Add min and max execute statement time in pg_stat_statement
| Lists: | pgsql-hackers |
|---|
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-18 08:02:59 |
| Message-ID: | 5260EB33.4050207@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I submit patch adding min and max execute statement time in pg_stat_statement in
next CF.
pg_stat_statement have execution time, but it is average execution time and does
not provide detail information very much. So I add min and max execute statement
time in pg_stat_statement columns. Usage is almost same as before. However, I add
pg_stat_statements_reset_time() function to get min_time and max_time in the
specific period. This function resets or inits min and max execution time before.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-min_max_exectime_v0.patch | text/x-diff | 12.3 KB |
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-18 13:21:13 |
| Message-ID: | 526135C9.8050708@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10/18/2013 04:02 AM, KONDO Mitsumasa wrote:
> I submit patch adding min and max execute statement time in pg_stat_statement in
> next CF.
>
> pg_stat_statement have execution time, but it is average execution time and does
> not provide detail information very much. So I add min and max execute statement
> time in pg_stat_statement columns. Usage is almost same as before. However, I add
> pg_stat_statements_reset_time() function to get min_time and max_time in the
> specific period. This function resets or inits min and max execution time before.
>
>
If we're going to extend pg_stat_statements, even more than min and max
I'd like to see the standard deviation in execution time.
cheers
andrew
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 11:17:53 |
| Message-ID: | 52650D61.1060901@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2013/10/18 22:21), Andrew Dunstan wrote:
> If we're going to extend pg_stat_statements, even more than min and max
> I'd like to see the standard deviation in execution time.
OK. I do! I am making some other patches, please wait more!
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center.;
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 19:52:16 |
| Message-ID: | 526585F0.6070705@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 22/10/13 00:17, KONDO Mitsumasa wrote:
> (2013/10/18 22:21), Andrew Dunstan wrote:
>> If we're going to extend pg_stat_statements, even more than min and max
>> I'd like to see the standard deviation in execution time.
> OK. I do! I am making some other patches, please wait more!
>
> Regards,
> --
> Mitsumasa KONDO
> NTT Open Source Software Center.;
>
>
How about the 'median', often a lot more useful than the 'arithmetic
mean' (which most people call the 'average').
Cheers,
Gavin
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 20:01:41 |
| Message-ID: | 4338.1382385701@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> writes:
>>> If we're going to extend pg_stat_statements, even more than min and max
>>> I'd like to see the standard deviation in execution time.
> How about the 'median', often a lot more useful than the 'arithmetic
> mean' (which most people call the 'average').
AFAIK, median is impossible to calculate cheaply (in particular, with
a fixed amount of workspace). So this apparently innocent request
is actually moving the goalposts a long way, because the space per
query table entry is a big concern for pg_stat_statements.
regards, tom lane
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 20:36:41 |
| Message-ID: | CA+TgmobgGHb_92adFnG7kBb44Ad-H7dAGeeUt2Ru=98Tb8g_bw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Oct 21, 2013 at 4:01 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> writes:
>>>> If we're going to extend pg_stat_statements, even more than min and max
>>>> I'd like to see the standard deviation in execution time.
>
>> How about the 'median', often a lot more useful than the 'arithmetic
>> mean' (which most people call the 'average').
>
> AFAIK, median is impossible to calculate cheaply (in particular, with
> a fixed amount of workspace). So this apparently innocent request
> is actually moving the goalposts a long way, because the space per
> query table entry is a big concern for pg_stat_statements.
Yeah, and I worry about min and max not being very usable - once they
get pushed out to extreme values, there's nothing to drag them back
toward normality except resetting the stats, and that's not something
we want to encourage people to do frequently. Of course, averages over
very long sampling intervals may not be too useful anyway, dunno.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 20:43:28 |
| Message-ID: | CAM3SWZQ=Eu4JBbqXR_rOdRL=c7DKvzD35q3v4=WKX109oBsV-w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Oct 21, 2013 at 1:36 PM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> Yeah, and I worry about min and max not being very usable - once they
> get pushed out to extreme values, there's nothing to drag them back
> toward normality except resetting the stats, and that's not something
> we want to encourage people to do frequently.
My thoughts exactly. Perhaps it'd be useful to separately invalidate
min/max times, without a full reset. But then you've introduced the
possibility of the average time (total_time/calls) exceeding the max
or being less than the min.
--
Peter Geoghegan
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 21:47:15 |
| Message-ID: | 5265A0E3.8030103@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 22/10/13 09:01, Tom Lane wrote:
> Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> writes:
>>>> If we're going to extend pg_stat_statements, even more than min and max
>>>> I'd like to see the standard deviation in execution time.
>> How about the 'median', often a lot more useful than the 'arithmetic
>> mean' (which most people call the 'average').
> AFAIK, median is impossible to calculate cheaply (in particular, with
> a fixed amount of workspace). So this apparently innocent request
> is actually moving the goalposts a long way, because the space per
> query table entry is a big concern for pg_stat_statements.
>
> regards, tom lane
Yeah, obvious - in retrospect! :-)
One way it could be done, but even this would consume far too much
storage and processing power (hence totally impractical), would be to
'simply' store a counter for each value found and increment it for each
occurence...
Cheers,
Gavin
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 22:09:26 |
| Message-ID: | 20131021220926.GC4987@eldon.alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Gavin Flower wrote:
> One way it could be done, but even this would consume far too much
> storage and processing power (hence totally impractical), would be
> to 'simply' store a counter for each value found and increment it
> for each occurence...
An histogram? Sounds like a huge lot of code complexity to me. Not
sure the gain is enough.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 22:48:52 |
| Message-ID: | 5265AF54.1000207@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10/21/2013 04:43 PM, Peter Geoghegan wrote:
> On Mon, Oct 21, 2013 at 1:36 PM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>> Yeah, and I worry about min and max not being very usable - once they
>> get pushed out to extreme values, there's nothing to drag them back
>> toward normality except resetting the stats, and that's not something
>> we want to encourage people to do frequently.
> My thoughts exactly. Perhaps it'd be useful to separately invalidate
> min/max times, without a full reset. But then you've introduced the
> possibility of the average time (total_time/calls) exceeding the max
> or being less than the min.
>
>
This is why I suggested the standard deviation, and why I find it would
be more useful than just min and max. A couple of outliers will set the
min and max to
possibly extreme values but hardly perturb the standard deviation over a
large number of observations.
cheers
andrew
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 23:09:52 |
| Message-ID: | 9084.1382396992@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> Yeah, and I worry about min and max not being very usable - once they
> get pushed out to extreme values, there's nothing to drag them back
> toward normality except resetting the stats, and that's not something
> we want to encourage people to do frequently. Of course, averages over
> very long sampling intervals may not be too useful anyway, dunno.
Good point, but that doesn't mean that the request is unreasonable.
For min/max, we could possibly address this concern by introducing an
exponential decay over time --- that is, every so often, you take some
small fraction of (max - min) and add that to the running min while
subtracting it from the max. Or some other variant on that theme. There
might be a way to progressively discount old observations for average too,
though I'm not sure exactly how at the moment.
regards, tom lane
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 23:29:24 |
| Message-ID: | 9571.1382398164@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
> This is why I suggested the standard deviation, and why I find it would
> be more useful than just min and max. A couple of outliers will set the
> min and max to possibly extreme values but hardly perturb the standard
> deviation over a large number of observations.
Hm. It's been a long time since college statistics, but doesn't the
entire concept of standard deviation depend on the assumption that the
underlying distribution is more-or-less normal (Gaussian)? Is there a
good reason to suppose that query runtime is Gaussian? (I'd bet not;
in particular, multimodal behavior seems very likely due to things like
plan changes.) If not, how much does that affect the usefulness of
a standard-deviation calculation?
regards, tom lane
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-21 23:44:41 |
| Message-ID: | 5265BC69.70403@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10/21/2013 07:29 PM, Tom Lane wrote:
> Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
>> This is why I suggested the standard deviation, and why I find it would
>> be more useful than just min and max. A couple of outliers will set the
>> min and max to possibly extreme values but hardly perturb the standard
>> deviation over a large number of observations.
> Hm. It's been a long time since college statistics, but doesn't the
> entire concept of standard deviation depend on the assumption that the
> underlying distribution is more-or-less normal (Gaussian)? Is there a
> good reason to suppose that query runtime is Gaussian? (I'd bet not;
> in particular, multimodal behavior seems very likely due to things like
> plan changes.) If not, how much does that affect the usefulness of
> a standard-deviation calculation?
IANA statistician, but the article at
<https://en.wikipedia.org/wiki/Standard_deviation> appears to have a
diagram with one sample that's multi-modal.
cheers
andrew
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 00:22:01 |
| Message-ID: | CAM3SWZTeeL+Rch9-UObftmJowu6rd8fO7B=zzqRbwsjxHPVi1A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Oct 21, 2013 at 4:29 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Hm. It's been a long time since college statistics, but doesn't the
> entire concept of standard deviation depend on the assumption that the
> underlying distribution is more-or-less normal (Gaussian)?
I don't see how. The standard deviation here would be expressed in
units of milliseconds. Now, that could be misleading, in that like a
mean average, it might "mischaracterize" the distribution. But it's
still got to be a big improvement.
I like the idea of a decay, but can't think of a principled scheme offhand.
--
Peter Geoghegan
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 00:26:29 |
| Message-ID: | CA+CSw_vL8ufYoPyeVTBCiKPybY_K5HStOrYu+Kp1XRDmHpKC8g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Oct 22, 2013 at 1:09 AM, Alvaro Herrera
<alvherre(at)2ndquadrant(dot)com> wrote:
> Gavin Flower wrote:
>
>> One way it could be done, but even this would consume far too much
>> storage and processing power (hence totally impractical), would be
>> to 'simply' store a counter for each value found and increment it
>> for each occurence...
>
> An histogram? Sounds like a huge lot of code complexity to me. Not
> sure the gain is enough.
I have a proof of concept patch somewhere that does exactly this. I
used logarithmic bin widths. With 8 log10 bins you can tell the
fraction of queries running at each order of magnitude from less than
1ms to more than 1000s. Or with 31 bins you can cover factor of 2
increments from 100us to over 27h. And the code is almost trivial,
just take a log of the duration and calculate the bin number from that
and increment the value in the corresponding bin.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 00:47:10 |
| Message-ID: | 5265CB0E.2070802@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 22/10/13 13:26, Ants Aasma wrote:
> On Tue, Oct 22, 2013 at 1:09 AM, Alvaro Herrera
> <alvherre(at)2ndquadrant(dot)com> wrote:
>> Gavin Flower wrote:
>>
>>> One way it could be done, but even this would consume far too much
>>> storage and processing power (hence totally impractical), would be
>>> to 'simply' store a counter for each value found and increment it
>>> for each occurence...
>> An histogram? Sounds like a huge lot of code complexity to me. Not
>> sure the gain is enough.
> I have a proof of concept patch somewhere that does exactly this. I
> used logarithmic bin widths. With 8 log10 bins you can tell the
> fraction of queries running at each order of magnitude from less than
> 1ms to more than 1000s. Or with 31 bins you can cover factor of 2
> increments from 100us to over 27h. And the code is almost trivial,
> just take a log of the duration and calculate the bin number from that
> and increment the value in the corresponding bin.
>
> Regards,
> Ants Aasma
That might be useful in determining if things are sufficiently bad to be
worth investigating in more detail. No point in tuning stuff that is
behaving acceptably.
Also good enough to say 95% execute within 5 seconds (or whatever).
Cheers,
Gavin
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 01:00:39 |
| Message-ID: | 5265CE37.4060102@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 22/10/13 13:26, Ants Aasma wrote:
> On Tue, Oct 22, 2013 at 1:09 AM, Alvaro Herrera
> <alvherre(at)2ndquadrant(dot)com> wrote:
>> Gavin Flower wrote:
>>
>>> One way it could be done, but even this would consume far too much
>>> storage and processing power (hence totally impractical), would be
>>> to 'simply' store a counter for each value found and increment it
>>> for each occurence...
>> An histogram? Sounds like a huge lot of code complexity to me. Not
>> sure the gain is enough.
> I have a proof of concept patch somewhere that does exactly this. I
> used logarithmic bin widths. With 8 log10 bins you can tell the
> fraction of queries running at each order of magnitude from less than
> 1ms to more than 1000s. Or with 31 bins you can cover factor of 2
> increments from 100us to over 27h. And the code is almost trivial,
> just take a log of the duration and calculate the bin number from that
> and increment the value in the corresponding bin.
>
> Regards,
> Ants Aasma
I suppose this has to be decided at compile time to keep the code both
simple and efficient - if so, I like the binary approach.
Curious, why start at 100us? I suppose this might be of interest if
everything of note is in RAM and/or stuff is on SSD's.
Cheers,
Gavin
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 01:23:06 |
| Message-ID: | CA+CSw_v3Jb0U_wPmxYsWjTkCWrp8szJAJ+5xJ=UXWOo0+=5Wiw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Oct 22, 2013 at 4:00 AM, Gavin Flower
<GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
>> I have a proof of concept patch somewhere that does exactly this. I
>> used logarithmic bin widths. With 8 log10 bins you can tell the
>> fraction of queries running at each order of magnitude from less than
>> 1ms to more than 1000s. Or with 31 bins you can cover factor of 2
>> increments from 100us to over 27h. And the code is almost trivial,
>> just take a log of the duration and calculate the bin number from that
>> and increment the value in the corresponding bin.
>
> I suppose this has to be decided at compile time to keep the code both
> simple and efficient - if so, I like the binary approach.
For efficiency's sake it can easily be done at run time, one extra
logarithm calculation per query will not be noticeable. Having a
proper user interface to make it configurable and changeable is where
the complexity is. We might just decide to go with something good
enough as even the 31 bin solution would bloat the pg_stat_statements
data structure only by about 10%.
> Curious, why start at 100us? I suppose this might be of interest if
> everything of note is in RAM and/or stuff is on SSD's.
Selecting a single row takes about 20us on my computer, I picked 100us
as a reasonable limit below where the exact speed doesn't matter
anymore.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Dimitri Fontaine <dimitri(at)2ndQuadrant(dot)fr> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 09:56:47 |
| Message-ID: | m2eh7dr5ls.fsf@2ndQuadrant.fr |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> writes:
> Hm. It's been a long time since college statistics, but doesn't the
> entire concept of standard deviation depend on the assumption that the
> underlying distribution is more-or-less normal (Gaussian)? Is there a
I just had a quick chat with a statistician friends of mine on that
topic, and it seems that the only way to make sense of an average is if
you know already the distribution.
In our case, what I keep experiencing with tuning queries is that we
have like 99% of them running under acceptable threshold and 1% of them
taking more and more time.
In a normal (Gaussian) distribution, there would be no query time
farther away from the average than any other, so my experience tells me
that the query time distribution is anything BUT normal (Gaussian).
> good reason to suppose that query runtime is Gaussian? (I'd bet not;
> in particular, multimodal behavior seems very likely due to things like
> plan changes.) If not, how much does that affect the usefulness of
> a standard-deviation calculation?
I don't know what multi-modal is.
What I've been gathering from my quick chat this morning is that either
you know how to characterize the distribution and then the min max and
average are useful on their own, or you need to keep track of an
histogram where all the bins are of the same size to be able to learn
what the distribution actually is.
We didn't get to the point where I could understand if storing histogram
with a constant size on log10 of the data rather than the data itself is
going to allow us to properly characterize the distribution.
The main question I want to answer here would be the percentiles one, I
want to get the query max execution timing for 95% of the executions,
then 99%, then 99.9% etc. There's no way to answer that without knowing
the distribution shape, so we need enough stats to learn what the
distribution shape is (hence, histograms).
Of course keeping enough stats seems to always begin with keeping the
min, max and average, so we can just begin there. We would just be
unable to answer interesting questions with just that.
Regards,
--
Dimitri Fontaine
http://2ndQuadrant.fr PostgreSQL : Expertise, Formation et Support
| From: | Daniel Farina <daniel(at)heroku(dot)com> |
|---|---|
| To: | Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 10:11:14 |
| Message-ID: | CAAZKuFbuaVyz1g6-VFgWMrrNH4ZqPm7+x_6U2KXHJdyQfvV4AQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Oct 22, 2013 at 2:56 AM, Dimitri Fontaine
<dimitri(at)2ndquadrant(dot)fr> wrote:
> Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> writes:
>> Hm. It's been a long time since college statistics, but doesn't the
>> entire concept of standard deviation depend on the assumption that the
>> underlying distribution is more-or-less normal (Gaussian)? Is there a
>
> I just had a quick chat with a statistician friends of mine on that
> topic, and it seems that the only way to make sense of an average is if
> you know already the distribution.
>
> In our case, what I keep experiencing with tuning queries is that we
> have like 99% of them running under acceptable threshold and 1% of them
> taking more and more time.
Agreed.
In a lot of Heroku's performance work, the Perc99 and Perc95 have
provided a lot more value that stddev, although stddev is a lot better
than nothing and probably easier to implement.
There are apparently high-quality statistical approximations of these
that are not expensive to compute and are small in memory representation.
That said, I'd take stddev over nothing for sure.
Handily for stddev, I think by snapshots of count(x), sum(x),
sum(x**2) (which I understand to be the components of stddev), I think
one can compute stddevs across different time spans using auxiliary
tools that sample this triplet on occasion. That's kind of a handy
property that I'm not sure if percN-approximates can get too easily.
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 11:03:23 |
| Message-ID: | 52665B7B.4090106@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 22/10/13 22:56, Dimitri Fontaine wrote:
> Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> writes:
>> Hm. It's been a long time since college statistics, but doesn't the
>> entire concept of standard deviation depend on the assumption that the
>> underlying distribution is more-or-less normal (Gaussian)? Is there a
> I just had a quick chat with a statistician friends of mine on that
> topic, and it seems that the only way to make sense of an average is if
> you know already the distribution.
>
> In our case, what I keep experiencing with tuning queries is that we
> have like 99% of them running under acceptable threshold and 1% of them
> taking more and more time.
>
> In a normal (Gaussian) distribution, there would be no query time
> farther away from the average than any other, so my experience tells me
> that the query time distribution is anything BUT normal (Gaussian).
>
>> good reason to suppose that query runtime is Gaussian? (I'd bet not;
>> in particular, multimodal behavior seems very likely due to things like
>> plan changes.) If not, how much does that affect the usefulness of
>> a standard-deviation calculation?
> I don't know what multi-modal is.
>
[...]
Multi-modal is basically having more than one hump when you graph the frequencies of values.
If you gave a series of mathematical questions of varying degrees of difficulty and divers areas in mathematics to a group of people between the ages of 20 & 25 selected at random in New Zealand, then you would have at least 2 humps. One hump would be those who had little mathematical training and/or no interest and those that had had more advanced mathematical training and/or were interested in mathematics.
You would also get at least 2 humps if you plotted numbers of people under the age of 50, with the number of visits to medical practioners. Basically those people with chronic illnesses with those who tend not to have extended periods of illness - this implies 2 humps, but it may be more complicated.
Grabbing people at random and getting them to fire a rifle at targets would also be multi modal. A lot of people with low scores and a lessor percentage with reasonable scores. I would expect this to be quite pronounced, people with lots of rifle practice will tend to do significantly better.
Cheers,
Gavin
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Dimitri Fontaine <dimitri(at)2ndQuadrant(dot)fr> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 13:26:43 |
| Message-ID: | 20131022132643.GX2706@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
All,
* Dimitri Fontaine (dimitri(at)2ndQuadrant(dot)fr) wrote:
> In our case, what I keep experiencing with tuning queries is that we
> have like 99% of them running under acceptable threshold and 1% of them
> taking more and more time.
This is usually described (at least where I come from) as 'rare events',
which goes to Tom's point that averages, stddev, etc, are not ideal
(though they are still better than nothing).
> > good reason to suppose that query runtime is Gaussian? (I'd bet not;
> > in particular, multimodal behavior seems very likely due to things like
> > plan changes.) If not, how much does that affect the usefulness of
> > a standard-deviation calculation?
Oscillating plan changes may fit multimodal but I don't feel that's
typical. My experience has been it's either an extremely rare plan
difference or it's a shift from one plan to another over time.
> What I've been gathering from my quick chat this morning is that either
> you know how to characterize the distribution and then the min max and
> average are useful on their own, or you need to keep track of an
> histogram where all the bins are of the same size to be able to learn
> what the distribution actually is.
A histogram would certainly be useful. We may also wish to look into
outlier/rare event detection methods and increase the logging we do in
those cases (if possible).
> Of course keeping enough stats seems to always begin with keeping the
> min, max and average, so we can just begin there. We would just be
> unable to answer interesting questions with just that.
It would probably be good to do some research into techniques for
outlier detection which minimizes CPU and storage cost.
Thanks,
Stephen
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 18:16:19 |
| Message-ID: | CAMkU=1xUnoddQHzQq9_b1UMWHbemVfRJX72f-0ezsv801ke6LQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Oct 21, 2013 at 4:29 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
> > This is why I suggested the standard deviation, and why I find it would
> > be more useful than just min and max. A couple of outliers will set the
> > min and max to possibly extreme values but hardly perturb the standard
> > deviation over a large number of observations.
>
> Hm. It's been a long time since college statistics, but doesn't the
> entire concept of standard deviation depend on the assumption that the
> underlying distribution is more-or-less normal (Gaussian)?
It is easy to misinterpret the standard deviation if the distribution is
not gaussian, but that is also true of the average. The standard deviation
(or the variance) is commonly used with non-gaussian distributions, either
because it is the most efficient estimator for those particular
distributions, or just because it is so commonly available.
Cheers,
Jeff
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Andrew Dunstan <andrew(at)dunslane(dot)net>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 18:33:08 |
| Message-ID: | CAMkU=1y3ZZSmLAhBZgPgxmTHa_sr7K6_eqEePt8ceNarcZv9Ow@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Oct 21, 2013 at 1:36 PM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> On Mon, Oct 21, 2013 at 4:01 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> > Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> writes:
> >>>> If we're going to extend pg_stat_statements, even more than min and
> max
> >>>> I'd like to see the standard deviation in execution time.
> >
> >> How about the 'median', often a lot more useful than the 'arithmetic
> >> mean' (which most people call the 'average').
> >
> > AFAIK, median is impossible to calculate cheaply (in particular, with
> > a fixed amount of workspace). So this apparently innocent request
> > is actually moving the goalposts a long way, because the space per
> > query table entry is a big concern for pg_stat_statements.
>
> Yeah, and I worry about min and max not being very usable - once they
> get pushed out to extreme values, there's nothing to drag them back
> toward normality except resetting the stats, and that's not something
> we want to encourage people to do frequently. Of course, averages over
> very long sampling intervals may not be too useful anyway, dunno.
>
I think the pg_stat_statements_reset() should be done every time you make a
change which you think (or hope) will push the system into a new regime,
which goes for either min/max or for average/stdev.
A histogram would be cool, but it doesn't seem very practical to implement.
If I really needed that I'd probably set log_min_duration_statement = 0
and mine the log files. But that means I'd have to wait to accumulate
enough logs once I made that change, then remember to turn it off.
What I'd like most in pg_stat_statements now is the ability to distinguish
which queries have a user grinding their teeth, versus which ones have a
cron job patiently doing a wait4. I don't know the best way to figure that
out, other than stratify on application_name. Or maybe a way to
selectively undo the query text normalization, so I could see which
parameters were causing the problem.
Cheers,
Jeff
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-22 19:13:26 |
| Message-ID: | 5266CE56.7030609@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
All,
Bringing this down to Earth: yes, it would be useful to have min and
max for pg_stat_statement, and even if we add more stats to
pg_stat_statement, it would be useful to have those two. So can we
approve this patch on that basis?
For my part, I generally use the 9-part percentiles for query analysis
(0,5,10,25,50,75,90,95,100). However, that's fairly expensive to
calculate, and would require a histogram or other approaches mentioned
earlier.
On 10/22/2013 11:16 AM, Jeff Janes wrote:
> It is easy to misinterpret the standard deviation if the distribution is
> not gaussian, but that is also true of the average. The standard deviation
> (or the variance) is commonly used with non-gaussian distributions, either
> because it is the most efficient estimator for those particular
> distributions, or just because it is so commonly available.
On the other hand, it's still true that a high STDDEV indicates a high
variance in the response times of a particular query, whereas a low one
indicates that most are close to the average. While precision math
might not work if we don't have the correct distribution, for gross DBA
checks it's still useful. That is, I can answer the question in many
cases of: "Does this query have a high average because of outliers, or
because it's consisently slow?" by looking at the STDDEV.
And FWIW, for sites where we monitor pg_stat_statements, we reset daily
or weekly. Otherwise, the stats have no meaning.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndQuadrant(dot)fr> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 02:19:07 |
| Message-ID: | 5267321B.9030909@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi All,
(2013/10/22 22:26), Stephen Frost wrote:
> * Dimitri Fontaine (dimitri(at)2ndQuadrant(dot)fr) wrote:
>> In our case, what I keep experiencing with tuning queries is that we
>> have like 99% of them running under acceptable threshold and 1% of them
>> taking more and more time.
>
> This is usually described (at least where I come from) as 'rare events',
> which goes to Tom's point that averages, stddev, etc, are not ideal
> (though they are still better than nothing).
>
>>> good reason to suppose that query runtime is Gaussian? (I'd bet not;
>>> in particular, multimodal behavior seems very likely due to things like
>>> plan changes.) If not, how much does that affect the usefulness of
>>> a standard-deviation calculation?
>
> Oscillating plan changes may fit multimodal but I don't feel that's
> typical. My experience has been it's either an extremely rare plan
> difference or it's a shift from one plan to another over time.
After all, all of avg, min, max and stdev are only numerical value for predicting
model. There aren't the robustness and strictness such as Write Ahead Logging. It
resembles a weather forecast. They are still better than nothing.
It is needed a human judgment to finally suppose a cause from the numerical
values. By the way, we can guess probability of the value from stdev.
Therefore we can guess easily even if there is an extreme value in min/max
whether it is normal or not.
>> What I've been gathering from my quick chat this morning is that either
>> you know how to characterize the distribution and then the min max and
>> average are useful on their own, or you need to keep track of an
>> histogram where all the bins are of the same size to be able to learn
>> what the distribution actually is.
>
> A histogram would certainly be useful. We may also wish to look into
> outlier/rare event detection methods and increase the logging we do in
> those cases (if possible).
>
>> Of course keeping enough stats seems to always begin with keeping the
>> min, max and average, so we can just begin there. We would just be
>> unable to answer interesting questions with just that.
>
> It would probably be good to do some research into techniques for
> outlier detection which minimizes CPU and storage cost.
pg_stat_statement is often used in operating database system, so I don't
like high CPU usage implementation. The software which will be lessor
performance just to install it is too unpleasant to accept. And if we
need more detail information for SQL tuning, it would be better to
develop other useful performance tuning and monitoring contrib not to
use in operating database system.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 16:20:38 |
| Message-ID: | 20131023162038.GN2706@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Josh,
* Josh Berkus (josh(at)agliodbs(dot)com) wrote:
> On the other hand, it's still true that a high STDDEV indicates a high
> variance in the response times of a particular query, whereas a low one
> indicates that most are close to the average. While precision math
> might not work if we don't have the correct distribution, for gross DBA
> checks it's still useful. That is, I can answer the question in many
> cases of: "Does this query have a high average because of outliers, or
> because it's consisently slow?" by looking at the STDDEV.
The concern is actually the reverse issue- often the question is "is
this query ever really slow?", or "when is this query really slow?" and
those questions are not answered by stddev, min, max, nor avg.
> And FWIW, for sites where we monitor pg_stat_statements, we reset daily
> or weekly. Otherwise, the stats have no meaning.
I have wondered if we (PG) should do that by default.. I agree that
often they are much more useful when reset periodically. Of course,
having actual historical information *would* be valuable, if you could
identify the time range covered..
Thanks,
Stephen
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Stephen Frost <sfrost(at)snowman(dot)net> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 20:07:51 |
| Message-ID: | CAMkU=1xc5595L6zx=D5SbVNY6HKbdiVS1KYjJ=ShdH0KPy8aLg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 9:20 AM, Stephen Frost <sfrost(at)snowman(dot)net> wrote:
> Josh,
>
> * Josh Berkus (josh(at)agliodbs(dot)com) wrote:
> > On the other hand, it's still true that a high STDDEV indicates a high
> > variance in the response times of a particular query, whereas a low one
> > indicates that most are close to the average. While precision math
> > might not work if we don't have the correct distribution, for gross DBA
> > checks it's still useful. That is, I can answer the question in many
> > cases of: "Does this query have a high average because of outliers, or
> > because it's consisently slow?" by looking at the STDDEV.
>
> The concern is actually the reverse issue- often the question is "is
> this query ever really slow?", or "when is this query really slow?" and
> those questions are not answered by stddev, min, max, nor avg.
>
How does max not answer "is this query ever really slow?"? But good point,
if we have a max, then I think a time-stamp for when that max was obtained
would also be very useful.
Cheers,
Jeff
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 20:17:53 |
| Message-ID: | 20131023201753.GP2706@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
* Jeff Janes (jeff(dot)janes(at)gmail(dot)com) wrote:
> On Wed, Oct 23, 2013 at 9:20 AM, Stephen Frost <sfrost(at)snowman(dot)net> wrote:
> > * Josh Berkus (josh(at)agliodbs(dot)com) wrote:
> > > On the other hand, it's still true that a high STDDEV indicates a high
> > > variance in the response times of a particular query, whereas a low one
> > > indicates that most are close to the average. While precision math
> > > might not work if we don't have the correct distribution, for gross DBA
> > > checks it's still useful. That is, I can answer the question in many
> > > cases of: "Does this query have a high average because of outliers, or
> > > because it's consisently slow?" by looking at the STDDEV.
> >
> > The concern is actually the reverse issue- often the question is "is
> > this query ever really slow?", or "when is this query really slow?" and
> > those questions are not answered by stddev, min, max, nor avg.
>
> How does max not answer "is this query ever really slow?"?
meh. max can end up being high for about a bazillion reasons and it'd
be difficult to really get any understanding of how or why it happened
from just that information.
> But good point,
> if we have a max, then I think a time-stamp for when that max was obtained
> would also be very useful.
And now we're getting into exactly what I was trying to suggest
up-thread: outlier detection and increased logging when a rare event
occurs..
Thanks,
Stephen
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Josh Berkus <josh(at)agliodbs(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 20:26:15 |
| Message-ID: | CAM3SWZQqN57O7uLumJ5QuGC+XbHxhGnqCtVP=PdC-zoUPw3E+g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 1:07 PM, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> wrote:
> How does max not answer "is this query ever really slow?"? But good point,
> if we have a max, then I think a time-stamp for when that max was obtained
> would also be very useful.
I'm concerned about the cost of all of this. And like Stephen, I'm not
too impressed by the idea of a permanent max - it's going to be some
value from before the cache was warmed the large majority of the time.
I think that there are some big savings to be made now that the query
text is only useful to humans, and isn't compared directly for the
purposes of matching and so on. Generally speaking, a human will
inquire about query execution costs far less frequently than the
system spends aggregating them. So fixing that problem would go a long
way towards resolving these concerns. It would also probably have the
benefit of making it possible for query texts to be arbitrarily long -
we'd be storing them in files (with a shared memory buffer). I get a
lot of complaints about the truncation of query texts in
pg_stat_statements, so I think that'd be really valuable. It would
make far higher pg_stat_statements.max values practical to boot, by
radically reducing the amount of shared memory required.
All of this might be a bit tricky, but I suspect it's well worth it.
--
Peter Geoghegan
| From: | Marc Mamin <M(dot)Mamin(at)intershop(dot)de> |
|---|---|
| To: | "'KONDO Mitsumasa'" <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndQuadrant(dot)fr> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, "Peter Geoghegan" <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 21:34:30 |
| Message-ID: | B6F6FD62F2624C4C9916AC0175D56D880CE3DDA2@jenmbs01.ad.intershop.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
>> Oscillating plan changes may fit multimodal but I don't feel that's
>> typical. My experience has been it's either an extremely rare plan
>> difference or it's a shift from one plan to another over time.
>After all, all of avg, min, max and stdev are only numerical value for predicting model. There aren't the robustness and strictness such as Write Ahead Logging. It resembles a weather forecast. They are still better than nothing.
>It is needed a human judgment to finally suppose a cause from the numerical values. By the way, we can guess probability of the value from stdev.
>Therefore we can guess easily even if there is an extreme value in min/max whether it is normal or not.
>>> What I've been gathering from my quick chat this morning is that
>>> either you know how to characterize the distribution and then the min
>>> max and average are useful on their own, or you need to keep track of
>>> an histogram where all the bins are of the same size to be able to
>>> learn what the distribution actually is.
Hello,
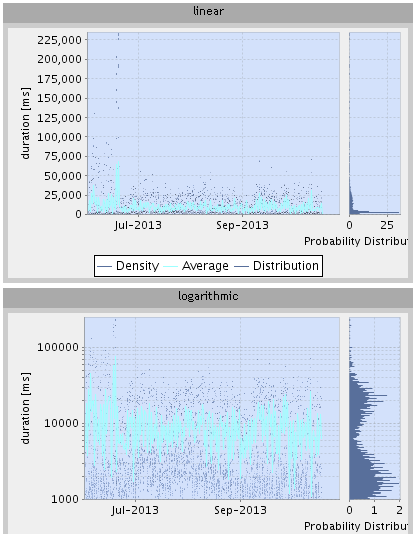
We have an in house reporting application doing a lot of response times graphing.
Our experience has shown that in many cases of interest (the one you want to dig in)
a logarithmic scale for histogram bins result in a better visualization.
attached an example from a problematic postgres query...
my 2 pences,
Marc Mamin
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 57.4 KB |
| From: | Martijn van Oosterhout <kleptog(at)svana(dot)org> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 21:46:01 |
| Message-ID: | 20131023214601.GB29432@svana.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Oct 22, 2013 at 11:16:19AM -0700, Jeff Janes wrote:
> On Mon, Oct 21, 2013 at 4:29 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> > Hm. It's been a long time since college statistics, but doesn't the
> > entire concept of standard deviation depend on the assumption that the
> > underlying distribution is more-or-less normal (Gaussian)?
>
> It is easy to misinterpret the standard deviation if the distribution is
> not gaussian, but that is also true of the average. The standard deviation
> (or the variance) is commonly used with non-gaussian distributions, either
> because it is the most efficient estimator for those particular
> distributions, or just because it is so commonly available.
Well, the standard deviation is the square root of the variance, which
is the second moment of the distribution. The first moment being the
mean. No matter what distribution it is, these are useful numbers.
If I had to guess a distribution for query runtimes I'd go for Poisson,
which would mean you'd expect the mean to equal the variance. Don't
have enough experience with such measurements to say whether that is
reasonable.
Have a nice day,
--
Martijn van Oosterhout <kleptog(at)svana(dot)org> http://svana.org/kleptog/
> He who writes carelessly confesses thereby at the very outset that he does
> not attach much importance to his own thoughts.
-- Arthur Schopenhauer
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Martijn van Oosterhout <kleptog(at)svana(dot)org> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 21:53:47 |
| Message-ID: | CAM3SWZSrBWDHop1PU_ScLQpdZZCHAb-8mEGXgLAbdTJtiJ06+w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 2:46 PM, Martijn van Oosterhout
<kleptog(at)svana(dot)org> wrote:
> Well, the standard deviation is the square root of the variance, which
> is the second moment of the distribution. The first moment being the
> mean. No matter what distribution it is, these are useful numbers.
I'm inclined to agree. Perhaps more importantly, like the mean, the
stddev is the truth, even if it doesn't tell the full story. This data
will always need to be interpreted by a reasonably well informed
human.
--
Peter Geoghegan
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, "'KONDO Mitsumasa'" <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndQuadrant(dot)fr> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 21:57:18 |
| Message-ID: | 5268463E.4010806@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24/10/13 10:34, Marc Mamin wrote:
>>> Oscillating plan changes may fit multimodal but I don't feel that's
>>> typical. My experience has been it's either an extremely rare plan
>>> difference or it's a shift from one plan to another over time.
>> After all, all of avg, min, max and stdev are only numerical value for predicting model. There aren't the robustness and strictness such as Write Ahead Logging. It resembles a weather forecast. They are still better than nothing.
>> It is needed a human judgment to finally suppose a cause from the numerical values. By the way, we can guess probability of the value from stdev.
>> Therefore we can guess easily even if there is an extreme value in min/max whether it is normal or not.
>>>> What I've been gathering from my quick chat this morning is that
>>>> either you know how to characterize the distribution and then the min
>>>> max and average are useful on their own, or you need to keep track of
>>>> an histogram where all the bins are of the same size to be able to
>>>> learn what the distribution actually is.
> Hello,
>
> We have an in house reporting application doing a lot of response times graphing.
> Our experience has shown that in many cases of interest (the one you want to dig in)
> a logarithmic scale for histogram bins result in a better visualization.
> attached an example from a problematic postgres query...
>
> my 2 pences,
>
> Marc Mamin
Looks definitely bimodal in the log version, very clear!
Yes, I feel that having a 32 log binary binned histogram (as Alvaro
Herrera suggested) would be very useful. Especially if the size of the
first bin can be set - as some people would like to be 100us and others
might prefer 1ms or something else.
Cheers,
Gavin
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
| Cc: | Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 22:26:09 |
| Message-ID: | CAM3SWZQYJMGHAOAR-6yBBndqwbJveY3ACJFRN1TEs8zR_Ah3+A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 2:57 PM, Gavin Flower
<GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
> Looks definitely bimodal in the log version, very clear!
>
> Yes, I feel that having a 32 log binary binned histogram (as Alvaro Herrera
> suggested) would be very useful.
I'm having a hard time imagining how you'd actually implement that.
For example, this:
https://wiki.postgresql.org/wiki/Aggregate_Histogram
requires that a "limit" be specified ahead of time. Is there a
principled way to increase or decrease this kind of limit over time,
and have the new buckets contents "spill into each other"?
--
Peter Geoghegan
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:00:11 |
| Message-ID: | 526854FB.8080302@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24/10/13 11:26, Peter Geoghegan wrote:
> On Wed, Oct 23, 2013 at 2:57 PM, Gavin Flower
> <GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
>> Looks definitely bimodal in the log version, very clear!
>>
>> Yes, I feel that having a 32 log binary binned histogram (as Alvaro Herrera
>> suggested) would be very useful.
> I'm having a hard time imagining how you'd actually implement that.
> For example, this:
>
> https://wiki.postgresql.org/wiki/Aggregate_Histogram
>
> requires that a "limit" be specified ahead of time. Is there a
> principled way to increase or decrease this kind of limit over time,
> and have the new buckets contents "spill into each other"?
>
To smplify things, I'm using 5 buckets, but 32 would be better.
Assume first bucket width is 1ms.
bucket range
0 x =< 1ms
1 1ms < x =< 2ms
2 2ms < x =< 4ms
3 4ms < x =< 8ms
5 8ms < x
If the size of the first bucket changed, then implicitly the histogram
would be restarted. As there is no meaningful way of using any data
from the existing histogram - even if the size of the first bucket was a
power of 2 greater than the old one (here things are fine, until you try
and apportion the data in the last bucket!).
Cheers,
Gavin
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:06:35 |
| Message-ID: | CAMkU=1wgbyA9AT9TUBmOM29C4nwGnaBm9T6pu_cAkdP05N358A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 3:26 PM, Peter Geoghegan <pg(at)heroku(dot)com> wrote:
> On Wed, Oct 23, 2013 at 2:57 PM, Gavin Flower
> <GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
> > Looks definitely bimodal in the log version, very clear!
> >
> > Yes, I feel that having a 32 log binary binned histogram (as Alvaro
> Herrera
> > suggested) would be very useful.
>
> I'm having a hard time imagining how you'd actually implement that.
> For example, this:
>
> https://wiki.postgresql.org/wiki/Aggregate_Histogram
>
> requires that a "limit" be specified ahead of time. Is there a
> principled way to increase or decrease this kind of limit over time,
> and have the new buckets contents "spill into each other"?
>
If you are doing a log scale in the bucket widths, 32 buckets covers a huge
range, so I think you could get away without having the ability to rescale
at all. For example just have the bottom bucket mean <=1ms, and the top
bucket mean > 12.42 days (rather than between 12.42 and 24.85 days). But
it should be possible to rescale if you really want to. If a bucket >32 is
needed, just add bucket[2] into bucket[1], slide buckets 3..32 down one
each, and initialize a new bucket 32, and bump the factor that says how
many times this shift has been done before.
Cheers,
Jeff
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:07:09 |
| Message-ID: | 5268569D.6000404@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24/10/13 12:00, Gavin Flower wrote:
> On 24/10/13 11:26, Peter Geoghegan wrote:
>> On Wed, Oct 23, 2013 at 2:57 PM, Gavin Flower
>> <GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
>>> Looks definitely bimodal in the log version, very clear!
>>>
>>> Yes, I feel that having a 32 log binary binned histogram (as Alvaro
>>> Herrera
>>> suggested) would be very useful.
>> I'm having a hard time imagining how you'd actually implement that.
>> For example, this:
>>
>> https://wiki.postgresql.org/wiki/Aggregate_Histogram
>>
>> requires that a "limit" be specified ahead of time. Is there a
>> principled way to increase or decrease this kind of limit over time,
>> and have the new buckets contents "spill into each other"?
>>
> To smplify things, I'm using 5 buckets, but 32 would be better.
> Assume first bucket width is 1ms.
>
> bucket range
> 0 x =< 1ms
> 1 1ms < x =< 2ms
> 2 2ms < x =< 4ms
> 3 4ms < x =< 8ms
> 5 8ms < x
>
>
> If the size of the first bucket changed, then implicitly the histogram
> would be restarted. As there is no meaningful way of using any data
> from the existing histogram - even if the size of the first bucket was
> a power of 2 greater than the old one (here things are fine, until you
> try and apportion the data in the last bucket!).
>
>
> Cheers,
> Gavin
>
>
Arghhhhh!
Just realized, that even if the size of the first bucket was a power of
2 greater than the old one, then you can't meaningfully use any of the
old data in any of the old buckets (this is 'obvious; but somewhat messy
to explain!)
Cheers,
Gavin
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:14:25 |
| Message-ID: | CAMkU=1zqKfgfttVGpFpKbf06nSzmuX+D2PmtnXrd8jn61C7UTA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 4:00 PM, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz
> wrote:
> On 24/10/13 11:26, Peter Geoghegan wrote:
>
>> On Wed, Oct 23, 2013 at 2:57 PM, Gavin Flower
>> <GavinFlower(at)archidevsys(dot)co(dot)nz**> wrote:
>>
>>> Looks definitely bimodal in the log version, very clear!
>>>
>>> Yes, I feel that having a 32 log binary binned histogram (as Alvaro
>>> Herrera
>>> suggested) would be very useful.
>>>
>> I'm having a hard time imagining how you'd actually implement that.
>> For example, this:
>>
>> https://wiki.postgresql.org/**wiki/Aggregate_Histogram<https://wiki.postgresql.org/wiki/Aggregate_Histogram>
>>
>> requires that a "limit" be specified ahead of time. Is there a
>> principled way to increase or decrease this kind of limit over time,
>> and have the new buckets contents "spill into each other"?
>>
>> To smplify things, I'm using 5 buckets, but 32 would be better.
> Assume first bucket width is 1ms.
>
> bucket range
> 0 x =< 1ms
> 1 1ms < x =< 2ms
> 2 2ms < x =< 4ms
> 3 4ms < x =< 8ms
> 5 8ms < x
>
The last bucket would be limited to 8ms < x <= 16 ms. If you find
something > 16ms, then you have to rescale *before* you increment any of
the buckets. Once you do, there is now room to hold it.
bucket range
0 x =< 2ms (sum of previous bucket 0 and previous bucket 1)
1 2ms < x =< 4ms
2 4ms < x =< 8ms
3 8ms < x =< 16ms
4 16ms < x =< 32ms (starts empty)
Cheers,
Jeff
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:24:41 |
| Message-ID: | CAM3SWZQ8yp4Xaey__kgdXger6PXwGPD1FLpfv2qj9evqyvyq6g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 4:14 PM, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> wrote:
> The last bucket would be limited to 8ms < x <= 16 ms. If you find something
>> 16ms, then you have to rescale *before* you increment any of the buckets.
> Once you do, there is now room to hold it.
How is that laid out in shared memory? If the answer is an array of 32
int64s, one per bucket, -1 from me to this proposal. A huge advantage
of pg_stat_statements today is that the overhead is actually fairly
modest. I really want to preserve that property.
--
Peter Geoghegan
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:26:28 |
| Message-ID: | 52685B24.40409@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24/10/13 12:14, Jeff Janes wrote:
> On Wed, Oct 23, 2013 at 4:00 PM, Gavin Flower
> <GavinFlower(at)archidevsys(dot)co(dot)nz <mailto:GavinFlower(at)archidevsys(dot)co(dot)nz>>
> wrote:
>
> On 24/10/13 11:26, Peter Geoghegan wrote:
>
> On Wed, Oct 23, 2013 at 2:57 PM, Gavin Flower
> <GavinFlower(at)archidevsys(dot)co(dot)nz
> <mailto:GavinFlower(at)archidevsys(dot)co(dot)nz>> wrote:
>
> Looks definitely bimodal in the log version, very clear!
>
> Yes, I feel that having a 32 log binary binned histogram
> (as Alvaro Herrera
> suggested) would be very useful.
>
> I'm having a hard time imagining how you'd actually implement
> that.
> For example, this:
>
> https://wiki.postgresql.org/wiki/Aggregate_Histogram
>
> requires that a "limit" be specified ahead of time. Is there a
> principled way to increase or decrease this kind of limit over
> time,
> and have the new buckets contents "spill into each other"?
>
> To smplify things, I'm using 5 buckets, but 32 would be better.
> Assume first bucket width is 1ms.
>
> bucket range
> 0 x =< 1ms
> 1 1ms < x =< 2ms
> 2 2ms < x =< 4ms
> 3 4ms < x =< 8ms
> 5 8ms < x
>
>
> The last bucket would be limited to 8ms < x <= 16 ms. If you find
> something > 16ms, then you have to rescale *before* you increment any
> of the buckets. Once you do, there is now room to hold it.
>
> bucket range
> 0 x =< 2ms (sum of previous bucket 0 and previous
> bucket 1)
> 1 2ms < x =< 4ms
> 2 4ms < x =< 8ms
> 3 8ms < x =< 16ms
> 4 16ms < x =< 32ms (starts empty)
>
> Cheers,
>
> Jeff
It is very important that the last bucket be unbounded, or you may lose
potentially important data. Especially if one asumes that all durations
will fit into the first n - 1 buckets, in which case being alerted to
the asumption being siginificantly wrong is crucial!
The logic to check on the values for the last bucket is trivial, so
there is no need to have an upper limit for it.
Cheers,
Gavin
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Martijn van Oosterhout <kleptog(at)svana(dot)org> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:30:44 |
| Message-ID: | 20131023233044.GQ2706@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
* Martijn van Oosterhout (kleptog(at)svana(dot)org) wrote:
> If I had to guess a distribution for query runtimes I'd go for Poisson,
> which would mean you'd expect the mean to equal the variance. Don't
> have enough experience with such measurements to say whether that is
> reasonable.
I was thinking the same, but I'm not sure how that really helps us. The
histogram is a good idea, imv, and I'll add my vote for implementing
that. If it's too expensive to do currently then we need to work out a
way to make it cheaper. The log-based histogram as an array w/ NULLs
for any empty buckets might not be that terrible.
Thanks,
Stephen
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:34:33 |
| Message-ID: | 20131023233432.GR2706@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
* Peter Geoghegan (pg(at)heroku(dot)com) wrote:
> On Wed, Oct 23, 2013 at 4:14 PM, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> wrote:
> > The last bucket would be limited to 8ms < x <= 16 ms. If you find something
> >> 16ms, then you have to rescale *before* you increment any of the buckets.
> > Once you do, there is now room to hold it.
>
> How is that laid out in shared memory? If the answer is an array of 32
> int64s, one per bucket, -1 from me to this proposal. A huge advantage
> of pg_stat_statements today is that the overhead is actually fairly
> modest. I really want to preserve that property.
Any chance we could accumulate into the histogram in local memory and
only push to the shared memory on an "infrequent" or at least "less
frequent" basis? Apologies, I've not looked into the pg_stat_statements
bits all that closely, but I can certainly see how having to hold it all
in shared memory with locking to update would be painful..
Thanks,
Stephen
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:46:12 |
| Message-ID: | 52685FC4.5070805@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10/23/2013 01:26 PM, Peter Geoghegan wrote:
> So fixing that problem would go a long
> way towards resolving these concerns. It would also probably have the
> benefit of making it possible for query texts to be arbitrarily long -
> we'd be storing them in files (with a shared memory buffer). I get a
> lot of complaints about the truncation of query texts in
> pg_stat_statements, so I think that'd be really valuable. It would
> make far higher pg_stat_statements.max values practical to boot, by
> radically reducing the amount of shared memory required.
>
> All of this might be a bit tricky, but I suspect it's well worth it.
So you're suggesting that instead of storing the aggregates as we
currently do, we store a buffer of the last N queries (in normal form)
and their stats? And then aggregate when the user asks for it?
That would be nice, and IMHO the only way we can really resolve all of
these stats concerns. Any approach we take using histograms etc. is
going to leave out some stat someone needs.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:48:13 |
| Message-ID: | 5268603D.8050101@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24/10/13 12:24, Peter Geoghegan wrote:
> On Wed, Oct 23, 2013 at 4:14 PM, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> wrote:
>> The last bucket would be limited to 8ms < x <= 16 ms. If you find something
>>> 16ms, then you have to rescale *before* you increment any of the buckets.
>> Once you do, there is now room to hold it.
> How is that laid out in shared memory? If the answer is an array of 32
> int64s, one per bucket, -1 from me to this proposal. A huge advantage
> of pg_stat_statements today is that the overhead is actually fairly
> modest. I really want to preserve that property.
>
32 int64 buckets is only 256 bytes, so a thousand histograms would be
less than a quarter of a MB. Any machine that busy, would likely have
many GB's of RAM. I have 32 GB on my development machine.
Though, I suppose that the option to have such histograms could be off
by default, which would seem reasonable. How about a convention not to
have histgrams, when the parameter specifying the width of the first
bucket was either missing or set to zero (assuming a 'negative value'
would be a syntax error!).
Cheers,
Gavin
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Stephen Frost <sfrost(at)snowman(dot)net> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:48:22 |
| Message-ID: | CAM3SWZT7XCZ9SXSiW+tJvHi+SF1sygp2m1fRKnyuJFgdr0by7g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 4:34 PM, Stephen Frost <sfrost(at)snowman(dot)net> wrote:
> Any chance we could accumulate into the histogram in local memory and
> only push to the shared memory on an "infrequent" or at least "less
> frequent" basis? Apologies, I've not looked into the pg_stat_statements
> bits all that closely, but I can certainly see how having to hold it all
> in shared memory with locking to update would be painful..
I doubt it. That trick I proposed around storing the query text in an
external file is only feasible because we never update the query text,
and we hardly ever care what it actually is in practice. Contrast that
with something that is in a structure protected by a spinlock. You'd
have to keep deltas stashed in TopMemoryContext, and for all kinds of
common cases that just wouldn't work. Plus you have to have some whole
new mechanism for aggregating the stats across backends when someone
expresses an interest in seeing totals.
--
Peter Geoghegan
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:51:26 |
| Message-ID: | CAM3SWZRQmoQ6N-xF2c5+6jpRAqLX-QWo2MTKheEp+tfKSC5H-w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 4:46 PM, Josh Berkus <josh(at)agliodbs(dot)com> wrote:
> So you're suggesting that instead of storing the aggregates as we
> currently do, we store a buffer of the last N queries (in normal form)
> and their stats? And then aggregate when the user asks for it?
No, I'm not. I'm suggesting storing the query texts externally, in a
file. They usually use 1024 bytes of shared memory per entry,
regardless of how long the query text is. This would allow
pg_stat_statements to store arbitrarily large query texts, while also
giving us breathing room if we have ambitions around expanding what
pg_stat_statements can (optionally) track.
Having said that, I am still pretty sensitive to bloating pg_stat_statements.
--
Peter Geoghegan
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:55:42 |
| Message-ID: | 526861FE.7010805@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24/10/13 12:46, Josh Berkus wrote:
> On 10/23/2013 01:26 PM, Peter Geoghegan wrote:
>> So fixing that problem would go a long
>> way towards resolving these concerns. It would also probably have the
>> benefit of making it possible for query texts to be arbitrarily long -
>> we'd be storing them in files (with a shared memory buffer). I get a
>> lot of complaints about the truncation of query texts in
>> pg_stat_statements, so I think that'd be really valuable. It would
>> make far higher pg_stat_statements.max values practical to boot, by
>> radically reducing the amount of shared memory required.
>>
>> All of this might be a bit tricky, but I suspect it's well worth it.
> So you're suggesting that instead of storing the aggregates as we
> currently do, we store a buffer of the last N queries (in normal form)
> and their stats? And then aggregate when the user asks for it?
>
> That would be nice, and IMHO the only way we can really resolve all of
> these stats concerns. Any approach we take using histograms etc. is
> going to leave out some stat someone needs.
>
I don't see it as as either/or.
It might be useful to optionally all the last n queries be stored as you
suggested. People could decide for themselves how much storage they are
willing to allocate for the purpose.
Storing the last n queries, could be helpful in seeing why some users
are suddenly experiencing very slow response times.
I think the histogram would be more useful over a day or a week.
Cheers,
Gavin
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-23 23:58:18 |
| Message-ID: | CAM3SWZRyVrfVE72u28Ei6FiCKTF4ye=SiMmus+Nmek4j-KbKOQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 4:48 PM, Gavin Flower
<GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
> 32 int64 buckets is only 256 bytes, so a thousand histograms would be less
> than a quarter of a MB. Any machine that busy, would likely have many GB's
> of RAM. I have 32 GB on my development machine.
Who wants to just run with a thousand entries? I have many small
instances running on AWS where that actually is an appreciable amount
of memory. Individually, any addition to pg_stat_statements shared
memory use looks small, but that doesn't mean we want every possible
thing. Futhermore, you're assuming that this is entirely a matter of
how much memory we use out of how much is available, and I don't
understand it that way.
--
Peter Geoghegan
| From: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-24 00:15:44 |
| Message-ID: | 526866B0.4000103@archidevsys.co.nz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24/10/13 12:58, Peter Geoghegan wrote:
> On Wed, Oct 23, 2013 at 4:48 PM, Gavin Flower
> <GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
>> 32 int64 buckets is only 256 bytes, so a thousand histograms would be less
>> than a quarter of a MB. Any machine that busy, would likely have many GB's
>> of RAM. I have 32 GB on my development machine.
> Who wants to just run with a thousand entries? I have many small
> instances running on AWS where that actually is an appreciable amount
> of memory. Individually, any addition to pg_stat_statements shared
> memory use looks small, but that doesn't mean we want every possible
> thing. Futhermore, you're assuming that this is entirely a matter of
> how much memory we use out of how much is available, and I don't
> understand it that way.
>
Anyhow, I was suggesting the faclity be off by default - I see no point
in enabling where people don't need it, even if the resource RAM,
processor, whatever, were minimal.
Cheers,
Gavin
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-24 00:17:23 |
| Message-ID: | CAM3SWZT9SqdfF7h5xHB9bOKft1hTj3Tfu8=dKL-uzoX0L9s=dw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 4:51 PM, Peter Geoghegan <pg(at)heroku(dot)com> wrote:
> No, I'm not. I'm suggesting storing the query texts externally, in a
> file. They usually use 1024 bytes of shared memory per entry,
> regardless of how long the query text is.
I should add that I think that that's about the useful limit of such
schemes. Maybe we could buy a bit more breathing room by storing some
of the stats externally, but I doubt it'd be worth it. I'm not
interested in optimizing pg_stat_statements in the direction of
supporting aggregating a number of distinct entries past much more
than 10,000. I am interested in making it store richer statistics,
provided we're very careful about the costs. Every time those counters
are incremented, a spinlock is held. I don't want everyone to have to
pay any non-trivial additional cost for that, given that the added
instrumentation may not actually be that useful to most users who just
want a rough picture.
--
Peter Geoghegan
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Marc Mamin <M(dot)Mamin(at)intershop(dot)de>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Stephen Frost <sfrost(at)snowman(dot)net>, Dimitri Fontaine <dimitri(at)2ndquadrant(dot)fr>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-24 00:25:22 |
| Message-ID: | CAM3SWZR114p8=_nZEy8K-mSYUziTTGaque31CVcGam8sbuoMRQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 5:15 PM, Gavin Flower
<GavinFlower(at)archidevsys(dot)co(dot)nz> wrote:
> Anyhow, I was suggesting the faclity be off by default - I see no point in
> enabling where people don't need it, even if the resource RAM, processor,
> whatever, were minimal.
As long as any new field in the Counters struct needs to be protected
by a spinlock, I will be suspicious of the cost. The track_io_timing
stuff is still protected, even when it's turned off. So I'm afraid
that it isn't that simple.
--
Peter Geoghegan
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-24 03:52:16 |
| Message-ID: | 20131024035216.GA6832@eldon.alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Peter Geoghegan escribió:
> I am interested in making it store richer statistics,
> provided we're very careful about the costs. Every time those counters
> are incremented, a spinlock is held.
Hmm, now if we had portable atomic addition, so that we could spare the
spinlock ...
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-24 13:54:52 |
| Message-ID: | 526926AC.9080404@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10/23/2013 07:51 PM, Peter Geoghegan wrote:
> On Wed, Oct 23, 2013 at 4:46 PM, Josh Berkus <josh(at)agliodbs(dot)com> wrote:
>> So you're suggesting that instead of storing the aggregates as we
>> currently do, we store a buffer of the last N queries (in normal form)
>> and their stats? And then aggregate when the user asks for it?
> No, I'm not. I'm suggesting storing the query texts externally, in a
> file. They usually use 1024 bytes of shared memory per entry,
> regardless of how long the query text is. This would allow
> pg_stat_statements to store arbitrarily large query texts, while also
> giving us breathing room if we have ambitions around expanding what
> pg_stat_statements can (optionally) track.
>
> Having said that, I am still pretty sensitive to bloating pg_stat_statements.
>
Me too. I think min, max and stddev will have a fairly small impact, and
give considerable bang for the buck. Not so sure about the other
suggestions. And of course, memory impact is only half the story - CPU
cycles spent is the other part.
I'll be quite happy if we can get around the query text length limit. I
have greatly increased the buffer size at quite a few clients, in one
case where they run some pretty large auto-generated queries and have
memory to burn, up to 40k.
cheers
andrew
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-24 14:54:32 |
| Message-ID: | CAM3SWZT+5o-9RmKxE8xUpnjXOQ7y7oT8qVSxfo1ovpj=K4U3VQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Oct 24, 2013 at 6:54 AM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
> I'll be quite happy if we can get around the query text length limit. I have
> greatly increased the buffer size at quite a few clients, in one case where
> they run some pretty large auto-generated queries and have memory to burn,
> up to 40k.
I've already hacked up a prototype patch. I've heard enough complaints
about that to want to fix it once and for all.
--
Peter Geoghegan
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-10-24 17:10:51 |
| Message-ID: | 5269549B.1070803@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 10/23/2013 08:52 PM, Alvaro Herrera wrote:
> Peter Geoghegan escribió:
>
>> I am interested in making it store richer statistics,
>> provided we're very careful about the costs. Every time those counters
>> are incremented, a spinlock is held.
>
> Hmm, now if we had portable atomic addition, so that we could spare the
> spinlock ...
Oh, sure, just take the *easy* way out. ;-)
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-13 22:11:46 |
| Message-ID: | CAM3SWZSq1S2WjRP8h2SxuJh+_2-Toa+uFAApUK3e67kobMpsrg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Oct 23, 2013 at 8:52 PM, Alvaro Herrera
<alvherre(at)2ndquadrant(dot)com> wrote:
> Hmm, now if we had portable atomic addition, so that we could spare the
> spinlock ...
That certainly seems like an interesting possibility.
I think that pg_stat_statements should be made to do this kind of
thing by a third party tool that aggregates snapshots of deltas.
Time-series data, including (approximate) *local* minima and maxima
should be built from that. I think tools like KONDO-san's pg_statsinfo
tool have an important role to play here. I would like to see it or a
similar tool become a kind of defacto standard for consuming
pg_stat_statements' output.
At this point we are in general very much chasing diminishing returns
by adding new things to the counters struct, particularly given that
it's currently protected by a spinlock. And adding a histogram or
min/max for something like execution time isn't an approach that can
be made to work for every existing cost tracked by pg_stat_statements.
So, taking all that into consideration, I'm afraid this patch gets a
-1 from me.
--
Peter Geoghegan
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-14 12:25:12 |
| Message-ID: | 5284C128.5010208@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2013/10/21 20:17), KONDO Mitsumasa wrote:
> (2013/10/18 22:21), Andrew Dunstan wrote:
>> If we're going to extend pg_stat_statements, even more than min and max
>> I'd like to see the standard deviation in execution time.
> OK. I do! I am making some other patches, please wait more!
I add stddev_time and fix some sources.
Psql result of my latest patch is under following.
userid | 10
dbid | 16384
query | UPDATE pgbench_tellers SET tbalance = tbalance + ? WHERE
tid = ?;
calls | 74746
total_time | 1094.2919999998
min_time | 0.007
max_time | 15.091
stddev_time | 0.100439187720684
rows | 74746
shared_blks_hit | 302346
shared_blks_read | 6
shared_blks_dirtied | 161
shared_blks_written | 0
local_blks_hit | 0
local_blks_read | 0
local_blks_dirtied | 0
local_blks_written | 0
temp_blks_read | 0
temp_blks_written | 0
blk_read_time | 0
blk_write_time | 0
I don't think a lot that order of columns in this table. If have any idea, please
send me. And thanks for a lot of comments and discussion, I am going to refer to
these for not only this patch but also development of pg_statsinfo and
pg_stats_reporter:-)
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-14 12:29:26 |
| Message-ID: | 5284C226.1010607@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Oh! Sorry...
I forgot to attach my latest patch.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-exectime_v1.patch | text/x-diff | 16.5 KB |
| From: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-14 17:09:29 |
| Message-ID: | CAHGQGwEyjGnu4rnxGvDP0R1mRt+jjd5WPHWuJEsvE5jvSgCpVg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Nov 14, 2013 at 7:11 AM, Peter Geoghegan <pg(at)heroku(dot)com> wrote:
> On Wed, Oct 23, 2013 at 8:52 PM, Alvaro Herrera
> <alvherre(at)2ndquadrant(dot)com> wrote:
>> Hmm, now if we had portable atomic addition, so that we could spare the
>> spinlock ...
>
> That certainly seems like an interesting possibility.
>
> I think that pg_stat_statements should be made to do this kind of
> thing by a third party tool that aggregates snapshots of deltas.
> Time-series data, including (approximate) *local* minima and maxima
> should be built from that. I think tools like KONDO-san's pg_statsinfo
> tool have an important role to play here. I would like to see it or a
> similar tool become a kind of defacto standard for consuming
> pg_stat_statements' output.
>
> At this point we are in general very much chasing diminishing returns
> by adding new things to the counters struct, particularly given that
> it's currently protected by a spinlock. And adding a histogram or
> min/max for something like execution time isn't an approach that can
> be made to work for every existing cost tracked by pg_stat_statements.
> So, taking all that into consideration, I'm afraid this patch gets a
> -1 from me.
Agreed.
Regards,
--
Fujii Masao
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-15 02:24:31 |
| Message-ID: | CAM3SWZSH8jC+a+hegGNpF2H9FywMKVnAj9R3ocrH=jDp1McBxA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Nov 14, 2013 at 9:09 AM, Fujii Masao <masao(dot)fujii(at)gmail(dot)com> wrote:
>> I think that pg_stat_statements should be made to do this kind of
>> thing by a third party tool that aggregates snapshots of deltas.
>> Time-series data, including (approximate) *local* minima and maxima
>> should be built from that. I think tools like KONDO-san's pg_statsinfo
>> tool have an important role to play here. I would like to see it or a
>> similar tool become a kind of defacto standard for consuming
>> pg_stat_statements' output.
> Agreed.
I would like to hear others' thoughts on how to proceed here. Has
anyone actually tried and failed with an approach that uses aggressive
aggregation of snapshots/deltas? If that's something that is
problematic, let's hear why. Maybe pg_stat_statements could do better
when snapshots are aggressively taken by tools at fixed intervals.
Most obviously, we could probably come up with a way better interface
for tools that need deltas only, where a consumer registers interest
in receiving snapshots. We could store a little bitmap structure in
shared memory, and set bits as corresponding pg_stat_statements
entries are dirtied, and only send query texts the first time.
I am still very much of the opinion that we need to expose queryid and
so on. I lost that argument several times, but it seems like there is
strong demand from it from many places - I've had people that I don't
know talk to me about it at conferences.
--
Peter Geoghegan
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-15 02:28:26 |
| Message-ID: | 528586CA.8010106@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2013/11/14 7:11), Peter Geoghegan wrote:
> On Wed, Oct 23, 2013 at 8:52 PM, Alvaro Herrera
> <alvherre(at)2ndquadrant(dot)com> wrote:
>> Hmm, now if we had portable atomic addition, so that we could spare the
>> spinlock ...
> And adding a histogram or
> min/max for something like execution time isn't an approach that can
> be made to work for every existing cost tracked by pg_stat_statements.
> So, taking all that into consideration, I'm afraid this patch gets a
> -1 from me.
It is confirmation just to make sure, does "this patch" mean my patch? I agree
with you about not adding another lock implementation. It will becomes overhead.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-15 02:31:35 |
| Message-ID: | CAM3SWZQpS_8xfwM6XZkNkXqcVvcVh-CfjyuY3hm8UY4tsLN+Fw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Nov 14, 2013 at 6:28 PM, KONDO Mitsumasa
<kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
> It is confirmation just to make sure, does "this patch" mean my patch? I
> agree with you about not adding another lock implementation. It will becomes
> overhead.
Yes, I referred to your patch. I don't want to go down this road,
because aggregation and constructing a timeline feels like the job of
another tool. I am concerned about local minima and maxima. Even with
the ability to reset min/max independently, you can't do so for each
entry individually. And this approach won't scale to a histogram or
more sophisticated ways of characterizing distribution, particularly
not multiplicatively for things other than execution time (blocks hit
and so on) - that spinlock needs to be held for very little time
indeed to preserve pg_stat_statements current low overhead.
As I said above, lets figure out how to have your tool or a similar
tool acquire snapshots inexpensively and frequently instead. That is a
discussion I'd be happy to have. IMO pg_stat_statements ought to be as
cheap as possible, and do one thing well - aggregate fixed-unit costs
cumulatively.
--
Peter Geoghegan
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-15 03:32:45 |
| Message-ID: | 528595DD.7060704@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2013/11/15 11:31), Peter Geoghegan wrote:
> On Thu, Nov 14, 2013 at 6:28 PM, KONDO Mitsumasa
> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>> It is confirmation just to make sure, does "this patch" mean my patch? I
>> agree with you about not adding another lock implementation. It will becomes
>> overhead.
>
> Yes, I referred to your patch. I don't want to go down this road,
> because aggregation and constructing a timeline feels like the job of
> another tool. I am concerned about local minima and maxima. Even with
> the ability to reset min/max independently, you can't do so for each
> entry individually. And this approach won't scale to a histogram or
> more sophisticated ways of characterizing distribution, particularly
> not multiplicatively for things other than execution time (blocks hit
> and so on)
I think that pg_stat_statements is light-weight monitoring tool, not whole
monitoring tool. This feature is very good for everyone to get statistics.
If you'd like to get more detail statistics, I suggest you to add another
monitoring tools like pg_stat_statements_full. It might more heavy, but it can
get more detail information. Everyone will welcome to new features of that.
> - that spinlock needs to be held for very little time
> indeed to preserve pg_stat_statements current low overhead.
I'd like to leave pg_stat_statement low overhead. My patch realizes it. I don't
add new locks and complicated code in my patch.
> As I said above, lets figure out how to have your tool or a similar
> tool acquire snapshots inexpensively and frequently instead.
We tried to solve this problem using our tool in the past.
However, it is difficult that except log output method which is log_statement=all
option. So we try to add new feature to pg_stat_statement, it would help DBA to
provide useful statistics without overhead.
> That is a
> discussion I'd be happy to have. IMO pg_stat_statements ought to be as
> cheap as possible, and do one thing well - aggregate fixed-unit costs
> cumulatively.
I am also happy to your discussion!
I'd like to install your new patch and give you my comment.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Josh Berkus <josh(at)agliodbs(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Robert Haas <robertmhaas(at)gmail(dot)com>, Gavin Flower <GavinFlower(at)archidevsys(dot)co(dot)nz>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-15 03:33:48 |
| Message-ID: | 5285961C.4010309@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2013/11/15 2:09), Fujii Masao wrote:
> Agreed.
Could you tell me your agreed reason? I am sorry that I suspect you doesn't
understand this disccusion enough:-(
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Ceter
| From: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2013-11-20 11:27:54 |
| Message-ID: | BF2827DCCE55594C8D7A8F7FFD3AB7713DDAC54F@SZXEML508-MBX.china.huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 14 November 2013, Kondo Mitsumasa wrote:
> Subject: Re: [HACKERS] Add min and max execute statement time in
> pg_stat_statement
>
> Oh! Sorry...
> I forgot to attach my latest patch.
* Is the patch in a patch format which has context?
No
* Does it apply cleanly to the current git master?
Yes.
* Does it compiles without any warning?
No. Compilation fails on windows platform.
.\contrib\pg_stat_statements\pg_stat_statements.c(1232) : error C2102: '&' requires l-value
1232 Line is: values[i++] = Float8GetDatumFast(sqrt(sqtime - avtime * avtime));
Thanks and Regards,
Kumar Rajeev Rastogi
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-21 11:54:54 |
| Message-ID: | 52DE600E.9080100@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Rebased patch is attached.
pg_stat_statements in PG9.4dev has already changed table columns in. So I hope
this patch will be committed in PG9.4dev.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-min-max-stdev-exectime_v2.patch | text/x-diff | 9.8 KB |
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-21 19:48:41 |
| Message-ID: | CA+U5nM+YhJuOjQ9ytNA6-N8cUGtxuNVO-faE6-xXPySDRmgBsw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21 January 2014 12:54, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
> Rebased patch is attached.
Does this fix the Windows bug reported by Kumar on 20/11/2013 ?
> pg_stat_statements in PG9.4dev has already changed table columns in. So I
> hope this patch will be committed in PG9.4dev.
I've read through the preceding discussion and I'm not very impressed.
Lots of people have spoken about wanting histogram output and I can't
even see a clear statement of whether that will or will not happen.
AFAICS, all that has happened is that people have given their opinions
and we've got almost the same identical patch, with a rush-rush
comment to commit even though we've waited months. If you submit a
patch, then you need to listen to feedback and be clear about what you
will do next, if you don't people will learn to ignore you and nobody
wants that. I should point out that technically this patch is late and
we could reject it solely on that basis, if we wanted to.
I agree with people saying that stddev is better than nothing at all,
so I am inclined to commit this, in spite of the above.
Any objections to commit?
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-21 20:09:34 |
| Message-ID: | 52DED3FE.2000609@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/21/2014 02:48 PM, Simon Riggs wrote:
> I agree with people saying that stddev is better than nothing at all,
> so I am inclined to commit this, in spite of the above. Any objections
> to commit?
I have not been following terribly closely, but if it includes stddev
then yes, please do, many of us will find it very useful indeed.
cheers
andrew
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-21 20:19:13 |
| Message-ID: | CAM3SWZQWZb+tNPFfmgBQTe2kiUzt=cA7Zs=naftMjWLaaDoEyg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jan 21, 2014 at 11:48 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> I agree with people saying that stddev is better than nothing at all,
> so I am inclined to commit this, in spite of the above.
I could live with stddev. But we really ought to be investing in
making pg_stat_statements work well with third-party tools. I am very
wary of enlarging the counters structure, because it is protected by a
spinlock. There has been no attempt to quantify that cost, nor has
anyone even theorized that it is not likely to be appreciable.
--
Peter Geoghegan
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-22 00:34:38 |
| Message-ID: | CA+U5nMJ75mkDA0s+Dff0EjKtn5wcTeXzmnj4OYUhxhOa7+YWzg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21 January 2014 21:19, Peter Geoghegan <pg(at)heroku(dot)com> wrote:
> On Tue, Jan 21, 2014 at 11:48 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>> I agree with people saying that stddev is better than nothing at all,
>> so I am inclined to commit this, in spite of the above.
>
> I could live with stddev. But we really ought to be investing in
> making pg_stat_statements work well with third-party tools. I am very
> wary of enlarging the counters structure, because it is protected by a
> spinlock. There has been no attempt to quantify that cost, nor has
> anyone even theorized that it is not likely to be appreciable.
OK, Kondo, please demonstrate benchmarks that show we have <1% impact
from this change. Otherwise we may need a config parameter to allow
the calculation.
Thanks very much.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-22 08:32:56 |
| Message-ID: | 52DF8238.30300@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/22 9:34), Simon Riggs wrote:
> AFAICS, all that has happened is that people have given their opinions
> and we've got almost the same identical patch, with a rush-rush
> comment to commit even though we've waited months. If you submit a
> patch, then you need to listen to feedback and be clear about what you
> will do next, if you don't people will learn to ignore you and nobody
> wants that.
I think it was replied that will be heavily. If we realize histogram in
pg_stat_statements, we have to implement dobuble precision arrays for storing
histogram data. And when we update histogram data in each statements, we must
update arrays with searching what response time is the smallest or biggest? It is
very big cost, assuming large memory, and too hevily when updating than we get
benefit from it. So I just add stddev for as fast as latest pg_stat_statements. I
got some agreed from some people, as you say.
> On 21 January 2014 21:19, Peter Geoghegan <pg(at)heroku(dot)com> wrote:
>> On Tue, Jan 21, 2014 at 11:48 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>>> I agree with people saying that stddev is better than nothing at all,
>>> so I am inclined to commit this, in spite of the above.
>>
>> I could live with stddev. But we really ought to be investing in
>> making pg_stat_statements work well with third-party tools. I am very
>> wary of enlarging the counters structure, because it is protected by a
>> spinlock. There has been no attempt to quantify that cost, nor has
>> anyone even theorized that it is not likely to be appreciable.
>
> OK, Kondo, please demonstrate benchmarks that show we have <1% impact
> from this change. Otherwise we may need a config parameter to allow
> the calculation.
OK, testing DBT-2 now. However, error range of benchmark might be 1% higher. So I
show you detail HTML results.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-22 13:26:00 |
| Message-ID: | CA+TgmoZ_y5TEONDHQcFs2x83bEOBUDxr1ieqoVC3qyHFf2sE3Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 22, 2014 at 3:32 AM, KONDO Mitsumasa
<kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>> OK, Kondo, please demonstrate benchmarks that show we have <1% impact
>> from this change. Otherwise we may need a config parameter to allow
>> the calculation.
>
> OK, testing DBT-2 now. However, error range of benchmark might be 1% higher.
> So I show you detail HTML results.
To see any impact from spinlock contention, I think you're pretty much
going to need a machine with >32 cores, I think, and lots of
concurrency. pgbench -S is probably a better test than DBT-2, because
it leaves out all the writing, so percentage-wise more time will be
spent doing things like updating the pgss hash table.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-23 01:28:39 |
| Message-ID: | 52E07047.9030307@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/22 22:26), Robert Haas wrote:
> On Wed, Jan 22, 2014 at 3:32 AM, KONDO Mitsumasa
> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>>> OK, Kondo, please demonstrate benchmarks that show we have <1% impact
>>> from this change. Otherwise we may need a config parameter to allow
>>> the calculation.
>>
>> OK, testing DBT-2 now. However, error range of benchmark might be 1% higher.
>> So I show you detail HTML results.
>
> To see any impact from spinlock contention, I think you're pretty much
> going to need a machine with >32 cores, I think, and lots of
> concurrency. pgbench -S is probably a better test than DBT-2, because
> it leaves out all the writing, so percentage-wise more time will be
> spent doing things like updating the pgss hash table.
Oh, thanks to inform me. I think essential problem of my patch has bottle neck in
sqrt() function and other division caluculation. I will replcace sqrt() function
in math.h to more faster algorithm. And moving unneccessary part of caluculation
in LWlocks or other locks. It might take time to improvement, so please wait for
a while.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-23 01:28:58 |
| Message-ID: | CAM3SWZSwsZMjHuKh1bsO695UA9-D_PBKBHJsdoa-BmGaQoWyCQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 22, 2014 at 5:28 PM, KONDO Mitsumasa
<kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
> Oh, thanks to inform me. I think essential problem of my patch has bottle
> neck in sqrt() function and other division caluculation.
Well, that's a pretty easy theory to test. Just stop calling them (and
do something similar to what we do for current counter fields instead)
and see how much difference it makes.
--
Peter Geoghegan
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-23 03:00:06 |
| Message-ID: | 52E085B6.9070500@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/22/2014 08:28 PM, KONDO Mitsumasa wrote:
> (2014/01/22 22:26), Robert Haas wrote:
>> On Wed, Jan 22, 2014 at 3:32 AM, KONDO Mitsumasa
>> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>>>> OK, Kondo, please demonstrate benchmarks that show we have <1% impact
>>>> from this change. Otherwise we may need a config parameter to allow
>>>> the calculation.
>>>
>>> OK, testing DBT-2 now. However, error range of benchmark might be 1%
>>> higher.
>>> So I show you detail HTML results.
>>
>> To see any impact from spinlock contention, I think you're pretty much
>> going to need a machine with >32 cores, I think, and lots of
>> concurrency. pgbench -S is probably a better test than DBT-2, because
>> it leaves out all the writing, so percentage-wise more time will be
>> spent doing things like updating the pgss hash table.
> Oh, thanks to inform me. I think essential problem of my patch has
> bottle neck in sqrt() function and other division caluculation. I will
> replcace sqrt() function in math.h to more faster algorithm. And
> moving unneccessary part of caluculation in LWlocks or other locks. It
> might take time to improvement, so please wait for a while.
>
Umm, I have not read the patch, but are you not using Welford's method?
Its per-statement overhead should be absolutely tiny (and should not
compute a square root at all per statement - the square root should
only be computed when the standard deviation is actually wanted, e.g.
when a user examines pg_stat_statements) See for example
<http://www.johndcook.com/standard_deviation.html>
cheers
andrew
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-23 04:33:06 |
| Message-ID: | 52E09B82.3040808@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/23 12:00), Andrew Dunstan wrote:
>
> On 01/22/2014 08:28 PM, KONDO Mitsumasa wrote:
>> (2014/01/22 22:26), Robert Haas wrote:
>>> On Wed, Jan 22, 2014 at 3:32 AM, KONDO Mitsumasa
>>> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>>>>> OK, Kondo, please demonstrate benchmarks that show we have <1% impact
>>>>> from this change. Otherwise we may need a config parameter to allow
>>>>> the calculation.
>>>>
>>>> OK, testing DBT-2 now. However, error range of benchmark might be 1% higher.
>>>> So I show you detail HTML results.
>>>
>>> To see any impact from spinlock contention, I think you're pretty much
>>> going to need a machine with >32 cores, I think, and lots of
>>> concurrency. pgbench -S is probably a better test than DBT-2, because
>>> it leaves out all the writing, so percentage-wise more time will be
>>> spent doing things like updating the pgss hash table.
>> Oh, thanks to inform me. I think essential problem of my patch has bottle neck
>> in sqrt() function and other division caluculation. I will replcace sqrt()
>> function in math.h to more faster algorithm. And moving unneccessary part of
>> caluculation in LWlocks or other locks. It might take time to improvement, so
>> please wait for a while.
>>
>
> Umm, I have not read the patch, but are you not using Welford's method? Its
> per-statement overhead should be absolutely tiny (and should not compute a square
> root at all per statement - the square root should only be computed when the
> standard deviation is actually wanted, e.g. when a user examines
> pg_stat_statements) See for example
> <http://www.johndcook.com/standard_deviation.html>
Thanks for your advice. I read your example roughly, however, I think calculating
variance is not so heavy in my patch. Double based sqrt caluculation is most
heavily in my mind. And I find fast square root algorithm that is used in 3D games.
http://en.wikipedia.org/wiki/Fast_inverse_square_root
This page shows inverse square root algorithm, but it can caluculate normal
square root, and it is faster algorithm at the price of precision than general
algorithm. I think we want to fast algorithm, so it will be suitable.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-23 12:43:22 |
| Message-ID: | 52E10E6A.5060708@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/23 10:28), Peter Geoghegan wrote:
> On Wed, Jan 22, 2014 at 5:28 PM, KONDO Mitsumasa
> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>> Oh, thanks to inform me. I think essential problem of my patch has bottle
>> neck in sqrt() function and other division caluculation.
>
> Well, that's a pretty easy theory to test. Just stop calling them (and
> do something similar to what we do for current counter fields instead)
> and see how much difference it makes.
What means "calling them"? I think that part of heavy you think is
pg_stat_statement view that is called by select query, not a part of LWLock
getting statistic by hook. Right?
I tested my patch in pgbench, but I cannot find bottleneck of my latest patch.
(Sorry, I haven't been test select query in pg_stat_statement view...) Here is a
test result.
* Result (Test result is represented by tps.)
method | try1 | try2 | try3
--------------------------------------------
without pgss | 130938 | 131558 | 131796
with pgss | 125164 | 125146 | 125358
with patched pgss| 126091 | 126681 | 126433
* Test Setting
shared_buffers=1024MB
checkpoint_segments = 300
checkpoint_timeout = 15min
checkpoint_completion_target = 0.7
* pgbench script
pgbench -h xxx.xxx.xxx.xxx mitsu-ko -i -s 100
psql -h xxx.xxx.xxx.xxx mitsu-ko -c 'CHECKPOINT'
pgbench -h xxx.xxx.xxx.xxx mitsu-ko -c64 -j32 -S -T 180
pgbench -h xxx.xxx.xxx.xxx mitsu-ko -c64 -j32 -S -T 180
pgbench -h xxx.xxx.xxx.xxx mitsu-ko -c64 -j32 -S -T 180
* Server SPEC:
CPU: Xeon E5-2670 1P/8C 2.6GHz #We don't have 32 core cpu...
Memory: 24GB
RAID: i420 2GB cache
Disk: 15K * 6 (RAID 1+0)
Attached is latest developping patch. It hasn't been test much yet, but sqrt
caluclation may be faster.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-exectime_v5.patch | text/x-diff | 11.9 KB |
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-23 14:18:26 |
| Message-ID: | 52E124B2.6020905@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/22/2014 11:33 PM, KONDO Mitsumasa wrote:
> (2014/01/23 12:00), Andrew Dunstan wrote:
>>
>> On 01/22/2014 08:28 PM, KONDO Mitsumasa wrote:
>>> (2014/01/22 22:26), Robert Haas wrote:
>>>> On Wed, Jan 22, 2014 at 3:32 AM, KONDO Mitsumasa
>>>> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>>>>>> OK, Kondo, please demonstrate benchmarks that show we have <1%
>>>>>> impact
>>>>>> from this change. Otherwise we may need a config parameter to allow
>>>>>> the calculation.
>>>>>
>>>>> OK, testing DBT-2 now. However, error range of benchmark might be
>>>>> 1% higher.
>>>>> So I show you detail HTML results.
>>>>
>>>> To see any impact from spinlock contention, I think you're pretty much
>>>> going to need a machine with >32 cores, I think, and lots of
>>>> concurrency. pgbench -S is probably a better test than DBT-2, because
>>>> it leaves out all the writing, so percentage-wise more time will be
>>>> spent doing things like updating the pgss hash table.
>>> Oh, thanks to inform me. I think essential problem of my patch has
>>> bottle neck
>>> in sqrt() function and other division caluculation. I will replcace
>>> sqrt()
>>> function in math.h to more faster algorithm. And moving unneccessary
>>> part of
>>> caluculation in LWlocks or other locks. It might take time to
>>> improvement, so
>>> please wait for a while.
>>>
>>
>> Umm, I have not read the patch, but are you not using Welford's
>> method? Its
>> per-statement overhead should be absolutely tiny (and should not
>> compute a square
>> root at all per statement - the square root should only be computed
>> when the
>> standard deviation is actually wanted, e.g. when a user examines
>> pg_stat_statements) See for example
>> <http://www.johndcook.com/standard_deviation.html>
> Thanks for your advice. I read your example roughly, however, I think
> calculating variance is not so heavy in my patch. Double based sqrt
> caluculation is most heavily in my mind. And I find fast square root
> algorithm that is used in 3D games.
> http://en.wikipedia.org/wiki/Fast_inverse_square_root
>
> This page shows inverse square root algorithm, but it can caluculate
> normal square root, and it is faster algorithm at the price of
> precision than general algorithm. I think we want to fast algorithm,
> so it will be suitable.
According to the link I gave above:
The most obvious way to compute variance then would be to have two
sums: one to accumulate the sum of the x's and another to accumulate
the sums of the squares of the x's. If the x's are large and the
differences between them small, direct evaluation of the equation
above would require computing a small number as the difference of
two large numbers, a red flag for numerical computing. The loss of
precision can be so bad that the expression above evaluates to a
/negative/ number even though variance is always positive.
As I read your patch that's what it seems to be doing.
What is more, if the square root calculation is affecting your
benchmarks, I suspect you are benchmarking the wrong thing. The
benchmarks should not call for a single square root calculation. What we
really want to know is what is the overhead from keeping these stats.
But your total runtime code (i.e. code NOT from calling
pg_stat_statements()) for stddev appears to be this:
e->counters.total_sqtime += total_time * total_time;
cheers
andrew
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-26 08:08:27 |
| Message-ID: | CA+U5nMLYoFN9fxsnLVjWCoX2xeT1sPuuKbVVoa2snW-Q5q5AZQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21 January 2014 19:48, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> On 21 January 2014 12:54, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>> Rebased patch is attached.
>
> Does this fix the Windows bug reported by Kumar on 20/11/2013 ?
Please respond.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-26 08:43:44 |
| Message-ID: | CADupcHXCRW7CmNxNZwVk9wxqReVgBYfR63ij8ywHHSOm-SaV4Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2014-01-26 Simon Riggs <simon(at)2ndquadrant(dot)com>
> On 21 January 2014 19:48, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> > On 21 January 2014 12:54, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>
> wrote:
> >> Rebased patch is attached.
> >
> > Does this fix the Windows bug reported by Kumar on 20/11/2013 ?
>
> Please respond.
Oh.. Very sorry...
Last day, I tried to find Kumar mail at 20/11/2013. But I couldn't find
it... Could you tell me e-mail title?
My patch catches up with latest 9.4HEAD.
Regards,
--
Mitsumasa KONDO
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-26 08:48:33 |
| Message-ID: | CA+U5nMLS3mqs7wJwLyQZBOQeFRvgfGR=T0u-syp-ui7sW2roXA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 23 January 2014 12:43, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
> I tested my patch in pgbench, but I cannot find bottleneck of my latest
> patch.
...
> Attached is latest developping patch. It hasn't been test much yet, but sqrt
> caluclation may be faster.
Thank you for reworking this so that the calculation happens outside the lock.
Given your testing, and my own observation that the existing code
could be reworked to avoid contention if people become concerned, I
think this is now ready for commit, as soon as the last point about
Windows is answered.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 12:09:02 |
| Message-ID: | 52E64C5E.10704@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/23 23:18), Andrew Dunstan wrote:
> What is more, if the square root calculation is affecting your benchmarks, I
> suspect you are benchmarking the wrong thing.
I run another test that has two pgbench-clients in same time, one is
select-only-query and another is executing 'SELECT * pg_stat_statement' query in
every one second. I used v6 patch in this test.
* Benchmark Commands
$bin/pgbench -h xxx.xxx.xxx.xxx mitsu-ko -c64 -j32 -S -T 180 -n &
$bin/pgbench -h xxx.xxx.xxx.xxx mitsu-ko -T 180 -n -f file.sql
** file.sql
SELECT * FROM pg_stat_statement;
\sleep 1s
* Select-only-query Result (Test result is represented by tps.)
method | try1 | try2 | try3
--------------------------------------------
with pgss | 125502 | 125818 | 125809
with patched pgss| 125909 | 125699 | 126040
This result shows my patch is almost same performance than before.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, rajeev(dot)rastogi(at)huawei(dot)com |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 12:16:59 |
| Message-ID: | 52E64E3B.5080609@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/26 17:43), Mitsumasa KONDO wrote:
> 2014-01-26 Simon Riggs <simon(at)2ndquadrant(dot)com <mailto:simon(at)2ndquadrant(dot)com>>
>
> On 21 January 2014 19:48, Simon Riggs <simon(at)2ndquadrant(dot)com
> <mailto:simon(at)2ndquadrant(dot)com>> wrote:
> > On 21 January 2014 12:54, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp
> <mailto:kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>> wrote:
> >> Rebased patch is attached.
> >
> > Does this fix the Windows bug reported by Kumar on 20/11/2013 ?
Sorry, I was misunderstanding. First name of Mr. Rajeev Rastogi is Kumar! I searched
only e-mail address and title by his name...
I don't have windows compiler enviroment, but attached patch might be fixed.
Could I ask Mr. Rajeev Rastogi to test my patch again?
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-exectime_v6.patch | text/x-diff | 12.0 KB |
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 12:45:18 |
| Message-ID: | 52E654DE.6060609@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/27/2014 07:09 AM, KONDO Mitsumasa wrote:
> (2014/01/23 23:18), Andrew Dunstan wrote:
>> What is more, if the square root calculation is affecting your
>> benchmarks, I
>> suspect you are benchmarking the wrong thing.
> I run another test that has two pgbench-clients in same time, one is
> select-only-query and another is executing 'SELECT *
> pg_stat_statement' query in every one second. I used v6 patch in this
> test.
>
The issue of concern is not the performance of pg_stat_statements, AUIU.
The issue is whether this patch affects performance generally, i.e. is
there a significant cost in collecting these extra stats. To test this
you would compare two general pgbench runs, one with the patch applied
and one without. I personally don't give a tinker's cuss about whether
the patch slows down pg_stat_statements a bit.
cheers
andrew
| From: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 13:48:16 |
| Message-ID: | CADupcHUfkPWfBzLPAxnnciuu1fCnNe1OnZ8kDkEdVUpMrJFCQg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2014-01-27 Andrew Dunstan <andrew(at)dunslane(dot)net>
>
> On 01/27/2014 07:09 AM, KONDO Mitsumasa wrote:
>
>> (2014/01/23 23:18), Andrew Dunstan wrote:
>>
>>> What is more, if the square root calculation is affecting your
>>> benchmarks, I
>>> suspect you are benchmarking the wrong thing.
>>>
>> I run another test that has two pgbench-clients in same time, one is
>> select-only-query and another is executing 'SELECT * pg_stat_statement'
>> query in every one second. I used v6 patch in this test.
>>
>>
>
> The issue of concern is not the performance of pg_stat_statements, AUIU.
> The issue is whether this patch affects performance generally, i.e. is
> there a significant cost in collecting these extra stats. To test this you
> would compare two general pgbench runs, one with the patch applied and one
> without.
I showed first test result which is compared with without
pg_stat_statements and without patch last day. They ran in same server and
same benchmark settings(clients and scale factor) as today's result. When
you merge and see the results, you can confirm not to affect of performance
in my patch.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 15:23:22 |
| Message-ID: | 52E679EA.6080005@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/27/2014 08:48 AM, Mitsumasa KONDO wrote:
>
>
> The issue of concern is not the performance of pg_stat_statements,
> AUIU. The issue is whether this patch affects performance
> generally, i.e. is there a significant cost in collecting these
> extra stats. To test this you would compare two general pgbench
> runs, one with the patch applied and one without.
>
> I showed first test result which is compared with without
> pg_stat_statements and without patch last day. They ran in same server
> and same benchmark settings(clients and scale factor) as today's
> result. When you merge and see the results, you can confirm not to
> affect of performance in my patch.
>
>
Yeah, sorry, I misread your message. I think this is good to go from a
performance point of view, although I'm still a bit worried about the
validity of the method (accumulating a sum of squares). OTOH, Welford's
method probably requires slightly more per statement overhead, and
certainly requires one more accumulator per statement. I guess if we
find ill conditioned results it wouldn't be terribly hard to change.
cheers
andrew
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 21:37:10 |
| Message-ID: | CAM3SWZTn3vwoewN+hsJn0eV3Bc1PNaJt_nM7phCV_8vjkneSjw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jan 27, 2014 at 4:45 AM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
> I personally don't give a tinker's cuss about whether the patch slows down
> pg_stat_statements a bit.
Why not? The assurance that the overhead is generally very low is what
makes it possible to install it widely usually without a second
thought. That's hugely valuable.
--
Peter Geoghegan
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 22:01:36 |
| Message-ID: | 52E6D740.5080302@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/27/2014 04:37 PM, Peter Geoghegan wrote:
> On Mon, Jan 27, 2014 at 4:45 AM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
>> I personally don't give a tinker's cuss about whether the patch slows down
>> pg_stat_statements a bit.
> Why not? The assurance that the overhead is generally very low is what
> makes it possible to install it widely usually without a second
> thought. That's hugely valuable.
>
>
I care very much what the module does to the performance of all
statements. But I don't care much if selecting from pg_stat_statements
itself is a bit slowed. Perhaps I didn't express myself as clearly as I
could have.
cheers
andrew
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-27 22:54:52 |
| Message-ID: | CAM3SWZTY_dmGoGcu_qOESzu6QHL3VOTr5brTJ2vK1iAzt_7OoQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jan 27, 2014 at 2:01 PM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
> I care very much what the module does to the performance of all statements.
> But I don't care much if selecting from pg_stat_statements itself is a bit
> slowed. Perhaps I didn't express myself as clearly as I could have.
Oh, I see. Of course the overhead of calling the pg_stat_statements()
function is much less important. Actually, I think that calling that
function is going to add a lot of noise to any benchmark aimed at
measuring added overhead as the counters struct is expanded.
--
Peter Geoghegan
| From: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-28 06:17:25 |
| Message-ID: | BF2827DCCE55594C8D7A8F7FFD3AB7713DDBD187@SZXEML508-MBX.china.huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27th January, Mitsumasa KONDO wrote:
> > 2014-01-26 Simon Riggs <simon(at)2ndquadrant(dot)com
> > <mailto:simon(at)2ndquadrant(dot)com>>
> >
> > On 21 January 2014 19:48, Simon Riggs <simon(at)2ndquadrant(dot)com
> > <mailto:simon(at)2ndquadrant(dot)com>> wrote:
> > > On 21 January 2014 12:54, KONDO Mitsumasa
> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp
> > <mailto:kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>> wrote:
> > >> Rebased patch is attached.
> > >
> > > Does this fix the Windows bug reported by Kumar on 20/11/2013 ?
> Sorry, I was misunderstanding. First name of Mr. Rajeev Rastogi is
> Kumar! I searched only e-mail address and title by his name...
>
> I don't have windows compiler enviroment, but attached patch might be
> fixed.
> Could I ask Mr. Rajeev Rastogi to test my patch again?
I tried to test this but I could not apply the patch on latest git HEAD.
This may be because of recent patch (related to pg_stat_statement only
"pg_stat_statements external query text storage "), which got committed
on 27th January.
Thanks and Regards,
Kumar Rajeev Rastogi
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-28 10:23:53 |
| Message-ID: | 52E78539.4090505@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/28 15:17), Rajeev rastogi wrote:
>
>
> On 27th January, Mitsumasa KONDO wrote:
>>> 2014-01-26 Simon Riggs <simon(at)2ndquadrant(dot)com
>>> <mailto:simon(at)2ndquadrant(dot)com>>
>>>
>>> On 21 January 2014 19:48, Simon Riggs <simon(at)2ndquadrant(dot)com
>>> <mailto:simon(at)2ndquadrant(dot)com>> wrote:
>>> > On 21 January 2014 12:54, KONDO Mitsumasa
>> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp
>>> <mailto:kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>> wrote:
>>> >> Rebased patch is attached.
>>> >
>>> > Does this fix the Windows bug reported by Kumar on 20/11/2013 ?
>> Sorry, I was misunderstanding. First name of Mr. Rajeev Rastogi is
>> Kumar! I searched only e-mail address and title by his name...
>>
>> I don't have windows compiler enviroment, but attached patch might be
>> fixed.
>> Could I ask Mr. Rajeev Rastogi to test my patch again?
>
> I tried to test this but I could not apply the patch on latest git HEAD.
> This may be because of recent patch (related to pg_stat_statement only
> "pg_stat_statements external query text storage "), which got committed
> on 27th January.
Thank you for trying to test my patch. As you say, recently commit changes
pg_stat_statements.c a lot. So I have to revise my patch. Please wait for a while.
By the way, latest pg_stat_statement might affect performance in Windows system.
Because it uses fflush() system call every creating new entry in
pg_stat_statements, and it calls many fread() to warm file cache. It works well
in Linux system, but I'm not sure in Windows system. If you have time, could you
test it on your Windows system? If it affects perfomance a lot, we can still
change it.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 06:51:15 |
| Message-ID: | 18631.1390978275@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> writes:
> By the way, latest pg_stat_statement might affect performance in Windows system.
> Because it uses fflush() system call every creating new entry in
> pg_stat_statements, and it calls many fread() to warm file cache.
This statement doesn't seem to have much to do with the patch as
committed. There are no fflush calls, and no notion of warming the
file cache either. We do assume that the OS is smart enough to keep
a frequently-read file in cache ... is Windows too stupid for that?
regards, tom lane
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 07:58:17 |
| Message-ID: | CAM3SWZQQFOnnhDL=dHz+Viy3ZNDxmYGGVC7k6xb9y0steEOzqw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jan 28, 2014 at 10:51 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> writes:
>> By the way, latest pg_stat_statement might affect performance in Windows system.
>> Because it uses fflush() system call every creating new entry in
>> pg_stat_statements, and it calls many fread() to warm file cache.
>
> This statement doesn't seem to have much to do with the patch as
> committed.
You could make a strong case for the patch improving performance in
practice for many users, by allowing us to increase the
pg_stat_statements.max default value to 5,000, 5 times the previous
value. The real expense of creating a new entry is the exclusive
locking of the hash table, which blocks *everything* in
pg_stat_statements. That isn't expanded at all, since queries are only
written with a shared lock, which only blocks the creation of new
entries which was already relatively expensive. In particular, it does
not block the maintenance of costs for all already observed entries in
the hash table. It's obvious that simply reducing the pressure on the
cache will improve matters a lot, which for many users the external
texts patch does.
Since Mitsumasa has compared that patch and at least one of his
proposed pg_stat_statements patches on several occasions, I will
re-iterate the difference: any increased overhead from the external
texts patch is paid only when a query is first entered into the hash
table. Then, there is obviously and self-evidently no additional
overhead from contention for any future execution of the same query,
no matter what, indefinitely (the exclusive locking section of
creating a new entry does not do I/O, except in fantastically unlikely
circumstances). So for many of the busy production systems I work
with, that's the difference between a cost paid perhaps tens of
thousands of times a second, and a cost paid every few days or weeks.
Even if he is right about a write() taking an unreasonably large
amount of time on Windows, the consequences felt as pg_stat_statements
LWLock contention would be very limited.
I am not opposed in principle to adding new things to the counters
struct in pg_stat_statements. I just think that the fact that the
overhead of installing the module on a busy production system is
currently so low is of *major* value, and therefore any person that
proposes to expand that struct should be required to very conclusively
demonstrate that there is no appreciably increase in overhead. Having
a standard deviation column would be nice, but it's still not that
important. Maybe when we have portable atomic addition we can afford
to be much more inclusive of that kind of thing.
--
Peter Geoghegan
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 08:03:54 |
| Message-ID: | 52E8B5EA.70301@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/29 15:51), Tom Lane wrote:
> KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> writes:
>> By the way, latest pg_stat_statement might affect performance in Windows system.
>> Because it uses fflush() system call every creating new entry in
>> pg_stat_statements, and it calls many fread() to warm file cache.
> This statement doesn't seem to have much to do with the patch as
> committed. There are no fflush calls, and no notion of warming the
> file cache either.
Oh, all right.
> We do assume that the OS is smart enough to keep
> a frequently-read file in cache ... is Windows too stupid for that?
I don't know about it. But I think Windows cache feature is stupid.
It seems to always write/read data to/from disk, nevertheless having large memory...
I'd like to know test result on Windows, if we can...
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 08:31:54 |
| Message-ID: | BF2827DCCE55594C8D7A8F7FFD3AB7713DDBDA35@SZXEML508-MBX.china.huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 28th January, Mitsumasa KONDO wrote:
> >>> 2014-01-26 Simon Riggs <simon(at)2ndquadrant(dot)com
> >>> <mailto:simon(at)2ndquadrant(dot)com>>
> >>>
> >>> On 21 January 2014 19:48, Simon Riggs <simon(at)2ndquadrant(dot)com
> >>> <mailto:simon(at)2ndquadrant(dot)com>> wrote:
> >>> > On 21 January 2014 12:54, KONDO Mitsumasa
> >> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp
> >>> <mailto:kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>> wrote:
> >>> >> Rebased patch is attached.
> >>> >
> >>> > Does this fix the Windows bug reported by Kumar on
> 20/11/2013 ?
> >> Sorry, I was misunderstanding. First name of Mr. Rajeev Rastogi is
> >> Kumar! I searched only e-mail address and title by his name...
> >>
> >> I don't have windows compiler enviroment, but attached patch might
> be
> >> fixed.
> >> Could I ask Mr. Rajeev Rastogi to test my patch again?
> >
> > I tried to test this but I could not apply the patch on latest git
> HEAD.
> > This may be because of recent patch (related to pg_stat_statement
> only
> > "pg_stat_statements external query text storage "), which got
> > committed on 27th January.
> Thank you for trying to test my patch. As you say, recently commit
> changes pg_stat_statements.c a lot. So I have to revise my patch.
> Please wait for a while.
>
> By the way, latest pg_stat_statement might affect performance in
> Windows system.
> Because it uses fflush() system call every creating new entry in
> pg_stat_statements, and it calls many fread() to warm file cache. It
> works well in Linux system, but I'm not sure in Windows system. If you
> have time, could you test it on your Windows system? If it affects
> perfomance a lot, we can still change it.
No Issue, you can share me the test cases, I will take the performance report.
Thanks and Regards,
Kumar Rajeev Rastogi
| From: | Magnus Hagander <magnus(at)hagander(dot)net> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 09:14:50 |
| Message-ID: | CABUevEz042juVie6CbBjRen-b09L2sZ7Ac4NuOJvHDA_L9VNXw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 29, 2014 at 9:03 AM, KONDO Mitsumasa <
kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
> (2014/01/29 15:51), Tom Lane wrote:
> > KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> writes:
> >> By the way, latest pg_stat_statement might affect performance in
> Windows system.
> >> Because it uses fflush() system call every creating new entry in
> >> pg_stat_statements, and it calls many fread() to warm file cache.
> > This statement doesn't seem to have much to do with the patch as
> > committed. There are no fflush calls, and no notion of warming the
> > file cache either.
> Oh, all right.
>
> > We do assume that the OS is smart enough to keep
> > a frequently-read file in cache ... is Windows too stupid for that?
> I don't know about it. But I think Windows cache feature is stupid.
> It seems to always write/read data to/from disk, nevertheless having large
> memory...
> I'd like to know test result on Windows, if we can...
>
>
I am quite certain the Windows cache is *not* that stupid, and hasn't been
since the Windows 3.1 days.
If you want to make certain, set FILE_ATTRIBUTE_TEMPORARY when the file is
opened, then it will work really hard not to write it to disk - harder than
most Linux fs'es do AFAIK. This should of course only be done if we don't
mind it going away :)
As per port/open.c, pg will set this when O_SHORT_LIVED is specified. But
AFAICT, we don't actually use this *anywhere* in the backend? Perhaps we
should for this - and also for the pgstat files?
(I may have missed a codepath, only had a minute to do some greping)
--
Magnus Hagander
Me: http://www.hagander.net/
Work: http://www.redpill-linpro.com/
| From: | Magnus Hagander <magnus(at)hagander(dot)net> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 09:16:54 |
| Message-ID: | CABUevEyqazbhco5MZsCdL256qMC-KjXj6y4uVBniqBmYYV09RQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 29, 2014 at 8:58 AM, Peter Geoghegan <pg(at)heroku(dot)com> wrote:
> I am not opposed in principle to adding new things to the counters
> struct in pg_stat_statements. I just think that the fact that the
> overhead of installing the module on a busy production system is
> currently so low is of *major* value, and therefore any person that
> proposes to expand that struct should be required to very conclusively
> demonstrate that there is no appreciably increase in overhead. Having
> a standard deviation column would be nice, but it's still not that
> important. Maybe when we have portable atomic addition we can afford
> to be much more inclusive of that kind of thing.
>
Not (at this point) commenting on the details, but a big +1 on the fact
that the overhead is low is a *very* important property. If the overhead
starts growing it will be uninstalled - and that will make things even
harder to diagnose.
--
Magnus Hagander
Me: http://www.hagander.net/
Work: http://www.redpill-linpro.com/
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Magnus Hagander <magnus(at)hagander(dot)net> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 12:55:44 |
| Message-ID: | CA+U5nM+=hKp2Epgjp4cJWZtW_NV6REOk+zN21z+zXpB2_GwcBg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 29 January 2014 09:16, Magnus Hagander <magnus(at)hagander(dot)net> wrote:
> On Wed, Jan 29, 2014 at 8:58 AM, Peter Geoghegan <pg(at)heroku(dot)com> wrote:
>>
>> I am not opposed in principle to adding new things to the counters
>> struct in pg_stat_statements. I just think that the fact that the
>> overhead of installing the module on a busy production system is
>> currently so low is of *major* value, and therefore any person that
>> proposes to expand that struct should be required to very conclusively
>> demonstrate that there is no appreciably increase in overhead. Having
>> a standard deviation column would be nice, but it's still not that
>> important. Maybe when we have portable atomic addition we can afford
>> to be much more inclusive of that kind of thing.
>
>
> Not (at this point) commenting on the details, but a big +1 on the fact that
> the overhead is low is a *very* important property. If the overhead starts
> growing it will be uninstalled - and that will make things even harder to
> diagnose.
+1 also. I think almost everybody agrees.
Having said that, I'm not certain that moves us forwards with how to
handle the patch at hand. Here is my attempt at an objective view of
whether or not to apply the patch:
The purpose of the patch is to provide additional help to diagnose
performance issues. Everybody seems to want this as an additional
feature, given the above caveat. The author has addressed the original
performance concerns there and provided some evidence to show that
appears effective.
It is possible that adding this extra straw breaks the camel's back,
but it seems unlikely to be that simple. A new feature to help
performance problems will be of a great use to many people; complaints
about the performance of pg_stat_statements are unlikely to increase
greatly from this change, since such changes would only affect those
right on the threshold of impact. The needs of the many...
Further changes to improve scalability of pg_stat_statements seem
warranted in the future, but I see no reason to block the patch for
that reason.
If somebody has some specific evidence that the impact outweighs the
benefit, please produce it or I am inclined to proceed to commit.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 14:06:43 |
| Message-ID: | 52E90AF3.8010904@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/29/2014 02:58 AM, Peter Geoghegan wrote:
>
> I am not opposed in principle to adding new things to the counters
> struct in pg_stat_statements. I just think that the fact that the
> overhead of installing the module on a busy production system is
> currently so low is of *major* value, and therefore any person that
> proposes to expand that struct should be required to very conclusively
> demonstrate that there is no appreciably increase in overhead. Having
> a standard deviation column would be nice, but it's still not that
> important. Maybe when we have portable atomic addition we can afford
> to be much more inclusive of that kind of thing.
>
Importance is in the eye of the beholder. As far as I'm concerned, min
and max are of FAR less value than stddev. If stddev gets left out I'm
going to be pretty darned annoyed, especially since the benchmarks seem
to show the marginal cost as being virtually unmeasurable. If those
aren't enough for you, perhaps you'd like to state what sort of tests
would satisfy you.
cheers
andrew
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 19:09:52 |
| Message-ID: | 52E95200.4060203@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/29/2014 04:55 AM, Simon Riggs wrote:
> It is possible that adding this extra straw breaks the camel's back,
> but it seems unlikely to be that simple. A new feature to help
> performance problems will be of a great use to many people; complaints
> about the performance of pg_stat_statements are unlikely to increase
> greatly from this change, since such changes would only affect those
> right on the threshold of impact. The needs of the many...
>
> Further changes to improve scalability of pg_stat_statements seem
> warranted in the future, but I see no reason to block the patch for
> that reason
If we're talking here about min, max and stddev, then +1. The stats
we've seen so far seem to indicate that any affect on query response
time is within the margin of error for pgbench.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 19:54:49 |
| Message-ID: | CA+TgmoYOG-aJUPBWPxzMuHEEW+RbHgL0zJzNT7mh06hk43eopw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 29, 2014 at 9:06 AM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
>> I am not opposed in principle to adding new things to the counters
>> struct in pg_stat_statements. I just think that the fact that the
>> overhead of installing the module on a busy production system is
>> currently so low is of *major* value, and therefore any person that
>> proposes to expand that struct should be required to very conclusively
>> demonstrate that there is no appreciably increase in overhead. Having
>> a standard deviation column would be nice, but it's still not that
>> important. Maybe when we have portable atomic addition we can afford
>> to be much more inclusive of that kind of thing.
>>
>
> Importance is in the eye of the beholder. As far as I'm concerned, min and
> max are of FAR less value than stddev. If stddev gets left out I'm going to
> be pretty darned annoyed, especially since the benchmarks seem to show the
> marginal cost as being virtually unmeasurable. If those aren't enough for
> you, perhaps you'd like to state what sort of tests would satisfy you.
I agree. I find it somewhat unlikely that pg_stat_statements is
fragile enough that these few extra counters are going to make much of
a difference. At the same time, I find min and max a dubious value
proposition. It seems highly likely to me that stddev will pay its
way, but I'm much less certain about the others.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 20:07:47 |
| Message-ID: | 52E95F93.70407@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/29/2014 11:54 AM, Robert Haas wrote:
> I agree. I find it somewhat unlikely that pg_stat_statements is
> fragile enough that these few extra counters are going to make much of
> a difference. At the same time, I find min and max a dubious value
> proposition. It seems highly likely to me that stddev will pay its
> way, but I'm much less certain about the others.
What I really want is percentiles, but I'm pretty sure we already shot
that down. ;-)
I could use min/max -- think of performance test runs. However, I agree
that they're less valuable than stddev.
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 21:14:02 |
| Message-ID: | CAM3SWZQzZxMgLDOGQxTH+YMrwLo9bC96=gfvuMV3an5M7zwZNg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 29, 2014 at 6:06 AM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
> mportance is in the eye of the beholder. As far as I'm concerned, min and
> max are of FAR less value than stddev. If stddev gets left out I'm going to
> be pretty darned annoyed, especially since the benchmarks seem to show the
> marginal cost as being virtually unmeasurable. If those aren't enough for
> you, perhaps you'd like to state what sort of tests would satisfy you.
I certainly agree that stddev is far more valuable than min and max.
I'd be inclined to not accept the latter on the grounds that they
aren't that useful.
So, am I correct in my understanding: The benchmark performed here [1]
was of a standard pgbench SELECT workload, with no other factor
influencing the general overhead (unlike the later test that queried
pg_stat_statements as well)? I'd prefer to have seen the impact on a
32 core system, where spinlock contention would naturally be more
likely to appear, but even still I'm duly satisfied.
There was no testing of the performance impact prior to 6 days ago,
and I'm surprised it took Mitsumasa that long to come up with
something like this, since I raised this concern about 3 months ago.
[1] http://www.postgresql.org/message-id/52E10E6A.5060708@lab.ntt.co.jp
--
Peter Geoghegan
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 21:32:30 |
| Message-ID: | 52E9736E.8010500@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/29/2014 04:14 PM, Peter Geoghegan wrote:
> On Wed, Jan 29, 2014 at 6:06 AM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
>> mportance is in the eye of the beholder. As far as I'm concerned, min and
>> max are of FAR less value than stddev. If stddev gets left out I'm going to
>> be pretty darned annoyed, especially since the benchmarks seem to show the
>> marginal cost as being virtually unmeasurable. If those aren't enough for
>> you, perhaps you'd like to state what sort of tests would satisfy you.
> I certainly agree that stddev is far more valuable than min and max.
> I'd be inclined to not accept the latter on the grounds that they
> aren't that useful.
>
> So, am I correct in my understanding: The benchmark performed here [1]
> was of a standard pgbench SELECT workload, with no other factor
> influencing the general overhead (unlike the later test that queried
> pg_stat_statements as well)? I'd prefer to have seen the impact on a
> 32 core system, where spinlock contention would naturally be more
> likely to appear, but even still I'm duly satisfied.
I could live with just stddev. Not sure others would be so happy.
Glad we're good on the performance impact front.
cheers
andrew
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-29 23:29:58 |
| Message-ID: | 10176.1391038198@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
> I could live with just stddev. Not sure others would be so happy.
FWIW, I'd vote for just stddev, on the basis that min/max appear to add
more to the counter update time than stddev does; you've got
this:
+ e->counters.total_sqtime += total_time * total_time;
versus this:
+ if (e->counters.min_time > total_time || e->counters.min_time == EXEC_TIME_INIT)
+ e->counters.min_time = total_time;
+ if (e->counters.max_time < total_time)
+ e->counters.max_time = total_time;
I think on most modern machines, a float multiply-and-add is pretty
darn cheap; a branch that might or might not be taken, OTOH, is a
performance bottleneck.
Similarly, the shared memory footprint hit is more: two new doubles
for min/max versus one for total_sqtime (assuming we're happy with
the naive stddev calculation).
If we felt that min/max were of similar value to stddev then this
would be mere nitpicking. But since people seem to agree they're
worth less, I'm thinking the cost/benefit ratio isn't there.
regards, tom lane
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 04:48:10 |
| Message-ID: | 52E9D98A.4000007@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/29 16:58), Peter Geoghegan wrote:
> On Tue, Jan 28, 2014 at 10:51 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> writes:
>>> By the way, latest pg_stat_statement might affect performance in Windows system.
>>> Because it uses fflush() system call every creating new entry in
>>> pg_stat_statements, and it calls many fread() to warm file cache.
>>
>> This statement doesn't seem to have much to do with the patch as
>> committed.
>
> You could make a strong case for the patch improving performance in
> practice for many users, by allowing us to increase the
> pg_stat_statements.max default value to 5,000, 5 times the previous
> value. The real expense of creating a new entry is the exclusive
> locking of the hash table, which blocks *everything* in
> pg_stat_statements. That isn't expanded at all, since queries are only
> written with a shared lock, which only blocks the creation of new
> entries which was already relatively expensive. In particular, it does
> not block the maintenance of costs for all already observed entries in
> the hash table. It's obvious that simply reducing the pressure on the
> cache will improve matters a lot, which for many users the external
> texts patch does.
>
> Since Mitsumasa has compared that patch and at least one of his
> proposed pg_stat_statements patches on several occasions, I will
> re-iterate the difference: any increased overhead from the external
> texts patch is paid only when a query is first entered into the hash
> table. Then, there is obviously and self-evidently no additional
> overhead from contention for any future execution of the same query,
> no matter what, indefinitely (the exclusive locking section of
> creating a new entry does not do I/O, except in fantastically unlikely
> circumstances). So for many of the busy production systems I work
> with, that's the difference between a cost paid perhaps tens of
> thousands of times a second, and a cost paid every few days or weeks.
> Even if he is right about a write() taking an unreasonably large
> amount of time on Windows, the consequences felt as pg_stat_statements
> LWLock contention would be very limited.
>
> I am not opposed in principle to adding new things to the counters
> struct in pg_stat_statements. I just think that the fact that the
> overhead of installing the module on a busy production system is
> currently so low is of *major* value, and therefore any person that
> proposes to expand that struct should be required to very conclusively
> demonstrate that there is no appreciably increase in overhead. Having
> a standard deviation column would be nice, but it's still not that
> important. Maybe when we have portable atomic addition we can afford
> to be much more inclusive of that kind of thing.
I'd like to know the truth and the fact in your patch, rather than your argument:-)
So I create detail pg_stat_statements benchmark tool using pgbench.
This tool can create 10000 pattern unique sqls in a file, and it is only
for measuring pg_stat_statements performance. Because it only updates
pg_stat_statements data and doesn't write to disk at all. It's fair benchmark.
[usage]
perl create_sql.pl >file.sql
psql -h -h xxx.xxx.xxx.xxx mitsu-ko -c 'SELECT pg_stat_statements_reset()'
pgbench -h xxx.xxx.xxx.xxx mitsu-ko -c64 -j32 -n -T 180 -f file.sql
[part of sample sqls file, they are executed in pgbench]
SELECT
1-1/9+5*8*6+5+9-6-3-4/9%7-2%7/5-9/7+2+9/7-1%5%9/3-4/4-9/1+5+5/6/5%2+1*2*3-8/8+5-3-8-4/8+5%2*2-2-5%6+4
SELECT
1%9%7-8/5%6-1%2*2-7+9*6-2*6-9+1-2*9+6+7*8-4-2*1%3/7-1%4%9+4+7/5+4/2-3-5%8/3/7*6-1%8*6*1/7/2%5*6/2-3-9
SELECT
1%3*2/8%6%5-3%1+1/6*6*5/9-2*5+6/6*5-1/2-6%4%8/7%2*7%5%9%5/9%1%1-3-9/2*1+1*6%8/2*4/1+6*7*1+5%6+9*1-9*6
...
I test some methods that include old pgss, old pgss with my patch, and new pgss.
Test server and postgresql.conf are same in I tested last day in this ML-thread.
And test methods and test results are here,
[methods]
method 1: with old pgss, pg_stat_statements.max=1000(default)
method 2: with old pgss with my patch, pg_stat_statements.max=1000(default)
peter 1 : with new pgss(Peter's patch), pg_stat_statements.max=5000(default)
peter 2 : with new pgss(Peter's patch), pg_stat_statements.max=1000
[for reference]
method 5:with old pgss, pg_stat_statements.max=5000
method 6:with old pgss with my patch, pg_stat_statements.max=5000
[results]
method | try1 | try2 | try3 | degrade performance ratio
-----------------------------------------------------------------
method 1 | 6.546 | 6.558 | 6.638 | 0% (reference score)
method 2 | 6.527 | 6.556 | 6.574 | 1%
peter 1 | 5.204 | 5.203 | 5.216 |20%
peter 2 | 4.241 | 4.236 | 4.262 |35%
method 5 | 5.931 | 5.848 | 5.872 |11%
method 6 | 5.794 | 5.792 | 5.776 |12%
New pgss is extremely degrade performance than old pgss, and I cannot see
performance scaling.
I understand that his argument was "My patch reduces time of LWLock in
pg_stat_statements,
it is good for performance. However, Kondo's patch will be degrade performance in
pg_stat_statements. so I give it -1.". But unless seeing this test results, his
claim seems
to contradict it even in Linux OS.
I think that his patch's strong point is only storing long query, at the sacrifice of
significant performance. Does it hope in community? At least, I don't hope it.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| create_sql.pl | text/plain | 404 bytes |
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 04:48:47 |
| Message-ID: | 52E9D9AF.2060209@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/29 17:31), Rajeev rastogi wrote:
> On 28th January, Mitsumasa KONDO wrote:
>> By the way, latest pg_stat_statement might affect performance in
>> Windows system.
>> Because it uses fflush() system call every creating new entry in
>> pg_stat_statements, and it calls many fread() to warm file cache. It
>> works well in Linux system, but I'm not sure in Windows system. If you
>> have time, could you test it on your Windows system? If it affects
>> perfomance a lot, we can still change it.
>
>
> No Issue, you can share me the test cases, I will take the performance report.
Thank you for your kind!
I posted another opinion in his patch. So please wait for a while, for not waste
your test time.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 10:21:12 |
| Message-ID: | 52EA2798.60603@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/01/30 8:29), Tom Lane wrote:
> Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
>> I could live with just stddev. Not sure others would be so happy.
>
> FWIW, I'd vote for just stddev, on the basis that min/max appear to add
> more to the counter update time than stddev does; you've got
> this:
>
> + e->counters.total_sqtime += total_time * total_time;
>
> versus this:
>
> + if (e->counters.min_time > total_time || e->counters.min_time == EXEC_TIME_INIT)
> + e->counters.min_time = total_time;
> + if (e->counters.max_time < total_time)
> + e->counters.max_time = total_time;
>
> I think on most modern machines, a float multiply-and-add is pretty
> darn cheap; a branch that might or might not be taken, OTOH, is a
> performance bottleneck.
>
> Similarly, the shared memory footprint hit is more: two new doubles
> for min/max versus one for total_sqtime (assuming we're happy with
> the naive stddev calculation).
>
> If we felt that min/max were of similar value to stddev then this
> would be mere nitpicking. But since people seem to agree they're
> worth less, I'm thinking the cost/benefit ratio isn't there.
Why do you surplus worried about cost in my patch? Were three double variables
assumed a lot of memory, or having lot of calculating cost? My test result
showed LWlock bottele-neck is urban legend. If you have more fair test
pattern, please tell me, I'll do it if the community will do fair judge.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 10:25:18 |
| Message-ID: | CAM3SWZR1C7GH0ym+JpfjarRDvkbDagOfq0COBRfn+Ar7WoHDrg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 29, 2014 at 8:48 PM, KONDO Mitsumasa
<kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
> I'd like to know the truth and the fact in your patch, rather than your
> argument:-)
I see.
> [part of sample sqls file, they are executed in pgbench]
> SELECT
> 1-1/9+5*8*6+5+9-6-3-4/9%7-2%7/5-9/7+2+9/7-1%5%9/3-4/4-9/1+5+5/6/5%2+1*2*3-8/8+5-3-8-4/8+5%2*2-2-5%6+4
> SELECT
> 1%9%7-8/5%6-1%2*2-7+9*6-2*6-9+1-2*9+6+7*8-4-2*1%3/7-1%4%9+4+7/5+4/2-3-5%8/3/7*6-1%8*6*1/7/2%5*6/2-3-9
> SELECT
> 1%3*2/8%6%5-3%1+1/6*6*5/9-2*5+6/6*5-1/2-6%4%8/7%2*7%5%9%5/9%1%1-3-9/2*1+1*6%8/2*4/1+6*7*1+5%6+9*1-9*6
> [methods]
> method 1: with old pgss, pg_stat_statements.max=1000(default)
> method 2: with old pgss with my patch, pg_stat_statements.max=1000(default)
> peter 1 : with new pgss(Peter's patch), pg_stat_statements.max=5000(default)
> peter 2 : with new pgss(Peter's patch), pg_stat_statements.max=1000
>
> [for reference]
> method 5:with old pgss, pg_stat_statements.max=5000
> method 6:with old pgss with my patch, pg_stat_statements.max=5000
>
> [results]
> method | try1 | try2 | try3 | degrade performance ratio
> -----------------------------------------------------------------
> method 1 | 6.546 | 6.558 | 6.638 | 0% (reference score)
> method 2 | 6.527 | 6.556 | 6.574 | 1%
> peter 1 | 5.204 | 5.203 | 5.216 |20%
> peter 2 | 4.241 | 4.236 | 4.262 |35%
>
> method 5 | 5.931 | 5.848 | 5.872 |11%
> method 6 | 5.794 | 5.792 | 5.776 |12%
So, if we compare the old pg_stat_statements and old default with the
new pg_stat_statements and the new default (why not? The latter still
uses less shared memory than the former), by the standard of this
benchmark there is a regression of about 20%. But you also note that
there is an 11% "regression" in the old pg_stat_statements against
*itself* when used with a higher pg_stat_statements.max setting of
5,000. This is completely contrary to everyone's prior understanding
that increasing the size of the hash table had a very *positive*
effect on performance by relieving cache pressure and thereby causing
less exclusive locking for an entry_dealloc().
Do you suppose that this very surprising result might just be because
this isn't a very representative benchmark? Nothing ever has the
benefit of *not* having to exclusive lock.
--
Peter Geoghegan
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 15:51:27 |
| Message-ID: | 32304.1391097087@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> writes:
> (2014/01/30 8:29), Tom Lane wrote:
>> If we felt that min/max were of similar value to stddev then this
>> would be mere nitpicking. But since people seem to agree they're
>> worth less, I'm thinking the cost/benefit ratio isn't there.
> Why do you surplus worried about cost in my patch? Were three double variables
> assumed a lot of memory, or having lot of calculating cost? My test result
> showed LWlock bottele-neck is urban legend. If you have more fair test
> pattern, please tell me, I'll do it if the community will do fair judge.
[ shrug... ] Standard pgbench tests are useless for measuring microscopic
issues like this one; whatever incremental cost is there will be swamped
by client communication and parse/plan overhead. You may have proven that
the overhead isn't 10% of round-trip query time, but we knew that without
testing.
If I were trying to measure the costs of these changes, I'd use short
statements executed inside loops in a plpgsql function. And I'd
definitely do it on a machine with quite a few cores (and a running
session on each one), so that spinlock contention might conceivably
happen often enough to be measurable.
If that still says that the runtime cost is down in the noise, we
could then proceed to debate whether min/max are worth a 10% increase
in the size of the shared pgss hash table. Because by my count,
that's about what two more doubles would be, now that we removed the
query texts from the hash table --- a table entry is currently 21
doublewords (at least on 64-bit machines) and we're debating increasing
it to 22 or 24.
regards, tom lane
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 16:50:47 |
| Message-ID: | 1203.1391100647@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Peter Geoghegan <pg(at)heroku(dot)com> writes:
> On Wed, Jan 29, 2014 at 8:48 PM, KONDO Mitsumasa
> <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> wrote:
>> method | try1 | try2 | try3 | degrade performance ratio
>> -----------------------------------------------------------------
>> method 1 | 6.546 | 6.558 | 6.638 | 0% (reference score)
>> method 2 | 6.527 | 6.556 | 6.574 | 1%
>> peter 1 | 5.204 | 5.203 | 5.216 |20%
>> peter 2 | 4.241 | 4.236 | 4.262 |35%
>>
>> method 5 | 5.931 | 5.848 | 5.872 |11%
>> method 6 | 5.794 | 5.792 | 5.776 |12%
> So, if we compare the old pg_stat_statements and old default with the
> new pg_stat_statements and the new default (why not? The latter still
> uses less shared memory than the former), by the standard of this
> benchmark there is a regression of about 20%. But you also note that
> there is an 11% "regression" in the old pg_stat_statements against
> *itself* when used with a higher pg_stat_statements.max setting of
> 5,000. This is completely contrary to everyone's prior understanding
> that increasing the size of the hash table had a very *positive*
> effect on performance by relieving cache pressure and thereby causing
> less exclusive locking for an entry_dealloc().
> Do you suppose that this very surprising result might just be because
> this isn't a very representative benchmark? Nothing ever has the
> benefit of *not* having to exclusive lock.
If I understand this test scenario properly, there are no duplicate
queries, so that each iteration creates a new hashtable entry (possibly
evicting an old one). And it's a single-threaded test, so that there
can be no benefit from reduced locking.
I don't find the results particularly surprising given that. We knew
going in that the external-texts patch would slow down creation of a new
hashtable entry: there's no way that writing a query text to a file isn't
slower than memcpy'ing it into shared memory. The performance argument
for doing it anyway is that by greatly reducing the size of hashtable
entries, it becomes more feasible to size the hashtable large enough so
that it's seldom necessary to evict hashtable entries. It's always going
to be possible to make the patch look bad by testing cases where no
savings in hashtable evictions is possible; which is exactly what this
test case does. But I don't think that's relevant to real-world usage.
pg_stat_statements isn't going to be useful unless there's a great deal of
repeated statement execution, so what we should be worrying about is the
case where a table entry exists not the case where it doesn't. At the
very least, test cases where there are *no* repeats are not representative
of cases people would be using pg_stat_statements with.
As for the measured slowdown with larger hashtable size (but still smaller
than the number of distinct queries in the test), my money is on the
larger table not fitting in L3 cache or something like that.
regards, tom lane
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 17:23:41 |
| Message-ID: | 1959.1391102621@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I wrote:
> If I understand this test scenario properly, there are no duplicate
> queries, so that each iteration creates a new hashtable entry (possibly
> evicting an old one). And it's a single-threaded test, so that there
> can be no benefit from reduced locking.
After looking more closely, it's *not* single-threaded, but each pgbench
thread is running through the same sequence of 10000 randomly generated
SQL statements. So everything depends on how nearly those clients stay
in step. I bet they'd stay pretty nearly in step, though --- any process
lagging behind would find all the hashtable entries already created, and
thus be able to catch up relative to the ones in the lead which are being
slowed by having to write out their query texts. So it seems fairly
likely that this scenario is greatly stressing the case where multiple
processes redundantly create the same hashtable entry. In any case,
while the same table entry does get touched once-per-client over a short
interval, there's no long-term reuse of table entries. So I still say
this isn't at all representative of real-world use of pg_stat_statements.
regards, tom lane
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 17:28:47 |
| Message-ID: | CA+TgmoZTmAjGu3mBY8c9Dy6QeH15OWDf4m0MyD0-1=9J+UBFzQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Jan 30, 2014 at 12:23 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> I wrote:
>> If I understand this test scenario properly, there are no duplicate
>> queries, so that each iteration creates a new hashtable entry (possibly
>> evicting an old one). And it's a single-threaded test, so that there
>> can be no benefit from reduced locking.
>
> After looking more closely, it's *not* single-threaded, but each pgbench
> thread is running through the same sequence of 10000 randomly generated
> SQL statements. So everything depends on how nearly those clients stay
> in step. I bet they'd stay pretty nearly in step, though --- any process
> lagging behind would find all the hashtable entries already created, and
> thus be able to catch up relative to the ones in the lead which are being
> slowed by having to write out their query texts. So it seems fairly
> likely that this scenario is greatly stressing the case where multiple
> processes redundantly create the same hashtable entry. In any case,
> while the same table entry does get touched once-per-client over a short
> interval, there's no long-term reuse of table entries. So I still say
> this isn't at all representative of real-world use of pg_stat_statements.
One could test it with each pgbench thread starting at a random point
in the same sequence and wrapping at the end.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Peter Geoghegan <pg(at)heroku(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 17:42:06 |
| Message-ID: | 2412.1391103726@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> One could test it with each pgbench thread starting at a random point
> in the same sequence and wrapping at the end.
Well, the real point is that 10000 distinct statements all occurring with
exactly the same frequency isn't a realistic scenario: any hashtable size
less than 10000 necessarily sucks, any size >= 10000 is perfect.
I'd think that what you want to test is a long-tailed frequency
distribution (probably a 1/N type of law) where a small number of
statements account for most of the hits and there are progressively fewer
uses of less common statements. What would then be interesting is how
does the performance change as the hashtable size is varied to cover more
or less of that distribution.
regards, tom lane
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 17:57:37 |
| Message-ID: | 2802.1391104657@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
BTW ... it occurs to me to wonder if it'd be feasible to keep the
query-texts file mmap'd in each backend, thereby reducing the overhead
to write a new text to about the cost of a memcpy, and eliminating the
read cost in pg_stat_statements() altogether. It's most likely not worth
the trouble; but if a more-realistic benchmark test shows that we actually
have a performance issue there, that might be a way out without giving up
the functional advantages of Peter's patch.
regards, tom lane
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 19:28:02 |
| Message-ID: | CAM3SWZSkom7mGbL4XE_pm+iguNB162M3jdfe8VyGXtWkvcrzCA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Jan 30, 2014 at 9:57 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> BTW ... it occurs to me to wonder if it'd be feasible to keep the
> query-texts file mmap'd in each backend, thereby reducing the overhead
> to write a new text to about the cost of a memcpy, and eliminating the
> read cost in pg_stat_statements() altogether. It's most likely not worth
> the trouble; but if a more-realistic benchmark test shows that we actually
> have a performance issue there, that might be a way out without giving up
> the functional advantages of Peter's patch.
There could be a worst case for that scheme too, plus we'd have to
figure out how to make in work with windows, which in the case of
mmap() is not a sunk cost AFAIK. I'm skeptical of the benefit of
pursuing that.
I'm totally unimpressed with the benchmark as things stand. It relies
on keeping 64 clients in perfect lockstep as each executes 10,000
queries that are each unique snowflakes. Though even though they're
unique snowflakes, and even though there are 10,000 of them, everyone
executes the same one at exactly the same time relative to each other,
in exactly the same order as quickly as possible. Even still, the
headline "reference score" of -35% is completely misleading, because
it isn't comparing like with like in terms of has table size. This
benchmark incidentally recommends that we reduce the default hash
table size to improve performance when the hash table is under
pressure, which is ludicrous. It's completely backwards. You could
also use the benchmark to demonstrate that the overhead of calling
pg_stat_statements() is ridiculously high, since like creating a new
query text, that only requires a shared lock too.
This is an implausibly bad worst case for larger hash table sizes in
pg_stat_statements generally. 5,000 entries is enough for the large
majority of applications. But for those that hit that limit, in
practice they're still going to find the vast majority of queries
already in the table as they're executed. If they don't, they can
double or triple their "max" setting, because the shared memory
overhead is so low. No one has any additional overhead once their
query is in the hash table already. In reality, actual applications
could hardly be further from the perfectly uniform distribution of
distinct queries presented here.
--
Peter Geoghegan
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 20:32:49 |
| Message-ID: | 18340.1391113969@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Peter Geoghegan <pg(at)heroku(dot)com> writes:
> On Thu, Jan 30, 2014 at 9:57 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> BTW ... it occurs to me to wonder if it'd be feasible to keep the
>> query-texts file mmap'd in each backend, thereby reducing the overhead
>> to write a new text to about the cost of a memcpy, and eliminating the
>> read cost in pg_stat_statements() altogether. It's most likely not worth
>> the trouble; but if a more-realistic benchmark test shows that we actually
>> have a performance issue there, that might be a way out without giving up
>> the functional advantages of Peter's patch.
> There could be a worst case for that scheme too, plus we'd have to
> figure out how to make in work with windows, which in the case of
> mmap() is not a sunk cost AFAIK. I'm skeptical of the benefit of
> pursuing that.
Well, it'd be something like #ifdef HAVE_MMAP then use mmap, else
use what's there today. But I agree that it's not something to pursue
unless we see a more credible demonstration of a problem. Presumably
any such code would have to be prepared to remap if the file grows
larger than it initially allowed for; and that would be complicated
and perhaps have unwanted failure modes.
> In reality, actual applications
> could hardly be further from the perfectly uniform distribution of
> distinct queries presented here.
Yeah, I made the same point in different words. I think any realistic
comparison of this code to what we had before needs to measure a workload
with a more plausible query frequency distribution.
regards, tom lane
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-30 21:22:29 |
| Message-ID: | CAM3SWZSEa0Mhq1YYdCcG3Grz3-=xAOddRB+ixB86AywuzpW=SA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Jan 30, 2014 at 12:32 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> In reality, actual applications
>> could hardly be further from the perfectly uniform distribution of
>> distinct queries presented here.
>
> Yeah, I made the same point in different words. I think any realistic
> comparison of this code to what we had before needs to measure a workload
> with a more plausible query frequency distribution.
Even though that distribution just doesn't square with anybody's
reality, you can still increase the pg_stat_statements.max setting to
10k and the problem goes away at little cost (a lower setting is
better, but a setting high enough to cache everything is best). But
you're not going to have terribly much use for pg_stat_statements
anyway....if you really do experience churn at that rate with 5,000
possible entries, the module is ipso facto useless, and should be
disabled.
--
Peter Geoghegan
| From: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-31 13:07:59 |
| Message-ID: | CADupcHUKHUua4Tbqi6QcAjsDrns4V6b2cw3HAepgwvB1o4e1JQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2014-01-31 Peter Geoghegan <pg(at)heroku(dot)com>
> On Thu, Jan 30, 2014 at 12:32 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> >> In reality, actual applications
> >> could hardly be further from the perfectly uniform distribution of
> >> distinct queries presented here.
> >
> > Yeah, I made the same point in different words. I think any realistic
> > comparison of this code to what we had before needs to measure a workload
> > with a more plausible query frequency distribution.
>
> Even though that distribution just doesn't square with anybody's
> reality, you can still increase the pg_stat_statements.max setting to
> 10k and the problem goes away at little cost (a lower setting is
> better, but a setting high enough to cache everything is best). But
> you're not going to have terribly much use for pg_stat_statements
> anyway....if you really do experience churn at that rate with 5,000
> possible entries, the module is ipso facto useless, and should be
> disabled.
I run extra test your and my patch with the pg_stat_statements.max
setting=10k
in other same setting and servers. They are faster than past results.
method | try1 | try2 | try3
--------------------------------------------
peter 3 | 6.769 | 6.784 | 6.785
method 5 | 6.770 | 6.774 | 6.761
I think that most significant overhead in pg_stat_statements is deleting
and inserting cost in hash table update, and not at LWLocks. If LWLock
is the most overhead, we can see the overhead -S pgbench, because it have
one select pet tern which are most Lock conflict case. But we can't see
such result.
I'm not sure about dynahash.c, but we can see hash conflict case in this
code.
IMHO, I think It might heavy because it have to run list search and compare
one
until not conflict it.
And past result shows that your patch's most weak point is that deleting
most old statement
and inserting new old statement cost is very high, as you know. It
accelerate to affect
update(delete and insert) cost in pg_stat_statements table. So you proposed
new setting
10k in default max value. But it is not essential solution, because it is
also good perfomance
for old pg_stat_statements. And when we set max=10K in your patch and want
to get most
used only 1000 queries in pg_stat_statements, we have to use order-by-query
with limit 1000.
Sort cost is relatively high, so monitoring query will be slow and high
cost. But old one is only set
pg_stat_statements.max=1000, and performance is not relatively bad. It will
be best settings for getting
most used 1000 queries infomation.
That' all my assumption.
Sorry for a few extra test, I had no time in my office today.
If we hope, I can run 1/N distribution pgbench test next week, I modify my
perl script little bit,
for creating multiple sql files with various sleep time.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-31 19:11:23 |
| Message-ID: | CAM3SWZTDsnP3y1YfF7QaW1BwyBxVPdxuxMV6OdjNFwaz3gUCMw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Jan 31, 2014 at 5:07 AM, Mitsumasa KONDO
<kondo(dot)mitsumasa(at)gmail(dot)com> wrote:
> And past result shows that your patch's most weak point is that deleting
> most old statement
> and inserting new old statement cost is very high, as you know.
No, there is no reason to imagine that entry_dealloc() is any slower,
really. There will perhaps be some additional contention with shared
lockers, but that isn't likely to be a major aspect. When the hash
table is full, in reality at that point it's very unlikely that there
will be two simultaneous sessions that need to create a new entry. As
I said, on many of the systems I work with it takes weeks to see a new
entry. This will be especially true now that the *.max default is
5,000.
> It accelerate to affect
> update(delete and insert) cost in pg_stat_statements table. So you proposed
> new setting
> 10k in default max value. But it is not essential solution, because it is
> also good perfomance
> for old pg_stat_statements.
I was merely pointing out that that would totally change the outcome
of your very artificial test-case. Decreasing the number of statements
to 5,000 would too. I don't think we should assign much weight to any
test case where the large majority or all statistics are wrong
afterwards, due to there being so much churn.
--
Peter Geoghegan
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-01-31 21:00:13 |
| Message-ID: | 21566.1391202013@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Peter Geoghegan <pg(at)heroku(dot)com> writes:
> On Fri, Jan 31, 2014 at 5:07 AM, Mitsumasa KONDO
> <kondo(dot)mitsumasa(at)gmail(dot)com> wrote:
>> It accelerate to affect
>> update(delete and insert) cost in pg_stat_statements table. So you proposed
>> new setting
>> 10k in default max value. But it is not essential solution, because it is
>> also good perfomance
>> for old pg_stat_statements.
> I was merely pointing out that that would totally change the outcome
> of your very artificial test-case. Decreasing the number of statements
> to 5,000 would too. I don't think we should assign much weight to any
> test case where the large majority or all statistics are wrong
> afterwards, due to there being so much churn.
To expand a bit:
(1) It's really not very interesting to consider pg_stat_statement's
behavior when the table size is too small to avoid 100% turnover;
that's not a regime where the module will provide useful functionality.
(2) It's completely unfair to pretend that a given hashtable size has the
same cost in old and new code; there's more than a 7X difference in the
shared-memory space eaten per hashtable entry. That does have an impact
on whether people can set the table size large enough to avoid churn.
The theory behind this patch is that for the same shared-memory
consumption you can make the table size enough larger to move the cache
hit rate up significantly, and that that will more than compensate
performance-wise for the increased time needed to make a new table entry.
Now that theory is capable of being disproven, but an artificial example
with a flat query frequency distribution isn't an interesting test case.
We don't care about optimizing performance for such cases, because they
have nothing to do with real-world usage.
regards, tom lane
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com> |
| Cc: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-02-12 06:45:54 |
| Message-ID: | 52FB18A2.20101@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi Rajeev,
> (2014/01/29 17:31), Rajeev rastogi wrote:
>> No Issue, you can share me the test cases, I will take the performance report.
Attached patch is supported to latest pg_stat_statements. It includes min, max,
and stdev statistics. Could you run compiling test on your windows enviroments?
I think compiling error was fixed.
We had disscuttion about which is needed useful statistics in community, I think
both of statistics have storong and weak point. When we see the less(2 or 3)
executed statement, stdev will be meaningless because it cannot calculate
estimated value precisely very much, however in this situation, min and max will
be propety work well because it isn't estimated value but fact value. On the
other hand, when we see the more frequency executed statement, they will be
contrary position
statistics, stdev will be very useful statistics for estimating whole statements,
and min and max might be extremely value.
At the end of the day, these value were needed each other for more useful
statistics when we want to see several actual statments. And past my experience
showed no performance problems in this patch. So I'd like to implements all these
values in pg_stat_statements.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-exectime_v7.patch | text/x-diff | 12.4 KB |
| From: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-02-17 12:44:27 |
| Message-ID: | BF2827DCCE55594C8D7A8F7FFD3AB7713DDC260E@SZXEML508-MBX.china.huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12 February 2014 12:16, KONDO Mitsumasa Wrote:
> Hi Rajeev,
>
> > (2014/01/29 17:31), Rajeev rastogi wrote:
> >> No Issue, you can share me the test cases, I will take the
> performance report.
> Attached patch is supported to latest pg_stat_statements. It includes
> min, max, and stdev statistics. Could you run compiling test on your
> windows enviroments?
> I think compiling error was fixed.
It got compiled successfully on Windows.
Thanks and Regards,
Kumar Rajeev Rastogi
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com> |
| Cc: | Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-02-18 11:11:50 |
| Message-ID: | 53033FF6.60108@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
(2014/02/17 21:44), Rajeev rastogi wrote:
> It got compiled successfully on Windows.
Thank you for checking on Windows! It is very helpful for me.
Can we allow to add three statistics? I think only adding stdev is difficult to
image for user. But if there are min and max, we can image each statements
situations more easily. And I don't want to manage this feature in my monitoring
tool that is called pg_statsinfo. Because it is beneficial for a lot of
pg_stat_statements user and for improvement of postgres performance in the future.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-03-04 09:38:01 |
| Message-ID: | 53159EF9.10704@lab.ntt.co.jp |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi all,
I think this patch is completely forgotten, and feel very unfortunate:(
Min, max, and stdev is basic statistics in general monitoring tools,
So I'd like to push it.
(2014/02/12 15:45), KONDO Mitsumasa wrote:
>> (2014/01/29 17:31), Rajeev rastogi wrote:
>>> No Issue, you can share me the test cases, I will take the performance report.
> Attached patch is supported to latest pg_stat_statements. It includes min, max,
> and stdev statistics. Could you run compiling test on your windows enviroments?
> I think compiling error was fixed.
>
> We had disscuttion about which is needed useful statistics in community, I think
> both of statistics have storong and weak point. When we see the less(2 or 3)
> executed statement, stdev will be meaningless because it cannot calculate
> estimated value precisely very much, however in this situation, min and max will
> be propety work well because it isn't estimated value but fact value. On the
> other hand, when we see the more frequency executed statement, they will be
> contrary position
> statistics, stdev will be very useful statistics for estimating whole statements,
> and min and max might be extremely value.
> At the end of the day, these value were needed each other for more useful
> statistics when we want to see several actual statments. And past my experience
> showed no performance problems in this patch. So I'd like to implements all these
> values in pg_stat_statements.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-04-07 17:43:30 |
| Message-ID: | 20140407174330.GG5822@eldon.alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
KONDO Mitsumasa wrote:
> Hi all,
>
> I think this patch is completely forgotten, and feel very unfortunate:(
>
> Min, max, and stdev is basic statistics in general monitoring tools,
> So I'd like to push it.
I just noticed that this patch not only adds min,max,stddev, but it also
adds the ability to reset an entry's counters. This hasn't been
mentioned in this thread at all; there has been no discussion on whether
this is something we want to have, nor on whether this is the right API.
What it does is add a new function pg_stat_statements_reset_time() which
resets the min and max values from all function's entries, without
touching the stddev state variables nor the number of calls. Note
there's no ability to reset the values for a single function.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-04-07 20:19:58 |
| Message-ID: | 28799.1396901998@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
> I just noticed that this patch not only adds min,max,stddev, but it also
> adds the ability to reset an entry's counters. This hasn't been
> mentioned in this thread at all; there has been no discussion on whether
> this is something we want to have, nor on whether this is the right API.
> What it does is add a new function pg_stat_statements_reset_time() which
> resets the min and max values from all function's entries, without
> touching the stddev state variables nor the number of calls. Note
> there's no ability to reset the values for a single function.
That seems pretty bizarre. At this late date, the best thing would
probably be to strip out the undiscussed functionality. It can get
resubmitted for 9.5 if there's a real use-case for it.
regards, tom lane
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-04-08 03:59:37 |
| Message-ID: | CA+TgmoZ9JVktP0=nhBH=mui_d2UVY4vFRrMaEMV_WqR_XQYaJw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Apr 7, 2014 at 4:19 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
>> I just noticed that this patch not only adds min,max,stddev, but it also
>> adds the ability to reset an entry's counters. This hasn't been
>> mentioned in this thread at all; there has been no discussion on whether
>> this is something we want to have, nor on whether this is the right API.
>
>> What it does is add a new function pg_stat_statements_reset_time() which
>> resets the min and max values from all function's entries, without
>> touching the stddev state variables nor the number of calls. Note
>> there's no ability to reset the values for a single function.
>
> That seems pretty bizarre. At this late date, the best thing would
> probably be to strip out the undiscussed functionality. It can get
> resubmitted for 9.5 if there's a real use-case for it.
If I'm understanding correctly, that actually seems reasonably
sensible. I mean, the big problem with min/max is that you might be
taking averages and standard deviations over a period of months, but
the maximum and minimum are not that meaningful over such a long
period. You might well want to keep a longer-term average while
seeing the maximum and minimum for, say, today. I don't know exactly
how useful that is, but it doesn't seem obviously dumb.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-04-08 04:22:36 |
| Message-ID: | 10584.1396930956@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> On Mon, Apr 7, 2014 at 4:19 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
>>> What it does is add a new function pg_stat_statements_reset_time() which
>>> resets the min and max values from all function's entries, without
>>> touching the stddev state variables nor the number of calls. Note
>>> there's no ability to reset the values for a single function.
>> That seems pretty bizarre. At this late date, the best thing would
>> probably be to strip out the undiscussed functionality. It can get
>> resubmitted for 9.5 if there's a real use-case for it.
> If I'm understanding correctly, that actually seems reasonably
> sensible. I mean, the big problem with min/max is that you might be
> taking averages and standard deviations over a period of months, but
> the maximum and minimum are not that meaningful over such a long
> period. You might well want to keep a longer-term average while
> seeing the maximum and minimum for, say, today. I don't know exactly
> how useful that is, but it doesn't seem obviously dumb.
Well, maybe it's okay, but not being able to reset the stddev state seems
odd, and the chosen function name seems odder. In any case, the time to
be discussing the design of such functionality was several months ago.
I'm still for ripping it out for 9.4, rather than being stuck with
behavior that's not been adequately discussed.
regards, tom lane
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-12-21 16:05:10 |
| Message-ID: | 5496EFB6.7030205@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04/07/2014 04:19 PM, Tom Lane wrote:
> Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
>> I just noticed that this patch not only adds min,max,stddev, but it also
>> adds the ability to reset an entry's counters. This hasn't been
>> mentioned in this thread at all; there has been no discussion on whether
>> this is something we want to have, nor on whether this is the right API.
>> What it does is add a new function pg_stat_statements_reset_time() which
>> resets the min and max values from all function's entries, without
>> touching the stddev state variables nor the number of calls. Note
>> there's no ability to reset the values for a single function.
> That seems pretty bizarre. At this late date, the best thing would
> probably be to strip out the undiscussed functionality. It can get
> resubmitted for 9.5 if there's a real use-case for it.
>
This seems to have fallen through the slats completely. I'd like to
revive it for 9.5, without the extra function. If someone wants to be
able to reset stats on a finer grained basis that should probably be a
separate patch.
One thing that bothered me slightly is that the stddev calculation
appears to use a rather naive "sum of squares" method of calculation,
which is known to give ill conditioned or impossible results under some
pathological conditions: see
<http://www.johndcook.com/blog/standard_deviation> for some details. I
don't know if our results are likely to be so skewed as to produce
pathological results, but ISTM we should probably take the trouble to be
correct and use Welford's method anyway.
On my blog Peter Geoghegan mentioned something about "atomic
fetch-and-add" being useful here, but I'm not quite sure what that's
referring to. Perhaps someone can give me a pointer.
Thoughts?
cheers
andrew
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-12-21 18:23:27 |
| Message-ID: | 20141221182326.GA1768@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan wrote:
> On my blog Peter Geoghegan mentioned something about "atomic fetch-and-add"
> being useful here, but I'm not quite sure what that's referring to. Perhaps
> someone can give me a pointer.
The point, I think, is that without atomic instructions you have to hold
a lock while incrementing the counters.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-12-21 18:25:43 |
| Message-ID: | 4EEECFF9-3BCD-49E3-82DC-51DA8DCD7C44@anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On December 21, 2014 7:23:27 PM CET, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> wrote:
>Andrew Dunstan wrote:
>
>> On my blog Peter Geoghegan mentioned something about "atomic
>fetch-and-add"
>> being useful here, but I'm not quite sure what that's referring to.
>Perhaps
>> someone can give me a pointer.
>
>The point, I think, is that without atomic instructions you have to
>hold
>a lock while incrementing the counters.
Port/atomics.h provides a abstraction for doing such atomic manipulations.
Andres
---
Please excuse brevity and formatting - I am writing this on my mobile phone.
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-12-21 19:04:21 |
| Message-ID: | 549719B5.6070605@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/21/2014 01:23 PM, Alvaro Herrera wrote:
> Andrew Dunstan wrote:
>
>> On my blog Peter Geoghegan mentioned something about "atomic fetch-and-add"
>> being useful here, but I'm not quite sure what that's referring to. Perhaps
>> someone can give me a pointer.
> The point, I think, is that without atomic instructions you have to hold
> a lock while incrementing the counters.
>
Hmm, do we do that now? That won't work for the stddev method I was
referring to, although it could for the sum of squares method. In that
case I would like someone more versed in numerical analysis than me to
tell me how safe using sum of squares actually is in our case. And how
about min and max? They don't look like good candidates for atomic
operations.
cheers
andrew
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-12-21 19:12:00 |
| Message-ID: | 3276.1419189120@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
> On 12/21/2014 01:23 PM, Alvaro Herrera wrote:
>> The point, I think, is that without atomic instructions you have to hold
>> a lock while incrementing the counters.
> Hmm, do we do that now?
We already have a spinlock mutex around the counter adjustment code, so
I'm not sure why this discussion is being held.
> I would like someone more versed in numerical analysis than me to
> tell me how safe using sum of squares actually is in our case.
That, on the other hand, might be a real issue. I'm afraid that
accumulating across a very long series of statements could lead
to severe roundoff error in the reported values, unless we use
a method chosen for numerical stability.
regards, tom lane
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2014-12-21 19:50:09 |
| Message-ID: | 54972471.7080306@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/21/2014 02:12 PM, Tom Lane wrote:
> Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
>> On 12/21/2014 01:23 PM, Alvaro Herrera wrote:
>>> The point, I think, is that without atomic instructions you have to hold
>>> a lock while incrementing the counters.
>> Hmm, do we do that now?
> We already have a spinlock mutex around the counter adjustment code, so
> I'm not sure why this discussion is being held.
Because Peter suggested we might be able to use atomics. I'm a bit
dubious that we can for min and max anyway.
>
>> I would like someone more versed in numerical analysis than me to
>> tell me how safe using sum of squares actually is in our case.
> That, on the other hand, might be a real issue. I'm afraid that
> accumulating across a very long series of statements could lead
> to severe roundoff error in the reported values, unless we use
> a method chosen for numerical stability.
>
>
Right.
The next question along those lines is whether we need to keep a running
mean or whether that can safely be calculated on the fly. The code at
<http://www.johndcook.com/blog/standard_deviation/> does keep a running
mean, and maybe that's required to prevent ill conditioned results,
although I'm quite sure I see how it would. But this isn't my area of
expertise.
cheers
andrew
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-06 23:15:21 |
| Message-ID: | 54AC6C89.9060701@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/21/2014 02:50 PM, Andrew Dunstan wrote:
>
> On 12/21/2014 02:12 PM, Tom Lane wrote:
>> Andrew Dunstan <andrew(at)dunslane(dot)net> writes:
>>> On 12/21/2014 01:23 PM, Alvaro Herrera wrote:
>>>> The point, I think, is that without atomic instructions you have to
>>>> hold
>>>> a lock while incrementing the counters.
>>> Hmm, do we do that now?
>> We already have a spinlock mutex around the counter adjustment code, so
>> I'm not sure why this discussion is being held.
>
> Because Peter suggested we might be able to use atomics. I'm a bit
> dubious that we can for min and max anyway.
>
>>
>>> I would like someone more versed in numerical analysis than me to
>>> tell me how safe using sum of squares actually is in our case.
>> That, on the other hand, might be a real issue. I'm afraid that
>> accumulating across a very long series of statements could lead
>> to severe roundoff error in the reported values, unless we use
>> a method chosen for numerical stability.
>>
>>
>
>
> Right.
>
> The next question along those lines is whether we need to keep a
> running mean or whether that can safely be calculated on the fly. The
> code at <http://www.johndcook.com/blog/standard_deviation/> does keep
> a running mean, and maybe that's required to prevent ill conditioned
> results, although I'm quite sure I see how it would. But this isn't my
> area of expertise.
>
I played it safe and kept a running mean, and since it's there and
useful in itself I exposed it via the function, so there are four new
columns, min_time, max_time, mean_time and stddev_time.
I'll add this to the upcoming commitfest.
cheers
andrew
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-extrastats.patch | text/x-patch | 12.9 KB |
| From: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-20 18:26:07 |
| Message-ID: | permail-201501201826078954262000006bbe-scheffa@message-id.uni-muenster.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Interesting patch.
I did a quick review looking only into the patch file.
The "sum of variances" variable contains
the "sum of squared differences" instead, I think.
And a very minor aspect:
The term "standard deviation" in your code stands for
(corrected) sample standard deviation, I think,
because you devide by n-1 instead of n to keep the
estimator unbiased.
How about mentioning the prefix "sample"
to indicate this beiing the estimator?
And I'm sure I'm missing C specifics (again)
(or it's the reduced patch file scope),
but you introduce sqrtd, but sqrt is called?
VlG
Arne
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-20 22:30:53 |
| Message-ID: | 54BED71D.4050302@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/20/2015 01:26 PM, Arne Scheffer wrote:
> Interesting patch.
> I did a quick review looking only into the patch file.
>
> The "sum of variances" variable contains
> the "sum of squared differences" instead, I think.
Umm, no. It's not.
e->counters.sum_var_time +=
(total_time - old_mean) * (total_time - e->counters.mean_time);
This is not a square that's being added. old_mean is not the same as
e->counters.mean_time.
Since the variance is this value divided by (n - 1), AIUI, I think "sum
of variances" isn't a bad description. I'm open to alternative suggestions.
>
> And a very minor aspect:
> The term "standard deviation" in your code stands for
> (corrected) sample standard deviation, I think,
> because you devide by n-1 instead of n to keep the
> estimator unbiased.
> How about mentioning the prefix "sample"
> to indicate this beiing the estimator?
I don't understand. I'm following pretty exactly the calculations stated
at <http://www.johndcook.com/blog/standard_deviation/>
I'm not a statistician. Perhaps others who are more literate in
statistics can comment on this paragraph.
>
> And I'm sure I'm missing C specifics (again)
> (or it's the reduced patch file scope),
> but you introduce sqrtd, but sqrt is called?
Good catch. Will fix.
cheers
andrew
| From: | David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-20 23:32:17 |
| Message-ID: | 1421796737983-5834805.post@n5.nabble.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan wrote
> On 01/20/2015 01:26 PM, Arne Scheffer wrote:
>>
>> And a very minor aspect:
>> The term "standard deviation" in your code stands for
>> (corrected) sample standard deviation, I think,
>> because you devide by n-1 instead of n to keep the
>> estimator unbiased.
>> How about mentioning the prefix "sample"
>> to indicate this beiing the estimator?
>
>
> I don't understand. I'm following pretty exactly the calculations stated
> at <http://www.johndcook.com/blog/standard_deviation/>
>
>
> I'm not a statistician. Perhaps others who are more literate in
> statistics can comment on this paragraph.
I'm largely in the same boat as Andrew but...
I take it that Arne is referring to:
http://en.wikipedia.org/wiki/Bessel's_correction
but the mere presence of an (n-1) divisor does not mean that is what is
happening. In this particular situation I believe the (n-1) simply is a
necessary part of the recurrence formula and not any attempt to correct for
sampling bias when estimating a population's variance. In fact, as far as
the database knows, the values provided to this function do represent an
entire population and such a correction would be unnecessary. I guess it
boils down to whether "future" queries are considered part of the population
or whether the population changes upon each query being run and thus we are
calculating the ever-changing population variance. Note point 3 in the
linked Wikipedia article.
David J.
--
View this message in context: http://postgresql.nabble.com/Add-min-and-max-execute-statement-time-in-pg-stat-statement-tp5774989p5834805.html
Sent from the PostgreSQL - hackers mailing list archive at Nabble.com.
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-20 23:54:15 |
| Message-ID: | 54BEEAA7.8020602@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/20/2015 06:32 PM, David G Johnston wrote:
> Andrew Dunstan wrote
>> On 01/20/2015 01:26 PM, Arne Scheffer wrote:
>>> And a very minor aspect:
>>> The term "standard deviation" in your code stands for
>>> (corrected) sample standard deviation, I think,
>>> because you devide by n-1 instead of n to keep the
>>> estimator unbiased.
>>> How about mentioning the prefix "sample"
>>> to indicate this beiing the estimator?
>>
>> I don't understand. I'm following pretty exactly the calculations stated
>> at <http://www.johndcook.com/blog/standard_deviation/>
>>
>>
>> I'm not a statistician. Perhaps others who are more literate in
>> statistics can comment on this paragraph.
> I'm largely in the same boat as Andrew but...
>
> I take it that Arne is referring to:
>
> http://en.wikipedia.org/wiki/Bessel's_correction
>
> but the mere presence of an (n-1) divisor does not mean that is what is
> happening. In this particular situation I believe the (n-1) simply is a
> necessary part of the recurrence formula and not any attempt to correct for
> sampling bias when estimating a population's variance. In fact, as far as
> the database knows, the values provided to this function do represent an
> entire population and such a correction would be unnecessary. I guess it
> boils down to whether "future" queries are considered part of the population
> or whether the population changes upon each query being run and thus we are
> calculating the ever-changing population variance. Note point 3 in the
> linked Wikipedia article.
>
>
Thanks. Still not quite sure what to do, though :-) I guess in the end
we want the answer to come up with similar results to the builtin stddev
SQL function. I'll try to set up a test program, to see if we do.
cheers
andrew
| From: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Mitsumasa KONDO <kondo(dot)mitsumasa(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 00:32:49 |
| Message-ID: | permail-201501210032499e949f53000035b4-scheffa@message-id.uni-muenster.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan schrieb am 2015-01-20:
> On 01/20/2015 01:26 PM, Arne Scheffer wrote:
> >Interesting patch.
> >I did a quick review looking only into the patch file.
> >The "sum of variances" variable contains
> >the "sum of squared differences" instead, I think.
> Umm, no. It's not.
Umm, yes, i think, it is ;-)
> e->counters.sum_var_time +=
> (total_time - old_mean) * (total_time - e->counters.mean_time);
> This is not a square that's being added.
That's correct.
Nevertheless it's the difference between the computed sum of squared
differences
and the preceeding one, added in every step.
> old_mean is not the same as
> e->counters.mean_time.
> Since the variance is this value divided by (n - 1), AIUI, I think
> "sum
> of variances" isn't a bad description. I'm open to alternative
> suggestions.
> >And a very minor aspect:
> >The term "standard deviation" in your code stands for
> >(corrected) sample standard deviation, I think,
> >because you devide by n-1 instead of n to keep the
> >estimator unbiased.
> >How about mentioning the prefix "sample"
> >to indicate this beiing the estimator?
> I don't understand. I'm following pretty exactly the calculations
> stated
> at <http://www.johndcook.com/blog/standard_deviation/>
(There is nothing bad about that calculations, Welford's algorithm
is simply sequently adding the differences mentioned above.)
VlG-Arne
> I'm not a statistician. Perhaps others who are more literate in
> statistics can comment on this paragraph.
> >And I'm sure I'm missing C specifics (again)
> >(or it's the reduced patch file scope),
> >but you introduce sqrtd, but sqrt is called?
> Good catch. Will fix.
> cheers
> andrew
| From: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de> |
|---|---|
| To: | David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, <pgsql-hackers(at)postgresql(dot)org>, <andrew(at)dunslane(dot)net> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 12:18:04 |
| Message-ID: | permail-20150121121804fe5316b600007a2b-scheffa@message-id.uni-muenster.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
David G Johnston schrieb am 2015-01-21:
> Andrew Dunstan wrote
> > On 01/20/2015 01:26 PM, Arne Scheffer wrote:
> >> And a very minor aspect:
> >> The term "standard deviation" in your code stands for
> >> (corrected) sample standard deviation, I think,
> >> because you devide by n-1 instead of n to keep the
> >> estimator unbiased.
> >> How about mentioning the prefix "sample"
> >> to indicate this beiing the estimator?
> > I don't understand. I'm following pretty exactly the calculations
> > stated
> > at <http://www.johndcook.com/blog/standard_deviation/>
> > I'm not a statistician. Perhaps others who are more literate in
> > statistics can comment on this paragraph.
> I'm largely in the same boat as Andrew but...
> I take it that Arne is referring to:
> http://en.wikipedia.org/wiki/Bessel's_correction
Yes, it is.
> but the mere presence of an (n-1) divisor does not mean that is what
> is
> happening. In this particular situation I believe the (n-1) simply
> is a
> necessary part of the recurrence formula and not any attempt to
> correct for
> sampling bias when estimating a population's variance.
That's wrong, it's applied in the end to the sum of squared differences
and therefore per definition the corrected sample standard deviation
estimator.
> In fact, as
> far as
> the database knows, the values provided to this function do represent
> an
> entire population and such a correction would be unnecessary. I
That would probably be an exotic assumption in a working database
and it is not, what is computed here!
> guess it
> boils down to whether "future" queries are considered part of the
> population
> or whether the population changes upon each query being run and thus
> we are
> calculating the ever-changing population variance.
Yes, indeed correct.
And exactly to avoid that misunderstanding, I suggested to
use the "sample" term.
To speak in Postgresql terms; applied in Andrews/Welfords algorithm
is stddev_samp(le), not stddev_pop(ulation).
Therefore stddev in Postgres is only kept for historical reasons, look at
http://www.postgresql.org/docs/9.4/static/functions-aggregate.html
Table 9-43.
VlG-Arne
> Note point 3 in
> the
> linked Wikipedia article.
> David J.
> --
> View this message in context:
> http://postgresql.nabble.com/Add-min-and-max-execute-statement-time-in-pg-stat-statement-tp5774989p5834805.html
> Sent from the PostgreSQL - hackers mailing list archive at
> Nabble.com.
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
| From: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 14:16:11 |
| Message-ID: | permail-20150121141611fe5316b600000d92-scheffa@message-id.uni-muenster.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> >>I don't understand. I'm following pretty exactly the calculations
> >>stated
> >>at <http://www.johndcook.com/blog/standard_deviation/>
> >>I'm not a statistician. Perhaps others who are more literate in
Maybe I'm mistaken here,
but I think, the algorithm is not that complicated.
I try to explain it further:
Comments appreciated.
Definition var_samp = Sum of squared differences /n-1
Definition stddev_samp = sqrt(var_samp)
Example N=4
1.) Sum of squared differences
1_4Sum(Xi-XM4)²
=
2.) adding nothing
1_4Sum(Xi-XM4)²
+0
+0
+0
=
3.) nothing changed
1_4Sum(Xi-XM4)²
+(-1_3Sum(Xi-XM3)²+1_3Sum(Xi-XM3)²)
+(-1_2Sum(Xi-XM2)²+1_2Sum(Xi-XM3)²)
+(-1_1Sum(Xi-XM2)²+1_1Sum(Xi-XM3)²)
=
4.) parts reordered
(1_4Sum(Xi-XM4)²-1_3Sum(Xi-XM3)²)
+(1_3Sum(Xi-XM3)²-1_2Sum(Xi-XM2)²)
+(1_2Sum(Xi-XM2)²-1_1Sum(Xi-XM2)²)
+1_1Sum(X1-XM1)²
=
5.)
(X4-XM4)(X4-XM3)
+ (X3-XM3)(X3-XM2)
+ (X2-XM2)(X2-XM1)
+ (X1-XM1)²
=
6.) XM1=X1 => There it is - The iteration part of Welfords Algorithm (in
reverse order)
(X4-XM4)(X4-XM3)
+ (X3-XM3)(X3-XM2)
+ (X2-XM2)(X2-X1)
+ 0
The missing piece is 4.) to 5.)
it's algebra, look at e.g.:
http://jonisalonen.com/2013/deriving-welfords-method-for-computing-variance/
> Thanks. Still not quite sure what to do, though :-) I guess in the
> end we want the answer to come up with similar results to the builtin
> stddev SQL function. I'll try to set up a test program, to see if we do.
If you want to go this way:
Maybe this is one of the very few times, you have to use a small sample
;-)
VlG-Arne
> cheers
> andrew
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
| From: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 14:27:03 |
| Message-ID: | permail-20150121142703fe5316b60000277f-scheffa@message-id.uni-muenster.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Sorry, corrected second try because of copy&paste mistakes:
VlG-Arne
> Comments appreciated.
> Definition var_samp = Sum of squared differences /n-1
> Definition stddev_samp = sqrt(var_samp)
> Example N=4
> 1.) Sum of squared differences
> 1_4Sum(Xi-XM4)²
> =
> 2.) adding nothing
> 1_4Sum(Xi-XM4)²
> +0
> +0
> +0
> =
> 3.) nothing changed
> 1_4Sum(Xi-XM4)²
> +(-1_3Sum(Xi-XM3)²+1_3Sum(Xi-XM3)²)
> +(-1_2Sum(Xi-XM2)²+1_2Sum(Xi-XM2)²)
> +(-1_1Sum(Xi-XM1)²+1_1Sum(Xi-XM1)²)
> =
> 4.) parts reordered
> (1_4Sum(Xi-XM4)²-1_3Sum(Xi-XM3)²)
> +(1_3Sum(Xi-XM3)²-1_2Sum(Xi-XM2)²)
> +(1_2Sum(Xi-XM2)²-1_1Sum(Xi-XM1)²)
> +1_1Sum(X1-XM1)²
> =
> 5.)
> (X4-XM4)(X4-XM3)
> + (X3-XM3)(X3-XM2)
> + (X2-XM2)(X2-XM1)
> + (X1-XM1)²
> =
> 6.) XM1=X1 => There it is - The iteration part of Welfords Algorithm
> (in
> reverse order)
> (X4-XM4)(X4-XM3)
> + (X3-XM3)(X3-XM2)
> + (X2-XM2)(X2-X1)
> + 0
> The missing piece is 4.) to 5.)
> it's algebra, look at e.g.:
> http://jonisalonen.com/2013/deriving-welfords-method-for-computing-variance/
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 14:46:53 |
| Message-ID: | 54BFBBDD.8080302@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/21/2015 09:27 AM, Arne Scheffer wrote:
> Sorry, corrected second try because of copy&paste mistakes:
> VlG-Arne
>
>> Comments appreciated.
>> Definition var_samp = Sum of squared differences /n-1
>> Definition stddev_samp = sqrt(var_samp)
>> Example N=4
>> 1.) Sum of squared differences
>> 1_4Sum(Xi-XM4)²
>> =
>> 2.) adding nothing
>> 1_4Sum(Xi-XM4)²
>> +0
>> +0
>> +0
>> =
>> 3.) nothing changed
>> 1_4Sum(Xi-XM4)²
>> +(-1_3Sum(Xi-XM3)²+1_3Sum(Xi-XM3)²)
>> +(-1_2Sum(Xi-XM2)²+1_2Sum(Xi-XM2)²)
>> +(-1_1Sum(Xi-XM1)²+1_1Sum(Xi-XM1)²)
>> =
>> 4.) parts reordered
>> (1_4Sum(Xi-XM4)²-1_3Sum(Xi-XM3)²)
>> +(1_3Sum(Xi-XM3)²-1_2Sum(Xi-XM2)²)
>> +(1_2Sum(Xi-XM2)²-1_1Sum(Xi-XM1)²)
>> +1_1Sum(X1-XM1)²
>> =
>> 5.)
>> (X4-XM4)(X4-XM3)
>> + (X3-XM3)(X3-XM2)
>> + (X2-XM2)(X2-XM1)
>> + (X1-XM1)²
>> =
>> 6.) XM1=X1 => There it is - The iteration part of Welfords Algorithm
>> (in
>> reverse order)
>> (X4-XM4)(X4-XM3)
>> + (X3-XM3)(X3-XM2)
>> + (X2-XM2)(X2-X1)
>> + 0
>> The missing piece is 4.) to 5.)
>> it's algebra, look at e.g.:
>> http://jonisalonen.com/2013/deriving-welfords-method-for-computing-variance/
>
>
I have no idea what you are saying here.
Here are comments in email to me from the author of
<http://www.johndcook.com/blog/standard_deviation> regarding the divisor
used:
My code is using the unbiased form of the sample variance, dividing
by n-1.
It's usually not worthwhile to make a distinction between a sample
and a population because the "population" is often itself a sample.
For example, if you could measure the height of everyone on earth at
one instance, that's the entire population, but it's still a sample
from all who have lived and who ever will live.
Also, for large n, there's hardly any difference between 1/n and
1/(n-1).
Maybe I should add that in the code comments. Otherwise, I don't think
we need a change.
cheers
andrew
| From: | Arne Scheffer <scheffa(at)uni-muenster(dot)de> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 16:21:01 |
| Message-ID: | alpine.DEB.2.02.1501211650370.2867@zivarne |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 21 Jan 2015, Andrew Dunstan wrote:
>
> On 01/21/2015 09:27 AM, Arne Scheffer wrote:
>> Sorry, corrected second try because of copy&paste mistakes:
>> VlG-Arne
>>
>>> Comments appreciated.
>>> Definition var_samp = Sum of squared differences /n-1
>>> Definition stddev_samp = sqrt(var_samp)
>>> Example N=4
>>> 1.) Sum of squared differences
>>> 1_4Sum(Xi-XM4)²
>>> =
>>> 2.) adding nothing
>>> 1_4Sum(Xi-XM4)²
>>> +0
>>> +0
>>> +0
>>> =
>>> 3.) nothing changed
>>> 1_4Sum(Xi-XM4)²
>>> +(-1_3Sum(Xi-XM3)²+1_3Sum(Xi-XM3)²)
>>> +(-1_2Sum(Xi-XM2)²+1_2Sum(Xi-XM2)²)
>>> +(-1_1Sum(Xi-XM1)²+1_1Sum(Xi-XM1)²)
>>> =
>>> 4.) parts reordered
>>> (1_4Sum(Xi-XM4)²-1_3Sum(Xi-XM3)²)
>>> +(1_3Sum(Xi-XM3)²-1_2Sum(Xi-XM2)²)
>>> +(1_2Sum(Xi-XM2)²-1_1Sum(Xi-XM1)²)
>>> +1_1Sum(X1-XM1)²
>>> =
>>> 5.)
>>> (X4-XM4)(X4-XM3)
>>> + (X3-XM3)(X3-XM2)
>>> + (X2-XM2)(X2-XM1)
>>> + (X1-XM1)²
>>> =
>>> 6.) XM1=X1 => There it is - The iteration part of Welfords Algorithm
>>> (in
>>> reverse order)
>>> (X4-XM4)(X4-XM3)
>>> + (X3-XM3)(X3-XM2)
>>> + (X2-XM2)(X2-X1)
>>> + 0
>>> The missing piece is 4.) to 5.)
>>> it's algebra, look at e.g.:
>>> http://jonisalonen.com/2013/deriving-welfords-method-for-computing-variance/
>>
>>
>
>
>
> I have no idea what you are saying here.
I'm sorry for that statistics stuff,
my attempt was only to visualize in detail
the mathematical reason for
the iterating part of Welfords algorithm
being computing the current sum of squared differences in every step
- therefore it's in my opinion better to call the variable sum_of_squared_diffs
(every statistician will be confused bei "sum_of_variances",
because: sample variance = sum_of_squared_diffs / n-1,
have a look at Mr. Cooks explanation)
- therefore deviding by n-1 is the unbiased estimator by definition.
(have a look at Mr. Cooks explanation)
- therefore I suggested (as a minor nomenclature issue) to call the column/description
stdev_samp (PostgreSQL-nomenclature) / sample_.... to indicate that information.
(have a look at the PostgreSQL aggregate functions, it's doing that the same way)
>
> Here are comments in email to me from the author of
> <http://www.johndcook.com/blog/standard_deviation> regarding the divisor
> used:
>
> My code is using the unbiased form of the sample variance, dividing
> by n-1.
>
I am relieved, now we are at least two persons saying that. :-)
Insert into the commonly known definition
>>> Definition stddev_samp = sqrt(var_samp)
from above, and it's exactly my point.
> Maybe I should add that in the code comments. Otherwise, I don't think we
> need a change.
Huh?
Why is it a bad thing to call the column "stddev_samp" analog to the
aggregate function or make a note in the documentation,
that the sample stddev is used to compute the solution?
I really think it not a good strategy having the user to make a test or dive
into the source code to determine the divisor used.
E.g. David expected stdev_pop, so there is a need for documentation for cases with a small sample.
VlG-Arne
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Arne Scheffer <scheffa(at)uni-muenster(dot)de> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 16:32:57 |
| Message-ID: | 54BFD4B9.9050707@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/21/2015 11:21 AM, Arne Scheffer wrote:
>
>
>
> Why is it a bad thing to call the column "stddev_samp" analog to the
> aggregate function or make a note in the documentation, that the
> sample stddev is used to compute the solution?
I think you are making a mountain out of a molehill, frankly. These
stats are not intended as anything other than a pretty indication of the
shape, to see if they are significantly influenced by outliers. For any
significantly large sample size the difference will be negligible.
But I will add a note to the documentation, that seems reasonable.
cheers
andrew
| From: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-01-21 16:58:23 |
| Message-ID: | permail-20150121165823fe5316b6000001cc-scheffa@message-id.uni-muenster.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andrew Dunstan schrieb am 2015-01-21:
> On 01/21/2015 11:21 AM, Arne Scheffer wrote:
> >Why is it a bad thing to call the column "stddev_samp" analog to the
> >aggregate function or make a note in the documentation, that the
> >sample stddev is used to compute the solution?
> I think you are making a mountain out of a molehill, frankly. These
> stats are not intended as anything other than a pretty indication of
> the
> shape, to see if they are significantly influenced by outliers. For
> any
> significantly large sample size the difference will be negligible.
You're right, I maybe exaggerated the statistics part a bit.
I wanted to help, because the patch is of interest for us.
I will try to keep focus in the future.
> But I will add a note to the documentation, that seems reasonable.
*happy*
Thx
Arne
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 00:44:48 |
| Message-ID: | 54E28F00.8020602@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21/01/15 17:32, Andrew Dunstan wrote:
>
> On 01/21/2015 11:21 AM, Arne Scheffer wrote:
>>
>>
>>
>> Why is it a bad thing to call the column "stddev_samp" analog to the
>> aggregate function or make a note in the documentation, that the
>> sample stddev is used to compute the solution?
>
>...
>
> But I will add a note to the documentation, that seems reasonable.
>
I agree this is worth mentioning in the doc.
In any case here some review from me:
We definitely want this feature, I wished to have this info many times.
The patch has couple of issues though:
The 1.2 to 1.3 upgrade file is named pg_stat_statements--1.2-1.3.sql and
should be renamed to pg_stat_statements--1.2--1.3.sql (two dashes).
There is new sqrtd function for fast sqrt calculation, which I think is
a good idea as it will reduce the overhead of the additional calculation
and this is not something where little loss of precision would matter
too much. The problem is that the new function is actually not used
anywhere in the code, I only see use of plain sqrt.
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Peter Geoghegan <pg(at)heroku(dot)com> |
|---|---|
| To: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 00:57:49 |
| Message-ID: | CAM3SWZTbE5BqQDJsuGns9QVTK-q7R2oOVjVOjTHXN7w4ZM0VGw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com> wrote:
> We definitely want this feature, I wished to have this info many times.
I would still like to see a benchmark.
--
Peter Geoghegan
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 01:48:09 |
| Message-ID: | 54E29DD9.40204@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17/02/15 01:57, Peter Geoghegan wrote:
> On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com> wrote:
>> We definitely want this feature, I wished to have this info many times.
>
> I would still like to see a benchmark.
>
>
Average of 3 runs of read-only pgbench on my system all with
pg_stat_statement activated:
HEAD: 20631
SQRT: 20533
SQRTD: 20592
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Petr Jelinek <petr(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 01:57:08 |
| Message-ID: | 54E29FF4.5070304@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 02/16/2015 08:48 PM, Petr Jelinek wrote:
> On 17/02/15 01:57, Peter Geoghegan wrote:
>> On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com>
>> wrote:
>>> We definitely want this feature, I wished to have this info many times.
>>
>> I would still like to see a benchmark.
>>
>>
>
> Average of 3 runs of read-only pgbench on my system all with
> pg_stat_statement activated:
> HEAD: 20631
> SQRT: 20533
> SQRTD: 20592
>
>
So using sqrtd the cost is 0.18%. I think that's acceptable.
cheers
andrew
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Petr Jelinek <petr(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 02:03:45 |
| Message-ID: | 54E2A181.3080706@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 02/16/2015 08:57 PM, Andrew Dunstan wrote:
>
> On 02/16/2015 08:48 PM, Petr Jelinek wrote:
>> On 17/02/15 01:57, Peter Geoghegan wrote:
>>> On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com>
>>> wrote:
>>>> We definitely want this feature, I wished to have this info many
>>>> times.
>>>
>>> I would still like to see a benchmark.
>>>
>>>
>>
>> Average of 3 runs of read-only pgbench on my system all with
>> pg_stat_statement activated:
>> HEAD: 20631
>> SQRT: 20533
>> SQRTD: 20592
>>
>>
>
>
> So using sqrtd the cost is 0.18%. I think that's acceptable.
>
Actually, sqrt/sqrtd is not called in accumulating the stats, only in
the reporting function. So it looks like the difference here should be
noise. Maybe we need some longer runs.
cheers
andrew
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 02:05:13 |
| Message-ID: | 54E2A1D9.9000903@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17/02/15 02:57, Andrew Dunstan wrote:
>
> On 02/16/2015 08:48 PM, Petr Jelinek wrote:
>> On 17/02/15 01:57, Peter Geoghegan wrote:
>>> On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com>
>>> wrote:
>>>> We definitely want this feature, I wished to have this info many times.
>>>
>>> I would still like to see a benchmark.
>>>
>>>
>>
>> Average of 3 runs of read-only pgbench on my system all with
>> pg_stat_statement activated:
>> HEAD: 20631
>> SQRT: 20533
>> SQRTD: 20592
>>
>>
>
>
> So using sqrtd the cost is 0.18%. I think that's acceptable.
>
I think so too.
I found one more issue with the 1.2--1.3 upgrade script, the DROP
FUNCTION pg_stat_statements(); should be DROP FUNCTION
pg_stat_statements(bool); since in 1.2 the function identity has changed.
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 02:07:36 |
| Message-ID: | 54E2A268.1040208@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17/02/15 03:03, Andrew Dunstan wrote:
>
> On 02/16/2015 08:57 PM, Andrew Dunstan wrote:
>>
>> On 02/16/2015 08:48 PM, Petr Jelinek wrote:
>>> On 17/02/15 01:57, Peter Geoghegan wrote:
>>>> On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com>
>>>> wrote:
>>>>> We definitely want this feature, I wished to have this info many
>>>>> times.
>>>>
>>>> I would still like to see a benchmark.
>>>>
>>>>
>>>
>>> Average of 3 runs of read-only pgbench on my system all with
>>> pg_stat_statement activated:
>>> HEAD: 20631
>>> SQRT: 20533
>>> SQRTD: 20592
>>>
>>>
>>
>>
>> So using sqrtd the cost is 0.18%. I think that's acceptable.
>>
>
> Actually, sqrt/sqrtd is not called in accumulating the stats, only in
> the reporting function. So it looks like the difference here should be
> noise. Maybe we need some longer runs.
>
Yes there are variations between individual runs so it might be really
just that, I can leave it running for much longer time tomorrow.
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 14:50:39 |
| Message-ID: | 54E3553F.2030209@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17/02/15 03:07, Petr Jelinek wrote:
> On 17/02/15 03:03, Andrew Dunstan wrote:
>>
>> On 02/16/2015 08:57 PM, Andrew Dunstan wrote:
>>>
>>> On 02/16/2015 08:48 PM, Petr Jelinek wrote:
>>>> On 17/02/15 01:57, Peter Geoghegan wrote:
>>>>> On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com>
>>>>> wrote:
>>>>>> We definitely want this feature, I wished to have this info many
>>>>>> times.
>>>>>
>>>>> I would still like to see a benchmark.
>>>>>
>>>>>
>>>>
>>>> Average of 3 runs of read-only pgbench on my system all with
>>>> pg_stat_statement activated:
>>>> HEAD: 20631
>>>> SQRT: 20533
>>>> SQRTD: 20592
>>>>
>>>>
>>>
>>>
>>> So using sqrtd the cost is 0.18%. I think that's acceptable.
>>>
>>
>> Actually, sqrt/sqrtd is not called in accumulating the stats, only in
>> the reporting function. So it looks like the difference here should be
>> noise. Maybe we need some longer runs.
>>
>
> Yes there are variations between individual runs so it might be really
> just that, I can leave it running for much longer time tomorrow.
>
Ok so I let it run for more than hour on a different system, the
difference is negligible - 14461 vs 14448 TPS. I think there is bigger
difference between individual runs than between the two versions...
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 15:12:06 |
| Message-ID: | 20150217151206.GE2895@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2015-02-17 15:50:39 +0100, Petr Jelinek wrote:
> On 17/02/15 03:07, Petr Jelinek wrote:
> >On 17/02/15 03:03, Andrew Dunstan wrote:
> >>On 02/16/2015 08:57 PM, Andrew Dunstan wrote:
> >>>>Average of 3 runs of read-only pgbench on my system all with
> >>>>pg_stat_statement activated:
> >>>>HEAD: 20631
> >>>>SQRT: 20533
> >>>>SQRTD: 20592
> >>>So using sqrtd the cost is 0.18%. I think that's acceptable.
> >>Actually, sqrt/sqrtd is not called in accumulating the stats, only in
> >>the reporting function. So it looks like the difference here should be
> >>noise. Maybe we need some longer runs.
> >Yes there are variations between individual runs so it might be really
> >just that, I can leave it running for much longer time tomorrow.
> Ok so I let it run for more than hour on a different system, the difference
> is negligible - 14461 vs 14448 TPS. I think there is bigger difference
> between individual runs than between the two versions...
These numbers sound like you measured them without concurrency, am I
right? If so, the benchmark isn't that interesting - the computation
happens while a spinlock is held, and that'll mainly matter if there are
many backends running at the same time.
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com>, Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-17 15:38:54 |
| Message-ID: | 54E3608E.4090009@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17/02/15 16:12, Andres Freund wrote:
> On 2015-02-17 15:50:39 +0100, Petr Jelinek wrote:
>> On 17/02/15 03:07, Petr Jelinek wrote:
>>> On 17/02/15 03:03, Andrew Dunstan wrote:
>>>> On 02/16/2015 08:57 PM, Andrew Dunstan wrote:
>>>>>> Average of 3 runs of read-only pgbench on my system all with
>>>>>> pg_stat_statement activated:
>>>>>> HEAD: 20631
>>>>>> SQRT: 20533
>>>>>> SQRTD: 20592
>
>>>>> So using sqrtd the cost is 0.18%. I think that's acceptable.
>
>>>> Actually, sqrt/sqrtd is not called in accumulating the stats, only in
>>>> the reporting function. So it looks like the difference here should be
>>>> noise. Maybe we need some longer runs.
>
>>> Yes there are variations between individual runs so it might be really
>>> just that, I can leave it running for much longer time tomorrow.
>
>> Ok so I let it run for more than hour on a different system, the difference
>> is negligible - 14461 vs 14448 TPS. I think there is bigger difference
>> between individual runs than between the two versions...
>
> These numbers sound like you measured them without concurrency, am I
> right? If so, the benchmark isn't that interesting - the computation
> happens while a spinlock is held, and that'll mainly matter if there are
> many backends running at the same time.
>
It's pgbench -j16 -c32
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Peter Eisentraut <peter_e(at)gmx(dot)net> |
|---|---|
| To: | David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-18 01:21:32 |
| Message-ID: | 54E3E91C.4020105@gmx.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 1/20/15 6:32 PM, David G Johnston wrote:
> In fact, as far as
> the database knows, the values provided to this function do represent an
> entire population and such a correction would be unnecessary. I guess it
> boils down to whether "future" queries are considered part of the population
> or whether the population changes upon each query being run and thus we are
> calculating the ever-changing population variance.
I think we should be calculating the population variance. We are
clearly taking the population to be all past queries (from the last
reset point). Otherwise calculating min and max wouldn't make sense.
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Peter Eisentraut <peter_e(at)gmx(dot)net>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-18 15:11:31 |
| Message-ID: | 54E4ABA3.5090807@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 02/17/2015 08:21 PM, Peter Eisentraut wrote:
> On 1/20/15 6:32 PM, David G Johnston wrote:
>> In fact, as far as
>> the database knows, the values provided to this function do represent an
>> entire population and such a correction would be unnecessary. I guess it
>> boils down to whether "future" queries are considered part of the population
>> or whether the population changes upon each query being run and thus we are
>> calculating the ever-changing population variance.
> I think we should be calculating the population variance. We are
> clearly taking the population to be all past queries (from the last
> reset point). Otherwise calculating min and max wouldn't make sense.
>
>
The difference is likely to be very small in any case where you actually
want to examine the standard deviation, so I feel we're rather arguing
about how many angels can fit on the head of a pin, but if this is the
consensus I'll change it.
cheers
andrew
| From: | David Fetter <david(at)fetter(dot)org> |
|---|---|
| To: | Peter Eisentraut <peter_e(at)gmx(dot)net> |
| Cc: | David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-19 01:34:39 |
| Message-ID: | 20150219013439.GB22348@fetter.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Feb 17, 2015 at 08:21:32PM -0500, Peter Eisentraut wrote:
> On 1/20/15 6:32 PM, David G Johnston wrote:
> > In fact, as far as the database knows, the values provided to this
> > function do represent an entire population and such a correction
> > would be unnecessary. I guess it boils down to whether "future"
> > queries are considered part of the population or whether the
> > population changes upon each query being run and thus we are
> > calculating the ever-changing population variance.
>
> I think we should be calculating the population variance.
Why population variance and not sample variance? In distributions
where the second moment about the mean exists, it's an unbiased
estimator of the variance. In this, it's different from the
population variance.
Cheers,
David.
--
David Fetter <david(at)fetter(dot)org> http://fetter.org/
Phone: +1 415 235 3778 AIM: dfetter666 Yahoo!: dfetter
Skype: davidfetter XMPP: david(dot)fetter(at)gmail(dot)com
Remember to vote!
Consider donating to Postgres: http://www.postgresql.org/about/donate
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | David Fetter <david(at)fetter(dot)org>, Peter Eisentraut <peter_e(at)gmx(dot)net> |
| Cc: | David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-19 01:50:45 |
| Message-ID: | 54E54175.8040303@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 02/18/2015 08:34 PM, David Fetter wrote:
> On Tue, Feb 17, 2015 at 08:21:32PM -0500, Peter Eisentraut wrote:
>> On 1/20/15 6:32 PM, David G Johnston wrote:
>>> In fact, as far as the database knows, the values provided to this
>>> function do represent an entire population and such a correction
>>> would be unnecessary. I guess it boils down to whether "future"
>>> queries are considered part of the population or whether the
>>> population changes upon each query being run and thus we are
>>> calculating the ever-changing population variance.
>> I think we should be calculating the population variance.
> Why population variance and not sample variance? In distributions
> where the second moment about the mean exists, it's an unbiased
> estimator of the variance. In this, it's different from the
> population variance.
>
Because we're actually measuring the whole population, and not a sample?
cheers
andrew
| From: | "David G(dot) Johnston" <david(dot)g(dot)johnston(at)gmail(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | David Fetter <david(at)fetter(dot)org>, Peter Eisentraut <peter_e(at)gmx(dot)net>, "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-19 03:31:09 |
| Message-ID: | CAKFQuwZL4DTEuimUeVYSE=f_itYoaVaPBMTUiHkj7EMTDZQr0g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Feb 18, 2015 at 6:50 PM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
>
> On 02/18/2015 08:34 PM, David Fetter wrote:
>
>> On Tue, Feb 17, 2015 at 08:21:32PM -0500, Peter Eisentraut wrote:
>>
>>> On 1/20/15 6:32 PM, David G Johnston wrote:
>>>
>>>> In fact, as far as the database knows, the values provided to this
>>>> function do represent an entire population and such a correction
>>>> would be unnecessary. I guess it boils down to whether "future"
>>>> queries are considered part of the population or whether the
>>>> population changes upon each query being run and thus we are
>>>> calculating the ever-changing population variance.
>>>>
>>>
> I think we should be calculating the population variance.
>>>
>>
> Why population variance and not sample variance? In distributions
>> where the second moment about the mean exists, it's an unbiased
>> estimator of the variance. In this, it's different from the
>> population variance.
>>
>
> Because we're actually measuring the whole population, and not a sample?
>
This.
The key incorrect word in David Fetter's statement is "estimator". We are
not estimating anything but rather providing descriptive statistics for a
defined population.
Users extrapolate that the next member added to the population would be
expected to conform to this statistical description without bias (though
see below). We can also then define the new population by including this
new member and generating new descriptive statistics (which allows for
evolution to be captured in the statistics).
Currently (I think) we allow the end user to kill off the entire population
and build up from scratch so that while, in the short term, the ability to
predict the attributes of future members is limited once the population has
reached a statistically significant level new predictions will no longer
be skewed by population members who attributes were defined in a older and
possibly significantly different environment. In theory it would be nice
to be able to give the user the ability to specify - by time or percentage
- a subset of the population to leave alive.
Actual time-weighted sampling would be an alternative but likely one
significantly more difficult to accomplish. I really have dug too deep
into the mechanics of the current code but I don't see any harm in sharing
the thought.
David J.
| From: | David Fetter <david(at)fetter(dot)org> |
|---|---|
| To: | "David G(dot) Johnston" <david(dot)g(dot)johnston(at)gmail(dot)com> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Eisentraut <peter_e(at)gmx(dot)net>, "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-19 18:10:54 |
| Message-ID: | 20150219181054.GB8831@fetter.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Feb 18, 2015 at 08:31:09PM -0700, David G. Johnston wrote:
> On Wed, Feb 18, 2015 at 6:50 PM, Andrew Dunstan <andrew(at)dunslane(dot)net> wrote:
> > On 02/18/2015 08:34 PM, David Fetter wrote:
> >
> >> On Tue, Feb 17, 2015 at 08:21:32PM -0500, Peter Eisentraut wrote:
> >>
> >>> On 1/20/15 6:32 PM, David G Johnston wrote:
> >>>
> >>>> In fact, as far as the database knows, the values provided to this
> >>>> function do represent an entire population and such a correction
> >>>> would be unnecessary. I guess it boils down to whether "future"
> >>>> queries are considered part of the population or whether the
> >>>> population changes upon each query being run and thus we are
> >>>> calculating the ever-changing population variance.
>
> > I think we should be calculating the population variance.
>
> >> Why population variance and not sample variance? In distributions
> >> where the second moment about the mean exists, it's an unbiased
> >> estimator of the variance. In this, it's different from the
> >> population variance.
>
> > Because we're actually measuring the whole population, and not a sample?
We're not. We're taking a sample, which is to say past measurements,
and using it to make inferences about the population, which includes
all queries in the future.
> The key incorrect word in David Fetter's statement is "estimator". We are
> not estimating anything but rather providing descriptive statistics for a
> defined population.
See above.
> Users extrapolate that the next member added to the population would be
> expected to conform to this statistical description without bias (though
> see below). We can also then define the new population by including this
> new member and generating new descriptive statistics (which allows for
> evolution to be captured in the statistics).
>
> Currently (I think) we allow the end user to kill off the entire population
> and build up from scratch so that while, in the short term, the ability to
> predict the attributes of future members is limited once the population has
> reached a statistically significant level new predictions will no longer
> be skewed by population members who attributes were defined in a older and
> possibly significantly different environment. In theory it would be nice
> to be able to give the user the ability to specify - by time or percentage
> - a subset of the population to leave alive.
I agree that stale numbers can fuzz things in a way we don't like, but
let's not creep too much feature in here.
> Actual time-weighted sampling would be an alternative but likely one
> significantly more difficult to accomplish.
Right.
Cheers,
David.
--
David Fetter <david(at)fetter(dot)org> http://fetter.org/
Phone: +1 415 235 3778 AIM: dfetter666 Yahoo!: dfetter
Skype: davidfetter XMPP: david(dot)fetter(at)gmail(dot)com
Remember to vote!
Consider donating to Postgres: http://www.postgresql.org/about/donate
| From: | "David G(dot) Johnston" <david(dot)g(dot)johnston(at)gmail(dot)com> |
|---|---|
| To: | David Fetter <david(at)fetter(dot)org> |
| Cc: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Eisentraut <peter_e(at)gmx(dot)net>, "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-19 18:19:58 |
| Message-ID: | CAKFQuwb2Up+rMMxa3Wkx4DjwdKrgmiOzGGTnsr6=Lb3uJKy1zw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Feb 19, 2015 at 11:10 AM, David Fetter <david(at)fetter(dot)org> wrote:
> On Wed, Feb 18, 2015 at 08:31:09PM -0700, David G. Johnston wrote:
> > On Wed, Feb 18, 2015 at 6:50 PM, Andrew Dunstan <andrew(at)dunslane(dot)net>
> wrote:
> > > On 02/18/2015 08:34 PM, David Fetter wrote:
> > >
> > >> On Tue, Feb 17, 2015 at 08:21:32PM -0500, Peter Eisentraut wrote:
> > >>
> > >>> On 1/20/15 6:32 PM, David G Johnston wrote:
> > >>>
> > >>>> In fact, as far as the database knows, the values provided to this
> > >>>> function do represent an entire population and such a correction
> > >>>> would be unnecessary. I guess it boils down to whether "future"
> > >>>> queries are considered part of the population or whether the
> > >>>> population changes upon each query being run and thus we are
> > >>>> calculating the ever-changing population variance.
> >
> > > I think we should be calculating the population variance.
> >
> > >> Why population variance and not sample variance? In distributions
> > >> where the second moment about the mean exists, it's an unbiased
> > >> estimator of the variance. In this, it's different from the
> > >> population variance.
> >
> > > Because we're actually measuring the whole population, and not a
> sample?
>
> We're not. We're taking a sample, which is to say past measurements,
> and using it to make inferences about the population, which includes
> all queries in the future.
>
>
"All past measurements" does not qualify as a "random sample" of a
population made up of all past measurements and any potential members that
may be added in the future. Without the "random sample" aspect you throw
away all pretense of avoiding bias so you might as well just call the
totality of the past measurements the population, describe them using
population descriptive statistics, and call it a day.
For large populations it isn't going to matter anyway but for small
populations the difference of one in the divisor seems like it would make
the past performance look worse than it actually was.
David J.
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Petr Jelinek <petr(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-21 21:09:02 |
| Message-ID: | 54E8F3EE.6050403@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 02/16/2015 09:05 PM, Petr Jelinek wrote:
> On 17/02/15 02:57, Andrew Dunstan wrote:
>>
>> On 02/16/2015 08:48 PM, Petr Jelinek wrote:
>>> On 17/02/15 01:57, Peter Geoghegan wrote:
>>>> On Mon, Feb 16, 2015 at 4:44 PM, Petr Jelinek <petr(at)2ndquadrant(dot)com>
>>>> wrote:
>>>>> We definitely want this feature, I wished to have this info many
>>>>> times.
>>>>
>>>> I would still like to see a benchmark.
>>>>
>>>>
>>>
>>> Average of 3 runs of read-only pgbench on my system all with
>>> pg_stat_statement activated:
>>> HEAD: 20631
>>> SQRT: 20533
>>> SQRTD: 20592
>>>
>>>
>>
>>
>> So using sqrtd the cost is 0.18%. I think that's acceptable.
>>
>
> I think so too.
>
> I found one more issue with the 1.2--1.3 upgrade script, the DROP
> FUNCTION pg_stat_statements(); should be DROP FUNCTION
> pg_stat_statements(bool); since in 1.2 the function identity has changed.
>
>
I think all the outstanding issues are fixed in this patch.
cheers
andrew
| Attachment | Content-Type | Size |
|---|---|---|
| pg_stat_statements-extrastats2.patch | text/x-patch | 13.2 KB |
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-02-22 00:59:41 |
| Message-ID: | 54E929FD.8090806@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21/02/15 22:09, Andrew Dunstan wrote:
>
> On 02/16/2015 09:05 PM, Petr Jelinek wrote:
>>
>> I found one more issue with the 1.2--1.3 upgrade script, the DROP
>> FUNCTION pg_stat_statements(); should be DROP FUNCTION
>> pg_stat_statements(bool); since in 1.2 the function identity has changed.
>>
>>
>
>
> I think all the outstanding issues are fixed in this patch.
>
I think PGSS_FILE_HEADER should be also updated, otherwise it's good.
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Petr Jelinek <petr(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net>, Peter Geoghegan <pg(at)heroku(dot)com> |
| Cc: | Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-03-14 14:09:49 |
| Message-ID: | 5504412D.4070909@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 22/02/15 01:59, Petr Jelinek wrote:
> On 21/02/15 22:09, Andrew Dunstan wrote:
>>
>> On 02/16/2015 09:05 PM, Petr Jelinek wrote:
>>>
>>> I found one more issue with the 1.2--1.3 upgrade script, the DROP
>>> FUNCTION pg_stat_statements(); should be DROP FUNCTION
>>> pg_stat_statements(bool); since in 1.2 the function identity has
>>> changed.
>>>
>>>
>>
>>
>> I think all the outstanding issues are fixed in this patch.
>>
>
> I think PGSS_FILE_HEADER should be also updated, otherwise it's good.
>
>
I see you marked this as 'needs review', I am marking it as 'ready for
committer' as it looks good to me.
Just don't forget to update the PGSS_FILE_HEADER while committing (I
think that one can be threated same way as catversion, ie be updated by
committer and not in patch submission).
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
| Cc: | Petr Jelinek <petr(at)2ndquadrant(dot)com>, Peter Geoghegan <pg(at)heroku(dot)com>, Arne Scheffer <arne(dot)scheffer(at)uni-muenster(dot)de>, David G Johnston <david(dot)g(dot)johnston(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Add min and max execute statement time in pg_stat_statement |
| Date: | 2015-03-20 09:34:57 |
| Message-ID: | 20150320093456.GA30141@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2015-02-21 16:09:02 -0500, Andrew Dunstan wrote:
> I think all the outstanding issues are fixed in this patch.
Do you plan to push this? I don't see a benefit in delaying things
any further...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services