it's tossed one day as simply a
> prototype for something more permanent, I think it's still worth doing now.
>
> The UI I'm thinking of for what I'm going to call pg_corrupt is a CLI
> that asks for:
>
> -A relation name
> -Corruption type (an entry from this list)
> -How many blocks to touch
>
> I'll just loop based on the count, randomly selecting a block each time
> and messing with it in that way.
>
> The randomness seed should be printed as part of the output, so that
> it's possible re-create the damage exactly later. If the server doesn't
> handle it correctly, we'll want to be able to replicate the condition it
> choked on exactly later, just based on the tool's log output.
>
> Any other requests?
After some thought, I don't see much value in introducing multiple
instances of corruption at a time. I would think that the smallest unit
of corruption would be the hardest to detect, so by introducing many of
them in one pass makes it easier to detect.
For example, if we introduce an all-ones page, and also transpose two
pages, the all-ones error might be detected even if the transpose error
is not being detected properly. And we'd not know that the transpose
error was not being detected, because the error appears as soon as it
sees the all-ones page.
Does it make sense to have a separate executable (pg_corrupt) just for
corrupting the data as a test? Or should it be part of a
corruption-testing harness (pg_corruptiontester?), that introduces the
corruption and then verifies that it's properly detected?
Regards,
Jeff Davis
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-14 20:15:41 |
| Message-ID: | 50CB88ED.10303@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/14/12 3:00 PM, Jeff Davis wrote:
> After some thought, I don't see much value in introducing multiple
> instances of corruption at a time. I would think that the smallest unit
> of corruption would be the hardest to detect, so by introducing many of
> them in one pass makes it easier to detect.
That seems reasonable. It would eliminate a lot of issues with
reproducing a fault too. I can just print the impacted block number
presuming it will show up in a log, and make it possible to override
picking one at random with a command line input.
> Does it make sense to have a separate executable (pg_corrupt) just for
> corrupting the data as a test? Or should it be part of a
> corruption-testing harness (pg_corruptiontester?), that introduces the
> corruption and then verifies that it's properly detected?
Let me see what falls out of the coding, I don't think this part needs
to get nailed down yet. Building a corruption testing harness is going
to involve a lot of creating new clusters and test data to torture.
It's a different style of problem than injecting faults in the first place.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Dimitri Fontaine <dimitri(at)2ndQuadrant(dot)fr> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-17 14:42:28 |
| Message-ID: | m2sj74zqnf.fsf@2ndQuadrant.fr |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Davis <pgsql(at)j-davis(dot)com> writes:
>> -A relation name
>> -Corruption type (an entry from this list)
>> -How many blocks to touch
>>
>> I'll just loop based on the count, randomly selecting a block each time
>> and messing with it in that way.
For the messing with it part, did you consider zzuf?
> Does it make sense to have a separate executable (pg_corrupt) just for
> corrupting the data as a test? Or should it be part of a
> corruption-testing harness (pg_corruptiontester?), that introduces the
> corruption and then verifies that it's properly detected?
Maybe we need our own zzuf implementation, though.
Regards,
--
Dimitri Fontaine
http://2ndQuadrant.fr PostgreSQL : Expertise, Formation et Support
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-17 19:14:22 |
| Message-ID: | CA+U5nM+fXBGj1eUr=p_cCb1hy0QaoEmge+YhL-u7=1nhsOO24A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 14 December 2012 20:15, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 12/14/12 3:00 PM, Jeff Davis wrote:
>>
>> After some thought, I don't see much value in introducing multiple
>> instances of corruption at a time. I would think that the smallest unit
>> of corruption would be the hardest to detect, so by introducing many of
>> them in one pass makes it easier to detect.
>
>
> That seems reasonable. It would eliminate a lot of issues with reproducing
> a fault too. I can just print the impacted block number presuming it will
> show up in a log, and make it possible to override picking one at random
> with a command line input.
Discussing this makes me realise that we need a more useful response
than just "your data is corrupt", so user can respond "yes, I know,
I'm trying to save whats left".
We'll need a way of expressing some form of corruption tolerance.
zero_damaged_pages is just insane, much better if we set
corruption_tolerance = N to allow us to skip N corrupt pages before
failing, with -1 meaning keep skipping for ever. Settable by superuser
only.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-17 19:29:21 |
| Message-ID: | 29774.1355772561@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Simon Riggs <simon(at)2ndQuadrant(dot)com> writes:
> Discussing this makes me realise that we need a more useful response
> than just "your data is corrupt", so user can respond "yes, I know,
> I'm trying to save whats left".
> We'll need a way of expressing some form of corruption tolerance.
> zero_damaged_pages is just insane, much better if we set
> corruption_tolerance = N to allow us to skip N corrupt pages before
> failing, with -1 meaning keep skipping for ever. Settable by superuser
> only.
Define "skip". Extra points if it makes sense for an index. And what
about things like pg_clog pages?
regards, tom lane
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-17 21:42:54 |
| Message-ID: | CA+U5nM+5M-VeARvEeqcbKzLsE6LoXrnbFkt=6JoLY9hh085QbQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17 December 2012 19:29, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Simon Riggs <simon(at)2ndQuadrant(dot)com> writes:
>> Discussing this makes me realise that we need a more useful response
>> than just "your data is corrupt", so user can respond "yes, I know,
>> I'm trying to save whats left".
>
>> We'll need a way of expressing some form of corruption tolerance.
>> zero_damaged_pages is just insane, much better if we set
>> corruption_tolerance = N to allow us to skip N corrupt pages before
>> failing, with -1 meaning keep skipping for ever. Settable by superuser
>> only.
>
> Define "skip".
Allow data access, but accept that the answer is silently incomplete.
Not really much difference from zero_damaged_pages which just removes
the error by removing any chance of repair or recovery, and then
silently gives the wrong answer.
> Extra points if it makes sense for an index.
I guess not, but that's no barrier to it working on heap pages only,
in my suggested use case.
> And what about things like pg_clog pages?
SLRUs aren't checksummed because of their lack of header space.
Perhaps that is a major point against the patch.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-18 02:21:12 |
| Message-ID: | 1355797272.24766.187.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2012-12-17 at 19:14 +0000, Simon Riggs wrote:
> We'll need a way of expressing some form of corruption tolerance.
> zero_damaged_pages is just insane,
The main problem I see with zero_damaged_pages is that it could
potentially write out the zero page, thereby really losing your data if
it wasn't already lost. (Of course, we document that you should have a
backup first, but it's still dangerous). I assume that this is the same
problem you are talking about.
I suppose we could have a new ReadBufferMaybe function that would only
be used by a sequential scan; and then just skip over the page if it's
corrupt, depending on a GUC. That would at least allow sequential scans
to (partially) work, which might be good enough for some data recovery
situations. If a catalog index is corrupted, that could just be rebuilt.
Haven't thought about the details, though.
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-18 08:17:29 |
| Message-ID: | CA+U5nMLm5f=Y14HeXz+Q2Zuo2By_saQ=LR6AJ1eK0xkYuxEB5g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 18 December 2012 02:21, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Mon, 2012-12-17 at 19:14 +0000, Simon Riggs wrote:
>> We'll need a way of expressing some form of corruption tolerance.
>> zero_damaged_pages is just insane,
>
> The main problem I see with zero_damaged_pages is that it could
> potentially write out the zero page, thereby really losing your data if
> it wasn't already lost. (Of course, we document that you should have a
> backup first, but it's still dangerous). I assume that this is the same
> problem you are talking about.
I think we should discuss whether we accept my premise? Checksums will
actually detect more errors than we see now, and people will want to
do something about that. Returning to backup is one way of handling
it, but on a busy production system with pressure on, there is
incentive to implement a workaround, not a fix. It's not an easy call
to say "we've got 3 corrupt blocks, so I'm going to take the whole
system offline while I restore from backup".
If you do restore from backup, and the backup also contains the 3
corrupt blocks, what then?
Clearly part of the response could involve pg_dump on the damaged
structure, at some point.
> I suppose we could have a new ReadBufferMaybe function that would only
> be used by a sequential scan; and then just skip over the page if it's
> corrupt, depending on a GUC. That would at least allow sequential scans
> to (partially) work, which might be good enough for some data recovery
> situations. If a catalog index is corrupted, that could just be rebuilt.
> Haven't thought about the details, though.
Not sure if you're being facetious here or not. Mild reworking of the
logic for heap page access could cope with a NULL buffer response and
subsequent looping, which would allow us to run pg_dump against a
damaged table to allow data to be saved, keeping file intact for
further analysis.
I'm suggesting we work a little harder than "your block is corrupt"
and give some thought to what the user will do next. Indexes are a
good case, because we can/should report the block error, mark the
index as invalid and then hint that it should be rebuilt.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-18 09:06:02 |
| Message-ID: | 50D031FA.6030307@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/18/12 3:17 AM, Simon Riggs wrote:
> Clearly part of the response could involve pg_dump on the damaged
> structure, at some point.
This is the main thing I wanted to try out more, once I have a decent
corruption generation tool. If you've corrupted a single record but can
still pg_dump the remainder, that seems the best we can do to help
people recover from that. Providing some documentation on how to figure
out what rows are in that block, presumably by using the contrib
inspection tools, would be helpful too.
> Indexes are a good case, because we can/should report the block error, mark the
> index as invalid and then hint that it should be rebuilt.
Marking a whole index invalid because there's one bad entry has enough
downsides that I'm not sure how much we'd want to automate that. Not
having that index available could easily result in an effectively down
system due to low performance. The choices are uglier if it's backing a
unique constraint.
In general, what I hope people will be able to do is switch over to
their standby server, and then investigate further. I think it's
unlikely that people willing to pay for block checksums will only have
one server. Having some way to nail down if the same block is bad on a
given standby seems like a useful interface we should offer, and it
shouldn't take too much work. Ideally you won't find the same
corruption there. I'd like a way to check the entirety of a standby for
checksum issues, ideally run right after it becomes current. It seems
the most likely way to see corruption on one of those is to replicate a
corrupt block.
There is no good way to make the poor soul who has no standby server
happy here. You're just choosing between bad alternatives. The first
block error is often just that--the first one, to be joined by others
soon afterward. My experience at how drives fail says the second error
is a lot more likely after you've seen one.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-18 20:49:03 |
| Message-ID: | 1355863743.24766.196.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2012-12-18 at 08:17 +0000, Simon Riggs wrote:
> I think we should discuss whether we accept my premise? Checksums will
> actually detect more errors than we see now, and people will want to
> do something about that. Returning to backup is one way of handling
> it, but on a busy production system with pressure on, there is
> incentive to implement a workaround, not a fix. It's not an easy call
> to say "we've got 3 corrupt blocks, so I'm going to take the whole
> system offline while I restore from backup".
Up until now, my assumption has generally been that, upon finding the
corruption, the primary course of action is taking that server down
(hopefully you have a good replica), and do some kind of restore or sync
a new replica.
It sounds like you are exploring other possibilities.
> > I suppose we could have a new ReadBufferMaybe function that would only
> > be used by a sequential scan; and then just skip over the page if it's
> > corrupt, depending on a GUC. That would at least allow sequential scans
> > to (partially) work, which might be good enough for some data recovery
> > situations. If a catalog index is corrupted, that could just be rebuilt.
> > Haven't thought about the details, though.
>
> Not sure if you're being facetious here or not.
No. It was an incomplete thought (as I said), but sincere.
> Mild reworking of the
> logic for heap page access could cope with a NULL buffer response and
> subsequent looping, which would allow us to run pg_dump against a
> damaged table to allow data to be saved, keeping file intact for
> further analysis.
Right.
> I'm suggesting we work a little harder than "your block is corrupt"
> and give some thought to what the user will do next. Indexes are a
> good case, because we can/should report the block error, mark the
> index as invalid and then hint that it should be rebuilt.
Agreed; this applies to any derived data.
I don't think it will be very practical to keep a server running in this
state forever, but it might give enough time to reach a suitable
maintenance window.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-18 20:52:25 |
| Message-ID: | 1355863945.24766.200.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2012-12-18 at 04:06 -0500, Greg Smith wrote:
> Having some way to nail down if the same block is bad on a
> given standby seems like a useful interface we should offer, and it
> shouldn't take too much work. Ideally you won't find the same
> corruption there. I'd like a way to check the entirety of a standby for
> checksum issues, ideally run right after it becomes current. It seems
> the most likely way to see corruption on one of those is to replicate a
> corrupt block.
Part of the design is that pg_basebackup would verify checksums during
replication, so we should not replicate corrupt blocks (of course,
that's not implemented yet, so it's still a concern for now).
And we can also have ways to do background/offline checksum verification
with a separate utility.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-19 23:30:41 |
| Message-ID: | 1355959841.24766.286.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2012-12-04 at 01:03 -0800, Jeff Davis wrote:
> > 4. We need some general performance testing to show whether this is
> > insane or not.
I ran a few tests.
Test 1 - find worst-case overhead for the checksum calculation on write:
fsync = off
bgwriter_lru_maxpages = 0
shared_buffers = 1024MB
checkpoint_segments = 64
autovacuum = off
The idea is to prevent interference from the bgwriter or autovacuum.
Also, I turn of fsync so that it's measuring the calculation overhead,
not the effort of actually writing to disk.
drop table foo;
create table foo(i int, j int) with (fillfactor=50);
create index foo_idx on foo(i);
insert into foo select g%25, -1 from generate_series(1,10000000) g;
checkpoint;
-- during the following sleep, issue an OS "sync"
-- to make test results more consistent
select pg_sleep(30);
\timing on
update foo set j=-1 where i = 0;
select pg_sleep(2);
checkpoint;
update foo set j=-1 where i = 0;
select pg_sleep(2);
checkpoint;
update foo set j=-1 where i = 0;
select pg_sleep(2);
checkpoint;
\timing off
I am measuring the time of the CHECKPOINT command, not the update. The
update is just to dirty all of the pages (they should all be HOT
updates). Without checksums, it takes about 400ms. With checksums, it
takes about 500ms. That overhead is quite low, considering that the
bottleneck is almost always somewhere else (like actually writing to
disk).
Test 2 - worst-case overhead for calculating checksum while reading data
Same configuration as above. This time, just load a big table:
drop table foo;
create table foo(i int, j int) with (fillfactor=50);
insert into foo select g%25, -1 from generate_series(1,10000000) g;
-- make sure hint bits and PD_ALL_VISIBLE are set everywhere
select count(*) from foo;
vacuum;
vacuum;
vacuum;
select relfilenode from pg_class where relname='foo';
Then shut down the server and restart it. Then do a "cat
data/base/12055/XXXX* > /dev/null" to get the table loaded into the OS
buffer cache. Then do:
\timing on
SELECT COUNT(*) FROM foo;
So, shared buffers are cold, but OS cache is warm. This should test the
overhead of going from the OS to shared buffers, which requires the
checksum calculation. Without checksums is around 820ms; with checksums
around 970ms. Again, this is quite reasonable, because I would expect
the bottleneck to be reading from the disk rather than the calculation
itself.
Test 3 - worst-case WAL overhead
For this test, I also left fsync off, because I didn't want to test the
effort to flush WAL (which shouldn't really be required for this test,
anyway). This was simpler:
drop table foo;
create table foo(i int, j int) with (fillfactor=50);
insert into foo select g%25, -1 from generate_series(1,10000000) g;
checkpoint;
select pg_sleep(1);
checkpoint;
select pg_sleep(30); -- do an OS "sync" while this is running
\timing on
SELECT COUNT(*) FROM foo;
Without checksums, it takes about 1000ms. With checksums, about 2350ms.
I also tested with checksums but without the CHECKPOINT commands above,
and it was also 1000ms.
This test is more plausible than the other two, so it's more likely to
be a real problem. So, the biggest cost of checksums is, by far, the
extra full-page images in WAL, which matches our expectations.
Regards,
Jeff Davis
| From: | Martijn van Oosterhout <kleptog(at)svana(dot)org> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2012-12-20 16:39:09 |
| Message-ID: | 20121220163908.GA29459@svana.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Dec 18, 2012 at 04:06:02AM -0500, Greg Smith wrote:
> On 12/18/12 3:17 AM, Simon Riggs wrote:
> >Clearly part of the response could involve pg_dump on the damaged
> >structure, at some point.
>
> This is the main thing I wanted to try out more, once I have a
> decent corruption generation tool. If you've corrupted a single
> record but can still pg_dump the remainder, that seems the best we
> can do to help people recover from that. Providing some
> documentation on how to figure out what rows are in that block,
> presumably by using the contrib inspection tools, would be helpful
> too.
FWIW, Postgres is pretty resiliant against corruption. I've maintained
a postgres db on a server with bad memory (don't ask) and since most
scrambling was in text strings you just got funny output sometimes. The
most common failure was a memory allocation failure as postgres tried
to copy a datum whose length field was correupted.
If things went really wonky you could identify the bad tuples by hand
and then delete them by ctid. Regular reindexing helped too.
All I'm saying is that a mode where you log a warning but proceed
anyway is useful. It won't pin down the exact error, but it will tell
you where to look and help find the non-obvious corruption (so you can
possibly fix it by hand).
Have a nice day,
--
Martijn van Oosterhout <kleptog(at)svana(dot)org> http://svana.org/kleptog/
> He who writes carelessly confesses thereby at the very outset that he does
> not attach much importance to his own thoughts.
-- Arthur Schopenhauer
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-10 06:06:40 |
| Message-ID: | 1357798000.5162.38.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2012-12-04 at 01:03 -0800, Jeff Davis wrote:
> For now, I rebased the patches against master, and did some very minor
> cleanup.
I think there is a problem here when setting PD_ALL_VISIBLE. I thought I
had analyzed that before, but upon review, it doesn't look right.
Setting PD_ALL_VISIBLE needs to be associated with a WAL action somehow,
and a bumping of the LSN, otherwise there is a torn page hazard.
The solution doesn't seem particularly difficult, but there are a few
strange aspects and I'm not sure exactly which path I should take.
First of all, the relationship between MarkBufferDirty and
SetBufferCommitInfoNeedsSave is a little confusing. The comment over
MarkBufferDirty is confusing because it says that the caller must have
an exclusive lock, or else bad data could be written. But that doesn't
have to do with marking the buffer dirty, that has to do with the data
page change you make while you are marking it dirty -- if it's a single
bit change, then there is no risk that I can see.
In the current code, the only real code difference between the two is
that SetBufferCommitInfoNeedsSave might fail to mark the buffer dirty if
there is a race. So, in the current code, we could actually combine the
two by passing a "force" flag (if true, behaves like MarkBufferDirty, if
false, behaves like SetBufferCommitInfoNeedsSave).
The checksums patch also introduces another behavior into
SetBufferCommitInfoNeedsSave, which is to write an XLOG_HINT WAL record
if checksums are enabled (to avoid torn page hazards). That's only
necessary for changes where the caller does not write WAL itself and
doesn't bump the LSN of the data page. (There's a reason the caller
can't easily write the XLOG_HINT WAL itself.) So, we could introduce
another flag "needsWAL" that would control whether we write the
XLOG_HINT WAL or not (only applies with checksums on, of course).
The reason for all of this is because the setting of PD_ALL_VISIBLE does
not fit MarkBufferDirty, because MarkBufferDirty does not write the
XLOG_HINT WAL and neither does the caller. But it also doesn't fit
SetBufferCommitInfoNeedsSave, because that is subject to a race. If
MarkBufferDirty had the signature:
MarkBufferDirty(Buffer buffer, bool force, bool needsWAL)
then "normal" page changes would look like:
MarkBufferDirty(buffer, true, false)
setting PD_ALL_VISIBLE would look like:
MarkBufferDirty(buffer, true, true)
and setting a hint would look like:
MarkBufferDirty(buffer, false, true)
Another approach would be for the caller who sets PD_ALL_VISIBLE to
write WAL. But that requires inventing a new WAL record or chaining the
heap block onto the wal entry when doing visibilitymap_set (only
necessary when checksums are on). That seems somewhat of a hack, but
perhaps it's not too bad.
Also, I have another patch posted that is removing PD_ALL_VISIBLE
entirely, which is dampening my enthusiasm to do too much work that
might be thrown away. So right now, I'm leaning toward just adding the
heap buffer to the WAL chain during visibilitymap_set.
Thoughts?
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-10 09:10:33 |
| Message-ID: | CA+U5nM+HeZ5u4Rs2w1RKjFJdif4uprY3WmLqhBNCyusoSdAu3w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10 January 2013 06:06, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> The checksums patch also introduces another behavior into
> SetBufferCommitInfoNeedsSave, which is to write an XLOG_HINT WAL record
> if checksums are enabled (to avoid torn page hazards). That's only
> necessary for changes where the caller does not write WAL itself and
> doesn't bump the LSN of the data page. (There's a reason the caller
> can't easily write the XLOG_HINT WAL itself.) So, we could introduce
> another flag "needsWAL" that would control whether we write the
> XLOG_HINT WAL or not (only applies with checksums on, of course).
That wouldn't work because it can't know the exact answer to that, but
the way the patch does this is already correct.
XLOG_HINT_WAL doesn't always write a WAL record, it only does it when
necessary. See XLogInsert()
Didn't fully understand other comments. Do we we need an answer now?
My head is somewhere else.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-10 19:04:03 |
| Message-ID: | 1357844643.13602.15.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> > The checksums patch also introduces another behavior into
> > SetBufferCommitInfoNeedsSave, which is to write an XLOG_HINT WAL record
> > if checksums are enabled (to avoid torn page hazards). That's only
> > necessary for changes where the caller does not write WAL itself and
> > doesn't bump the LSN of the data page. (There's a reason the caller
> > can't easily write the XLOG_HINT WAL itself.) So, we could introduce
> > another flag "needsWAL" that would control whether we write the
> > XLOG_HINT WAL or not (only applies with checksums on, of course).
>
> That wouldn't work because it can't know the exact answer to that, but
> the way the patch does this is already correct.
The name I chose was poor, but the flag should mean "the caller does not
write WAL associated with this action". If that flag is true, and if
checksums are enabled, then it would do an XLogInsert, which may write
WAL (depending on the LSN check).
That part of the patch is correct currently, but the problem is with
updates to PD_ALL_VISIBLE. Let me try to explain again:
Calls to PageSetAllVisible are not directly associated with a WAL
action, but they are associated with a call to MarkBufferDirty and do
have an exclusive content lock on the buffer. There's a torn page hazard
there for checksums, because without any WAL action associated with the
data page, there is no backup page.
One idea might be to use SetBufferCommitInfoNeedsSave (which will write
WAL if necessary) instead of MarkBufferDirty. But that is unsafe,
because it might not actually mark the buffer dirty due to a race
(documented in SetBufferCommitInfoNeedsSave). So that's why I wanted to
refactor MarkBufferDirty/SetBufferCommitInfoNeedsSave, to separate the
concept that it may need a WAL record from the concept that actually
dirtying the page is optional.
Another idea is to make the WAL action for visibilitymap_set have
another item in the chain pointing to the heap buffer, and bump the heap
LSN.
Regards,
Jeff Davis
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-13 06:05:04 |
| Message-ID: | 50F24E90.6040007@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/19/12 6:30 PM, Jeff Davis wrote:
> The idea is to prevent interference from the bgwriter or autovacuum.
> Also, I turn of fsync so that it's measuring the calculation overhead,
> not the effort of actually writing to disk.
With my test server issues sorted, what I did was setup a single 7200RPM
drive with a battery-backed write cache card. That way fsync doesn't
bottleneck things. And I to realized that limit had to be cracked
before anything use useful could be done. Having the BBWC card is a bit
better than fsync=off, because we'll get something more like the
production workload out of it. I/O will be realistic, but limited to
only one one drive can pull off.
> Without checksums, it takes about 1000ms. With checksums, about 2350ms.
> I also tested with checksums but without the CHECKPOINT commands above,
> and it was also 1000ms.
I think we need to use lower checkpoint_segments to try and trigger more
checkpoints. My 10 minute pgbench-tool runs will normally have at most
3 checkpoints. I would think something like 10 would be more useful, to
make sure we're spending enough time seeing extra WAL writes;
> This test is more plausible than the other two, so it's more likely to
> be a real problem. So, the biggest cost of checksums is, by far, the
> extra full-page images in WAL, which matches our expectations.
What I've done with pgbench-tools is actually measure the amount of WAL
from the start to the end of the test run. To analyze it you need to
scale it a bit; computing "wal bytes / commit" seems to work.
pgbench-tools also launches vmstat and isstat in a way that it's
possible to graph the values later. The interesting results I'm seeing
are when the disk is about 80% busy and when it's 100% busy.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-16 00:36:46 |
| Message-ID: | 50F5F61E.2000806@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
First rev of a simple corruption program is attached, in very C-ish
Python. The parameters I settled on are to accept a relation name, byte
offset, byte value, and what sort of operation to do: overwrite, AND,
OR, XOR. I like XOR here because you can fix it just by running the
program again. Rewriting this in C would not be terribly difficult, and
most of the time spent on this version was figuring out what to do.
This follows Jeff's idea that the most subtle corruption is the hardest
to spot, so testing should aim at the smallest unit of change. If you
can spot a one bit error in an unused byte of a page, presumably that
will catch large errors like a byte swap. I find some grim amusement
that the checksum performance testing I've been trying to do got stuck
behind a problem with a tiny, hard to detect single bit of corruption.
Here's pgbench_accounts being corrupted, the next to last byte on this line:
$ pgbench -i -s 1
$ ./pg_corrupt pgbench_accounts show
Reading byte 0 within file /usr/local/var/postgres/base/16384/25242
Current byte= 0 / $00
$ hexdump /usr/local/var/postgres/base/16384/25242 | head
0000000 00 00 00 00 00 00 00 00 00 00 04 00 0c 01 80 01
...
$ ./pg_corrupt pgbench_accounts 14 1
/usr/local/var/postgres base/16384/25242 8192 13434880 1640
Reading byte 14 within file /usr/local/var/postgres/base/16384/25242
Current byte= 128 / $80
Modified byte= 129 / $81
File modified successfully
$ hexdump /usr/local/var/postgres/base/16384/25242 | head
0000000 00 00 00 00 00 00 00 00 00 00 04 00 0c 01 81 01
That doesn't impact selecting all of the rows:
$ psql -c "select count(*) from pgbench_accounts"
count
--------
100000
And pg_dump works fine against the table too. Tweaking this byte looks
like a reasonable first test case for seeing if checksums can catch an
error that query execution doesn't.
Next I'm going to test the functional part of the latest checksum patch;
duplicate Jeff's targeted performance tests; and then run some of my
own. I wanted to get this little tool circulating now that it's useful
first.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
| pg_corrupt | text/plain | 4.3 KB |
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-17 01:38:38 |
| Message-ID: | 1358386718.1953.6.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
New version of checksums patch.
Changes:
* rebased
* removed two duplicate lines; apparently the result of a bad merge
* Added heap page to WAL chain when logging an XLOG_HEAP2_VISIBLE to
avoid torn page issues updating PD_ALL_VISIBLE. This is the most
significant change.
* minor comment cleanup
No open issues that I'm aware of with the patch itself.
Greg appears to have made some progress on the automated corruption
tester.
Note to reviewers: I also have a patch out to remove PD_ALL_VISIBLE
entirely. The code around PD_ALL_VISIBLE is quite tricky (with or
without this patch), so if the PD_ALL_VISIBLE patch is committed first
then it will make reviewing this patch easier. Regardless, the second
patch to be committed will need to be rebased on top of the first.
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| replace-tli-with-checksums-20130116.patch.gz | application/x-gzip | 8.8 KB |
| checksums-20130116.patch.gz | application/x-gzip | 18.2 KB |
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-17 03:04:59 |
| Message-ID: | 1358391899.1953.9.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2013-01-15 at 19:36 -0500, Greg Smith wrote:
> First rev of a simple corruption program is attached, in very C-ish
> Python.
Great. Did you verify that my patch works as you expect at least in the
simple case?
> The parameters I settled on are to accept a relation name, byte
> offset, byte value, and what sort of operation to do: overwrite, AND,
> OR, XOR. I like XOR here because you can fix it just by running the
> program again.
Oh, good idea.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-24 21:03:41 |
| Message-ID: | 1359061421.601.39.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-01-16 at 17:38 -0800, Jeff Davis wrote:
> New version of checksums patch.
And another new version of both patches.
Changes:
* Rebased.
* Rename SetBufferCommitInfoNeedsSave to MarkBufferDirtyHint. Now that
it's being used more places, it makes sense to give it a more generic
name.
* My colleague, Yingjie He, noticed that the FSM doesn't write any WAL,
and therefore we must protect those operations against torn pages. That
seems simple enough: just use MarkBufferDirtyHint (formerly
SetBufferCommitInfoNeedsSave) instead of MarkBufferDirty. The FSM
changes are not critical, so the fact that we may lose the dirty bit is
OK.
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| replace-tli-with-checksums-20130124.patch.gz | application/x-gzip | 8.8 KB |
| checksums-20130124.patch.gz | application/x-gzip | 20.0 KB |
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-25 20:29:58 |
| Message-ID: | CA+TgmoanW2AKXugNFg7HWYSZ2aYBDXuTTxk2K4kZGhonLYKOWA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Jan 10, 2013 at 1:06 AM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Tue, 2012-12-04 at 01:03 -0800, Jeff Davis wrote:
>> For now, I rebased the patches against master, and did some very minor
>> cleanup.
>
> I think there is a problem here when setting PD_ALL_VISIBLE. I thought I
> had analyzed that before, but upon review, it doesn't look right.
> Setting PD_ALL_VISIBLE needs to be associated with a WAL action somehow,
> and a bumping of the LSN, otherwise there is a torn page hazard.
>
> The solution doesn't seem particularly difficult, but there are a few
> strange aspects and I'm not sure exactly which path I should take.
>
> First of all, the relationship between MarkBufferDirty and
> SetBufferCommitInfoNeedsSave is a little confusing. The comment over
> MarkBufferDirty is confusing because it says that the caller must have
> an exclusive lock, or else bad data could be written. But that doesn't
> have to do with marking the buffer dirty, that has to do with the data
> page change you make while you are marking it dirty -- if it's a single
> bit change, then there is no risk that I can see.
>
> In the current code, the only real code difference between the two is
> that SetBufferCommitInfoNeedsSave might fail to mark the buffer dirty if
> there is a race. So, in the current code, we could actually combine the
> two by passing a "force" flag (if true, behaves like MarkBufferDirty, if
> false, behaves like SetBufferCommitInfoNeedsSave).
>
> The checksums patch also introduces another behavior into
> SetBufferCommitInfoNeedsSave, which is to write an XLOG_HINT WAL record
> if checksums are enabled (to avoid torn page hazards). That's only
> necessary for changes where the caller does not write WAL itself and
> doesn't bump the LSN of the data page. (There's a reason the caller
> can't easily write the XLOG_HINT WAL itself.) So, we could introduce
> another flag "needsWAL" that would control whether we write the
> XLOG_HINT WAL or not (only applies with checksums on, of course).
I thought Simon had the idea, at some stage, of writing a WAL record
to cover hint-bit changes only at the time we *write* the buffer and
only if no FPI had already been emitted that checkpoint cycle. I'm
not sure whether that approach was sound, but if so it seems more
efficient than this approach.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-26 02:35:30 |
| Message-ID: | 1359167730.28476.21.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-01-25 at 15:29 -0500, Robert Haas wrote:
> I thought Simon had the idea, at some stage, of writing a WAL record
> to cover hint-bit changes only at the time we *write* the buffer and
> only if no FPI had already been emitted that checkpoint cycle. I'm
> not sure whether that approach was sound, but if so it seems more
> efficient than this approach.
My patch is based on his original idea; although I've made quite a lot
of changes, I believe that I have stuck to his same basic design w.r.t.
WAL.
This patch does not cause a new FPI to be emitted if one has already
been emitted this cycle. It also does not emit a WAL record at all if an
FPI has already been emitted.
If we were to try to defer writing the WAL until the page was being
written, the most it would possibly save is the small XLOG_HINT WAL
record; it would not save any FPIs.
At first glance, it seems sound as long as the WAL FPI makes it to disk
before the data. But to meet that requirement, it seems like we'd need
to write an FPI and then immediately flush WAL before cleaning a page,
and that doesn't seem like a win. Do you (or Simon) see an opportunity
here that I'm missing?
By the way, the approach I took was to add the heap buffer to the WAL
chain of the XLOG_HEAP2_VISIBLE wal record when doing log_heap_visible.
It seemed simpler to understand than trying to add a bunch of options to
MarkBufferDirty.
Regards,
Jeff Davis
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-27 04:23:02 |
| Message-ID: | CA+TgmoaBj9t3_mCDuc21m+b3i+yM+vekmaSDSM8vr8jOyuq2QQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Jan 25, 2013 at 9:35 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Fri, 2013-01-25 at 15:29 -0500, Robert Haas wrote:
>> I thought Simon had the idea, at some stage, of writing a WAL record
>> to cover hint-bit changes only at the time we *write* the buffer and
>> only if no FPI had already been emitted that checkpoint cycle. I'm
>> not sure whether that approach was sound, but if so it seems more
>> efficient than this approach.
>
> My patch is based on his original idea; although I've made quite a lot
> of changes, I believe that I have stuck to his same basic design w.r.t.
> WAL.
>
> This patch does not cause a new FPI to be emitted if one has already
> been emitted this cycle. It also does not emit a WAL record at all if an
> FPI has already been emitted.
>
> If we were to try to defer writing the WAL until the page was being
> written, the most it would possibly save is the small XLOG_HINT WAL
> record; it would not save any FPIs.
How is the XLOG_HINT_WAL record kept small and why does it not itself
require an FPI?
> At first glance, it seems sound as long as the WAL FPI makes it to disk
> before the data. But to meet that requirement, it seems like we'd need
> to write an FPI and then immediately flush WAL before cleaning a page,
> and that doesn't seem like a win. Do you (or Simon) see an opportunity
> here that I'm missing?
I am not sure that isn't a win. After all, we can need to flush WAL
before flushing a buffer anyway, so this is just adding another case -
and the payoff is that the initial access to a page, setting hint
bits, is quickly followed by a write operation, we avoid the need for
any extra WAL to cover the hint bit change. I bet that's common,
because if updating you'll usually need to look at the tuples on the
page and decide whether they are visible to your scan before, say,
updating one of them
> By the way, the approach I took was to add the heap buffer to the WAL
> chain of the XLOG_HEAP2_VISIBLE wal record when doing log_heap_visible.
> It seemed simpler to understand than trying to add a bunch of options to
> MarkBufferDirty.
Unless I am mistaken, that's going to heavy penalize the case where
the user vacuums an insert-only table. It will emit much more WAL
than currently.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-27 08:50:51 |
| Message-ID: | CA+U5nMLbJxUrKKD-Szy10DVZOmdKydD_He84O0BxRR5vsa48jQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 25 January 2013 20:29, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>> The checksums patch also introduces another behavior into
>> SetBufferCommitInfoNeedsSave, which is to write an XLOG_HINT WAL record
>> if checksums are enabled (to avoid torn page hazards). That's only
>> necessary for changes where the caller does not write WAL itself and
>> doesn't bump the LSN of the data page. (There's a reason the caller
>> can't easily write the XLOG_HINT WAL itself.) So, we could introduce
>> another flag "needsWAL" that would control whether we write the
>> XLOG_HINT WAL or not (only applies with checksums on, of course).
>
> I thought Simon had the idea, at some stage, of writing a WAL record
> to cover hint-bit changes only at the time we *write* the buffer and
> only if no FPI had already been emitted that checkpoint cycle. I'm
> not sure whether that approach was sound, but if so it seems more
> efficient than this approach.
The requirement is that we ensure that a FPI is written to WAL before
any changes to the block are made.
The patch does that by inserting an XLOG_HINT_WAL record when we set a
hint. The insert is a no-op if we've already written the FPI in this
checkpoint cycle and we don't even reach there except when dirtying a
clean data block.
If we attempted to defer the FPI last thing before write, we'd need to
cope with the case that writes at checkpoint occur after the logical
start of the checkpoint, and also with the overhead of additional
writes at checkpoint time.
I don't see any advantage in deferring the FPI, but I do see
disadvantage in complicating this.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-27 17:04:34 |
| Message-ID: | CA+TgmoYvtsJq=JvacxJcAMzWJ2wY=qg+5OG=DnFQoH_TOx_YJQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Jan 27, 2013 at 3:50 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> If we attempted to defer the FPI last thing before write, we'd need to
> cope with the case that writes at checkpoint occur after the logical
> start of the checkpoint, and also with the overhead of additional
> writes at checkpoint time.
Oh, good point. That's surely a good reason not to do it that way.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-27 22:28:50 |
| Message-ID: | 1359325730.7413.33.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, 2013-01-26 at 23:23 -0500, Robert Haas wrote:
> > If we were to try to defer writing the WAL until the page was being
> > written, the most it would possibly save is the small XLOG_HINT WAL
> > record; it would not save any FPIs.
>
> How is the XLOG_HINT_WAL record kept small and why does it not itself
> require an FPI?
There's a maximum of one FPI per page per cycle, and we need the FPI for
any modified page in this design regardless.
So, deferring the XLOG_HINT WAL record doesn't change the total number
of FPIs emitted. The only savings would be on the trivial XLOG_HINT wal
record itself, because we might notice that it's not necessary in the
case where some other WAL action happened to the page.
> > At first glance, it seems sound as long as the WAL FPI makes it to disk
> > before the data. But to meet that requirement, it seems like we'd need
> > to write an FPI and then immediately flush WAL before cleaning a page,
> > and that doesn't seem like a win. Do you (or Simon) see an opportunity
> > here that I'm missing?
>
> I am not sure that isn't a win. After all, we can need to flush WAL
> before flushing a buffer anyway, so this is just adding another case -
Right, but if we get the WAL record in earlier, there is a greater
chance that it goes out with some unrelated WAL flush, and we don't need
to flush the WAL to clean the buffer at all. Separating WAL insertions
from WAL flushes seems like a fairly important goal, so I'm a little
skeptical of a proposal to narrow that gap so drastically.
It's hard to analyze without a specific proposal on the table. But if
cleaning pages requires a WAL record followed immediately by a flush, it
seems like that would increase the number of actual WAL flushes we need
to do by a lot.
> and the payoff is that the initial access to a page, setting hint
> bits, is quickly followed by a write operation, we avoid the need for
> any extra WAL to cover the hint bit change. I bet that's common,
> because if updating you'll usually need to look at the tuples on the
> page and decide whether they are visible to your scan before, say,
> updating one of them
That's a good point, I'm just not sure how avoid that problem without a
lot of complexity or a big cost. It seems like we want to defer the
XLOG_HINT WAL record for a short time; but not wait so long that we need
to clean the buffer or miss a chance to piggyback on another WAL flush.
> > By the way, the approach I took was to add the heap buffer to the WAL
> > chain of the XLOG_HEAP2_VISIBLE wal record when doing log_heap_visible.
> > It seemed simpler to understand than trying to add a bunch of options to
> > MarkBufferDirty.
>
> Unless I am mistaken, that's going to heavy penalize the case where
> the user vacuums an insert-only table. It will emit much more WAL
> than currently.
Yes, that's true, but I think that's pretty fundamental to this
checksums design (and of course it only applies if checksums are
enabled). We need to make sure an FPI is written and the LSN bumped
before we write a page.
That's why I was pushing a little on various proposals to either remove
or mitigate the impact of hint bits (load path, remove PD_ALL_VISIBLE,
cut down on the less-important hint bits, etc.). Maybe those aren't
viable, but that's why I spent time on them.
There are some other options, but I cringe a little bit thinking about
them. One is to simply exclude the PD_ALL_VISIBLE bit from the checksum
calculation, so that a torn page doesn't cause a problem (though
obviously that one bit would be vulnerable to corruption). Another is to
use a double-write buffer, but that didn't seem to go very far. Or, we
could abandon the whole thing and tell people to use ZFS/btrfs/NAS/SAN.
Regards,
Jeff Davis
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-01-29 02:34:41 |
| Message-ID: | CA+TgmoZL5+-s8NJLYvuZE7_qcVc=FzpM8y5S5L1UdKZukwc=4A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Jan 27, 2013 at 5:28 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> There's a maximum of one FPI per page per cycle, and we need the FPI for
> any modified page in this design regardless.
>
> So, deferring the XLOG_HINT WAL record doesn't change the total number
> of FPIs emitted. The only savings would be on the trivial XLOG_HINT wal
> record itself, because we might notice that it's not necessary in the
> case where some other WAL action happened to the page.
OK, I see. So the case where this really hurts is where a page is
updated for hint bits only and then not touched again for the
remainder of the checkpoint cycle.
>> > At first glance, it seems sound as long as the WAL FPI makes it to disk
>> > before the data. But to meet that requirement, it seems like we'd need
>> > to write an FPI and then immediately flush WAL before cleaning a page,
>> > and that doesn't seem like a win. Do you (or Simon) see an opportunity
>> > here that I'm missing?
>>
>> I am not sure that isn't a win. After all, we can need to flush WAL
>> before flushing a buffer anyway, so this is just adding another case -
>
> Right, but if we get the WAL record in earlier, there is a greater
> chance that it goes out with some unrelated WAL flush, and we don't need
> to flush the WAL to clean the buffer at all. Separating WAL insertions
> from WAL flushes seems like a fairly important goal, so I'm a little
> skeptical of a proposal to narrow that gap so drastically.
>
> It's hard to analyze without a specific proposal on the table. But if
> cleaning pages requires a WAL record followed immediately by a flush, it
> seems like that would increase the number of actual WAL flushes we need
> to do by a lot.
Yeah, maybe. I think Simon had a good argument for not pursuing this
route, anyway.
>> and the payoff is that the initial access to a page, setting hint
>> bits, is quickly followed by a write operation, we avoid the need for
>> any extra WAL to cover the hint bit change. I bet that's common,
>> because if updating you'll usually need to look at the tuples on the
>> page and decide whether they are visible to your scan before, say,
>> updating one of them
>
> That's a good point, I'm just not sure how avoid that problem without a
> lot of complexity or a big cost. It seems like we want to defer the
> XLOG_HINT WAL record for a short time; but not wait so long that we need
> to clean the buffer or miss a chance to piggyback on another WAL flush.
>
>> > By the way, the approach I took was to add the heap buffer to the WAL
>> > chain of the XLOG_HEAP2_VISIBLE wal record when doing log_heap_visible.
>> > It seemed simpler to understand than trying to add a bunch of options to
>> > MarkBufferDirty.
>>
>> Unless I am mistaken, that's going to heavy penalize the case where
>> the user vacuums an insert-only table. It will emit much more WAL
>> than currently.
>
> Yes, that's true, but I think that's pretty fundamental to this
> checksums design (and of course it only applies if checksums are
> enabled). We need to make sure an FPI is written and the LSN bumped
> before we write a page.
>
> That's why I was pushing a little on various proposals to either remove
> or mitigate the impact of hint bits (load path, remove PD_ALL_VISIBLE,
> cut down on the less-important hint bits, etc.). Maybe those aren't
> viable, but that's why I spent time on them.
>
> There are some other options, but I cringe a little bit thinking about
> them. One is to simply exclude the PD_ALL_VISIBLE bit from the checksum
> calculation, so that a torn page doesn't cause a problem (though
> obviously that one bit would be vulnerable to corruption). Another is to
> use a double-write buffer, but that didn't seem to go very far. Or, we
> could abandon the whole thing and tell people to use ZFS/btrfs/NAS/SAN.
I am inclined to think that we shouldn't do any of this stuff for now.
I think it's OK if the first version of checksums is
not-that-flexible and/or not-that-performant. We can optimize for
those things later. Trying to monkey with this at the same time we're
trying to get checksums in risks introducing new diverting focus from
getting checksums done at all, and risks also introducing new data
corruption bugs. We have a reputation of long standing for getting it
right first and then getting it to perform well later, so it shouldn't
a be a total shock if we take that approach here, too. I see no
reason to think that the performance problems must be solved up front
or not at all.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-02-25 06:30:12 |
| Message-ID: | 512B04F4.3000201@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Attached is some bit rot updates to the checksums patches. The
replace-tli one still works fine. I fixed a number of conflicts in the
larger patch. The one I've attached here isn't 100% to project
standards--I don't have all the context diff tools setup yet for
example. I expect to revise this more now that I've got the whole week
cleared to work on CF submissions.
Here's the bit rot fixes:
src/backend/commands/vacuumlazy.c: Changed a call to look like this:
1157 visibilitymap_set(onerel, blkno, buffer,
InvalidXLogRecPtr, *vmbuffer,
1158 visibility_cutoff_xid);
To match calling order and make complier warnings go away.
src/backend/storage/buffer/bufmgr.c : merged against some changes
related to unlogged table buffer management. Merge seems clean once
done by hand.
src/include/catalog/pg_control.h: The patch used this value for XLOG_HINT:
#define XLOG_HINT 0x90
That's now been used for XLOG_END_OF_RECOVERY so I made it 0xA0 instead:
#define XLOG_HINT 0xA0
Unrelated to merge issues, I saw this in the patch:
localbuf.c: XXX do we want to write checksums for local buffers? An option?
And wanted to highlight this concern is still floating around.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
| checksums-20130224.patch | text/plain | 63.5 KB |
| replace-tli-with-checksums-20130124.patch | text/plain | 47.1 KB |
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-01 16:48:31 |
| Message-ID: | CAAZKuFZzA+aw8ZL4F_5C8T8ZHRtJo3cM1aJQddGLQCpEz_3-kQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Feb 24, 2013 at 10:30 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> Attached is some bit rot updates to the checksums patches. The replace-tli
> one still works fine....
I rather badly want this feature, and if the open issues with the
patch has hit zero, I'm thinking about applying it, shipping it, and
turning it on. Given that the heap format has not changed, the main
affordence I may check for is if I can work in backwards compatibility
(while not maintaining the checksums, of course) in case of an
emergency.
--
fdr
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-03 14:22:16 |
| Message-ID: | 51335C98.9050104@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/02/2013 12:48 AM, Daniel Farina wrote:
> On Sun, Feb 24, 2013 at 10:30 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
>> Attached is some bit rot updates to the checksums patches. The replace-tli
>> one still works fine....
> I rather badly want this feature, and if the open issues with the
> patch has hit zero, I'm thinking about applying it, shipping it, and
> turning it on. Given that the heap format has not changed, the main
> affordence I may check for is if I can work in backwards compatibility
> (while not maintaining the checksums, of course) in case of an
> emergency.
Did you get a chance to see whether you can run it in
checksum-validation-and-update-off backward compatible mode? This seems
like an important thing to have working (and tested for) in case of
bugs, performance issues or other unforseen circumstances.
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-03 18:24:32 |
| Message-ID: | 51339560.8030701@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
The 16-bit checksum feature seems functional, with two sources of
overhead. There's some CPU time burned to compute checksums when pages
enter the system. And there's extra overhead for WAL logging hint bits.
I'll quantify both of those better in another message.
For completeness sake I've attached the latest versions of the patches I
tested (same set as my last message) along with the testing programs and
source changes that have been useful for my review. I have a test case
now demonstrating a tricky issue my gut told me was possible in page
header handling, and that's what I talk about most here.
= Handling bit errors in page headers =
The thing I've been stuck on is trying to find a case where turning
checksums on results in data that could be read becoming completely
unavailable, after a single bit of corruption. That seemed to me the
biggest risk of this feature. If checksumming can result in lost data,
where before that data would be available just with some potential for
error in it, that's kind of bad. I've created a program that does just
that, with a repeatable shell script test case (check-check.sh)
This builds on the example I gave before, where I can corrupt a single
bit of data in pgbench_accounts (lowest bit in byte 14 in the page) and
then reads that page without problems:
$ psql -c "select sum(abalance) from pgbench_accounts"
sum
-----
0
Corrupting the same bit on a checksums enabled build catches the problem:
WARNING: page verification failed, calculated checksum 5900 but
expected 9227
ERROR: invalid page header in block 0 of relation base/16384/16397
This is good, because it's exactly the sort of quiet corruption that the
feature is supposed to find. But clearly it's *possible* to still read
all of the data in this page, because the build without checksums does
just that. All of these fail now:
$ psql -c "select sum(abalance) from pgbench_accounts"
WARNING: page verification failed, calculated checksum 5900 but
expected 9227
ERROR: invalid page header in block 0 of relation base/16384/16397
$ psql -c "select * from pgbench_accounts"
WARNING: page verification failed, calculated checksum 5900 but
expected 9227
ERROR: invalid page header in block 0 of relation base/16384/16397
And you get this sort of mess out of pg_dump:
COPY pgbench_accounts (aid, bid, abalance, filler) FROM stdin;
pg_dump: WARNING: page verification failed, calculated checksum 5900
but expected 9227
\.
pg_dump: Dumping the contents of table "pgbench_accounts" failed:
PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page header in block
0 of relation base/16384/16397
pg_dump: The command was: COPY public.pgbench_accounts (aid, bid,
abalance, filler) TO stdout;
I think an implicit goal of this feature was to soldier on when possible
to do so. The case where something in the page header is corrupted
seems the weakest part of that idea. I would still be happy to enable
this feature on a lot of servers, because stopping in the case of subtle
header corruption just means going to another known good copy of the
data; probably a standby server.
I could see some people getting surprised by this change though. I'm
not sure if it's possible to consider a checksum failure in a page
header something that is WARNed about, rather than always treating it as
a failure and the data is unavailable (without page inspection tools at
least). That seems like the main thing that might be improved in this
feature right now.
= Testing issues =
It is surprisingly hard to get a repeatable test program that corrupts a
bit on a data page. If you already have a copy of the page in memory
and you corrupt the copy on disk, the corrupted copy won't be noticed.
And if you happen to trigger a write of that page, the corruption will
quietly be fixed. This is all good, but it's something to be aware of
when writing test code.
The other thing to watch out for is that you're not hitting an
Index-Only Scan anywhere, because then you're bypassing the database
page you corrupted.
What I've done is come up with a repeatable test case that shows the
checksum patch finding a single bit of corruption that is missed by a
regular server. The program is named check-check.sh, and a full output
run is attached as check-check.log
I also added a developer only debugging test patch as
show_block_verifications.patch This makes every block read spew a
message about what relation it's touching, and proves the checksum
mechanism is being hit each time. The main reason I needed that is to
make sure the pages I expected to be read were actually the ones being
read. When I accidentally was hitting index-only scans for example, I
could tell that because it was touching something from
pgbench_accounts_pkey instead the pgbench_account table data I was
corrupting.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
| check-check.log | text/plain | 9.1 KB |
| check-check.sh | application/x-sh | 1.5 KB |
| checksums-20130124.patch | text/plain | 72.0 KB |
| checksums-20130224.patch | text/plain | 63.5 KB |
| pg_corrupt | text/plain | 4.3 KB |
| replace-tli-with-checksums-20130124.patch | text/plain | 47.1 KB |
| show_block_verifications.patch | text/plain | 1.1 KB |
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-03 21:06:30 |
| Message-ID: | 5133BB56.9070603@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
And here's an updated version of the checksum corruption testing wrapper
script already. This includes an additional safety check that you've
set PGDATA to a location that can be erased. Presumably no one else
would like to accidentally do this:
rm -rf /*
Like I just did.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
| check-check.sh | application/x-sh | 1.6 KB |
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-03 23:05:22 |
| Message-ID: | 5133D732.4090801@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/19/12 6:30 PM, Jeff Davis wrote:
> I ran a few tests.
> Test 1 - find worst-case overhead for the checksum calculation on write:
> Test 2 - worst-case overhead for calculating checksum while reading data
> Test 3 - worst-case WAL overhead
What I've done is wrap all of these tests into a shell script that runs
them 3 times each, with and without checksums. That includes steps like
the spots where Jeff found a "sync" helped improve repeatability. I ran
these manually before and didn't notice enough of a difference to argue
with any of his results at the time. Having them packaged up usefully
means I can try some additional platforms too, and other testers should
be easily able to take a crack at it.
On the last one, in addition to runtime I directly measure how many
bytes of WAL are written. It's 0 in the usual case, where the hint bit
changes triggered by the first "SELECT * FROM foo" don't generate any WAL.
Detailed results with both my and Jeff's numbers are in the attached
spreadsheet. I did my tests on a Mac writing to SSD, to try and get
some variety in the test platforms. The main difference there is that
Test 1 is much slower on my system, enough so that the slowdown isn't as
pronounced.
Remember, these are a set of tests designed to magnify the worst case
here. I don't feel any of these results make the feature uncommittable.
The numbers I'm getting are not significantly different from the ones
Jeff posted back in December, and those were acceptable to some of the
early adopter candidates I've been surveying informally. These numbers
are amplifying overhead without doing much in the way of real disk I/O,
which can easily be a lot more expensive than any of this. I do think
there needs to be a bit more documentation of the potential downsides to
checksumming written though, since they are pretty hefty in some situations.
I'm going to get some pgbench results next, to try and put this into a
more realistic context too. The numbers for this round break down like
this:
= Test 1 - find worst-case overhead for the checksum calculation on write =
This can hit 25% of runtime when you isolate it out. I'm not sure if
how I'm running this multiple times makes sense yet. This one is so
much slower on my Mac that I can't barely see a change at all.
= Test 2 - worst-case overhead for calculating checksum while reading data =
Jeff saw an 18% slowdown, I get 24 to 32%. This one bothers me because
the hit is going to happen during the very common situation where data
is shuffling a lot between a larger OS cache and shared_buffers taking a
relatively small fraction. If that issue were cracked, such that
shared_buffers could be >50% of RAM, I think the typical real-world
impact of this would be easier to take.
= Test 3 - worst-case WAL overhead =
This is the really nasty one. The 10,000,000 rows touched by the SELECT
statement here create no WAL in a non-checksum environment. When
checksums are on, 368,513,656 bytes of WAL are written, so about 37
bytes per row.
Jeff saw this increase runtime by 135%, going from 1000ms to 2350ms. My
multiple runs are jumping around in a way I also don't trust fully yet.
But the first and best of the ones I'm seeing goes from 1660ms to
4013ms, which is a 140% increase. The others are even worse. I suspect
I'm filling a cache that isn't cleared before the second and third run
are over. I'll know for sure when I switch back to Linux.
The really nasty case I can see making people really cranky is where
someone has fsync on, a slowly rotating drive, and then discovers this
slowing read statements. There's already a decent share of "why is it
writing when I do 'SELECT *'?" complaints around the block I/O, which is
fully asynchronous in a lot of cases.
Right now the whole hint bit mechanism and its overhead are treated as
an internal detail that isn't in the regular documentation. I think
committing this sort of checksum patch will require exposing some of the
implementation to the user in the documentation, so people can
understand what the trouble cases are--either in advance or when trying
to puzzle out why they're hitting one of them.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
| ChecksumPerfResults.xls | application/vnd.ms-excel | 9.0 KB |
| perf-checksum.conf | text/plain | 399 bytes |
| perf-checksum.sh | application/x-sh | 4.0 KB |
| wal-functions.sql | text/plain | 1.7 KB |
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 03:18:38 |
| Message-ID: | 5134128E.6080207@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/3/13 9:22 AM, Craig Ringer wrote:
> Did you get a chance to see whether you can run it in
> checksum-validation-and-update-off backward compatible mode? This seems
> like an important thing to have working (and tested for) in case of
> bugs, performance issues or other unforseen circumstances.
There isn't any way to do this in the current code. The big
simplification Jeff introduced here, to narrow complexity toward a
commit candidate, was to make checksumming a cluster-level decision.
You get it for everything or not at all.
The problem I posted about earlier today, where a header checksum error
can block access to the entire relation, could be resolved with some
sort of "ignore read checksums" GUC. But that's impractical right now
for the write side of things. There have been a long list of metadata
proposals to handle situations where part of a cluster is checksummed,
but not all of it. Once that sort of feature is implemented, it becomes
a lot easier to talk about selectively disabling writes.
As for a design of a GUC that might be useful here, the option itself
strikes me as being like archive_mode in its general use. There is an
element of parameters like wal_sync_method or enable_cassert though,
where the options available vary depending on how you built the cluster.
Maybe name it checksum_level with options like this:
off: only valid option if you didn't enable checksums with initdb
enforcing: full checksum behavior as written right now.
unvalidated: broken checksums on reads are ignored.
The main tricky case I see in that is where you read in a page with a
busted checksum using "unvalidated". Ideally you wouldn't write such a
page back out again, because it's going to hide that it's corrupted in
some way already. How to enforce that though? Perhaps "unvalidated"
only be allowed in a read-only transaction?
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 03:52:35 |
| Message-ID: | 51341A83.6030709@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/04/2013 11:18 AM, Greg Smith wrote:
> On 3/3/13 9:22 AM, Craig Ringer wrote:
>> Did you get a chance to see whether you can run it in
>> checksum-validation-and-update-off backward compatible mode? This seems
>> like an important thing to have working (and tested for) in case of
>> bugs, performance issues or other unforseen circumstances.
>
> There isn't any way to do this in the current code. The big
> simplification Jeff introduced here, to narrow complexity toward a
> commit candidate, was to make checksumming a cluster-level decision.
> You get it for everything or not at all.
>
> The problem I posted about earlier today, where a header checksum
> error can block access to the entire relation, could be resolved with
> some sort of "ignore read checksums" GUC. But that's impractical
> right now for the write side of things. There have been a long list
> of metadata proposals to handle situations where part of a cluster is
> checksummed, but not all of it. Once that sort of feature is
> implemented, it becomes a lot easier to talk about selectively
> disabling writes.
>
> As for a design of a GUC that might be useful here, the option itself
> strikes me as being like archive_mode in its general use. There is an
> element of parameters like wal_sync_method or enable_cassert though,
> where the options available vary depending on how you built the
> cluster. Maybe name it checksum_level with options like this:
>
> off: only valid option if you didn't enable checksums with initdb
> enforcing: full checksum behavior as written right now.
> unvalidated: broken checksums on reads are ignored.
>
> The main tricky case I see in that is where you read in a page with a
> busted checksum using "unvalidated". Ideally you wouldn't write such
> a page back out again, because it's going to hide that it's corrupted
> in some way already. How to enforce that though? Perhaps
> "unvalidated" only be allowed in a read-only transaction?
That sounds like a really good step for disaster recovery, yes.
I also suspect that at least in the first release it might be desirable
to have an option that essentially says "something's gone horribly wrong
and we no longer want to check or write checksums, we want a
non-checksummed DB that can still read our data from before we turned
checksumming off". Essentially, a way for someone who's trying
checksumming in production after their staging tests worked out OK to
abort and go back to the non-checksummed case without having to do a
full dump and reload.
Given that, I suspect we need a 4th state, like "disabled" or
"unvalidating_writable" where we ignore checksums completely and
maintain the checksum-enabled layout but just write padding to the
checksum fields and don't bother to check them on reading.
My key concern boils down to being able to get someone up and running
quickly and with minimal disruption if something we didn't think of goes
wrong. "Oh, you have to dump and reload your 1TB database before you can
start writing to it again" isn't going to cut it.
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 04:19:44 |
| Message-ID: | 513420E0.2060005@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/3/13 10:52 PM, Craig Ringer wrote:
> I also suspect that at least in the first release it might be desirable
> to have an option that essentially says "something's gone horribly wrong
> and we no longer want to check or write checksums, we want a
> non-checksummed DB that can still read our data from before we turned
> checksumming off".
I see that as being something that involves disabling the cluster-wide
flag that turns checksumming on, the one that is reported by
pg_controldata. I think it would have to be a one-way, system down kind
of change, which I think is fair given the ugly (but feasible) situation
you're describing. It would need to be something stronger than a GUC.
Once you start writing out pages without checksums, you're back into the
fuzzy state where some pages have them, others don't, and there's no
good way to deal with that yet.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 04:23:13 |
| Message-ID: | 513421B1.80008@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/04/2013 12:19 PM, Greg Smith wrote:
> On 3/3/13 10:52 PM, Craig Ringer wrote:
>> I also suspect that at least in the first release it might be desirable
>> to have an option that essentially says "something's gone horribly wrong
>> and we no longer want to check or write checksums, we want a
>> non-checksummed DB that can still read our data from before we turned
>> checksumming off".
>
> I see that as being something that involves disabling the cluster-wide
> flag that turns checksumming on, the one that is reported by
> pg_controldata. I think it would have to be a one-way, system down
> kind of change, which I think is fair given the ugly (but feasible)
> situation you're describing. It would need to be something stronger
> than a GUC. Once you start writing out pages without checksums, you're
> back into the fuzzy state where some pages have them, others don't,
> and there's no good way to deal with that yet.
Agreed, I was envisioning a one-way process where re-enabling checksums
would involve be a re-initdb and reload. A DB restart seems perfectly
reasonable, it's just a full dump and reload before they can get running
again that I feel must be avoided.
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 07:11:36 |
| Message-ID: | CA+U5nMKD2DGfyF2xvNN01eGgd9_SsM_k=4akPkv13gJ90Orm_w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3 March 2013 18:24, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> The 16-bit checksum feature seems functional, with two sources of overhead.
> There's some CPU time burned to compute checksums when pages enter the
> system. And there's extra overhead for WAL logging hint bits. I'll
> quantify both of those better in another message.
It's crunch time. Do you and Jeff believe this patch should be
committed to Postgres core?
Are there objectors?
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 08:36:49 |
| Message-ID: | 51345D21.6010104@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 09:11, Simon Riggs wrote:
> Are there objectors?
FWIW, I still think that checksumming belongs in the filesystem, not
PostgreSQL. If you go ahead with this anyway, at the very least I'd like
to see some sort of a comparison with e.g btrfs. How do performance,
error-detection rate, and behavior on error compare? Any other metrics
that are relevant here?
- Heikki
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 16:00:00 |
| Message-ID: | 1362412800.26602.32.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 10:36 +0200, Heikki Linnakangas wrote:
> On 04.03.2013 09:11, Simon Riggs wrote:
> > Are there objectors?
>
> FWIW, I still think that checksumming belongs in the filesystem, not
> PostgreSQL.
Doing checksums in the filesystem has some downsides. One is that you
need to use a copy-on-write filesystem like btrfs or zfs, which (by
design) will fragment the heap on random writes. If we're going to start
pushing people toward those systems, we will probably need to spend some
effort to mitigate this problem (aside: my patch to remove
PD_ALL_VISIBLE might get some new wind behind it).
There are also other issues, like what fraction of our users can freely
move to btrfs, and when. If it doesn't happen to be already there, you
need root to get it there, which has never been a requirement before.
I don't fundamentally disagree. We probably need to perform reasonably
well on btrfs in COW mode[1] regardless, because a lot of people will be
using it a few years from now. But there are a lot of unknowns here, and
I'm concerned about tying checksums to a series of things that will be
resolved a few years from now, if ever.
[1] Interestingly, you can turn off COW mode on btrfs, but you lose
checksums if you do.
> If you go ahead with this anyway, at the very least I'd like
> to see some sort of a comparison with e.g btrfs. How do performance,
> error-detection rate, and behavior on error compare? Any other metrics
> that are relevant here?
I suspect it will be hard to get an apples-to-apples comparison here
because of the heap fragmentation, which means that a sequential scan is
not so sequential. That may be acceptable for some workloads but not for
others, so it would get tricky to compare. And any performance numbers
from an experimental filesystem are somewhat suspect anyway.
Also, it's a little more challenging to test corruption on a filesystem,
because you need to find the location of the file you want to corrupt,
and corrupt it out from underneath the filesystem.
Greg may have more comments on this matter.
Regards,
Jeff Davis
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 18:58:46 |
| Message-ID: | 5134EEE6.3070903@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 2:11 AM, Simon Riggs wrote:
> It's crunch time. Do you and Jeff believe this patch should be
> committed to Postgres core?
I want to see a GUC to allow turning this off, to avoid the problem I
saw where a non-critical header corruption problem can cause an entire
page to be unreadable. A variation on that capable of turning this off
altogether, as Craig suggested, is a good idea too.
Those are both simple fixes, and I would be pleased to see this
committed at that point.
I'll write up a long discussion of filesystem trends and why I think
this is more relevant than ever if that's the main objection now. There
is no such thing as a stable release of btrfs, and no timetable for when
there will be one. I could do some benchmarks of that but I didn't
think they were very relevant. Who cares how fast something might run
when it may not work correctly? btrfs might as well be /dev/null to me
right now--sure it's fast, but maybe the data won't be there at all.
How long has it taken the Linux kernel to reach the point it handles
write barriers and fsync correctly? It does not give me a lot of
confidence that now is the time they'll suddenly start executing on
database filesystem mechanics perfectly.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 19:54:07 |
| Message-ID: | 1362426847.23497.3.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-02-25 at 01:30 -0500, Greg Smith wrote:
> Attached is some bit rot updates to the checksums patches. The
> replace-tli one still works fine. I fixed a number of conflicts in the
> larger patch. The one I've attached here isn't 100% to project
> standards--I don't have all the context diff tools setup yet for
> example. I expect to revise this more now that I've got the whole week
> cleared to work on CF submissions.
Thank you for the rebase. I redid the rebase myself and came up with
essentially the same result, but there was an additional problem that
needed fixing after the materialized view patch.
I will post a new version tonight that includes those fixes as well as
something to address these recent comments (probably just another GUC).
Further comment in another reply.
Regards,
Jeff Davis
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:13:13 |
| Message-ID: | 51350059.8050003@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 20:58, Greg Smith wrote:
> There
> is no such thing as a stable release of btrfs, and no timetable for when
> there will be one. I could do some benchmarks of that but I didn't think
> they were very relevant. Who cares how fast something might run when it
> may not work correctly? btrfs might as well be /dev/null to me right
> now--sure it's fast, but maybe the data won't be there at all.
This PostgreSQL patch hasn't seen any production use, either. In fact,
I'd consider btrfs to be more mature than this patch. Unless you think
that there will be some major changes to the worse in performance in
btrfs, it's perfectly valid and useful to compare the two.
A comparison with ZFS would be nice too. That's mature, and has checksums.
- Heikki
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Daniel Farina <daniel(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:22:24 |
| Message-ID: | 1362428544.23497.43.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 11:52 +0800, Craig Ringer wrote:
> I also suspect that at least in the first release it might be desirable
> to have an option that essentially says "something's gone horribly wrong
> and we no longer want to check or write checksums, we want a
> non-checksummed DB that can still read our data from before we turned
> checksumming off". Essentially, a way for someone who's trying
> checksumming in production after their staging tests worked out OK to
> abort and go back to the non-checksummed case without having to do a
> full dump and reload.
A recovery option to extract data sounds like a good idea, but I don't
want to go as far as you are suggesting here.
An option to ignore checksum failures (while still printing the
warnings) sounds like all we need here. I think Greg's point that the
page might be written out again (hiding the corruption) is a very good
one, but the same is true for zero_damaged_pages. So we can just still
allow the writes to proceed (including setting the checksum on write),
and the system should be as available as it would be without checksums.
Regards,
Jeff Davis
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:27:44 |
| Message-ID: | 513503C0.3030809@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 18:00, Jeff Davis wrote:
> On Mon, 2013-03-04 at 10:36 +0200, Heikki Linnakangas wrote:
>> On 04.03.2013 09:11, Simon Riggs wrote:
>>> Are there objectors?
>>
>> FWIW, I still think that checksumming belongs in the filesystem, not
>> PostgreSQL.
>
> Doing checksums in the filesystem has some downsides. One is that you
> need to use a copy-on-write filesystem like btrfs or zfs, which (by
> design) will fragment the heap on random writes.
Yeah, fragmentation will certainly hurt some workloads. But how badly,
and which workloads, and how does that compare with the work that
PostgreSQL has to do to maintain the checksums? I'd like to see some
data on those things.
> There are also other issues, like what fraction of our users can freely
> move to btrfs, and when. If it doesn't happen to be already there, you
> need root to get it there, which has never been a requirement before.
If you're serious enough about your data that you want checksums, you
should be able to choose your filesystem.
>> If you go ahead with this anyway, at the very least I'd like
>> to see some sort of a comparison with e.g btrfs. How do performance,
>> error-detection rate, and behavior on error compare? Any other metrics
>> that are relevant here?
>
> I suspect it will be hard to get an apples-to-apples comparison here
> because of the heap fragmentation, which means that a sequential scan is
> not so sequential. That may be acceptable for some workloads but not for
> others, so it would get tricky to compare.
An apples-to-apples comparison is to run the benchmark and see what
happens. If it gets fragmented as hell on btrfs, and performance tanks
because of that, then that's your result. If avoiding fragmentation is
critical to the workload, then with btrfs you'll want to run the
defragmenter in the background to keep it in order, and factor that into
the test case.
I realize that performance testing is laborious. But we can't skip it
and assume that the patch performs fine, because it's hard to benchmark.
- Heikki
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:40:00 |
| Message-ID: | 1362429600.23497.96.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 22:13 +0200, Heikki Linnakangas wrote:
> On 04.03.2013 20:58, Greg Smith wrote:
> > There
> > is no such thing as a stable release of btrfs, and no timetable for when
> > there will be one. I could do some benchmarks of that but I didn't think
> > they were very relevant. Who cares how fast something might run when it
> > may not work correctly? btrfs might as well be /dev/null to me right
> > now--sure it's fast, but maybe the data won't be there at all.
>
> This PostgreSQL patch hasn't seen any production use, either. In fact,
> I'd consider btrfs to be more mature than this patch. Unless you think
> that there will be some major changes to the worse in performance in
> btrfs, it's perfectly valid and useful to compare the two.
>
> A comparison with ZFS would be nice too. That's mature, and has checksums.
Is there any reason why we can't have both postgres and filesystem
checksums? The same user might not want both (or might, if neither are
entirely trustworthy yet), but I think it's too early to declare one as
the "right" solution and the other not. Even with btrfs stable, I
pointed out a number of reasons users might not want it, and reasons
that the project should not depend on it.
Numbers are always nice, but it takes a lot of effort to come up with
them. What kind of numbers are you looking for, and how *specifically*
will those numbers affect the decision?
If btrfs with checksums is 10% slower than ext4 with postgres checksums,
does that mean we should commit the postgres checksums?
On the other side of the coin, if btrfs with checksums is exactly the
same speed as ext4 with no postgres checksums (i.e. checksums are free
if we use btrfs), does that mean postgres checksums should be rejected?
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Craig Ringer <craig(at)2ndquadrant(dot)com>, Daniel Farina <daniel(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:48:31 |
| Message-ID: | 1362430111.23497.113.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 2013-03-03 at 22:18 -0500, Greg Smith wrote:
> As for a design of a GUC that might be useful here, the option itself
> strikes me as being like archive_mode in its general use. There is an
> element of parameters like wal_sync_method or enable_cassert though,
> where the options available vary depending on how you built the cluster.
> Maybe name it checksum_level with options like this:
>
> off: only valid option if you didn't enable checksums with initdb
> enforcing: full checksum behavior as written right now.
> unvalidated: broken checksums on reads are ignored.
I think GUCs should be orthogonal to initdb settings. If nothing else,
it's extra effort to get initdb to write the right postgresql.conf.
A single new GUC that prevents checksum failures from causing an error
seems sufficient to address the concerns you, Dan, and Craig raised.
We would still calculate the checksum and print the warning; and then
pass it through the rest of the header checks. If the header checks
pass, then it proceeds. If the header checks fail, and if
zero_damaged_pages is off, then it would still generate an error (as
today).
So: ignore_checksum_failures = on|off ?
> The main tricky case I see in that is where you read in a page with a
> busted checksum using "unvalidated". Ideally you wouldn't write such a
> page back out again, because it's going to hide that it's corrupted in
> some way already. How to enforce that though? Perhaps "unvalidated"
> only be allowed in a read-only transaction?
That's a good point. But we already have zero_damaged_pages, which does
something similar. And it's supposed to be a recovery option to get the
data out rather than something to run in online mode. It will still
print the warning, so it won't completely hide the corruption.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:48:58 |
| Message-ID: | 1362430138.23497.115.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 13:58 -0500, Greg Smith wrote:
> On 3/4/13 2:11 AM, Simon Riggs wrote:
> > It's crunch time. Do you and Jeff believe this patch should be
> > committed to Postgres core?
>
> I want to see a GUC to allow turning this off, to avoid the problem I
> saw where a non-critical header corruption problem can cause an entire
> page to be unreadable. A variation on that capable of turning this off
> altogether, as Craig suggested, is a good idea too.
Based on your comments as well those of Dan and Craig, I am leaning
toward a GUC that causes a checksum failure to be ignored. It will still
emit the checksum failure warning, but proceed.
That will then fall through to the normal header checks we've always
had, and the same zero_damaged_pages option. So, to get past a really
corrupt page, you'd need to set ignore_checksum_failure and
zero_damaged_pages.
> I'll write up a long discussion of filesystem trends and why I think
> this is more relevant than ever if that's the main objection now. There
> is no such thing as a stable release of btrfs, and no timetable for when
> there will be one. I could do some benchmarks of that but I didn't
> think they were very relevant. Who cares how fast something might run
> when it may not work correctly? btrfs might as well be /dev/null to me
> right now--sure it's fast, but maybe the data won't be there at all.
> How long has it taken the Linux kernel to reach the point it handles
> write barriers and fsync correctly? It does not give me a lot of
> confidence that now is the time they'll suddenly start executing on
> database filesystem mechanics perfectly.
I have a similar viewpoint here. It will take significant effort to come
up with anything, and I'm not sure how meaningful the numbers would be.
Even if btrfs is great, this feature is not mutually exclusive with
btrfs:
* users might not have easy access to run the filesystem
* they might not trust it
* they might get poor performance numbers
* postgres checksums might provide a good test of btrfs checksums, and
vice-versa, until both are stable
Additionally, I don't like the idea of depending so heavily on what
linux is doing. If there are performance problems that affect postgres,
will they fix them? Will they introduce new ones? Are there a zillion
tuneable options that a new user has to get right in order to run
postgres efficiently, and will poor settings mean a bunch of "postgres
is slow" blog posts?
Regards,
Jeff Davis
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:51:55 |
| Message-ID: | 5135096B.6060003@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 10:00 AM, Jeff Davis wrote:
> On Mon, 2013-03-04 at 10:36 +0200, Heikki Linnakangas wrote:
>> >On 04.03.2013 09:11, Simon Riggs wrote:
>>> > >Are there objectors?
>> >
>> >FWIW, I still think that checksumming belongs in the filesystem, not
>> >PostgreSQL.
> Doing checksums in the filesystem has some downsides.
Additionally, no filesystem I'm aware of checksums the data in the filesystem cache. A PG checksum would.
I'll also mention that this debate has been had in the past. The time to object to the concept of a checksuming feature was a long time ago, before a ton of development effort went into this... :(
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 20:57:32 |
| Message-ID: | 51350ABC.3000400@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 2:48 PM, Jeff Davis wrote:
> On Mon, 2013-03-04 at 13:58 -0500, Greg Smith wrote:
>> >On 3/4/13 2:11 AM, Simon Riggs wrote:
>>> > >It's crunch time. Do you and Jeff believe this patch should be
>>> > >committed to Postgres core?
>> >
>> >I want to see a GUC to allow turning this off, to avoid the problem I
>> >saw where a non-critical header corruption problem can cause an entire
>> >page to be unreadable. A variation on that capable of turning this off
>> >altogether, as Craig suggested, is a good idea too.
> Based on your comments as well those of Dan and Craig, I am leaning
> toward a GUC that causes a checksum failure to be ignored. It will still
> emit the checksum failure warning, but proceed.
I suggest we paint that GUC along the lines of "checksum_failure_log_level", defaulting to ERROR. That way if someone wanted completely bury the elogs to like DEBUG they could.
My $2.98 (inflation adjusted).
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:00:09 |
| Message-ID: | 1362430809.23497.127.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 22:27 +0200, Heikki Linnakangas wrote:
> Yeah, fragmentation will certainly hurt some workloads. But how badly,
> and which workloads, and how does that compare with the work that
> PostgreSQL has to do to maintain the checksums? I'd like to see some
> data on those things.
I think we all would. Btrfs will be a major filesystem in a few years,
and we should be ready to support it.
Unfortunately, it's easier said than done. What you're talking about
seems like a significant benchmark report that encompasses a lot of
workloads. And there's a concern that a lot of it will be invalidated if
they are still improving the performance of btrfs.
> If you're serious enough about your data that you want checksums, you
> should be able to choose your filesystem.
I simply disagree. I am targeting my feature at casual users. They may
not have a lot of data or a dedicated DBA, but the data they do have
might be very important transactional data.
And right now, if they take a backup of their data, it will contain all
of the corruption from the original. And since corruption is silent
today, then they would probably think the backup is fine, and may delete
the previous good backups.
> An apples-to-apples comparison is to run the benchmark and see what
> happens. If it gets fragmented as hell on btrfs, and performance tanks
> because of that, then that's your result. If avoiding fragmentation is
> critical to the workload, then with btrfs you'll want to run the
> defragmenter in the background to keep it in order, and factor that into
> the test case.
Again, easier said than done. To get real fragmentation problems, the
data set needs to be huge, and we need to reach a steady state of this
background defrag process, and a million other things.
> I realize that performance testing is laborious. But we can't skip it
> and assume that the patch performs fine, because it's hard to benchmark.
You aren't asking me to benchmark the patch in question. You are asking
me to benchmark a filesystem that very few people actually run postgres
on in production. I don't think that's a reasonable requirement.
Regards,
Jeff Davis
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jim Nasby <jim(at)nasby(dot)net> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:00:32 |
| Message-ID: | 51350B70.9040304@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 22:51, Jim Nasby wrote:
> The time to
> object to the concept of a checksuming feature was a long time ago,
> before a ton of development effort went into this... :(
I did. Development went ahead anyway.
- Heikki
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:11:49 |
| Message-ID: | 51350E15.7060309@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 22:40, Jeff Davis wrote:
> Is there any reason why we can't have both postgres and filesystem
> checksums?
Of course not. But if we can get away without checksums in Postgres,
that's better, because then we don't need to maintain that feature in
Postgres. If the patch gets committed, it's not mission accomplished.
There will be discussion and need for further development on things like
what to do if you get a checksum failure, patches to extend the
checksums to cover things like the clog and other non-data files and so
forth. And it's an extra complication that will need to be taken into
account when developing other new features; in particular, hint bit
updates need to write a WAL record. Even if you have all the current
hint bits covered, it's an extra hurdle for future patches that might
want to have hint bits in e.g new index access methods.
> The same user might not want both (or might, if neither are
> entirely trustworthy yet), but I think it's too early to declare one as
> the "right" solution and the other not. Even with btrfs stable, I
> pointed out a number of reasons users might not want it, and reasons
> that the project should not depend on it.
The PostgreSQL project would not be depending on it, any more than the
project depends on filesystem snapshots for backup purposes, or the OS
memory manager for caching.
> Numbers are always nice, but it takes a lot of effort to come up with
> them. What kind of numbers are you looking for, and how *specifically*
> will those numbers affect the decision?
Benchmark of vanilla PostgreSQL, PostgreSQL + this patch, and PostgreSQL
running on btrfs or ZFS with data checksums enabled. DBT-2 might be a
good candidate, as it's I/O heavy. That would be a good general test; in
addition it would be good to see a benchmark of the worst case scenario
for the fragmentation you're expecting to see on btrfs, as well as a
worst case scenario for the extra WAL traffic with the patch.
> If btrfs with checksums is 10% slower than ext4 with postgres checksums,
> does that mean we should commit the postgres checksums?
In my opinion, a 10% gain would not be worth it, and we should not
commit in that case.
> On the other side of the coin, if btrfs with checksums is exactly the
> same speed as ext4 with no postgres checksums (i.e. checksums are free
> if we use btrfs), does that mean postgres checksums should be rejected?
Yes, I think so. I'm sure at least some others will disagree; Greg
already made it quite clear that he doesn't care how the performance of
this compares with btrfs.
- Heikki
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:14:21 |
| Message-ID: | 51350EAD.5030004@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 3:00 PM, Heikki Linnakangas wrote:
> On 04.03.2013 22:51, Jim Nasby wrote:
>> The time to
>> object to the concept of a checksuming feature was a long time ago,
>> before a ton of development effort went into this... :(
>
> I did. Development went ahead anyway.
Right, because the community felt that this was valuable enough to do regardless of things like FS checksumming. But now you're bringing the issue up yet again, this time after a large amount of time has been invested.
I know that you're doing what you feel is best for the project, but in this case the community didn't agree with your view. Raising the same objection at this point is not productive at this point.
| From: | "ktm(at)rice(dot)edu" <ktm(at)rice(dot)edu> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:18:17 |
| Message-ID: | 20130304211817.GD3889@aart.rice.edu |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 04, 2013 at 01:00:09PM -0800, Jeff Davis wrote:
> On Mon, 2013-03-04 at 22:27 +0200, Heikki Linnakangas wrote:
> > If you're serious enough about your data that you want checksums, you
> > should be able to choose your filesystem.
>
> I simply disagree. I am targeting my feature at casual users. They may
> not have a lot of data or a dedicated DBA, but the data they do have
> might be very important transactional data.
>
> And right now, if they take a backup of their data, it will contain all
> of the corruption from the original. And since corruption is silent
> today, then they would probably think the backup is fine, and may delete
> the previous good backups.
>
+1
There is no reasonable availability of checksum capable filesystems across
PostgreSQL's supported OSes. It really needs to be available in core.
Regards,
Ken
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:22:01 |
| Message-ID: | 51351079.1@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 23:00, Jeff Davis wrote:
> On Mon, 2013-03-04 at 22:27 +0200, Heikki Linnakangas wrote:
>> Yeah, fragmentation will certainly hurt some workloads. But how badly,
>> and which workloads, and how does that compare with the work that
>> PostgreSQL has to do to maintain the checksums? I'd like to see some
>> data on those things.
>
> I think we all would. Btrfs will be a major filesystem in a few years,
> and we should be ready to support it.
Perhaps we should just wait a few years? If we suspect that this becomes
obsolete in a few years, it's probably better to just wait, than add a
feature we'll have to keep maintaining. Assuming it gets committed
today, it's going to take a year or two for 9.3 to get released and all
the bugs ironed out, anyway.
- Heikki
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jim Nasby <jim(at)nasby(dot)net> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:40:26 |
| Message-ID: | 513514CA.4000608@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 22:51, Jim Nasby wrote:
> Additionally, no filesystem I'm aware of checksums the data in the
> filesystem cache. A PG checksum would.
The patch says:
> + * IMPORTANT NOTE -
> + * The checksum is not valid at all times on a data page. We set it before we
> + * flush page/buffer, and implicitly invalidate the checksum when we modify the
> + * page. A heavily accessed buffer might then spend most of its life with an
> + * invalid page checksum, so testing random pages in the buffer pool will tell
> + * you nothing. The reason for this is that the checksum detects otherwise
> + * silent errors caused by the filesystems on which we rely. We do not protect
> + * buffers against uncorrectable memory errors, since these have a very low
> + * measured incidence according to research on large server farms,
> + * http://www.cs.toronto.edu/~bianca/papers/sigmetrics09.pdf, discussed 2010/12/22.
It's still true that it does in fact cover pages in the filesystem
cache, but apparently that's not important.
- Heikki
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 21:42:39 |
| Message-ID: | 20130304214239.GS16142@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
* Heikki Linnakangas (hlinnakangas(at)vmware(dot)com) wrote:
> Perhaps we should just wait a few years? If we suspect that this
> becomes obsolete in a few years, it's probably better to just wait,
> than add a feature we'll have to keep maintaining. Assuming it gets
> committed today, it's going to take a year or two for 9.3 to get
> released and all the bugs ironed out, anyway.
For my 2c, I don't see it being obsolete in a few years, even if every
existing FS out there gets checksumming (which won't happen, imv).
It's quite clear that there is still ongoing development in the
filesystem space and any new software will have its own set of bugs.
Having a layer of protection built-in to PG wil undoubtably be a good
thing and will be used by our users.
Thanks,
Stephen
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Jim Nasby <jim(at)nasby(dot)net> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 22:01:39 |
| Message-ID: | 1362434499.23497.134.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 14:57 -0600, Jim Nasby wrote:
> I suggest we paint that GUC along the lines of
> "checksum_failure_log_level", defaulting to ERROR. That way if someone
> wanted completely bury the elogs to like DEBUG they could.
The reason I didn't want to do that is because it's essentially a
recovery feature. A boolean seems more appropriate than a slider.
That's a good point about burying the messages with DEBUG, but I think
it might be slightly over-engineering it. I am willing to change it if
others want it, though.
Regards,
Jeff Davis
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Daniel Farina <daniel(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 23:20:30 |
| Message-ID: | 51352C3E.5070609@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/05/2013 04:48 AM, Jeff Davis wrote:
> We would still calculate the checksum and print the warning; and then
> pass it through the rest of the header checks. If the header checks
> pass, then it proceeds. If the header checks fail, and if
> zero_damaged_pages is off, then it would still generate an error (as
> today).
>
> So: ignore_checksum_failures = on|off ?
That seems reasonable to me. It would be important to document clearly
in postgresql.conf and on the docs for the option that enabling this
option can launder data corruption, so that blocks that we suspected
were damaged are marked clean on rewrite. So long as that's clearly
documented I'm personally quite comfortable with your suggestion, since
my focus is just making sure I can get a DB back to a fully operational
state as quickly as possible when that's necessary.
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-04 23:34:13 |
| Message-ID: | 51352F75.8010201@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 3:13 PM, Heikki Linnakangas wrote:
> This PostgreSQL patch hasn't seen any production use, either. In fact,
> I'd consider btrfs to be more mature than this patch. Unless you think
> that there will be some major changes to the worse in performance in
> btrfs, it's perfectly valid and useful to compare the two.
I think my last message came out with a bit more hostile attitude about
this than I intended it to; sorry about that. My problem with this idea
comes from looking at the history of how Linux has failed to work
properly before. The best example I can point at is the one I
documented at
http://www.postgresql.org/message-id/4B512D0D.4030909@2ndquadrant.com
along with this handy pgbench chart:
http://www.phoronix.com/scan.php?page=article&item=ubuntu_lucid_alpha2&num=3
TPS on pgbench dropped from 1102 to about 110 after a kernel bug fix.
It was 10X as fast in some kernel versions because fsync wasn't working
properly. Kernel filesystem issues have regularly resulted in data not
being written to disk when it should have been, inflating the results
accordingly. Fake writes due to "lying drives", write barriers that
only actually work on server-class hardware, write barriers that don't
work on md volumes, and then this one; it's a recurring pattern. It's
not the fault of the kernel developers, it's a hard problem and drive
manufacturers aren't making it easy for them.
My concern, then, is that if the comparison target is btrfs performance,
how do we know it's working reliably? The track record says that bugs
in this area usually inflate results, compared with a correct
implementation. You are certainly right that this checksum code is less
mature than btrfs; it's just over a year old after all. I feel quite
good that it's not benchmarking faster than it really is, especially
when I can directly measure how the write volume is increasing in the
worst result.
I can't say that btrfs is slower or faster than it will eventually be
due to bugs; I can't tell you the right way to tune btrfs for
PostgreSQL; and I haven't even had anyone asking the question yet.
Right now, the main thing I know about testing performance on Linux
kernels new enough to support btrfs is that they're just generally slow
running PostgreSQL. See the multiple confirmed regression issues at
http://www.postgresql.org/message-id/60B572D9298D944580F7D51195DD30804357FA4ABF@VMBX125.ihostexchange.net
for example. That new kernel mess needs to get sorted out too one day.
Why does database performance suck on kernel 3.2? I don't know yet,
but it doesn't help me get excited about assuming btrfs results will be
useful.
ZFS was supposed to save everyone from worrying about corruption issues.
That didn't work out, I think due to the commercial agenda behind its
development. Now we have btrfs coming in some number of years, a
project still tied more than I would like to Oracle. I'm not too
optimistic about that one either. It doesn't help that now the original
project lead, Chris Mason, has left there and is working at
FusionIO--and that company's filesystem plans don't include
checksumming, either. (See
http://www.fusionio.com/blog/under-the-hood-of-the-iomemory-sdk/ for a
quick intro to what they're doing right now, which includes bypassing
the Linux filesystem layer with their own flash optimized but POSIX
compliant directFS)
There is an optimistic future path I can envision where btrfs matures
quickly and in a way that performs well for PostgreSQL. Maybe we'll end
up there, and if that happens everyone can look back and say this was a
stupid idea. But there are a lot of other outcomes I see as possible
here, and in all the rest of them having some checksumming capabilities
available is a win.
One of the areas PostgreSQL has a solid reputation on is being trusted
to run as reliably as possible. All of the deployment trends I'm seeing
have people moving toward less reliable hardware. VMs, cloud systems,
regular drives instead of hardware RAID, etc. A lot of people badly
want to leave behind the era of the giant database server, and have a
lot of replicas running on smaller/cheaper systems instead. There's a
useful advocacy win for the project if lower grade hardware can be used
to hit a target reliability level, with software picking up some of the
error detection job instead. Yes, it costs something in terms of future
maintenance on the codebase, as new features almost invariably do. If I
didn't see being able to make noise about the improved reliability of
PostgreSQL as valuable enough to consider it anyway, I wouldn't even be
working on this thing.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndQuadrant(dot)com>, Daniel Farina <daniel(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 00:15:24 |
| Message-ID: | 5135391C.2050103@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 5:20 PM, Craig Ringer wrote:
> On 03/05/2013 04:48 AM, Jeff Davis wrote:
>> We would still calculate the checksum and print the warning; and then
>> pass it through the rest of the header checks. If the header checks
>> pass, then it proceeds. If the header checks fail, and if
>> zero_damaged_pages is off, then it would still generate an error (as
>> today).
>>
>> So: ignore_checksum_failures = on|off ?
> That seems reasonable to me. It would be important to document clearly
> in postgresql.conf and on the docs for the option that enabling this
> option can launder data corruption, so that blocks that we suspected
> were damaged are marked clean on rewrite. So long as that's clearly
> documented I'm personally quite comfortable with your suggestion, since
> my focus is just making sure I can get a DB back to a fully operational
> state as quickly as possible when that's necessary.
I replied to this somewhere else in the thread when I over-looked Jeff's original post, so sorry for the noise... :(
Would it be better to do checksum_logging_level = <valid elog levels> ? That way someone could set the notification to anything from DEBUG up to PANIC. ISTM the default should be ERROR.
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Jim Nasby <jim(at)nasby(dot)net> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndQuadrant(dot)com>, Daniel Farina <daniel(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 00:22:30 |
| Message-ID: | 51353AC6.506@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/05/2013 08:15 AM, Jim Nasby wrote:
>
> Would it be better to do checksum_logging_level = <valid elog levels>
> ? That way someone could set the notification to anything from DEBUG
> up to PANIC. ISTM the default should be ERROR.
That seems nice at first brush, but I don't think it holds up.
All our other log_level parameters control only output. If I saw that
parameter, I would think "aah, this is how we control the detail and
verbosity of messages regarding checksum checking and maintenance". I
would be totally astonished if I changed it and it actually affected the
system's data integrity checking and enforcement processes. Logging
control GUCs control what we show to what clients/log files, not what
log statements get executed; they're a filter and don't control the
behaviour of the emitting log point.
Control over whether checksum failures are an error or merely warned
about is reasonable, but I strongly disagree with the idea of making
this seem like it's just a logging parameter.
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndQuadrant(dot)com>, Daniel Farina <daniel(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 00:24:43 |
| Message-ID: | 51353B4B.5060407@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 6:22 PM, Craig Ringer wrote:
> On 03/05/2013 08:15 AM, Jim Nasby wrote:
>>
>> Would it be better to do checksum_logging_level = <valid elog levels>
>> ? That way someone could set the notification to anything from DEBUG
>> up to PANIC. ISTM the default should be ERROR.
> That seems nice at first brush, but I don't think it holds up.
>
> All our other log_level parameters control only output. If I saw that
> parameter, I would think "aah, this is how we control the detail and
> verbosity of messages regarding checksum checking and maintenance". I
> would be totally astonished if I changed it and it actually affected the
> system's data integrity checking and enforcement processes. Logging
> control GUCs control what we show to what clients/log files, not what
> log statements get executed; they're a filter and don't control the
> behaviour of the emitting log point.
>
> Control over whether checksum failures are an error or merely warned
> about is reasonable, but I strongly disagree with the idea of making
> this seem like it's just a logging parameter.
Good point. I thought we actually had precedent for controlling the level that something gets logged at, but now that you mention it I guess we don't. And this could sure as hell cause confusion.
So yeah, your original idea sounds best.
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 00:43:10 |
| Message-ID: | 51353F9E.809@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Heikki,
> Perhaps we should just wait a few years? If we suspect that this becomes
> obsolete in a few years, it's probably better to just wait, than add a
> feature we'll have to keep maintaining. Assuming it gets committed
> today, it's going to take a year or two for 9.3 to get released and all
> the bugs ironed out, anyway.
You are far more optimistic about FS development than I am:
* Windows and OSX are unlikely to ever have usable FS checksums
* BTRFS may be years away from being production-quality for DB server,
and (given the current dev priorities) may *never* be suitable for DB
servers.
* For various reasons, many users may stay with other filesystems, even
on Linux.
* All filesystems have bugs, and the FS may be itself causing the
corruption.
* FS checksums may not catch underlying driver bugs (i.e. better to have
two checks than one if you KNOW something is wrong)
We have people who could use PostgreSQL-level checksums *now* because
they are having data corruption issues *now* and need a tool to help
determine what layer the corruption is occurring at.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 01:04:27 |
| Message-ID: | CAAZKuFZrK+pZeJZ+B6vsudT_j7YLdrGNUKmV2ZTmQTUtCtNKHg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 4, 2013 at 1:22 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> On 04.03.2013 23:00, Jeff Davis wrote:
>>
>> On Mon, 2013-03-04 at 22:27 +0200, Heikki Linnakangas wrote:
>>>
>>> Yeah, fragmentation will certainly hurt some workloads. But how badly,
>>> and which workloads, and how does that compare with the work that
>>> PostgreSQL has to do to maintain the checksums? I'd like to see some
>>> data on those things.
>>
>>
>> I think we all would. Btrfs will be a major filesystem in a few years,
>> and we should be ready to support it.
>
>
> Perhaps we should just wait a few years? If we suspect that this becomes
> obsolete in a few years, it's probably better to just wait, than add a
> feature we'll have to keep maintaining. Assuming it gets committed today,
> it's going to take a year or two for 9.3 to get released and all the bugs
> ironed out, anyway.
Putting aside the not-so-rosy predictions seen elsewhere in this
thread about the availability of a high performance, reliable
checksumming file system available on common platforms, I'd like to
express what benefit this feature will have to me:
Corruption has easily occupied more than one person-month of time last
year for us. This year to date I've burned two weeks, although
admittedly this was probably the result of statistical clustering.
Other colleagues of mine have probably put in a week or two in
aggregate in this year to date. The ability to quickly, accurately,
and maybe at some later date proactively finding good backups to run
WAL recovery from is one of the biggest strides we can make in the
operation of Postgres. The especially ugly cases are where the page
header is not corrupt, so full page images can carry along malformed
tuples...basically, when the corruption works its way into the WAL,
we're in much worse shape. Checksums would hopefully prevent this
case, converting them into corrupt pages that will not be modified.
It would be better yet if I could write tools to find the last-good
version of pages, and so I think tight integration with Postgres will
see a lot of benefits that would be quite difficult and non-portable
when relying on file system checksumming.
You are among the most well-positioned to make assessments of the cost
of the feature, but I thought you might appreciate a perspective of
the benefits, too. I think they're large, and for me they are the
highest pole in the tent for "what makes Postgres stressful to operate
as-is today." It's a testament to the quality of the programming in
Postgres that Postgres programming error is not the largest problem.
For sense of reference, I think the next largest operational problem
is the disruption caused by logical backups, e.g. pg_dump, and in
particular its long running transactions and sessions.
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 01:27:04 |
| Message-ID: | 1362446824.23497.424.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 23:22 +0200, Heikki Linnakangas wrote:
> On 04.03.2013 23:00, Jeff Davis wrote:
> > On Mon, 2013-03-04 at 22:27 +0200, Heikki Linnakangas wrote:
> >> Yeah, fragmentation will certainly hurt some workloads. But how badly,
> >> and which workloads, and how does that compare with the work that
> >> PostgreSQL has to do to maintain the checksums? I'd like to see some
> >> data on those things.
> >
> > I think we all would. Btrfs will be a major filesystem in a few years,
> > and we should be ready to support it.
>
> Perhaps we should just wait a few years? If we suspect that this becomes
> obsolete in a few years
I do not expect it to be obsolete, even if btrfs is stable and fast
today.
Consider this hypothetical scenario: what if btrfs performs acceptably
well today, but they tune it away from our needs later and it tanks
performance? Then, when we complain, the btrfs people say "for DB
workloads, you should turn off COW, or use ext4 or XFS". And then we say
"but we want checksums". And then they tell us that real databases do
their own checksums.
Then what?
I don't think that scenario is very outlandish. Postgres is essentially
a COW system (for tuples), and stacking COW on top of COW does not seem
like a good idea (neither for filesystems nor actual cows). So it may be
within reason for the filesystem folks to say we're doing the wrong
thing, and then checksums are our problem again. Additionally, I don't
have a lot of faith that linux will address all of our btrfs complaints
(even legitimate ones) in a reasonable amount of time, if ever.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 01:39:27 |
| Message-ID: | 1362447567.23497.438.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-04 at 23:11 +0200, Heikki Linnakangas wrote:
> Of course not. But if we can get away without checksums in Postgres,
> that's better, because then we don't need to maintain that feature in
> Postgres. If the patch gets committed, it's not mission accomplished.
> There will be discussion and need for further development on things like
> what to do if you get a checksum failure, patches to extend the
> checksums to cover things like the clog and other non-data files and so
> forth. And it's an extra complication that will need to be taken into
> account when developing other new features; in particular, hint bit
> updates need to write a WAL record. Even if you have all the current
> hint bits covered, it's an extra hurdle for future patches that might
> want to have hint bits in e.g new index access methods.
The example you chose of adding a hint bit is a little overstated -- as
far as I can tell, setting a hint bit follows pretty much the same
pattern as before, except that I renamed the function to
MarkBufferDirtyHint().
But I agree in general. If complexity can be removed or avoided, that is
a very good thing. But right now, we have no answer to a real problem
that other databases do have an answer for. To me, the benefit is worth
the cost.
We aren't going down an irreversible path by adding checksums. If every
platform has a good checksumming filesystem and there is no demand for
the postgres code any more, we can deprecate it and remove it. But at
least users would have something between now and then.
> The PostgreSQL project would not be depending on it, any more than the
> project depends on filesystem snapshots for backup purposes, or the OS
> memory manager for caching.
I don't understand your analogies at all. We have WAL-protected base
backups so that users can get a consistent snapshot without filesystem
snapshots. To follow the analogy, we want postgres checksums so that the
user can be protected without filesystem checksums.
I would agree with you if we could point users somewhere and actually
recommend something and say "what you're doing now is wrong, do X
instead" (though if there is only one such X, we are dependent on it).
But even if we fast forward to three years from now: if someone shows up
saying that XFS gives him the best performance, but wants checksums,
will we really be able to say "you are wrong to be using XFS; use
Btrfs"?
One of the things I like about postgres is that we don't push a lot of
hard trade-offs on users. Several people (including you) put in effort
recently to support unlogged gist indexes. Are there some huge number of
users there that can't live without unlogged gist indexes? Probably not.
But that is one less thing that potential users have to trade away, and
one less thing to be confused or frustrated about.
I want to get to the point where checksums are the default, and only
advanced users would disable them. If that point comes in the form of
checksumming filesystems that are fast enough and enabled by default on
most of the platforms we support, that's fine with me. But I'm not very
sure that it will happen that way ever, and certainly not soon.
> > If btrfs with checksums is 10% slower than ext4 with postgres checksums,
> > does that mean we should commit the postgres checksums?
>
> In my opinion, a 10% gain would not be worth it, and we should not
> commit in that case.
>
> > On the other side of the coin, if btrfs with checksums is exactly the
> > same speed as ext4 with no postgres checksums (i.e. checksums are free
> > if we use btrfs), does that mean postgres checksums should be rejected?
>
> Yes, I think so. I'm sure at least some others will disagree; Greg
> already made it quite clear that he doesn't care how the performance of
> this compares with btrfs.
If all paths lead to rejection, what are these tests supposed to
accomplish, exactly?
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 03:09:04 |
| Message-ID: | 1362452944.23497.455.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 2013-03-03 at 18:05 -0500, Greg Smith wrote:
> = Test 1 - find worst-case overhead for the checksum calculation on write =
>
> This can hit 25% of runtime when you isolate it out. I'm not sure if
> how I'm running this multiple times makes sense yet. This one is so
> much slower on my Mac that I can't barely see a change at all.
>
> = Test 2 - worst-case overhead for calculating checksum while reading data =
>
> Jeff saw an 18% slowdown, I get 24 to 32%. This one bothers me because
> the hit is going to happen during the very common situation where data
> is shuffling a lot between a larger OS cache and shared_buffers taking a
> relatively small fraction. If that issue were cracked, such that
> shared_buffers could be >50% of RAM, I think the typical real-world
> impact of this would be easier to take.
I believe that test 1 and test 2 can be improved a little, if there is a
need. Right now we copy the page and then calculate the checksum on the
copy. If we instead calculate as we're copying, I believe it will make
it significantly faster.
I decided against doing that, because it decreased the readability, and
we can always do that later as an optimization. That should mitigate the
case you have in mind, which is a very legitimate concern. I'll wait for
someone to ask for it, though.
> = Test 3 - worst-case WAL overhead =
>
> This is the really nasty one. The 10,000,000 rows touched by the SELECT
> statement here create no WAL in a non-checksum environment. When
> checksums are on, 368,513,656 bytes of WAL are written, so about 37
> bytes per row.
Yeah, nothing we can do about this.
> Right now the whole hint bit mechanism and its overhead are treated as
> an internal detail that isn't in the regular documentation. I think
> committing this sort of checksum patch will require exposing some of the
> implementation to the user in the documentation, so people can
> understand what the trouble cases are--either in advance or when trying
> to puzzle out why they're hitting one of them.
Any particular sections that you think would be good to update?
Thank you for the test results.
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 09:01:50 |
| Message-ID: | CA+U5nMJY4+JLnFBQOMtthpd5fSTS-=YC9oBqbierUJ8eBFhc6Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 5 March 2013 01:04, Daniel Farina <daniel(at)heroku(dot)com> wrote:
> Corruption has easily occupied more than one person-month of time last
> year for us. This year to date I've burned two weeks, although
> admittedly this was probably the result of statistical clustering.
> Other colleagues of mine have probably put in a week or two in
> aggregate in this year to date. The ability to quickly, accurately,
> and maybe at some later date proactively finding good backups to run
> WAL recovery from is one of the biggest strides we can make in the
> operation of Postgres. The especially ugly cases are where the page
> header is not corrupt, so full page images can carry along malformed
> tuples...basically, when the corruption works its way into the WAL,
> we're in much worse shape. Checksums would hopefully prevent this
> case, converting them into corrupt pages that will not be modified.
>
> It would be better yet if I could write tools to find the last-good
> version of pages, and so I think tight integration with Postgres will
> see a lot of benefits that would be quite difficult and non-portable
> when relying on file system checksumming.
>
> You are among the most well-positioned to make assessments of the cost
> of the feature, but I thought you might appreciate a perspective of
> the benefits, too. I think they're large, and for me they are the
> highest pole in the tent for "what makes Postgres stressful to operate
> as-is today." It's a testament to the quality of the programming in
> Postgres that Postgres programming error is not the largest problem.
That's good perspective.
I think we all need to be clear that committing this patch also
commits the community (via the committer) to significant work and
responsibility around this, and my minimum assessment of it is 1 month
per year for a 3-5 years, much of that on the committer. In effect
this will move time and annoyance experienced by users of Postgres
back onto developers of Postgres. That is where it should be, but the
effect will be large and easily noticeable, IMHO.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 09:35:14 |
| Message-ID: | 5135BC52.3020609@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.03.2013 09:11, Simon Riggs wrote:
> On 3 March 2013 18:24, Greg Smith<greg(at)2ndquadrant(dot)com> wrote:
>
>> The 16-bit checksum feature seems functional, with two sources of overhead.
>> There's some CPU time burned to compute checksums when pages enter the
>> system. And there's extra overhead for WAL logging hint bits. I'll
>> quantify both of those better in another message.
>
> It's crunch time. Do you and Jeff believe this patch should be
> committed to Postgres core?
>
> Are there objectors?
In addition to my hostility towards this patch in general, there are
some specifics in the patch I'd like to raise (read out in a grumpy voice):
If you enable checksums, the free space map never gets updated in a
standby. It will slowly drift to be completely out of sync with reality,
which could lead to significant slowdown and bloat after failover.
Since the checksums are an all-or-nothing cluster-wide setting, the
three extra flags in the page header, PD_CHECKSUMS1, PD_CHECKSUM2 and
PD_HEADERCHECK, are not needed. Let's leave them out. That keeps the
code simpler, and leaves the bits free for future use. If we want to
enable such per-page setting in the future, we can add it later. For a
per-relation scheme, they're not needed.
> + * The checksum algorithm is a modified Fletcher 64-bit (which is
> + * order-sensitive). The modification is because, at the end, we have two
> + * 64-bit sums, but we only have room for a 16-bit checksum. So, instead of
> + * using a modulus of 2^32 - 1, we use 2^8 - 1; making it also resemble a
> + * Fletcher 16-bit. We don't use Fletcher 16-bit directly, because processing
> + * single bytes at a time is slower.
How does the error detection rate of this compare with e.g CRC-16? Is
there any ill effect from truncating the Fletcher sums like this?
> + /*
> + * Store the sums as bytes in the checksum. We add one to shift the range
> + * from 0..255 to 1..256, to make zero invalid for checksum bytes (which
> + * seems wise).
> + */
> + p8Checksum[0] = (sum1 % 255) + 1;
> + p8Checksum[1] = (sum2 % 255) + 1;
That's a bit odd. We don't avoid zero in the WAL crc, and I don't recall
seeing that in other checksum implementations either. 16-bits is not
very wide for a checksum, and this eats about 1% of the space of valid
values.
I can see that it might be a handy debugging aid to avoid 0. But there's
probably no need to avoid 0 in both bytes, it seems enough to avoid a
completely zero return value.
XLogCheckBuffer() and XLogCheckBufferNeedsBackup() read the page LSN
without a lock. That's not atomic, so it could incorrectly determine
that a page doesn't need to be backed up. We used to always hold an
exclusive lock on the buffer when it's called, which prevents
modifications to the LSN, but that's no longer the case.
Shouldn't SetBufferCommitInfoNeedsSave() check the BM_PERMANENT flag? I
think it will generate WAL records for unlogged tables as it is.
- Heikki
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-05 18:02:55 |
| Message-ID: | 1362506575.26602.89.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Thank you for the review.
On Tue, 2013-03-05 at 11:35 +0200, Heikki Linnakangas wrote:
> If you enable checksums, the free space map never gets updated in a
> standby. It will slowly drift to be completely out of sync with reality,
> which could lead to significant slowdown and bloat after failover.
Will investigate.
> Since the checksums are an all-or-nothing cluster-wide setting, the
> three extra flags in the page header, PD_CHECKSUMS1, PD_CHECKSUM2 and
> PD_HEADERCHECK, are not needed. Let's leave them out. That keeps the
> code simpler, and leaves the bits free for future use. If we want to
> enable such per-page setting in the future, we can add it later. For a
> per-relation scheme, they're not needed.
They don't really need to be there, I just put them there because it
seemed wise if we ever want to allow online enabling/disabling of
checksums. But I will remove them.
> How does the error detection rate of this compare with e.g CRC-16? Is
> there any ill effect from truncating the Fletcher sums like this?
I don't recall if I published these results or not, but I loaded a
table, and used pageinspect to get the checksums of the pages. I then
did some various GROUP BY queries to see if I could find any clustering
or stepping of the checksum values, and I could not. The distribution
seemed very uniform across the 255^2 space.
I tried to think of other problems, like missing errors in the high or
low bits of a word or a page (similar to the issue with mod 256
described below), but I couldn't find any. I'm not enough of an expert
to say more than that about the error detection rate.
Fletcher is probably significantly faster than CRC-16, because I'm just
doing int32 addition in a tight loop.
Simon originally chose Fletcher, so perhaps he has more to say.
> That's a bit odd. We don't avoid zero in the WAL crc, and I don't recall
> seeing that in other checksum implementations either. 16-bits is not
> very wide for a checksum, and this eats about 1% of the space of valid
> values.
>
> I can see that it might be a handy debugging aid to avoid 0. But there's
> probably no need to avoid 0 in both bytes, it seems enough to avoid a
> completely zero return value.
http://en.wikipedia.org/wiki/Fletcher%27s_checksum
If you look at the section on Fletcher-16, it discusses the choice of
the modulus. If we used 256, then an error anywhere except the lowest
byte of a 4-byte word read from the page would be missed.
Considering that I was using only 255 values anyway, I thought I might
as well shift the values away from zero.
We could get slightly better by using all combinations. I also
considered chopping the 64-bit ints into 16-bit chunks and XORing them
together. But when I saw the fact that we avoided zero with the other
approach, I kind of liked it, and kept it.
> XLogCheckBuffer() and XLogCheckBufferNeedsBackup() read the page LSN
> without a lock. That's not atomic, so it could incorrectly determine
> that a page doesn't need to be backed up. We used to always hold an
> exclusive lock on the buffer when it's called, which prevents
> modifications to the LSN, but that's no longer the case.
Will investigate, but it sounds like a buffer header lock will fix it.
> Shouldn't SetBufferCommitInfoNeedsSave() check the BM_PERMANENT flag? I
> think it will generate WAL records for unlogged tables as it is.
Yes, thank you.
Also, in FlushBuffer(), this patch moves the clearing of the
BM_JUST_DIRTIED bit to before the WAL flush. That seems to expand the
window during which a change to a page will prevent it from being marked
clean. Do you see any performance problem with that?
The alternative is to take the buffer header lock twice: once to get the
LSN, then WAL flush, then another header lock to clear BM_JUST_DIRTIED.
Not sure if that's better or worse. This goes back to Simon's patch, so
he may have a comment here, as well.
I'll post a new patch with these comments addressed, probably tomorrow
so that I have some time to self-review and do some basic testing.
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 08:32:32 |
| Message-ID: | CA+U5nM+HAHseXwB+AKXrdvDYce5gU1P=hf7oG8rNV2zyPsjRwg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 5 March 2013 09:35, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> wrote:
>> Are there objectors?
>
>
> In addition to my hostility towards this patch in general, there are some
> specifics in the patch I'd like to raise (read out in a grumpy voice):
;-) We all want to make the right choice here, so all viewpoints
gratefully received so we can decide.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 08:41:07 |
| Message-ID: | CA+U5nML8pZyg=EVWMd_b7-JZ52fU7HKOA5s6Lo3YSnLa_Jim+w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 5 March 2013 18:02, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> Fletcher is probably significantly faster than CRC-16, because I'm just
> doing int32 addition in a tight loop.
>
> Simon originally chose Fletcher, so perhaps he has more to say.
IIRC the research showed Fletcher was significantly faster for only a
small loss in error detection rate.
It was sufficient to make our error detection > 1 million times
better, possibly more. That seems sufficient to enable early detection
of problems, since if we missed the first error, a second is very
likely to be caught (etc). So I am assuming that we're trying to catch
a pattern of errors early, rather than guarantee we can catch the very
first error.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 11:34:21 |
| Message-ID: | 513729BD.1010501@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 06.03.2013 10:41, Simon Riggs wrote:
> On 5 March 2013 18:02, Jeff Davis<pgsql(at)j-davis(dot)com> wrote:
>
>> Fletcher is probably significantly faster than CRC-16, because I'm just
>> doing int32 addition in a tight loop.
>>
>> Simon originally chose Fletcher, so perhaps he has more to say.
>
> IIRC the research showed Fletcher was significantly faster for only a
> small loss in error detection rate.
>
> It was sufficient to make our error detection> 1 million times
> better, possibly more. That seems sufficient to enable early detection
> of problems, since if we missed the first error, a second is very
> likely to be caught (etc). So I am assuming that we're trying to catch
> a pattern of errors early, rather than guarantee we can catch the very
> first error.
Fletcher's checksum is good in general, I was mainly worried about
truncating the Fletcher-64 into two 8-bit values. I can't spot any
obvious weakness in it, but if it's indeed faster and as good as a
straightforward Fletcher-16, I wonder why that method is not more widely
used.
Another thought is that perhaps something like CRC32C would be faster to
calculate on modern hardware, and could be safely truncated to 16-bits
using the same technique you're using to truncate the Fletcher's
Checksum. Greg's tests showed that the overhead of CRC calculation is
significant in some workloads, so it would be good to spend some time to
optimize that. It'd be difficult to change the algorithm in a future
release without breaking on-disk compatibility, so let's make sure we
pick the best one.
- Heikki
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 14:45:19 |
| Message-ID: | 20130306144519.GA4970@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-03-06 13:34:21 +0200, Heikki Linnakangas wrote:
> On 06.03.2013 10:41, Simon Riggs wrote:
> >On 5 March 2013 18:02, Jeff Davis<pgsql(at)j-davis(dot)com> wrote:
> >
> >>Fletcher is probably significantly faster than CRC-16, because I'm just
> >>doing int32 addition in a tight loop.
> >>
> >>Simon originally chose Fletcher, so perhaps he has more to say.
> >
> >IIRC the research showed Fletcher was significantly faster for only a
> >small loss in error detection rate.
> >
> >It was sufficient to make our error detection> 1 million times
> >better, possibly more. That seems sufficient to enable early detection
> >of problems, since if we missed the first error, a second is very
> >likely to be caught (etc). So I am assuming that we're trying to catch
> >a pattern of errors early, rather than guarantee we can catch the very
> >first error.
>
> Fletcher's checksum is good in general, I was mainly worried about
> truncating the Fletcher-64 into two 8-bit values. I can't spot any obvious
> weakness in it, but if it's indeed faster and as good as a straightforward
> Fletcher-16, I wonder why that method is not more widely used.
I personally am not that convinced that fletcher is a such good choice given
that it afaik doesn't distinguish between all-zero and all-one runs that are
long enough.
> Another thought is that perhaps something like CRC32C would be faster to
> calculate on modern hardware, and could be safely truncated to 16-bits using
> the same technique you're using to truncate the Fletcher's Checksum. Greg's
> tests showed that the overhead of CRC calculation is significant in some
> workloads, so it would be good to spend some time to optimize that. It'd be
> difficult to change the algorithm in a future release without breaking
> on-disk compatibility, so let's make sure we pick the best one.
I had implemented a noticeably faster CRC32 implementation somewhere
around 201005202227(dot)49990(dot)andres(at)anarazel(dot)de . I have since repeatedly
seen pg's CRC32 implementation being a major limitation, so I think
brushing up that patch would be a good idea.
We might think about switching the polynom for WAL at the same time,
given, as you say, CRC32c is available in hardware. The bigger problem
is probably stuff like the control file et al.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Garick Hamlin <ghamlin(at)isc(dot)upenn(dot)edu> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 16:21:21 |
| Message-ID: | 20130306162121.GB12808@isc.upenn.edu |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 06, 2013 at 01:34:21PM +0200, Heikki Linnakangas wrote:
> On 06.03.2013 10:41, Simon Riggs wrote:
>> On 5 March 2013 18:02, Jeff Davis<pgsql(at)j-davis(dot)com> wrote:
>>
>>> Fletcher is probably significantly faster than CRC-16, because I'm just
>>> doing int32 addition in a tight loop.
>>>
>>> Simon originally chose Fletcher, so perhaps he has more to say.
>>
>> IIRC the research showed Fletcher was significantly faster for only a
>> small loss in error detection rate.
>>
>> It was sufficient to make our error detection> 1 million times
>> better, possibly more. That seems sufficient to enable early detection
>> of problems, since if we missed the first error, a second is very
>> likely to be caught (etc). So I am assuming that we're trying to catch
>> a pattern of errors early, rather than guarantee we can catch the very
>> first error.
>
> Fletcher's checksum is good in general, I was mainly worried about
> truncating the Fletcher-64 into two 8-bit values. I can't spot any
> obvious weakness in it, but if it's indeed faster and as good as a
> straightforward Fletcher-16, I wonder why that method is not more widely
> used.
I was wondering about the effectiveness of this resulting truncated hash
function as well.
> Another thought is that perhaps something like CRC32C would be faster to
> calculate on modern hardware, and could be safely truncated to 16-bits
> using the same technique you're using to truncate the Fletcher's
> Checksum. Greg's tests showed that the overhead of CRC calculation is
> significant in some workloads, so it would be good to spend some time to
> optimize that. It'd be difficult to change the algorithm in a future
> release without breaking on-disk compatibility, so let's make sure we
> pick the best one.
If picking a CRC why not a short optimal one rather than truncate CRC32C?
I've been reading about optimal checksum for small messages for other
reasons and found this paper quite good.
http://www.ece.cmu.edu/~koopman/roses/dsn04/koopman04_crc_poly_embedded.pdf
I was interested in small messages and small checksums so this paper may not be
as much help here.
Other than CRCs and fletcher sums, Pearson hashing with a 16-bit block might
be worth considering. Either a pearson hash or a 16-CRC is small enough to
implement with a lookup table rather than a formula.
I've been wondering what kind of errors we expect? Single bit flips? Large
swaths of bytes corrupted? Are we more worried about collisions (the odds
total garbage has the same checksum) or the odds we detect a flip of n-bits.
I would think since the message is large and a write to the wrong location
seems about as likely as a bit flip a pearson hash be good.
Any choice seems like it would be a nice improvement of noticing a storage stack
problem. The difference would be subtle. Can I estimate the odds of
undetected corruption that occurred since the condition was first detected
accurately or does the checksum/hash perform poorly?
Garick
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Garick Hamlin <ghamlin(at)isc(dot)upenn(dot)edu> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 17:03:20 |
| Message-ID: | 20130306170320.GD4970@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-03-06 11:21:21 -0500, Garick Hamlin wrote:
> If picking a CRC why not a short optimal one rather than truncate CRC32C?
CRC32C is available in hardware since SSE4.2.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Garick Hamlin <ghamlin(at)isc(dot)upenn(dot)edu>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 18:24:43 |
| Message-ID: | 19157.1362594283@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andres Freund <andres(at)2ndquadrant(dot)com> writes:
> On 2013-03-06 11:21:21 -0500, Garick Hamlin wrote:
>> If picking a CRC why not a short optimal one rather than truncate CRC32C?
> CRC32C is available in hardware since SSE4.2.
I think that should be at most a fourth-order consideration, since we
are not interested solely in Intel hardware, nor do we have any portable
way of getting at such a feature even if the hardware has it.
regards, tom lane
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 18:34:53 |
| Message-ID: | CA+Tgmoa-JtULkz4QO1kX_rddfNFUS3WqLDa5o5LELEMXogup9g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 4, 2013 at 3:13 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> On 04.03.2013 20:58, Greg Smith wrote:
>>
>> There
>> is no such thing as a stable release of btrfs, and no timetable for when
>> there will be one. I could do some benchmarks of that but I didn't think
>> they were very relevant. Who cares how fast something might run when it
>> may not work correctly? btrfs might as well be /dev/null to me right
>> now--sure it's fast, but maybe the data won't be there at all.
>
> This PostgreSQL patch hasn't seen any production use, either. In fact, I'd
> consider btrfs to be more mature than this patch. Unless you think that
> there will be some major changes to the worse in performance in btrfs, it's
> perfectly valid and useful to compare the two.
>
> A comparison with ZFS would be nice too. That's mature, and has checksums.
We've had a few EnterpriseDB customers who have had fantastically
painful experiences with PostgreSQL + ZFS. Supposedly, aligning the
ZFS block size to the PostgreSQL block size is supposed to make these
problems go away, but in my experience it does not have that effect.
So I think telling people who want checksums "go use ZFS" is a lot
like telling them "oh, I see you have a hangnail, we recommend that
you solve that by cutting your arm off with a rusty saw".
There may be good reasons to reject this patch. Or there may not.
But I completely disagree with the idea that asking them to solve the
problem at the filesystem level is sensible.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 19:14:19 |
| Message-ID: | 5137958B.3080404@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> There may be good reasons to reject this patch. Or there may not.
> But I completely disagree with the idea that asking them to solve the
> problem at the filesystem level is sensible.
Yes, can we get back to the main issues with the patch?
1) argument over whether the checksum is sufficient to detect most
errors, or if it will give users false confidence.
2) performance overhead.
Based on Smith's report, I consider (2) to be a deal-killer right now.
The level of overhead reported by him would prevent the users I work
with from ever employing checksums on production systems.
Specifically, the writing checksums for a read-only query is a defect I
think is prohibitively bad. When we first talked about this feature for
9.2, we were going to exclude hint bits from checksums, in order to
avoid this issue; what happened to that?
(FWIW, I still support the idea of moving hint bits to a separate
filehandle, as we do with the FSM, but clearly that's not happening for
9.3 ...)
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 23:00:32 |
| Message-ID: | 5137CA90.4020906@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert,
> We've had a few EnterpriseDB customers who have had fantastically
> painful experiences with PostgreSQL + ZFS. Supposedly, aligning the
> ZFS block size to the PostgreSQL block size is supposed to make these
> problems go away, but in my experience it does not have that effect.
> So I think telling people who want checksums "go use ZFS" is a lot
> like telling them "oh, I see you have a hangnail, we recommend that
> you solve that by cutting your arm off with a rusty saw".
Wow, what platform are you using ZFS on?
(we have a half-dozen clients on ZFS ...)
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 23:04:19 |
| Message-ID: | CA+TgmoaEVY4CS0CX98RjT562DQ1qLUgDa7AgFNPAywmStrGFxQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 6, 2013 at 2:14 PM, Josh Berkus <josh(at)agliodbs(dot)com> wrote:
> Based on Smith's report, I consider (2) to be a deal-killer right now.
I was pretty depressed by those numbers, too.
> The level of overhead reported by him would prevent the users I work
> with from ever employing checksums on production systems.
Agreed.
> Specifically, the writing checksums for a read-only query is a defect I
> think is prohibitively bad.
That particular part doesn't bother me so much as some of the others -
but let's step back and look at the larger issue. I suspect we can
all agree that the performance of this feature is terrible. The
questions I think we should be asking are:
1. Are the problems fundamental, or things where we can reasonable
foresee future improvement? The latter situation wouldn't bother me
very much even if the current situation is pretty bad, but if there's
no real hope of improvement, that's more of a problem.
2. Are the performance results sufficiently bad that we think this
would be more of a liability than an asset?
> When we first talked about this feature for
> 9.2, we were going to exclude hint bits from checksums, in order to
> avoid this issue; what happened to that?
I don't think anyone ever thought that was a particularly practical
design. I certainly don't.
> (FWIW, I still support the idea of moving hint bits to a separate
> filehandle, as we do with the FSM, but clearly that's not happening for
> 9.3 ...)
Or, most likely, ever. The whole benefit of hint bits is that the
information you need is available in the same bytes you have to read
anyway. Moving the information to another fork (not filehandle) would
probably give up most of the benefit.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 23:06:51 |
| Message-ID: | CA+TgmoYJPoADz2bRtZ0y_JynWGB5PaBuYLceKY=V1M+Aue7QZQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 6, 2013 at 6:00 PM, Josh Berkus <josh(at)agliodbs(dot)com> wrote:
>> We've had a few EnterpriseDB customers who have had fantastically
>> painful experiences with PostgreSQL + ZFS. Supposedly, aligning the
>> ZFS block size to the PostgreSQL block size is supposed to make these
>> problems go away, but in my experience it does not have that effect.
>> So I think telling people who want checksums "go use ZFS" is a lot
>> like telling them "oh, I see you have a hangnail, we recommend that
>> you solve that by cutting your arm off with a rusty saw".
>
> Wow, what platform are you using ZFS on?
>
> (we have a half-dozen clients on ZFS ...)
Not us, customers. But as to platform, I have yet to run across
anyone running ZFS on anything but Solaris. I'd be interested to hear
your experiences. Mine rhyme with "sun a play dreaming".
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | "Joshua D(dot) Drake" <jd(at)commandprompt(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-06 23:15:03 |
| Message-ID: | 5137CDF7.9060707@commandprompt.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/06/2013 03:06 PM, Robert Haas wrote:
>
> On Wed, Mar 6, 2013 at 6:00 PM, Josh Berkus <josh(at)agliodbs(dot)com> wrote:
>>> We've had a few EnterpriseDB customers who have had fantastically
>>> painful experiences with PostgreSQL + ZFS. Supposedly, aligning the
>>> ZFS block size to the PostgreSQL block size is supposed to make these
>>> problems go away, but in my experience it does not have that effect.
>>> So I think telling people who want checksums "go use ZFS" is a lot
>>> like telling them "oh, I see you have a hangnail, we recommend that
>>> you solve that by cutting your arm off with a rusty saw".
>>
>> Wow, what platform are you using ZFS on?
>>
>> (we have a half-dozen clients on ZFS ...)
>
> Not us, customers. But as to platform, I have yet to run across
> anyone running ZFS on anything but Solaris. I'd be interested to hear
> your experiences. Mine rhyme with "sun a play dreaming".
I would guess he meant on X86_64 or Sparc.
JD
>
--
Command Prompt, Inc. - http://www.commandprompt.com/
PostgreSQL Support, Training, Professional Services and Development
High Availability, Oracle Conversion, Postgres-XC
@cmdpromptinc - 509-416-6579
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 00:14:09 |
| Message-ID: | 5137DBD1.2090707@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/4/13 7:04 PM, Daniel Farina wrote:
> Corruption has easily occupied more than one person-month of time last
> year for us.
Just FYI for anyone that's experienced corruption... we've looked into doing row-level checksums at work. The only challenge we ran into was how to check them when reading data back. I don't remember the details but there was an issue with doing this via SELECT rules. It would be possible if you were willing to put writable views on all your tables (which isn't actually as horrible as it sounds; it wouldn't be hard to write a function to automagically do that for you).
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 00:17:32 |
| Message-ID: | 5137DC9C.202@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/6/13 1:14 PM, Josh Berkus wrote:
>
>> There may be good reasons to reject this patch. Or there may not.
>> But I completely disagree with the idea that asking them to solve the
>> problem at the filesystem level is sensible.
>
> Yes, can we get back to the main issues with the patch?
>
> 1) argument over whether the checksum is sufficient to detect most
> errors, or if it will give users false confidence.
>
> 2) performance overhead.
>
> Based on Smith's report, I consider (2) to be a deal-killer right now.
> The level of overhead reported by him would prevent the users I work
> with from ever employing checksums on production systems.
FWIW, the write workload most likely wouldn't be a problem for us. I am concerned about the reported 24-32% hit when reading back in from FS cache... that might kill this for us.
I'm working on doing a test to see how bad it actually is for us... but getting stuff like that done at work is like pulling teeth, so we'll see...
> Specifically, the writing checksums for a read-only query is a defect I
> think is prohibitively bad. When we first talked about this feature for
> 9.2, we were going to exclude hint bits from checksums, in order to
> avoid this issue; what happened to that?
>
> (FWIW, I still support the idea of moving hint bits to a separate
> filehandle, as we do with the FSM, but clearly that's not happening for
> 9.3 ...)
+1
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 00:37:40 |
| Message-ID: | 5137E154.2030506@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/06/2013 07:34 PM, Heikki Linnakangas wrote:
> It'd be difficult to change the algorithm in a future release without
> breaking on-disk compatibility,
On-disk compatibility is broken with major releases anyway, so I don't
see this as a huge barrier.
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 00:41:17 |
| Message-ID: | 20130307004117.GA12720@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-03-07 08:37:40 +0800, Craig Ringer wrote:
> On 03/06/2013 07:34 PM, Heikki Linnakangas wrote:
> > It'd be difficult to change the algorithm in a future release without
> > breaking on-disk compatibility,
> On-disk compatibility is broken with major releases anyway, so I don't
> see this as a huge barrier.
Uh, pg_upgrade?
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 00:44:44 |
| Message-ID: | 5137E2FC.6050708@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/6/13 1:34 PM, Robert Haas wrote:
> We've had a few EnterpriseDB customers who have had fantastically
> painful experiences with PostgreSQL + ZFS. Supposedly, aligning the
> ZFS block size to the PostgreSQL block size is supposed to make these
> problems go away, but in my experience it does not have that effect.
There are a couple of major tuning issues you have to get right for good
ZFS performance, like its tendency to gobble more RAM than is
necessarily appropriate for a PostgreSQL host. If you nail down all
those and carefully setup everything it can work OK. When Sun had a
bunch of good engineers working on the problem they certainly pulled it
off. I managed a 3TB database on a ZFS volume for a while myself.
Being able to make filesystem snapshots cleanly and easily was very nice.
As for the write performance implications of COW, though, at a couple of
points I was only able to keep that system ingesting data fast enough if
I turned fsync off :( It's not as if even ZFS makes all the filesystem
issues the database worries about go away either. Take a look at
http://www.c0t0d0s0.org/archives/6071-No,-ZFS-really-doesnt-need-a-fsck.html
as an example. That should leave you with a healthy concern over ZFS
handling of power interruption and lying drives. "[NTFS and ext3] have
the same problem, but it has different effects, that aren't as visible
as in ZFS." ext4 actually fixed this for most hardware though, and I
believe ZFS still has the same uberblock concern. ZFS reliability and
its page checksums are good, but they're not magic for eliminating torn
page issues.
Normally I would agree with Heikki's theory of "let's wait a few years
and see if the filesystem will take care of it" idea. But for me, the
"when do we get checksums?" clock started ticking in 2006 when ZFS
popularized its implementation, and now it's gone off and it keeps
ringing at new places. I would love it if FreeBSD had caught a massive
popularity wave in the last few years, so ZFS was running in a lot more
places. Instead what I keep seeing is deployments Linux with filesystem
choices skewed toward conservative. Forget about the leading edge--I'd
be happy if I could get one large customer to migrate off of ext3...
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 00:50:37 |
| Message-ID: | 5137E45D.9000104@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/07/2013 08:41 AM, Andres Freund wrote:
> On 2013-03-07 08:37:40 +0800, Craig Ringer wrote:
>> On 03/06/2013 07:34 PM, Heikki Linnakangas wrote:
>>> It'd be difficult to change the algorithm in a future release without
>>> breaking on-disk compatibility,
>> On-disk compatibility is broken with major releases anyway, so I don't
>> see this as a huge barrier.
> Uh, pg_upgrade?
Yeah. I was thinking that pg_upgrade copes with a lot of
incompatibilities already, but this is lower-level. Darn.
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 03:27:53 |
| Message-ID: | 51380939.7030901@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/6/13 6:34 AM, Heikki Linnakangas wrote:
> Another thought is that perhaps something like CRC32C would be faster to
> calculate on modern hardware, and could be safely truncated to 16-bits
> using the same technique you're using to truncate the Fletcher's
> Checksum. Greg's tests showed that the overhead of CRC calculation is
> significant in some workloads, so it would be good to spend some time to
> optimize that. It'd be difficult to change the algorithm in a future
> release without breaking on-disk compatibility, so let's make sure we
> pick the best one.
Simon sent over his first rev of this using a quick to compute 16 bit
checksum as a reasonable trade-off, one that it's possible to do right
now. It's not optimal in a few ways, but it catches single bit errors
that are missed right now, and Fletcher-16 computes quickly and without
a large amount of code. It's worth double-checking that the code is
using the best Fletcher-16 approach available. I've started on that,
but I'm working on your general performance concerns first, with the
implementation that's already there.
From what I've read so far, I think picking Fletcher-16 instead of the
main alternative, CRC-16-IBM AKA CRC-16-ANSI, is a reasonable choice.
There's a good table showing the main possibilities here at
https://en.wikipedia.org/wiki/Cyclic_redundancy_check
One day I hope that in-place upgrade learns how to do page format
upgrades, with the sort of background conversion tools and necessary
tracking metadata we've discussed for that work. When that day comes, I
would expect it to be straightforward to upgrade pages from 16 bit
Fletcher checksums to 32 bit CRC-32C ones. Ideally we would be able to
jump on the CRC-32C train today, but there's nowhere to put all 32 bits.
Using a Fletcher 16 bit checksum for 9.3 doesn't prevent the project
from going that way later though, once page header expansion is a solved
problem.
The problem with running CRC32C in software is that the standard fast
approach uses a "slicing" technique that requires a chunk of
pre-computed data be around, a moderately large lookup table. I don't
see that there's any advantage to having all that baggage around if
you're just going to throw away half of the result anyway. More on
CRC32Cs in my next message.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Garick Hamlin <ghamlin(at)isc(dot)upenn(dot)edu>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 03:30:50 |
| Message-ID: | 513809EA.2010103@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/6/13 1:24 PM, Tom Lane wrote:
> Andres Freund <andres(at)2ndquadrant(dot)com> writes:
>> On 2013-03-06 11:21:21 -0500, Garick Hamlin wrote:
>>> If picking a CRC why not a short optimal one rather than truncate CRC32C?
>
>> CRC32C is available in hardware since SSE4.2.
>
> I think that should be at most a fourth-order consideration, since we
> are not interested solely in Intel hardware, nor do we have any portable
> way of getting at such a feature even if the hardware has it.
True, but that situation might actually improve.
The Castagnoli CRC-32C that's accelerated on the better Intel CPUs is
also used to protect iSCSI and SCTP (a streaming protocol). And there
is an active project to use a CRC32C to checksum ext4 metadata blocks on
Linux: https://ext4.wiki.kernel.org/index.php/Ext4_Metadata_Checksums
https://groups.google.com/forum/?fromgroups=#!topic/linux.kernel/APKfoMzjgdY
Now, that project doesn't make the Postgres feature obsolete, because
there's nowhere to put checksum data for every block on ext4 without
whacking block alignment. The filesystem can't make an extra 32 bits
appear on every block any more than we can. It's using a similar trick
to the PG checksum feature, grabbing some empty space just for the
metadata then shoving the CRC32C into there. But the fact that this is
going on means that there are already Linux kernel modules built with
both software/hardware accelerated versions of the CRC32C function. And
the iSCSI/SCTP use cases means it's not out of the question this will
show up in other useful forms one day. Maybe two years from now, there
will be a common Linux library that autoconf can find to compute the CRC
for us--with hardware acceleration when available, in software if not.
The first of those ext4 links above even discusses the exact sort of
issue we're facing. The author wonders if the easiest way to proceed
for 16 bit checksums is to compute the CRC32C, then truncate it, simply
because CRC32C creation is so likely to get hardware help one day. I
think that logic doesn't really apply to the PostgreSQL case as strongly
though, as the timetime before we can expect a hardware accelerated
version to be available is much further off than a Linux kernel
developer's future.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Greg Stark <stark(at)mit(dot)edu> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 04:12:27 |
| Message-ID: | CAM-w4HPmofBAmQD83CkO8C+6DP5c3WvGrewzaJOHB7V98KXsNg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 6, 2013 at 11:04 PM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>> When we first talked about this feature for
>> 9.2, we were going to exclude hint bits from checksums, in order to
>> avoid this issue; what happened to that?
>
> I don't think anyone ever thought that was a particularly practical
> design. I certainly don't.
Really? I thought it was pretty much the consensus for a good while.
The main problem it ran into was that we kept turning up hint bits
that we didn't realize we had. Index line pointers turned out to have
hint bits, page headers have one, and so on. As long as it was just
the heap page per-tuple transaction hint bits it seemed plausible to
just skip them or move them all to a contiguous blocks. Once it
started to look like the checksumming code had to know about every
data structure on every page it seemed a bit daunting. But that wasn't
something we realized for quite a long time.
--
greg
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 04:17:12 |
| Message-ID: | 513814C8.9000204@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
TL;DR summary: on a system I thought was a fair middle of the road
server, pgbench tests are averaging about a 2% increase in WAL writes
and a 2% slowdown when I turn on checksums. There are a small number of
troublesome cases where that overhead rises to closer to 20%, an upper
limit that's shown up in a few tests aiming to stress this feature now.
On 3/4/13 10:09 PM, Jeff Davis wrote:
>> = Test 2 - worst-case overhead for calculating checksum while reading data =
>>
>> Jeff saw an 18% slowdown, I get 24 to 32%. This one bothers me because
>> the hit is going to happen during the very common situation where data
>> is shuffling a lot between a larger OS cache and shared_buffers taking a
>> relatively small fraction.
>
> I believe that test 1 and test 2 can be improved a little, if there is a
> need. Right now we copy the page and then calculate the checksum on the
> copy. If we instead calculate as we're copying, I believe it will make
> it significantly faster.
It's good to know there's at least some ideas for optimizing this one
further. I think the situation where someone has:
shared_buffers < database < total RAM
is fairly common for web applications. For people on Amazon EC2
instances for example, giving out the performance tuning advice of "get
a bigger instance until the database fits in RAM" works amazingly well.
If the hotspot of that data set fits in shared_buffers, those people
will still be in good shape even with checksums enabled. If the hot
working set is spread out more randomly, though, it's not impossible to
see how they could suffer regularly from this ~20% OS cache->shared
buffers movement penalty.
Regardless, Jeff's three cases are good synthetic exercises to see
worst-case behavior, but they are magnifying small differences. To see
a more general case, I ran through a series of pgbench tests in its
standard write mode. In order to be useful, I ended up using a system
with a battery-backed write cache, but with only a single drive
attached. I needed fsync to be fast to keep that from being the
bottleneck. But I wanted physical I/O to be slow. I ran three test
sets at various size/client loads: one without the BBWC (which I kept
here because it gives some useful scale to the graphs), one with the
baseline 9.3 code, and one with checksums enabled on the cluster. I did
only basic postgresql.conf tuning:
checkpoint_segments | 64
shared_buffers | 2GB
There's two graphs comparing sets attached, you can see that the
slowdown of checksums for this test is pretty minor. There is a clear
gap between the two plots, but it's not a very big one, especially if
you note how much difference a BBWC makes.
I put the numeric results into a spreadsheet, also attached. There's so
much noise in pgbench results that I found it hard to get a single
number for the difference; they bounce around about +/-5% here.
Averaging across everything gives a solid 2% drop when checksums are on
that looked detectable above the noise.
Things are worse on the bigger data sets. At the highest size I tested,
the drop was more like 7%. The two larger size / low client count
results I got were really bad, 25% and 16% drops. I think this is
closing in on the range of things: perhaps only 2% when most of your
data fits in shared_buffers, more like 10% if your database is bigger,
and in the worst case 20% is possible. I don't completely trust those
25/16% numbers though, I'm going to revisit that configuration.
The other thing I track now in pgbench-tools is how many bytes of WAL
are written. Since the total needs to be measured relative to work
accomplished, the derived number that looks useful there is "average
bytes of WAL per transaction". On smaller database this is around 6K,
while larger databases topped out for me at around 22K WAL
bytes/transaction. Remember that the pgbench transaction is several
statements. Updates touch different blocks in pgbench_accounts, index
blocks, and the small tables.
The WAL increase from checksumming is a bit more consistent than the TPS
rates. Many cases were 3 to 5%. There was one ugly case were it hit
30%, and I want to dig into where that came from more. On average,
again it was a 2% increase over the baseline.
Cases where you spew hint bit WAL data where before none were written
(Jeff's test #3) remain a far worst performer than any of these. Since
pgbench does a VACUUM before starting, none of those cases were
encountered here though.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
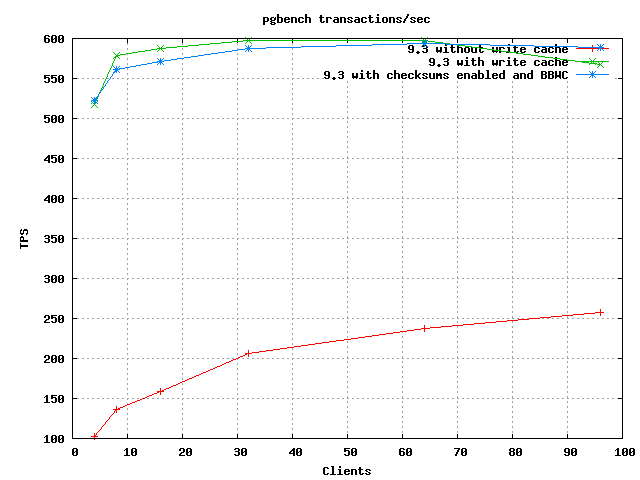
|
image/png | 5.3 KB |
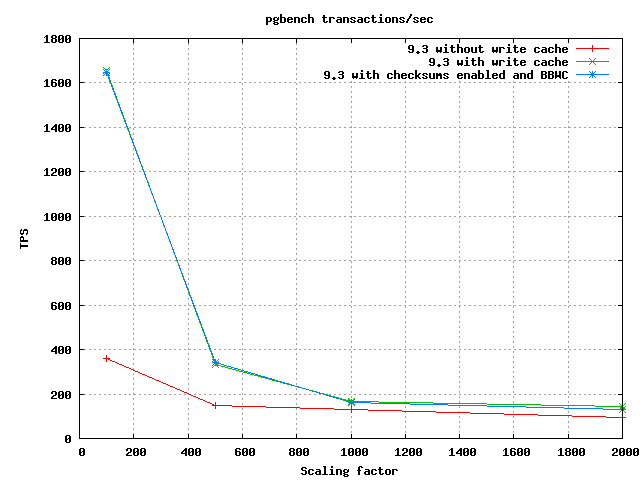
|
image/png | 5.6 KB |
| Checksum-pgbench.xls | application/vnd.ms-excel | 21.5 KB |
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 05:15:57 |
| Message-ID: | CAAZKuFazVrKnpNMy8zU-LuhjZ1=_YuxsV7sDzEwx1UzPM5sbjQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 6, 2013 at 8:17 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> TL;DR summary: on a system I thought was a fair middle of the road server,
> pgbench tests are averaging about a 2% increase in WAL writes and a 2%
> slowdown when I turn on checksums. There are a small number of troublesome
> cases where that overhead rises to closer to 20%, an upper limit that's
> shown up in a few tests aiming to stress this feature now.
I have only done some cursory research, but cpu-time of 20% seem to
expected for InnoDB's CRC computation[0]. Although a galling number,
this comparison with other systems may be a way to see how much of
that overhead is avoidable or just the price of entry. It's unclear
how this 20% cpu-time compares to your above whole-system results, but
it's enough to suggest that nothing comes for (nearly) free.
[0]: http://mysqlha.blogspot.com/2009/05/innodb-checksum-performance.html
--
fdr
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 06:07:17 |
| Message-ID: | 51382E95.1020407@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/7/13 12:15 AM, Daniel Farina wrote:
> I have only done some cursory research, but cpu-time of 20% seem to
> expected for InnoDB's CRC computation[0]. Although a galling number,
> this comparison with other systems may be a way to see how much of
> that overhead is avoidable or just the price of entry. It's unclear
> how this 20% cpu-time compares to your above whole-system results, but
> it's enough to suggest that nothing comes for (nearly) free.
That does provide a useful measuring point: how long does the
computation take compared to the memcpy that moves the buffer around.
It looks like they started out with 3.2 memcpy worth of work, and with
enough optimization ended up at 1.27 worth.
The important thing to keep in mind is that shared_buffers works pretty
well at holding on to the most frequently accessed information. A
typical server I see will show pg_statio information suggesting 90%+ of
block requests are coming from hits there, the rest misses suggesting a
mix of OS cache and real disk reads. Let's say 90% are hits, 5% are
fetches at this 20% penalty, and 5% are real reads where the checksum
time is trivial compared to physical disk I/O. That works out to be a
real average slowdown of 6%. I think way more deployments are going to
be like that case, which matches most of my pgbench runs, than the worse
case workloads.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-07 21:45:25 |
| Message-ID: | 1362692725.26602.113.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2013-03-05 at 11:35 +0200, Heikki Linnakangas wrote:
> If you enable checksums, the free space map never gets updated in a
> standby. It will slowly drift to be completely out of sync with reality,
> which could lead to significant slowdown and bloat after failover.
One of the design points of this patch is that those operations that use
MarkBufferDirtyHint(), including tuple hint bits, the FSM, index dead
markers, etc., do not directly go to the standby. That's because the
standby can't write WAL, so it can't protect itself against a torn page
breaking the checksum.
However, these do make it through by riding along with a full-page image
in the WAL. The fact that checksums are enabled means that these full
page images will be written once per modified page per checkpoint, and
then replayed on the standby. FSM should get the updates the same way,
even though no other WAL is written for the FSM.
If full_page_writes are disabled, then the updates will never arrive.
But in that case, I think we can just go ahead and dirty the page during
recovery, because there isn't a real problem. I was hesitant to make
this change in my patch because:
1. I wanted to see if someone saw a flaw in this reasoning; and
2. I noticed that full_page_images can be changed with a SIGHUP, which
could add complexity (I don't see any reason we allow this... shouldn't
we just force a restart for that change?).
I added a README file, moved some of the explanatory material there, and
tried to clarify this situation.
Let me know if you see a problem that I'm missing. I verified that at
least some FSM changes do make it through with checksums on, but I
didn't dig much deeper than that.
> Since the checksums are an all-or-nothing cluster-wide setting, the
> three extra flags in the page header, PD_CHECKSUMS1, PD_CHECKSUM2 and
> PD_HEADERCHECK, are not needed. Let's leave them out. That keeps the
> code simpler, and leaves the bits free for future use. If we want to
> enable such per-page setting in the future, we can add it later. For a
> per-relation scheme, they're not needed.
Removed header bits.
> XLogCheckBuffer() and XLogCheckBufferNeedsBackup() read the page LSN
> without a lock. That's not atomic, so it could incorrectly determine
> that a page doesn't need to be backed up. We used to always hold an
> exclusive lock on the buffer when it's called, which prevents
> modifications to the LSN, but that's no longer the case.
Fixed. I added a new exported function, BufferGetLSNAtomic().
There was another similar omission in gistget.c.
By the way, I can not find any trace of XLogCheckBufferNeedsBackup(),
was that a typo?
> Shouldn't SetBufferCommitInfoNeedsSave() check the BM_PERMANENT flag? I
> think it will generate WAL records for unlogged tables as it is.
Fixed.
I also rebased and added a GUC to control whether the checksum failure
causes an error or not.
I need to do another self-review after these changes and some more
extensive testing, so I might have missed a couple things.
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| checksums-20130307.patch.gz | application/x-gzip | 21.6 KB |
| replace-tli-with-checksums-20130307.patch.gz | application/x-gzip | 8.8 KB |
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-08 03:31:07 |
| Message-ID: | 20130308033107.GD25013@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 4, 2013 at 05:04:27PM -0800, Daniel Farina wrote:
> Putting aside the not-so-rosy predictions seen elsewhere in this
> thread about the availability of a high performance, reliable
> checksumming file system available on common platforms, I'd like to
> express what benefit this feature will have to me:
>
> Corruption has easily occupied more than one person-month of time last
> year for us. This year to date I've burned two weeks, although
> admittedly this was probably the result of statistical clustering.
> Other colleagues of mine have probably put in a week or two in
> aggregate in this year to date. The ability to quickly, accurately,
> and maybe at some later date proactively finding good backups to run
> WAL recovery from is one of the biggest strides we can make in the
> operation of Postgres. The especially ugly cases are where the page
> header is not corrupt, so full page images can carry along malformed
> tuples...basically, when the corruption works its way into the WAL,
> we're in much worse shape. Checksums would hopefully prevent this
> case, converting them into corrupt pages that will not be modified.
>
> It would be better yet if I could write tools to find the last-good
> version of pages, and so I think tight integration with Postgres will
> see a lot of benefits that would be quite difficult and non-portable
> when relying on file system checksumming.
I see Heroku has corruption experience, and I know Jim Nasby has
struggled with corruption in the past.
I also see the checksum patch is taking a beating. I wanted to step
back and ask what percentage of known corruptions cases will this
checksum patch detect? What percentage of these corruptions would
filesystem checksums have detected?
Also, don't all modern storage drives have built-in checksums, and
report problems to the system administrator? Does smartctl help report
storage corruption?
Let me take a guess at answering this --- we have several layers in a
database server:
1 storage
2 storage controller
3 file system
4 RAM
5 CPU
My guess is that storage checksums only cover layer 1, while our patch
covers layers 1-3, and probably not 4-5 because we only compute the
checksum on write.
If that is correct, the open question is what percentage of corruption
happens in layers 1-3?
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-08 06:07:19 |
| Message-ID: | CAFj8pRAcXKLXqsQvkZw8FFLNd2SSX0axgRGVmd1pczPO1ee2FQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2013/3/8 Bruce Momjian <bruce(at)momjian(dot)us>:
> On Mon, Mar 4, 2013 at 05:04:27PM -0800, Daniel Farina wrote:
>> Putting aside the not-so-rosy predictions seen elsewhere in this
>> thread about the availability of a high performance, reliable
>> checksumming file system available on common platforms, I'd like to
>> express what benefit this feature will have to me:
>>
>> Corruption has easily occupied more than one person-month of time last
>> year for us. This year to date I've burned two weeks, although
>> admittedly this was probably the result of statistical clustering.
>> Other colleagues of mine have probably put in a week or two in
>> aggregate in this year to date. The ability to quickly, accurately,
>> and maybe at some later date proactively finding good backups to run
>> WAL recovery from is one of the biggest strides we can make in the
>> operation of Postgres. The especially ugly cases are where the page
>> header is not corrupt, so full page images can carry along malformed
>> tuples...basically, when the corruption works its way into the WAL,
>> we're in much worse shape. Checksums would hopefully prevent this
>> case, converting them into corrupt pages that will not be modified.
>>
>> It would be better yet if I could write tools to find the last-good
>> version of pages, and so I think tight integration with Postgres will
>> see a lot of benefits that would be quite difficult and non-portable
>> when relying on file system checksumming.
>
> I see Heroku has corruption experience, and I know Jim Nasby has
> struggled with corruption in the past.
>
> I also see the checksum patch is taking a beating. I wanted to step
> back and ask what percentage of known corruptions cases will this
> checksum patch detect? What percentage of these corruptions would
> filesystem checksums have detected?
>
> Also, don't all modern storage drives have built-in checksums, and
> report problems to the system administrator? Does smartctl help report
> storage corruption?
>
> Let me take a guess at answering this --- we have several layers in a
> database server:
>
> 1 storage
> 2 storage controller
> 3 file system
> 4 RAM
> 5 CPU
>
> My guess is that storage checksums only cover layer 1, while our patch
> covers layers 1-3, and probably not 4-5 because we only compute the
> checksum on write.
>
> If that is correct, the open question is what percentage of corruption
> happens in layers 1-3?
I cooperate with important Czech bank - and they request checksum as
any other tool to increase a possibility to failure identification. So
missing checksums penalize a usability PostgreSQL to critical systems
- speed is not too important there.
Regards
Pavel
>
> --
> Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
> EnterpriseDB http://enterprisedb.com
>
> + It's impossible for everything to be true. +
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-08 06:35:45 |
| Message-ID: | CAAZKuFaby3ShuAxq7wiDCPUHoiEYjkO73LDufwdhpQ2MgTbSFQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Mar 7, 2013 at 7:31 PM, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> On Mon, Mar 4, 2013 at 05:04:27PM -0800, Daniel Farina wrote:
>> Putting aside the not-so-rosy predictions seen elsewhere in this
>> thread about the availability of a high performance, reliable
>> checksumming file system available on common platforms, I'd like to
>> express what benefit this feature will have to me:
>>
>> Corruption has easily occupied more than one person-month of time last
>> year for us. This year to date I've burned two weeks, although
>> admittedly this was probably the result of statistical clustering.
>> Other colleagues of mine have probably put in a week or two in
>> aggregate in this year to date. The ability to quickly, accurately,
>> and maybe at some later date proactively finding good backups to run
>> WAL recovery from is one of the biggest strides we can make in the
>> operation of Postgres. The especially ugly cases are where the page
>> header is not corrupt, so full page images can carry along malformed
>> tuples...basically, when the corruption works its way into the WAL,
>> we're in much worse shape. Checksums would hopefully prevent this
>> case, converting them into corrupt pages that will not be modified.
>>
>> It would be better yet if I could write tools to find the last-good
>> version of pages, and so I think tight integration with Postgres will
>> see a lot of benefits that would be quite difficult and non-portable
>> when relying on file system checksumming.
>
> I see Heroku has corruption experience, and I know Jim Nasby has
> struggled with corruption in the past.
More than a little: it has entered the realm of the routine, and
happens frequently enough that it has become worthwhile to start
looking for patterns.
Our methods so far rely heavily on our archives to deal with it: it's
time consuming but the 'simple' case of replaying WAL from some
earlier base backup resulting in a non-corrupt database is easily the
most common. Interestingly, the WAL has never failed to recover
halfway through because of CRC failures while treating corruption[0].
We know this fairly convincingly because we constantly sample txid and
wal positions while checking the database, as we typically do about
every thirty seconds.
I think this unreasonable effectiveness of this strategy of old backup
and WAL replay might suggest that database checksums would prove
useful. In my mind, the ways this formula could work so well if the
bug was RAM or CPU based is slimmed considerably.
[0] I have seen -- very rarely -- substantial periods of severe WAL
corruption (files are not even remotely the correct size) propagated
to the archives in the case of disaster recovery where the machine met
its end because of the WAL disk being marked as dead.
--
fdr
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-08 08:38:15 |
| Message-ID: | 5139A377.1040905@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 08.03.2013 05:31, Bruce Momjian wrote:
> Also, don't all modern storage drives have built-in checksums, and
> report problems to the system administrator? Does smartctl help report
> storage corruption?
>
> Let me take a guess at answering this --- we have several layers in a
> database server:
>
> 1 storage
> 2 storage controller
> 3 file system
> 4 RAM
> 5 CPU
>
> My guess is that storage checksums only cover layer 1, while our patch
> covers layers 1-3, and probably not 4-5 because we only compute the
> checksum on write.
There is a thing called "Data Integrity Field" and/or "Data Integrity
Extensions", that allow storing a checksum with each disk sector, and
verifying the checksum in each layer. The basic idea is that instead of
512 byte sectors, the drive is formatted to use 520 byte sectors, with
the extra 8 bytes used for the checksum and some other metadata. That
gets around the problem we have in PostgreSQL, and that filesystems
have, which is that you need to store the checksum somewhere along with
the data.
When a write I/O request is made in the OS, the OS calculates the
checksum and passes it to through the controller to the drive. The drive
verifies the checksum, and aborts the I/O request if it doesn't match.
On a read, the checksum is read from the drive along with the actual
data, passed through the controller, and the OS verifies it. This covers
layers 1-2 or 1-3.
Now, this requires all the components to have support for that. I'm not
an expert on these things, but I'd guess that that's a tall order today.
I don't know which hardware vendors and kernel versions support that.
But things usually keep improving, and hopefully in a few years, you can
easily buy a hardware stack that supports DIF all the way through.
In theory, the OS could also expose the DIF field to the application, so
that you get end-to-end protection from the application to the disk.
This means that the application somehow gets access to those extra bytes
in each sector, and you have to calculate and verify the checksum in the
application. There are no standard APIs for that yet, though.
See https://www.kernel.org/doc/Documentation/block/data-integrity.txt.
- Heikki
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-08 09:11:49 |
| Message-ID: | 5139AB55.6000404@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 07.03.2013 23:45, Jeff Davis wrote:
> By the way, I can not find any trace of XLogCheckBufferNeedsBackup(),
> was that a typo?
Ah, sorry, that was a new function introduced by another patch I was
reviewing at the same time, and I conflated the two.
- Heikki
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-08 17:46:25 |
| Message-ID: | 513A23F1.2040200@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> I also see the checksum patch is taking a beating. I wanted to step
> back and ask what pertntage of known corruptions cases will this
> checksum patch detect?
I'm pretty sure that early on Jeff posted some statstics which indicated
that the current approach would detect 99% of corruption introduced at
the PostgreSQL, filesystem, or storage layer, and a significant but
minority amount of the corruption introduced through bad RAM (this is
harder to detect, and FS checksums don't catch it either).
> What percentage of these corruptions would
> filesystem checksums have detected?
In what way is that relevant? Given that there were already a couple
dozen posts establishing that FS checksums are not adequate, please
don't bring this up again.
> Also, don't all modern storage drives have built-in checksums, and
> report problems to the system administrator? Does smartctl help report
> storage corruption?
To date, there are no useful tools which would detect user-level file
corruption using these. Not that there couldn't theoretically be, but
such tools appearing in "enterprise" OSes is at least several years away.
> Let me take a guess at answering this --- we have several layers in a
> database server:
>
> 1 storage
> 2 storage controller
> 3 file system
> 4 RAM
> 5 CPU
>
> My guess is that storage checksums only cover layer 1, while our patch
> covers layers 1-3, and probably not 4-5 because we only compute the
> checksum on write.
You're forgetting two other major causes:
* PostgreSQL bugs
* operator error
>
> If that is correct, the open question is what percentage of corruption
> happens in layers 1-3?
The majority. I don't know that anyone has done an industry survey to
determine this, but out of the cases of Postgres corruption we've had to
deal with for clients, only one was the result of bad RAM. I have never
seen corruption caused by a CPU bug. The rest have been caused by:
* operator error
* postgres bugs
* bad controller/driver
* bad disk
* filesystem bug
Further, the solution for bad RAM is fairly easy: use ECC RAM, and make
sure that the syslog goes to some real person. ECC RAM is pretty good
at detecting its own errors.
There's also another use case people have not been discussing, which is
the "technical validation" use case. Give you an example:
We had a client who had a server device running on FreeBSD/UFS. In
2009, they upgraded the device spec, including new storage and a new
version of PostgreSQL. Their customers began filing corruption bug reports.
After some examination of the systems involved, we conculded that the
issue was the FreeBSD drivers for the new storage, which were unstable
and had custom source patches. However, without PostgreSQL checksums,
we couldn't *prove* it wasn't PostgreSQL at fault. It ended up taking
weeks of testing, most of which was useless, to prove to them they had a
driver problem so it could be fixed. If Postgres had had checksums, we
could have avoided wasting a couple weeks looking for non-existant
PostgreSQL bugs.
In any large enterprise with dozens to hundreds of PostgreSQL servers,
PostgreSQL, the OS/FS, and the hardware are going to be run by 3
different teams. When corruption occurs, the DBAs need to be able to
demonstrate that the corruption is not in the DBMS, in order to get the
other teams to hunt corruption bugs on their own layers.
Also, I'm kinda embarassed that, at this point, InnoDB has checksums and
we don't. :-(
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Greg Stark <stark(at)mit(dot)edu> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-09 00:40:26 |
| Message-ID: | CAM-w4HN38U8c=taT10y=d9B_8DXuuYSy+prEe0z6+n0q-tCCuw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Mar 8, 2013 at 5:46 PM, Josh Berkus <josh(at)agliodbs(dot)com> wrote:
> After some examination of the systems involved, we conculded that the
> issue was the FreeBSD drivers for the new storage, which were unstable
> and had custom source patches. However, without PostgreSQL checksums,
> we couldn't *prove* it wasn't PostgreSQL at fault. It ended up taking
> weeks of testing, most of which was useless, to prove to them they had a
> driver problem so it could be fixed. If Postgres had had checksums, we
> could have avoided wasting a couple weeks looking for non-existant
> PostgreSQL bugs.
How would Postgres checksums have proven that?
A checksum failure just means *something* has gone wrong. it could
still be Postgres that's done it. In fact I would hazard that checksum
failures would be the way most Postgres bugs will be found at some
point.
> Also, I'm kinda embarassed that, at this point, InnoDB has checksums and
> we don't. :-(
As much as it sounds silly I think this is a valid argument. Not just
InnoDB but Oracle and other database and even other storage software.
I think even if the patch doesn't get accepted this go around it'll be
in the next release. Either we'll think of solutions for some of the
performance bottlenecks, we'll iron out the transition so you can turn
it off and on freely, or we'll just realize that people are running
with the patch and life is ok even with these problems.
If i understand the performance issues right the main problem is the
extra round trip to the wal log which can require a sync. Is that
right? That seems like a deal breaker to me. I would think an 0-10%
i/o bandwidth or cpu bandwidth penalty would be acceptable but an
extra rotational latency even just on some transactions would be a
real killer.
--
greg
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-09 01:32:01 |
| Message-ID: | 513A9111.1050305@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/8/13 3:38 AM, Heikki Linnakangas wrote:
> See https://www.kernel.org/doc/Documentation/block/data-integrity.txt
That includes an interesting comment that's along the lines of the MySQL
checksum tests already mentioned:
"The 16-bit CRC checksum mandated by both the SCSI and SATA specs
is somewhat heavy to compute in software. Benchmarks found that
calculating this checksum had a significant impact on system
performance for a number of workloads. Some controllers allow a
lighter-weight checksum to be used when interfacing with the operating
system. Emulex, for instance, supports the TCP/IP checksum instead."
The TCP/IP checksum spec is at https://tools.ietf.org/html/rfc793 ; its
error detection limitations are described at
http://www.noahdavids.org/self_published/CRC_and_checksum.html ; and a
good article about optimizing its code is at
http://www.locklessinc.com/articles/tcp_checksum/ I'll take a longer
look at whether it's an improvement on the Fletcher-16 used by the
current patch. All of these 16 bit checksums are so much better than
nothing. I don't think some shift toward prioritizing computation speed
over detection rate is a problem. In the long run really sensitive 32
bit checksums will become more practical.
As Heikki pointed out, the direction this whole area seems to be going
is that one day you might get checksums all the way from application to
hardware. That's another possible future where having some field tested
checksum feature in the database will be valuable.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-09 16:04:49 |
| Message-ID: | CA+U5nMJezD73T7YRon=k1Gq1drbnuRMXNWAQJ=hxaOwOb8_Kpw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 8 March 2013 03:31, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> I also see the checksum patch is taking a beating. I wanted to step
> back and ask what percentage of known corruptions cases will this
> checksum patch detect? What percentage of these corruptions would
> filesystem checksums have detected?
>
> Also, don't all modern storage drives have built-in checksums, and
> report problems to the system administrator? Does smartctl help report
> storage corruption?
>
> Let me take a guess at answering this --- we have several layers in a
> database server:
>
> 1 storage
> 2 storage controller
> 3 file system
> 4 RAM
> 5 CPU
>
> My guess is that storage checksums only cover layer 1, while our patch
> covers layers 1-3, and probably not 4-5 because we only compute the
> checksum on write.
>
> If that is correct, the open question is what percentage of corruption
> happens in layers 1-3?
Yes, checksums patch is taking a beating, and so it should. If we find
a reason to reject, we should.
CPU and RAM error checking are pretty standard now. Storage isn't
necessarily the same. The figures we had from the Google paper early
in development showed it was worth checksumming storage, but not
memory. I did originally argue for memory also, but there was
insufficient evidence of utility.
At the moment, we only reject blocks if the header is damaged. That
covers basic sanity checks on about 10 bytes near the start of every
block. Given that some errors might still be allowed through, lets say
that covers just 8 bytes of the block. Checksums cover the whole block
and detect most errors, >99.999%. Which means that we will detect
errors on 8192 bytes of the block. Which means that checksums are
approximately 1000 times better at spotting corruption than not using
them. Or put it another way, if you don't use checksums, by the time
you see a single corrupt block header you will on average have lost
about 500 blocks/4MB of user data. That doesn't sound too bad, but if
your database has been giving wrong answers during the period those
blocks went bad, you could be looking at a significant number of
reads/writes gone bad, since updates would spread corruption to other
rows and data would be retrieved incorrectly over a long period.
I agree with Robert's comments. This isn't a brilliant design, its a
brilliant stop-gap until we get a better design. However, that is a
whole chunk of work away, with pg_upgrade handling on-disk page
rewrites, plus some as yet undecided redesign of the way hint bits
work. It's a long way off.
There are performance wrinkles also, no question. For some
applications, not losing data is worth the hit.
Given the patch offers choice to users, I think its acceptable to look
towards committing it.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-13 06:33:04 |
| Message-ID: | 1363156384.29942.8.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 2013-03-07 at 13:45 -0800, Jeff Davis wrote:
> I need to do another self-review after these changes and some more
> extensive testing, so I might have missed a couple things.
New patch attached.
Aside from rebasing, I also found a problem with temp tables. At first I
was going to fix it by continuing to exclude temp tables from checksums
entirely. But then I re-thought it and decided to just checksum temp
tables, too.
Excluding temp tables from checksums means more special cases in the
code, and more documentation. After thinking about it, there is no huge
benefit to excluding temp tables:
* small temp tables will be in memory only, and never checksummed
* no WAL for temp tables, so the biggest cost of checksums is
non-existent
* there are good reasons to want to checksum temp tables, because they
can be used to stage data for permanent tables
However, I'm willing to be convinced to exclude temp tables again.
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| checksums-20130312.patch.gz | application/x-gzip | 22.0 KB |
| replace-tli-with-checksums-20130312.patch.gz | application/x-gzip | 8.9 KB |
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-13 17:09:45 |
| Message-ID: | 5140B2D9.2050608@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff,
> However, I'm willing to be convinced to exclude temp tables again.
>
Those reasons sound persuasive. Let's leave them in for 9.3.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-13 22:24:54 |
| Message-ID: | 5140FCB6.5020709@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/7/13 9:31 PM, Bruce Momjian wrote:
> 1 storage
> 2 storage controller
> 3 file system
> 4 RAM
> 5 CPU
I would add 2.5 in there: storage interconnect. iSCSI, FC, what-have-you. Obviously not everyone has that.
> My guess is that storage checksums only cover layer 1, while our patch
> covers layers 1-3, and probably not 4-5 because we only compute the
> checksum on write.
Actually, it depends. In our case, we run 512GB servers and 8GB shared buffers (previous testing has shown that anything much bigger than 8G hurts performance).
So in our case, PG checksums protect a very significant portion of #4.
> If that is correct, the open question is what percentage of corruption
> happens in layers 1-3?
The last bout of corruption we had was entirely coincident with memory failures. IIRC we had 3-4 corruption events on more than one server. Everything was running standard ECC (sadly, not 4-bit ECC).
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-15 12:32:57 |
| Message-ID: | CA+CSw_tpKCxj31nmm6xesyA78zaAYWsrJQRGVVE6imLzLy+ApA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 6, 2013 at 1:34 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> Fletcher's checksum is good in general, I was mainly worried about
> truncating the Fletcher-64 into two 8-bit values. I can't spot any obvious
> weakness in it, but if it's indeed faster and as good as a straightforward
> Fletcher-16, I wonder why that method is not more widely used.
As implented, the fletcher algorithm as implemented results in:
checksum low byte = (blkno + sum over i [0..N) (x_i)) % 255 + 1
checksum high byte = (blkno + sum over i in [0..N) ((N - i)*x_i)) % 255 + 1
Where N is the number of 4 bytes words in the page and x_i is the i-th
word. As modular arithmetic is a ring, it is easy to show that any
addition or subtraction of a multiple of 255 = 0xFF will result in no
change to the resulting value. The most obvious case here is that you
can swap any number of bytes from 0x00 to 0xFF or back without
affecting the hash.
> Another thought is that perhaps something like CRC32C would be faster to
> calculate on modern hardware, and could be safely truncated to 16-bits using
> the same technique you're using to truncate the Fletcher's Checksum. Greg's
> tests showed that the overhead of CRC calculation is significant in some
> workloads, so it would be good to spend some time to optimize that. It'd be
> difficult to change the algorithm in a future release without breaking
> on-disk compatibility, so let's make sure we pick the best one.
I took a look at how the fletcher-64 compiles. It's a very tight loop
of 1 mov, 3 adds and a cmp/jne. Guestimating the performance on a
modern CPU, if the buffer is still in L1, I would expect this to run
at about 2 bytes/cycle depending on actual scheduling efficiency. Peak
execution unit capacity would results in 4/3 cycles per 4 bytes or 3
bytes/cycle. Coincidentally 2 bytes/cycle would result in about 20%
overhead for ReadBuffer on my machine - close to the overall overhead
measured.
Best case using the CRC32 instruction would be 6.8 bytes/cycle [1].
But this got me thinking about how to do this faster. It seems to me
that the fastest approach would be to accumulate many checksums in
parallel and combine in the end to take advantage of vector
instructions. A quick look at vector instructions and their
throughputs and latencies shows that best bet would be to use the
common (hash = hash*prime + value) mechanism with 16bit values. For
processors made in the last 5 years, accumulating atleast 64 16bit
checksums in parallel would be required to achieve optimal throughput
(3-5 cycle latency for pmullw, 1 cycle for paddw with parallel issue
capability, total 6 cycles * 8 values per vector, rounding up to next
power of two). By unrolling the inner loop, this should be able to run
at a throughput of 1 cycle per 16byte vector on all recent x86's, the
necessary vector instructions are available on all x86-64 CPUs.
I was able to coax GCC to vectorize the code in the attached patch (on
top of checksums-20130312.patch.gz) by adding -ftree-vectorize and
-funroll-loops. But for some silly reason GCC insists on storing the
intermediate values on to stack on each iteration negating any
possible performance benefit. If anyone thinks this avenue is worth
further investigation and would like to do performance tests, I can
whip together a manual asm implementation.
I'm not really sure if parallel checksums would be worth doing or not.
On one hand, enabling data parallelism would make it more future
proof, on the other hand, the unvectorized variant is slower than
Fletcher-64.
On another note, I think I found a bug with the current latest patch.
for (i = SizeOfPageHeaderData; i < BLCKSZ / sizeof(uint32); i++)
should probably be
for (i = SizeOfPageHeaderData / sizeof(uint32); i < BLCKSZ /
sizeof(uint32); i++)
[1] http://www.drdobbs.com/parallel/fast-parallelized-crc-computation-using/229401411
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-15 12:34:51 |
| Message-ID: | CA+CSw_u4RjsfRSGPR1NDMZmKM391y7jvG3LAuvnsaJtkywL=-w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Mar 15, 2013 at 2:32 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> I was able to coax GCC to vectorize the code in the attached patch
Now actually attached.
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| parallel-checksum.patch | application/octet-stream | 5.6 KB |
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-15 13:08:45 |
| Message-ID: | 20130315130845.GC21834@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-03-15 14:32:57 +0200, Ants Aasma wrote:
> On Wed, Mar 6, 2013 at 1:34 PM, Heikki Linnakangas
> <hlinnakangas(at)vmware(dot)com> wrote:
> > Fletcher's checksum is good in general, I was mainly worried about
> > truncating the Fletcher-64 into two 8-bit values. I can't spot any obvious
> > weakness in it, but if it's indeed faster and as good as a straightforward
> > Fletcher-16, I wonder why that method is not more widely used.
>
> As implented, the fletcher algorithm as implemented results in:
>
> checksum low byte = (blkno + sum over i [0..N) (x_i)) % 255 + 1
> checksum high byte = (blkno + sum over i in [0..N) ((N - i)*x_i)) % 255 + 1
>
> Where N is the number of 4 bytes words in the page and x_i is the i-th
> word. As modular arithmetic is a ring, it is easy to show that any
> addition or subtraction of a multiple of 255 = 0xFF will result in no
> change to the resulting value. The most obvious case here is that you
> can swap any number of bytes from 0x00 to 0xFF or back without
> affecting the hash.
I commented on this before, I personally think this property makes fletcher a
not so good fit for this. Its not uncommon for parts of a block being all-zero
and many disk corruptions actually change whole runs of bytes.
We could try to mess with this by doing an unsigned addition for each byte we
checksum. Increment the first byte by 0, the second one by 1, ... and then wrap
around at 254 again. That would allow us to detect changes of multiple bytes
that swap from all-zero to all-ones or viceversa.
I think we should just try to use some polynom of CRC32 and try to get that
fast though.
Even without taking advantage of vectorization and such you can get a good,
good bit faster than our current
implementation. E.g. http://archives.postgresql.org/message-id/201005202227.49990.andres%40anarazel.de
I still think changing the polynom to Castagnoli makes sense... Both from a
performance and from an error detection perspective.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-16 21:02:44 |
| Message-ID: | CA+U5nMLVN_M9ReFZPM1O9jZ6QX=f5h4-jG14MHX3ax5ZWiB=9w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 15 March 2013 13:08, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> On 2013-03-15 14:32:57 +0200, Ants Aasma wrote:
>> On Wed, Mar 6, 2013 at 1:34 PM, Heikki Linnakangas
>> <hlinnakangas(at)vmware(dot)com> wrote:
>> > Fletcher's checksum is good in general, I was mainly worried about
>> > truncating the Fletcher-64 into two 8-bit values. I can't spot any obvious
>> > weakness in it, but if it's indeed faster and as good as a straightforward
>> > Fletcher-16, I wonder why that method is not more widely used.
>>
>> As implented, the fletcher algorithm as implemented results in:
>>
>> checksum low byte = (blkno + sum over i [0..N) (x_i)) % 255 + 1
>> checksum high byte = (blkno + sum over i in [0..N) ((N - i)*x_i)) % 255 + 1
>>
>> Where N is the number of 4 bytes words in the page and x_i is the i-th
>> word. As modular arithmetic is a ring, it is easy to show that any
>> addition or subtraction of a multiple of 255 = 0xFF will result in no
>> change to the resulting value. The most obvious case here is that you
>> can swap any number of bytes from 0x00 to 0xFF or back without
>> affecting the hash.
>
> I commented on this before, I personally think this property makes fletcher a
> not so good fit for this. Its not uncommon for parts of a block being all-zero
> and many disk corruptions actually change whole runs of bytes.
I think you're right to pick up on this point, and Ants has done a
great job of explaining the issue more clearly.
My perspective, after some thought, is that this doesn't matter to the
overall effectiveness of this feature.
PG blocks do have large runs of 0x00 in them, though that is in the
hole in the centre of the block. If we don't detect problems there,
its not such a big deal. Most other data we store doesn't consist of
large runs of 0x00 or 0xFF as data. Most data is more complex than
that, so any runs of 0s or 1s written to the block will be detected.
So what we need to look at is how that problem affects the quality of
our detection. I would guess we can say that our detection might only
be 99% effective, rather than 100% effective. I'm not sure the issue
is that bad, but lets look at what would happen if it was that value.
Checksums are for detecting problems. What kind of problems? Sporadic
changes of bits? Or repeated errors. If we were trying to trap
isolated bit changes then CRC-32 would be appropriate. But I'm
assuming that whatever causes the problem is going to recur, so what
we want to do is detect hardware that is starting to go bad and needs
to be replaced. So errors show a repetitive pattern, increasing in
frequency and coverage over time; and "issue" is not an isolated
incident, its the beginning of a series of related problems. This much
the same as the idea that for every mouse you see in your house there
are another 10 you don't, and if you ignore the sighting of a mouse,
the problem will get worse, often quickly. What we want to do is
detect infestations/mouse colonies, rather than detect isolated and
non-repeated visitors.
Running checksums on the whole block gives us about x1000 better
chance of detecting a run of issues than we have with just header
checks. The perfection of the actual check, 99%/100%, doesn't alter
much the overall *gain* in detection rate we get from using checksums,
and so I can say its less important that the check itself is
watertight. And in fact, no checksum is watertight, it is a technique
that trades performance for detection quality. So even a detector that
spotted only 90% of real errors would still be a massive gain in
overall detection, because we are applying the check across the whole
block.
What we need is a cheap way of detecting problems as early as
possible. Checksums don't prevent disk corruption, they just alert us
to the presence of disk corruption, allowing us to avoid data
corruption by reverting to backups. If we don't detect things early
enough, then we find that reverting to backup doesn't work because the
backed-up data blocks are corrupt. Fletcher-16 seems to be the best
combination of speed v quality.
What I think we could do here is to allow people to set their checksum
algorithm with a plugin. But if we do that, then we open up the
possibility for user error on people changing checksum algorithms and
not realising that won't change values already calculated. That would
be a bad usability problem in itself and is almost certain to bite,
since user error is a larger source of real world problems than
hardware error. So I'd rather not do that.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Andres Freund <andres(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-17 00:41:07 |
| Message-ID: | 14584.1363480867@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Simon Riggs <simon(at)2ndQuadrant(dot)com> writes:
> On 15 March 2013 13:08, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
>> I commented on this before, I personally think this property makes fletcher a
>> not so good fit for this. Its not uncommon for parts of a block being all-zero
>> and many disk corruptions actually change whole runs of bytes.
> I think you're right to pick up on this point, and Ants has done a
> great job of explaining the issue more clearly.
> My perspective, after some thought, is that this doesn't matter to the
> overall effectiveness of this feature.
> PG blocks do have large runs of 0x00 in them, though that is in the
> hole in the centre of the block. If we don't detect problems there,
> its not such a big deal. Most other data we store doesn't consist of
> large runs of 0x00 or 0xFF as data. Most data is more complex than
> that, so any runs of 0s or 1s written to the block will be detected.
Meh. I don't think that argument holds a lot of water. The point of
having checksums is not so much to notice corruption as to be able to
point the finger at flaky hardware. If we have an 8K page with only
1K of data in it, and we fail to notice that the hardware dropped a lot
of bits in the other 7K, we're not doing our job; and that's not really
something to write off, because it would be a lot better if we complain
*before* the hardware manages to corrupt something valuable.
So I think we'd be best off to pick an algorithm whose failure modes
don't line up so nicely with probable hardware failure modes. It's
worth noting that one of the reasons that CRCs are so popular is
precisely that they were designed to detect burst errors with high
probability.
> What I think we could do here is to allow people to set their checksum
> algorithm with a plugin.
Please, no. What happens when their plugin goes missing? Or they
install the wrong one on their multi-terabyte database? This feature is
already on the hairy edge of being impossible to manage; we do *not*
need to add still more complication.
regards, tom lane
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-17 20:41:40 |
| Message-ID: | CA+U5nMLwTzbL=rCF5UMatjA9529StyOosL+c3KcSAde6bW_GRQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17 March 2013 00:41, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Simon Riggs <simon(at)2ndQuadrant(dot)com> writes:
>> On 15 March 2013 13:08, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
>>> I commented on this before, I personally think this property makes fletcher a
>>> not so good fit for this. Its not uncommon for parts of a block being all-zero
>>> and many disk corruptions actually change whole runs of bytes.
>
>> I think you're right to pick up on this point, and Ants has done a
>> great job of explaining the issue more clearly.
>
>> My perspective, after some thought, is that this doesn't matter to the
>> overall effectiveness of this feature.
>
>> PG blocks do have large runs of 0x00 in them, though that is in the
>> hole in the centre of the block. If we don't detect problems there,
>> its not such a big deal. Most other data we store doesn't consist of
>> large runs of 0x00 or 0xFF as data. Most data is more complex than
>> that, so any runs of 0s or 1s written to the block will be detected.
>
> Meh. I don't think that argument holds a lot of water. The point of
> having checksums is not so much to notice corruption as to be able to
> point the finger at flaky hardware. If we have an 8K page with only
> 1K of data in it, and we fail to notice that the hardware dropped a lot
> of bits in the other 7K, we're not doing our job; and that's not really
> something to write off, because it would be a lot better if we complain
> *before* the hardware manages to corrupt something valuable.
>
> So I think we'd be best off to pick an algorithm whose failure modes
> don't line up so nicely with probable hardware failure modes. It's
> worth noting that one of the reasons that CRCs are so popular is
> precisely that they were designed to detect burst errors with high
> probability.
I think that's a reasonable refutation of my argument, so I will
relent, especially since nobody's +1'd me.
>> What I think we could do here is to allow people to set their checksum
>> algorithm with a plugin.
>
> Please, no. What happens when their plugin goes missing? Or they
> install the wrong one on their multi-terabyte database? This feature is
> already on the hairy edge of being impossible to manage; we do *not*
> need to add still more complication.
Agreed. (And thanks for saying please!)
So I'm now moving towards commit using a CRC algorithm. I'll put in a
feature to allow algorithm be selected at initdb time, though that is
mainly a convenience to allow us to more easily do further testing on
speedups and whether there are any platform specific regressions
there.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-17 20:45:31 |
| Message-ID: | CA+U5nMKtjP3kL3PD=fEwzSgxSaBFVFY0eqLSHq+rpadUWKa2SQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 13 March 2013 06:33, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Thu, 2013-03-07 at 13:45 -0800, Jeff Davis wrote:
>> I need to do another self-review after these changes and some more
>> extensive testing, so I might have missed a couple things.
>
> New patch attached.
>
> Aside from rebasing, I also found a problem with temp tables. At first I
> was going to fix it by continuing to exclude temp tables from checksums
> entirely. But then I re-thought it and decided to just checksum temp
> tables, too.
>
> Excluding temp tables from checksums means more special cases in the
> code, and more documentation. After thinking about it, there is no huge
> benefit to excluding temp tables:
> * small temp tables will be in memory only, and never checksummed
> * no WAL for temp tables, so the biggest cost of checksums is
> non-existent
> * there are good reasons to want to checksum temp tables, because they
> can be used to stage data for permanent tables
>
> However, I'm willing to be convinced to exclude temp tables again.
I'm convinced we must include temp tables. No point putting a lock on
the front door if there's a back door still open.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 00:04:29 |
| Message-ID: | 51465A0D.4050108@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/15/13 5:32 AM, Ants Aasma wrote:
> Best case using the CRC32 instruction would be 6.8 bytes/cycle [1].
> But this got me thinking about how to do this faster...
> [1] http://www.drdobbs.com/parallel/fast-parallelized-crc-computation-using/229401411
The optimization work you went through here looked very nice.
Unfortunately, a few things seem pushing toward using a CRC16 instead of
the Fletcher approach. It seems possible to execute a CRC16 in a
reasonable enough time, in the same neighborhood as the Fletcher one.
And there is some hope that hardware acceleration for CRCs will be
available in a system API/compiler feature one day, making them even
cheaper.
Ants, do you think you could take a similar look at optimizing a CRC16
calculation? I'm back to where I can do a full performance comparison
run again starting tomorrow, with the latest version of this patch, and
I'd like to do that with a CRC16 implementation or two. I'm not sure if
it's possible to get a quicker implementation because the target is a
CRC16, or whether it's useful to consider truncating a CRC32 into a CRC16.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 00:50:11 |
| Message-ID: | 514664C3.9080404@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/17/13 1:41 PM, Simon Riggs wrote:
> So I'm now moving towards commit using a CRC algorithm. I'll put in a
> feature to allow algorithm be selected at initdb time, though that is
> mainly a convenience to allow us to more easily do further testing on
> speedups and whether there are any platform specific regressions
> there.
That sounds reasonable. As I just posted, I'm hoping Ants can help make
a pass over a CRC16 version, since his one on the Fletcher one seemed
very productive. If you're spending time looking at this, I know I'd
prefer to see you poking at the WAL related aspects instead. There are
more of us who are capable of crunching CRC code than the list of people
who have practice at WAL changes like you do.
I see the situation with checksums right now as being similar to the
commit/postpone situation for Hot Standby in 9.0. The code is uglier
and surely buggier than we'd like, but it has been getting beat on
regularly for over a year now to knock problems out. There are surely
more bugs left to find. The improved testing that comes only from
something being committed is probably necessary to really advance the
testing coverage though. But with adopting the feature being a strict
opt-in, the bug rate for non-adopters isn't that broad. All the TLI
rearrangements is a lot of the patch, but that's pretty mechanical work
that doesn't seem that risky.
There was one question that kepts coming up in person this week (Simon,
Jeff, Daniel, Josh Berkus, and myself were all in the same place for a
few days) that I wanted to address with some thoughts on-list. Given
that the current overhead is right on the edge of being acceptable, the
concern is whether committing this will lock the project into a
permanent problem that can't be improved later. I think it's
manageable, though. Here's how I interpret the data we have:
-The checksum has to change from Fletcher 16 to CRC-16. The "hairy"
parts of the feature don't change very much from that though. I see
exactly which checksum is produced is a pretty small detail, from a code
correctness perspective. It's not like this will be starting over the
testing cycle completely. The performance change should be quantified
though.
-Some common workloads will show no performance drop, like things that
fit into shared_buffers and don't write hint bits.
-Some common workloads that write things seem to hit about a 2% drop,
presumably because they hit one of the slower situations around 10% of
the time.
-There are a decent number of hard to deal with workloads that have
shared_buffers <-> OS cache thrashing, and any approach here will
regularly hit them with around a 20% drop. There's some hope that this
will improve later, especially if a CRC is used and later versions can
pick up the Intel i7 CRC32 hardware acceleration. The magnitude of this
overhead doesn't seem too negotiable though. We've heard enough
comparisons with other people's implementations now to see that's near
the best anyone does here. If the weird slowdowns some people report
with very large values of shared_buffers is fixed, that will make this
situation better. That's on my hit list of things I really want to see
sorted in the next release.
-The worst of the worst case behavior is Jeff's "SELECTs now write a WAL
logged hint bit now" test, which can easily exceed a 20% drop. There
have been lots of features submitted in the last two releases that try
to improve hint bit operations. Some of those didn't show enough of a
win to be worth the trouble. It may be the case, though, that in a
checksummed environment those wins are suddenly big enough to matter.
If any of those go in later, the worst case for checksums could then
improve too. Having to test both ways, with and without checksums,
complicates the performance testing. But the project has to start
adopting a better approach to that in the next year regardless IMHO, and
I'm scheduling time to help as much as I can with it. (That's a whole
other discussion)
-Having COPY FREEZE available now is a useful tool to eliminate a lot of
the load/expensive hint bit write scenarios I know exist in the real
world. I think the docs for checksumming should even highlight that
synergy.
As long as the feature is off by default, so that people have to turn it
on to hit the biggest changed code paths, the exposure to potential bugs
doesn't seem too bad. New WAL data is no fun, but it's not like this
hasn't happened before.
For version <9.3+1>, there's a decent sized list of potential
performance improvements that seem possible. I don't see any reason to
believe committing a CRC16 based version of this will lock the
implementation into a bad form that can't be optimized later. The
comparison with Hot Standby again seems apt again here. There was a
decent list of rough edges that were hit by early 9.0 adopters only when
they turned the feature on. Then many were improved in 9.1.
Checksumming seems it could follow the same path. Committed for 9.3,
improvements expected during <9.3+1> work, generally considered well
tested by the release of <9.3+1>.
On the testing front, we've seen on-list interest in this feature from
companies like Heroku and Enova, who both have some resources and
practice to help testing too. Heroku can spin up test instances with
workloads any number of ways. Enova can make a Londiste standby with
checksums turned on to hit it with a logical replicated workload, while
the master stays un-checksummed.
If this goes in, I fully intent to hold both companies to hitting the
feature with as many workloads as they can help generate during (and
beyond) beta. I have my own stress tests I'll keep running too. If the
bug rate from the beta adopters is bad and doesn't improve, there's is
always the uncomfortable possibility of reverting it before the first RC.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 05:26:08 |
| Message-ID: | CAAZKuFaX_TY-J5kwrR8jicr5NnBLQnAZHuem-HczaG1fc9JP9A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Mar 17, 2013 at 5:50 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On the testing front, we've seen on-list interest in this feature from
> companies like Heroku and Enova, who both have some resources and practice
> to help testing too. Heroku can spin up test instances with workloads any
> number of ways. Enova can make a Londiste standby with checksums turned on
> to hit it with a logical replicated workload, while the master stays
> un-checksummed.
I was thinking about turning checksums on for all new databases as
long as I am able to turn them off easily, per my message prior:
http://www.postgresql.org/message-id/CAAZKuFZzA+aw8ZL4F_5C8T8ZHRtJo3cM1aJQddGLQCpEz_3-kQ@mail.gmail.com.
An unstated assumption here was that I could apply the patch to 9.2
with some work. It seems the revitalized interest in the patch has
raised a couple of issues on inspection that have yet to be resolved,
so before moving I'd prefer to wait for a quiescence in the patch's
evolution, as
was the case for some time even after review.
However, if we want to just hit 9.3dev with a bunch of synthetic
traffic, that's probably doable also, and in some ways easier (or at
least less risky).
--
fdr
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 14:01:24 |
| Message-ID: | CA+U5nML-HGoWuDH7sU-f3Yn_-4BXg44+zkBMyGbSxgP71xcLSw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 18 March 2013 00:50, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 3/17/13 1:41 PM, Simon Riggs wrote:
>>
>> So I'm now moving towards commit using a CRC algorithm. I'll put in a
>> feature to allow algorithm be selected at initdb time, though that is
>> mainly a convenience to allow us to more easily do further testing on
>> speedups and whether there are any platform specific regressions
>> there.
>
> That sounds reasonable. As I just posted, I'm hoping Ants can help make a
> pass over a CRC16 version, since his one on the Fletcher one seemed very
> productive. If you're spending time looking at this, I know I'd prefer to
> see you poking at the WAL related aspects instead. There are more of us who
> are capable of crunching CRC code than the list of people who have practice
> at WAL changes like you do.
Just committed the first part, which was necessary refactoring.
I see at least 2 further commits here:
* Next part is the checksum patch itself, with some checksum calc or
other (mostly unimportant from a code perspective, since the actual
algorithm is just a small isolated piece of code.
* Further commit(s) to set the agreed checksum algorithm and/or tune it.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 17:52:58 |
| Message-ID: | 20130318175258.GB16641@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Mar 17, 2013 at 05:50:11PM -0700, Greg Smith wrote:
> As long as the feature is off by default, so that people have to
> turn it on to hit the biggest changed code paths, the exposure to
> potential bugs doesn't seem too bad. New WAL data is no fun, but
> it's not like this hasn't happened before.
With a potential 10-20% overhead, I am unclear who would enable this at
initdb time.
I assume a user would wait until they suspected corruption to turn it
on, and because it is only initdb-enabled, they would have to
dump/reload their cluster. The open question is whether this is a
usable feature as written, or whether we should wait until 9.4.
pg_upgrade can't handle this because the old/new clusters would have the
same catalog version number and the tablespace directory names would
conflict. Even if they are not using tablespaces, the old heap/index
files would not have checksums and therefore would throw an error as
soon as you accessed them. In fact, this feature is going to need
pg_upgrade changes to detect from pg_controldata that the old/new
clusters have the same checksum setting.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 18:21:44 |
| Message-ID: | CAFj8pRAD2ZZtcR0KDef_GTU+xpEeD0wDKbSA8paDgrnJb4DOOA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2013/3/18 Bruce Momjian <bruce(at)momjian(dot)us>:
> On Sun, Mar 17, 2013 at 05:50:11PM -0700, Greg Smith wrote:
>> As long as the feature is off by default, so that people have to
>> turn it on to hit the biggest changed code paths, the exposure to
>> potential bugs doesn't seem too bad. New WAL data is no fun, but
>> it's not like this hasn't happened before.
>
> With a potential 10-20% overhead, I am unclear who would enable this at
> initdb time.
everybody who has no 100% loaded server.
I can see on almost all PostgreSQL instances load to 5 on 8CPU core instances.
It is similar to PostgreSQL statistics - I remember so it did 20% slowdown too
Regards
Pavel
>
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
>
> pg_upgrade can't handle this because the old/new clusters would have the
> same catalog version number and the tablespace directory names would
> conflict. Even if they are not using tablespaces, the old heap/index
> files would not have checksums and therefore would throw an error as
> soon as you accessed them. In fact, this feature is going to need
> pg_upgrade changes to detect from pg_controldata that the old/new
> clusters have the same checksum setting.
>
> --
> Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
> EnterpriseDB http://enterprisedb.com
>
> + It's impossible for everything to be true. +
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 18:24:37 |
| Message-ID: | CA+U5nM+zxW1Axq3hzCb17fiDBrM8o=NN--aCa+RSPdoBo+w6_A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 18 March 2013 17:52, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> On Sun, Mar 17, 2013 at 05:50:11PM -0700, Greg Smith wrote:
>> As long as the feature is off by default, so that people have to
>> turn it on to hit the biggest changed code paths, the exposure to
>> potential bugs doesn't seem too bad. New WAL data is no fun, but
>> it's not like this hasn't happened before.
>
> With a potential 10-20% overhead,
... for some workloads.
> I am unclear who would enable this at initdb time.
Anybody that cares a lot about their data.
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
When two experienced technical users tell us this is important and
that they will use it, we should listen.
> In fact, this feature is going to need
> pg_upgrade changes to detect from pg_controldata that the old/new
> clusters have the same checksum setting.
I don't see any way they can differ.
pg_upgrade and checksums don't mix, in this patch, at least.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 18:25:53 |
| Message-ID: | 20130318182553.GW4361@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
* Bruce Momjian (bruce(at)momjian(dot)us) wrote:
> With a potential 10-20% overhead, I am unclear who would enable this at
> initdb time.
I'd expect that quite a few people would, myself included on a brand new
DB that I didn't have any reason to think would need to be
super-performant.
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
It's absolutely useful as an initdb-only option. If we want to worry
about users who will see corruption and who will wait until then to want
to turn on this feature, then we should just enable it by default.
> pg_upgrade can't handle this because the old/new clusters would have the
> same catalog version number and the tablespace directory names would
> conflict.
pg_upgrade would just need to complain and exit if someone tried to go
from a non-checksum DB to a DB which was initdb'd with checksums, right?
I don't see pg_upgrade being able to convert from one to the other.
Users can use pg_dump/restore for that..
> Even if they are not using tablespaces, the old heap/index
> files would not have checksums and therefore would throw an error as
> soon as you accessed them. In fact, this feature is going to need
> pg_upgrade changes to detect from pg_controldata that the old/new
> clusters have the same checksum setting.
Right, but that's it, imv.
Thanks,
Stephen
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 18:28:24 |
| Message-ID: | 51475CC8.5010303@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> With a potential 10-20% overhead, I am unclear who would enable this at
> initdb time.
People who know they have a chronic issue with bad disks/cards/drivers
would. Or anyone with enough machines that IO corruption is an
operational concern worth more than 10% overhead.
Or, in a word: Heroku, Enova and Aster Data, by their own admission.
This seems like a sufficiently rsignificant user group to make it
worthwhile to get something in, as long as it's something we can build on.
Also, Simon, Greg and I discussed this feature while at PyCon last week.
We went over it to discuss whether the poor performance now was a
permanent result of the checksum design, or whether it would be possible
to improve performance in future versions of PostgreSQL without an
incompatible change. We concluded that it would be possible to improve
it substantially while using the same file & checksum format. Some of
the performance improvements require finally doing something to clean up
hint bits, though, so it's not something we want to do for 9.3 at this
stage.
As such, I'm recommending that we go ahead with committing this feature.
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
"release early, release often". We just need to document that the
feature has substantial performance overhead, and the limitations around
it. Right now it's useful to a minority of our users, but in the future
it can be made useful to a larger group. And, importantly, for that
minority, there really is no other solution.
> pg_upgrade can't handle this because the old/new clusters would have the
> same catalog version number and the tablespace directory names would
> conflict. Even if they are not using tablespaces, the old heap/index
> files would not have checksums and therefore would throw an error as
> soon as you accessed them. In fact, this feature is going to need
> pg_upgrade changes to detect from pg_controldata that the old/new
> clusters have the same checksum setting.
Better get cracking, then! ;-)
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 18:42:23 |
| Message-ID: | 1363632143.2726.0.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-03-18 at 13:52 -0400, Bruce Momjian wrote:
> In fact, this feature is going to need
> pg_upgrade changes to detect from pg_controldata that the old/new
> clusters have the same checksum setting.
I believe that has been addressed in the existing patch. Let me know if
you see any problems.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 19:02:41 |
| Message-ID: | 1363633361.2726.4.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 2013-03-17 at 22:26 -0700, Daniel Farina wrote:
> as long as I am able to turn them off easily
To be clear: you don't get the performance back by doing
"ignore_checksum_failure = on". You only get around the error itself,
which allows you to dump/reload the good data.
Regards,
Jeff Davis
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 19:03:44 |
| Message-ID: | 20130318190344.GC16641@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 11:42:23AM -0700, Jeff Davis wrote:
> On Mon, 2013-03-18 at 13:52 -0400, Bruce Momjian wrote:
> > In fact, this feature is going to need
> > pg_upgrade changes to detect from pg_controldata that the old/new
> > clusters have the same checksum setting.
>
> I believe that has been addressed in the existing patch. Let me know if
> you see any problems.
Oh, I see it now, right at the top. I didn't realize anyone else would
have been looking to address this. Nice!
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 19:06:18 |
| Message-ID: | 20130318190618.GD16641@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 06:24:37PM +0000, Simon Riggs wrote:
> On 18 March 2013 17:52, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> > On Sun, Mar 17, 2013 at 05:50:11PM -0700, Greg Smith wrote:
> >> As long as the feature is off by default, so that people have to
> >> turn it on to hit the biggest changed code paths, the exposure to
> >> potential bugs doesn't seem too bad. New WAL data is no fun, but
> >> it's not like this hasn't happened before.
> >
> > With a potential 10-20% overhead,
>
> ... for some workloads.
>
>
> > I am unclear who would enable this at initdb time.
>
> Anybody that cares a lot about their data.
>
> > I assume a user would wait until they suspected corruption to turn it
> > on, and because it is only initdb-enabled, they would have to
> > dump/reload their cluster. The open question is whether this is a
> > usable feature as written, or whether we should wait until 9.4.
>
> When two experienced technical users tell us this is important and
> that they will use it, we should listen.
>
>
> > In fact, this feature is going to need
> > pg_upgrade changes to detect from pg_controldata that the old/new
> > clusters have the same checksum setting.
>
> I don't see any way they can differ.
>
> pg_upgrade and checksums don't mix, in this patch, at least.
Jeff has already addressed the issue in the patch, e.g. if someone
initdb's the new cluster with checksums.
I am now fine with the patch based on the feedback I received. I needed
to hear that the initdb limitation and the new performance numbers still
produced a useful feature.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 19:25:55 |
| Message-ID: | CA+U5nMK5ous2F4W6ZFsqeoCe_tw14nJpwt5J-b0=Sc0ScgEiqg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 18 March 2013 19:02, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Sun, 2013-03-17 at 22:26 -0700, Daniel Farina wrote:
>> as long as I am able to turn them off easily
>
> To be clear: you don't get the performance back by doing
> "ignore_checksum_failure = on". You only get around the error itself,
> which allows you to dump/reload the good data.
Given that the worst pain point comes from setting hint bits during a
large SELECT, it makes sense to offer an option to simply skip hint
bit setting when we are reading data (SELECT, not
INSERT/UPDATE/DELETE). That seems like a useful option even without
checksums. I know I have seen cases across many releases where setting
that would have been good, since it puts the cleanup back onto
VACUUM/writers, rather than occasional SELECTs.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 19:40:48 |
| Message-ID: | 51476DC0.9000106@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/18/13 10:52 AM, Bruce Momjian wrote:
> With a potential 10-20% overhead, I am unclear who would enable this at
> initdb time.
If you survey people who are running PostgreSQL on "cloud" hardware, be
it Amazon's EC2 or similar options from other vendors, you will find a
high percentage of them would pay quite a bit of performance to make
their storage more reliable. To pick one common measurement for
popularity, a Google search on "ebs corruption" returns 17 million hits.
To quote one of those, Baron Schwartz of Percona talking about MySQL
on EC2:
"BTW, I have seen data corruption on EBS volumes. It’s not clear whether
it was InnoDB’s fault (extremely unlikely IMO), the operating system’s
fault, EBS’s fault, or something else."
http://www.mysqlperformanceblog.com/2011/08/04/mysql-performance-on-ec2ebs-versus-rds/
*That* uncertainty is where a lot of the demand for this feature is
coming from. People deploy into the cloud, their data gets corrupted,
and no one call tell them what/why/how it happened. And that means they
don't even know what to change to make it better. The only people I see
really doing something about this problem all seem years off, and I'm
not sure they are going to help--especially since some of them are
targeting "enterprise" storage rather than the cloud-style installations.
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
The reliability issues of both physical and virtual hardware are so
widely known that many people will deploy with this on as their default
configuration.
If you don't trust your existing data, you can't retroactively check it.
A checksum of an already corrupt block is useless. Accordingly, there
is no use case for converting an installation with real or even
suspected problems to a checksummed one. If you wait until you suspect
corruption to care about checksums, it's really too late. There is only
one available next step: you must do a dump to figure out what's
readable. That is the spot that all of the incoming data recovery
customers we see at 2ndQuadrant are already in when we're called. The
cluster is suspicious, sometimes they can get data out of it with a
dump, and if we hack up their install we can usually recover a bit more
than they could.
After the data from a partially corrupted database is dumped, someone
who has just been through that pain might decide they should turn
checksums on when they restore the dump. When it's on, they can access
future damage easily at the block level when it happens, and possibly
repair it without doing a full dump/reload. What's implemented in the
feature we're talking about has a good enough UI to handle this entire
cycle I see damaged installations go through.
> In fact, this feature is going to need
> pg_upgrade changes to detect from pg_controldata that the old/new
> clusters have the same checksum setting.
I think that's done already, but it's certainly something to test out too.
Good questions, Bruce, I don't think the reasons behind this feature's
demand have been highlighted very well before. I try not to spook the
world by talking regularly about how many corrupt PostgreSQL databases
I've seen, but they do happen. Most of my regular ranting on crappy
SSDs that lie about writes comes from a TB scale PostgreSQL install that
got corrupted due to the write-cache flaws of the early Intel
SSDs--twice. The would have happily lost even the worst-case 20% of
regular performance to avoid going down for two days each time they saw
corruption, where we had to dump/reload to get them going again. If the
install had checksums, I could have figured out which blocks were
damaged and manually fixed them. Without checksums, there's no way to
even tell for sure what is broken.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 19:46:32 |
| Message-ID: | 51476F18.6060303@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/18/13 10:52 AM, Bruce Momjian wrote:
> With a potential 10-20% overhead, I am unclear who would enable this at
> initdb time.
If you survey people who are running PostgreSQL on "cloud" hardware, be
it Amazon's EC2 or similar options from other vendors, you will find a
high percentage of them would pay quite a bit of performance to make
their storage more reliable. To pick one common measurement for
popularity, a Google search on "ebs corruption" returns 17 million hits.
To quote one of those, Baron Schwartz of Percona talking about MySQL
on EC2:
"BTW, I have seen data corruption on EBS volumes. It’s not clear whether
it was InnoDB’s fault (extremely unlikely IMO), the operating system’s
fault, EBS’s fault, or something else."
http://www.mysqlperformanceblog.com/2011/08/04/mysql-performance-on-ec2ebs-versus-rds/
*That* uncertainty is where a lot of the demand for this feature is
coming from. People deploy into the cloud, their data gets corrupted,
and no one call tell them what/why/how it happened. And that means they
don't even know what to change to make it better. The only people I see
really doing something about this problem all seem years off, and I'm
not sure they are going to help--especially since some of them are
targeting "enterprise" storage rather than the cloud-style installations.
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
The reliability issues of both physical and virtual hardware are so
widely known that many people will deploy with this on as their default
configuration.
If you don't trust your existing data, you can't retroactively check it.
A checksum of an already corrupt block is useless. Accordingly, there
is no use case for converting an installation with real or even
suspected problems to a checksummed one. If you wait until you suspect
corruption to care about checksums, it's really too late. There is only
one available next step: you must do a dump to figure out what's
readable. That is the spot that all of the incoming data recovery
customers we see at 2ndQuadrant are already in when we're called. The
cluster is suspicious, sometimes they can get data out of it with a
dump, and if we hack up their install we can usually recover a bit more
than they could.
After the data from a partially corrupted database is dumped, someone
who has just been through that pain might decide they should turn
checksums on when they restore the dump. When it's on, they can access
future damage easily at the block level when it happens, and possibly
repair it without doing a full dump/reload. What's implemented in the
feature we're talking about has a good enough UI to handle this entire
cycle I see damaged installations go through.
Good questions, Bruce, I don't think the reasons behind this feature's
demand have been highlighted very well before. I try not to spook the
world by talking regularly about how many corrupt PostgreSQL databases
I've seen, but they do happen. Most of my regular ranting on crappy
SSDs that lie about writes comes from a TB scale PostgreSQL install that
got corrupted due to the write-cache flaws of the early Intel
SSDs--twice. The would have happily lost even the worst-case 20% of
regular performance to avoid going down for two days each time they saw
corruption, where we had to dump/reload to get them going again. If the
install had checksums, I could have figured out which blocks were
damaged and manually fixed them. Without checksums, there really was
nowhere to go except dump/reload.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-18 20:31:00 |
| Message-ID: | 51477984.5010008@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/18/13 10:52 AM, Bruce Momjian wrote:
> With a potential 10-20% overhead, I am unclear who would enable this at
> initdb time.
If you survey people who are running PostgreSQL on "cloud" hardware, be
it Amazon's EC2 or similar options from other vendors, you will find a
high percentage of them would pay quite a bit of performance to make
their storage more reliable. To pick one common measurement for
popularity, a Google search on "ebs corruption" returns 17 million hits.
To quote one of those, Baron Schwartz of Percona talking about MySQL
on EC2:
"BTW, I have seen data corruption on EBS volumes. It’s not clear whether
it was InnoDB’s fault (extremely unlikely IMO), the operating system’s
fault, EBS’s fault, or something else."
http://www.mysqlperformanceblog.com/2011/08/04/mysql-performance-on-ec2ebs-versus-rds/
*That* uncertainty is where a lot of the demand for this feature is
coming from. People deploy into the cloud, their data gets corrupted,
and no one call tell them what/why/how it happened. And that means they
don't even know what to change to make it better. The only people I see
really doing something about this problem all seem years off, and I'm
not sure they are going to help--especially since some of them are
targeting "enterprise" storage rather than the cloud-style installations.
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
The reliability issues of both physical and virtual hardware are so
widely known that many people will deploy with this on as their default
configuration.
If you don't trust your existing data, you can't retroactively check it.
A checksum of an already corrupt block is useless. Accordingly, there
is no use case for converting an installation with real or even
suspected problems to a checksummed one. If you wait until you suspect
corruption to care about checksums, it's really too late. There is only
one available next step: you must do a dump to figure out what's
readable. That is the spot that all of the incoming data recovery
customers we see at 2ndQuadrant are already in when we're called. The
cluster is suspicious, sometimes they can get data out of it with a
dump, and if we hack up their install we can usually recover a bit more
than they could.
After the data from a partially corrupted database is dumped, someone
who has just been through that pain might decide they should turn
checksums on when they restore the dump. When it's on, they can access
future damage easily at the block level when it happens, and possibly
repair it without doing a full dump/reload. What's implemented in the
feature we're talking about has a good enough UI to handle this entire
cycle I see damaged installations go through.
Good questions, Bruce, I don't think the reasons behind this feature's
demand have been highlighted very well before. I try not to spook the
world by talking regularly about how many corrupt PostgreSQL databases
I've seen, but they do happen. Right now we have two states: "believed
good" and "believed corrupted"--and the transitions between them are
really nasty. Just being able to quantify corruption would be a huge
improvement.
Related aside, most of my regular ranting on crappy SSDs that lie about
writes comes from a TB scale PostgreSQL install that got corrupted due
to the write-cache flaws of the early Intel SSDs--twice. They would
have happily lost even the worst-case 20% of regular performance to
avoid going down for two days each time they saw corruption, where we
had to dump/reload to get them going again. If the install had
checksums, I could have figured out which blocks were damaged and
manually fixed them, basically go on a hunt for torn pages and the last
known good copy via full-page write. Without checksums, there really
was nowhere to go with them except dump/reload.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 00:17:59 |
| Message-ID: | CA+CSw_u=P8goPbpvcN8iABUacQumD_VH9MHvKiXQ+fgsqyT0SQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 2:04 AM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 3/15/13 5:32 AM, Ants Aasma wrote:
>>
>> Best case using the CRC32 instruction would be 6.8 bytes/cycle [1].
>> But this got me thinking about how to do this faster...
>> [1]
>> http://www.drdobbs.com/parallel/fast-parallelized-crc-computation-using/229401411
>
>
> The optimization work you went through here looked very nice. Unfortunately,
> a few things seem pushing toward using a CRC16 instead of the Fletcher
> approach. It seems possible to execute a CRC16 in a reasonable enough time,
> in the same neighborhood as the Fletcher one. And there is some hope that
> hardware acceleration for CRCs will be available in a system API/compiler
> feature one day, making them even cheaper.
>
> Ants, do you think you could take a similar look at optimizing a CRC16
> calculation? I'm back to where I can do a full performance comparison run
> again starting tomorrow, with the latest version of this patch, and I'd like
> to do that with a CRC16 implementation or two. I'm not sure if it's
> possible to get a quicker implementation because the target is a CRC16, or
> whether it's useful to consider truncating a CRC32 into a CRC16.
I looked for fast CRC implementations on the net. The fastest plain C
variant I could find was one produced by Intels R&D department
(available with a BSD license [1], requires some porting). It does 8 x
8bit table lookups in parallel, requiring a 8*256*4 = 8kB lookup
table.
Using the table lookup method CRC16 would run at exactly the same
speed but the table would be 2x smaller. There is also an option to do
4 lookup tables, this approach is said to be about 2x slower for 2x
less data.
I took a look at assembly generated for the slice-by-8 algorithm. It
seems to me that GCC for some mysterious reason decides to accumulate
the xor's in a serial chain, losing superscalar execution
possibilities. If it could be coaxed into accumulating xor's in a tree
pattern the performance should improve somewhere between 1.5 and 2x.
For CRC32C there is also an option to use the crc32 instructions
available on newer Intel machines and run 3 parallel CRC calculations
to cover for the 3 cycle latency on that instruction, combining them
in the end [2]. Skimming the paper it looks like there are some
patents in this area, so if we wish to implement this, we would have
to see how we can navigate around them. The other issue is that crc32
instruction is Intel only so far. The cited performance is 6.8
bytes/cycle.
There is also an option to use pclmulqdq instruction to do generic
CRC's in 16byte blocks. This is available on Intel Westmere and up
(2010+) and AMD Bulldozer and up (2011+). Sample ASM code is available
in the Intel paper. [3] Cited speed is 0.88 bytes/cycle.
I lifted the benchmark framework of the 8 byte slicing method from the
Intel code and ran some tests on the implementations I had available -
the 8 byte slicing CRC from Intel, fletcher from the checksum patch,
my parallel 16bit checksums approach and a hand coded 32bit parallel
checksum I had (requires SSE4.1 as implemented but on sandy bridge
platform the performance should be equivalent to a 16bit one that
requires only SSE2).
So here come the results:
gcc4.7 -O2, 8192byte buffer:
CRC32 slicing by 8 Algorithm (bytes/cycle), 0.524249
Fletcher Algorithm: (bytes/cycle), 1.930567
SIMD Algorithm (gcc): (bytes/cycle), 0.575617
SIMD Algorithm (hand coded): (bytes/cycle), 9.196853
gcc4.7 -O2 -ftree-vectorize -funroll-loops, 8192byte buffer:
CRC32 slicing by 8 Algorithm (bytes/cycle), 0.523573
Fletcher Algorithm: (bytes/cycle), 3.316269
SIMD Algorithm (gcc): (bytes/cycle), 7.866682
SIMD Algorithm (hand coded): (bytes/cycle), 9.114214
Notes:
* As you can see, CRC based approach would have 4x larger performance
overhead compared to the Fletcher algorithm as implemented in the
current patch.
* This benchmark is the best case for the slicing CRC algorithm. Real
world uses might not have the lookup table in cache.
* We should probably check what the code path length from read syscall
to checksum calculation is. We don't want it to contain something that
would push the page out from cache.
* Even a pclmulqdq based implementation would be a lot slower than Fletcher.
* The Fletcher algorithm benefits greatly from unrolling as the loop
body is so cheap and the algorithm is ALU bound.
* As predicted the SIMD algorithm is quite slow if the compiler won't
vectorize it. But notice that the performance is comparable to
unaccelerated CRC.
* The vectorized SIMD gcc variant is outperforming the claimed
performance of hardware accelerated crc32 using only SSE2 features
(available in the base x86-64 instruction set). The gap isn't large
though.
* Vectorized SIMD code performance is surprisingly close to handcoded.
Not sure if there is something holding back the handcoded version or
if the measurement overhead is coming into play here. This would
require further investigation. perf accounted 25% of execution time to
rdtsc instructions in the measurement loop for the handcoded variant
not all of that is from the pipeline flush.
My 2¢ is that we should either go with truncated CRC32C in the hope
that hardware implementations get more widespread and we can maybe
pick the optimized implementation based on cpuid at runtime. Or if we
need performance right now, we should go with the parallel
implementation and amend the build infrastructure to support
vectorization where possible. This would get good performance to 99%
of users out there and the ones missing out would have a solution that
is as fast as the best CRC algorithm.
I don't really have a lot of cycles left to devote on this this week.
I can maybe help code one of the approaches into PostgreSQL to measure
how much the real world result effect is. Or if you'd like to test the
SIMD version, you can take my last patch in this thread and compare
CFLAGS="-O2 -ftree-vectorize -funroll-loops" built versions. Check
"objdump -d src/backend/storage/page/bufpage.o | grep pmullw" to
verify that it is vectorized.
The parallel multiply-by-prime-and-add algorithm would also need
verification that it gives good detection of interesting error cases.
It's used widely as a hash function so it shouldn't be too bad.
I have also attached the test infrastructure I used so you can
replicate results if you wish. Compile with "gcc -g -O2
[-ftree-vectorize -funroll-loops] crc.c 8x256_tables.c -lm -o crc".
Run with "./crc -t warm -d warm -i 1 -p 8192 -n 100000". If you don't
have a SSE4.1 capable CPU (x86 produced in the last 2 years) the last
test will crash so you might want to comment that out.
[1] http://sourceforge.net/projects/slicing-by-8/
[2] http://www.intel.com/content/dam/www/public/us/en/documents/white-papers/crc-iscsi-polynomial-crc32-instruction-paper.pdf
[3] http://download.intel.com/embedded/processor/whitepaper/327889.pdf
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| intel-slice-by-8.tar.gz | application/x-gzip | 20.2 KB |
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 00:36:21 |
| Message-ID: | CAAZKuFazZx_4aYM_fs7wh=g7ss8MmghdogJCyRry=eVUvzjTyQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 1:31 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 3/18/13 10:52 AM, Bruce Momjian wrote:
>>
>> With a potential 10-20% overhead, I am unclear who would enable this at
>> initdb time.
>
>
> If you survey people who are running PostgreSQL on "cloud" hardware, be it
> Amazon's EC2 or similar options from other vendors, you will find a high
> percentage of them would pay quite a bit of performance to make their
> storage more reliable. To pick one common measurement for popularity, a
> Google search on "ebs corruption" returns 17 million hits. To quote one of
> those, Baron Schwartz of Percona talking about MySQL on EC2:>
> "BTW, I have seen data corruption on EBS volumes. It’s not clear whether it
> was InnoDB’s fault (extremely unlikely IMO), the operating system’s fault,
> EBS’s fault, or something else."
Clarification, because I think this assessment as delivered feeds some
unnecessary FUD about EBS:
EBS is quite reliable. Presuming that all noticed corruptions are
strictly EBS's problem (that's quite a stretch), I'd say the defect
rate falls somewhere in the range of volume-centuries.
I want to point this out because I think EBS gets an outsized amount
of public flogging, and not all of it is deserved.
My assessment of the caustion at hand: I care about this feature not
because EBS sucks more than anything else by a large degree, but
because there's an ever mounting number of EBS volumes whose defects
are under the responsibility of comparatively few individuals.
--
fdr
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 02:13:59 |
| Message-ID: | 5147C9E7.4090608@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/18/13 5:36 PM, Daniel Farina wrote:
> Clarification, because I think this assessment as delivered feeds some
> unnecessary FUD about EBS:
>
> EBS is quite reliable. Presuming that all noticed corruptions are
> strictly EBS's problem (that's quite a stretch), I'd say the defect
> rate falls somewhere in the range of volume-centuries.
I wasn't trying to flog EBS as any more or less reliable than other
types of storage. What I was trying to emphasize, similarly to your
"quite a stretch" comment, was the uncertainty involved when such
deployments fail. Failures happen due to many causes outside of just
EBS itself. But people are so far removed from the physical objects
that fail, it's harder now to point blame the right way when things fail.
A quick example will demonstrate what I mean. Let's say my server at
home dies. There's some terrible log messages, it crashes, and when it
comes back up it's broken. Troubleshooting and possibly replacement
parts follow. I will normally expect an eventual resolution that
includes data like "the drive showed X SMART errors" or "I swapped the
memory with a similar system and the problem followed the RAM". I'll
learn something about what failed that I might use as feedback to adjust
my practices. But an EC2+EBS failure doesn't let you get to the root
cause effectively most of the time, and that makes people nervous.
I can already see "how do checksums alone help narrow the blame?" as the
next question. I'll post something summarizing how I use them for that
tomorrow, just out of juice for that tonight.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 02:59:39 |
| Message-ID: | CAAZKuFaw=+bmJK2+Rf46b1aaHd=SbOAjeHAD_WEG6Nj5DrPfyw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 7:13 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> I wasn't trying to flog EBS as any more or less reliable than other types of
> storage. What I was trying to emphasize, similarly to your "quite a
> stretch" comment, was the uncertainty involved when such deployments fail.
> Failures happen due to many causes outside of just EBS itself. But people
> are so far removed from the physical objects that fail, it's harder now to
> point blame the right way when things fail.
I didn't mean to imply you personally were going out of your way to
flog EBS, but there is a sufficient vacuum in the narrative that
someone could reasonably interpereted it that way, so I want to set it
straight. The problem is the quantity of databases per human. The
Pythons said it best: 'A simple question of weight ratios.'
> A quick example will demonstrate what I mean. Let's say my server at home
> dies. There's some terrible log messages, it crashes, and when it comes
> back up it's broken. Troubleshooting and possibly replacement parts follow.
> I will normally expect an eventual resolution that includes data like "the
> drive showed X SMART errors" or "I swapped the memory with a similar system
> and the problem followed the RAM". I'll learn something about what failed
> that I might use as feedback to adjust my practices. But an EC2+EBS failure
> doesn't let you get to the root cause effectively most of the time, and that
> makes people nervous.
Yes, the layering makes it tougher to do vertical treatment of obscure
issues. Redundancy has often been the preferred solution here: bugs
come and go all the time, and everyone at each level tries to fix what
they can without much coordination from the layer above or below.
There are hopefully benefits in throughput of progress at each level
from this abstraction, but predicting when any one particular issue
will go understood top to bottom is even harder than it already was.
Also, I think the line of reasoning presented is biased towards a
certain class of database: there are many, many databases with minimal
funding and oversight being run in the traditional way, and the odds
they'll get a vigorous root cause analysis in event of an obscure
issue is already close to nil. Although there are other
considerations at play (like not just leaving those users with nothing
more than a "bad block" message), checksums open some avenues
gradually benefit those use cases, too.
> I can already see "how do checksums alone help narrow the blame?" as the
> next question. I'll post something summarizing how I use them for that
> tomorrow, just out of juice for that tonight.
Not from me. It seems pretty intuitive from here how database
maintained checksums assist in partitioning the problem.
--
fdr
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Andres Freund <andres(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Greg Smith <greg(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 17:18:08 |
| Message-ID: | 1363713488.2369.55.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, 2013-03-16 at 20:41 -0400, Tom Lane wrote:
> Simon Riggs <simon(at)2ndQuadrant(dot)com> writes:
> > On 15 March 2013 13:08, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> >> I commented on this before, I personally think this property makes fletcher a
> >> not so good fit for this. Its not uncommon for parts of a block being all-zero
> >> and many disk corruptions actually change whole runs of bytes.
[ referring to Ants's comment that the existing algorithm doesn't
distinguish between 0x00 and 0xFF ]
> Meh. I don't think that argument holds a lot of water. The point of
> having checksums is not so much to notice corruption as to be able to
> point the finger at flaky hardware. If we have an 8K page with only
> 1K of data in it, and we fail to notice that the hardware dropped a lot
> of bits in the other 7K, we're not doing our job; and that's not really
> something to write off, because it would be a lot better if we complain
> *before* the hardware manages to corrupt something valuable.
I will move back to verifying the page hole, as well.
There are a few approaches:
1. Verify that the page hole is zero before write and after read.
2. Include it in the calculation (if we think there are some corner
cases where the hole might not be all zero).
3. Zero the page hole before write, and verify that it's zero on read.
This can be done during the memcpy at no performance penalty in
PageSetChecksumOnCopy(), but that won't work for
PageSetChecksumInplace().
With option #2 or #3, we might also verify that the hole is all-zero if
asserts are enabled.
> So I think we'd be best off to pick an algorithm whose failure modes
> don't line up so nicely with probable hardware failure modes. It's
> worth noting that one of the reasons that CRCs are so popular is
> precisely that they were designed to detect burst errors with high
> probability.
Another option is to use a different modulus. The page
http://en.wikipedia.org/wiki/Fletcher%27s_checksum suggests that a prime
number can be a good modulus for Fletcher-32. Perhaps we could use 251
instead of 255? That would make it less likely to miss a common form of
hardware failure, although it would also reduce the number of possible
checksums slightly (about 4% fewer than 2^16).
I'm leaning toward this option now, or a CRC of some kind if the
performance is reasonable.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 17:26:19 |
| Message-ID: | 1363713979.2369.63.camel@jdavis-laptop |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-03-15 at 14:32 +0200, Ants Aasma wrote:
> The most obvious case here is that you
> can swap any number of bytes from 0x00 to 0xFF or back without
> affecting the hash.
That's a good point. Someone (Simon?) had brought that up before, but
you and Tom convinced me that it's a problem. As I said in my reply to
Tom, one option is to change the modulus.
> I took a look at how the fletcher-64 compiles.
Great analysis, thank you.
> I'm not really sure if parallel checksums would be worth doing or not.
> On one hand, enabling data parallelism would make it more future
> proof, on the other hand, the unvectorized variant is slower than
> Fletcher-64.
Looks like we still have several options being discussed. I think the
checksum with modulo 255 is out, but perhaps a different modulus is
still on the table. And if we can get a CRC to be fast enough, then we'd
all be happy with that option.
Another thing to consider is that, right now, the page is copied and
then checksummed. If we can calculate the checksum during the copy, that
might save us a small amount of effort. My feeling is that it would only
really help if the checksum is very cheap and works on large word sizes,
but I'm not sure.
> On another note, I think I found a bug with the current latest patch.
Ugh. Great catch, thank you!
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 17:45:07 |
| Message-ID: | CA+U5nMLg4C-MOaMS_XoMqRc-7AnWzkOTWep5cZOktJtZs6EBMA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 19 March 2013 17:18, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> I will move back to verifying the page hole, as well.
That was agreed long ago...
> There are a few approaches:
>
> 1. Verify that the page hole is zero before write and after read.
> 2. Include it in the calculation (if we think there are some corner
> cases where the hole might not be all zero).
> 3. Zero the page hole before write, and verify that it's zero on read.
> This can be done during the memcpy at no performance penalty in
> PageSetChecksumOnCopy(), but that won't work for
> PageSetChecksumInplace().
>
> With option #2 or #3, we might also verify that the hole is all-zero if
> asserts are enabled.
(3) seems likely to be more expensive than (2), since we're talking
unaligned memory writes rather than a single pre-fetchable block read.
In any case, at initial patch commit, we should CRC the whole block
and allow for the possibility of improvement following measurements.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 17:47:24 |
| Message-ID: | CA+U5nMKm19un=NhEvA7ao1z=4mEUY-9d3PT25RVRm6=ptD0LeQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 19 March 2013 00:17, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> I looked for fast CRC implementations on the net.
Thanks very much for great input.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Andres Freund <andres(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Greg Smith <greg(at)2ndQuadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 18:07:53 |
| Message-ID: | 8385.1363716473@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Davis <pgsql(at)j-davis(dot)com> writes:
> I will move back to verifying the page hole, as well.
> There are a few approaches:
> 1. Verify that the page hole is zero before write and after read.
> 2. Include it in the calculation (if we think there are some corner
> cases where the hole might not be all zero).
> 3. Zero the page hole before write, and verify that it's zero on read.
> This can be done during the memcpy at no performance penalty in
> PageSetChecksumOnCopy(), but that won't work for
> PageSetChecksumInplace().
TBH, I do not think that the checksum code ought to be so familiar with
the page format as to know that there *is* a hole, much less be willing
to zero out what it thinks is a hole. I consider #3 totally
unacceptable from a safety standpoint, and don't much care for #1
either. #2 sounds like the thing to do.
regards, tom lane
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Greg Stark <stark(at)mit(dot)edu> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 18:32:31 |
| Message-ID: | 5148AF3F.5040801@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/8/13 4:40 PM, Greg Stark wrote:
> On Fri, Mar 8, 2013 at 5:46 PM, Josh Berkus <josh(at)agliodbs(dot)com> wrote:
>> After some examination of the systems involved, we conculded that the
>> issue was the FreeBSD drivers for the new storage, which were unstable
>> and had custom source patches. However, without PostgreSQL checksums,
>> we couldn't *prove* it wasn't PostgreSQL at fault. It ended up taking
>> weeks of testing, most of which was useless, to prove to them they had a
>> driver problem so it could be fixed. If Postgres had had checksums, we
>> could have avoided wasting a couple weeks looking for non-existant
>> PostgreSQL bugs.
>
> How would Postgres checksums have proven that?
It's hard to prove this sort of thing definitively. I see this more as
a source of evidence that can increase confidence that the database is
doing the right thing, most usefully in a replication environment.
Systems that care about data integrity nowadays are running with a WAL
shipping replica of some sort. Right now there's no way to grade the
master vs. standby copies of data, to figure out which is likely to be
the better copy. In a checksum environment, here's a new
troubleshooting workflow that becomes possible:
1) Checksum error happens on the master.
2) The same block is checked on the standby. It has the same 16 bit
checksum, but different data, and its checksum matches its data.
3) The copy of that block on the standby, which was shipped over the
network instead of being stored locally, is probably good.
4) The database must have been consistent when the data was in RAM on
the master.
5) Conclusion: there's probably something wrong at a storage layer
below the database on the master.
Now, of course this doesn't automatically point the finger correctly
with every possible corruption possibility. But this example is a
situation I've seen in the real world when a bad driver flips a random
bit in a block. If Josh had been able to show his client the standby
server built from streaming replication was just fine, and corruption
was limited to the master, that doesn't *prove* the database isn't the
problem. But it does usefully adjust the perception of what faults are
likely and unlikely away from it. Right now when I see master/standby
differences in data blocks, it's the old problem of telling the true
time when you have two clocks. Having a checksum helps pick the right
copy when there is more than one, and one has been corrupted by storage
layer issues.
> If i understand the performance issues right the main problem is the
> extra round trip to the wal log which can require a sync. Is that
> right?
I don't think this changes things such that there is a second fsync per
transaction. That is a worthwhile test workload to add though. Right
now the tests Jeff and I have ran have specifically avoided systems with
slow fsync, because you can't really test the CPU/memory overhead very
well if you're hitting the rotational latency bottleneck.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 21:28:49 |
| Message-ID: | 5148D891.5080003@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/18/13 8:17 PM, Ants Aasma wrote:
> I looked for fast CRC implementations on the net. The fastest plain C
> variant I could find was one produced by Intels R&D department
> (available with a BSD license [1], requires some porting).
Very specifically, it references
http://opensource.org/licenses/bsd-license.html as the 2 clause BSD
license it is released under. If PostgreSQL wanted to use that as its
implementation, the source file would need to have Intel's copyright,
and there's this ugly thing:
"Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution."
I don't remember if there's any good precedent for whether this form of
BSD licensed code can be assimilated into PostgreSQL without having to
give credit to Intel in impractical places. I hate these licenses with
the binary restrictions in them.
> For CRC32C there is also an option to use the crc32 instructions
> available on newer Intel machines and run 3 parallel CRC calculations
> to cover for the 3 cycle latency on that instruction, combining them
> in the end [2]. Skimming the paper it looks like there are some
> patents in this area, so if we wish to implement this, we would have
> to see how we can navigate around them.
Discussing patent issues, especially about how someone else implemented
a feature on list, is generally bad news. But since as you noted Intel
has interacted with other open-source communities already with code
related to those patents, I think it's OK to talk about that for a bit.
Yes, there are two Intel patents on how they actually implement the
CRC32C in their processor. I just read them both, and they have many
very specific claims. I suspect their purpose is to keep AMD from
knocking off the exact way Intel does this in hardware. But they also
contributed CRC32C code to Linux:
https://lwn.net/Articles/292984/
http://git.kernel.org/cgit/linux/kernel/git/herbert/cryptodev-2.6.git/tree/arch/x86/crypto/crc32c-pcl-intel-asm_64.S
with a dual license, GPLv2 and the 2 clause BSD again. In theory any
CRC32C implementation might get dragged into court over Intel's patents
if they wanted to shake someone down.
But they would bring a world of hurt upon themselves for asserting a
CRC32C patent claim against any open-source project, considering that
they contributed this code themselves under a pair of liberal licenses.
This doesn't set off any of my "beware of patents" alarms. Intel
wants projects to use this approach, detect their acceleration when it's
available, and run faster on Intel than AMD. Dragging free software
packages into court over code they submitted would create a PR disaster
for Intel. That would practically be entrapment on their part.
> perf accounted 25% of execution time to
> rdtsc instructions in the measurement loop for the handcoded variant
> not all of that is from the pipeline flush.
To clarify this part, rdtsc is instruction that gets timing information
from the processor: "Read Time Stamp Counter". So Ants is saying a lot
of the runtime is the timing itself. rdtsc execution time is the
overhead that the pg_test_timing utility estimates in some cases.
The main message I took away from this paper is that it's possible to
speed up CRC computation if you fix a) the CRC polynomial and b) the
size of the input buffer. There may be some good optimization
possibilities in both those, given I'd only expect Postgres to use one
polynomial and the typical database page sizes. Intel's processor
acceleration has optimizations for running against 1K blocks for
example. I don't think requiring the database page size to be a
multiple of 1K is ever going to be an unreasonable limitation, if that's
what it takes to get useful hardware acceleration.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 22:08:35 |
| Message-ID: | CA+CSw_uvM4eLc95yLxNHzoLGMsyx=+NGupHiwptHSyhUrCyMEg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Mar 19, 2013 at 11:28 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> I don't remember if there's any good precedent for whether this form of BSD
> licensed code can be assimilated into PostgreSQL without having to give
> credit to Intel in impractical places. I hate these licenses with the
> binary restrictions in them.
It's easy enough to re-implement this from scratch, including the
table generation if that is an issue. It's a very simple algorithm.
> Yes, there are two Intel patents on how they actually implement the CRC32C
> in their processor. I just read them both, and they have many very specific
> claims. I suspect their purpose is to keep AMD from knocking off the exact
> way Intel does this in hardware. But they also contributed CRC32C code to
> Linux:
>
> https://lwn.net/Articles/292984/
> http://git.kernel.org/cgit/linux/kernel/git/herbert/cryptodev-2.6.git/tree/arch/x86/crypto/crc32c-pcl-intel-asm_64.S
>
> with a dual license, GPLv2 and the 2 clause BSD again. In theory any CRC32C
> implementation might get dragged into court over Intel's patents if they
> wanted to shake someone down.
Thanks for checking that out. The kernel code is indeed the same 3
parallel CRC's combined at the end method described in the paper.
Looks like that is thankfully a non-issue.
> The main message I took away from this paper is that it's possible to speed
> up CRC computation if you fix a) the CRC polynomial and b) the size of the
> input buffer. There may be some good optimization possibilities in both
> those, given I'd only expect Postgres to use one polynomial and the typical
> database page sizes. Intel's processor acceleration has optimizations for
> running against 1K blocks for example. I don't think requiring the database
> page size to be a multiple of 1K is ever going to be an unreasonable
> limitation, if that's what it takes to get useful hardware acceleration.
The variable size CRC seemed to asymptotically approach the fixed
block speed at 1k. It only affects the specifics of the final
recombination. That said the, fixed size 1k looks good enough if we
decide to go this route. My main worry is that there is a reasonably
large population of users out there that don't have that acceleration
capability and will have to settle for performance overhead 4x worse
than what you currently measured for a shared buffer swapping
workload.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 22:52:19 |
| Message-ID: | 5148EC23.4040801@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/19/13 6:08 PM, Ants Aasma wrote:
> My main worry is that there is a reasonably
> large population of users out there that don't have that acceleration
> capability and will have to settle for performance overhead 4x worse
> than what you currently measured for a shared buffer swapping
> workload.
That would be very bad. I want to keep hammering on this part of the
implementation. If the only style of checksum that's computationally
feasible is the Fletcher one that's already been done--if that approach
is basically the most expensive one that's practical to use--I'd still
consider that a major win over doing nothing.
While being a lazy researcher today instead of writing code, I
discovered that the PNG file format includes a CRC-32 on its data
chunks, and to support that there's a CRC32 function inside of zlib:
http://www.zlib.net/zlib_tech.html
Is there anywhere that compiles a PostgreSQL --without-zlib that matters?
The UI looks like this:
ZEXTERN uLong ZEXPORT crc32 OF((uLong crc, const Bytef *buf, uInt len));
And they've already put some work into optimizing its table-driven
implementation. Seems possible to punt the whole problem of how to do
this efficiently toward the zlib developers, let them drop into assembly
to get the best possible Intel acceleration etc. one day.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 23:13:58 |
| Message-ID: | CAAZKuFZrES3L4wDxw4wtKNswjrM4JnNY59rdLgbcv59mO=FY0g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Mar 19, 2013 at 3:52 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 3/19/13 6:08 PM, Ants Aasma wrote:
>>
>> My main worry is that there is a reasonably
>> large population of users out there that don't have that acceleration
>> capability and will have to settle for performance overhead 4x worse
>> than what you currently measured for a shared buffer swapping
>> workload.
>
>
> That would be very bad. I want to keep hammering on this part of the
> implementation. If the only style of checksum that's computationally
> feasible is the Fletcher one that's already been done--if that approach is
> basically the most expensive one that's practical to use--I'd still consider
> that a major win over doing nothing.
>
> While being a lazy researcher today instead of writing code, I discovered
> that the PNG file format includes a CRC-32 on its data chunks, and to
> support that there's a CRC32 function inside of zlib:
> http://www.zlib.net/zlib_tech.html
>
> Is there anywhere that compiles a PostgreSQL --without-zlib that matters?
I'm confused. Postgres includes a CRC32 implementation for WAL, does
it not? Are you referring to something else?
I happen to remember this because I moved some things around to enable
third party programs (like xlogdump) to be separately compiled:
http://www.postgresql.org/message-id/E1S2Xo0-0004uv-FW@gemulon.postgresql.org
--
fdr
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-19 23:22:24 |
| Message-ID: | 5148F330.6080407@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/19/2013 06:52 PM, Greg Smith wrote:
>
>
> While being a lazy researcher today instead of writing code, I
> discovered that the PNG file format includes a CRC-32 on its data
> chunks, and to support that there's a CRC32 function inside of zlib:
> http://www.zlib.net/zlib_tech.html
>
> Is there anywhere that compiles a PostgreSQL --without-zlib that matters?
Some of the smaller platforms might not have it readily available. I
doubt there is any common server class or general computing platform
where it's not available.
cheers
andrew
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 00:03:35 |
| Message-ID: | 5148FCD7.2030703@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/19/13 7:13 PM, Daniel Farina wrote:
> I'm confused. Postgres includes a CRC32 implementation for WAL, does
> it not? Are you referring to something else?
I'm just pointing out that zlib includes one, too, and they might be
more motivated/able as a project to chase after Intel's hardware
acceleration for CRCs one day. They already have code switching from C
to assembly to get extra performance out of their longest_match()
function. The PostgreSQL CRC code is unlikely to go into twiddling
assembly code, but zlib--which is usually linked in anyway--will.
And Adler-32 isn't just an option, it's named after a dude who works on
zlib, and I can see he's already playing with the Intel acceleration by
some of his recent answers at
http://stackoverflow.com/users/1180620/mark-adler
I just re-discovered Ross Williams' CRC guide, which was already
referenced in pg_crc_tables.h, so I think I'm getting close to being
caught up on all the options here. Simon suggested the other day that
we should make the exact checksum mechanism used pluggable at initdb
time, just some last minute alternatives checking on the performance of
the real server code. I've now got the WAL CRC32, the zlib CRC32, and
the Intel-derived versions Ants hacked on to compare.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 00:11:13 |
| Message-ID: | CA+CSw_uXO-fRkuzL0Yzs0wSdL8dipZV-ugMvYN-yV45SGUBU2w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 20, 2013 at 12:52 AM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 3/19/13 6:08 PM, Ants Aasma wrote:
>>
>> My main worry is that there is a reasonably
>> large population of users out there that don't have that acceleration
>> capability and will have to settle for performance overhead 4x worse
>> than what you currently measured for a shared buffer swapping
>> workload.
>
>
> That would be very bad. I want to keep hammering on this part of the
> implementation. If the only style of checksum that's computationally
> feasible is the Fletcher one that's already been done--if that approach is
> basically the most expensive one that's practical to use--I'd still consider
> that a major win over doing nothing.
Well there is also the SIMD checksum that outperforms hardware
assisted CRC's, is almost 3 times as fast as Fletcher on the most
popular platform, should run fast on every CPU that has vector
instructions (almost all server CPUs from the last 10 years), should
run fast even on last two generations of cellphone CPUs and I don't
see any obvious errors that it misses. It will require some
portability work (maybe use intrinsics instead of relying on the
vectorizer) but I don't see why it wouldn't work.
> While being a lazy researcher today instead of writing code, I discovered
> that the PNG file format includes a CRC-32 on its data chunks, and to
> support that there's a CRC32 function inside of zlib:
> http://www.zlib.net/zlib_tech.html
>
> Is there anywhere that compiles a PostgreSQL --without-zlib that matters?
>
> The UI looks like this:
>
> ZEXTERN uLong ZEXPORT crc32 OF((uLong crc, const Bytef *buf, uInt len));
>
> And they've already put some work into optimizing its table-driven
> implementation. Seems possible to punt the whole problem of how to do this
> efficiently toward the zlib developers, let them drop into assembly to get
> the best possible Intel acceleration etc. one day.
That's the same byte at a time lookup-table algorithm that Intel uses
in the slice-by-8 method, zlib uses a 4 level lookup table for a
smaller table but more overhead. Also, zlib uses the 0x04C11DB7
polynomial that is not supported by the Intel accelerated crc32c
instruction. I believe that if we go crc32 route we should definitely
pick the Castagnoli polynomial that atleast has the hope of being
accelerated.
I copied crc32.c, crc32.h and zutil.h from zlib to the test framework
and ran the tests. While at it I also did a version where the fletcher
loop was unrolled by hand 8 times.
Results on sandy bridge (plain -O2 compile):
CRC32 slicing by 8 Algorithm (bytes/cycle), 0.522284
CRC32 zlib (bytes/cycle), 0.308307
Fletcher Algorithm: (bytes/cycle), 1.891964
Fletcher Algorithm hand unrolled: (bytes/cycle), 3.306666
SIMD Algorithm (gcc): (bytes/cycle), 0.572407
SIMD Algorithm (hand coded): (bytes/cycle), 9.124589
Results from papers:
crc32c instruction (castagnoli only): 6.8 bytes/cycle
pqlmulqdq based crc32: 0.9 bytes/cycle
Fletcher is also still a strong contender, we just need to replace the
255 modulus with something less prone to common errors, maybe use
65521 as the modulus. I'd have to think how to best combine the values
in that case. I believe we can lose the property that neither byte can
be zero, just avoiding both being zero seems good enough to me.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 00:17:12 |
| Message-ID: | CA+U5nMJmYF2UzBfX2SC9+TG_69zgfxd5mD6krYcqJOHpH+f0Ow@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 20 March 2013 00:03, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> Simon suggested the other day that we should make the
> exact checksum mechanism used pluggable at initdb time, just some last
> minute alternatives checking on the performance of the real server code.
> I've now got the WAL CRC32, the zlib CRC32, and the Intel-derived versions
> Ants hacked on to compare.
Selectable, not pluggable.
I think the safe option is to calculate WAL CRC32, take the lowest 16
bits and use that.
We know that will work, has reasonable distribution characteristics
and might even speed things up rather than have two versions of CRC in
the CPU cache. It also gives us just one set of code to tune to cover
both.
I'd rather get this committed with a safe option and then y'all can
discuss the fine merits of each algorithm at leisure.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Daniel Farina <daniel(at)heroku(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 00:54:14 |
| Message-ID: | 514908B6.30306@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/19/13 8:17 PM, Simon Riggs wrote:
> We know that will work, has reasonable distribution characteristics
> and might even speed things up rather than have two versions of CRC in
> the CPU cache.
That sounds reasonable to me. All of these CRC options have space/time
trade-offs via how large the lookup tables they use are. And if those
are already sitting in the CPU data cache via their use in the WAL
writes, using them for this purpose too could give them an advantage
that's not obvious in a synthetic test. I'm curious how that plays out
when multiple cores are involved too.
It would be hilarious if optimizing the CRC calculation makes WAL-heavy
workloads with checksums still net faster in the next release. Makes me
wonder how much of the full-page write overhead is being gobbled up by
CRC time already, on systems with a good sized write cache.
> I'd rather get this committed with a safe option and then y'all can
> discuss the fine merits of each algorithm at leisure.
Yes, that's what we're already doing--it just looks like work :)
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 02:05:26 |
| Message-ID: | 17821.1363745126@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Greg Smith <greg(at)2ndQuadrant(dot)com> writes:
> While being a lazy researcher today instead of writing code, I
> discovered that the PNG file format includes a CRC-32 on its data
> chunks, and to support that there's a CRC32 function inside of zlib:
> http://www.zlib.net/zlib_tech.html
Hah, old sins keep coming back to haunt one ;-)
Keep in mind that PNG was designed in 1995, and that any speed
considerations in that spec were decided in the context of whether it
would take noticeably longer to view an image downloaded over analog
dialup. That design context also informed a greater interest in error
checking than has been seen in any other image file format before (or
since, I believe).
> And they've already put some work into optimizing its table-driven
> implementation. Seems possible to punt the whole problem of how to do
> this efficiently toward the zlib developers, let them drop into assembly
> to get the best possible Intel acceleration etc. one day.
I would not hold my breath waiting for any such work from either the
zlib or libpng developers; both of those projects are basically in
maintenance mode AFAIK. If we want hardware acceleration we're going
to have to deal with the portability issues ourselves.
FWIW, I would argue that any tradeoffs we make in this area must be made
on the assumption of no such acceleration. If we can later make things
better for Intel(TM) users, that's cool, but let's not screw those using
other CPUs.
regards, tom lane
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 03:40:26 |
| Message-ID: | 51492FAA.2000200@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/19/13 10:05 PM, Tom Lane wrote:
> FWIW, I would argue that any tradeoffs we make in this area must be made
> on the assumption of no such acceleration. If we can later make things
> better for Intel(TM) users, that's cool, but let's not screw those using
> other CPUs.
I see compatibility with the acceleration as a tie-breaker. If there's
two approaches that are otherwise about equal, such as choosing the
exact CRC polynomial, you might as well pick the one that works faster
with Intel's SSE. I'll make sure that this gets benchmarked soon on a
decent AMD system too though. I've been itching to assemble a 24 core
AMD box at home anyway, this gives me an excuse to pull the trigger on that.
Thanks for the summary of how you view the zlib/libpng project state. I
saw 4 releases from zlib in 2012, so it seemed possible development
might still move forward there.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 10:31:10 |
| Message-ID: | CA+CSw_toidEtAh6uFP-tUgyY226b9hSru3A7YECpxEALL2oaqg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 20, 2013 at 5:40 AM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> I see compatibility with the acceleration as a tie-breaker. If there's two
> approaches that are otherwise about equal, such as choosing the exact CRC
> polynomial, you might as well pick the one that works faster with Intel's
> SSE. I'll make sure that this gets benchmarked soon on a decent AMD system
> too though. I've been itching to assemble a 24 core AMD box at home anyway,
> this gives me an excuse to pull the trigger on that.
I went ahead and changed the hand coded ASM to do 16bit sums so it's
fully SSE2 based. While at it I moved some explicit address
calculation in the inner loop into addressing commands. I then tested
this on a 6 year old low end AMD Athlon 64 (I think it's a K8) for a
not-so-recent CPU data point. Results from a plain -O2 compile:
CRC32 slicing by 8 Algorithm (bytes/cycle), 0.649208
CRC32 zlib (bytes/cycle), 0.405863
Fletcher Algorithm: (bytes/cycle), 1.309119
Fletcher Algorithm hand unrolled: (bytes/cycle), 3.063854
SIMD Algorithm (gcc): (bytes/cycle), 0.453141
SIMD Algorithm (hand coded): (bytes/cycle), 4.481808
Slower speed of the SIMD is expected here as K8 only has 64bit data
paths. It does surprsiginly well on the CRC32 algorithm, probably
thanks to lower L1 latency.
The asm rewrite made Intel also faster, now runs on Sandy Bridge at
11.2 bytes/cycle.
New version of code attached for anyone who would like to test. Build
with "gcc -g -O2 crc.c 8x256_tables.c -lm -o crc". Run with "./crc -t
warm -d warm -i 1 -p 8192 -n 1000000". Should run without errors on
all x86-64 CPU's.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| intel-slice-by-8.tar.gz | application/x-gzip | 66.2 KB |
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 11:01:28 |
| Message-ID: | CA+CSw_uSZexiHbRTrmUpeiFGQVw8K9mhS5LiGCcfT83aO_b-2g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 20, 2013 at 12:31 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> New version of code attached for anyone who would like to test. Build
> with "gcc -g -O2 crc.c 8x256_tables.c -lm -o crc". Run with "./crc -t
> warm -d warm -i 1 -p 8192 -n 1000000". Should run without errors on
> all x86-64 CPU's.
I just noticed that I accidentally omitted the slash from the prefix
when creating the archive. Here is the archive that has correct file
names and extracts into a subdir.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| intel-slice-by-8.tar.gz | application/x-gzip | 66.2 KB |
| From: | Greg Stark <stark(at)mit(dot)edu> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 12:13:51 |
| Message-ID: | CAM-w4HO8jQ_+fzRiA5_VHx8zxd41pf7gTpbD=o7kbu+bjyYWWQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 5:52 PM, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> With a potential 10-20% overhead, I am unclear who would enable this at
> initdb time.
For what it's worth I think cpu overhead of the checksum is totally a
red herring.. Of course there's no reason not to optimize it to be as
fast as possible but if we say there's a 10% cpu overhead due to
calculating the checksum users will think that's perfectly reasonable
trade-off and have no trouble looking at their cpu utilization and
deciding whether they have that overhead to spare. They can always buy
machines with more cores anyways.
Added I/O overhead, especially fsync latency is the performance impact
that I think we should be focusing on. Uses will be totally taken by
surprise to hear that checksums require I/O. And fsync latency to the
xlog is very very difficult to reduce. You can buy more hard drives
until the cows come home and the fsync latency will hardly change.
--
greg
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-20 13:41:25 |
| Message-ID: | 20130320134125.GB25125@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 01:52:58PM -0400, Bruce Momjian wrote:
> I assume a user would wait until they suspected corruption to turn it
> on, and because it is only initdb-enabled, they would have to
> dump/reload their cluster. The open question is whether this is a
> usable feature as written, or whether we should wait until 9.4.
>
> pg_upgrade can't handle this because the old/new clusters would have the
> same catalog version number and the tablespace directory names would
> conflict. Even if they are not using tablespaces, the old heap/index
> files would not have checksums and therefore would throw an error as
> soon as you accessed them. In fact, this feature is going to need
> pg_upgrade changes to detect from pg_controldata that the old/new
> clusters have the same checksum setting.
A few more issues with pg_upgrade: if we ever decide to change the
checksum calculation in a later major release, pg_upgrade might not work
because of the checksum change but could still work for users who don't
use checksums.
Also, while I understand why we have to set the checksum option at
initdb time, it seems we could enable users to turn it off after initdb
--- is there any mechanism for this?
Also, if a users uses checksums in 9.3, could they initdb without
checksums in 9.4 and use pg_upgrade? As coded, the pg_controldata
checksum settings would not match and pg_upgrade would throw an error,
but it might be possible to allow this, i.e. you could go from checksum
to no checksum initdb clusters, but not from no checksum to checksum. I
am wondering if the patch should reflect this.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-22 01:04:45 |
| Message-ID: | 1363914285.1618.38.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-03-20 at 02:11 +0200, Ants Aasma wrote:
> Fletcher is also still a strong contender, we just need to replace the
> 255 modulus with something less prone to common errors, maybe use
> 65521 as the modulus. I'd have to think how to best combine the values
> in that case. I believe we can lose the property that neither byte can
> be zero, just avoiding both being zero seems good enough to me.
Agreed on all points.
I've been following your analysis and testing, and it looks like there
are still at least three viable approaches:
1. Some variant of Fletcher
2. Some variant of CRC32
3. Some SIMD-based checksum
Each of those has some open implementation questions, as well. If we
settle on one of those approaches, we don't necessarily need the fastest
implementation right away. I might even argue that the first patch to be
committed should be a simple implementation of whatever algorithm we
choose, and then optimization should be done in a separate patch (if it
is tricky to get right).
Of course, it's hard to settle on the general algorithm to use without
knowing the final performance numbers. So right now I'm in somewhat of a
holding pattern until we settle on something.
Regards,
Jeff Davis
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-22 15:09:53 |
| Message-ID: | CA+CSw_su1fopLNBz1NAfkSNw4_=gv+5pf0KdLQmpvuKW1Q4v+Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Mar 22, 2013 at 3:04 AM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> I've been following your analysis and testing, and it looks like there
> are still at least three viable approaches:
>
> 1. Some variant of Fletcher
> 2. Some variant of CRC32
> 3. Some SIMD-based checksum
>
> Each of those has some open implementation questions, as well. If we
> settle on one of those approaches, we don't necessarily need the fastest
> implementation right away. I might even argue that the first patch to be
> committed should be a simple implementation of whatever algorithm we
> choose, and then optimization should be done in a separate patch (if it
> is tricky to get right).
+1 on correct first, fast second.
> Of course, it's hard to settle on the general algorithm to use without
> knowing the final performance numbers. So right now I'm in somewhat of a
> holding pattern until we settle on something.
For performance the K8 results gave me confidence that we have a
reasonably good overview what the performance is like for the class of
CPU's that PostgreSQL is likely to run on. I don't think there is
anything left to optimize there, all algorithms are pretty close to
maximum theoretical performance. Still, benchmarks on AMD's Bulldozer
arch and maybe on some non-x86 machines (Power, Itanium, Sparc) would
be very welcome to ensure that I haven't missed anything.
To see real world performance numbers I dumped the algorithms on top
of the checksums patch. I set up postgres with 32MB shared buffers,
and ran with concurrency 4 select only pgbench and a worst case
workload, results are median of 5 1-minute runs. I used fletcher as it
was in the checksums patch without unrolling. Unrolling would cut the
performance hit by a third or so.
The worst case workload is set up using
CREATE TABLE sparse (id serial primary key, v text) WITH (fillfactor=10);
INSERT INTO sparse (v) SELECT REPEAT('x', 1000) FROM generate_series(1,100000);
VACUUM ANALYZE sparse;
The test query itself is a simple SELECT count(v) FROM sparse;
Results for the worst case workload:
No checksums: tps = 14.710519
Fletcher checksums: tps = 10.825564 (1.359x slowdown)
CRC checksums: tps = 5.844995 (2.517x slowdown)
SIMD checksums: tps = 14.062388 (1.046x slowdown)
Results for pgbench scale 100:
No checksums: tps = 56623.819783
Fletcher checksums: tps = 55282.222687 (1.024x slowdown)
CRC Checksums: tps = 50571.324795 (1.120x slowdown)
SIMD Checksums: tps = 56608.888985 (1.000x slowdown)
So to conclude, the 3 approaches:
CRC:
Time to checksum 8192 bytes:
12'000 - 16'000 cycles best case without special hardware
1'200 cycles with hardware (new Intel only)
Code size: 131 bytes
* Can calculate arbitrary number of bytes per invocation, state is 4
bytes. Implementation can be shared with WAL.
* Quite slow without hardware acceleration.
* Software implementation requires a 8kB table for calculation or it
will be even slower. Quite likely to fall out of cache.
* If we wish to use hardware acceleration then the polynomial should
be switched to Castagnoli. I think the old polynomial needs to stay as
the values seem to be stored in indexes by tsvector compression and
multibyte trigrams. (not 100% sure, just skimmed the code)
* Error detection of 32bit Castagnoli CRC is known to be good, the
effect of truncating to 16 bits is not analyzed yet.
Fletcher:
Time to checksum 8192 bytes:
2'600 cycles +- 100
Code size: 170 bytes unrolled
* Very simple implementation for optimal speed.
* Needs to calculate 4 bytes at a time, requires 8 bytes of state.
Implementation that can work for WAL would be tricky but not
impossible. Probably wouldn't share code.
* Should give good enough error detection with suitable choice for
final recombination.
SIMD Checksums:
Time to checksum 8192 bytes:
730 cycles for processors with 128bit SIMD units
1830 cycles for processors with 64bit SIMD units
Code size: 436 bytes
* Requires vectorization, intrinsics or ASM for decent performance.
* Needs to calculate 128bytes at a time, requires 128 bytes of state.
Using for anything other than summing fixed size blocks looks tricky.
* Loosely based on Fowler-Noll-Vo and should have reasonably good
error detection capabilities.
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-22 17:35:08 |
| Message-ID: | 1363973708.18894.21.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-03-22 at 17:09 +0200, Ants Aasma wrote:
> For performance the K8 results gave me confidence that we have a
> reasonably good overview what the performance is like for the class of
> CPU's that PostgreSQL is likely to run on. I don't think there is
> anything left to optimize there, all algorithms are pretty close to
> maximum theoretical performance.
Great work!
> The worst case workload is set up using
> CREATE TABLE sparse (id serial primary key, v text) WITH (fillfactor=10);
> INSERT INTO sparse (v) SELECT REPEAT('x', 1000) FROM generate_series(1,100000);
> VACUUM ANALYZE sparse;
>
> The test query itself is a simple SELECT count(v) FROM sparse;
>
> Results for the worst case workload:
> No checksums: tps = 14.710519
> Fletcher checksums: tps = 10.825564 (1.359x slowdown)
> CRC checksums: tps = 5.844995 (2.517x slowdown)
> SIMD checksums: tps = 14.062388 (1.046x slowdown)
I assume this is in the "bad region" identified by Greg, where there is
no disk activity, but shared_buffers is small, leading to a lot of
movement between the OS cache and shared buffers?
What do you mean by TPS exactly? If the select query is writing hint
bits, then you wouldn't be able to repeat it because they are already
set. So are you repeating the creation/loading of the table, as well?
> Results for pgbench scale 100:
> No checksums: tps = 56623.819783
> Fletcher checksums: tps = 55282.222687 (1.024x slowdown)
> CRC Checksums: tps = 50571.324795 (1.120x slowdown)
> SIMD Checksums: tps = 56608.888985 (1.000x slowdown)
>
> So to conclude, the 3 approaches:
Great analysis. Still a tough choice.
One thing that might be interesting is to look at doing SIMD for both
data and WAL. I wonder if that would be a noticeable speedup for WAL
full-page writes? That would give greater justification for the extra
work it will take (intrinsics/ASM), and it would be a nice win for
non-checksum users.
I also notice that http://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%
80%93Vo_hash_function explicitly mentions adapting FNV to a smaller
size. That gives me a little more confidence. Do you have other links we
should read about this approach, or possible weaknesses?
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-22 18:00:49 |
| Message-ID: | 1363975249.18894.33.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-03-22 at 17:09 +0200, Ants Aasma wrote:
> So to conclude, the 3 approaches:
One other question: assuming that the algorithms use the full 16-bit
space, is there a good way to avoid zero without skewing the result? Can
we do something like un-finalize (after we figure out that it's zero),
compute in an extra salt value, and then re-finalize? That might work
for Fletcher; but I don't think that works for CRC or Fowler-Noll-Vo
because the final value is the same as the state.
I'm still slightly concerned about differentiating checksummed pages in
the future if we want to offer a transition path, since we no longer use
header bits. Avoiding zero might help us there. Hopefully not necessary,
but something we might find useful. Also, it would help us identify
situations where the checksum is never set.
Regards,
Jeff Davis
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-22 18:24:45 |
| Message-ID: | CA+CSw_vGGpbomdXOnXdkPaAbxmF4RXJF4Mo3L-AkFi9ZHSUqhQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Mar 22, 2013 at 7:35 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Fri, 2013-03-22 at 17:09 +0200, Ants Aasma wrote:
>> For performance the K8 results gave me confidence that we have a
>> reasonably good overview what the performance is like for the class of
>> CPU's that PostgreSQL is likely to run on. I don't think there is
>> anything left to optimize there, all algorithms are pretty close to
>> maximum theoretical performance.
>
> Great work!
Thanks.
>> The worst case workload is set up using
>> CREATE TABLE sparse (id serial primary key, v text) WITH (fillfactor=10);
>> INSERT INTO sparse (v) SELECT REPEAT('x', 1000) FROM generate_series(1,100000);
>> VACUUM ANALYZE sparse;
>>
>> The test query itself is a simple SELECT count(v) FROM sparse;
>>
>> Results for the worst case workload:
>> No checksums: tps = 14.710519
>> Fletcher checksums: tps = 10.825564 (1.359x slowdown)
>> CRC checksums: tps = 5.844995 (2.517x slowdown)
>> SIMD checksums: tps = 14.062388 (1.046x slowdown)
>
> I assume this is in the "bad region" identified by Greg, where there is
> no disk activity, but shared_buffers is small, leading to a lot of
> movement between the OS cache and shared buffers?
>
> What do you mean by TPS exactly? If the select query is writing hint
> bits, then you wouldn't be able to repeat it because they are already
> set. So are you repeating the creation/loading of the table, as well?
The table is created once, size is 800MB with one hinted tuple per
page. Shared buffers is set to 32MB, machine is Intel Core i5-2500K
with 16GB of memory (2 memory channels, 1333MHz, overheads are likely
to be larger with faster memory). This is the worst case workload for
in-memory workload that doesn't fit into shared_buffers as almost no
work other than swapping buffer pages in is done. I think things like
bitmap heap scans might show similar characteristics.
>> Results for pgbench scale 100:
>> No checksums: tps = 56623.819783
>> Fletcher checksums: tps = 55282.222687 (1.024x slowdown)
>> CRC Checksums: tps = 50571.324795 (1.120x slowdown)
>> SIMD Checksums: tps = 56608.888985 (1.000x slowdown)
>>
>> So to conclude, the 3 approaches:
>
> Great analysis. Still a tough choice.
>
> One thing that might be interesting is to look at doing SIMD for both
> data and WAL. I wonder if that would be a noticeable speedup for WAL
> full-page writes? That would give greater justification for the extra
> work it will take (intrinsics/ASM), and it would be a nice win for
> non-checksum users.
Andres showed that switching out the existing CRC for zlib's would
result in 8-30% increase in INSERT-SELECT speed
(http://www.postgresql.org/message-id/201005202227.49990.andres@anarazel.de)
with the speeded up CRC still showing up as 10% of the profile. So I
guess another 5% speedup by doing the CRC 8 bytes at a time instead of
the used 4. And another couple % by using Fletcher or SIMD.
> I also notice that http://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%
> 80%93Vo_hash_function explicitly mentions adapting FNV to a smaller
> size. That gives me a little more confidence. Do you have other links we
> should read about this approach, or possible weaknesses?
It mentions that one should use 32bit FNV and fold it down to 16bit
via xor. This doesn't work here because SSE2 doesn't have pmulld
(SSE4.1). I have taken some liberties here by actually doing 64 16bit
FNV like operations in parallel and then doing an FNV like combination
of them at the end. However the choices there are concerned with good
hashing performance, while for checksums it should matter much even if
the average error detection rate goes from 99.998% to 99.99% as long
as common error scenarios don't match up with the collisions. If
decide to go this route we should definitely research what the
effectiveness consequences here are and what are good choices for the
prime values used. On the face of it multiply by prime and add/xor
looks like it provides pretty good mixing, resists transposed
sequences, zeroing out blocks. The worst case seems to be bit errors.
As far as I can see, this implementation should detect all single bit
errors, but if one of the bit errors is on MSB, a second single error
in MSB will cancel it out. I haven't done the math but it should still
work out as better than 99% chance to detect random 2 bit errors.
On Fri, Mar 22, 2013 at 8:00 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Fri, 2013-03-22 at 17:09 +0200, Ants Aasma wrote:
>> So to conclude, the 3 approaches:
>
> One other question: assuming that the algorithms use the full 16-bit
> space, is there a good way to avoid zero without skewing the result? Can
> we do something like un-finalize (after we figure out that it's zero),
> compute in an extra salt value, and then re-finalize? That might work
> for Fletcher; but I don't think that works for CRC or Fowler-Noll-Vo
> because the final value is the same as the state.
Taking the Fletcher or CRC32 result modulo 65521 (largest prime <
16bits) only gives a very slight skew that shouldn't really matter for
all practical purposes. For the SIMD FNV implementation we can just
reduce the 64 16bit values down to 4, concat them together to a single
64bit number (by just skipping the last two reduction steps) and take
a modulo from that.
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 03:14:35 |
| Message-ID: | 514D1E1B.7020600@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/23/2013 02:00 AM, Jeff Davis wrote:
> On Fri, 2013-03-22 at 17:09 +0200, Ants Aasma wrote:
>> So to conclude, the 3 approaches:
> One other question: assuming that the algorithms use the full 16-bit
> space, is there a good way to avoid zero without skewing the result? Can
> we do something like un-finalize (after we figure out that it's zero),
> compute in an extra salt value, and then re-finalize? That might work
> for Fletcher; but I don't think that works for CRC or Fowler-Noll-Vo
> because the final value is the same as the state.
>
> I'm still slightly concerned about differentiating checksummed pages in
> the future if we want to offer a transition path, since we no longer use
> header bits. Avoiding zero might help us there. Hopefully not necessary,
> but something we might find useful.
Avoiding a magic value for "not checksummed" might help, but IMO zero is
a terrible choice for that since it's one of the most likely things to
be written in chunks over good data during some kinds of corruption
event (memory overwriting, etc).
Making zero a "not checksummed" magic value would significantly detract
from the utility of checksums IMO.
> Also, it would help us identify
> situations where the checksum is never set.
Now that seems more useful - "ERROR: BUG or disk corruption found".
--
Craig Ringer http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 04:19:51 |
| Message-ID: | 514D2D67.2070404@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I realize Simone relented on this, but FWIW...
On 3/16/13 4:02 PM, Simon Riggs wrote:
> Most other data we store doesn't consist of
> large runs of 0x00 or 0xFF as data. Most data is more complex than
> that, so any runs of 0s or 1s written to the block will be detected.
...
It's not that uncommon for folks to have tables that have a bunch of int[2,4,8]s all in a row, and I'd bet it's not uncommon for a lot of those fields to be zero.
> Checksums are for detecting problems. What kind of problems? Sporadic
> changes of bits? Or repeated errors. If we were trying to trap
> isolated bit changes then CRC-32 would be appropriate. But I'm
> assuming that whatever causes the problem is going to recur,
That's opposite to my experience. When we've had corruption events we will normally have one to several blocks with problems how up essentially all at once. Of course we can't prove that all the corruption happened at exactly the same time, but I believe it's a strong possibility. If it wasn't exactly the same time it was certainly over a span of minutes to hours... *but* we've never seen new corruption occur after we start an investigation (we frequently wait several hours for the next time we can take an outage without incurring a huge loss in revenue). That we would run for a number of hours with no additional corruption leads me to believe that whatever caused the corruption was essentially a "one-time" [1] event.
[1] One-time except for the fact that there were several periods where we would have corruption occur in 12 or 6 month intervals.
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Daniel Farina <daniel(at)heroku(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 04:26:27 |
| Message-ID: | 514D2EF3.9050904@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/18/13 2:25 PM, Simon Riggs wrote:
> On 18 March 2013 19:02, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
>> On Sun, 2013-03-17 at 22:26 -0700, Daniel Farina wrote:
>>> as long as I am able to turn them off easily
>>
>> To be clear: you don't get the performance back by doing
>> "ignore_checksum_failure = on". You only get around the error itself,
>> which allows you to dump/reload the good data.
>
> Given that the worst pain point comes from setting hint bits during a
> large SELECT, it makes sense to offer an option to simply skip hint
> bit setting when we are reading data (SELECT, not
> INSERT/UPDATE/DELETE). That seems like a useful option even without
> checksums. I know I have seen cases across many releases where setting
> that would have been good, since it puts the cleanup back onto
> VACUUM/writers, rather than occasional SELECTs.
+1
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 04:35:35 |
| Message-ID: | 514D3117.9080201@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/20/13 8:41 AM, Bruce Momjian wrote:
> On Mon, Mar 18, 2013 at 01:52:58PM -0400, Bruce Momjian wrote:
>> I assume a user would wait until they suspected corruption to turn it
>> on, and because it is only initdb-enabled, they would have to
>> dump/reload their cluster. The open question is whether this is a
>> usable feature as written, or whether we should wait until 9.4.
>>
>> pg_upgrade can't handle this because the old/new clusters would have the
>> same catalog version number and the tablespace directory names would
>> conflict. Even if they are not using tablespaces, the old heap/index
>> files would not have checksums and therefore would throw an error as
>> soon as you accessed them. In fact, this feature is going to need
>> pg_upgrade changes to detect from pg_controldata that the old/new
>> clusters have the same checksum setting.
>
> A few more issues with pg_upgrade: if we ever decide to change the
> checksum calculation in a later major release, pg_upgrade might not work
> because of the checksum change but could still work for users who don't
> use checksums.
>
> Also, while I understand why we have to set the checksum option at
> initdb time, it seems we could enable users to turn it off after initdb
> --- is there any mechanism for this?
>
> Also, if a users uses checksums in 9.3, could they initdb without
> checksums in 9.4 and use pg_upgrade? As coded, the pg_controldata
> checksum settings would not match and pg_upgrade would throw an error,
> but it might be possible to allow this, i.e. you could go from checksum
> to no checksum initdb clusters, but not from no checksum to checksum. I
> am wondering if the patch should reflect this.
If the docs don't warn about this, they should, but I don't think it's the responsibility of this patch to deal with that problem. The reason I don't believe this patch should deal with it is because that is a known, rather serious, limitation of pg_upgrade. It's something about pg_upgrade that just needs to be fixed, regardless of what patches might make the situation worse.
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Craig Ringer <craig(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 12:42:59 |
| Message-ID: | CA+CSw_sx6AqRST2sg2YN1vQFCaqQPcnZYqGPpUoT1mns3_63qw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Mar 23, 2013 at 5:14 AM, Craig Ringer <craig(at)2ndquadrant(dot)com> wrote:
> Making zero a "not checksummed" magic value would significantly detract
> from the utility of checksums IMO.
FWIW using 65521 modulus to compress larger checksums into 16 bits
will leave 14 non-zero values unused.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 13:10:30 |
| Message-ID: | 20130323131030.GB12686@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> >> Results for pgbench scale 100:
> >> No checksums: tps = 56623.819783
> >> Fletcher checksums: tps = 55282.222687 (1.024x slowdown)
> >> CRC Checksums: tps = 50571.324795 (1.120x slowdown)
> >> SIMD Checksums: tps = 56608.888985 (1.000x slowdown)
> >>
> >> So to conclude, the 3 approaches:
> >
> > Great analysis. Still a tough choice.
+1
> > One thing that might be interesting is to look at doing SIMD for both
> > data and WAL. I wonder if that would be a noticeable speedup for WAL
> > full-page writes? That would give greater justification for the extra
> > work it will take (intrinsics/ASM), and it would be a nice win for
> > non-checksum users.
>
> Andres showed that switching out the existing CRC for zlib's would
> result in 8-30% increase in INSERT-SELECT speed
> (http://www.postgresql.org/message-id/201005202227.49990.andres@anarazel.de)
> with the speeded up CRC still showing up as 10% of the profile. So I
> guess another 5% speedup by doing the CRC 8 bytes at a time instead of
> the used 4. And another couple % by using Fletcher or SIMD.
I am not sure the considerations for WAL are the same as for page checksums -
the current WAL code only computes the CRCs in rather small chunks, so very
pipelineable algorithms/implementations don't necessarly show the same benefit
for WAL as they do for page checksums...
And even if the checksumming were to be changed to compute the CRC in larger
chunks - a very sensible thing imo - it would still be relatively small sizes
in many workloads.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 13:36:03 |
| Message-ID: | CA+CSw_veVyAzw_ezWM1ezN7ahEkcqPHZoX0pBa0RcdqiH-KNtA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Mar 23, 2013 at 3:10 PM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
>> Andres showed that switching out the existing CRC for zlib's would
>> result in 8-30% increase in INSERT-SELECT speed
>> (http://www.postgresql.org/message-id/201005202227.49990.andres@anarazel.de)
>> with the speeded up CRC still showing up as 10% of the profile. So I
>> guess another 5% speedup by doing the CRC 8 bytes at a time instead of
>> the used 4. And another couple % by using Fletcher or SIMD.
>
> I am not sure the considerations for WAL are the same as for page checksums -
> the current WAL code only computes the CRCs in rather small chunks, so very
> pipelineable algorithms/implementations don't necessarly show the same benefit
> for WAL as they do for page checksums...
Sure, but I think that WAL checksums are not a big overhead in that case anyway.
I should point out that getting the SIMD algorithm to not be a loss
for small variable sized workloads will take considerable amount of
effort and code. Whereas it's quite easy for pipelined CRC32 and
Fletcher (or should I say Adler as we want to use mod 65521).
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-23 13:55:39 |
| Message-ID: | 20130323135539.GF12686@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-03-23 15:36:03 +0200, Ants Aasma wrote:
> On Sat, Mar 23, 2013 at 3:10 PM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> >> Andres showed that switching out the existing CRC for zlib's would
> >> result in 8-30% increase in INSERT-SELECT speed
> >> (http://www.postgresql.org/message-id/201005202227.49990.andres@anarazel.de)
> >> with the speeded up CRC still showing up as 10% of the profile. So I
> >> guess another 5% speedup by doing the CRC 8 bytes at a time instead of
> >> the used 4. And another couple % by using Fletcher or SIMD.
> >
> > I am not sure the considerations for WAL are the same as for page checksums -
> > the current WAL code only computes the CRCs in rather small chunks, so very
> > pipelineable algorithms/implementations don't necessarly show the same benefit
> > for WAL as they do for page checksums...
>
> Sure, but I think that WAL checksums are not a big overhead in that case anyway.
I have seen profiles that indicate rather the contrary... Even in the optimal
case of no FPWs a single heap_insert() results in the CRC computed in 5 steps
or so. 4 of them over potentially noncontiguous pointer addressed memory.
If you add an index or two where the situation is the same the slowdown is not
all that surprising.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Jim Nasby <jim(at)nasby(dot)net> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-25 13:25:44 |
| Message-ID: | 20130325132544.GA17029@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Mar 22, 2013 at 11:35:35PM -0500, Jim Nasby wrote:
> On 3/20/13 8:41 AM, Bruce Momjian wrote:
> >Also, if a users uses checksums in 9.3, could they initdb without
> >checksums in 9.4 and use pg_upgrade? As coded, the pg_controldata
> >checksum settings would not match and pg_upgrade would throw an
> >error, but it might be possible to allow this, i.e. you could go from
> >checksum to no checksum initdb clusters, but not from no checksum to
> >checksum. I am wondering if the patch should reflect this.
>
> If the docs don't warn about this, they should, but I don't think it's
> the responsibility of this patch to deal with that problem. The reason
> I don't believe this patch should deal with it is because that is a
> known, rather serious, limitation of pg_upgrade. It's something about
> pg_upgrade that just needs to be fixed, regardless of what patches
> might make the situation worse.
Huh? It wasn't a "serious limitation" of pg_upgrade until this patch.
What limitation does pg_upgrade have regardless of this patch?
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-25 13:51:45 |
| Message-ID: | 20130325135145.GB17029@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Mar 22, 2013 at 05:09:53PM +0200, Ants Aasma wrote:
> To see real world performance numbers I dumped the algorithms on top
> of the checksums patch. I set up postgres with 32MB shared buffers,
> and ran with concurrency 4 select only pgbench and a worst case
> workload, results are median of 5 1-minute runs. I used fletcher as it
> was in the checksums patch without unrolling. Unrolling would cut the
> performance hit by a third or so.
>
> The worst case workload is set up using
> CREATE TABLE sparse (id serial primary key, v text) WITH (fillfactor=10);
> INSERT INTO sparse (v) SELECT REPEAT('x', 1000) FROM generate_series(1,100000);
> VACUUM ANALYZE sparse;
>
> The test query itself is a simple SELECT count(v) FROM sparse;
>
> Results for the worst case workload:
> No checksums: tps = 14.710519
> Fletcher checksums: tps = 10.825564 (1.359x slowdown)
> CRC checksums: tps = 5.844995 (2.517x slowdown)
> SIMD checksums: tps = 14.062388 (1.046x slowdown)
>
> Results for pgbench scale 100:
> No checksums: tps = 56623.819783
> Fletcher checksums: tps = 55282.222687 (1.024x slowdown)
> CRC Checksums: tps = 50571.324795 (1.120x slowdown)
> SIMD Checksums: tps = 56608.888985 (1.000x slowdown)
Great analysis. Is there any logic to using a lighter-weight checksum
calculation for cases where the corruption is rare? For example, we
know that network transmission can easily be corrupted, while buffer
corruption is rare, and if corruption happens once, it is likely to
happen again.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-26 01:34:49 |
| Message-ID: | CA+CSw_v3PUaq_TD5gt+v1=7KSSPOKSKzkLDigg+TkpRpvB8gYQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 25, 2013 at 3:51 PM, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> Great analysis. Is there any logic to using a lighter-weight checksum
> calculation for cases where the corruption is rare? For example, we
> know that network transmission can easily be corrupted, while buffer
> corruption is rare, and if corruption happens once, it is likely to
> happen again.
It's a matter of use-cases. 16bit (or 32bit, or even 64bit) checksums
will never be enough to give good enough guarantees about correctness
of data. They are at best the canaries in the coal mine, alerting
about underlying issues in the database setup. For our use case one
single corruption only has a fraction of a percent of chance of
escaping. Multiple errors quickly bring the probability of ignoring
corruption into the range of winning two lotteries at once while being
struck by lightning. The main thing to look out for is that we don't
have any blind spots for conceivable systemic errors. If we decide to
go with the SIMD variant then I intend to figure out what the blind
spots are and show that they don't matter.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-27 14:06:19 |
| Message-ID: | CA+TgmoZw25zxAmKm1tdP_AbWXoyjLBOw4Q0yH-AWLdNfOqqMRA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 18, 2013 at 4:31 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> to get them going again. If the install had checksums, I could have figured
> out which blocks were damaged and manually fixed them, basically go on a
> hunt for torn pages and the last known good copy via full-page write.
Wow. How would you extract such a block image from WAL?
That would be a great tool to have, but I didn't know there was any
practical way of doing it today.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-27 14:15:19 |
| Message-ID: | 20130327141519.GC7148@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-03-27 10:06:19 -0400, Robert Haas wrote:
> On Mon, Mar 18, 2013 at 4:31 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> > to get them going again. If the install had checksums, I could have figured
> > out which blocks were damaged and manually fixed them, basically go on a
> > hunt for torn pages and the last known good copy via full-page write.
>
> Wow. How would you extract such a block image from WAL?
>
> That would be a great tool to have, but I didn't know there was any
> practical way of doing it today.
Given pg_xlogdump that should be doable with 5min of hacking in 9.3. Just add
some hunk to write out the page to the if (config->bkp_details) hunk in
pg_xlogdump.c:XLogDumpDisplayRecord. I have done that for some debugging already.
If somebody comes up with a sensible & simple UI for this I am willing to
propose a patch adding it to pg_xlogdump. One would have to specify the
rel/file/node, the offset, and the target file.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-29 01:02:06 |
| Message-ID: | CA+TgmoZaui-41k_20EVJgt_DynVUdTrE5txjgawBy391b_uD1w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Mar 27, 2013 at 10:15 AM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> On 2013-03-27 10:06:19 -0400, Robert Haas wrote:
>> On Mon, Mar 18, 2013 at 4:31 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
>> > to get them going again. If the install had checksums, I could have figured
>> > out which blocks were damaged and manually fixed them, basically go on a
>> > hunt for torn pages and the last known good copy via full-page write.
>>
>> Wow. How would you extract such a block image from WAL?
>>
>> That would be a great tool to have, but I didn't know there was any
>> practical way of doing it today.
>
> Given pg_xlogdump that should be doable with 5min of hacking in 9.3. Just add
> some hunk to write out the page to the if (config->bkp_details) hunk in
> pg_xlogdump.c:XLogDumpDisplayRecord. I have done that for some debugging already.
>
> If somebody comes up with a sensible & simple UI for this I am willing to
> propose a patch adding it to pg_xlogdump. One would have to specify the
> rel/file/node, the offset, and the target file.
Hmm. Cool. But, wouldn't the hard part be to figure out where to
start reading the WAL in search of the *latest* FPI?
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-29 07:05:00 |
| Message-ID: | 20130329070500.GE28736@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-03-28 21:02:06 -0400, Robert Haas wrote:
> On Wed, Mar 27, 2013 at 10:15 AM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> > On 2013-03-27 10:06:19 -0400, Robert Haas wrote:
> >> On Mon, Mar 18, 2013 at 4:31 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> >> > to get them going again. If the install had checksums, I could have figured
> >> > out which blocks were damaged and manually fixed them, basically go on a
> >> > hunt for torn pages and the last known good copy via full-page write.
> >>
> >> Wow. How would you extract such a block image from WAL?
> >>
> >> That would be a great tool to have, but I didn't know there was any
> >> practical way of doing it today.
> >
> > Given pg_xlogdump that should be doable with 5min of hacking in 9.3. Just add
> > some hunk to write out the page to the if (config->bkp_details) hunk in
> > pg_xlogdump.c:XLogDumpDisplayRecord. I have done that for some debugging already.
> >
> > If somebody comes up with a sensible & simple UI for this I am willing to
> > propose a patch adding it to pg_xlogdump. One would have to specify the
> > rel/file/node, the offset, and the target file.
>
> Hmm. Cool. But, wouldn't the hard part be to figure out where to
> start reading the WAL in search of the *latest* FPI?
I'd expect having to read the whole WAL and write out all the available
FPIs. You might be able to a guess a bit based on the LSN in the header.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-03-29 18:37:22 |
| Message-ID: | 5155DF62.9030807@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3/25/13 8:25 AM, Bruce Momjian wrote:
> On Fri, Mar 22, 2013 at 11:35:35PM -0500, Jim Nasby wrote:
>> >On 3/20/13 8:41 AM, Bruce Momjian wrote:
>>> > >Also, if a users uses checksums in 9.3, could they initdb without
>>> > >checksums in 9.4 and use pg_upgrade? As coded, the pg_controldata
>>> > >checksum settings would not match and pg_upgrade would throw an
>>> > >error, but it might be possible to allow this, i.e. you could go from
>>> > >checksum to no checksum initdb clusters, but not from no checksum to
>>> > >checksum. I am wondering if the patch should reflect this.
>> >
>> >If the docs don't warn about this, they should, but I don't think it's
>> >the responsibility of this patch to deal with that problem. The reason
>> >I don't believe this patch should deal with it is because that is a
>> >known, rather serious, limitation of pg_upgrade. It's something about
>> >pg_upgrade that just needs to be fixed, regardless of what patches
>> >might make the situation worse.
> Huh? It wasn't a "serious limitation" of pg_upgrade until this patch.
> What limitation does pg_upgrade have regardless of this patch?
The limitation that it depends on binary compatibility.
I suppose it's unfair to say that's a pg_upgrade limitation, but it's a certainly a limitation of Postgres upgrade capability. So far we've been able to skirt the issue but at some point we need to address this.
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-05 16:23:05 |
| Message-ID: | 1365178985.14231.84.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2013-03-26 at 03:34 +0200, Ants Aasma wrote:
> The main thing to look out for is that we don't
> have any blind spots for conceivable systemic errors. If we decide to
> go with the SIMD variant then I intend to figure out what the blind
> spots are and show that they don't matter.
Are you still looking into SIMD? Right now, it's using the existing CRC
implementation. Obviously we can't change it after it ships. Or is it
too late to change it already?
Regards,
Jeff Davis
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-05 18:39:03 |
| Message-ID: | CA+CSw_tMoA85e=1vS4oMjZjG2MR_huLiKoVPd80Dp5RURDSGcQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Apr 5, 2013 at 7:23 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Tue, 2013-03-26 at 03:34 +0200, Ants Aasma wrote:
>> The main thing to look out for is that we don't
>> have any blind spots for conceivable systemic errors. If we decide to
>> go with the SIMD variant then I intend to figure out what the blind
>> spots are and show that they don't matter.
>
> Are you still looking into SIMD? Right now, it's using the existing CRC
> implementation. Obviously we can't change it after it ships. Or is it
> too late to change it already?
Yes, I just managed to get myself some time so I can look at it some
more. I was hoping that someone would weigh in on what their
preferences are on the performance/effectiveness trade-off and the
fact that we need to use assembler to make it fly so I knew how to go
forward.
The worst blind spot that I could come up with was an even number of
single bit errors that are all on the least significant bit of 16bit
word. This type of error can occur in memory chips when row lines go
bad, usually stuck at zero or one. The SIMD checksum would have 50%
chance of detecting such errors (assuming reasonably uniform
distribution of 1 and 0 bits in the low order). On the other hand,
anyone caring about data integrity should be running ECC protected
memory anyway, making this particular error unlikely in practice.
Otherwise the algorithm seems reasonably good, it detects
transpositions, zeroing out ranges and other such common errors. It's
especially good on localized errors, detecting all single bit errors.
I did a quick test harness to empirically test the effectiveness of
the hash function. As test data I loaded an imdb dataset dump into
master and then concatenated everything in the database datadir except
pg_* together. That makes for a total of 2.8GB data. The test cases I
tried so far were randomized bit flips 1..4 per page, write 0x00 or
0xFF byte into each location on the page (1 byte error), zero out the
ending of the page starting from a random location and write a segment
of random garbage into the page. The partial write and bit flip tests
were repeated 1000 times per page. The results so far are here:
Test Detects Miss rate
----------------------------------------
Single bit flip 100.000000% 1:inf
Double bit flip 99.230267% 1:130
Triple bit flip 99.853346% 1:682
Quad bit flip 99.942418% 1:1737
Write 0x00 byte 99.999999% 1:148602862
Write 0xFF byte 99.999998% 1:50451919
Partial write 99.922942% 1:12988
Write garbage 99.998435% 1:63885
Unless somebody tells me not to waste my time I'll go ahead and come
up with a workable patch by Monday.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-05 19:02:24 |
| Message-ID: | 1365188544.7580.2907.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-04-05 at 21:39 +0300, Ants Aasma wrote:
> Yes, I just managed to get myself some time so I can look at it some
> more. I was hoping that someone would weigh in on what their
> preferences are on the performance/effectiveness trade-off and the
> fact that we need to use assembler to make it fly so I knew how to go
> forward.
My opinion is that we don't need to be perfect as long as we catch 99%
of random errors and we don't have any major blind spots. Also, the
first version doesn't necessarily need to perform well; we can leave
optimization as future work. Requiring assembly to achieve those
optimizations is a drawback in terms of maintainability, but it seems
isolated so I don't think it's a major problem.
Ideally, the algorithm would also be suitable for WAL checksums, and we
could eventually use it for that as well.
> The worst blind spot that I could come up with was an even number of
> single bit errors that are all on the least significant bit of 16bit
> word. This type of error can occur in memory chips when row lines go
> bad, usually stuck at zero or one.
We're not really trying to catch memory errors anyway. Of course it
would be nice, but I would rather have more people using a slightly
flawed algorithm than fewer using it because it has too great a
performance impact.
> Unless somebody tells me not to waste my time I'll go ahead and come
> up with a workable patch by Monday.
Sounds great to me, thank you.
Regards,
Jeff Davis
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-05 19:39:51 |
| Message-ID: | 515F2887.80001@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 4/5/13 12:23 PM, Jeff Davis wrote:
> Are you still looking into SIMD? Right now, it's using the existing CRC
> implementation. Obviously we can't change it after it ships. Or is it
> too late to change it already?
Simon just headed away for a break, so I'll try to answer this. He
committed with the truncated WAL CRC to get the feature in with as few
changes as possible. The idea was to see if any more serious problems
fell out ASAP, before getting any deeper in to adding more code for
optimization. The issues already spotted by Fujii Masao and Jeff Janes
suggest that was a good choice.
Since this is a initdb time change and not in the field yet, in theory
changes to the CRC method used could go along with a catversion bump.
At the point in the 9.3 release cycle where those stop being acceptable
then it's definitely too late. That's not quite yet though. Doing some
more tuning to make this feature faster during the alpha period is
something I would like to see the project consider.
I'm gearing up right now to help do more testing of the various options
that Ants has been generated. This week's progress was getting a good
AMD based system into my test farm, along with one of Seagate's new
drives with a built-in BBWC. (Their latest SSHD flash hybrid model
caches writes with a capacitor for clean shutdown on power loss)
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Kevin Grittner <kgrittn(at)ymail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-05 20:25:14 |
| Message-ID: | 1365193514.43330.YahooMailNeo@web162903.mail.bf1.yahoo.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> My opinion is that we don't need to be perfect as long as we
> catch 99% of random errors and we don't have any major blind
> spots.
+1
> Also, the first version doesn't necessarily need to perform well;
> we can leave optimization as future work.
+1, as long as we don't slow down instances not using the feature,
and we don't paint ourselves into a corner.
> We're not really trying to catch memory errors anyway.
+1
--
Kevin Grittner
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Kevin Grittner <kgrittn(at)ymail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-06 07:40:55 |
| Message-ID: | 515FD187.9050707@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 05.04.2013 23:25, Kevin Grittner wrote:
> Jeff Davis<pgsql(at)j-davis(dot)com> wrote:
>> Also, the first version doesn't necessarily need to perform well;
>> we can leave optimization as future work.
>
> +1, as long as we don't slow down instances not using the feature,
> and we don't paint ourselves into a corner.
Speaking of which: I did some profiling yesterday of a test case that's
heavy on WAL insertions, without checksums. I saw BufferGetLSNAtomic
consuming 1.57% of the CPU time. That's not much, but it's clearly
additional overhead caused by the checksums patch:
Events: 6K cycles
+ 26,60% postmaster postgres [.] XLogInsert
+ 6,15% postmaster postgres [.] LWLockAcquire
+ 4,74% postmaster postgres [.] LWLockRelease
+ 2,47% postmaster postgres [.] PageAddItem
+ 2,19% postmaster postgres [.] ReadBuffer_common
+ 2,18% postmaster postgres [.] heap_fill_tuple
+ 1,95% postmaster postgres [.] ExecNestLoop
+ 1,89% postmaster postgres [.] ExecModifyTable
+ 1,85% postmaster postgres [.] heap_insert
+ 1,82% postmaster postgres [.] heap_prepare_insert
+ 1,79% postmaster postgres [.] heap_form_tuple
+ 1,76% postmaster postgres [.] RelationGetBufferForTuple
+ 1,75% postmaster libc-2.13.so [.] __memcpy_ssse3
+ 1,73% postmaster postgres [.] PinBuffer
+ 1,67% postmaster postgres [.] hash_any
+ 1,64% postmaster postgres [.] ExecProcNode
+ 1,63% postmaster postgres [.] RelationPutHeapTuple
+ 1,57% postmaster postgres [.] BufferGetLSNAtomic
+ 1,51% postmaster postgres [.] ExecProject
+ 1,42% postmaster postgres [.] hash_search_with_hash_value
+ 1,34% postmaster postgres [.] AllocSetAlloc
+ 1,21% postmaster postgres [.] UnpinBuffer
+ 1,19% postmaster [kernel.kallsyms] [k] copy_user_generic_string
+ 1,13% postmaster postgres [.] MarkBufferDirty
+ 1,07% postmaster postgres [.] ExecScan
+ 1,00% postmaster postgres [.] ExecMaterializeSlot
AFAICS that could be easily avoided by doing a simple PageGetLSN() like
we used to, if checksums are not enabled. In XLogCheckBuffer:
> /*
> * XXX We assume page LSN is first data on *every* page that can be passed
> * to XLogInsert, whether it otherwise has the standard page layout or
> * not. We don't need the buffer header lock for PageGetLSN because we
> * have exclusive lock on the page and/or the relation.
> */
> *lsn = BufferGetLSNAtomic(rdata->buffer);
Also, the second sentence in the above comment is completely bogus now.
- Heikki
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Kevin Grittner <kgrittn(at)ymail(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-08 08:16:40 |
| Message-ID: | CA+U5nM+0Rvpc4wynwjerNk-WfWqhJ-mwNics=MT7w5X4f0UzBQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 6 April 2013 08:40, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> wrote:
> AFAICS that could be easily avoided by doing a simple PageGetLSN() like we
> used to, if checksums are not enabled. In XLogCheckBuffer:
>
> /*
>> * XXX We assume page LSN is first data on *every* page that can
>> be passed
>> * to XLogInsert, whether it otherwise has the standard page
>> layout or
>> * not. We don't need the buffer header lock for PageGetLSN
>> because we
>> * have exclusive lock on the page and/or the relation.
>> */
>> *lsn = BufferGetLSNAtomic(rdata->**buffer);
>>
>
> Also, the second sentence in the above comment is completely bogus now.
Both points addressed on separate commits.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-09 02:35:16 |
| Message-ID: | CA+CSw_s=XptYYott1oZLTgxgRfndBMCuVzCrTRNqt7GM47Yy_w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Apr 5, 2013 at 9:39 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> Unless somebody tells me not to waste my time I'll go ahead and come
> up with a workable patch by Monday.
And here you go. I decided to be verbose with the comments as it's
easier to delete a comment to write one. I also left in a huge jumble
of macros to calculate the contents of a helper var during compile
time. This can easily be replaced with the calculated values once we
settle on specific parameters.
Currently only x86-64 is implemented. 32bit x86 would be mostly a
copy-and-paste job, replacing 64bit pointer registers with 32bit ones.
For other platforms the simplest way would be to use a vectorizing
compiler on the generic variant. -funroll-loops -ftree-vectorize is
enough on gcc.
Quick bench results on the worst case workload:
master no checksums: tps = 15.561848
master with checksums: tps = 1.695450
simd checksums: tps = 14.602698
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| simd-checksums.patch | application/octet-stream | 11.3 KB |
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-09 07:03:59 |
| Message-ID: | CA+U5nML8JYeGqM-k4eEwNJi5H=U57oPLBsBDoZUv4cfcmdnpUA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 9 April 2013 03:35, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> On Fri, Apr 5, 2013 at 9:39 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> > Unless somebody tells me not to waste my time I'll go ahead and come
> > up with a workable patch by Monday.
>
> And here you go. I decided to be verbose with the comments as it's
> easier to delete a comment to write one. I also left in a huge jumble
> of macros to calculate the contents of a helper var during compile
> time. This can easily be replaced with the calculated values once we
> settle on specific parameters.
>
Thanks. Would you mind reworking the patch so that you aren't removing the
existing code, only IFDEFing it out of the way. I'd like to make it as easy
as possible to skip your implementation for both us and the use of the
code, and/or add another implementation also.
> Currently only x86-64 is implemented. 32bit x86 would be mostly a
> copy-and-paste job, replacing 64bit pointer registers with 32bit ones.
> For other platforms the simplest way would be to use a vectorizing
> compiler on the generic variant. -funroll-loops -ftree-vectorize is
> enough on gcc.
>
> Quick bench results on the worst case workload:
> master no checksums: tps = 15.561848
> master with checksums: tps = 1.695450
> simd checksums: tps = 14.602698
Could you also re-summarise everything you've said so far on this? I want
to make sure this has everyone's attention, knowledge and consent before we
consider applying. We would also need most of that in a README to ensure we
don't forget.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-09 07:20:06 |
| Message-ID: | CA+CSw_uZ-iAPgjS=3iyQRkorjVryefNJFgaRO-RZrLOYfWvkXw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Apr 9, 2013 at 10:03 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> Thanks. Would you mind reworking the patch so that you aren't removing the
> existing code, only IFDEFing it out of the way. I'd like to make it as easy
> as possible to skip your implementation for both us and the use of the code,
> and/or add another implementation also.
I'm not sure that would make much sense. The checksum function will be
a part of the page format. If we wish for configurable checksum
functions then I'd like to hear some discussion on how that would
work. As it is, it seems to cause more headaches than it is worth.
> Could you also re-summarise everything you've said so far on this? I want to
> make sure this has everyone's attention, knowledge and consent before we
> consider applying. We would also need most of that in a README to ensure we
> don't forget.
Sure, give me a day or so. I'm not certain how much of the discovery
process is worth of README status. I think I will mostly go with why
the result is at is, skipping the journey. Any further questions would
certainly help as I think I gave a reasonably thorough explanation in
the patch.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-09 07:39:35 |
| Message-ID: | CA+CSw_ugiW91Qeg+7k=PDvtxbo+Q95D4eufPsNutvQHKHyr2UQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Apr 9, 2013 at 5:35 AM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> Quick bench results on the worst case workload:
> master no checksums: tps = 15.561848
> master with checksums: tps = 1.695450
> simd checksums: tps = 14.602698
For reference, results for the generic version, with default build
params and with the ones required for vectorizing:
simd checksums generic: tps = 6.683347
simd checksums generic vectorized: tps = 12.755203
It would be great if we could hint other platforms about the
vectorization possibilities. Unfortunately I'm not strong enough in
portability fu to come up with the necessary incantations to make all
compilers dance to my will.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-10 01:36:55 |
| Message-ID: | 1365557815.4736.121.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2013-04-09 at 05:35 +0300, Ants Aasma wrote:
> And here you go. I decided to be verbose with the comments as it's
> easier to delete a comment to write one. I also left in a huge jumble
> of macros to calculate the contents of a helper var during compile
> time. This can easily be replaced with the calculated values once we
> settle on specific parameters.
Great, thank you.
Is it possible to put an interface over it that somewhat resembles the
CRC checksum (INIT/COMP/FIN)? It looks a little challenging because of
the nature of the algorithm, but it would make it easier to extend to
other places (e.g. WAL). It doesn't have to match the INIT/COMP/FIN
pattern exactly.
Regardless, we should have some kind of fairly generic interface and
move the code to its own file (e.g. checksum.c).
To make the interface more generic, would it make sense to require the
caller to save the page's stored checksum and zero it before
calculating? That would avoid the awkwardness of avoiding the
pd_checksum field. For example (code for illustration only):
PageCalcChecksum16(Page page, BlockNumber blkno)
{
PageHeader phdr = (PageHeader)page;
uint16 stored_checksum = phdr->pd_checksum;
uint16 calc_checksum;
phdr->pd_checksum = 0;
calc_checksum = SIMD_CHECKSUM(page, BLCKSZ);
phdr->pd_checksum = stored_checksum;
return calc_checksum;
}
That would make it possible to use a different word size -- is uint16
optimal or would a larger word be more efficient?
It looks like the block size needs to be an even multiple of
sizeof(uint16)*NSUMS. And it also look like it's hard to combine
different regions of memory into the same calculation (unless we want to
just calculate them separately and XOR them or something). Does that
mean that this is not suitable for WAL at all?
Using SIMD for WAL is not a requirement at all; I just thought it might
be a nice benefit for non-checksum-enabled users in some later release.
Regards,
Jeff Davis
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-10 08:01:53 |
| Message-ID: | CA+CSw_vSNUY7ecA7oMnXKHss4J0JRBqNAh67e84uznfMt7bOVw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 10, 2013 at 4:36 AM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Tue, 2013-04-09 at 05:35 +0300, Ants Aasma wrote:
>> And here you go. I decided to be verbose with the comments as it's
>> easier to delete a comment to write one. I also left in a huge jumble
>> of macros to calculate the contents of a helper var during compile
>> time. This can easily be replaced with the calculated values once we
>> settle on specific parameters.
>
> Great, thank you.
>
> Is it possible to put an interface over it that somewhat resembles the
> CRC checksum (INIT/COMP/FIN)? It looks a little challenging because of
> the nature of the algorithm, but it would make it easier to extend to
> other places (e.g. WAL). It doesn't have to match the INIT/COMP/FIN
> pattern exactly.
The algorithm has 128 bytes of state. Storing it on every step would
negate any performance gains and C doesn't have a way to keep it in
registers. If we can trust that the compiler doesn't clobber xmm
registers then it could be split up into the following pieces:
1. init
2. process 128 bytes
3. aggregate state
4. mix in block number
Even if we don't split it up, factoring out steps 1..3 would make
sense as there is no point in making step 4 platform specific and so
is just duplicated.
> Regardless, we should have some kind of fairly generic interface and
> move the code to its own file (e.g. checksum.c).
>
> To make the interface more generic, would it make sense to require the
> caller to save the page's stored checksum and zero it before
> calculating? That would avoid the awkwardness of avoiding the
> pd_checksum field. For example (code for illustration only):
Yes, that would help make it reusable.
> That would make it possible to use a different word size -- is uint16
> optimal or would a larger word be more efficient?
Larger words would have better mixing as multiplies mix 4 bytes at a
time instead of 2. Performance of the vectorized version will be the
same as it is tied to the vector length but unvectorized will get a
speed up. The reason I picked 16bits is not actually related to the
checksum hole but because pmullw instruction is guaranteed to be
available on all 64bit CPUs whereas pmulld is only available on the
latest CPUs.
> It looks like the block size needs to be an even multiple of
> sizeof(uint16)*NSUMS. And it also look like it's hard to combine
> different regions of memory into the same calculation (unless we want to
> just calculate them separately and XOR them or something). Does that
> mean that this is not suitable for WAL at all?
I think it would be possible to define a padding scheme for
irregularly sized memory segments where we would only need a lead-out
command for blocks that are not a multiple of 128 bytes. The
performance of it would need to be measured. All-in-all, it's not
really a great match for WAL. While all of the fast checksums process
many bytes in a single iteration, they still process an order of
magnitude bytes less and so have an easier time with irregularly
shaped blocks.
> Using SIMD for WAL is not a requirement at all; I just thought it might
> be a nice benefit for non-checksum-enabled users in some later release.
I think we should first deal with using it for page checksums and if
future versions want to reuse some of the code for WAL checksums then
we can rearrange the code.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-10 09:25:25 |
| Message-ID: | CA+U5nMK_Z7-TYugRCvbJZE-kxO9roXR9urv0P1UN2GW8VPYKPw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10 April 2013 09:01, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>
> > Using SIMD for WAL is not a requirement at all; I just thought it might
> > be a nice benefit for non-checksum-enabled users in some later release.
>
> I think we should first deal with using it for page checksums and if
> future versions want to reuse some of the code for WAL checksums then
> we can rearrange the code.
We have essentially the same problem in both cases: we want to calculate a
checksum of BLCKSZ chunks of data, plus some smaller header data. We
currently use the same code for both cases and it makes sense to do the
same thing with any new code. This is also the *same* issue: when we make a
new hint we need to issue a full page write in WAL, so we are calculating
checksums in two new places: XLOG_HINT records and data blocks.
Few technical points:
* We're taking a copy of the buffer, so Jeff's zero trick works safely, I
think.
* We can use a different algorithm for big and small blocks, we just need a
way to show we've done that, for example setting the high order bit of the
checksum.
* We might even be able to calculate CRC32 checksum for normal WAL records,
and use Ants' checksum for full page writes (only). So checking WAL
checksum would then be to confirm header passes CRC32 and then re-check the
Ants checksum of each backup block.
This work needs to happen now, since once the checksum algorithm is set we
won't easily be able to change it.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-10 10:15:12 |
| Message-ID: | CA+CSw_swAo9F8Mkm5bO5hnpzo62BQZmUzA71UPKLejj-OSgC3g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 10, 2013 at 12:25 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> On 10 April 2013 09:01, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>>
>>
>> > Using SIMD for WAL is not a requirement at all; I just thought it might
>> > be a nice benefit for non-checksum-enabled users in some later release.
>>
>> I think we should first deal with using it for page checksums and if
>> future versions want to reuse some of the code for WAL checksums then
>> we can rearrange the code.
>
>
> We have essentially the same problem in both cases: we want to calculate a
> checksum of BLCKSZ chunks of data, plus some smaller header data. We
> currently use the same code for both cases and it makes sense to do the same
> thing with any new code. This is also the *same* issue: when we make a new
> hint we need to issue a full page write in WAL, so we are calculating
> checksums in two new places: XLOG_HINT records and data blocks.
>
> Few technical points:
>
> * We're taking a copy of the buffer, so Jeff's zero trick works safely, I
> think.
> * We can use a different algorithm for big and small blocks, we just need a
> way to show we've done that, for example setting the high order bit of the
> checksum.
> * We might even be able to calculate CRC32 checksum for normal WAL records,
> and use Ants' checksum for full page writes (only). So checking WAL checksum
> would then be to confirm header passes CRC32 and then re-check the Ants
> checksum of each backup block.
If we ensure that the checksum on the page is correct when we do a
full page write then we could only include the checksum field in the
WAL CRC. When reading WAL we would first check that the CRC is correct
and then verify the the page checksum.
> This work needs to happen now, since once the checksum algorithm is set we
> won't easily be able to change it.
The page checksum algorithm needs to be decided now, but WAL CRCs and
full page writes can be changed in 9.4 and don't need to be perfect on
the first try.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-10 14:23:42 |
| Message-ID: | 20130410142342.GC17800@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 10, 2013 at 01:15:12PM +0300, Ants Aasma wrote:
> > This work needs to happen now, since once the checksum algorithm is set we
> > won't easily be able to change it.
>
> The page checksum algorithm needs to be decided now, but WAL CRCs and
> full page writes can be changed in 9.4 and don't need to be perfect on
> the first try.
I can confirm that --- pg_upgrade doesn't copy any of the WAL stream
from old to new cluster.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-10 18:19:56 |
| Message-ID: | 1365617996.12032.3.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-04-10 at 11:01 +0300, Ants Aasma wrote:
> I think we should first deal with using it for page checksums and if
> future versions want to reuse some of the code for WAL checksums then
> we can rearrange the code.
Sounds good to me, although I expect we at least want any assembly to be
in a separate file (if the specialization makes it in 9.3).
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-10 19:17:08 |
| Message-ID: | CA+U5nM+kty+8_1MX6Y0FjM=6-MLcj9McSz69O5znFaEzXzytxQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10 April 2013 11:15, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> > * We might even be able to calculate CRC32 checksum for normal WAL
> records,
> > and use Ants' checksum for full page writes (only). So checking WAL
> checksum
> > would then be to confirm header passes CRC32 and then re-check the Ants
> > checksum of each backup block.
>
> If we ensure that the checksum on the page is correct when we do a
> full page write then we could only include the checksum field in the
> WAL CRC. When reading WAL we would first check that the CRC is correct
> and then verify the the page checksum.
OK, so we have a single combined "calculate a checksum for a block"
function. That uses Jeff's zeroing trick and Ants' bulk-oriented
performance optimization.
For buffer checksums we simply calculate for the block.
For WAL full page writes, we first set the checksums for all defined
buffers, then calculate the checksum of remaining data plus the pd_checksum
field from each block using the normal WAL CRC32.
Seems good to me. One set of fast code. And it avoids the weirdness that
the checksum stored on the full page is actually wrong.
It also means that the WAL checksum calculation includes the hole, yet we
do not include the data for the hole. So we have to do an extra copy when
restoring the backuo block.
Comments?
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-11 03:27:16 |
| Message-ID: | 1365650836.12032.20.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-04-10 at 20:17 +0100, Simon Riggs wrote:
> OK, so we have a single combined "calculate a checksum for a block"
> function. That uses Jeff's zeroing trick and Ants' bulk-oriented
> performance optimization.
>
>
> For buffer checksums we simply calculate for the block.
Sounds good.
> For WAL full page writes, we first set the checksums for all defined
> buffers, then calculate the checksum of remaining data plus the
> pd_checksum field from each block using the normal WAL CRC32.
>
> Seems good to me. One set of fast code. And it avoids the weirdness
> that the checksum stored on the full page is actually wrong.
Oh, that's a nice benefit.
> It also means that the WAL checksum calculation includes the hole, yet
> we do not include the data for the hole. So we have to do an extra
> copy when restoring the backuo block.
I like this, but it sounds like there is some room for discussion on
some of these points. I assume changes to the WAL checksums are 9.4
material?
I'm satisfied with SIMD data checksums in 9.3 and that we have a plan
for using SIMD for WAL checksums later.
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-11 19:12:59 |
| Message-ID: | CA+U5nMKL5KOq_q8MOZceG9NOuiVB3FQYe+VYVADasyWO-to-Hg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11 April 2013 04:27, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Wed, 2013-04-10 at 20:17 +0100, Simon Riggs wrote:
>
> > OK, so we have a single combined "calculate a checksum for a block"
> > function. That uses Jeff's zeroing trick and Ants' bulk-oriented
> > performance optimization.
> >
> >
> > For buffer checksums we simply calculate for the block.
>
> Sounds good.
>
> > For WAL full page writes, we first set the checksums for all defined
> > buffers, then calculate the checksum of remaining data plus the
> > pd_checksum field from each block using the normal WAL CRC32.
> >
> > Seems good to me. One set of fast code. And it avoids the weirdness
> > that the checksum stored on the full page is actually wrong.
>
> Oh, that's a nice benefit.
So, if we apply a patch like the one attached, we then end up with the WAL
checksum using the page checksum as an integral part of its calculation.
(There is no increase in code inside WALInsertLock, nothing at all touched
in that area).
Then all we need to do is make PageSetChecksumInplace() use Ants' algo and
we're done.
Only point worth discussing is that this change would make backup blocks be
covered by a 16-bit checksum, not the CRC-32 it is now. i.e. the record
header is covered by a CRC32 but the backup blocks only by 16-bit.
(Attached patch is discussion only. Checking checksum in recovery isn't
coded at all.)
Thoughts?
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| make_wal_records_use_page_checksums.v0.patch | application/octet-stream | 2.6 KB |
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 17:32:01 |
| Message-ID: | 20130412173201.GC28226@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 10, 2013 at 11:19:56AM -0700, Jeff Davis wrote:
> On Wed, 2013-04-10 at 11:01 +0300, Ants Aasma wrote:
> > I think we should first deal with using it for page checksums and if
> > future versions want to reuse some of the code for WAL checksums then
> > we can rearrange the code.
>
> Sounds good to me, although I expect we at least want any assembly to be
> in a separate file (if the specialization makes it in 9.3).
Sounds good. Simon has done a good job shepherding this to completion.
My only question is whether the 16-bit page checksums stored in WAL
reduce our ability to detect failed/corrupt writes to WAL?
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 19:07:36 |
| Message-ID: | 1365793656.4736.133.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 2013-04-11 at 20:12 +0100, Simon Riggs wrote:
> So, if we apply a patch like the one attached, we then end up with the
> WAL checksum using the page checksum as an integral part of its
> calculation. (There is no increase in code inside WALInsertLock,
> nothing at all touched in that area).
>
>
> Then all we need to do is make PageSetChecksumInplace() use Ants' algo
> and we're done.
>
>
> Only point worth discussing is that this change would make backup
> blocks be covered by a 16-bit checksum, not the CRC-32 it is now. i.e.
> the record header is covered by a CRC32 but the backup blocks only by
> 16-bit.
FWIW, that's fine with me.
> (Attached patch is discussion only. Checking checksum in recovery
> isn't coded at all.)
I like it.
A few points:
* Given that setting the checksum is unconditional in a backup block, do
we want to zero the checksum field when the backup block is restored if
checksums are disabled? Otherwise we would have a strange situation
where some blocks have a checksum on disk even when checksums are
disabled.
* When we do PageSetChecksumInplace(), we need to be 100% sure that the
hole is empty; otherwise the checksum will fail when we re-expand it. It
might be worth a memset beforehand just to be sure.
Regards,
Jeff Davis
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 19:21:46 |
| Message-ID: | 20130412192146.GD28226@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Apr 12, 2013 at 12:07:36PM -0700, Jeff Davis wrote:
> > (Attached patch is discussion only. Checking checksum in recovery
> > isn't coded at all.)
>
> I like it.
>
> A few points:
>
> * Given that setting the checksum is unconditional in a backup block, do
> we want to zero the checksum field when the backup block is restored if
> checksums are disabled? Otherwise we would have a strange situation
> where some blocks have a checksum on disk even when checksums are
> disabled.
>
> * When we do PageSetChecksumInplace(), we need to be 100% sure that the
> hole is empty; otherwise the checksum will fail when we re-expand it. It
> might be worth a memset beforehand just to be sure.
Do we write the page holes to the WAL for full-page writes? I hope we
don't.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 19:28:42 |
| Message-ID: | 20130412192842.GD6209@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-11 20:12:59 +0100, Simon Riggs wrote:
> On 11 April 2013 04:27, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
>
> > On Wed, 2013-04-10 at 20:17 +0100, Simon Riggs wrote:
> >
> > > OK, so we have a single combined "calculate a checksum for a block"
> > > function. That uses Jeff's zeroing trick and Ants' bulk-oriented
> > > performance optimization.
> > >
> > >
> > > For buffer checksums we simply calculate for the block.
> >
> > Sounds good.
> >
> > > For WAL full page writes, we first set the checksums for all defined
> > > buffers, then calculate the checksum of remaining data plus the
> > > pd_checksum field from each block using the normal WAL CRC32.
> > >
> > > Seems good to me. One set of fast code. And it avoids the weirdness
> > > that the checksum stored on the full page is actually wrong.
> >
> > Oh, that's a nice benefit.
>
>
> So, if we apply a patch like the one attached, we then end up with the WAL
> checksum using the page checksum as an integral part of its calculation.
> (There is no increase in code inside WALInsertLock, nothing at all touched
> in that area).
>
> Then all we need to do is make PageSetChecksumInplace() use Ants' algo and
> we're done.
>
> Only point worth discussing is that this change would make backup blocks be
> covered by a 16-bit checksum, not the CRC-32 it is now. i.e. the record
> header is covered by a CRC32 but the backup blocks only by 16-bit.
That means we will have to do the verification for this in
ValidXLogRecord() *not* in RestoreBkpBlock or somesuch. Otherwise we
won't always recognize the end of WAL correctly.
And I am a bit wary of reducing the likelihood of noticing the proper
end-of-recovery by reducing the crc width.
Why again are we doing this now? Just to reduce the overhead of CRC
computation for full page writes? Or are we forseeing issues with the
page checksums being wrong because of non-zero data in the hole being
zero after the restore from bkp blocks?
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 19:31:36 |
| Message-ID: | 20130412193136.GF28226@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Apr 12, 2013 at 09:28:42PM +0200, Andres Freund wrote:
> > Only point worth discussing is that this change would make backup blocks be
> > covered by a 16-bit checksum, not the CRC-32 it is now. i.e. the record
> > header is covered by a CRC32 but the backup blocks only by 16-bit.
>
> That means we will have to do the verification for this in
> ValidXLogRecord() *not* in RestoreBkpBlock or somesuch. Otherwise we
> won't always recognize the end of WAL correctly.
> And I am a bit wary of reducing the likelihood of noticing the proper
> end-of-recovery by reducing the crc width.
>
> Why again are we doing this now? Just to reduce the overhead of CRC
> computation for full page writes? Or are we forseeing issues with the
> page checksums being wrong because of non-zero data in the hole being
> zero after the restore from bkp blocks?
I thought the idea is that we were going to re-use the already-computed
CRC checksum on the page, and we only have 16-bits of storage for that.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 19:34:17 |
| Message-ID: | 20130412193417.GE6209@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-12 15:31:36 -0400, Bruce Momjian wrote:
> On Fri, Apr 12, 2013 at 09:28:42PM +0200, Andres Freund wrote:
> > > Only point worth discussing is that this change would make backup blocks be
> > > covered by a 16-bit checksum, not the CRC-32 it is now. i.e. the record
> > > header is covered by a CRC32 but the backup blocks only by 16-bit.
> >
> > That means we will have to do the verification for this in
> > ValidXLogRecord() *not* in RestoreBkpBlock or somesuch. Otherwise we
> > won't always recognize the end of WAL correctly.
> > And I am a bit wary of reducing the likelihood of noticing the proper
> > end-of-recovery by reducing the crc width.
> >
> > Why again are we doing this now? Just to reduce the overhead of CRC
> > computation for full page writes? Or are we forseeing issues with the
> > page checksums being wrong because of non-zero data in the hole being
> > zero after the restore from bkp blocks?
>
> I thought the idea is that we were going to re-use the already-computed
> CRC checksum on the page, and we only have 16-bits of storage for that.
Well, but the proposal seems to be to do this also for non-checksum
enabled datadirs, so ...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 20:03:48 |
| Message-ID: | 516868A4.6000403@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12.04.2013 22:31, Bruce Momjian wrote:
> On Fri, Apr 12, 2013 at 09:28:42PM +0200, Andres Freund wrote:
>>> Only point worth discussing is that this change would make backup blocks be
>>> covered by a 16-bit checksum, not the CRC-32 it is now. i.e. the record
>>> header is covered by a CRC32 but the backup blocks only by 16-bit.
>>
>> That means we will have to do the verification for this in
>> ValidXLogRecord() *not* in RestoreBkpBlock or somesuch. Otherwise we
>> won't always recognize the end of WAL correctly.
>> And I am a bit wary of reducing the likelihood of noticing the proper
>> end-of-recovery by reducing the crc width.
>>
>> Why again are we doing this now? Just to reduce the overhead of CRC
>> computation for full page writes? Or are we forseeing issues with the
>> page checksums being wrong because of non-zero data in the hole being
>> zero after the restore from bkp blocks?
>
> I thought the idea is that we were going to re-use the already-computed
> CRC checksum on the page, and we only have 16-bits of storage for that.
No, the patch has to compute the 16-bit checksum for the page when the
full-page image is added to the WAL record. There would otherwise be no
need to calculate the page checksum at that point, but only later when
the page is written out from shared buffer cache.
I think this is a bad idea. It complicates the WAL format significantly.
Simon's patch didn't include the changes to recovery to validate the
checksum, but I suspect it would be complicated. And it reduces the
error-detection capability of WAL recovery. Keep in mind that unlike
page checksums, which are never expected to fail, so even if we miss a
few errors it's still better than nothing, the WAL checkum is used to
detect end-of-WAL. There is expected to be a failure every time we do
crash recovery. This far, we've considered the probability of one in
1^32 small enough for that purpose, but IMHO one in 1^16 is much too weak.
If you want to speed up the CRC calculation of full-page images, you
could have an optimized version of the WAL CRC algorithm, using e.g.
SIMD instructions. Because typical WAL records are small, max 100-200
bytes, and it consists of several even smaller chunks, the normal WAL
CRC calculation is quite resistant to common optimization techniques.
But it might work for the full-page images. Let's not conflate it with
the page checksums, though.
- Heikki
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 20:42:42 |
| Message-ID: | CA+U5nM+jvGMatxp0LHE90RAjCSwjGU7KzMs0uMjEFWMEkS6qag@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12 April 2013 21:03, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> wrote:
> No, the patch has to compute the 16-bit checksum for the page when the
> full-page image is added to the WAL record. There would otherwise be no need
> to calculate the page checksum at that point, but only later when the page
> is written out from shared buffer cache.
>
> I think this is a bad idea. It complicates the WAL format significantly.
> Simon's patch didn't include the changes to recovery to validate the
> checksum, but I suspect it would be complicated. And it reduces the
> error-detection capability of WAL recovery. Keep in mind that unlike page
> checksums, which are never expected to fail, so even if we miss a few errors
> it's still better than nothing, the WAL checkum is used to detect
> end-of-WAL. There is expected to be a failure every time we do crash
> recovery. This far, we've considered the probability of one in 1^32 small
> enough for that purpose, but IMHO one in 1^16 is much too weak.
>
> If you want to speed up the CRC calculation of full-page images, you could
> have an optimized version of the WAL CRC algorithm, using e.g. SIMD
> instructions. Because typical WAL records are small, max 100-200 bytes, and
> it consists of several even smaller chunks, the normal WAL CRC calculation
> is quite resistant to common optimization techniques. But it might work for
> the full-page images. Let's not conflate it with the page checksums, though.
I accept the general tone of that as a reasonable perspective and in
many ways am on the fence myself. This is sensitive stuff.
A few points
* The code to validate the checksum isn't complex, though it is more
than the current one line. Lets say about 10 lines of clear code. I'll
work on that to show its true. I don't see that as a point of
objection.
* WAL checksum is not used as the sole basis for end-of-WAL discovery.
We reuse the WAL files, so the prev field in each WAL record shows
what the previous end of WAL was. Hence if the WAL checksums give a
false positive we still have a double check that the data really is
wrong. It's unbelievable that you'd get a false positive and then have
the prev field match as well, even though it was the genuine
end-of-WAL.
Yes, we could also have a second SIMD calculation optimised for WAL
CRC32 on an 8192 byte block, rather than just one set of SIMD code for
both. We could also have a single set of SIMD code producing a 32-bit
checksum, then take the low 16 bits as we do currently.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 21:02:37 |
| Message-ID: | 1365800557.4736.142.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-04-12 at 15:21 -0400, Bruce Momjian wrote:
> > * When we do PageSetChecksumInplace(), we need to be 100% sure that the
> > hole is empty; otherwise the checksum will fail when we re-expand it. It
> > might be worth a memset beforehand just to be sure.
>
> Do we write the page holes to the WAL for full-page writes? I hope we
> don't.
No, but the page hole is included in the checksum.
Let's say that the page hole contains some non-zero value, and we
calculate a checksum. When we eliminate the page hole, and then
reconstitute the page using zeros for the page hole later, then the page
will not match the checksum any more.
So, we need to be sure the original page hole is all-zero when we
calculate the checksum.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 21:30:59 |
| Message-ID: | 1365802259.4736.166.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-04-12 at 21:28 +0200, Andres Freund wrote:
> That means we will have to do the verification for this in
> ValidXLogRecord() *not* in RestoreBkpBlock or somesuch. Otherwise we
> won't always recognize the end of WAL correctly.
> And I am a bit wary of reducing the likelihood of noticing the proper
> end-of-recovery by reducing the crc width.
Good point.
> Why again are we doing this now? Just to reduce the overhead of CRC
> computation for full page writes? Or are we forseeing issues with the
> page checksums being wrong because of non-zero data in the hole being
> zero after the restore from bkp blocks?
That shouldn't be a problem, because the block is not expected to have a
proper checksum in WAL, and it will be recalculated before being
written. So I see these changes as mostly independent.
The reason we're discussing right now is because, when choosing the
checksum algorithm, I was hoping that it might be usable in the future
for WAL backup blocks. I'm convinced that they can be; and the primary
question now seems to be "should they be", which does not need to be
settled right now in my opinion.
Anyway, I would be perfectly happy if we just got the SIMD algorithm in
for data pages. The support for changing the WAL checksums seems
lukewarm, and there might be quite a few alternatives (e.g. optimizing
the CRC for backup blocks as Heikki suggested) to achieve that
performance goal.
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 21:38:27 |
| Message-ID: | 1365802707.4736.173.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, 2013-04-12 at 23:03 +0300, Heikki Linnakangas wrote:
> I think this is a bad idea. It complicates the WAL format significantly.
> Simon's patch didn't include the changes to recovery to validate the
> checksum, but I suspect it would be complicated. And it reduces the
> error-detection capability of WAL recovery. Keep in mind that unlike
> page checksums, which are never expected to fail, so even if we miss a
> few errors it's still better than nothing, the WAL checkum is used to
> detect end-of-WAL. There is expected to be a failure every time we do
> crash recovery. This far, we've considered the probability of one in
> 1^32 small enough for that purpose, but IMHO one in 1^16 is much too weak.
One thing that just occurred to me is that we could make the SIMD
checksum a 32-bit checksum, and reduce it down to 16 bits for the data
pages. That might give us more flexibility to later use it for WAL
without compromising on the error detection nearly as much (though
obviously that wouldn't work with Simon's current proposal which uses
the same data page checksum in a WAL backup block).
In general, we have more flexibility with WAL because there is no
upgrade issue. It would be nice to share code with the data page
checksum algorithm; but really we should just use whatever offers the
best trade-off in terms of complexity, performance, and error detection
rate.
I don't think we need to decide all of this right now. Personally, I'm
satisfied having SIMD checksums on data pages now and leaving WAL
optimization until later.
Regards,
Jeff Davis
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-12 22:21:44 |
| Message-ID: | CA+CSw_syEL6yhfY+Z64viRcBwR2jRw+GA6hYrT+_2J56GUhUeg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Apr 13, 2013 at 12:38 AM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Fri, 2013-04-12 at 23:03 +0300, Heikki Linnakangas wrote:
>> I think this is a bad idea. It complicates the WAL format significantly.
>> Simon's patch didn't include the changes to recovery to validate the
>> checksum, but I suspect it would be complicated. And it reduces the
>> error-detection capability of WAL recovery. Keep in mind that unlike
>> page checksums, which are never expected to fail, so even if we miss a
>> few errors it's still better than nothing, the WAL checkum is used to
>> detect end-of-WAL. There is expected to be a failure every time we do
>> crash recovery. This far, we've considered the probability of one in
>> 1^32 small enough for that purpose, but IMHO one in 1^16 is much too weak.
>
> One thing that just occurred to me is that we could make the SIMD
> checksum a 32-bit checksum, and reduce it down to 16 bits for the data
> pages. That might give us more flexibility to later use it for WAL
> without compromising on the error detection nearly as much (though
> obviously that wouldn't work with Simon's current proposal which uses
> the same data page checksum in a WAL backup block).
The simple 32bit version of the algorithm would need CPU capability
checks for the fast version and would work only on CPUs produced in
the last few years. Not a show stopper but but more complex code and
less applicability for sure.
An alternative would be to calculate 2 16 bit checksums, concat them
for the 32bit checksum and add them for the 16 bit one. In this case
we wouldn't need to change the current algorithm. A future change
could just factor out everything until the last add as the common
function. But keep in mind that we are talking about sharing about 400
bytes of machine code here.
> In general, we have more flexibility with WAL because there is no
> upgrade issue. It would be nice to share code with the data page
> checksum algorithm; but really we should just use whatever offers the
> best trade-off in terms of complexity, performance, and error detection
> rate.
>
> I don't think we need to decide all of this right now. Personally, I'm
> satisfied having SIMD checksums on data pages now and leaving WAL
> optimization until later.
+1
I feel quite uneasy about reducing the effectiveness of WAL end
detection. There are many ways to improve WAL performance and I have
no idea what would be the best one. At the very least some performance
tests are in order. As this is not an essential part of having usable
checksums, but a general performance optimization I feel that it is
not fair to others to postpone the release to resolve this now. I'd be
more than happy to research this for 9.4.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 07:39:59 |
| Message-ID: | CA+U5nMK78MAn54hqFw6NzuHji=fW4MPSG8ex+FKguMHfwHNUbg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12 April 2013 23:21, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> In general, we have more flexibility with WAL because there is no
>> upgrade issue. It would be nice to share code with the data page
>> checksum algorithm; but really we should just use whatever offers the
>> best trade-off in terms of complexity, performance, and error detection
>> rate.
>>
>> I don't think we need to decide all of this right now. Personally, I'm
>> satisfied having SIMD checksums on data pages now and leaving WAL
>> optimization until later.
>
> +1
OK, lets drop that idea then. SIMD checksums for 16-bit page checksums
only in this release.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Andres Freund <andres(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 13:14:26 |
| Message-ID: | 20130413131426.GA4604@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Apr 12, 2013 at 02:38:27PM -0700, Jeff Davis wrote:
> In general, we have more flexibility with WAL because there is no
> upgrade issue. It would be nice to share code with the data page
> checksum algorithm; but really we should just use whatever offers the
> best trade-off in terms of complexity, performance, and error detection
> rate.
>
> I don't think we need to decide all of this right now. Personally, I'm
> satisfied having SIMD checksums on data pages now and leaving WAL
> optimization until later.
As I understand it, SIMD is just a CPU-optimized method for producing a
CRC checksum. Is that right? Does it produce the same result as a
non-CPU-optimized CRC calculation?
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndQuadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 13:29:30 |
| Message-ID: | 20130413132930.GA10556@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-13 09:14:26 -0400, Bruce Momjian wrote:
> On Fri, Apr 12, 2013 at 02:38:27PM -0700, Jeff Davis wrote:
> > In general, we have more flexibility with WAL because there is no
> > upgrade issue. It would be nice to share code with the data page
> > checksum algorithm; but really we should just use whatever offers the
> > best trade-off in terms of complexity, performance, and error detection
> > rate.
> >
> > I don't think we need to decide all of this right now. Personally, I'm
> > satisfied having SIMD checksums on data pages now and leaving WAL
> > optimization until later.
>
> As I understand it, SIMD is just a CPU-optimized method for producing a
> CRC checksum. Is that right? Does it produce the same result as a
> non-CPU-optimized CRC calculation?
No we are talking about a different algorithm that results in different
results, thats why its important to choose now since we can't change it
later without breaking pg_upgrade in further releases.
http://en.wikipedia.org/wiki/SIMD_%28hash_function%29
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 14:58:53 |
| Message-ID: | 2149.1365865133@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andres Freund <andres(at)2ndquadrant(dot)com> writes:
> On 2013-04-13 09:14:26 -0400, Bruce Momjian wrote:
>> As I understand it, SIMD is just a CPU-optimized method for producing a
>> CRC checksum. Is that right? Does it produce the same result as a
>> non-CPU-optimized CRC calculation?
> No we are talking about a different algorithm that results in different
> results, thats why its important to choose now since we can't change it
> later without breaking pg_upgrade in further releases.
> http://en.wikipedia.org/wiki/SIMD_%28hash_function%29
[ squint... ] We're talking about a *cryptographic* hash function?
Why in the world was this considered a good idea for page checksums?
In the first place, it's probably not very fast compared to some
alternatives, and in the second place, the criteria by which people
would consider it a good crypto hash function have approximately nothing
to do with what we need for a checksum function. What we want for a
checksum function is high probability of detection of common hardware
failure modes, such as burst errors and all-zeroes. This is
particularly critical when we're going with only a 16-bit checksum ---
the probabilities need to be skewed in the right direction, or it's not
going to be all that terribly useful.
CRCs are known to be good for that sort of thing; it's what they were
designed for. I'd like to see some evidence that any substitute
algorithm has similar properties. Without that, I'm going to vote
against this idea.
regards, tom lane
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 15:10:07 |
| Message-ID: | 20130413151006.GC10556@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-13 10:58:53 -0400, Tom Lane wrote:
> Andres Freund <andres(at)2ndquadrant(dot)com> writes:
> > On 2013-04-13 09:14:26 -0400, Bruce Momjian wrote:
> >> As I understand it, SIMD is just a CPU-optimized method for producing a
> >> CRC checksum. Is that right? Does it produce the same result as a
> >> non-CPU-optimized CRC calculation?
>
> > No we are talking about a different algorithm that results in different
> > results, thats why its important to choose now since we can't change it
> > later without breaking pg_upgrade in further releases.
> > http://en.wikipedia.org/wiki/SIMD_%28hash_function%29
>
> [ squint... ] We're talking about a *cryptographic* hash function?
> Why in the world was this considered a good idea for page checksums?
In Ants' implementation its heck of a lot of faster than any CRC
implementation we have seen so far on relatively large blocks (like pages).
pgbench results:
CA+CSw_uXO-fRkuzL0Yzs0wSdL8dipZV-ugMvYN-yV45SGUBU2w(at)mail(dot)gmail(dot)com
byte/cycle comparison:
CA+CSw_su1fopLNBz1NAfkSNw4_=gv+5pf0KdLQmpvuKW1Q4v+Q(at)mail(dot)gmail(dot)com
> In the first place, it's probably not very fast compared to some
> alternatives, and in the second place, the criteria by which people
> would consider it a good crypto hash function have approximately nothing
> to do with what we need for a checksum function. What we want for a
> checksum function is high probability of detection of common hardware
> failure modes, such as burst errors and all-zeroes. This is
> particularly critical when we're going with only a 16-bit checksum ---
> the probabilities need to be skewed in the right direction, or it's not
> going to be all that terribly useful.
>
> CRCs are known to be good for that sort of thing; it's what they were
> designed for. I'd like to see some evidence that any substitute
> algorithm has similar properties. Without that, I'm going to vote
> against this idea.
Ants has dome some analysis on this, like
CA+CSw_tMoA85e=1vS4oMjZjG2MR_huLiKoVPd80Dp5RURDSGcQ(at)mail(dot)gmail(dot)com .
That doesn't look bad to me and unless I am missing something its better
than our CRC with 16bit.
So while I would say its not 100% researched there has been a rather
detailed investigation by Ants - I am rather impressed.
My biggest doubt so far is the reliance on inline assembly for the top
performance on x86-64 and a generic implementation otherwise that only
is really fast with appropriate compiler flags..
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 15:14:28 |
| Message-ID: | CA+CSw_vnoxC0HvuEzSUO50i_Jk7ozjbX2Ns7R=1GnnqPGVpSww@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Apr 13, 2013 at 5:58 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Andres Freund <andres(at)2ndquadrant(dot)com> writes:
>> On 2013-04-13 09:14:26 -0400, Bruce Momjian wrote:
>>> As I understand it, SIMD is just a CPU-optimized method for producing a
>>> CRC checksum. Is that right? Does it produce the same result as a
>>> non-CPU-optimized CRC calculation?
>
>> No we are talking about a different algorithm that results in different
>> results, thats why its important to choose now since we can't change it
>> later without breaking pg_upgrade in further releases.
>> http://en.wikipedia.org/wiki/SIMD_%28hash_function%29
>
> [ squint... ] We're talking about a *cryptographic* hash function?
> Why in the world was this considered a good idea for page checksums?
>
> In the first place, it's probably not very fast compared to some
> alternatives, and in the second place, the criteria by which people
> would consider it a good crypto hash function have approximately nothing
> to do with what we need for a checksum function. What we want for a
> checksum function is high probability of detection of common hardware
> failure modes, such as burst errors and all-zeroes. This is
> particularly critical when we're going with only a 16-bit checksum ---
> the probabilities need to be skewed in the right direction, or it's not
> going to be all that terribly useful.
>
> CRCs are known to be good for that sort of thing; it's what they were
> designed for. I'd like to see some evidence that any substitute
> algorithm has similar properties. Without that, I'm going to vote
> against this idea.
Sorry for creating confusion here by playing fast and loose with the
terminology. We are not talking about that hash function at all. What
we are talking about here is Fowler-Noll-Vo-ish
(http://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%80%93Vo_hash_function)
hash function that is restructured to be parallelisable with SIMD
instructions with the explicit goal of being as fast as possible. The
resulting hash function is roughly two orders of magnitude faster than
1-byte-at-a-time CRC32 currently in use. Performance is about
comparable with optimized fixed size memcpy running in cache.
Based on current analysis, it is particularly good at detecting single
bit errors, as good at detecting burst errors as can be expected from
16 bits and not horrible at detecting burst writes of zeroes. It is
quite bad at detecting multiple uncorrelated single bit errors and
extremely bad at detecting repeating patterns of errors in low order
bits.
All in all I would say that the performance is worth the loss in
detection capability as we are not talking about using the checksum to
prove correctness.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 15:26:26 |
| Message-ID: | 20130413152626.GD10556@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-13 18:14:28 +0300, Ants Aasma wrote:
> On Sat, Apr 13, 2013 at 5:58 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> > Andres Freund <andres(at)2ndquadrant(dot)com> writes:
> >> On 2013-04-13 09:14:26 -0400, Bruce Momjian wrote:
> >>> As I understand it, SIMD is just a CPU-optimized method for producing a
> >>> CRC checksum. Is that right? Does it produce the same result as a
> >>> non-CPU-optimized CRC calculation?
> >
> >> No we are talking about a different algorithm that results in different
> >> results, thats why its important to choose now since we can't change it
> >> later without breaking pg_upgrade in further releases.
> >> http://en.wikipedia.org/wiki/SIMD_%28hash_function%29
> >
> > [ squint... ] We're talking about a *cryptographic* hash function?
> > Why in the world was this considered a good idea for page checksums?
> >
> > In the first place, it's probably not very fast compared to some
> > alternatives, and in the second place, the criteria by which people
> > would consider it a good crypto hash function have approximately nothing
> > to do with what we need for a checksum function. What we want for a
> > checksum function is high probability of detection of common hardware
> > failure modes, such as burst errors and all-zeroes. This is
> > particularly critical when we're going with only a 16-bit checksum ---
> > the probabilities need to be skewed in the right direction, or it's not
> > going to be all that terribly useful.
> >
> > CRCs are known to be good for that sort of thing; it's what they were
> > designed for. I'd like to see some evidence that any substitute
> > algorithm has similar properties. Without that, I'm going to vote
> > against this idea.
>
> Sorry for creating confusion here by playing fast and loose with the
> terminology. We are not talking about that hash function at all. What
> we are talking about here is Fowler-Noll-Vo-ish
> (http://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%80%93Vo_hash_function)
> hash function that is restructured to be parallelisable with SIMD
> instructions with the explicit goal of being as fast as possible. The
> resulting hash function is roughly two orders of magnitude faster than
> 1-byte-at-a-time CRC32 currently in use. Performance is about
> comparable with optimized fixed size memcpy running in cache.
Gah, one shouldn't look to quick for a reference, sorry.
> Based on current analysis, it is particularly good at detecting single
> bit errors, as good at detecting burst errors as can be expected from
> 16 bits and not horrible at detecting burst writes of zeroes. It is
> quite bad at detecting multiple uncorrelated single bit errors and
> extremely bad at detecting repeating patterns of errors in low order
> bits.
> All in all I would say that the performance is worth the loss in
> detection capability as we are not talking about using the checksum to
> prove correctness.
Is it actually a loss compared to our 16bit flavor of crc32 we now use?
I didn't think so far from the properties you described?
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-13 16:53:18 |
| Message-ID: | CA+CSw_tFV9=u_iPt8PheF3xwe01uosiZnbR2v43BBcN9rpC8Eg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Apr 13, 2013 at 6:26 PM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
>> All in all I would say that the performance is worth the loss in
>> detection capability as we are not talking about using the checksum to
>> prove correctness.
>
> Is it actually a loss compared to our 16bit flavor of crc32 we now use?
> I didn't think so far from the properties you described?
I would have to run the testsuite I made to see now much but I would
presume so. The algorithm relies on multiplication for bit diffusion
and multiply has lousy diffusion on low order bits, exactly no
diffusion for the lowest bit. And for 16bit values low order bits is
quite a large fraction of the total hash.
If we allow for operations that are not in SSE2 then there are a few
things that we could do to make the hash quality better without
affecting performance. pmulld instruction (SSE4.1) would allow for
32bit values in the intermediate state. And pshufb (SSE3) would allow
us to swap high and low bytes introducing additional mixing. On Intel
Sandy Bridge, if I understand the microarchitecture correctly, either
change would be basically free, but not both because pshufb and paddw
use execution ports 0 and 5, while pmulld needs port 0 and pmullw
needs port 1. Currently the main loop takes 1 cycle per 16byte chunk,
any changes introducing conflicts there would cut the performance in
half.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-14 02:30:10 |
| Message-ID: | 20130414023010.GB4604@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Apr 13, 2013 at 06:14:28PM +0300, Ants Aasma wrote:
> > CRCs are known to be good for that sort of thing; it's what they were
> > designed for. I'd like to see some evidence that any substitute
> > algorithm has similar properties. Without that, I'm going to vote
> > against this idea.
>
> Sorry for creating confusion here by playing fast and loose with the
> terminology. We are not talking about that hash function at all. What
> we are talking about here is Fowler-Noll-Vo-ish
> (http://en.wikipedia.org/wiki/Fowler%E2%80%93Noll%E2%80%93Vo_hash_function)
> hash function that is restructured to be parallelisable with SIMD
> instructions with the explicit goal of being as fast as possible. The
> resulting hash function is roughly two orders of magnitude faster than
> 1-byte-at-a-time CRC32 currently in use. Performance is about
> comparable with optimized fixed size memcpy running in cache.
>
> Based on current analysis, it is particularly good at detecting single
> bit errors, as good at detecting burst errors as can be expected from
> 16 bits and not horrible at detecting burst writes of zeroes. It is
> quite bad at detecting multiple uncorrelated single bit errors and
> extremely bad at detecting repeating patterns of errors in low order
> bits.
>
> All in all I would say that the performance is worth the loss in
> detection capability as we are not talking about using the checksum to
> prove correctness.
Agreed. It would be good to get these details into the patch so others
are not confused in the future.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 14:05:21 |
| Message-ID: | CA+U5nMJ-Oiqmtvb-+JA3ix91tdbGSaYn9VsvBXSjX+9hRA4PwQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 9 April 2013 03:35, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> On Fri, Apr 5, 2013 at 9:39 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> Unless somebody tells me not to waste my time I'll go ahead and come
>> up with a workable patch by Monday.
>
> And here you go. I decided to be verbose with the comments as it's
> easier to delete a comment to write one. I also left in a huge jumble
> of macros to calculate the contents of a helper var during compile
> time. This can easily be replaced with the calculated values once we
> settle on specific parameters.
>
> Currently only x86-64 is implemented. 32bit x86 would be mostly a
> copy-and-paste job, replacing 64bit pointer registers with 32bit ones.
> For other platforms the simplest way would be to use a vectorizing
> compiler on the generic variant. -funroll-loops -ftree-vectorize is
> enough on gcc.
>
> Quick bench results on the worst case workload:
> master no checksums: tps = 15.561848
> master with checksums: tps = 1.695450
> simd checksums: tps = 14.602698
Numbers look very good on this. Well done.
I support the direction of this, but I don't think I'm sufficiently
well qualified to verify that the code does what it should and/or fix
it if it breaks. If others want to see this happen you'll need to
pitch in.
My only review comments are to ask for some explanation of the magic numbers...
#define CSUM_PRIME1 0x49
#define CSUM_PRIME2 0x986b
#define CSUM_TRUNC 65521
Where magic means a level of technology far above my own
understanding, and yet no (or not enough) code comments to assist me.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Greg Stark <stark(at)mit(dot)edu> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 17:45:39 |
| Message-ID: | CAM-w4HMkUBaGo1jQCAYJyRFnOju1yioz6Z7QrpSTawvk7EiapQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Apr 12, 2013 at 9:42 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> * WAL checksum is not used as the sole basis for end-of-WAL discovery.
> We reuse the WAL files, so the prev field in each WAL record shows
> what the previous end of WAL was. Hence if the WAL checksums give a
> false positive we still have a double check that the data really is
> wrong. It's unbelievable that you'd get a false positive and then have
> the prev field match as well, even though it was the genuine
> end-of-WAL.
This is kind of true and kind of not true. If a system loses power
while writing lots of data to WAL then the blocks at the end of the
WAL might not be written out in order. Everything since the last log
sync might be partly written out and partly not written out. That's
the case where the checksum is critical. The beginning of a record
could easily be written out including xl_prev and the end of the
record not written. 1/64,000 power losses would then end up with an
assertion failure or corrupt database.
--
greg
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Greg Stark <stark(at)mit(dot)edu> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 19:27:46 |
| Message-ID: | 6846.1366140466@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Greg Stark <stark(at)mit(dot)edu> writes:
> On Fri, Apr 12, 2013 at 9:42 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>> * WAL checksum is not used as the sole basis for end-of-WAL discovery.
>> We reuse the WAL files, so the prev field in each WAL record shows
>> what the previous end of WAL was. Hence if the WAL checksums give a
>> false positive we still have a double check that the data really is
>> wrong. It's unbelievable that you'd get a false positive and then have
>> the prev field match as well, even though it was the genuine
>> end-of-WAL.
> This is kind of true and kind of not true. If a system loses power
> while writing lots of data to WAL then the blocks at the end of the
> WAL might not be written out in order. Everything since the last log
> sync might be partly written out and partly not written out. That's
> the case where the checksum is critical. The beginning of a record
> could easily be written out including xl_prev and the end of the
> record not written. 1/64,000 power losses would then end up with an
> assertion failure or corrupt database.
I have a hard time believing that it's a good idea to add checksums to
data pages and at the same time weaken our ability to detect WAL
corruption. So this seems to me to be going in the wrong direction.
What's it buying for us anyway? A few CPU cycles saved during WAL
generation? That's probably swamped by the other costs of writing WAL,
especially if you're using replication.
regards, tom lane
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Greg Stark <stark(at)mit(dot)edu>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 19:45:41 |
| Message-ID: | CA+U5nMKnQFgkgNFbOBAe58PiPD_HnEc5GpGv9KZJqRE3n94Dpg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 16 April 2013 20:27, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Greg Stark <stark(at)mit(dot)edu> writes:
>> On Fri, Apr 12, 2013 at 9:42 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>>> * WAL checksum is not used as the sole basis for end-of-WAL discovery.
>>> We reuse the WAL files, so the prev field in each WAL record shows
>>> what the previous end of WAL was. Hence if the WAL checksums give a
>>> false positive we still have a double check that the data really is
>>> wrong. It's unbelievable that you'd get a false positive and then have
>>> the prev field match as well, even though it was the genuine
>>> end-of-WAL.
>
>> This is kind of true and kind of not true. If a system loses power
>> while writing lots of data to WAL then the blocks at the end of the
>> WAL might not be written out in order. Everything since the last log
>> sync might be partly written out and partly not written out. That's
>> the case where the checksum is critical. The beginning of a record
>> could easily be written out including xl_prev and the end of the
>> record not written. 1/64,000 power losses would then end up with an
>> assertion failure or corrupt database.
>
> I have a hard time believing that it's a good idea to add checksums to
> data pages and at the same time weaken our ability to detect WAL
> corruption. So this seems to me to be going in the wrong direction.
> What's it buying for us anyway? A few CPU cycles saved during WAL
> generation? That's probably swamped by the other costs of writing WAL,
> especially if you're using replication.
This part of the thread is dead now .... I said "lets drop this idea"
on 13 April.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 20:20:26 |
| Message-ID: | 21E23B6A-C5A7-4A54-AB24-D6EA7FD405FE@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr13, 2013, at 17:14 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
> Based on current analysis, it is particularly good at detecting single
> bit errors, as good at detecting burst errors as can be expected from
> 16 bits and not horrible at detecting burst writes of zeroes. It is
> quite bad at detecting multiple uncorrelated single bit errors and
> extremely bad at detecting repeating patterns of errors in low order
> bits.
I've read the patch and tried to understand why it's that bad at
detecting repeating patterns of errors in low order bits, and to see
if there might be a way to fix that without too much of a performance
impact.
Here's what I gather the algorithm does:
It treats the input data, a page of L bytes, as a Nx64 matrix V
of 16-bit quantities (N = L/64, obviously).
It then first computes (using two primes p (PRIME1) and q (PRIME2))
S = V[1,1]*p^63*q^63 + V[1,2]*p^63*q^62 + … + V[1,64]*p^63*q^0
+ V[2,1]*p^62*q^63 + V[2,2]*p^62*q^62 + … + V[2,64]*p^62*q^0
+ …
+ V[N,1]*p^0 *q^63 + V[N,2]*p^0 *q^62 + … + V[N,64]*p^0 *q^0
(mod 2^16)
= sum V[i,j]*p^(64-i)*q^(64-j)
Note that it does that by first computing the row-wise sums without
the q^i coefficient, and then (in what the code calls the aggregation
phase) combines those row-wise sums into a total, adding the q^i-
coefficients along the way.
The final hash value is then
H = S * p + B * q mod 2^16
where B is a salt value intended to detect swapped pages (currently
B is simply the page index)
This raises two question. First, why are there two primes? You could
just as well using a single prime q and set p=q^64 mod 2^16. You then
get
S = sum V[i,j] * q^(64*(64-i) + (64-j)
= sum V[i,j] * q^(4096 - 64*(i-1) - j)
You get higher prime powers that way, but you can easily choose a prime
that yields distinct values mod 2^16 for exponents up to 16383. Your
PRIME2, for example, does. (It wraps around for 16384, i.e.
PRIME2^16384 = 1 mod 2^16, but that's true for every possible prime since
16384 is the Carmichael function's value at 2^16)
Second, why does it use addition instead of XOR? It seems that FNV
usually XORs the terms together instead of adding them?
Regarding the bad behaviour for multiple low-bit errors - can you
explain why it behaves badly in that case? I currently fail to see
why that would be. I *can* see that the lowest bit of the hash depends
only on the lowest bit of the input words, but as long as the lowest
bits of the input words also affect other bits of the hash, that shouldn't
matter. Which I think they do, but I might be missing something...
Here, btw, is a page on FNV hashing. It mentions a few rules for
picking suitable primes
http://www.isthe.com/chongo/tech/comp/fnv
best regards,
Florian Pflug
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 20:59:12 |
| Message-ID: | CA+CSw_vfBoVbnBq=gjiBXUj5kxRCtQSFb4iu6mrN6Ve3v3m_Yg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Apr 16, 2013 at 5:05 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> On 9 April 2013 03:35, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> On Fri, Apr 5, 2013 at 9:39 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>>> Unless somebody tells me not to waste my time I'll go ahead and come
>>> up with a workable patch by Monday.
>>
>> And here you go. I decided to be verbose with the comments as it's
>> easier to delete a comment to write one. I also left in a huge jumble
>> of macros to calculate the contents of a helper var during compile
>> time. This can easily be replaced with the calculated values once we
>> settle on specific parameters.
>>
>> Currently only x86-64 is implemented. 32bit x86 would be mostly a
>> copy-and-paste job, replacing 64bit pointer registers with 32bit ones.
>> For other platforms the simplest way would be to use a vectorizing
>> compiler on the generic variant. -funroll-loops -ftree-vectorize is
>> enough on gcc.
>>
>> Quick bench results on the worst case workload:
>> master no checksums: tps = 15.561848
>> master with checksums: tps = 1.695450
>> simd checksums: tps = 14.602698
>
> Numbers look very good on this. Well done.
>
> I support the direction of this, but I don't think I'm sufficiently
> well qualified to verify that the code does what it should and/or fix
> it if it breaks. If others want to see this happen you'll need to
> pitch in.
>
> My only review comments are to ask for some explanation of the magic numbers...
> #define CSUM_PRIME1 0x49
> #define CSUM_PRIME2 0x986b
> #define CSUM_TRUNC 65521
>
> Where magic means a level of technology far above my own
> understanding, and yet no (or not enough) code comments to assist me.
The specific values used are mostly magic to me too. As mentioned in a
short sentence in the patch, the values are experimentally chosen,
guided by some intuition about what good values should look like.
Basically the methodology for the choice was that I took all the pages
from a 2.8GB test database, and then for each page introduced a bunch
of common errors and observed how many errors were undetected. The
main observations were: 1) the exact value of the primes doesn't
really matter for detection efficiency.
2) values with a non-uniform distribution of zeroes and ones seem to
work slightly better.
I'll write up a readme of why the values are how they are and with
some more explanation of the algorithm.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 21:20:18 |
| Message-ID: | 9153.1366147218@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Ants Aasma <ants(at)cybertec(dot)at> writes:
> On Tue, Apr 16, 2013 at 5:05 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>> My only review comments are to ask for some explanation of the magic numbers...
> The specific values used are mostly magic to me too. As mentioned in a
> short sentence in the patch, the values are experimentally chosen,
> guided by some intuition about what good values should look like.
There actually is quite a lot of theory out there about this sort of
thing. If we are inventing our own checksum function then We're Doing
It Wrong. We should be adopting an existing, proven function.
"Experimentally derived" is about the worst recommendation I can think
of in this area.
regards, tom lane
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 21:41:30 |
| Message-ID: | CA+CSw_tcQHE12Lnp9xCbgm1c26R3tAZoqnY5YN+_xEvPPwpzFA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Apr 16, 2013 at 11:20 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> On Apr13, 2013, at 17:14 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> Based on current analysis, it is particularly good at detecting single
>> bit errors, as good at detecting burst errors as can be expected from
>> 16 bits and not horrible at detecting burst writes of zeroes. It is
>> quite bad at detecting multiple uncorrelated single bit errors and
>> extremely bad at detecting repeating patterns of errors in low order
>> bits.
>
> I've read the patch and tried to understand why it's that bad at
> detecting repeating patterns of errors in low order bits, and to see
> if there might be a way to fix that without too much of a performance
> impact.
>
> Here's what I gather the algorithm does:
>
> It treats the input data, a page of L bytes, as a Nx64 matrix V
> of 16-bit quantities (N = L/64, obviously).
> It then first computes (using two primes p (PRIME1) and q (PRIME2))
>
> S = V[1,1]*p^63*q^63 + V[1,2]*p^63*q^62 + … + V[1,64]*p^63*q^0
> + V[2,1]*p^62*q^63 + V[2,2]*p^62*q^62 + … + V[2,64]*p^62*q^0
> + …
> + V[N,1]*p^0 *q^63 + V[N,2]*p^0 *q^62 + … + V[N,64]*p^0 *q^0
> (mod 2^16)
> = sum V[i,j]*p^(64-i)*q^(64-j)
>
> Note that it does that by first computing the row-wise sums without
> the q^i coefficient, and then (in what the code calls the aggregation
> phase) combines those row-wise sums into a total, adding the q^i-
> coefficients along the way.
>
> The final hash value is then
>
> H = S * p + B * q mod 2^16
>
> where B is a salt value intended to detect swapped pages (currently
> B is simply the page index)
Great job analyzing the analytic form of the algorithm and sorry I you
had to do it instead finding it in the documentation.
> This raises two question. First, why are there two primes? You could
> just as well using a single prime q and set p=q^64 mod 2^16. You then
> get
> S = sum V[i,j] * q^(64*(64-i) + (64-j)
> = sum V[i,j] * q^(4096 - 64*(i-1) - j)
> You get higher prime powers that way, but you can easily choose a prime
> that yields distinct values mod 2^16 for exponents up to 16383. Your
> PRIME2, for example, does. (It wraps around for 16384, i.e.
> PRIME2^16384 = 1 mod 2^16, but that's true for every possible prime since
> 16384 is the Carmichael function's value at 2^16)
The experimental detection rate is about the same if we use a single
prime. But I think you have the analytical form wrong here. It should
be given q = p:
S = sum V[i,j] * p^(64-i) * p^(64-j)
= sum V[i,j] * p^(64 - i + 64 - j)
= sum V[i,j] * p^(128 - i -j)
This makes the whole matrix symmetric. While I can't think of any real
world errors that would exhibit symmetry in this 64x64 matrix, it
seemed better to me to avoid the issue altogether and use different
primes. IIRC it helped a lot for the case of page[i] = i & 0xFF.
> Second, why does it use addition instead of XOR? It seems that FNV
> usually XORs the terms together instead of adding them?
Testing showed slightly better detection rate for adds. Intuitively I
think it's because the carry introduces some additional mixing.
> Regarding the bad behaviour for multiple low-bit errors - can you
> explain why it behaves badly in that case? I currently fail to see
> why that would be. I *can* see that the lowest bit of the hash depends
> only on the lowest bit of the input words, but as long as the lowest
> bits of the input words also affect other bits of the hash, that shouldn't
> matter. Which I think they do, but I might be missing something...
Looks like you're right. I was somehow concentrating only on how the
lowest bits depend on the input.
> Here, btw, is a page on FNV hashing. It mentions a few rules for
> picking suitable primes
>
> http://www.isthe.com/chongo/tech/comp/fnv
Unfortunately the rules don't apply here because of the hash size.
Thanks for your analysis. I will do my best to get this all into a
document and will do some more analysis to see if I can come up with
some kind of proof for the error cases.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-16 23:26:01 |
| Message-ID: | 39824EEF-9740-4440-A7E8-D0DD72229D2A@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr16, 2013, at 23:41 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
> On Tue, Apr 16, 2013 at 11:20 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>> On Apr13, 2013, at 17:14 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
>>> Based on current analysis, it is particularly good at detecting single
>>> bit errors, as good at detecting burst errors as can be expected from
>>> 16 bits and not horrible at detecting burst writes of zeroes. It is
>>> quite bad at detecting multiple uncorrelated single bit errors and
>>> extremely bad at detecting repeating patterns of errors in low order
>>> bits.
>>
>> I've read the patch and tried to understand why it's that bad at
>> detecting repeating patterns of errors in low order bits, and to see
>> if there might be a way to fix that without too much of a performance
>> impact.
>>
>> Here's what I gather the algorithm does:
>>
>> It treats the input data, a page of L bytes, as a Nx64 matrix V
>> of 16-bit quantities (N = L/64, obviously).
>> It then first computes (using two primes p (PRIME1) and q (PRIME2))
>>
>> S = V[1,1]*p^63*q^63 + V[1,2]*p^63*q^62 + … + V[1,64]*p^63*q^0
>> + V[2,1]*p^62*q^63 + V[2,2]*p^62*q^62 + … + V[2,64]*p^62*q^0
>> + …
>> + V[N,1]*p^0 *q^63 + V[N,2]*p^0 *q^62 + … + V[N,64]*p^0 *q^0
>> (mod 2^16)
>> = sum V[i,j]*p^(64-i)*q^(64-j)
>>
>> Note that it does that by first computing the row-wise sums without
>> the q^i coefficient, and then (in what the code calls the aggregation
>> phase) combines those row-wise sums into a total, adding the q^i-
>> coefficients along the way.
>>
>> The final hash value is then
>>
>> H = S * p + B * q mod 2^16
>>
>> where B is a salt value intended to detect swapped pages (currently
>> B is simply the page index)
>
> Great job analyzing the analytic form of the algorithm and sorry I you
> had to do it instead finding it in the documentation.
No problem, glad if I can help!
>> This raises two question. First, why are there two primes? You could
>> just as well using a single prime q and set p=q^64 mod 2^16. You then
>> get
>> S = sum V[i,j] * q^(64*(64-i) + (64-j)
>> = sum V[i,j] * q^(4096 - 64*(i-1) - j)
>> You get higher prime powers that way, but you can easily choose a prime
>> that yields distinct values mod 2^16 for exponents up to 16383. Your
>> PRIME2, for example, does. (It wraps around for 16384, i.e.
>> PRIME2^16384 = 1 mod 2^16, but that's true for every possible prime since
>> 16384 is the Carmichael function's value at 2^16)
>
> The experimental detection rate is about the same if we use a single
> prime. But I think you have the analytical form wrong here. It should
> be given q = p:
>
> S = sum V[i,j] * p^(64-i) * p^(64-j)
> = sum V[i,j] * p^(64 - i + 64 - j)
> = sum V[i,j] * p^(128 - i -j)
Yeah, if you set q = p that's true. My suggestion was p=q^64 though...
>> Second, why does it use addition instead of XOR? It seems that FNV
>> usually XORs the terms together instead of adding them?
>
> Testing showed slightly better detection rate for adds. Intuitively I
> think it's because the carry introduces some additional mixing.
Hm, but OTOH it makes S linear in V, i.e. if you have two inputs
V1,V2 and V = V1 + V2, then S = S1 + S2. Also, if V' = V*m, then
S' = S*m. The second property is quite undesirable, I think. Assume
all the V[i,j] are divisible by 2^k, i.e. have zeros at all bit
positions 0..(k-1). Then, due to linearity, S is also divisible by
2^k, i.e. also has no ones before the k-th bit. This means, for example
that if you hash values values which all have their lowest bit cleared,
you get only 2^15 distinct hash values. If they all have the two
lowest bits cleared, you get only 2^14 distinct values, and so on…
Generally, linearity doesn't seem to be a property that one wants
in a hash I think, so my suggestion is to stick to XOR.
>> Here, btw, is a page on FNV hashing. It mentions a few rules for
>> picking suitable primes
>>
>> http://www.isthe.com/chongo/tech/comp/fnv
>
> Unfortunately the rules don't apply here because of the hash size.
Yeah :-(.
I noticed that their 32-bit prime only has a single one outside
the first 16 bits. Maybe we can take advantage of that and use a
32-bit state while still providing decent performance on machines
without a 32-bit x 32-bit -> 32-bit multiply instruction?
If we lived in an Intel-only world, I'd suggest going with a
32-bit state, since SSE4.1 support is *very* wide-spread already -
the last CPUs without it came out over 5 years ago, I think.
(Core2 and later support SSE4.1, and some later Core1 do too)
But unfortunately things look bleak even for other x86
implementations - AMD support SSE4.1 only starting with
Bulldozer, which came out 2011 or so I believe. Leaving the x86
realm, it seems that only ARM's NEON provides the instructions
we'd need - AltiVec seems to be support only 16-bit multiplies,
and from what some quick googling brought up, MIPS and SPARC
SIMD instructions look no better..
OTOH, chances are that nobody will ever do SIMD implementations
for those machines. In that case, working in 32-bit chunks instead
of 16-bit chunks would be beneficial, since it requires half the
number of instructions…
best regards,
Florian Pflug
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 14:47:55 |
| Message-ID: | CA+CSw_u1DsVaoqDq+g0WKw6p8F-WSmkPA8wEJ3f=9Rkq9UZ0JA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 2:26 AM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>>> This raises two question. First, why are there two primes? You could
>>> just as well using a single prime q and set p=q^64 mod 2^16. You then
>>> get
>>> S = sum V[i,j] * q^(64*(64-i) + (64-j)
>>> = sum V[i,j] * q^(4096 - 64*(i-1) - j)
>>> You get higher prime powers that way, but you can easily choose a prime
>>> that yields distinct values mod 2^16 for exponents up to 16383. Your
>>> PRIME2, for example, does. (It wraps around for 16384, i.e.
>>> PRIME2^16384 = 1 mod 2^16, but that's true for every possible prime since
>>> 16384 is the Carmichael function's value at 2^16)
>>
>> The experimental detection rate is about the same if we use a single
>> prime. But I think you have the analytical form wrong here. It should
>> be given q = p:
>>
>> S = sum V[i,j] * p^(64-i) * p^(64-j)
>> = sum V[i,j] * p^(64 - i + 64 - j)
>> = sum V[i,j] * p^(128 - i -j)
>
> Yeah, if you set q = p that's true. My suggestion was p=q^64 though...
So it was, I guess it was too late here and I missed it... All thing
considered that is a good suggestion, if for nothing else, the generic
implementation can be smaller this way.
>>> Second, why does it use addition instead of XOR? It seems that FNV
>>> usually XORs the terms together instead of adding them?
>>
>> Testing showed slightly better detection rate for adds. Intuitively I
>> think it's because the carry introduces some additional mixing.
>
> Hm, but OTOH it makes S linear in V, i.e. if you have two inputs
> V1,V2 and V = V1 + V2, then S = S1 + S2. Also, if V' = V*m, then
> S' = S*m. The second property is quite undesirable, I think. Assume
> all the V[i,j] are divisible by 2^k, i.e. have zeros at all bit
> positions 0..(k-1). Then, due to linearity, S is also divisible by
> 2^k, i.e. also has no ones before the k-th bit. This means, for example
> that if you hash values values which all have their lowest bit cleared,
> you get only 2^15 distinct hash values. If they all have the two
> lowest bits cleared, you get only 2^14 distinct values, and so on…
>
> Generally, linearity doesn't seem to be a property that one wants
> in a hash I think, so my suggestion is to stick to XOR.
This made me remember, the issue I had was with high order bits, not
with low order ones, somehow I got them confused. The exact issue is
that the high order bits don't affect any bit lower than them. It's
easy to see that if you remember the shift and add nature of multiply.
Unfortunately XOR will not fix that. Neither will adding an offset
basis. This is the fundamental thing that is behind the not-so-great
uncorrelated bit error detection rate.
While I understand that linearity is not a desirable property, I
couldn't think of a realistic case where it would hurt. I can see how
it can hurt checksums of variable length values, but for our fixed
buffer case it's definitely not so clear cut. On the pro side the
distributive property that is behind linearity allowed me to do final
aggregation in a tree form, performing the multiplies in parallel
instead of linearly. This adds up to the difference between 250 cycles
(64*(3 cycle IMUL + 1 cycle XOR)) and 25 cycles (4*5 cycle pmullw + 5
cycle addw). Given that the main loop is about 576 cycles, this is a
significant difference.
>>> Here, btw, is a page on FNV hashing. It mentions a few rules for
>>> picking suitable primes
>>>
>>> http://www.isthe.com/chongo/tech/comp/fnv
>>
>> Unfortunately the rules don't apply here because of the hash size.
>
> Yeah :-(.
>
> I noticed that their 32-bit prime only has a single one outside
> the first 16 bits. Maybe we can take advantage of that and use a
> 32-bit state while still providing decent performance on machines
> without a 32-bit x 32-bit -> 32-bit multiply instruction?
Looking at the Power instruction set, a 32bit mul by the FNV prime
would look like this:
vmulouh tmp1, hash, prime
vmladduhm tmp1, hash, prime<<16
vslw tmp2, hash, 24
vadduwm hash, tmp1, tmp2
That is 4 instructions to multiply 4 values. Depending on the specific
execution ports on the processor it might faster or slower than the
scalar version but not by a whole lot. Main benefit would be that the
intermediate state could be held in registers.
> If we lived in an Intel-only world, I'd suggest going with a
> 32-bit state, since SSE4.1 support is *very* wide-spread already -
> the last CPUs without it came out over 5 years ago, I think.
> (Core2 and later support SSE4.1, and some later Core1 do too)
>
> But unfortunately things look bleak even for other x86
> implementations - AMD support SSE4.1 only starting with
> Bulldozer, which came out 2011 or so I believe. Leaving the x86
> realm, it seems that only ARM's NEON provides the instructions
> we'd need - AltiVec seems to be support only 16-bit multiplies,
> and from what some quick googling brought up, MIPS and SPARC
> SIMD instructions look no better..
>
> OTOH, chances are that nobody will ever do SIMD implementations
> for those machines. In that case, working in 32-bit chunks instead
> of 16-bit chunks would be beneficial, since it requires half the
> number of instructions…
Great job finding the information about other instructionsets. I
checked Intel manuals and Itanium too is one of the 16bit pmul
architectures.
Working in 32-bit chunks would also help non-x86 platforms by reducing
the number of registers needed to hold state. Those architectures are
not as register starved and can hold most of the required state in
registers. This would speed them up to about the same speed as
Fletcher32/Adler32, which is about the best we can hope for without
vectorizing.
I wonder if we use 32bit FNV-1a's (the h = (h^v)*p variant) with
different offset-basis values, would it be enough to just XOR fold the
resulting values together. The algorithm looking like this:
static uint16
PageCalcChecksum16(Page page, BlockNumber blkno)
{
uint32 sums[N_SUMS];
uint32 (*pageArr)[N_SUMS] = (uint32 (*)[N_SUMS]) page;
uint32 final_sum;
int i, j;
/* initialize partial checksums to arbitrary offsets */
memcpy(sums, checksum_offsets, sizeof(checksum_offsets));
/* calculate N_SUMS parallel FNV-1a hashes over the page */
for (i = 0; BLCKSZ/sizeof(uint32)/N_SUMS; i++)
for (j = 0; j < N_SUMS; j++)
sums[j] = (sums[j] ^ pageArr[0][j]) * FNV_PRIME;
/* XOR fold hashes together */
final_sum = sums[i];
for (i = 1; i < N_SUMS; i++)
final_sum ^= sums[i];
/* mix in block number */
final_sum ^= blkno;
/* truncate to 16bits by modulo prime and offset by 1 to avoid zero */
return (final_sum % CHECKSUM_TRUNC) + 1;
}
The SSE4.1 implementation of this would be as fast as the last pat,
generic version will be faster and we avoid the linearity issue. By
using different offsets for each of the partial hashes we don't
directly suffer from commutativity of the final xor folding. By using
the xor-then-multiply variant the last values hashed have their bits
mixed before folding together.
Speaking against this option is the fact that we will need to do CPU
detection at startup to make it fast on the x86 that support SSE4.1,
and the fact that AMD CPUs before 2011 will run it an order of
magnitude slower (but still faster than the best CRC).
Any opinions if it would be a reasonable tradeoff to have a better
checksum with great performance on latest x86 CPUs and good
performance on other architectures at the expense of having only ok
performance on older AMD CPUs?
Also, any good suggestions where should we do CPU detection when we go
this route?
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 15:09:04 |
| Message-ID: | 20130417150904.GK5343@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 05:47:55PM +0300, Ants Aasma wrote:
> The SSE4.1 implementation of this would be as fast as the last pat,
> generic version will be faster and we avoid the linearity issue. By
> using different offsets for each of the partial hashes we don't
> directly suffer from commutativity of the final xor folding. By using
> the xor-then-multiply variant the last values hashed have their bits
> mixed before folding together.
>
> Speaking against this option is the fact that we will need to do CPU
> detection at startup to make it fast on the x86 that support SSE4.1,
> and the fact that AMD CPUs before 2011 will run it an order of
> magnitude slower (but still faster than the best CRC).
>
> Any opinions if it would be a reasonable tradeoff to have a better
> checksum with great performance on latest x86 CPUs and good
> performance on other architectures at the expense of having only ok
> performance on older AMD CPUs?
>
> Also, any good suggestions where should we do CPU detection when we go
> this route?
As much as I love the idea of improving the algorithm, it is disturbing
we are discussing this so close to beta, with an algorithm that is under
analysis, with no (runtime) CPU detection, and in something that is
going to be embedded into our data page format. I can't even think of
another case where we do run-time CPU detection.
I am wondering if we need to tell users that pg_upgrade will not be
possible if you enable page-level checksums, so we are not trapped with
something we want to improve in 9.4.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 15:28:06 |
| Message-ID: | 285666DD-B6D0-4D52-81DC-7037EF76E385@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr17, 2013, at 17:09 , Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> As much as I love the idea of improving the algorithm, it is disturbing
> we are discussing this so close to beta, with an algorithm that is under
> analysis, with no (runtime) CPU detection, and in something that is
> going to be embedded into our data page format. I can't even think of
> another case where we do run-time CPU detection.
We could still ship the new checksum algorithm with 9.3, but omit the
SSE-optimized version, i.e. include only the plain C implementation.
I think Ants mentioned somehwere that gcc does a pretty good job of
vectorizing that, so people who really care (and who use GCC)
could compile with -msse41 --unrool-loops --tree-vectorize, and get
performance close to that of a hand-coded SSE version.
The important decision we're facing is which algorithm to use. I personally
believe Ants is on the right track there - FNV or a variant thereof
looks like a good choice to me, but the details have yet to be nailed
I think.
However, you're right that time's running out. It'd be a shame though
if we'd lock ourselves into CRC as the only available algorithm essentially
forever. Is there any way we can change the checksum algorithm in 9.4
*without* breaking pg_upgrade? Maybe pd_pagesize_version could be used
for that - we could make version 5 mean "just like version 4, but with
a different checksum algorithm". Since the layout wouldn't actually
chance, that'd be far easier to pull off than actually supporting multiple
page layouts. If that works, then shipping 9.3 with CRC is probably
the best solution. If not, we should see to it that something like Ants
parallel version of FNV or a smallget into 9.3 if at all possible,
IMHO.
best regards,
Florian Pflug
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 15:54:46 |
| Message-ID: | 99343716-5F5A-45C8-B2F6-74B9BA357396@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr17, 2013, at 16:47 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
> This made me remember, the issue I had was with high order bits, not
> with low order ones, somehow I got them confused. The exact issue is
> that the high order bits don't affect any bit lower than them. It's
> easy to see that if you remember the shift and add nature of multiply.
> Unfortunately XOR will not fix that. Neither will adding an offset
> basis. This is the fundamental thing that is behind the not-so-great
> uncorrelated bit error detection rate.
Right. We could maybe fix that by extending the update step to
tmp = s[j] ^ d[i,j]
s[j] = (t * PRIME) ^ (t >> 1)
or something like that. Shifting t instead of (t * PRIME) should
help to reduce the performance impact, since a reordering CPU should
be able to parallelize the multiple and the shift. Note though that
I haven't really though that through extensively - the general idea
should be sound, but whether 1 is a good shifting amount I do not
know.
> While I understand that linearity is not a desirable property, I
> couldn't think of a realistic case where it would hurt. I can see how
> it can hurt checksums of variable length values, but for our fixed
> buffer case it's definitely not so clear cut. On the pro side the
> distributive property that is behind linearity allowed me to do final
> aggregation in a tree form, performing the multiplies in parallel
> instead of linearly. This adds up to the difference between 250 cycles
> (64*(3 cycle IMUL + 1 cycle XOR)) and 25 cycles (4*5 cycle pmullw + 5
> cycle addw). Given that the main loop is about 576 cycles, this is a
> significant difference.
> I wonder if we use 32bit FNV-1a's (the h = (h^v)*p variant) with
> different offset-basis values, would it be enough to just XOR fold the
> resulting values together. The algorithm looking like this:
Hm, this will make the algorithm less resilient to some particular
input permutations (e.g. those which swap the 64*i-th and the (64+1)-ith
words), but those seem very unlikely to occur randomly. But if we're
worried about that, we could use your linear combination method for
the aggregation phase.
> Speaking against this option is the fact that we will need to do CPU
> detection at startup to make it fast on the x86 that support SSE4.1,
> and the fact that AMD CPUs before 2011 will run it an order of
> magnitude slower (but still faster than the best CRC).
Hm, CPU detection isn't that hard, and given the speed at which Intel
currently invents new instructions we'll end up going that route sooner
or later anyway, I think.
> Any opinions if it would be a reasonable tradeoff to have a better
> checksum with great performance on latest x86 CPUs and good
> performance on other architectures at the expense of having only ok
> performance on older AMD CPUs?
The loss on AMD is offset by the increased performance on machines
where we can't vectorize, I'd say.
best regards,
Florian Pflug
| From: | Greg Stark <stark(at)mit(dot)edu> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 15:58:10 |
| Message-ID: | CAM-w4HPSefBjK+wn61PwVQLHt0tK_5KkbeLFbK71LYPJERk=cw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 4:28 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> Is there any way we can change the checksum algorithm in 9.4
> *without* breaking pg_upgrade?
Personally I think we're going to need a solution for page format
changes someday eventually....
What advantages are we postponing now to avoid it?
* 32-bit checksums?
* Being able to enable/disable checksums?
Anything else?
--
greg
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 16:15:05 |
| Message-ID: | 20130417161505.GL5343@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 05:28:06PM +0200, Florian Pflug wrote:
> However, you're right that time's running out. It'd be a shame though
> if we'd lock ourselves into CRC as the only available algorithm essentially
> forever. Is there any way we can change the checksum algorithm in 9.4
> *without* breaking pg_upgrade? Maybe pd_pagesize_version could be used
> for that - we could make version 5 mean "just like version 4, but with
> a different checksum algorithm". Since the layout wouldn't actually
> chance, that'd be far easier to pull off than actually supporting multiple
> page layouts. If that works, then shipping 9.3 with CRC is probably
> the best solution. If not, we should see to it that something like Ants
> parallel version of FNV or a smallget into 9.3 if at all possible,
> IMHO.
I was going to ask about the flexibility of pg_upgrade and checksums.
Right now you have to match the old and new cluster checksum modes, but
it seems it would be possible to allow pg_upgrade use from checksum to
no-checksum servers. Does the backend look at the pg_controldata setting,
or at the page checksum flag? If the former, it seems pg_upgrade could
run a a no-checksum server just fine that had checksum information on
its pages. This might give us more flexibility in changing the checksum
algorithm in the future, i.e. you only lose checksum ability.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 16:33:58 |
| Message-ID: | 62411714-DFBD-4D78-A2A6-AE574B6D26DD@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr17, 2013, at 18:15 , Bruce Momjian <bruce(at)momjian(dot)us> wrote:
> On Wed, Apr 17, 2013 at 05:28:06PM +0200, Florian Pflug wrote:
>> However, you're right that time's running out. It'd be a shame though
>> if we'd lock ourselves into CRC as the only available algorithm essentially
>> forever. Is there any way we can change the checksum algorithm in 9.4
>> *without* breaking pg_upgrade? Maybe pd_pagesize_version could be used
>> for that - we could make version 5 mean "just like version 4, but with
>> a different checksum algorithm". Since the layout wouldn't actually
>> chance, that'd be far easier to pull off than actually supporting multiple
>> page layouts. If that works, then shipping 9.3 with CRC is probably
>> the best solution. If not, we should see to it that something like Ants
>> parallel version of FNV or a smallget into 9.3 if at all possible,
>> IMHO.
>
> I was going to ask about the flexibility of pg_upgrade and checksums.
> Right now you have to match the old and new cluster checksum modes, but
> it seems it would be possible to allow pg_upgrade use from checksum to
> no-checksum servers. Does the backend look at the pg_controldata setting,
> or at the page checksum flag? If the former, it seems pg_upgrade could
> run a a no-checksum server just fine that had checksum information on
> its pages. This might give us more flexibility in changing the checksum
> algorithm in the future, i.e. you only lose checksum ability.
AFAIK, there's currently no per-page checksum flag. Still, being only
able to go from checksummed to not-checksummed probably is for all
practical purposes the same as not being able to pg_upgrade at all.
Otherwise, why would people have enabled checksums in the first place?
best regards,
Florian Pflug
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 16:42:51 |
| Message-ID: | 20130417164251.GN5343@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 06:33:58PM +0200, Florian Pflug wrote:
> > I was going to ask about the flexibility of pg_upgrade and checksums.
> > Right now you have to match the old and new cluster checksum modes, but
> > it seems it would be possible to allow pg_upgrade use from checksum to
> > no-checksum servers. Does the backend look at the pg_controldata setting,
> > or at the page checksum flag? If the former, it seems pg_upgrade could
> > run a a no-checksum server just fine that had checksum information on
> > its pages. This might give us more flexibility in changing the checksum
> > algorithm in the future, i.e. you only lose checksum ability.
>
> AFAIK, there's currently no per-page checksum flag. Still, being only
> able to go from checksummed to not-checksummed probably is for all
> practical purposes the same as not being able to pg_upgrade at all.
> Otherwise, why would people have enabled checksums in the first place?
Good point, but it is _an_ option, at least.
I would like to know the answer of how an upgrade from checksum to
no-checksum would behave so I can modify pg_upgrade to allow it.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Greg Stark <stark(at)mit(dot)edu> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Bruce Momjian <bruce(at)momjian(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 17:22:01 |
| Message-ID: | 4121.1366219321@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Greg Stark <stark(at)mit(dot)edu> writes:
> On Wed, Apr 17, 2013 at 4:28 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>> Is there any way we can change the checksum algorithm in 9.4
>> *without* breaking pg_upgrade?
> Personally I think we're going to need a solution for page format
> changes someday eventually....
> What advantages are we postponing now to avoid it?
Um, other than the ability to make a release?
We aren't going to hold up 9.3 until that particular bit of pie in the
sky lands. Indeed I don't expect to see it available in the next couple
years either. When we were looking at that seriously, two or three
years ago, arbitrary page format changes looked *hard*.
The idea of bumping the page format version number to signal a checksum
algorithm change might work though.
regards, tom lane
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Greg Stark <stark(at)mit(dot)edu>, Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 17:24:42 |
| Message-ID: | 20130417172442.GP5343@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 01:22:01PM -0400, Tom Lane wrote:
> Greg Stark <stark(at)mit(dot)edu> writes:
> > On Wed, Apr 17, 2013 at 4:28 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> >> Is there any way we can change the checksum algorithm in 9.4
> >> *without* breaking pg_upgrade?
>
> > Personally I think we're going to need a solution for page format
> > changes someday eventually....
>
> > What advantages are we postponing now to avoid it?
>
> Um, other than the ability to make a release?
>
> We aren't going to hold up 9.3 until that particular bit of pie in the
> sky lands. Indeed I don't expect to see it available in the next couple
> years either. When we were looking at that seriously, two or three
> years ago, arbitrary page format changes looked *hard*.
>
> The idea of bumping the page format version number to signal a checksum
> algorithm change might work though.
Uh, not sure how pg_upgrade would detect that as the version number is
not stored in pg_controldata, e.g.:
Data page checksums: enabled/disabled
Do we need to address this for 9.3? (Yuck)
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Stark <stark(at)mit(dot)edu>, Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 17:29:18 |
| Message-ID: | 4295.1366219758@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Bruce Momjian <bruce(at)momjian(dot)us> writes:
> Uh, not sure how pg_upgrade would detect that as the version number is
> not stored in pg_controldata, e.g.:
> Data page checksums: enabled/disabled
That seems pretty shortsighted. The field probably ought to be defined
as containing a checksum algorithm ID number, not a boolean.
But having said that, I'm not sure why this would be pg_upgrade's
problem. By definition, we do not want pg_upgrade running around
looking at individual data pages. Therefore, whatever we might do
about checksum algorithm changes would have to be something that can be
managed on-the-fly by the newer server.
regards, tom lane
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Greg Stark <stark(at)mit(dot)edu>, Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 18:10:17 |
| Message-ID: | 20130417181017.GQ5343@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 01:29:18PM -0400, Tom Lane wrote:
> Bruce Momjian <bruce(at)momjian(dot)us> writes:
> > Uh, not sure how pg_upgrade would detect that as the version number is
> > not stored in pg_controldata, e.g.:
>
> > Data page checksums: enabled/disabled
>
> That seems pretty shortsighted. The field probably ought to be defined
> as containing a checksum algorithm ID number, not a boolean.
>
> But having said that, I'm not sure why this would be pg_upgrade's
> problem. By definition, we do not want pg_upgrade running around
> looking at individual data pages. Therefore, whatever we might do
> about checksum algorithm changes would have to be something that can be
> managed on-the-fly by the newer server.
Well, my idea was that pg_upgrade would allow upgrades from old clusters
with the same checksum algorithm version, but not non-matching ones.
This would allow the checksum algorithm to be changed and force
pg_upgrade to fail.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Greg Stark <stark(at)mit(dot)edu>, Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 18:34:51 |
| Message-ID: | 7420.1366223691@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Bruce Momjian <bruce(at)momjian(dot)us> writes:
> On Wed, Apr 17, 2013 at 01:29:18PM -0400, Tom Lane wrote:
>> But having said that, I'm not sure why this would be pg_upgrade's
>> problem. By definition, we do not want pg_upgrade running around
>> looking at individual data pages. Therefore, whatever we might do
>> about checksum algorithm changes would have to be something that can be
>> managed on-the-fly by the newer server.
> Well, my idea was that pg_upgrade would allow upgrades from old clusters
> with the same checksum algorithm version, but not non-matching ones.
> This would allow the checksum algorithm to be changed and force
> pg_upgrade to fail.
It's rather premature to be defining pg_upgrade's behavior for a
situation that doesn't exist yet, and may very well never exist
in that form. It seems more likely to me that we'd want to allow
incremental algorithm changes, in which case pg_upgrade ought not do
anything about this case anyway.
regards, tom lane
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 20:59:12 |
| Message-ID: | 1366232352.4736.324.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-04-17 at 12:42 -0400, Bruce Momjian wrote:
> > AFAIK, there's currently no per-page checksum flag. Still, being only
> > able to go from checksummed to not-checksummed probably is for all
> > practical purposes the same as not being able to pg_upgrade at all.
> > Otherwise, why would people have enabled checksums in the first place?
>
> Good point, but it is _an_ option, at least.
>
> I would like to know the answer of how an upgrade from checksum to
> no-checksum would behave so I can modify pg_upgrade to allow it.
Why? 9.3 pg_upgrade certainly doesn't need it. When we get to 9.4, if
someone has checksums enabled and wants to disable it, why is pg_upgrade
the right time to do that? Wouldn't it make more sense to allow them to
do that at any time?
Regards,
Jeff Davis
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Stark <stark(at)mit(dot)edu> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Bruce Momjian <bruce(at)momjian(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 21:00:36 |
| Message-ID: | 1366232436.4736.326.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-04-17 at 16:58 +0100, Greg Stark wrote:
> On Wed, Apr 17, 2013 at 4:28 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> > Is there any way we can change the checksum algorithm in 9.4
> > *without* breaking pg_upgrade?
>
> Personally I think we're going to need a solution for page format
> changes someday eventually....
>
> What advantages are we postponing now to avoid it?
>
> * 32-bit checksums?
> * Being able to enable/disable checksums?
>
> Anything else?
I'm not sure that changing the page format is the most difficult part of
enabling/disabling checksums. It's easy enough to have page header bits
if the current information is not enough (and those bits were there, but
Heikki requested their removal and I couldn't think of a concrete reason
to keep them).
Eventually, it would be nice to be able to break the page format and
have more space for things like checksums (and probably a few other
things, maybe some visibility-related optimizations). But that's a few
years off and we don't have any real plan for that.
What I wanted to accomplish with this patch is the simplest checksum
mechanism that we could get that would be fast enough that many people
would be able to use it. I expect it to be useful until we do decide to
break the page format.
Regards,
Jeff Davis
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 21:36:38 |
| Message-ID: | 20130417213638.GR5343@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 01:59:12PM -0700, Jeff Davis wrote:
> On Wed, 2013-04-17 at 12:42 -0400, Bruce Momjian wrote:
> > > AFAIK, there's currently no per-page checksum flag. Still, being only
> > > able to go from checksummed to not-checksummed probably is for all
> > > practical purposes the same as not being able to pg_upgrade at all.
> > > Otherwise, why would people have enabled checksums in the first place?
> >
> > Good point, but it is _an_ option, at least.
> >
> > I would like to know the answer of how an upgrade from checksum to
> > no-checksum would behave so I can modify pg_upgrade to allow it.
>
> Why? 9.3 pg_upgrade certainly doesn't need it. When we get to 9.4, if
> someone has checksums enabled and wants to disable it, why is pg_upgrade
> the right time to do that? Wouldn't it make more sense to allow them to
> do that at any time?
Well, right now, pg_upgrade is the only way you could potentially turn
off checksums. You are right that we might eventually want a command,
but my point is that we currently have a limitation in pg_upgrade that
might not be necessary.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 21:44:02 |
| Message-ID: | CA+CSw_u7QSNegqE196q4wOfgR8xxK_agj=M_NG1t+seTdJNxAg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 6:54 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> On Apr17, 2013, at 16:47 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> This made me remember, the issue I had was with high order bits, not
>> with low order ones, somehow I got them confused. The exact issue is
>> that the high order bits don't affect any bit lower than them. It's
>> easy to see that if you remember the shift and add nature of multiply.
>> Unfortunately XOR will not fix that. Neither will adding an offset
>> basis. This is the fundamental thing that is behind the not-so-great
>> uncorrelated bit error detection rate.
>
> Right. We could maybe fix that by extending the update step to
>
> tmp = s[j] ^ d[i,j]
> s[j] = (t * PRIME) ^ (t >> 1)
>
> or something like that. Shifting t instead of (t * PRIME) should
> help to reduce the performance impact, since a reordering CPU should
> be able to parallelize the multiple and the shift. Note though that
> I haven't really though that through extensively - the general idea
> should be sound, but whether 1 is a good shifting amount I do not
> know.
I was thinking about something similar too. The big issue here is that
the parallel checksums already hide each other latencies effectively
executing one each of movdqu/pmullw/paddw each cycle, that's why the
N_SUMS adds up to 128 bytes not 16 bytes.
I went ahead and coded up both the parallel FNV-1a and parallel FNV-1a
+ srl1-xor variants and ran performance tests and detection rate tests
on both.
Performance results:
Mul-add checksums: 12.9 bytes/s
FNV-1a checksums: 13.5 bytes/s
FNV-1a + srl-1: 7.4 bytes/s
Detection rates:
False positive rates:
Add-mul FNV-1a FNV-1a + srl-1
Single bit flip: 1:inf 1:129590 1:64795
Double bit flip: 1:148 1:511 1:53083
Triple bit flip: 1:673 1:5060 1:61511
Quad bit flip: 1:1872 1:19349 1:68320
Write 0x00 byte: 1:774538137 1:118776 1:68952
Write 0xFF byte: 1:165399500 1:137489 1:68958
Partial write: 1:59949 1:71939 1:89923
Write garbage: 1:64866 1:64980 1:67732
Write run of 00: 1:57077 1:61140 1:59723
Write run of FF: 1:63085 1:59609 1:62977
Test descriptions:
N bit flip: picks N random non-overlapping bits and flips their value.
Write X byte: overwrites a single byte with X.
Partial write: picks a random cut point, overwrites everything from
there to end with 0x00.
Write garbage/run of X: picks two random cut points and fills
everything in between with random values/X bytes.
So adding in the shifted value nearly cuts the performance in half. I
think that by playing with the instruction order I might coax the CPU
scheduler to schedule the instructions better, but even in best case
it will be somewhat slower. The point to keep in mind that even this
slower speed is still faster than hardware accelerated CRC32, so all
in all the hit might not be so bad. The effect on false positive rates
for double bit errors is particularly impressive. I'm now running a
testrun that shift right by 13 to see how that works out, intuitively
it should help dispersing the bits a lot faster.
>> I wonder if we use 32bit FNV-1a's (the h = (h^v)*p variant) with
>> different offset-basis values, would it be enough to just XOR fold the
>> resulting values together. The algorithm looking like this:
>
> Hm, this will make the algorithm less resilient to some particular
> input permutations (e.g. those which swap the 64*i-th and the (64+1)-ith
> words), but those seem very unlikely to occur randomly. But if we're
> worried about that, we could use your linear combination method for
> the aggregation phase.
I don't think it significantly reduces resilience to permutations
thanks to using different basis offsets and multiply not distributing
over xor.
>> Speaking against this option is the fact that we will need to do CPU
>> detection at startup to make it fast on the x86 that support SSE4.1,
>> and the fact that AMD CPUs before 2011 will run it an order of
>> magnitude slower (but still faster than the best CRC).
>
> Hm, CPU detection isn't that hard, and given the speed at which Intel
> currently invents new instructions we'll end up going that route sooner
> or later anyway, I think.
Sure it's not that hard but it does have an order of magnitude more
design decisions than #if defined(__x86_64__). Maybe a first stab
could avoid a generic infrastructure and just have the checksum
function as a function pointer, with the default "trampoline"
implementation running a cpuid and overwriting the function pointer
with either the optimized or generic versions and then calling it.
>> Any opinions if it would be a reasonable tradeoff to have a better
>> checksum with great performance on latest x86 CPUs and good
>> performance on other architectures at the expense of having only ok
>> performance on older AMD CPUs?
>
> The loss on AMD is offset by the increased performance on machines
> where we can't vectorize, I'd say.
+1 Old AMD machines won't soon be used by anyone caring about
performance, where a lousy checksum algorithm will stick around for a
while.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 22:32:05 |
| Message-ID: | 12819.1366237925@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Ants Aasma <ants(at)cybertec(dot)at> writes:
> I was thinking about something similar too. The big issue here is that
> the parallel checksums already hide each other latencies effectively
> executing one each of movdqu/pmullw/paddw each cycle, that's why the
> N_SUMS adds up to 128 bytes not 16 bytes.
The more I read of this thread, the more unhappy I get. It appears that
the entire design process is being driven by micro-optimization for CPUs
being built by Intel in 2013. That ought to be, at best, a fifth-order
consideration, with full recognition that it'll be obsolete in two years,
and is already irrelevant to anyone not running one of those CPUs.
I would like to ban all discussion of assembly-language optimizations
until after 9.3 is out, so that we can concentrate on what actually
matters. Which IMO is mostly the error detection rate and the probable
nature of false successes. I'm glad to see that you're paying at least
some attention to that, but the priorities in this discussion are
completely backwards.
And I reiterate that there is theory out there about the error detection
capabilities of CRCs. I'm not seeing any theory here, which leaves me
with very little confidence that we know what we're doing.
regards, tom lane
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 23:09:23 |
| Message-ID: | 3A16C439-AC0F-4842-A4DD-BD25526462BF@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr18, 2013, at 00:32 , Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Ants Aasma <ants(at)cybertec(dot)at> writes:
>> I was thinking about something similar too. The big issue here is that
>> the parallel checksums already hide each other latencies effectively
>> executing one each of movdqu/pmullw/paddw each cycle, that's why the
>> N_SUMS adds up to 128 bytes not 16 bytes.
>
> The more I read of this thread, the more unhappy I get. It appears that
> the entire design process is being driven by micro-optimization for CPUs
> being built by Intel in 2013. That ought to be, at best, a fifth-order
> consideration, with full recognition that it'll be obsolete in two years,
> and is already irrelevant to anyone not running one of those CPUs.
Micro-optimization for particular CPUs yes, but general performance
considerations, no. For example, 2^n is probably one of the worst modulus
you can pick for a hash function - any prime would work much better.
But doing the computations modulo 2^16 or 2^32 carries zero performance
overhead, whereas picking another modulus requires some renormalization
after every operation. That, however, is *not* a given - it stems from
the fact nearly all CPUs in existence operated on binary integers. This
fact must thus enter into the design phase very early, and makes
2^16 or 2^32 a sensible choice for a modulus *despite* it's shortcomings,
simply because it allows for fast implementations.
> I would like to ban all discussion of assembly-language optimizations
> until after 9.3 is out, so that we can concentrate on what actually
> matters. Which IMO is mostly the error detection rate and the probable
> nature of false successes. I'm glad to see that you're paying at least
> some attention to that, but the priorities in this discussion are
> completely backwards.
I'd say lots of attention is paid to that, but there's *also* attention
paid to speed. Which I good, because ideally we want to end up with
a checksum with both has good error-detection properties *and* good
performance. If performance is of no concern to us, then there's little
reason not to use CRC…
> And I reiterate that there is theory out there about the error detection
> capabilities of CRCs. I'm not seeing any theory here, which leaves me
> with very little confidence that we know what we're doing.
If you've got any pointers to literature on error-detection capabilities
of CPU-friendly checksum functions, please share. I am aware of the vast
literature on CRC, and also on some other algebraic approaches, but
none of those even come close to the speed of FNV+shift (unless there's
a special CRC instruction, that is). And there's also a ton of stuff on
cryptographic hashing, but those are optimized for a completely different
use-case...
best regards,
Florian Pflug
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 23:25:52 |
| Message-ID: | 126F7E97-8E72-409B-975E-60F1AC54311F@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr17, 2013, at 23:44 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
> Performance results:
> Mul-add checksums: 12.9 bytes/s
> FNV-1a checksums: 13.5 bytes/s
> FNV-1a + srl-1: 7.4 bytes/s
>
> Detection rates:
> False positive rates:
> Add-mul FNV-1a FNV-1a + srl-1
> Single bit flip: 1:inf 1:129590 1:64795
> Double bit flip: 1:148 1:511 1:53083
> Triple bit flip: 1:673 1:5060 1:61511
> Quad bit flip: 1:1872 1:19349 1:68320
> Write 0x00 byte: 1:774538137 1:118776 1:68952
> Write 0xFF byte: 1:165399500 1:137489 1:68958
> Partial write: 1:59949 1:71939 1:89923
> Write garbage: 1:64866 1:64980 1:67732
> Write run of 00: 1:57077 1:61140 1:59723
> Write run of FF: 1:63085 1:59609 1:62977
>
> Test descriptions:
> N bit flip: picks N random non-overlapping bits and flips their value.
> Write X byte: overwrites a single byte with X.
> Partial write: picks a random cut point, overwrites everything from
> there to end with 0x00.
> Write garbage/run of X: picks two random cut points and fills
> everything in between with random values/X bytes.
Cool, thanks for testing that! The results for FNV-1a + srl-1 look
promising, I think. Its failure rate is consistently about 1:2^16,
which is the value you'd expect. That gives me some confidence that
the additional shift as working as expected.
BTW, which prime are you using for FNV-1a and FNV-1a+srl1?
> So adding in the shifted value nearly cuts the performance in half. I
> think that by playing with the instruction order I might coax the CPU
> scheduler to schedule the instructions better, but even in best case
> it will be somewhat slower. The point to keep in mind that even this
> slower speed is still faster than hardware accelerated CRC32, so all
> in all the hit might not be so bad.
Yeah. ~7 bytes/cycle still translates to over 10GB/s on typical CPU,
so that's still plenty fast I'd say...
> The effect on false positive rates
> for double bit errors is particularly impressive. I'm now running a
> testrun that shift right by 13 to see how that works out, intuitively
> it should help dispersing the bits a lot faster.
Maybe, but it also makes *only* bits 14 and 15 actually affects bits
below them, because all other's are shifted out. If you choose the
right prime it may still work, you'd have to pick one which with
enough lower bits set so that every bits affects bit 14 or 15 at some
point…
All in all a small shift seems better to me - if 1 for some reason
isn't a good choice, I'd expect 3 or so to be a suitable
replacement, but nothing much larger…
I should have some time tomorrow to spent on this, and will try
to validate our FNV-1a modification, and see if I find a way to judge
whether 1 is a good shift.
>>> I wonder if we use 32bit FNV-1a's (the h = (h^v)*p variant) with
>>> different offset-basis values, would it be enough to just XOR fold the
>>> resulting values together. The algorithm looking like this:
>>
>> Hm, this will make the algorithm less resilient to some particular
>> input permutations (e.g. those which swap the 64*i-th and the (64+1)-ith
>> words), but those seem very unlikely to occur randomly. But if we're
>> worried about that, we could use your linear combination method for
>> the aggregation phase.
>
> I don't think it significantly reduces resilience to permutations
> thanks to using different basis offsets and multiply not distributing
> over xor.
Oh, yeah, I though you were still using 0 as base offset. If you don't,
the objection is moot.
best regards,
Florian Pflug
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-17 23:56:15 |
| Message-ID: | CA+CSw_soQRHONU984YiKEvTY7Ug6UyfCSvy_zNhkKTBnsiJvPA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 1:32 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Ants Aasma <ants(at)cybertec(dot)at> writes:
>> I was thinking about something similar too. The big issue here is that
>> the parallel checksums already hide each other latencies effectively
>> executing one each of movdqu/pmullw/paddw each cycle, that's why the
>> N_SUMS adds up to 128 bytes not 16 bytes.
>
> The more I read of this thread, the more unhappy I get. It appears that
> the entire design process is being driven by micro-optimization for CPUs
> being built by Intel in 2013. That ought to be, at best, a fifth-order
> consideration, with full recognition that it'll be obsolete in two years,
> and is already irrelevant to anyone not running one of those CPUs.
The large scale structure takes into account the trends in computer
architecture. A lot more so than using anything straight out of the
literature. Specifically, computer architectures have hit a wall in
terms of sequential throughput, so the linear dependency chain in the
checksum algorithm will be the bottleneck soon if it isn't already.
From that it follows that a fast and future proof algorithm should not
calculate the checksum in a single log chain. The proposed algorithms
divide the input into 64x64 and 32x64 chunks. It's easy to show that
both convert the dependency chain from O(n) to O(sqrt(n)). Secondly,
unless we pick something really popular, CPUs are unlikely to provide
specifically for us, so the algorithm should be built from general
purpose computational pieces. Vector integer multiply and xor are
pretty much guaranteed to be there and fast on future CPUs. In my view
it's much more probable to be available and fast on future CPU's than
something like the Intel CRC32 acceleration.
> I would like to ban all discussion of assembly-language optimizations
> until after 9.3 is out, so that we can concentrate on what actually
> matters. Which IMO is mostly the error detection rate and the probable
> nature of false successes. I'm glad to see that you're paying at least
> some attention to that, but the priorities in this discussion are
> completely backwards.
I approached it from the angle that what needs to be done to get a
fundamentally fast approach have a good enough error detection rate
and not have a way of generating false positives that will give a
likely error. The algorithms are simple enough and well studied enough
that the rewards from tweaking them are negligible. I think the
resulting performance speaks for itself. Now the question is what is a
good enough algorithm. In my view, the checksum is more like a canary
in the coal mine, not something that can be relied upon, and so
ultimate efficiency is not that important if there are no obvious
horrible cases. I can see that there are other views and so am
exploring different tradeoffs between performance and quality.
> And I reiterate that there is theory out there about the error detection
> capabilities of CRCs. I'm not seeing any theory here, which leaves me
> with very little confidence that we know what we're doing.
I haven't found much literature that is of use here. There is theory
underlying here coming from basic number theory and distilled into
rules for hash functions. For the FNV hash the prime supposedly is
carefully chosen, although all literature so far is saying "it is a
good choice, but here is not the place to explain why".
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 00:05:35 |
| Message-ID: | CA+CSw_uizH4DJKMsdWP1rJA7xXw+AFy673XDwGfYkC+_LLS6Dg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 2:25 AM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> On Apr17, 2013, at 23:44 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> Performance results:
>> Mul-add checksums: 12.9 bytes/s
>> FNV-1a checksums: 13.5 bytes/s
>> FNV-1a + srl-1: 7.4 bytes/s
>>
>> Detection rates:
>> False positive rates:
>> Add-mul FNV-1a FNV-1a + srl-1
>> Single bit flip: 1:inf 1:129590 1:64795
>> Double bit flip: 1:148 1:511 1:53083
>> Triple bit flip: 1:673 1:5060 1:61511
>> Quad bit flip: 1:1872 1:19349 1:68320
>> Write 0x00 byte: 1:774538137 1:118776 1:68952
>> Write 0xFF byte: 1:165399500 1:137489 1:68958
>> Partial write: 1:59949 1:71939 1:89923
>> Write garbage: 1:64866 1:64980 1:67732
>> Write run of 00: 1:57077 1:61140 1:59723
>> Write run of FF: 1:63085 1:59609 1:62977
>>
>> Test descriptions:
>> N bit flip: picks N random non-overlapping bits and flips their value.
>> Write X byte: overwrites a single byte with X.
>> Partial write: picks a random cut point, overwrites everything from
>> there to end with 0x00.
>> Write garbage/run of X: picks two random cut points and fills
>> everything in between with random values/X bytes.
>
> Cool, thanks for testing that! The results for FNV-1a + srl-1 look
> promising, I think. Its failure rate is consistently about 1:2^16,
> which is the value you'd expect. That gives me some confidence that
> the additional shift as working as expected.
>
> BTW, which prime are you using for FNV-1a and FNV-1a+srl1?
The official 32bit FNV one, 16777619.
Offsets were just random numbers. Seems good enough given the
following from the FNV page:
"These non-zero integers are the FNV-0 hashes of the following 32 octets:
chongo <Landon Curt Noll> /\../\"
>> The effect on false positive rates
>> for double bit errors is particularly impressive. I'm now running a
>> testrun that shift right by 13 to see how that works out, intuitively
>> it should help dispersing the bits a lot faster.
Empirical results are slightly better with shift of 13:
Single bit flip: 1:61615
Double bit flip: 1:58078
Triple bit flip: 1:66329
Quad bit flip: 1:62141
Write 0x00 byte: 1:66327
Write 0xFF byte: 1:65274
Partial write: 1:71939
Write garbage: 1:65095
Write run of 0: 1:62845
Write run of FF: 1:64638
> Maybe, but it also makes *only* bits 14 and 15 actually affects bits
> below them, because all other's are shifted out. If you choose the
> right prime it may still work, you'd have to pick one which with
> enough lower bits set so that every bits affects bit 14 or 15 at some
> point…
>
> All in all a small shift seems better to me - if 1 for some reason
> isn't a good choice, I'd expect 3 or so to be a suitable
> replacement, but nothing much larger…
I don't think the big shift is a problem, the other bits were taken
into account by the multiply, and with the larger shift the next
multiplication will disperse the changes once again. Nevertheless, I'm
running the tests with shift of 3 now.
> I should have some time tomorrow to spent on this, and will try
> to validate our FNV-1a modification, and see if I find a way to judge
> whether 1 is a good shift.
Great. I will spend some brain cycles on it too.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 00:21:42 |
| Message-ID: | 516F3C96.4020504@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 4/17/13 6:32 PM, Tom Lane wrote:
> The more I read of this thread, the more unhappy I get. It appears that
> the entire design process is being driven by micro-optimization for CPUs
> being built by Intel in 2013.
And that's not going to get anyone past review, since all the tests I've
been doing the last two weeks are on how fast an AMD Opteron 6234 with
OS cache >> shared_buffers can run this. The main thing I'm still
worried about is what happens when you have a fast machine that can move
memory around very quickly and an in-memory workload, but it's hamstrung
by the checksum computation--and it's not a 2013 Intel machine.
The question I started with here was answered to some depth and then
skipped past. I'd like to jerk attention back to that, since I thought
some good answers from Ants went by. Is there a simple way to optimize
the committed CRC computation (or a similar one with the same error
detection properties) based on either:
a) Knowing that the input will be a 8K page, rather than the existing
use case with an arbitrary sized WAL section.
b) Straightforward code rearrangement or optimization flags.
That was all I thought was still feasible to consider changing for 9.3 a
few weeks ago. And the possible scope has only been shrinking since then.
> And I reiterate that there is theory out there about the error detection
> capabilities of CRCs. I'm not seeing any theory here, which leaves me
> with very little confidence that we know what we're doing.
Let me see if I can summarize where the messages flying by are at since
you'd like to close this topic for now:
-Original checksum feature used Fletcher checksums. Its main problems,
to quote wikipedia, include that it "cannot distinguish between blocks
of all 0 bits and blocks of all 1 bits".
-Committed checksum feature uses truncated CRC-32. This has known good
error detection properties, but is expensive to compute. There's reason
to believe that particular computation will become cheaper on future
platforms though. But taking full advantage of that will require adding
CPU-specific code to the database.
-The latest idea is using the Fowler–Noll–Vo hash function:
https://en.wikipedia.org/wiki/Fowler_Noll_Vo_hash There's 20 years of
research around when that is good or bad. The exactly properties depend
on magic "FNV primes": http://isthe.com/chongo/tech/comp/fnv/#fnv-prime
that can vary based on both your target block size and how many bytes
you'll process at a time. For PostgreSQL checksums, one of the common
problems--getting an even distribution of the hashed values--isn't
important the way it is for other types of hashes. Ants and Florian
have now dug into how exactly that and specific CPU optimization
concerns impact the best approach for 8K database pages. This is very
clearly a 9.4 project that is just getting started.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 00:56:15 |
| Message-ID: | CA+CSw_vL3Lc-csRe4Aa4Z7Vh1ARfLQMQW-r2DSg6jDOeXEVq4Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 3:21 AM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 4/17/13 6:32 PM, Tom Lane wrote:
>>
>> The more I read of this thread, the more unhappy I get. It appears that
>> the entire design process is being driven by micro-optimization for CPUs
>> being built by Intel in 2013.
>
>
> And that's not going to get anyone past review, since all the tests I've
> been doing the last two weeks are on how fast an AMD Opteron 6234 with OS
> cache >> shared_buffers can run this. The main thing I'm still worried
> about is what happens when you have a fast machine that can move memory
> around very quickly and an in-memory workload, but it's hamstrung by the
> checksum computation--and it's not a 2013 Intel machine.
>
> The question I started with here was answered to some depth and then skipped
> past. I'd like to jerk attention back to that, since I thought some good
> answers from Ants went by. Is there a simple way to optimize the committed
> CRC computation (or a similar one with the same error detection properties)
> based on either:
>
> a) Knowing that the input will be a 8K page, rather than the existing use
> case with an arbitrary sized WAL section.
>
> b) Straightforward code rearrangement or optimization flags.
>
> That was all I thought was still feasible to consider changing for 9.3 a few
> weeks ago. And the possible scope has only been shrinking since then.
Nothing from the two points, but the CRC calculation algorithm can be
switched out for slice-by-4 or slice-by-8 variant. Speed up was around
factor of 4 if I remember correctly.
>> And I reiterate that there is theory out there about the error detection
>> capabilities of CRCs. I'm not seeing any theory here, which leaves me
>> with very little confidence that we know what we're doing.
>
>
> Let me see if I can summarize where the messages flying by are at since
> you'd like to close this topic for now:
>
> -Original checksum feature used Fletcher checksums. Its main problems, to
> quote wikipedia, include that it "cannot distinguish between blocks of all 0
> bits and blocks of all 1 bits".
That was only the most glaring problem.
> -Committed checksum feature uses truncated CRC-32. This has known good
> error detection properties, but is expensive to compute. There's reason to
> believe that particular computation will become cheaper on future platforms
> though. But taking full advantage of that will require adding CPU-specific
> code to the database.
Actually the state is that with the polynomial used there is currently
close to zero hope of CPUs optimizing for us. By switching the
polynomial we can have hardware acceleration on Intel CPUs, little
hope of others supporting given that AMD hasn't by now and Intel touts
around patents in this area. However the calculation can be made about
factor of 4 faster by restructuring the calculation. This optimization
is plain C and not CPU specific.
The committed checksum is an order of magnitude slower than the
Fletcher one that was performance tested with the patch.
> -The latest idea is using the Fowler–Noll–Vo hash function:
> https://en.wikipedia.org/wiki/Fowler_Noll_Vo_hash There's 20 years of
> research around when that is good or bad. The exactly properties depend on
> magic "FNV primes": http://isthe.com/chongo/tech/comp/fnv/#fnv-prime that
> can vary based on both your target block size and how many bytes you'll
> process at a time. For PostgreSQL checksums, one of the common
> problems--getting an even distribution of the hashed values--isn't important
> the way it is for other types of hashes. Ants and Florian have now dug into
> how exactly that and specific CPU optimization concerns impact the best
> approach for 8K database pages. This is very clearly a 9.4 project that is
> just getting started.
I'm not sure about the 9.4 part: if we ship with the builtin CRC as
committed, there is a 100% chance that we will want to switch out the
algorithm in 9.4, and there will be quite a large subset of users that
will find the performance unusable. If we change it to whatever we
come up with here, there is a small chance that the algorithm will
give worse than expected error detection rate in some circumstances
and we will want offer a better algorithm. More probably it will be
good enough and the low performance hit will allow more users to turn
it on. This is a 16bit checksum that we talking about, not SHA-1, it
is expected to occasionally fail to detect errors. I can provide you
with a patch of the generic version of any of the discussed algorithms
within an hour, leaving plenty of time in beta or in 9.4 to
accommodate the optimized versions. It's literally a dozen self
contained lines of code.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 01:16:36 |
| Message-ID: | CAAZKuFY+6TYosFrE-nSNBvxw5rSMFzkgrPxm=nNfoED6C+vfPA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 5:21 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> Let me see if I can summarize where the messages flying by are at since
> you'd like to close this topic for now:
>
> -Original checksum feature used Fletcher checksums. Its main problems, to
> quote wikipedia, include that it "cannot distinguish between blocks of all 0
> bits and blocks of all 1 bits".
>
> -Committed checksum feature uses truncated CRC-32. This has known good
> error detection properties, but is expensive to compute. There's reason to
> believe that particular computation will become cheaper on future platforms
> though. But taking full advantage of that will require adding CPU-specific
> code to the database.
>
> -The latest idea is using the Fowler–Noll–Vo hash function:
> https://en.wikipedia.org/wiki/Fowler_Noll_Vo_hash There's 20 years of
> research around when that is good or bad. The exactly properties depend on
> magic "FNV primes": http://isthe.com/chongo/tech/comp/fnv/#fnv-prime that
> can vary based on both your target block size and how many bytes you'll
> process at a time. For PostgreSQL checksums, one of the common
> problems--getting an even distribution of the hashed values--isn't important
> the way it is for other types of hashes. Ants and Florian have now dug into
> how exactly that and specific CPU optimization concerns impact the best
> approach for 8K database pages. This is very clearly a 9.4 project that is
> just getting started.
I was curious about the activity in this thread and wanted to understand
the tradeoffs, and came to the same understanding as you when poking
around. It seems the tough aspect of the equation is that the most
well studied thing is slow (CRC-32C) unless you have special ISA
support Trying to find as much information and conclusive research on
FNV was a lot more challenging. Fletcher is similar in that regard.
Given my hasty attempt to understand each of the alternatives, my
qualitative judgement is that, strangely enough, the most conservative
choice of the three (in terms of being understood and treated in the
literature more than ten times over) is CRC-32C, but it's also the one
being cast as only suitable inside micro-optimization. To add
another, theoretically-oriented dimension to the discussion, I'd like
suggest it's also the most thoroughly studied of all the alternatives.
I really had a hard time finding follow-up papers about the two
alternatives, but to be fair, I didn't try very hard...then again, I
didn't try very hard for any of the three, it's just that CRC32C was
by far the easiest find materials on.
The original paper is often shorthanded "Castagnoli 93", but it exists
in the IEEE's sphere of influence and is hard to find a copy of.
Luckily, a pretty interesting survey paper discussing some of the
issues was written by Koopman in 2002 and is available:
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.11.8323 As a
pedagolgical note, it's pretty interesting and accessible piece of
writing (for me, as someone who knows little of error
detection/correction) and explains some of the engineering reasons
that provoke such exercises.
Basically...if it comes down to understand what the heck is going on
and what the trade-offs are, it was a lot easier to brush up on
CRC32-C in my meandering around the Internet.
One might think this level of scrutiny would constitute a viable
explanation of why CRC32C found its way into several standards and
then finally in silicon.
All in all, if the real world costs of CRC32C on not-SSE4.2 are
allowable, I think it's the most researched and and conservative
option, although perhaps some of the other polynomials seen in Koopman
could also be desirable. It seems there's a tradeoff in CRC
polynomials between long-message and short-message error detection,
and the paper above may allow for a more informed selection. CRC32C
is considered a good trade-off for both, but I haven't assessed the
paper in enough detail to suggest whether there are specialized
long-run polynomials that may be better still (although, then, there
is also the microoptimization question, which postdates the literature
I was looking at by a lot).
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 02:08:10 |
| Message-ID: | 516F558A.7020907@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 4/17/13 8:56 PM, Ants Aasma wrote:
> Nothing from the two points, but the CRC calculation algorithm can be
> switched out for slice-by-4 or slice-by-8 variant. Speed up was around
> factor of 4 if I remember correctly...I can provide you
> with a patch of the generic version of any of the discussed algorithms
> within an hour, leaving plenty of time in beta or in 9.4 to
> accommodate the optimized versions.
Can you nail down a solid, potential for commit slice-by-4 or slice-by-8
patch then? You dropped into things like per-byte overhead to reach
this conclusion, which was fine to let the methods battle each other.
Maybe I missed it, but I didn't remember seeing an obvious full patch
for this implementation then come back up from that. With the schedule
pressure this needs to return to more database-level tests. Your
concerns about the committed feature being much slower then the original
Fletcher one are troubling, and we might as well do that showdown again
now with the best of the CRC implementations you've found.
> Actually the state is that with the [CRC] polynomial used there is
> currently close to zero hope of CPUs optimizing for us.
Ah, I didn't catch that before. It sounds like the alternate slicing
implementation should also use a different polynomial then, which sounds
reasonable. This doesn't even have to be exactly the same CRC function
that the WAL uses. A CRC that's modified for performance or having a
better future potential is fine; there's just a lot of resistance to
using something other than a CRC right now.
> I'm not sure about the 9.4 part: if we ship with the builtin CRC as
> committed, there is a 100% chance that we will want to switch out the
> algorithm in 9.4, and there will be quite a large subset of users that
> will find the performance unusable.
Now I have to switch out my reviewer hat for my 3 bit fortune telling
one. (It uses a Magic 8 Ball) This entire approach is squeezing what
people would prefer to be a 32 bit CRC into a spare 16 bits, as a useful
step advancing toward a long term goal. I have four major branches of
possible futures here I've thought about:
1) Database checksums with 16 bits are good enough, but they have to be
much faster to satisfy users. It may take a different checksum
implementation altogether to make that possible, and distinguishing
between the two of them requires borrowing even more metadata bits from
somewhere. (This seems the future you're worried about)
2) Database checksums work out well, but they have to be 32 bits to
satisfy users and/or error detection needs. Work on pg_upgrade and
expanding the page headers will be needed. Optimization of the CRC now
has a full 32 bit target.
3) The demand for database checksums is made obsolete by either
mainstream filesystem checksumming, performance issues, or just general
market whim. The 16 bit checksum PostgreSQL implements becomes a
vestigial feature, and whenever it gets in the way of making changes
someone proposes eliminating them. (I call this one the "rules" future)
4) 16 bit checksums turn out to be such a problem in the field that
everyone regrets the whole thing, and discussions turn immediately
toward how to eliminate that risk.
It's fair that you're very concerned about (1), but I wouldn't give it
100% odds of happening either. The user demand that's motivated me to
work on this will be happy with any of (1) through (3), and in two of
them optimizing the 16 bit checksums now turns out to be premature.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Daniel Farina <daniel(at)heroku(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 06:08:00 |
| Message-ID: | 20130418060800.GA24426@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-17 18:16:36 -0700, Daniel Farina wrote:
> The original paper is often shorthanded "Castagnoli 93", but it exists
> in the IEEE's sphere of influence and is hard to find a copy of.
> Luckily, a pretty interesting survey paper discussing some of the
> issues was written by Koopman in 2002 and is available:
> http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.11.8323 As a
> pedagolgical note, it's pretty interesting and accessible piece of
> writing (for me, as someone who knows little of error
> detection/correction) and explains some of the engineering reasons
> that provoke such exercises.
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=231911&userType=inst
There's also a koopman paper from 2004 thats interesting.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 06:09:35 |
| Message-ID: | 20130418060935.GB24426@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-18 00:44:02 +0300, Ants Aasma wrote:
> I went ahead and coded up both the parallel FNV-1a and parallel FNV-1a
> + srl1-xor variants and ran performance tests and detection rate tests
> on both.
>
> Performance results:
> Mul-add checksums: 12.9 bytes/s
> FNV-1a checksums: 13.5 bytes/s
> FNV-1a + srl-1: 7.4 bytes/s
>
> Detection rates:
> False positive rates:
> Add-mul FNV-1a FNV-1a + srl-1
> Single bit flip: 1:inf 1:129590 1:64795
> Double bit flip: 1:148 1:511 1:53083
> Triple bit flip: 1:673 1:5060 1:61511
> Quad bit flip: 1:1872 1:19349 1:68320
> Write 0x00 byte: 1:774538137 1:118776 1:68952
> Write 0xFF byte: 1:165399500 1:137489 1:68958
> Partial write: 1:59949 1:71939 1:89923
> Write garbage: 1:64866 1:64980 1:67732
> Write run of 00: 1:57077 1:61140 1:59723
> Write run of FF: 1:63085 1:59609 1:62977
>
> Test descriptions:
> N bit flip: picks N random non-overlapping bits and flips their value.
> Write X byte: overwrites a single byte with X.
> Partial write: picks a random cut point, overwrites everything from
> there to end with 0x00.
> Write garbage/run of X: picks two random cut points and fills
> everything in between with random values/X bytes.
I don't think this table is complete without competing numbers for
truncated crc-32. Any chance to get that?
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 08:17:39 |
| Message-ID: | CA+U5nML47A3uBV-SFeenXK1anKj-XYe3wWAq2sasQoHr9v89WQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17 April 2013 22:36, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
>> > I would like to know the answer of how an upgrade from checksum to
>> > no-checksum would behave so I can modify pg_upgrade to allow it.
>>
>> Why? 9.3 pg_upgrade certainly doesn't need it. When we get to 9.4, if
>> someone has checksums enabled and wants to disable it, why is pg_upgrade
>> the right time to do that? Wouldn't it make more sense to allow them to
>> do that at any time?
>
> Well, right now, pg_upgrade is the only way you could potentially turn
> off checksums. You are right that we might eventually want a command,
> but my point is that we currently have a limitation in pg_upgrade that
> might not be necessary.
We don't currently have checksums, so pg_upgrade doesn't need to cope
with turning them off in 9.3
For 9.4, it might, but likely we've have a tool to turn them off
before then anyway.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 10:43:43 |
| Message-ID: | CAAZKuFZFGJn_j_RsHw6-dnqrW5y8JYDD4kM1YkKsRVym36ELOA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 11:08 PM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> On 2013-04-17 18:16:36 -0700, Daniel Farina wrote:
>> The original paper is often shorthanded "Castagnoli 93", but it exists
>> in the IEEE's sphere of influence and is hard to find a copy of.
>> Luckily, a pretty interesting survey paper discussing some of the
>> issues was written by Koopman in 2002 and is available:
>> http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.11.8323 As a
>> pedagolgical note, it's pretty interesting and accessible piece of
>> writing (for me, as someone who knows little of error
>> detection/correction) and explains some of the engineering reasons
>> that provoke such exercises.
>
> http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=231911&userType=inst
>
> There's also a koopman paper from 2004 thats interesting.
Having read the 2002 paper more, it seems that the current CRC32
doesn't have a whole lot going for it: CRC32C pretty much cleans its
clock across the board (I don't understand detected Hamming Distance
that seem greater than the information content of the message, e.g. HD
14 with 8 bit messages as seen in CRC32C: that's where CRC32 can "win").
CRC32C looks, all in all, the most flexible, because detection of
Hamming Distance 4 spans from 5244-131072 bits (the upper range of
which is a full 16KiB!) and there is superior Hamming Distance
detection on shorter messages up until the point where it seems like
the Hamming Distance able to be detected is larger than the message
size itself (e.g. HM 13 on an 8 bit message). I'm not sure if this is
an error in my understanding, or what.
Also, larger runs (16KB) are better served by CRC32C: even the
probably-best contender I can see (0xD419CC15) drops to Hamming
Distance 2-detection right after 65505 bits. CRC32C has the biggest
range at HD4, although Koopman 0xBA0DC66 comes close, gaining superior
Hamming distance detection for 178-16360 bits (the upper end of this
rnage is short of 2KiB by 3 bytes).
All in all, there is no reason I can see to keep CRC32 at all, vs
CRC32C on the basis of error detection alone, so putting aside all the
business about instruction set architecture, I think a software CRC32C
in a vacuum can be seen as a robustness improvement.
There may be polynomials that are not CRC32 or CRC32C that one might
view as having slightly better tradeoffs as seen in Table 1 of Koopman
2002, but it's kind of a stretch: being able to handle 8KB and 16KB as
seen in CRC32C at HD4 as seen in CRC32C is awfully compelling to me.
Koopman 0xBA0DC66B can admirably reach HD6 on a much larger range, up
to 16360 bytes, which is every so shy of 2KiB. Castagnoli 0xD419CC15
can, short of 8KB by 31 bits can detect HD 5.
Corrections welcome on my interpretations of Tbl 1.
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 14:02:50 |
| Message-ID: | CA+CSw_sR8Wwf9S7fu7h60GUE8uK8i_9o5iomkwdCY1sq=sdicQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 5:08 AM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 4/17/13 8:56 PM, Ants Aasma wrote:
>>
>> Nothing from the two points, but the CRC calculation algorithm can be
>> switched out for slice-by-4 or slice-by-8 variant. Speed up was around
>> factor of 4 if I remember correctly...I can provide you
>
>> with a patch of the generic version of any of the discussed algorithms
>> within an hour, leaving plenty of time in beta or in 9.4 to
>> accommodate the optimized versions.
>
> Can you nail down a solid, potential for commit slice-by-4 or slice-by-8
> patch then? You dropped into things like per-byte overhead to reach this
> conclusion, which was fine to let the methods battle each other. Maybe I
> missed it, but I didn't remember seeing an obvious full patch for this
> implementation then come back up from that. With the schedule pressure this
> needs to return to more database-level tests. Your concerns about the
> committed feature being much slower then the original Fletcher one are
> troubling, and we might as well do that showdown again now with the best of
> the CRC implementations you've found.
I meant any of fast ones is easy to nail down. The sped up slice-by-8
is somewhat slightly trickier to clean up. Especially if anyone
expects it to accelerate WAL calculation, then it brings up a whole
bunch of design questions on how to handle alignment issues. For
performance testing what is attached should work fine, it would still
need some cleanup.
> It's fair that you're very concerned about (1), but I wouldn't give it 100%
> odds of happening either. The user demand that's motivated me to work on
> this will be happy with any of (1) through (3), and in two of them
> optimizing the 16 bit checksums now turns out to be premature.
Fair enough, although I'd like to point out the optimization is
premature in the sense that the effort might go to waste. The checksum
function is a self contained, easy to test and very low maintenance
piece of code - not the usual premature optimization risk.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| crc32c-sb8-checksum.v0.patch | application/octet-stream | 27.9 KB |
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 14:57:34 |
| Message-ID: | CA+CSw_vdR=h5Au1imBan1KREoyE6=jHva6fDwgG2rc3GW6Dfeg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 9:09 AM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> On 2013-04-18 00:44:02 +0300, Ants Aasma wrote:
>> I went ahead and coded up both the parallel FNV-1a and parallel FNV-1a
>> + srl1-xor variants and ran performance tests and detection rate tests
>> on both.
>>
>> Performance results:
>> Mul-add checksums: 12.9 bytes/s
>> FNV-1a checksums: 13.5 bytes/s
>> FNV-1a + srl-1: 7.4 bytes/s
>>
>> Detection rates:
>> False positive rates:
>> Add-mul FNV-1a FNV-1a + srl-1
>> Single bit flip: 1:inf 1:129590 1:64795
>> Double bit flip: 1:148 1:511 1:53083
>> Triple bit flip: 1:673 1:5060 1:61511
>> Quad bit flip: 1:1872 1:19349 1:68320
>> Write 0x00 byte: 1:774538137 1:118776 1:68952
>> Write 0xFF byte: 1:165399500 1:137489 1:68958
>> Partial write: 1:59949 1:71939 1:89923
>> Write garbage: 1:64866 1:64980 1:67732
>> Write run of 00: 1:57077 1:61140 1:59723
>> Write run of FF: 1:63085 1:59609 1:62977
>>
>> Test descriptions:
>> N bit flip: picks N random non-overlapping bits and flips their value.
>> Write X byte: overwrites a single byte with X.
>> Partial write: picks a random cut point, overwrites everything from
>> there to end with 0x00.
>> Write garbage/run of X: picks two random cut points and fills
>> everything in between with random values/X bytes.
>
> I don't think this table is complete without competing numbers for
> truncated crc-32. Any chance to get that?
I didn't have time to run the full test set, the CRC32 is so slow that
the test would take 7 hours so I ran it on 10% of the dataset. The
number shouldn't be off by much as that still gives about 3.6M probes
for each test.
CRC32C slice-by-8: 0.57 bytes/cycle
Single bit flip: 1:inf
Double bit flip: 1:33105
Triple bit flip: 1:inf
Quad bit flip: 1:31665
Write 0x00 byte: 1:181934
Write 0xFF byte: 1:230424
Partial write: 1:324
Write garbage: 1:75059
Write run of 0: 1:57951
Write run of FF: 1:65677
The behavior for bit flips is about what is expected. A bias towards
detecting odd number of bit flips is probably behind the better than
uniform detection rate of byte overwrites. The partial write is very
odd and might be some kind of bug, although I'm not sure yet what.
Will investigate.
I also did avalanche diagrams for the two FNV algorithms discussed.
Basically the methodology is that I generated pages with random data,
took their checksum and then tried flipping each bit on the page,
counting for each checksum bit how many times it was affected by the
input bit change. Ideally each input bit affects each output bit with
50% probability. The attached images are created for 1M random pages
(1 petabyte of data checksummed for anyone counting). Each 32x16 block
corresponds to how each 32bit word affects the 16 bits of the
checksum. Black is ideal 50% flip rate, blue is 5% bias (+-2.5%),
green is 33%, yellow is 75% and red is 100% bias (output is never
flipped or always flipped). High bias reduces error detection rate for
bit errors in the given bits.
This confirms the analytical result that high bits in plain FNV are
not well dispersed. The dispersal pattern of FNV-1a ^ srl-3 however
looks great. Only the last 128 bytes are not well mixed. I'd say that
if we introduce one more round of mixing the result would be about as
good as we can hope for.
I'll generate an avalanche diagram for CRC32C too, but it will take a
while even if I use a smaller dataset.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| avalanche-random-fnv.png | image/png | 335.7 KB |
| avalanche-random-fnv-srl.png | image/png | 272.9 KB |
{kind=link}
{kind=link}
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 15:01:47 |
| Message-ID: | 20130418150147.GU5343@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 09:17:39AM +0100, Simon Riggs wrote:
> On 17 April 2013 22:36, Bruce Momjian <bruce(at)momjian(dot)us> wrote:
>
> >> > I would like to know the answer of how an upgrade from checksum to
> >> > no-checksum would behave so I can modify pg_upgrade to allow it.
> >>
> >> Why? 9.3 pg_upgrade certainly doesn't need it. When we get to 9.4, if
> >> someone has checksums enabled and wants to disable it, why is pg_upgrade
> >> the right time to do that? Wouldn't it make more sense to allow them to
> >> do that at any time?
> >
> > Well, right now, pg_upgrade is the only way you could potentially turn
> > off checksums. You are right that we might eventually want a command,
> > but my point is that we currently have a limitation in pg_upgrade that
> > might not be necessary.
>
> We don't currently have checksums, so pg_upgrade doesn't need to cope
> with turning them off in 9.3
True, 9.2 doesn't have checksums, while 9.3 will. One point is that
pg_upgrade could actually be used to turn off checksums for 9.3 to 9.3
upgrades if no tablespaces are used.
> For 9.4, it might, but likely we've have a tool to turn them off
> before then anyway.
True. Would we want pg_upgrade to still enforce matching checksum
modes for old and new servers at that point? Eventually we will have to
decide that.
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Florian Pflug <fgp(at)phlo(dot)org>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 16:48:01 |
| Message-ID: | CA+CSw_vVGUCVpvKMniZcB6e6p=EWEBahfuBHEw0rmv3Rku=3Qg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 5:57 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> I'll generate an avalanche diagram for CRC32C too, but it will take a
> while even if I use a smaller dataset.
Well that was useless... In CRC flipping each bit in the input flips
preset pattern of bits in the output regardless of the actual data on
the page. Some stats for CRC32C - input bits affect 28344 different
bit combinations. Count of bits by number of duplicated bitpatterns:
[(1, 8868),
(2, 17722),
(3, 17775),
(4, 12048),
(5, 5725),
(6, 2268),
(7, 875),
(8, 184),
(9, 45),
(10, 10),
(16, 16)]
Count of bit positions by number of bit-positions affected:
[(0, 16),
(1, 25),
(3, 1185),
(5, 8487),
(7, 22970),
(9, 22913),
(11, 8790),
(13, 1119),
(15, 31)]
Map of number of bit position affected, with 8 being black and 0 or 16
being red attached.
I'm not sure if the issues with partial writes are somehow related to this.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 28.8 KB |
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 17:04:08 |
| Message-ID: | 1366304648.12032.22.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-04-17 at 20:21 -0400, Greg Smith wrote:
> -Original checksum feature used Fletcher checksums. Its main problems,
> to quote wikipedia, include that it "cannot distinguish between blocks
> of all 0 bits and blocks of all 1 bits".
That is fairly easy to fix by using a different modulus: 251 vs 255.
Regards,
Jeff Davis
| From: | Florian Weimer <fw(at)deneb(dot)enyo(dot)de> |
|---|---|
| To: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 17:04:41 |
| Message-ID: | 8738unrcra.fsf@mid.deneb.enyo.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
* Greg Smith:
> The TCP/IP checksum spec is at https://tools.ietf.org/html/rfc793 ;
> its error detection limitations are described at
> http://www.noahdavids.org/self_published/CRC_and_checksum.html ; and a
> good article about optimizing its code is at
> http://www.locklessinc.com/articles/tcp_checksum/ I'll take a longer
> look at whether it's an improvement on the Fletcher-16 used by the
> current patch.
The TCP checksum is too weak to be practical. Every now an then, I
see data transfers where the checksum is valid, but the content
contains bit flips. Anything that flips bits randomly at intervals
which are multiples of 16 bits is quite likely to pass through
checksum detection.
In practice, TCP relies on checksumming on the sub-IP layers.
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 17:05:41 |
| Message-ID: | D5C7221E-2913-43CD-8973-1CE21219259A@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr18, 2013, at 19:04 , Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Wed, 2013-04-17 at 20:21 -0400, Greg Smith wrote:
>> -Original checksum feature used Fletcher checksums. Its main problems,
>> to quote wikipedia, include that it "cannot distinguish between blocks
>> of all 0 bits and blocks of all 1 bits".
>
> That is fairly easy to fix by using a different modulus: 251 vs 255.
At the expense of a drastic performance hit though, no? Modulus operations
aren't exactly cheap.
best regards,
Florian Pflug
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 17:13:15 |
| Message-ID: | CA+CSw_tQZw2oZPQ5TUv8kVweKPuHhZaDYka-8KJg30y_Kr-Lbg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 8:05 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> On Apr18, 2013, at 19:04 , Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
>> On Wed, 2013-04-17 at 20:21 -0400, Greg Smith wrote:
>>> -Original checksum feature used Fletcher checksums. Its main problems,
>>> to quote wikipedia, include that it "cannot distinguish between blocks
>>> of all 0 bits and blocks of all 1 bits".
>>
>> That is fairly easy to fix by using a different modulus: 251 vs 255.
>
> At the expense of a drastic performance hit though, no? Modulus operations
> aren't exactly cheap.
The modulus can be done in the end. By using a modulus of 65521 the
resulting checksum is called Adler-32. [1] However the quality of
Fletcher-32/Adler-32 is strictly worse than even the first iteration
of multiply-add based checksums proposed.
[1] http://en.wikipedia.org/wiki/Adler-32
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 17:15:20 |
| Message-ID: | E7FF4EB0-BC20-4C7B-9A0F-7075B61C90DB@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr18, 2013, at 18:48 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
> On Thu, Apr 18, 2013 at 5:57 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> I'll generate an avalanche diagram for CRC32C too, but it will take a
>> while even if I use a smaller dataset.
>
> Well that was useless... In CRC flipping each bit in the input flips
> preset pattern of bits in the output regardless of the actual data on
> the page. Some stats for CRC32C - input bits affect 28344 different
> bit combinations. Count of bits by number of duplicated bitpatterns:
Yup, CRC is linear too. CRC is essentially long division for polynomials,
i.e. you interpret the N input bits as the coefficients of a (large)
polynomial of degree (N-1), and divide by the CRC polynomial. The remainder
is the checksum, and consists of B bits where B is the degree of the
CRC polynomial. (Polynomial here means polynomial over GF(2), i.e. over
a field with only two values 0 and 1)
I'm currently trying to see if one can easily explain the partial-write
behaviour from that. Having lots of zeros at the end end corresponds
to an input polynomial of the form
p(x) * x^l
where l is the number of zero bits. The CRC (q(x) is the CRC polynomial) is
p(x) * x^l mod q(x) = (p(x) mod q(x)) * (x^l mod q(x)) mod q(x)
That still doesn't explain it, though - the result *should* simply
be the checksum of p(x), scrambled a bit by the multiplication with
(x^l mod q(x)). But if q(x) is irreducible, that scrambling is invertible
(as multiplication module some irreducible element always is), and thus
shouldn't matter much.
So either the CRC32-C polynomial isn't irreducible, or there something
fishy going on. Could there be a bug in your CRC implementation? Maybe
a mixup between big and little endian, or something like that?
The third possibility is that I've overlooking something, of course ;-)
Will think more about this tomorrow if time permits
best regards,
Florian Pflug
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 17:24:32 |
| Message-ID: | CA+CSw_vKD+ttWet12KwFiQPo=jNd1yHt=W6tVqthL9TqhgLWBQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 8:15 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> So either the CRC32-C polynomial isn't irreducible, or there something
> fishy going on. Could there be a bug in your CRC implementation? Maybe
> a mixup between big and little endian, or something like that?
I'm suspecting an implementation bug myself. I already checked the
test harness and that was all sane, compiler hadn't taken any
unforgivable liberties there. I will crosscheck the output with other
implementations to verify that the checksum is implemented correctly.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Greg Smith <greg(at)2ndQuadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 17:40:00 |
| Message-ID: | 1366306800.12032.36.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 2013-04-18 at 19:05 +0200, Florian Pflug wrote:
> On Apr18, 2013, at 19:04 , Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> > On Wed, 2013-04-17 at 20:21 -0400, Greg Smith wrote:
> >> -Original checksum feature used Fletcher checksums. Its main problems,
> >> to quote wikipedia, include that it "cannot distinguish between blocks
> >> of all 0 bits and blocks of all 1 bits".
> >
> > That is fairly easy to fix by using a different modulus: 251 vs 255.
>
> At the expense of a drastic performance hit though, no? Modulus operations
> aren't exactly cheap.
Modulo is only necessary when there's a possibility of overflow, or at
the very end of the calculation. If we accumulate 32-bit integers into
64-bit sums, then it turns out that it can't overflow given the largest
input we support (32K page).
32K page = 8192 32-bit integers
1*(2^32-1) + 2*(2^32-1) + 3*(2^32-1) ... 8192*(2^32-1)
= (2^32-1) * (8192^2 - 8192)/2
= 144097595856261120 ( < 2^64-1 )
So, we only need to do the modulo at the end.
Regards,
Jeff Davis
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 18:02:49 |
| Message-ID: | CA+CSw_tfmXkGz_AE+f+3y99b06XZwZ-N1+4a3DFB389OoL-bsQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 8:24 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> On Thu, Apr 18, 2013 at 8:15 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>> So either the CRC32-C polynomial isn't irreducible, or there something
>> fishy going on. Could there be a bug in your CRC implementation? Maybe
>> a mixup between big and little endian, or something like that?
>
> I'm suspecting an implementation bug myself. I already checked the
> test harness and that was all sane, compiler hadn't taken any
> unforgivable liberties there. I will crosscheck the output with other
> implementations to verify that the checksum is implemented correctly.
Looks like the implementation is correct. I cross-referenced it
against a bitwise algorithm for crc32 with the castagnoli polynomial.
This also rules out any endianness issues as the bitwise variant
consumes input byte at a time.
What ever it is, it is something specific to PostgreSQL page layout.
If I use /dev/urandom as the source the issue disappears. So much for
CRC32 being proven good.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 18:11:28 |
| Message-ID: | 730D0717-66D8-4096-A60E-2D0055A34CCA@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 18.04.2013, at 20:02, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> On Thu, Apr 18, 2013 at 8:24 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> On Thu, Apr 18, 2013 at 8:15 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>>> So either the CRC32-C polynomial isn't irreducible, or there something
>>> fishy going on. Could there be a bug in your CRC implementation? Maybe
>>> a mixup between big and little endian, or something like that?
>>
>> I'm suspecting an implementation bug myself. I already checked the
>> test harness and that was all sane, compiler hadn't taken any
>> unforgivable liberties there. I will crosscheck the output with other
>> implementations to verify that the checksum is implemented correctly.
>
> Looks like the implementation is correct. I cross-referenced it
> against a bitwise algorithm for crc32 with the castagnoli polynomial.
> This also rules out any endianness issues as the bitwise variant
> consumes input byte at a time.
>
> What ever it is, it is something specific to PostgreSQL page layout.
> If I use /dev/urandom as the source the issue disappears. So much for
> CRC32 being proven good.
Weird. Is the code of your test harness available publicly, or could you post it? I'd like to look into this...
best regard,
Florian Pflug
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 18:50:25 |
| Message-ID: | CA+CSw_tH9d0WPz-JtUwa+zfOn-imtS_GgPxMC=VoHyPu9hFThA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 9:11 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> On 18.04.2013, at 20:02, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>> On Thu, Apr 18, 2013 at 8:24 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
>>> On Thu, Apr 18, 2013 at 8:15 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>>>> So either the CRC32-C polynomial isn't irreducible, or there something
>>>> fishy going on. Could there be a bug in your CRC implementation? Maybe
>>>> a mixup between big and little endian, or something like that?
>>>
>>> I'm suspecting an implementation bug myself. I already checked the
>>> test harness and that was all sane, compiler hadn't taken any
>>> unforgivable liberties there. I will crosscheck the output with other
>>> implementations to verify that the checksum is implemented correctly.
>>
>> Looks like the implementation is correct. I cross-referenced it
>> against a bitwise algorithm for crc32 with the castagnoli polynomial.
>> This also rules out any endianness issues as the bitwise variant
>> consumes input byte at a time.
>>
>> What ever it is, it is something specific to PostgreSQL page layout.
>> If I use /dev/urandom as the source the issue disappears. So much for
>> CRC32 being proven good.
>
> Weird. Is the code of your test harness available publicly, or could you post it? I'd like to look into this...
Mystery solved. It was a bug in the test harness. If a page was
partially zero the cut-point wasn't correctly excluded from the
all-zero suffix, when overwriting the zero suffix correctly gave a
checksum match it was counted as a false positive. It didn't pop up on
other algorithms because for other algorithms I used a lot more data
and so the partial page false positives were drowned out. With this
fixed all algorithms give reasonably good detection rates for partial
writes.
The (now correct) testsuite is attached. Compile check-detection.c,
others files are included from there. See defines above the main
function for parameters. Please excuse the code being a hodgepodge of
thrown together snippets. For test data I used all files from a fresh
pg-9.3 database loaded with the IMDB dataset, including vm and fsm
pages.
Sorry about the false alarm.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| checksums-fnv.c | text/x-csrc | 5.5 KB |
| 8x256_tables.c | text/x-csrc | 30.0 KB |
| checksums-crc32c.c | text/x-csrc | 1.7 KB |
| check-detection.c | text/x-csrc | 6.5 KB |
| From: | Greg Stark <stark(at)mit(dot)edu> |
|---|---|
| To: | Florian Weimer <fw(at)deneb(dot)enyo(dot)de> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Daniel Farina <daniel(at)heroku(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Jim Nasby <jim(at)nasby(dot)net> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-18 21:20:08 |
| Message-ID: | CAM-w4HPSivQU9Reyk4aH0YSroMU=fpQd0QjvJNkWfK_O0tWgdw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Apr 18, 2013 at 6:04 PM, Florian Weimer <fw(at)deneb(dot)enyo(dot)de> wrote:
> The TCP checksum is too weak to be practical. Every now an then, I
> see data transfers where the checksum is valid, but the content
> contains bit flips.
Well of course, it's only a 16-bit checksum. 64k packets isn't very
many so if you're not counting checksum failures it won't take very
long before one gets through. The purpose of the checksum is to notify
you that you have a problem, not to block bad packets from getting
through.
> Anything that flips bits randomly at intervals
> which are multiples of 16 bits is quite likely to pass through
> checksum detection.
I'm not sure about this
--
greg
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 15:27:25 |
| Message-ID: | CA+TgmoYCHBtTLrb8rXi4i3FVFNXGjma3m4coDA+1WtcGwqvwhQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Apr 17, 2013 at 8:21 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
>> The more I read of this thread, the more unhappy I get. It appears that
>> the entire design process is being driven by micro-optimization for CPUs
>> being built by Intel in 2013.
>
> And that's not going to get anyone past review, since all the tests I've
> been doing the last two weeks are on how fast an AMD Opteron 6234 with OS
> cache >> shared_buffers can run this. The main thing I'm still worried
> about is what happens when you have a fast machine that can move memory
> around very quickly and an in-memory workload, but it's hamstrung by the
> checksum computation--and it's not a 2013 Intel machine.
This is a good point. However, I don't completely agree with the
conclusion that we shouldn't be worrying about any of this right now.
While I agree with Tom that it's far too late to think about any
CPU-specific optimizations for 9.3, I have a lot of concern, based on
Ants's numbers, that we've picked a checksum algorithm which is hard
to optimize for performance. If we don't get that fixed for 9.3,
we're potentially looking at inflicting many years of serious
suffering on our user base. If we at least get the *algorithm* right
now, we can worry about optimizing it later. If we get it wrong,
we'll be living with the consequence of that for a really long time.
I wish that we had not scheduled beta quite so soon, as I am sure
there will be even more resistance to changing this after beta. But
I'm having a hard time escaping the conclusion that we're on the edge
of shipping something we will later regret quite deeply. Maybe I'm
wrong?
...Robert
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 15:33:03 |
| Message-ID: | 20130422153303.GH4052@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-04-22 11:27:25 -0400, Robert Haas wrote:
> On Wed, Apr 17, 2013 at 8:21 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> >> The more I read of this thread, the more unhappy I get. It appears that
> >> the entire design process is being driven by micro-optimization for CPUs
> >> being built by Intel in 2013.
> >
> > And that's not going to get anyone past review, since all the tests I've
> > been doing the last two weeks are on how fast an AMD Opteron 6234 with OS
> > cache >> shared_buffers can run this. The main thing I'm still worried
> > about is what happens when you have a fast machine that can move memory
> > around very quickly and an in-memory workload, but it's hamstrung by the
> > checksum computation--and it's not a 2013 Intel machine.
>
> This is a good point. However, I don't completely agree with the
> conclusion that we shouldn't be worrying about any of this right now.
> While I agree with Tom that it's far too late to think about any
> CPU-specific optimizations for 9.3, I have a lot of concern, based on
> Ants's numbers, that we've picked a checksum algorithm which is hard
> to optimize for performance. If we don't get that fixed for 9.3,
> we're potentially looking at inflicting many years of serious
> suffering on our user base. If we at least get the *algorithm* right
> now, we can worry about optimizing it later. If we get it wrong,
> we'll be living with the consequence of that for a really long time.
>
> I wish that we had not scheduled beta quite so soon, as I am sure
> there will be even more resistance to changing this after beta. But
> I'm having a hard time escaping the conclusion that we're on the edge
> of shipping something we will later regret quite deeply. Maybe I'm
> wrong?
I don't see us changing away from CRCs anymore either by now. But I
think at least changing the polynom to something that
a) has higher error detection properties
b) can noticeably sped up on a a good part of the hardware pg is run on
If we are feeling really adventurous we can switch to a faster CRC
implementation, there are enough ones around and I know that at least my
proposed patch from some years ago (which is by far not the fastest that
is doable) is in production usage some places.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 16:25:14 |
| Message-ID: | CA+CSw_vTfKNT+6zVM8-ukWXefk32-yPx0UvorQS3dMVsQ_GmBw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Apr 22, 2013 at 6:27 PM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> On Wed, Apr 17, 2013 at 8:21 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
>>> The more I read of this thread, the more unhappy I get. It appears that
>>> the entire design process is being driven by micro-optimization for CPUs
>>> being built by Intel in 2013.
>>
>> And that's not going to get anyone past review, since all the tests I've
>> been doing the last two weeks are on how fast an AMD Opteron 6234 with OS
>> cache >> shared_buffers can run this. The main thing I'm still worried
>> about is what happens when you have a fast machine that can move memory
>> around very quickly and an in-memory workload, but it's hamstrung by the
>> checksum computation--and it's not a 2013 Intel machine.
>
> This is a good point. However, I don't completely agree with the
> conclusion that we shouldn't be worrying about any of this right now.
> While I agree with Tom that it's far too late to think about any
> CPU-specific optimizations for 9.3, I have a lot of concern, based on
> Ants's numbers, that we've picked a checksum algorithm which is hard
> to optimize for performance. If we don't get that fixed for 9.3,
> we're potentially looking at inflicting many years of serious
> suffering on our user base. If we at least get the *algorithm* right
> now, we can worry about optimizing it later. If we get it wrong,
> we'll be living with the consequence of that for a really long time.
I was just now writing up a generic C based patch based on the
parallel FNV-1a + shift that we discussed with Florian with an added
round of mixing. Testing the performance in isolation indicates that:
1) it is about an order of magnitude faster than the Sarwate CRC
method used in Postgresql.
2) it is about 2x faster than fastest software based CRC method.
3) by using -msse4.1 -funroll-loops -ftree-vectorize compilation
options the performance improves 5x. (within 20% of handcoded ASM)
This leaves lingering doubts about the quality of the checksum. It's
hard if not impossible to prove absence of interesting patterns that
would trigger collisions. I do know the checksum quality is miles
ahead of the Fletcher sum originally proposed and during the last week
I haven't been able to think of a way to make the collision rate
significantly differ from CRC.
> I wish that we had not scheduled beta quite so soon, as I am sure
> there will be even more resistance to changing this after beta. But
> I'm having a hard time escaping the conclusion that we're on the edge
> of shipping something we will later regret quite deeply. Maybe I'm
> wrong?
Its unfortunate that this got delayed by so long. The performance side
of the argument was clear a month ago.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Florian Pflug <fgp(at)phlo(dot)org>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 16:36:36 |
| Message-ID: | CA+CSw_uTJZPtzY3+LoyzMtOucLZVfEvSQRY2ci8O5aN9PygO7g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Apr 22, 2013 at 6:33 PM, Andres Freund <andres(at)2ndquadrant(dot)com> wrote:
> I don't see us changing away from CRCs anymore either by now. But I
> think at least changing the polynom to something that
> a) has higher error detection properties
> b) can noticeably sped up on a a good part of the hardware pg is run on
+1 of changing the polynomial if we stick with CRC, but I think the
differences in error detection capability are mostly academic for
PostgreSQL usecase. Or does anyone have an experience with seeing
multiple random bit errors per page.
> If we are feeling really adventurous we can switch to a faster CRC
> implementation, there are enough ones around and I know that at least my
> proposed patch from some years ago (which is by far not the fastest that
> is doable) is in production usage some places.
The faster CRC implementation just use parallel lookup tables of more
bytes in parallel. Performance results from [1] show that doing 4
bytes in parallel will yield a 2.8x speedup, and 8 bytes in parallel
yields another 1.7x on top of that at the cost of using a 8kB lookup
table. And the end result is still over 3x slower than the code in the
original patch, where Greg's performance results prompted me to look
at what would have a lower overhead.
[1] http://create.stephan-brumme.com/crc32/
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 18:00:43 |
| Message-ID: | 51757ACB.9040807@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04/22/2013 09:25 AM, Ants Aasma wrote:
> This leaves lingering doubts about the quality of the checksum. It's
> hard if not impossible to prove absence of interesting patterns that
> would trigger collisions. I do know the checksum quality is miles
> ahead of the Fletcher sum originally proposed and during the last week
> I haven't been able to think of a way to make the collision rate
> significantly differ from CRC.
When we originally discussed this feature, we were potentially
discussing a checksum algo which produced collisions for 1 out of 256
pages. That approach was considered acceptable, since it would be very
unlikely for such a collision to occur across multiple corrupted pages,
and fairly rare to have only one corrupted page.
So my perspective is, if we're doing better than 1 in 256, it's good enough.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 18:04:47 |
| Message-ID: | 05FD045A-D6C1-43FE-BD20-30A3B4930B0E@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr22, 2013, at 18:25 , Ants Aasma <ants(at)cybertec(dot)at> wrote:
> I was just now writing up a generic C based patch based on the
> parallel FNV-1a + shift that we discussed with Florian with an added
> round of mixing. Testing the performance in isolation indicates that:
> 1) it is about an order of magnitude faster than the Sarwate CRC
> method used in Postgresql.
> 2) it is about 2x faster than fastest software based CRC method.
> 3) by using -msse4.1 -funroll-loops -ftree-vectorize compilation
> options the performance improves 5x. (within 20% of handcoded ASM)
>
> This leaves lingering doubts about the quality of the checksum. It's
> hard if not impossible to prove absence of interesting patterns that
> would trigger collisions. I do know the checksum quality is miles
> ahead of the Fletcher sum originally proposed and during the last week
> I haven't been able to think of a way to make the collision rate
> significantly differ from CRC.
Note though that CRCs may very well have similar "interesting"
corruption patterns which don't cause the checksum to change, though.
The only guarantee they really give is that those patterns will involve
more than N-1 flipped bits, where N is the hamming distance of the
CRC. For 16-bit checksums, N can at most be 16 (since XOR-ing the data
with a shifted version of the CRC polynomial will not cause the checksum
to change).
Thus, once more than two bytes on a page get corrupted, CRCs may not
have any advantage over fnv1+shift or similar approaches. They may even
work worse, since detecting some forms of corruption with 100% certainty
means missing others with a probability of more than 2^-16. Some CRC
polynomials for example detect all corruptions which affect an odd number
of bits, but in turn have a probability of 2^-15 of missing ones which
affect an even number of bits.
Since we're mostly attempting to protect against disk, not memory
corruption here, I'm not convinced at all that errors in only a few
bits are all that common, and certainly not that they are more likely
than other forms of corruption. I'd expect, for example, that blocks of
512 bytes (i.e. one sector) suddenly reading 0 is at least as likely
as a single flipped bit.
The one downside of the fnv1+shift approach is that it's built around
the assumption that processing 64-bytes at once is the sweet spot. That
might be true for x86 and x86_64 today, but it won't stay that way for
long, and quite surely isn't true for other architectures. That doesn't
necessarily rule it out, but it certainly weakens the argument that
slipping it into 9.3 avoids having the change the algorithm later...
best regards,
Florian Pflug
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Jeff Davis <pgsql(at)j-davis(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 19:08:56 |
| Message-ID: | CA+CSw_sXy=ruvHRO6bENVYBkm=5mSHk5RW9bOKL9RdQPR3usEg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Apr 22, 2013 at 9:04 PM, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> The one downside of the fnv1+shift approach is that it's built around
> the assumption that processing 64-bytes at once is the sweet spot. That
> might be true for x86 and x86_64 today, but it won't stay that way for
> long, and quite surely isn't true for other architectures. That doesn't
> necessarily rule it out, but it certainly weakens the argument that
> slipping it into 9.3 avoids having the change the algorithm later...
It's actually 128 bytes as it was tested. The ideal shape depends on
multiplication latency, multiplication throughput and amount of
registers available. Specifically BLCKSZ/mul_throughput_in_bytes needs
to be larger than BLCKSZ/(N_SUMS*sizeof(uint32))*(mul latency + 2*xor
latency). For latest Intel the values are 8192/16 = 512 and
8192/(32*4)*(5 + 2*1) = 448. 128 bytes is also 8 registers which is
the highest power of two fitting into architectural registers (16).
This means that the value chosen is indeed the sweet spot for x86
today. For future processors we can expect the multiplication width to
increase and possibly the latency too shifting the sweet spot into
higher widths. In fact, Haswell coming out later this year should have
AVX2 instructions that introduce integer ops on 256bit registers,
making the current choice already suboptimal.
All that said, having a lower width won't make the algorithm slower on
future processors, it will just leave some parallelism on the table
that could be used to make it even faster. The line in the sand needed
to be drawn somewhere, I chose the maximum comfortable width today
fearing that even that would be shot down based on code size.
Coincidentally 32 elements is also the internal parallelism that GPUs
have settled on. We could bump the width up by one notch to buy some
future safety, but after that I'm skeptical we will see any
conventional processors that would benefit from a higher width. I just
tested that the auto-vectorized version runs at basically identical
speed as GCC's inability to do good register allocation means that it
juggles values between registers and the stack one way or the other.
So to recap, I don't know of any CPUs where a lower value would be
better. Raising the width by one notch would mean better performance
on future processors, but raising it further would just bloat the size
of the inner loop without much benefit in sight.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 19:14:04 |
| Message-ID: | 1366658044.2646.35.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-04-22 at 20:04 +0200, Florian Pflug wrote:
> The one downside of the fnv1+shift approach is that it's built around
> the assumption that processing 64-bytes at once is the sweet spot. That
> might be true for x86 and x86_64 today, but it won't stay that way for
> long, and quite surely isn't true for other architectures. That doesn't
> necessarily rule it out, but it certainly weakens the argument that
> slipping it into 9.3 avoids having the change the algorithm later...
I think you are setting the bar way too high. Right now, we have a slow
algorithm. According to Ants's tests, FNV-1a is much, much faster. Do
you think that it will still be such a bottleneck that we will want to
change it again later for purely performance reasons?
The only time this is likely to matter is in the situation Greg Smith
describes, where shared buffers is much smaller than memory, and the
working set of buffers is near the size of memory (in other words, a lot
of buffers moving to and from shared memory, but not much to or from
disk). And it's already significantly faster than algorithm in the
original tests (Fletcher), so it's not clear that it's still even a
serious problem.
(Also remember that checksum users already accept a WAL penalty.)
The biggest problem now is getting one of these faster algorithms (FNV
or even a faster CRC) into shape that is acceptable to
reviewers/committers. If we don't do that, we will be missing out on a
lot of potential checksum users for whom the existing CRC algorithm is
just too slow.
Regards,
Jeff Davis
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Ants Aasma <ants(at)cybertec(dot)at>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 19:15:36 |
| Message-ID: | CA+Tgmoa15iKaBrr5mF1DRArsDcso7x8+3Az3nd4OODJF5qghBg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Apr 22, 2013 at 3:14 PM, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> The biggest problem now is getting one of these faster algorithms (FNV
> or even a faster CRC) into shape that is acceptable to
> reviewers/committers. If we don't do that, we will be missing out on a
> lot of potential checksum users for whom the existing CRC algorithm is
> just too slow.
+1.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Florian Pflug <fgp(at)phlo(dot)org>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 19:22:21 |
| Message-ID: | 1366658541.2646.50.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, 2013-04-22 at 19:25 +0300, Ants Aasma wrote:
> I was just now writing up a generic C based patch based on the
> parallel FNV-1a + shift that we discussed with Florian with an added
> round of mixing. Testing the performance in isolation indicates that:
> 1) it is about an order of magnitude faster than the Sarwate CRC
> method used in Postgresql.
> 2) it is about 2x faster than fastest software based CRC method.
> 3) by using -msse4.1 -funroll-loops -ftree-vectorize compilation
> options the performance improves 5x. (within 20% of handcoded ASM)
That's great news!
This means that we can have a simple C implementation in a separate
file, and pass a few build flags when compiling just that file (so it
doesn't affect other code). That should make reviewers/committers happy
(including me).
FWIW, that was my last real concern about FNV (reviewability). I'm not
worried about the performance based on your analysis; nor am I worried
about the error detection rate.
Regards,
Jeff Davis
| From: | Florian Pflug <fgp(at)phlo(dot)org> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 19:32:23 |
| Message-ID: | F5836927-696C-40D3-A7DF-23D3B8180971@phlo.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Apr22, 2013, at 21:14 , Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Mon, 2013-04-22 at 20:04 +0200, Florian Pflug wrote:
>> The one downside of the fnv1+shift approach is that it's built around
>> the assumption that processing 64-bytes at once is the sweet spot. That
>> might be true for x86 and x86_64 today, but it won't stay that way for
>> long, and quite surely isn't true for other architectures. That doesn't
>> necessarily rule it out, but it certainly weakens the argument that
>> slipping it into 9.3 avoids having the change the algorithm later...
>
> I think you are setting the bar way too high. Right now, we have a slow
> algorithm. According to Ants's tests, FNV-1a is much, much faster. Do
> you think that it will still be such a bottleneck that we will want to
> change it again later for purely performance reasons?
To clarify, it wasn't my intent to argue against shipping FNV1+SHIFT
in 9.3 - in fact I'd like to see us do exactly that. I was merely trying
to be unbiased, and hence stated not only arguments in favour or FNV1+SHIFT
(the ones about CRCs theoretical advantages in error detection being
not really relevant to us), but also the one downside of FNV1+SHIFT.
Seems like I could have done a better job expressing myself though.
> The biggest problem now is getting one of these faster algorithms (FNV
> or even a faster CRC) into shape that is acceptable to
> reviewers/committers. If we don't do that, we will be missing out on a
> lot of potential checksum users for whom the existing CRC algorithm is
> just too slow.
Assuming that we only ship a plain C implementation with 9.3, what
are we missing on that front? The C implementation of FNV1+SHIFT is
only a few dozen lines or so.
best regards,
Florian Pflug
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Florian Pflug <fgp(at)phlo(dot)org> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 19:54:40 |
| Message-ID: | CA+U5nMKL6kJYCQ75i+vMnM0+X0Zf3DZ4EHYVVjwRrXiUJdjFYQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 22 April 2013 20:32, Florian Pflug <fgp(at)phlo(dot)org> wrote:
> Assuming that we only ship a plain C implementation with 9.3, what
> are we missing on that front? The C implementation of FNV1+SHIFT is
> only a few dozen lines or so.
Forgive me, I can't seem to locate the patch for this? Re-post please,
just for clarity.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Jeff Davis <pgsql(at)j-davis(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 19:57:31 |
| Message-ID: | CA+CSw_vsxb0FsA-f=4PS_-eygv_TZeQsFSXXsxbPChL8dBRrxw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Apr 22, 2013 at 10:54 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> On 22 April 2013 20:32, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>
>> Assuming that we only ship a plain C implementation with 9.3, what
>> are we missing on that front? The C implementation of FNV1+SHIFT is
>> only a few dozen lines or so.
>
> Forgive me, I can't seem to locate the patch for this? Re-post please,
> just for clarity.
Not posted yet. I'm writing it as we speak. Will post within half an hour or so.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Florian Pflug <fgp(at)phlo(dot)org>, Jeff Davis <pgsql(at)j-davis(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-22 22:08:07 |
| Message-ID: | CA+CSw_vinyf-w45i=M1m__MpJZY=e8S4Nt_KNnpEbtWjTOaSUA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Apr 22, 2013 at 10:57 PM, Ants Aasma <ants(at)cybertec(dot)at> wrote:
> On Mon, Apr 22, 2013 at 10:54 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>> On 22 April 2013 20:32, Florian Pflug <fgp(at)phlo(dot)org> wrote:
>>
>>> Assuming that we only ship a plain C implementation with 9.3, what
>>> are we missing on that front? The C implementation of FNV1+SHIFT is
>>> only a few dozen lines or so.
>>
>> Forgive me, I can't seem to locate the patch for this? Re-post please,
>> just for clarity.
>
> Not posted yet. I'm writing it as we speak. Will post within half an hour or so.
A slight delay, but here it is. I didn't lift the checksum part into a
separate file as I didn't have a great idea what I would call it. The
code is reasonably compact so I don't see a great need for this right
now. It would be more worth the effort when/if we add non-generic
variants. I'm not particularly attached to the method I used to mask
out pd_checksum field, this could be improved if someone has a better
idea how to structure the code.
I confirmed with objdump that compiling on GCC 4.7 with -msse4.1
-funroll-loops -ftree-vectorize does in fact vectorize that loop.
Simple way to verify: objdump -d src/backend/storage/page/bufpage.o |
grep pmulld | wc -l should output 16.
Unfortunately I can't work on this patch for about a week. Postgresql
9.3 will have to wait for me as I need to tend to the release of Ants
v2.0.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| Attachment | Content-Type | Size |
|---|---|---|
| parallel-fnv-checksum.patch | application/octet-stream | 6.9 KB |
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-23 01:35:38 |
| Message-ID: | 1366680938.2646.244.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2013-04-23 at 01:08 +0300, Ants Aasma wrote:
> A slight delay, but here it is. I didn't lift the checksum part into a
> separate file as I didn't have a great idea what I would call it. The
> code is reasonably compact so I don't see a great need for this right
> now. It would be more worth the effort when/if we add non-generic
> variants. I'm not particularly attached to the method I used to mask
> out pd_checksum field, this could be improved if someone has a better
> idea how to structure the code.
Thank you. A few initial comments:
I have attached (for illustration purposes only) a patch on top of yours
that divides the responsibilities a little more cleanly.
* easier to move into a separate file, and use your recommended compiler
flags without affecting other routines in bufpage.c
* makes the checksum algorithm itself simpler
* leaves the data-page-specific aspects (mixing in the page number,
ignoring pd_checksum, reducing to 16 bits) to PageCalcChecksum16
* overall easier to review and understand
I'm not sure what we should call the separate file or where we should
put it, though. How about src/backend/utils/checksum/checksum_fnv.c? Is
there a clean way to override the compiler flags for a single file so we
don't need to put it in its own directory?
Regards,
Jeff Davis
| Attachment | Content-Type | Size |
|---|---|---|
| fnv-jeff.patch | text/x-patch | 3.5 KB |
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-23 04:33:07 |
| Message-ID: | 20130423043307.GI2169@eldon.alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Davis escribió:
> I'm not sure what we should call the separate file or where we should
> put it, though. How about src/backend/utils/checksum/checksum_fnv.c? Is
> there a clean way to override the compiler flags for a single file so we
> don't need to put it in its own directory?
Sure, see src/backend/parser/Makefile about gram.o.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-23 15:28:33 |
| Message-ID: | CA+U5nMKVEu8UDXQe+Nk=d7Nqm4ypFSzaEf0esaK4j31LyQCOBQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 23 April 2013 02:35, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Tue, 2013-04-23 at 01:08 +0300, Ants Aasma wrote:
>> A slight delay, but here it is. I didn't lift the checksum part into a
>> separate file as I didn't have a great idea what I would call it. The
>> code is reasonably compact so I don't see a great need for this right
>> now. It would be more worth the effort when/if we add non-generic
>> variants. I'm not particularly attached to the method I used to mask
>> out pd_checksum field, this could be improved if someone has a better
>> idea how to structure the code.
>
> Thank you. A few initial comments:
>
> I have attached (for illustration purposes only) a patch on top of yours
> that divides the responsibilities a little more cleanly.
>
> * easier to move into a separate file, and use your recommended compiler
> flags without affecting other routines in bufpage.c
> * makes the checksum algorithm itself simpler
> * leaves the data-page-specific aspects (mixing in the page number,
> ignoring pd_checksum, reducing to 16 bits) to PageCalcChecksum16
> * overall easier to review and understand
>
> I'm not sure what we should call the separate file or where we should
> put it, though. How about src/backend/utils/checksum/checksum_fnv.c? Is
> there a clean way to override the compiler flags for a single file so we
> don't need to put it in its own directory?
OK, I like that a lot better and it seems something I could commit.
I suggest the following additional changes...
* put the README stuff directly in the checksum.c file
* I think we need some external links that describe this algorithm
and we need comments that explain what we know about this in terms of
detection capability and why it was chosen against others
* We need some comments/analysis about whether the coding causes a
problem if vectorization is *not* available
* make the pg_control.data_checksums field into a version number, for
future flexibility...
patch attached
* rename the routine away from checksum_fnv so its simply a generic
checksum call - more modular.
That way all knowledge of the algorithm is in one file only. If we do
need to change the algorithm in the future we can more easily support
multiple versions.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| checksums_version.v1.patch | application/octet-stream | 4.8 KB |
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-24 00:10:44 |
| Message-ID: | 1366762244.2646.252.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, 2013-04-23 at 16:28 +0100, Simon Riggs wrote:
> * make the pg_control.data_checksums field into a version number, for
> future flexibility...
> patch attached
Commenting on this separately because it's a separate issue.
I'd prefer that it was some kind of a checksum ID code -- e.g. 0 for no
checksum, 1 for FNV-1a-SR3, etc. That would allow us to release 9.4 with
a new algorithm without forcing existing users to change.
initdb would have to take the code as an option, probably in string
form.
What do you think?
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-24 07:20:38 |
| Message-ID: | CA+U5nM+X7d7QSf8TQhB0aeYut+C4EQVEosfCj5VwzkTEE9g5+Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24 April 2013 01:10, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> On Tue, 2013-04-23 at 16:28 +0100, Simon Riggs wrote:
>> * make the pg_control.data_checksums field into a version number, for
>> future flexibility...
>> patch attached
>
> Commenting on this separately because it's a separate issue.
>
> I'd prefer that it was some kind of a checksum ID code -- e.g. 0 for no
> checksum, 1 for FNV-1a-SR3, etc. That would allow us to release 9.4 with
> a new algorithm without forcing existing users to change.
That's exactly what the patch does.
> initdb would have to take the code as an option, probably in string
> form.
When/if we have multiple options we can add that. The main thing was
to make sure the control file recorded things in a common way.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-24 20:06:57 |
| Message-ID: | 1366834017.12032.103.camel@jdavis |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-04-24 at 08:20 +0100, Simon Riggs wrote:
> On 24 April 2013 01:10, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> > I'd prefer that it was some kind of a checksum ID code -- e.g. 0 for no
> > checksum, 1 for FNV-1a-SR3, etc. That would allow us to release 9.4 with
> > a new algorithm without forcing existing users to change.
>
> That's exactly what the patch does.
The word "version" indicates an order to it though, like N+1 is always
preferable to N. This is user-facing (through pg_controldata output),
otherwise I wouldn't mind.
> > initdb would have to take the code as an option, probably in string
> > form.
>
> When/if we have multiple options we can add that. The main thing was
> to make sure the control file recorded things in a common way.
The main strange thing to me is that we're still using the
enabled/disabled for the output of pg_controldata as well as the
"version".
When we do have multiple options, it seems like we'd just have one field
output:
Data page checksums: none|crc32c|pg-fnv
What goal are you trying to accomplish with this patch? pg_control
doesn't need to be compatible between releases, so can't we just add
this later when we really do have multiple options?
Regards,
Jeff Davis
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Jeff Davis <pgsql(at)j-davis(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-24 20:09:12 |
| Message-ID: | CA+U5nMKk=fzyua2YcKN4fmrMgTYz-LG5V_yAemn+2asA324o8Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24 April 2013 21:06, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
> What goal are you trying to accomplish with this patch?
That we might need to patch the checksum version on a production release.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Davis <pgsql(at)j-davis(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)2ndquadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-25 02:59:32 |
| Message-ID: | 1366858772.2646.331.camel@sussancws0025 |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 2013-04-24 at 21:09 +0100, Simon Riggs wrote:
> On 24 April 2013 21:06, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
>
> > What goal are you trying to accomplish with this patch?
>
> That we might need to patch the checksum version on a production release.
Oh, I see.
I don't think we need two output fields from pg_controldata though. It's
a little redundant, and confused me when I was looking at the impact on
pg_upgrade. And it means nothing to the user until we actually have
multiple algorithms available, at which time we are better off with a
text representation.
Other than that, I think your patch is fine to accomplish the
aforementioned goal. Essentially, it just changes the bool to a uint32,
which I favor.
Regards,
Jeff Davis
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Ants Aasma <ants(at)cybertec(dot)at>, Florian Pflug <fgp(at)phlo(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Greg Smith <greg(at)2ndQuadrant(dot)com>, Andres Freund <andres(at)2ndQuadrant(dot)com>, Bruce Momjian <bruce(at)momjian(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Enabling Checksums |
| Date: | 2013-04-25 14:37:22 |
| Message-ID: | 23592.1366900642@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Simon Riggs <simon(at)2ndQuadrant(dot)com> writes:
> On 24 April 2013 21:06, Jeff Davis <pgsql(at)j-davis(dot)com> wrote:
>> What goal are you trying to accomplish with this patch?
> That we might need to patch the checksum version on a production release.
I don't actually buy that argument, certainly not as something that
could happen in 9.3.
I'm inclined to think we should forget about this until we have a
concrete use-case for it. As Jeff says, there is no need for pg_control
contents to be compatible across major releases, so there's no harm in
waiting if we have any doubts about how it ought to work.
regards, tom lane