Re: XLogInsert scaling, revisited
| Lists: | pgsql-hackers |
|---|
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgreSQL(dot)org> |
| Subject: | XLogInsert scaling, revisited |
| Date: | 2012-09-20 15:29:12 |
| Message-ID: | 505B3648.1040801@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I've been slowly continuing to work that I started last winder to make
XLogInsert scale better. I have tried quite a few different approaches
since then, and have settled on the attached. This is similar but not
exactly the same as what I did in the patches I posted earlier.
The basic idea, like before, is to split WAL insertion into two phases:
1. Reserve the right amount of WAL. This is done while holding just a
spinlock. Thanks to the changes I made earlier to the WAL format, the
space calculations are now much simpler and the critical section boils
down to almost just "CurBytePos += size_of_wal_record". See
ReserveXLogInsertLocation() function.
2. Copy the WAL record to the right location in the WAL buffers. This
slower part can be done mostly in parallel.
The difficult part is tracking which insertions are currently in
progress, and being able to wait for an insertion to finish copying the
record data in place. I'm using a small number (7 at the moment) of WAL
insertion slots for that. The first thing that XLogInsert does is to
grab one of the slots. Each slot is protected by a LWLock, and
XLogInsert reserves a slot by acquiring its lock. It holds the lock
until it has completely finished copying the WAL record in place. In
each slot, there's an XLogRecPtr that indicates how far the current
inserter has progressed with its insertion. Typically, for a short
record that fits on a single page, it is updated after the insertion is
finished, but if the insertion needs to wait for a WAL buffer to become
available, it updates the XLogRecPtr before sleeping.
To wait for all insertions up to a point to finish, you scan all the
insertion slots, and observe that the XLogRecPtrs in them are >= the
point you're interested in. The number of slots is a tradeoff: more
slots allow more concurrency in inserting records, but makes it slower
to determine how far it can be safely flushed.
I did some performance tests with this, on an 8-core HP Proliant server,
in a VM running under VMware vSphere 5.1. The tests were performed with
Greg Smith's pgbench-tools kit, with one of two custom workload scripts:
1. Insert 1000 rows in each transaction. This is exactly the sort of
workload where WALInsertLock currently becomes a bottleneck. Without the
the patch, the test scales very badly, with about 420 TPS with a single
client, peaking only at 520 TPS with two clients. With the patch, it
scales up to about 1200 TPS, with 7 clients. I believe the test becomes
I/O limited at that point; looking at iostat output while the test is
running shows about 200MB/s of writes, and that is roughly what the I/O
subsystem of this machine can do, according to a simple test with 'dd
...; sync". Or perhaps having more "insertion slots" would allow it to
go higher - the patch uses exactly 7 slots at the moment.
http://hlinnaka.iki.fi/xloginsert-scaling/results-1k/
2. Insert only 10 rows in each transaction. This simulates an OLTP
workload with fairly small transactions. The patch doesn't make a huge
difference with that workload. It performs somewhat worse with 4-16
clients, but then somewhat better with > 16 clients. The patch adds some
overhead to flushing the WAL, I believe that's what's causing the
slowdown with 4-16 clients. But with more clients, the WALInsertLock
bottleneck becomes more significant, and you start to see a benefit again.
http://hlinnaka.iki.fi/xloginsert-scaling/results-10/
Overall, the results look pretty good. I'm going to take a closer look
at the slowdown in the second test. I think it might be fixable with
some changes to how WaitInsertionsToFinish() and WALWriteLock work
together, although I'm not sure how exactly it ought to work.
Comments, ideas?
- Heikki
| Attachment | Content-Type | Size |
|---|---|---|
| xloginsert-scale-20.patch.gz | application/x-gzip | 26.7 KB |
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2012-09-20 15:37:42 |
| Message-ID: | 18237.1348155462@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> writes:
> I've been slowly continuing to work that I started last winder to make
> XLogInsert scale better. I have tried quite a few different approaches
> since then, and have settled on the attached. This is similar but not
> exactly the same as what I did in the patches I posted earlier.
This sounds pretty good. I'm a bit bothered by the fact that you've
settled on 7 parallel-insertion slots after testing on an 8-core
machine. I suspect that it's not a coincidence that you're seeing
a sweet spot for #slots ~= #CPUs. If that is what's happening, we're
going to want to be able to configure the #slots at postmaster start.
Not sure how we'd go about it exactly - is there any reasonably portable
way to find out how many CPUs the machine has? Or do we have to use a
GUC for that?
regards, tom lane
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2012-09-20 15:51:30 |
| Message-ID: | 201209201751.30910.andres@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thursday, September 20, 2012 05:37:42 PM Tom Lane wrote:
> Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> writes:
> > I've been slowly continuing to work that I started last winder to make
> > XLogInsert scale better. I have tried quite a few different approaches
> > since then, and have settled on the attached. This is similar but not
> > exactly the same as what I did in the patches I posted earlier.
Sounds pretty cool from a quick read.
> This sounds pretty good. I'm a bit bothered by the fact that you've
> settled on 7 parallel-insertion slots after testing on an 8-core
> machine. I suspect that it's not a coincidence that you're seeing
> a sweet spot for #slots ~= #CPUs. If that is what's happening, we're
> going to want to be able to configure the #slots at postmaster start.
> Not sure how we'd go about it exactly - is there any reasonably portable
> way to find out how many CPUs the machine has? Or do we have to use a
> GUC for that?
Several platforms support sysconf(_SC_NPROCESSORS_CONF) although after a quick
look it doesn't seem to be standardized. A guc initialized to that or falling
back to 4 or so?
Andres
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2012-09-20 15:55:53 |
| Message-ID: | CA+U5nM+yx=gnYYa_eTMq23k=X669Tp--Tm7Rus8papvzJmY+jg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 20 September 2012 16:29, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> wrote:
> 1. Insert 1000 rows in each transaction. This is exactly the sort of
> workload where WALInsertLock currently becomes a bottleneck. Without the the
> patch, the test scales very badly, with about 420 TPS with a single client,
> peaking only at 520 TPS with two clients. With the patch, it scales up to
> about 1200 TPS, with 7 clients. I believe the test becomes I/O limited at
> that point; looking at iostat output while the test is running shows about
> 200MB/s of writes, and that is roughly what the I/O subsystem of this
> machine can do, according to a simple test with 'dd ...; sync". Or perhaps
> having more "insertion slots" would allow it to go higher - the patch uses
> exactly 7 slots at the moment.
>
> http://hlinnaka.iki.fi/xloginsert-scaling/results-1k/
>
> 2. Insert only 10 rows in each transaction. This simulates an OLTP workload
> with fairly small transactions. The patch doesn't make a huge difference
> with that workload. It performs somewhat worse with 4-16 clients, but then
> somewhat better with > 16 clients. The patch adds some overhead to flushing
> the WAL, I believe that's what's causing the slowdown with 4-16 clients. But
> with more clients, the WALInsertLock bottleneck becomes more significant,
> and you start to see a benefit again.
>
> http://hlinnaka.iki.fi/xloginsert-scaling/results-10/
>
> Overall, the results look pretty good.
Yes, excellent work.
The results seem sensitive to the use case, so my thoughts immediately
switch to auto-tuning or at least appropriate usage.
I'm a bit worried that its a narrow use case, since the problem
quickly moves from lock contention to I/O limiting.
It sounds like the use case where this is a win would be parallel data
loading into a high I/O bandwidth server. Could we do some more
tests/discuss to see how wide the use case is?
I'm also wondering about this from a different perspective. I was
looking to rate-limit WAL inserts from certain operations - would
rate-limiting remove the contention problem, or is that just a
different feature.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2012-09-20 16:21:09 |
| Message-ID: | 505B4275.4020400@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 20.09.2012 18:37, Tom Lane wrote:
> I suspect that it's not a coincidence that you're seeing
> a sweet spot for #slots ~= #CPUs.
Yeah, quite possible. I did not test with any different number of slots,
so I don't know if that's the sweet spot, but I wouldn't be surprised if
it is.
> If that is what's happening, we're going to want to be able to
> configure the #slots at postmaster start. Not sure how we'd go about
> it exactly - is there any reasonably portable way to find out how
> many CPUs the machine has? Or do we have to use a GUC for that?
Detecting the number of CPUs and using that might not be optimal. Even
with a machine with a lot of CPUs, a workload might not be limited by
WAL insertion speed. Perhaps we could have a counter of how often you
have to wait for a slot, and adjust the number of slots on the fly based
on that. Similar to the way the spinlock delay is adjusted.
At the moment, I'm grabbing the lock on a slot before determining which
blocks need to be backed up because of full_page_writes, and before
calculating the CRCs. I can try to move that so that the lock is grabbed
later, more like the WALInsertLock currently works. That would make the
duration the slot locks are held much shorter, which probably would make
the number of slots less important.
- Heikki
| From: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2012-09-24 18:06:06 |
| Message-ID: | CAHGQGwHqT=xZ0JEgXB4XLWXj67F7p0NgL+6syGw0NO7Qzg_G0w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Sep 21, 2012 at 12:29 AM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> I've been slowly continuing to work that I started last winder to make
> XLogInsert scale better. I have tried quite a few different approaches since
> then, and have settled on the attached. This is similar but not exactly the
> same as what I did in the patches I posted earlier.
>
> The basic idea, like before, is to split WAL insertion into two phases:
>
> 1. Reserve the right amount of WAL. This is done while holding just a
> spinlock. Thanks to the changes I made earlier to the WAL format, the space
> calculations are now much simpler and the critical section boils down to
> almost just "CurBytePos += size_of_wal_record". See
> ReserveXLogInsertLocation() function.
>
> 2. Copy the WAL record to the right location in the WAL buffers. This slower
> part can be done mostly in parallel.
>
> The difficult part is tracking which insertions are currently in progress,
> and being able to wait for an insertion to finish copying the record data in
> place. I'm using a small number (7 at the moment) of WAL insertion slots for
> that. The first thing that XLogInsert does is to grab one of the slots. Each
> slot is protected by a LWLock, and XLogInsert reserves a slot by acquiring
> its lock. It holds the lock until it has completely finished copying the WAL
> record in place. In each slot, there's an XLogRecPtr that indicates how far
> the current inserter has progressed with its insertion. Typically, for a
> short record that fits on a single page, it is updated after the insertion
> is finished, but if the insertion needs to wait for a WAL buffer to become
> available, it updates the XLogRecPtr before sleeping.
>
> To wait for all insertions up to a point to finish, you scan all the
> insertion slots, and observe that the XLogRecPtrs in them are >= the point
> you're interested in. The number of slots is a tradeoff: more slots allow
> more concurrency in inserting records, but makes it slower to determine how
> far it can be safely flushed.
>
> I did some performance tests with this, on an 8-core HP Proliant server, in
> a VM running under VMware vSphere 5.1. The tests were performed with Greg
> Smith's pgbench-tools kit, with one of two custom workload scripts:
>
> 1. Insert 1000 rows in each transaction. This is exactly the sort of
> workload where WALInsertLock currently becomes a bottleneck. Without the the
> patch, the test scales very badly, with about 420 TPS with a single client,
> peaking only at 520 TPS with two clients. With the patch, it scales up to
> about 1200 TPS, with 7 clients. I believe the test becomes I/O limited at
> that point; looking at iostat output while the test is running shows about
> 200MB/s of writes, and that is roughly what the I/O subsystem of this
> machine can do, according to a simple test with 'dd ...; sync". Or perhaps
> having more "insertion slots" would allow it to go higher - the patch uses
> exactly 7 slots at the moment.
>
> http://hlinnaka.iki.fi/xloginsert-scaling/results-1k/
>
> 2. Insert only 10 rows in each transaction. This simulates an OLTP workload
> with fairly small transactions. The patch doesn't make a huge difference
> with that workload. It performs somewhat worse with 4-16 clients, but then
> somewhat better with > 16 clients. The patch adds some overhead to flushing
> the WAL, I believe that's what's causing the slowdown with 4-16 clients. But
> with more clients, the WALInsertLock bottleneck becomes more significant,
> and you start to see a benefit again.
>
> http://hlinnaka.iki.fi/xloginsert-scaling/results-10/
>
> Overall, the results look pretty good. I'm going to take a closer look at
> the slowdown in the second test. I think it might be fixable with some
> changes to how WaitInsertionsToFinish() and WALWriteLock work together,
> although I'm not sure how exactly it ought to work.
>
> Comments, ideas?
Sounds good.
The patch could be applied cleanly and the compile could be successfully done.
But when I ran initdb, I got the following assertion error:
------------------------------------------
$ initdb -D data --locale=C --encoding=UTF-8
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "C".
The default text search configuration will be set to "english".
creating directory data ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
creating configuration files ... ok
creating template1 database in data/base/1 ... ok
initializing pg_authid ... ok
initializing dependencies ... TRAP: FailedAssertion("!(((uint64)
currpos) % 8192 >= (((intptr_t) ((sizeof(XLogPageHeaderData))) + ((8)
- 1)) & ~((intptr_t) ((8) - 1))) || rdata_len == 0)", File: "xlog.c",
Line: 1363)
sh: line 1: 29537 Abort trap: 6 "/dav/hoge/bin/postgres"
--single -F -O -c search_path=pg_catalog -c exit_on_error=true
template1 > /dev/null
child process exited with exit code 134
initdb: removing data directory "data"
------------------------------------------
I got the above problem on MacOS:
$ uname -a
Darwin hrk.local 11.4.0 Darwin Kernel Version 11.4.0: Mon Apr 9
19:32:15 PDT 2012; root:xnu-1699.26.8~1/RELEASE_X86_64 x86_64
Regards,
--
Fujii Masao
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2012-09-27 15:58:18 |
| Message-ID: | 5064779A.3050407@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24.09.2012 21:06, Fujii Masao wrote:
> The patch could be applied cleanly and the compile could be successfully done.
Thanks for the testing!
> But when I ran initdb, I got the following assertion error:
>
> ------------------------------------------
> $ initdb -D data --locale=C --encoding=UTF-8
> The files belonging to this database system will be owned by user "postgres".
> This user must also own the server process.
>
> The database cluster will be initialized with locale "C".
> The default text search configuration will be set to "english".
>
> creating directory data ... ok
> creating subdirectories ... ok
> selecting default max_connections ... 100
> selecting default shared_buffers ... 128MB
> creating configuration files ... ok
> creating template1 database in data/base/1 ... ok
> initializing pg_authid ... ok
> initializing dependencies ... TRAP: FailedAssertion("!(((uint64)
> currpos) % 8192>= (((intptr_t) ((sizeof(XLogPageHeaderData))) + ((8)
> - 1))& ~((intptr_t) ((8) - 1))) || rdata_len == 0)", File: "xlog.c",
> Line: 1363)
> sh: line 1: 29537 Abort trap: 6 "/dav/hoge/bin/postgres"
> --single -F -O -c search_path=pg_catalog -c exit_on_error=true
> template1> /dev/null
> child process exited with exit code 134
> initdb: removing data directory "data"
> ------------------------------------------
>
> I got the above problem on MacOS:
Hmm, I cannot reproduce this on my Linux laptop. However, I think I see
what the problem is: the assertion should assert that (*CurrPos* %
XLOG_BLCKZ >= SizeOfXLogShortPHD), not currpos. The former is an
XLogRecPtr, the latter is a pointer. If the WAL buffers are aligned at
8k boundaries, the effect is the same, but otherwise the assertion is
just wrong. And as it happens, if O_DIRECT is defined, we align WAL
buffers at XLOG_BLCKSZ. I think that's why I don't see this on my
laptop. Does Mac OS X not define O_DIRECT?
Anyway, attached is a patch with that fixed.
- Heikki
| Attachment | Content-Type | Size |
|---|---|---|
| xloginsert-scale-21.patch.gz | application/x-gzip | 24.6 KB |
| From: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2012-09-28 19:09:53 |
| Message-ID: | CAHGQGwGJYD=TZgqLXB57s-ZoWVeQ8FLLGzPAKDM84+s4Uf8shw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Sep 28, 2012 at 12:58 AM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> Hmm, I cannot reproduce this on my Linux laptop. However, I think I see what
> the problem is: the assertion should assert that (*CurrPos* % XLOG_BLCKZ >=
> SizeOfXLogShortPHD), not currpos. The former is an XLogRecPtr, the latter is
> a pointer. If the WAL buffers are aligned at 8k boundaries, the effect is
> the same, but otherwise the assertion is just wrong. And as it happens, if
> O_DIRECT is defined, we align WAL buffers at XLOG_BLCKSZ. I think that's why
> I don't see this on my laptop. Does Mac OS X not define O_DIRECT?
Yes, AFAIK Mac OS doesn't support O_DIRECT.
> Anyway, attached is a patch with that fixed.
Thanks! In new patch, initdb was successfully completed.
I encountered another strange issue: When I called pg_switch_xlog() while
pgbench -j 1 -c 1 -T 600 is running, both pg_switch_xlog() and all connections
of pgbench got stuck.
Here is the backtrace of stuck pg_switch_xlog():
(gdb) bt
#0 0x00007fff8fe13c46 in semop ()
#1 0x0000000106b97d34 in PGSemaphoreLock ()
#2 0x0000000106a2e8cf in WaitXLogInsertionsToFinish ()
#3 0x0000000106a2fe8b in XLogInsert ()
#4 0x0000000106a30576 in RequestXLogSwitch ()
#5 0x0000000106a37950 in pg_switch_xlog ()
#6 0x0000000106b19bd3 in ExecMakeFunctionResult ()
#7 0x0000000106b14be1 in ExecProject ()
#8 0x0000000106b2b83d in ExecResult ()
#9 0x0000000106b14000 in ExecProcNode ()
#10 0x0000000106b13080 in standard_ExecutorRun ()
#11 0x0000000106be919f in PortalRunSelect ()
#12 0x0000000106bea5c9 in PortalRun ()
#13 0x0000000106be8519 in PostgresMain ()
#14 0x0000000106ba4ef9 in PostmasterMain ()
#15 0x0000000106b418f1 in main ()
Here is the backtrace of stuck pgbench connection:
(gdb) bt
#0 0x00007fff8fe13c46 in semop ()
#1 0x0000000106b97d34 in PGSemaphoreLock ()
#2 0x0000000106bda95e in LWLockAcquireWithCondVal ()
#3 0x0000000106a25556 in WALInsertLockAcquire ()
#4 0x0000000106a2fa8a in XLogInsert ()
#5 0x0000000106a0386d in heap_update ()
#6 0x0000000106b2a03e in ExecModifyTable ()
#7 0x0000000106b14010 in ExecProcNode ()
#8 0x0000000106b13080 in standard_ExecutorRun ()
#9 0x0000000106be9ceb in ProcessQuery ()
#10 0x0000000106be9eec in PortalRunMulti ()
#11 0x0000000106bea71e in PortalRun ()
#12 0x0000000106be8519 in PostgresMain ()
#13 0x0000000106ba4ef9 in PostmasterMain ()
#14 0x0000000106b418f1 in main ()
Though I've not read the patch yet, probably lock mechanism
in XLogInsert would have a bug which causes the above problem.
Regards,
--
Fujii Masao
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgreSQL(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-05-28 17:48:02 |
| Message-ID: | 20130528174801.GX15045@eldon.alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Heikki Linnakangas wrote:
> I've been slowly continuing to work that I started last winder to
> make XLogInsert scale better. I have tried quite a few different
> approaches since then, and have settled on the attached. This is
> similar but not exactly the same as what I did in the patches I
> posted earlier.
Did this go anywhere?
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgreSQL(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-05-29 17:40:48 |
| Message-ID: | 51A63DA0.1010309@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 28.05.2013 20:48, Alvaro Herrera wrote:
> Heikki Linnakangas wrote:
>> I've been slowly continuing to work that I started last winder to
>> make XLogInsert scale better. I have tried quite a few different
>> approaches since then, and have settled on the attached. This is
>> similar but not exactly the same as what I did in the patches I
>> posted earlier.
>
> Did this go anywhere?
Thanks for asking :-). I've been fixing bitrot throughout the winter. I
just started cleaning it up again last week, and also continued with
performance testing.
Unfortunately I lost the 8-core box I used earlier to test this, to disk
failure, so I can't repeat the tests I ran earlier. However, I have
access to a new 32-core box, the attached results are from that.
I've ran a whole bunch of tests with this in various configurations, and
have no longer been able to find a case where the patch would perform
worse than what we have now. In cases where WALInsertLock is not a
bottleneck, it's a wash, but in general, write-heavy workloads benefit.
Here, I've attached the results from one test case. The test case is
inserting 10 rows in a transaction: "insert into foo select
generate_series(1,10)". I used pgbench-tools to run the tests. The data
directory was put on a RAM drive (tmpfs), to eliminate disk as the
bottleneck. The test runs were very small, only 30s each, but I don't
see much jitter in the resulting plots, so I think that's ok.
I should mention that I also had the attached spinlock patch applied in
all the runs, baseline and patched. I'm not sure how much difference it
made in this particular case, but it made a big difference in some
tests, see http://www.postgresql.org/message-id/519A938A.1070903@vmware.com.
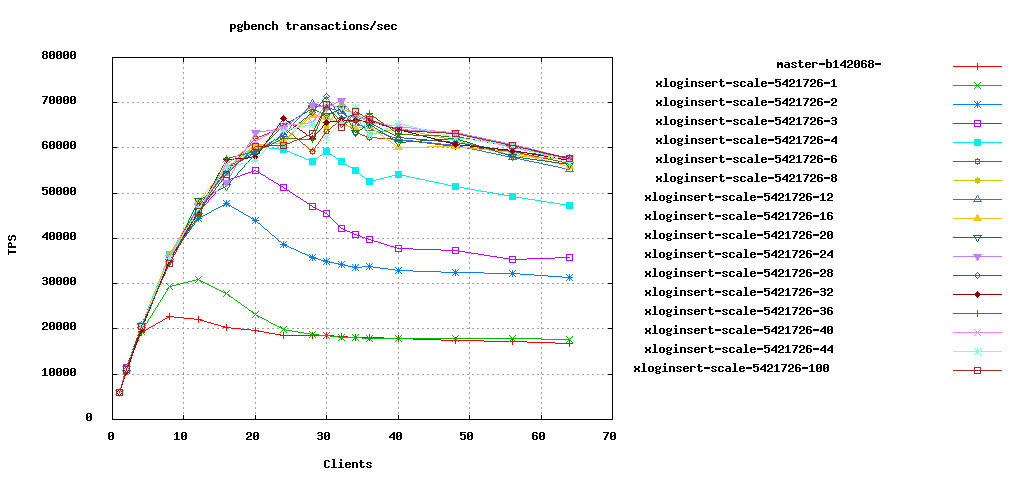
See attached image, insert10-clients-sets.png. The red line,
"master-b142068-" is the baseline run with a 9.3 checkout of that
commitid. The other lines are with the attached patch (*), with
different numbers of "slots". Back in September, Tom was worried that I
only ran the tests with 7 slots, which happened to be almost the same as
the number of cores; this test shows the effect of the number of slots.
It's now controlled by a GUC, num_xloginsert_slots.
To my surpise, the patch seems to be beneficial in this test even with
num_xloginsert_slots=1. The green line, "xloginsert-scale-5421726-1" is
higher than the baseline between 8 - 24 clients. I did not expect that;
num_xloginsert_slots=1 doesn't allow any more concurrency than the
single WALInsertLock we have without the patch. I'm not sure what's
going on there - maybe the fact that WAL pages are now initialized by
WAL writer in the background helps - but can't complain I guess. In some
other test scenarios, I saw num_xloginsert_slots=1 to perform worse than
unpatched code, but num_xloginsert_slots=2 already shows a benefit in
all the scenarios I've tried.
The optimal setting on this box seems to be num_xloginsert_slots >= 8.
Smaller values perform worse, but raising it higher makes little difference.
Overall, I'm really pleased with the performance of this now. But I'd
appreciate it if others would run this on different hardware and
different workloads, to verify that I haven't missed something.
One little thing that's broken at the moment is commit_delay. The code
is safe as it stands, but you won't see any performance benefit from
commit_delay because it doesn't try to flush any more WAL after the
delay than before it. That shouldn't be hard to fix, just haven't gotten
around to it.
(*) actually, an older version of the patch, but I haven't changed
anything substantial since, at least not on purpose, just moved code
around and fixed comments.
- Heikki
| Attachment | Content-Type | Size |
|---|---|---|
| xloginsert-scale-22.patch.gz | application/x-gzip | 26.2 KB |
|
image/png | 14.6 KB |
| unlocked-spin.patch | text/x-diff | 377 bytes |
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-05-30 00:46:00 |
| Message-ID: | CA+CSw_ucP1PY_0kFWDmaS3_VzcG4cmrZTV9UZY2F17jUp_4mvQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, May 29, 2013 at 8:40 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> Thanks for asking :-). I've been fixing bitrot throughout the winter. I just
> started cleaning it up again last week, and also continued with performance
> testing.
>
> Unfortunately I lost the 8-core box I used earlier to test this, to disk
> failure, so I can't repeat the tests I ran earlier. However, I have access
> to a new 32-core box, the attached results are from that.
The results look great!
Is this 32 physical cores or with hyperthreading? If the former, then
did you profile what is behind the sublinear scaling at concurrency
>8?
Shouldn't the pg_write_barrier in AdvanceXLInsertBuffer be
complemented with pg_read_barrier after reading the value of xlblocks
in GetXLogBuffer? It might not be needed if some other action is
providing the barrier, but in that case I think it deserves a comment
why it's not needed so future refactorings don't create a data race.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-18 18:17:56 |
| Message-ID: | CAMkU=1wWKjXp-X=Sv2qV-czZ71AcQW5DT5o+Q2EXwsfhmkpdsA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi Heikki,
I am getting conflicts applying version 22 of this patch to 9.4dev. Could
you rebase?
Does anyone know of an easy way to apply an external patch through git, so
I can get git-style merge conflict markers, rather than getting patch's
reject file?
Cheers,
Jeff
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-19 06:28:33 |
| Message-ID: | 51C14F91.70702@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 18.06.2013 21:17, Jeff Janes wrote:
> Hi Heikki,
>
> I am getting conflicts applying version 22 of this patch to 9.4dev. Could
> you rebase?
Here you go.
> Does anyone know of an easy way to apply an external patch through git, so
> I can get git-style merge conflict markers, rather than getting patch's
> reject file?
I've been wishing for that too. You can check out an older version of
the branch, one that the patch applies cleanly to, and then merge
forward. But that's cumbersome.
- Heikki
| Attachment | Content-Type | Size |
|---|---|---|
| xloginsert-scale-23.patch.gz | application/x-gzip | 26.2 KB |
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-21 18:55:02 |
| Message-ID: | CAMkU=1yvfWsQ4YV2k-kDvRAmA39F2RzgPqpZRUVz0vref4Mwrg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jun 18, 2013 at 11:28 PM, Heikki Linnakangas <
hlinnakangas(at)vmware(dot)com> wrote:
> On 18.06.2013 21:17, Jeff Janes wrote:
>
>> Hi Heikki,
>>
>> I am getting conflicts applying version 22 of this patch to 9.4dev. Could
>> you rebase?
>>
>
> Here you go.
I think I'm getting an undetected deadlock between the checkpointer and a
user process running a TRUNCATE command.
This is the checkpointer:
#0 0x0000003a73eeaf37 in semop () from /lib64/libc.so.6
#1 0x00000000005ff847 in PGSemaphoreLock (sema=0x7f8c0a4eb730,
interruptOK=0 '\000') at pg_sema.c:415
#2 0x00000000004b0abf in WaitOnSlot (upto=416178159648) at xlog.c:1775
#3 WaitXLogInsertionsToFinish (upto=416178159648) at xlog.c:2086
#4 0x00000000004b657a in CopyXLogRecordToWAL (write_len=32, isLogSwitch=1
'\001', rdata=0x0, StartPos=<value optimized out>, EndPos=416192397312)
at xlog.c:1389
#5 0x00000000004b6fb2 in XLogInsert (rmid=0 '\000', info=<value optimized
out>, rdata=0x7fff00000020) at xlog.c:1209
#6 0x00000000004b7644 in RequestXLogSwitch () at xlog.c:8748
#7 0x0000000000611be3 in CheckArchiveTimeout () at checkpointer.c:622
#8 0x0000000000611d97 in CheckpointWriteDelay (flags=<value optimized
out>, progress=<value optimized out>) at checkpointer.c:705
#9 0x000000000062ec5a in BufferSync (flags=64) at bufmgr.c:1322
#10 CheckPointBuffers (flags=64) at bufmgr.c:1828
#11 0x00000000004b1393 in CheckPointGuts (checkPointRedo=416178159592,
flags=64) at xlog.c:8365
#12 0x00000000004b8ff3 in CreateCheckPoint (flags=64) at xlog.c:8148
#13 0x00000000006121c3 in CheckpointerMain () at checkpointer.c:502
#14 0x00000000004c4c4a in AuxiliaryProcessMain (argc=2,
argv=0x7fff21c4a5d0) at bootstrap.c:439
#15 0x000000000060a68c in StartChildProcess (type=CheckpointerProcess) at
postmaster.c:4954
#16 0x000000000060d1ea in reaper (postgres_signal_arg=<value optimized
out>) at postmaster.c:2571
#17 <signal handler called>
#18 0x0000003a73ee14d3 in __select_nocancel () from /lib64/libc.so.6
#19 0x000000000060efee in ServerLoop (argc=<value optimized out>,
argv=<value optimized out>) at postmaster.c:1537
#20 PostmasterMain (argc=<value optimized out>, argv=<value optimized out>)
at postmaster.c:1246
#21 0x00000000005ad4e0 in main (argc=3, argv=0x179fd00) at main.c:196
And this is the TRUNCATE command.
#0 0x0000003a73eeaf37 in semop () from /lib64/libc.so.6
#1 0x00000000005ff847 in PGSemaphoreLock (sema=0x7f8c0a4ea8d0,
interruptOK=0 '\000') at pg_sema.c:415
#2 0x00000000004b002d in WALInsertSlotAcquireOne (slotno=-1) at xlog.c:1667
#3 0x00000000004b6d5d in XLogInsert (rmid=0 '\000', info=<value optimized
out>, rdata=0x7fff21c4a5e0) at xlog.c:1115
#4 0x00000000004b8abc in XLogPutNextOid (nextOid=67198981) at xlog.c:8704
#5 0x00000000004a3bc2 in GetNewObjectId () at varsup.c:495
#6 0x00000000004c5195 in GetNewRelFileNode (reltablespace=<value optimized
out>, pg_class=0x0, relpersistence=<value optimized out>) at catalog.c:437
#7 0x000000000070f52d in RelationSetNewRelfilenode
(relation=0x7f8c019cb2a0, freezeXid=2144367079, minmulti=1) at
relcache.c:2758
#8 0x000000000055de61 in ExecuteTruncate (stmt=<value optimized out>) at
tablecmds.c:1163
#9 0x0000000000656080 in standard_ProcessUtility (parsetree=0x2058900,
queryString=<value optimized out>, context=<value optimized out>,
params=0x0,
dest=<value optimized out>, completionTag=<value optimized out>) at
utility.c:552
#10 0x0000000000652a87 in PortalRunUtility (portal=0x17bf510,
utilityStmt=0x2058900, isTopLevel=1 '\001', dest=0x2058c40,
completionTag=0x7fff21c4a9a0 "")
at pquery.c:1187
#11 0x00000000006539fd in PortalRunMulti (portal=0x17bf510, isTopLevel=1
'\001', dest=0x2058c40, altdest=0x2058c40, completionTag=0x7fff21c4a9a0 "")
at pquery.c:1318
#12 0x00000000006540b3 in PortalRun (portal=0x17bf510,
count=9223372036854775807, isTopLevel=1 '\001', dest=0x2058c40,
altdest=0x2058c40,
completionTag=0x7fff21c4a9a0 "") at pquery.c:816
#13 0x0000000000650944 in exec_simple_query (query_string=0x2057e90
"truncate foo") at postgres.c:1048
#14 0x0000000000651fe9 in PostgresMain (argc=<value optimized out>,
argv=<value optimized out>, dbname=0x1fc9e98 "jjanes", username=<value
optimized out>)
at postgres.c:3985
#15 0x000000000060f80b in BackendRun (argc=<value optimized out>,
argv=<value optimized out>) at postmaster.c:3987
#16 BackendStartup (argc=<value optimized out>, argv=<value optimized out>)
at postmaster.c:3676
#17 ServerLoop (argc=<value optimized out>, argv=<value optimized out>) at
postmaster.c:1577
#18 PostmasterMain (argc=<value optimized out>, argv=<value optimized out>)
at postmaster.c:1246
#19 0x00000000005ad4e0 in main (argc=3, argv=0x179fd00) at main.c:196
This is using the same testing harness as in the last round of this patch.
Is there a way for me to dump the list of held/waiting lwlocks from gdb?
Cheers,
Jeff
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-22 11:32:46 |
| Message-ID: | 51C58B5E.7030102@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21.06.2013 21:55, Jeff Janes wrote:
> I think I'm getting an undetected deadlock between the checkpointer and a
> user process running a TRUNCATE command.
>
> This is the checkpointer:
>
> #0 0x0000003a73eeaf37 in semop () from /lib64/libc.so.6
> #1 0x00000000005ff847 in PGSemaphoreLock (sema=0x7f8c0a4eb730,
> interruptOK=0 '\000') at pg_sema.c:415
> #2 0x00000000004b0abf in WaitOnSlot (upto=416178159648) at xlog.c:1775
> #3 WaitXLogInsertionsToFinish (upto=416178159648) at xlog.c:2086
> #4 0x00000000004b657a in CopyXLogRecordToWAL (write_len=32, isLogSwitch=1
> '\001', rdata=0x0, StartPos=<value optimized out>, EndPos=416192397312)
> at xlog.c:1389
> #5 0x00000000004b6fb2 in XLogInsert (rmid=0 '\000', info=<value optimized
> out>, rdata=0x7fff00000020) at xlog.c:1209
> #6 0x00000000004b7644 in RequestXLogSwitch () at xlog.c:8748
Hmm, it looks like the xlog-switch is trying to wait for itself to
finish. The concurrent TRUNCATE is just being blocked behind the
xlog-switch, which is stuck on itself.
I wasn't able to reproduce exactly that, but I got a PANIC by running
pgbench and concurrently doing "select pg_switch_xlog()" many times in psql.
Attached is a new version that fixes at least the problem I saw. Not
sure if it fixes what you saw, but it's worth a try. How easily can you
reproduce that?
> This is using the same testing harness as in the last round of this patch.
> Is there a way for me to dump the list of held/waiting lwlocks from gdb?
You can print out the held_lwlocks array. Or to make it more friendly,
write a function that prints it out and call that from gdb. There's no
easy way to print out who's waiting for what that I know of.
Thanks for the testing!
- Heikki
| Attachment | Content-Type | Size |
|---|---|---|
| xloginsert-scale-24.patch.gz | application/x-gzip | 26.5 KB |
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-24 18:01:01 |
| Message-ID: | 20130624180101.GJ6471@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-06-22 14:32:46 +0300, Heikki Linnakangas wrote:
> Attached is a new version that fixes at least the problem I saw. Not sure if
> it fixes what you saw, but it's worth a try. How easily can you reproduce
> that?
Ok, I started to look at this:
* Could you document the way slots prevent checkpoints from occurring
when XLogInsert rechecks for full page writes? I think it's correct -
but not very obvious on a glance.
* The read of Insert->RedoRecPtr while rechecking whether it's out of
date now is unlocked, is that correct? And why?
* Have you measured whether it works to just keep as many slots as
max_backends requires around and not bothering with dynamically
allocating them to inserters?
That seems to require to keep actually waiting slots in a separate
list which very well might make that too expensive.
Correctness wise the biggest problem for that probably is exlusive
acquiration of all slots CreateCheckpoint() does...
* What about using some sort of linked list of unused slots for
WALInsertSlotAcquireOne? Everytime we're done we put it to the *end*
of the list so it's less likely to have been grabbed by somebody else
so we can reuse it.
a) To grab a new one go to the head of the linked list spinlock it and
recheck whether it's still free. If not, restart. Otherwise, remove
from list.
b) To reuse a previously used slot
That way we only have to do the PGSemaphoreLock() dance if there
really aren't any free slots.
* The queuing logic around slots seems to lack documentation. It's
complex enough to warrant that imo.
* Not a big fan of the "holdingAll" variable name, for a file-global one
that seems a bit too generic.
* Could you add a #define or comment for the 64 used in
XLogInsertSlotPadded? Not everyone might recognize that immediately as
the most common cacheline size.
Commenting on the reason we pad in general would be a good idea as
well.
* Is it correct that WALInsertSlotAcquireOne() resets xlogInsertingAt of
all slots *before* it has acquired locks in all of them? If yes, why
haven't we already reset it to something invalid?
* Is GetXLogBuffer()'s unlocked read correct without a read barrier?
* XLogBytePosToEndRecPtr() seems to have a confusing name to me. At
least the comment needs to better explain that it's named that way
because of the way it's used.
Also, doesn't
seg_offset += fullpages * XLOG_BLCKSZ + bytesleft + SizeOfXLogShortPHD;
potentially point into the middle of a page?
* I wish we could get rid of the bytepos notion, it - while rather
clever - complicates things. But that's probably not going to happen
unless we get rid of short/long page headers :/
Cool stuff!
Greetings,
Andres Freund
PS: Btw, git diff|... -w might be more helpful than not indenting a
block.
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-25 21:18:01 |
| Message-ID: | CAMkU=1wEz3bhbY9KuRoYZh-7tXajXr95w36tgBCPFD4KfmLYjg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Jun 22, 2013 at 4:32 AM, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com
> wrote:
> On 21.06.2013 21:55, Jeff Janes wrote:
>
>>
>> Hmm, it looks like the xlog-switch is trying to wait for itself to
> finish. The concurrent TRUNCATE is just being blocked behind the
> xlog-switch, which is stuck on itself.
>
> I wasn't able to reproduce exactly that, but I got a PANIC by running
> pgbench and concurrently doing "select pg_switch_xlog()" many times in psql.
>
> Attached is a new version that fixes at least the problem I saw. Not sure
> if it fixes what you saw, but it's worth a try. How easily can you
> reproduce that?
With v23, it got stuck both times I tried it, once after 4 hours and once
after 6 hours.
With v24, it has been running for 30 hours so far with no problems. So
there is a pretty good chance that it is fixed.
>
> This is using the same testing harness as in the last round of this patch.
>>
>
> This one? http://www.postgresql.org/**message-id/CAMkU=1xoA6Fdyoj_**
> 4fMLqpicZR1V9GP7cLnXJdHU+**iGgqb6WUw(at)mail(dot)gmail(dot)com<http://www.postgresql.org/message-id/CAMkU=1xoA6Fdyoj_4fMLqpicZR1V9GP7cLnXJdHU+iGgqb6WUw@mail.gmail.com>
Yes. I have cleaned it up some and added use of checksum, I don't know if
any of those things are needed to invoke the problem.
Cheers,
Jeff
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-26 15:52:30 |
| Message-ID: | 51CB0E3E.5060605@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 24.06.2013 21:01, Andres Freund wrote:
> Ok, I started to look at this:
Thanks!
> * Could you document the way slots prevent checkpoints from occurring
> when XLogInsert rechecks for full page writes? I think it's correct -
> but not very obvious on a glance.
There's this in the comment near the top of the file:
* To update RedoRecPtr or fullPageWrites, one has to make sure that all
* subsequent inserters see the new value. This is done by reserving
all the
* insertion slots before changing the value. XLogInsert reads
RedoRecPtr and
* fullPageWrites after grabbing a slot, so by holding all the slots
* simultaneously, you can ensure that all subsequent inserts see the new
* value. Those fields change very seldom, so we prefer to be fast and
* non-contended when they need to be read, and slow when they're changed.
Does that explain it well enough? XLogInsert holds onto a slot while it
rechecks for full page writes.
> * The read of Insert->RedoRecPtr while rechecking whether it's out of
> date now is unlocked, is that correct? And why?
Same here, XLogInsert holds the slot while rechecking Insert->RedoRecptr.
> * Have you measured whether it works to just keep as many slots as
> max_backends requires around and not bothering with dynamically
> allocating them to inserters?
> That seems to require to keep actually waiting slots in a separate
> list which very well might make that too expensive.
>
> Correctness wise the biggest problem for that probably is exlusive
> acquiration of all slots CreateCheckpoint() does...
Hmm. It wouldn't be much different, each backend would still need to
reserve its own dedicated slot, because it might be held by the a
backend that grabbed all the slots. Also, bgwriter and checkpointer need
to flush the WAL, so they'd need slots too.
More slots make WaitXLogInsertionsToFinish() more expensive, as it has
to loop through all of them. IIRC some earlier pgbench tests I ran
didn't show much difference in performance, whether there were 40 slots
or 100, as long as there was enough of them. I can run some more tests
with even more slots to see how it behaves.
> * What about using some sort of linked list of unused slots for
> WALInsertSlotAcquireOne? Everytime we're done we put it to the *end*
> of the list so it's less likely to have been grabbed by somebody else
> so we can reuse it.
> a) To grab a new one go to the head of the linked list spinlock it and
> recheck whether it's still free. If not, restart. Otherwise, remove
> from list.
> b) To reuse a previously used slot
>
> That way we only have to do the PGSemaphoreLock() dance if there
> really aren't any free slots.
That adds a spinlock acquisition / release into the critical path, to
protect the linked list. I'm trying very hard to avoid serialization
points like that.
While profiling the tests I've done, finding a free slot hasn't shown up
much. So I don't think it's a problem performance-wise as it is, and I
don't think it would make the code simpler.
> * The queuing logic around slots seems to lack documentation. It's
> complex enough to warrant that imo.
Yeah, it's complex. I expanded the comments above XLogInsertSlot, to
explain how xlogInsertingAt works. Did that help, or was it some other
part of that that needs more docs?
> * Not a big fan of the "holdingAll" variable name, for a file-global one
> that seems a bit too generic.
Renamed to holdingAllSlots.
> * Could you add a #define or comment for the 64 used in
> XLogInsertSlotPadded? Not everyone might recognize that immediately as
> the most common cacheline size.
> Commenting on the reason we pad in general would be a good idea as
> well.
Copy-pasted and edited the explanation from LWLockPadded for that. I
also changed the way it's allocated so that it's aligned at 64-byte
boundary, like we do for lwlocks.
> * Is it correct that WALInsertSlotAcquireOne() resets xlogInsertingAt of
> all slots *before* it has acquired locks in all of them? If yes, why
> haven't we already reset it to something invalid?
I didn't understand this part. Can you elaborate?
> * Is GetXLogBuffer()'s unlocked read correct without a read barrier?
Hmm. I thought that it was safe because GetXLogBuffer() handles the case
that you get a "torn read" of the 64-bit XLogRecPtr value. But now that
I think of it, I wonder if it's possible for reads/writes to be
reordered so that AdvanceXLInsertBuffer() overwrites WAL data that
another backend has copied onto a page. Something like this:
1. Backend B zeroes a new WAL page, and sets its address in xlblocks
2. Backend A calls GetXLogBuffer(), and gets a pointer to that page
3. Backend A copies the WAL data to the page.
There is no lock acquisition in backend A during those steps, so I think
in theory the writes from step 3 might be reordered to happen before
step 1, so that that step 1 overwrites the WAL data written in step 3.
It sounds crazy, but after reading README.barrier, I don't see anything
that guarantees it won't happen in the weaker memory models.
To be safe, I'll add a full memory barrier to GetXLogBuffer(), and rerun
the benchmarks.
> * XLogBytePosToEndRecPtr() seems to have a confusing name to me. At
> least the comment needs to better explain that it's named that way
> because of the way it's used.
Ok, added a sentence on that. Let me know if that helped or if you have
better suggestions.
> Also, doesn't
> seg_offset += fullpages * XLOG_BLCKSZ + bytesleft + SizeOfXLogShortPHD;
> potentially point into the middle of a page?
Yes. seg_offset is the byte offset from the beginning of the segment,
it's supposed to point in the middle of the page.
> * I wish we could get rid of the bytepos notion, it - while rather
> clever - complicates things. But that's probably not going to happen
> unless we get rid of short/long page headers :/
Yeah. Fortunately its use is quite isolated.
I've attached a new version of the patch, with some additional comments
as mentioned in the above paragraphs. And the memory barrier.
- Heikki
| Attachment | Content-Type | Size |
|---|---|---|
| xloginsert-scale-25.patch.gz | application/x-gzip | 27.2 KB |
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-27 12:27:58 |
| Message-ID: | 20130627122758.GG1254@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 2013-06-26 18:52:30 +0300, Heikki Linnakangas wrote:
> >* Could you document the way slots prevent checkpoints from occurring
> > when XLogInsert rechecks for full page writes? I think it's correct -
> > but not very obvious on a glance.
>
> There's this in the comment near the top of the file:
>
> * To update RedoRecPtr or fullPageWrites, one has to make sure that all
> * subsequent inserters see the new value. This is done by reserving all the
> * insertion slots before changing the value. XLogInsert reads RedoRecPtr
> and
> * fullPageWrites after grabbing a slot, so by holding all the slots
> * simultaneously, you can ensure that all subsequent inserts see the new
> * value. Those fields change very seldom, so we prefer to be fast and
> * non-contended when they need to be read, and slow when they're changed.
>
> Does that explain it well enough? XLogInsert holds onto a slot while it
> rechecks for full page writes.
Yes. Earlieron that was explained in XLogInsert() - maybe point to the
documentation ontop of the file? The file is too big to expect everyone
to reread the whole file in a new release...
> >* The read of Insert->RedoRecPtr while rechecking whether it's out of
> > date now is unlocked, is that correct? And why?
> Same here, XLogInsert holds the slot while rechecking Insert->RedoRecptr.
I was wondering whether its guaranteed that we don't read a cached
value, but I didn't think of the memory barriers due to the spinlock in
Release/AcquireSlot. I think I thought that release wouldn't acquire the
spinlock at all.
> >* Have you measured whether it works to just keep as many slots as
> > max_backends requires around and not bothering with dynamically
> > allocating them to inserters?
> > That seems to require to keep actually waiting slots in a separate
> > list which very well might make that too expensive.
> >
> > Correctness wise the biggest problem for that probably is exlusive
> > acquiration of all slots CreateCheckpoint() does...
>
> Hmm. It wouldn't be much different, each backend would still need to reserve
> its own dedicated slot, because it might be held by the a backend that
> grabbed all the slots. Also, bgwriter and checkpointer need to flush the
> WAL, so they'd need slots too.
>
> More slots make WaitXLogInsertionsToFinish() more expensive, as it has to
> loop through all of them. IIRC some earlier pgbench tests I ran didn't show
> much difference in performance, whether there were 40 slots or 100, as long
> as there was enough of them. I can run some more tests with even more slots
> to see how it behaves.
In a very quick test I ran previously I did see the slot acquiration in
the profile when using short connections that all did some quick inserts
- which isn't surprising since they tend to all start with the same
slot so they will all fight for the first slots.
Maybe we could ammeliorate that by initializing MySlotNo to
(MyProc->pgprocno % num_xloginsert_slots) when uninitialized? That won't
be completely fair since the number of procs won't usually be a multiple
of num_insert_slots, but I doubt that will be problematic.
> >* What about using some sort of linked list of unused slots for
> > WALInsertSlotAcquireOne? Everytime we're done we put it to the *end*
> > of the list so it's less likely to have been grabbed by somebody else
> > so we can reuse it.
> > a) To grab a new one go to the head of the linked list spinlock it and
> > recheck whether it's still free. If not, restart. Otherwise, remove
> > from list.
> > b) To reuse a previously used slot
> >
> > That way we only have to do the PGSemaphoreLock() dance if there
> > really aren't any free slots.
>
> That adds a spinlock acquisition / release into the critical path, to
> protect the linked list. I'm trying very hard to avoid serialization points
> like that.
Hm. We already have at least one spinlock in that path? Or are you
thinking of a global one protecting the linked list? If so, I think we
should be able to get away with locking individual slots.
IIRC if you never need to delete list elements you can even get away
with a lockless implementation.
> While profiling the tests I've done, finding a free slot hasn't shown up
> much. So I don't think it's a problem performance-wise as it is, and I don't
> think it would make the code simpler.
It sure wouldn't make it simpler. As I said above, I saw the slot
acquiration in a profile when using -C and a short pgbench script (that
just inserts 10 rows).
> >* The queuing logic around slots seems to lack documentation. It's
> > complex enough to warrant that imo.
>
> Yeah, it's complex. I expanded the comments above XLogInsertSlot, to explain
> how xlogInsertingAt works. Did that help, or was it some other part of that
> that needs more docs?
What I don't understand so far is why we don't reset xlogInsertingAt
during SlotReleaseOne. There are places documenting that we don't do so,
but not why unless I missed it.
Do we do this only to have some plausible value for a backend that been
acquired but hasn't copied data yet? If so, why isn't it sufficient to
initialize it in ReserveXLogInsertLocation?
> >* Is it correct that WALInsertSlotAcquireOne() resets xlogInsertingAt of
> > all slots *before* it has acquired locks in all of them? If yes, why
> > haven't we already reset it to something invalid?
> I didn't understand this part. Can you elaborate?
It has to do with my lack of understanding of the above. If there's a
reason not to reset xlogInsertingAt during ReleaseOne() we might have a
problem.
Consider a scenario with num_xloginsert_slots = 2. Slot 0 has been
released but still has xlogInsertingAt = 0/ff00100. Slot 1 is unused.
1) checkpointer: WALInsertSlotAcquire(exclusive)
2) checkpointer: WALInsertSlotAcquireOne(0), clears xlogInsertingAt
3) WaitXLogInsertionsToFinish() checks slot 0's xlogInsertingAt: InvalidXLogRecPtr
4) WaitXLogInsertionsToFinish() checks slot 1's xlogInsertingAt: InvalidXLogRecPtr
2) checkpointer: WALInsertSlotAcquireOne(1), sets xlogInsertingAt = 1
In this case we WaitXLogInsertionsToFinish() could run without getting
blocked and report that everything up to Insert->CurrBytePos has been
finished since all slots have xlogInsertingAt = InvalidXLogRecPtr.
> >* Is GetXLogBuffer()'s unlocked read correct without a read barrier?
>
> Hmm. I thought that it was safe because GetXLogBuffer() handles the case
> that you get a "torn read" of the 64-bit XLogRecPtr value. But now that I
> think of it, I wonder if it's possible for reads/writes to be reordered so
> that AdvanceXLInsertBuffer() overwrites WAL data that another backend has
> copied onto a page. Something like this:
Yea, I am not so much worried about a torn value, but about an out of
date one that looks valid. A barrier sounds good.
> >* XLogBytePosToEndRecPtr() seems to have a confusing name to me. At
> > least the comment needs to better explain that it's named that way
> > because of the way it's used.
>
> Ok, added a sentence on that. Let me know if that helped or if you have
> better suggestions.
Yes, that's better.
> > Also, doesn't
> >seg_offset += fullpages * XLOG_BLCKSZ + bytesleft + SizeOfXLogShortPHD;
> > potentially point into the middle of a page?
>
> Yes. seg_offset is the byte offset from the beginning of the segment, it's
> supposed to point in the middle of the page.
Misunderstood something...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-06-27 17:36:22 |
| Message-ID: | 20130627173622.GO1254@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-06-26 18:52:30 +0300, Heikki Linnakangas wrote:
> There's this in the comment near the top of the file:
Btw, I find the 'you' used in the comment somewhat irritating. Not badly
so, but reading something like:
* When you are about to write
* out WAL, it is important to call WaitXLogInsertionsToFinish() *before*
* acquiring WALWriteLock, to avoid deadlocks. Otherwise you might get stuck
* waiting for an insertion to finish (or at least advance to next
* uninitialized page), while you're holding WALWriteLock.
just seems strange to me. If this directed at plugin authors, maybe, but
it really isn't...
But that's probably a question for a native speaker...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-01 13:40:44 |
| Message-ID: | 20130701134044.GR11516@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-06-26 18:52:30 +0300, Heikki Linnakangas wrote:
> >* Could you document the way slots prevent checkpoints from occurring
> > when XLogInsert rechecks for full page writes? I think it's correct -
> > but not very obvious on a glance.
>
> There's this in the comment near the top of the file:
>
> * To update RedoRecPtr or fullPageWrites, one has to make sure that all
> * subsequent inserters see the new value. This is done by reserving all the
> * insertion slots before changing the value. XLogInsert reads RedoRecPtr
> and
> * fullPageWrites after grabbing a slot, so by holding all the slots
> * simultaneously, you can ensure that all subsequent inserts see the new
> * value. Those fields change very seldom, so we prefer to be fast and
> * non-contended when they need to be read, and slow when they're changed.
>
> Does that explain it well enough? XLogInsert holds onto a slot while it
> rechecks for full page writes.
I am a bit worried about that logic. We're basically reverting to the
old logic whe xlog writing is an exlusive affair. We will have to wait
for all the other queued inserters before we're finished. I am afraid
that that will show up latencywise.
I have two ideas to improve on that:
a) Queue the backend that does WALInsertSlotAcquire(true) at the front
of the exclusive waiters in *AcquireOne. That should be fairly easy.
b) Get rid of WALInsertSlotAcquire(true) by not relying on
blocking all slot acquiration. I think with some trickery we can do that
safely:
In CreateCheckpoint() we first acquire the insertpos_lck and read
CurrBytePos as a recptr. Set some shared memory variable, say,
PseudoRedoRecPtr, that's now used to check whether backup blocks need to
be made. Release insertpos_lck. Then acquire each slot once, but without
holding the other slots. That guarantees that all XLogInsert()ing
backends henceforth see our PseudoRedoRecPtr value. Then just proceed in
CreateCheckpoint() as we're currently doing except computing RedoRecPtr
under a spinlock.
If a backend reads PseudoRedoRecPtr before we've set RedoRecPtr
accordingly, all that happens is that we possibly have written a FPI too
early.
Makes sense?
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-02 16:48:40 |
| Message-ID: | 51D30468.9060704@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27.06.2013 15:27, Andres Freund wrote:
> Hi,
>
> On 2013-06-26 18:52:30 +0300, Heikki Linnakangas wrote:
>>> * Could you document the way slots prevent checkpoints from occurring
>>> when XLogInsert rechecks for full page writes? I think it's correct -
>>> but not very obvious on a glance.
>>
>> There's this in the comment near the top of the file:
>>
>> * To update RedoRecPtr or fullPageWrites, one has to make sure that all
>> * subsequent inserters see the new value. This is done by reserving all the
>> * insertion slots before changing the value. XLogInsert reads RedoRecPtr
>> and
>> * fullPageWrites after grabbing a slot, so by holding all the slots
>> * simultaneously, you can ensure that all subsequent inserts see the new
>> * value. Those fields change very seldom, so we prefer to be fast and
>> * non-contended when they need to be read, and slow when they're changed.
>>
>> Does that explain it well enough? XLogInsert holds onto a slot while it
>> rechecks for full page writes.
>
> Yes. Earlieron that was explained in XLogInsert() - maybe point to the
> documentation ontop of the file? The file is too big to expect everyone
> to reread the whole file in a new release...
>
>>> * The read of Insert->RedoRecPtr while rechecking whether it's out of
>>> date now is unlocked, is that correct? And why?
>
>> Same here, XLogInsert holds the slot while rechecking Insert->RedoRecptr.
>
> I was wondering whether its guaranteed that we don't read a cached
> value, but I didn't think of the memory barriers due to the spinlock in
> Release/AcquireSlot. I think I thought that release wouldn't acquire the
> spinlock at all.
>
>>> * Have you measured whether it works to just keep as many slots as
>>> max_backends requires around and not bothering with dynamically
>>> allocating them to inserters?
>>> That seems to require to keep actually waiting slots in a separate
>>> list which very well might make that too expensive.
>>>
>>> Correctness wise the biggest problem for that probably is exlusive
>>> acquiration of all slots CreateCheckpoint() does...
>>
>> Hmm. It wouldn't be much different, each backend would still need to reserve
>> its own dedicated slot, because it might be held by the a backend that
>> grabbed all the slots. Also, bgwriter and checkpointer need to flush the
>> WAL, so they'd need slots too.
>>
>> More slots make WaitXLogInsertionsToFinish() more expensive, as it has to
>> loop through all of them. IIRC some earlier pgbench tests I ran didn't show
>> much difference in performance, whether there were 40 slots or 100, as long
>> as there was enough of them. I can run some more tests with even more slots
>> to see how it behaves.
>
> In a very quick test I ran previously I did see the slot acquiration in
> the profile when using short connections that all did some quick inserts
> - which isn't surprising since they tend to all start with the same
> slot so they will all fight for the first slots.
>
> Maybe we could ammeliorate that by initializing MySlotNo to
> (MyProc->pgprocno % num_xloginsert_slots) when uninitialized? That won't
> be completely fair since the number of procs won't usually be a multiple
> of num_insert_slots, but I doubt that will be problematic.
>
>>> * What about using some sort of linked list of unused slots for
>>> WALInsertSlotAcquireOne? Everytime we're done we put it to the *end*
>>> of the list so it's less likely to have been grabbed by somebody else
>>> so we can reuse it.
>>> a) To grab a new one go to the head of the linked list spinlock it and
>>> recheck whether it's still free. If not, restart. Otherwise, remove
>>> from list.
>>> b) To reuse a previously used slot
>>>
>>> That way we only have to do the PGSemaphoreLock() dance if there
>>> really aren't any free slots.
>>
>> That adds a spinlock acquisition / release into the critical path, to
>> protect the linked list. I'm trying very hard to avoid serialization points
>> like that.
>
> Hm. We already have at least one spinlock in that path? Or are you
> thinking of a global one protecting the linked list? If so, I think we
> should be able to get away with locking individual slots.
> IIRC if you never need to delete list elements you can even get away
> with a lockless implementation.
>
>> While profiling the tests I've done, finding a free slot hasn't shown up
>> much. So I don't think it's a problem performance-wise as it is, and I don't
>> think it would make the code simpler.
>
> It sure wouldn't make it simpler. As I said above, I saw the slot
> acquiration in a profile when using -C and a short pgbench script (that
> just inserts 10 rows).
>
>>> * The queuing logic around slots seems to lack documentation. It's
>>> complex enough to warrant that imo.
>>
>> Yeah, it's complex. I expanded the comments above XLogInsertSlot, to explain
>> how xlogInsertingAt works. Did that help, or was it some other part of that
>> that needs more docs?
>
> What I don't understand so far is why we don't reset xlogInsertingAt
> during SlotReleaseOne. There are places documenting that we don't do so,
> but not why unless I missed it.
We could reset it in SlotReleaseOne. However, the next inserter that
acquires the slot would then need to set it to a valid value again, in
SlotAcquireOne. Leaving it at its previous value is a convenient way to
have it pre-initialized with some value for the next SlotAcquireOne call
that uses the same slot.
Perhaps that should be changed, just to make the logic easier to
understand. I agree it seems confusing. Another way to initialize
xlogInsertingAt in SlotAcquireOne would be e.g to use an old value
cached in the same backend. Or just always initialize it to 1, which
would force any WaitXLogInsertionsToFinish() call to wait for the
inserter, until it has finished or updated its value. But maybe that
wouldn't make any difference in practice, and would be less bizarre.
> Do we do this only to have some plausible value for a backend that been
> acquired but hasn't copied data yet?
Yes, exactly.
> If so, why isn't it sufficient to
> initialize it in ReserveXLogInsertLocation?
It would be, but then ReserveXLogInsertLocation would need to hold the
slot's spinlock at the same time with insertpos_lck, so that it could
atomically read the current CurrBytePos value and copy it to
xlogInsertingAt. It's important to keep ReserveXLogInsertLocation() as
lightweight as possible, to maximize concurrency.
Unless you initialize it to 1 in SlotAcquireOne - then can update it
after ReserveXLogInsertLocation() at leisure. But then it might not be
worth the extra spinlock acquisition to update at all, until you finish
the insertion and release the slot (or move to next page), making this
identical to the idea that I pondered above.
I'll do some testing with that. If it performs OK, initializing
xlogInsertingAt to 1 is clearer than leaving it at its old value.
- Heikki
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-02 17:15:23 |
| Message-ID: | 20130702171523.GA27409@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-07-02 19:48:40 +0300, Heikki Linnakangas wrote:
> >If so, why isn't it sufficient to
> >initialize it in ReserveXLogInsertLocation?
>
> It would be, but then ReserveXLogInsertLocation would need to hold the
> slot's spinlock at the same time with insertpos_lck, so that it could
> atomically read the current CurrBytePos value and copy it to
> xlogInsertingAt. It's important to keep ReserveXLogInsertLocation() as
> lightweight as possible, to maximize concurrency.
If you make it so that you always acquire the slot's spinlock first and
insertpos_lck after, the scalability shouldn't be any different from
now? Both the duration during which insertpos_lck is held and the
overall amount of atomic ops should be the same?
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 07:45:41 |
| Message-ID: | 51DA6E25.9090204@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01.07.2013 16:40, Andres Freund wrote:
> On 2013-06-26 18:52:30 +0300, Heikki Linnakangas wrote:
>>> * Could you document the way slots prevent checkpoints from occurring
>>> when XLogInsert rechecks for full page writes? I think it's correct -
>>> but not very obvious on a glance.
>>
>> There's this in the comment near the top of the file:
>>
>> * To update RedoRecPtr or fullPageWrites, one has to make sure that all
>> * subsequent inserters see the new value. This is done by reserving all the
>> * insertion slots before changing the value. XLogInsert reads RedoRecPtr
>> and
>> * fullPageWrites after grabbing a slot, so by holding all the slots
>> * simultaneously, you can ensure that all subsequent inserts see the new
>> * value. Those fields change very seldom, so we prefer to be fast and
>> * non-contended when they need to be read, and slow when they're changed.
>>
>> Does that explain it well enough? XLogInsert holds onto a slot while it
>> rechecks for full page writes.
>
> I am a bit worried about that logic. We're basically reverting to the
> old logic whe xlog writing is an exlusive affair. We will have to wait
> for all the other queued inserters before we're finished. I am afraid
> that that will show up latencywise.
A single stall of the xlog-insertion "pipeline" at a checkpoint is
hardly going to be a problem. I wish PostgreSQL was real-time enough for
that to matter, but I think we're very very far from that.
- Heikki
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 09:16:34 |
| Message-ID: | 51DA8372.9010002@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Ok, I've committed this patch now. Finally, phew!
I think I've addressed all your comments about the comments. I moved
some of the comments around: I split up the large one near the top of
the file, moving its paragraphs closer to the code where they apply.
Regarding your performance-related worries: you have good thoughts on
how to improve things, but let's wait until we see some evidence that
there is a problem, before any further optimizations.
I fixed one bug related to aligning the WAL buffers. The patch assumes
WAL buffers to be aligned at a full XLOG_BLCKSZ boundary, but did not
enforce it. That was already happening on platforms with O_DIRECT, which
is why I didn't notice that in testing, but it would've failed on others.
I just remembered one detail that I'm not sure has been mentioned on the
mailing list yet. Per the commit message:
> This has one user-visible change: switching to a new WAL segment with
> pg_switch_xlog() now fills the remaining unused portion of the
> segment with zeros. This potentially adds some overhead, but it has
> been a very common practice by DBA's to clear the "tail" of the
> segment with an external pg_clearxlogtail utility anyway, to make the
> WAL files compress better. With this patch, it's no longer necessary
> to do that.
I simplified the handling of xlogInsertingAt per discussion, and added
the memory barrier to GetXLogBuffer(). I ran again the pgbench tests I
did earlier with the now-committed version of the patch (except for some
comment changes). The results are here:
http://hlinnaka.iki.fi/xloginsert-scaling/xloginsert-scale-26/
I tested three different workloads. with different numbers of "slots",
ranging from 1 to 1000. The tests were run on a 32-core machine, in a
VM. As the baseline, I used a fresh checkout from master branch, with
this one-line patch:
http://www.postgresql.org/message-id/519A938A.1070903@vmware.com. That
patch adjusts the spinlock delay loop, which happens to make a big
difference on this box. We'll have to revisit and apply that patch
separately, but I think that's the correct baseline to test this
xloginsert scaling patch against.
nobranch
--------
This is the "pgbench -N" workload. Throughput is mainly limited by
flushing the WAL at commits. The patch makes no big difference here,
which is good. The point of the test is to demonstrate that the patch
doesn't make WAL flushing noticeably more expensive.
nobranch-sync-commit-off
------------------------
Same as above, but with synchronous_commit=off. Here the patch somewhat.
WAL insertion doesn't seem to be the biggest limiting factor in this
test, but it's nice to see some benefit.
xlogtest
--------
The workload in this test is a single INSERT statement that inserts a
lot of rows: "INSERT INTO foo:client_id SELECT 1 FROM
generate_series(1,100) a, generate_series(1,100) b". Each client inserts
to a separate table, to eliminate as much lock contention as possible,
making the WAL insertion bottleneck as serious as possible (although I'm
not sure how much difference that makes). This pretty much a best case
scenario for this patch.
This test shows a big gain from the patch, as it should. The peak
performance goes from about 35 TPS to 100 TPS. With the patch, I suspect
the test saturates the I/O subsystem at that point. I think it could go
higher with better I/O hardware.
All in all, I'm satisfied enough with this to commit. The default number
of insertion slots, 8, seems to work fine for all the workloads on this
box. We may have to adjust that or other details later, but what it
needs now is more testing by people with different hardware.
Thanks to everyone involved for the review and testing! And if you can,
please review the patch as committed once more.
- Heikki
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 09:22:22 |
| Message-ID: | 51DA84CE.1070909@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 08.07.2013 12:16, Heikki Linnakangas wrote:
> I just remembered one detail that I'm not sure has been mentioned on the
> mailing list yet. Per the commit message:
>
>> This has one user-visible change: switching to a new WAL segment with
>> pg_switch_xlog() now fills the remaining unused portion of the
>> segment with zeros. This potentially adds some overhead, but it has
>> been a very common practice by DBA's to clear the "tail" of the
>> segment with an external pg_clearxlogtail utility anyway, to make the
>> WAL files compress better. With this patch, it's no longer necessary
>> to do that.
Magnus just pointed out over IM that the above also applies to
xlog-switches caused by archive_timeout, not just pg_switch_xlog(). IOW,
all xlog-switch WAL records.
- Heikki
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 09:23:06 |
| Message-ID: | 51DA84FA.4070703@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27.06.2013 20:36, Andres Freund wrote:
> On 2013-06-26 18:52:30 +0300, Heikki Linnakangas wrote:
>> There's this in the comment near the top of the file:
>
> Btw, I find the 'you' used in the comment somewhat irritating. Not badly
> so, but reading something like:
>
> * When you are about to write
> * out WAL, it is important to call WaitXLogInsertionsToFinish() *before*
> * acquiring WALWriteLock, to avoid deadlocks. Otherwise you might get stuck
> * waiting for an insertion to finish (or at least advance to next
> * uninitialized page), while you're holding WALWriteLock.
>
> just seems strange to me. If this directed at plugin authors, maybe, but
> it really isn't...
Agreed, that was bad wording. Fixed.
- Heikki
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 10:21:17 |
| Message-ID: | CA+CSw_vw6+QH90yPZ49batYj9SjDUkK9vWBT0W1PqeN__Aqo0A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jul 8, 2013 at 12:16 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> Ok, I've committed this patch now. Finally, phew!
Fantastic work!
> I simplified the handling of xlogInsertingAt per discussion, and added the
> memory barrier to GetXLogBuffer(). I ran again the pgbench tests I did
> earlier with the now-committed version of the patch (except for some comment
> changes). The results are here:
I can't see a reason why a full memory barrier is needed at
GetXLogBuffer, we just need to ensure that we read the content of the
page after we check the end pointer from xlblocks. A read barrier is
enough here unless there is some other undocumented interaction. I
don't think it matters for performance, but it seems like good
practice to have the barriers exactly matching the documentation.
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Ants Aasma <ants(at)cybertec(dot)at> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 10:38:44 |
| Message-ID: | 51DA96B4.2040609@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 08.07.2013 13:21, Ants Aasma wrote:
> On Mon, Jul 8, 2013 at 12:16 PM, Heikki Linnakangas
> <hlinnakangas(at)vmware(dot)com> wrote:
>> Ok, I've committed this patch now. Finally, phew!
>
> Fantastic work!
>
>> I simplified the handling of xlogInsertingAt per discussion, and added the
>> memory barrier to GetXLogBuffer(). I ran again the pgbench tests I did
>> earlier with the now-committed version of the patch (except for some comment
>> changes). The results are here:
>
> I can't see a reason why a full memory barrier is needed at
> GetXLogBuffer, we just need to ensure that we read the content of the
> page after we check the end pointer from xlblocks. A read barrier is
> enough here unless there is some other undocumented interaction.
GetXLogBuffer() doesn't read the content of the page - it writes to it
(or rather, the caller of GetXLogBarrier() does). The barrier is needed
between reading xlblocks (to check that the buffer contains the right
page), and writing the WAL data to the buffer. README.barrier says that
you need a full memory barrier to separate a load and a store.
- Heikki
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 10:43:27 |
| Message-ID: | 20130708104327.GA7242@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-07-08 10:45:41 +0300, Heikki Linnakangas wrote:
> On 01.07.2013 16:40, Andres Freund wrote:
> >On 2013-06-26 18:52:30 +0300, Heikki Linnakangas wrote:
> >>>* Could you document the way slots prevent checkpoints from occurring
> >>> when XLogInsert rechecks for full page writes? I think it's correct -
> >>> but not very obvious on a glance.
> >>
> >>There's this in the comment near the top of the file:
> >>
> >> * To update RedoRecPtr or fullPageWrites, one has to make sure that all
> >> * subsequent inserters see the new value. This is done by reserving all the
> >> * insertion slots before changing the value. XLogInsert reads RedoRecPtr
> >>and
> >> * fullPageWrites after grabbing a slot, so by holding all the slots
> >> * simultaneously, you can ensure that all subsequent inserts see the new
> >> * value. Those fields change very seldom, so we prefer to be fast and
> >> * non-contended when they need to be read, and slow when they're changed.
> >>
> >>Does that explain it well enough? XLogInsert holds onto a slot while it
> >>rechecks for full page writes.
> >
> >I am a bit worried about that logic. We're basically reverting to the
> >old logic whe xlog writing is an exlusive affair. We will have to wait
> >for all the other queued inserters before we're finished. I am afraid
> >that that will show up latencywise.
>
> A single stall of the xlog-insertion "pipeline" at a checkpoint is hardly
> going to be a problem. I wish PostgreSQL was real-time enough for that to
> matter, but I think we're very very far from that.
Well, the stall won't necessarily be that short. There might be several
backends piling on every insertion slot and waiting - and thus put to
sleep by the kerenl. I am pretty sure it's easy enough to get stalls in
the second range that way.
Sure, there are lots of reasons we don't have all that reliable response
times, but IME the amount of response time jitter is one of the bigger
pain points of postgres. And this feature has a good chance of reducing
that pain noticeably...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Ants Aasma <ants(at)cybertec(dot)at> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Ants Aasma <ants(at)cybertec(dot)at>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 12:53:46 |
| Message-ID: | CA+CSw_t3dJrPHtwjs_d05CNc+3WD1zDkCG1TNTkv5wTbQSOCAA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jul 8, 2013 at 1:38 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> GetXLogBuffer() doesn't read the content of the page - it writes to it (or
> rather, the caller of GetXLogBarrier() does). The barrier is needed between
> reading xlblocks (to check that the buffer contains the right page), and
> writing the WAL data to the buffer. README.barrier says that you need a full
> memory barrier to separate a load and a store.
Indeed you are right. My bad. I somehow thought that every location in
the WAL buffer is written once while it's actually done twice due to
AdvanceXLInsertBuffer() zeroing the page out.
Now thinking about it, if that memset or the full memory barrier in
GetXLogBuffer() ever prove to be a significant overhead, the
initialization could be optimized to avoid zeroing the page.
AdvanceXLInsertBuffer() would only write the header fields,
CopyXLogRecordToWAL() needs to take care to write out zeroes for
alignment padding and xlog switches and always write out xlp_rem_len
and XLP_FIRST_IS_CONTRECORD bit of xlp_info. xlp_info needs to be
split into two 8bit variables so XLP_FIRST_IS_CONTRECORD and
XLP_LONG_HEADER/XLP_BKP_REMOVABLE can be written into disjoint memory
locations. This way all memory locations in xlog buffer page are
stored exactly once and there is no data race between writes making it
possible to omit the barrier from GetXLogBuffer.
WaitXLogInsertionsToFinish() takes care of the memory barrier for
XlogWrite().
Regards,
Ants Aasma
--
Cybertec Schönig & Schönig GmbH
Gröhrmühlgasse 26
A-2700 Wiener Neustadt
Web: http://www.postgresql-support.de
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 20:34:41 |
| Message-ID: | BB3F0D0F-BDCF-45C2-8B89-29B7DEA7424C@gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Jul 8, 2013, at 4:16 AM, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> wrote:
> Ok, I've committed this patch now. Finally, phew!
Woohoo!
...Robert
| From: | Michael Paquier <michael(dot)paquier(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-08 23:00:52 |
| Message-ID: | CAB7nPqSZK8KZj7uW8hWa54cjtxEvmxLjJHvvBWvnVzxfKEOwaQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jul 8, 2013 at 6:16 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> Ok, I've committed this patch now. Finally, phew!
+1. Great patch!
--
Michael
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Michael Paquier <michael(dot)paquier(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-09 09:48:42 |
| Message-ID: | 20130709094842.GB8613@awork2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-07-09 08:00:52 +0900, Michael Paquier wrote:
> On Mon, Jul 8, 2013 at 6:16 PM, Heikki Linnakangas
> <hlinnakangas(at)vmware(dot)com> wrote:
> > Ok, I've committed this patch now. Finally, phew!
> +1. Great patch!
And one more: +1
There seem to be quite some lowhanging fruits to make stuff faster after
this bottleneck is out of the way. The by far biggest thing visible in
profiles seems to be the CRC32 computation atm...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Abhijit Menon-Sen <ams(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-12 06:32:18 |
| Message-ID: | 20130712063218.GB17906@toroid.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
At 2013-07-08 12:16:34 +0300, hlinnakangas(at)vmware(dot)com wrote:
>
> Ok, I've committed this patch now. Finally, phew!
Good.
I'd signed up to review this patch, and did spend some considerable time
on it, but although I managed to understand what was going on (which was
my objective), I didn't find anything useful to say about it beyond what
others had brought up already. Sorry.
> Thanks to everyone involved for the review and testing! And if you
> can, please review the patch as committed once more.
…so I read through the patch as committed again, and it looks good.
Thanks.
-- Abhijit
| From: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-15 17:24:06 |
| Message-ID: | CAHGQGwGFuyR4LMrV=t=WCZc+t2Nra8OuB0KHDzJ_aC_6wGG1-Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jul 8, 2013 at 6:16 PM, Heikki Linnakangas
<hlinnakangas(at)vmware(dot)com> wrote:
> Ok, I've committed this patch now. Finally, phew!
I found that this patch causes the assertion failure. When I set up simple
replication environment and promoted the standby before executing any
transaction on the master, I got the following assertion failure.
2013-07-16 02:22:06 JST sby1 LOG: received promote request
2013-07-16 02:22:06 JST sby1 FATAL: terminating walreceiver process
due to administrator command
2013-07-16 02:22:06 JST sby1 LOG: redo done at 0/20000F0
2013-07-16 02:22:06 JST sby1 LOG: selected new timeline ID: 2
hrk:head-pgsql postgres$ 2013-07-16 02:22:06 JST sby1 LOG: archive
recovery complete
TRAP: FailedAssertion("!(readOff == (XLogCtl->xlblocks[firstIdx] -
8192) % ((uint32) (16 * 1024 * 1024)))", File: "xlog.c", Line: 7048)
2013-07-16 02:22:12 JST sby1 LOG: startup process (PID 37115) was
terminated by signal 6: Abort trap
2013-07-16 02:22:12 JST sby1 LOG: terminating any other active server processes
Regards,
--
Fujii Masao
| From: | Michael Paquier <michael(dot)paquier(at)gmail(dot)com> |
|---|---|
| To: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-16 23:18:13 |
| Message-ID: | CAB7nPqTwh-LRudzo=HNo=YX1qAm+SxrN_1s_7PWJeJzgtMwpzA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jul 16, 2013 at 2:24 AM, Fujii Masao <masao(dot)fujii(at)gmail(dot)com> wrote:
> On Mon, Jul 8, 2013 at 6:16 PM, Heikki Linnakangas
> <hlinnakangas(at)vmware(dot)com> wrote:
>> Ok, I've committed this patch now. Finally, phew!
>
> I found that this patch causes the assertion failure. When I set up simple
> replication environment and promoted the standby before executing any
> transaction on the master, I got the following assertion failure.
>
> 2013-07-16 02:22:06 JST sby1 LOG: received promote request
> 2013-07-16 02:22:06 JST sby1 FATAL: terminating walreceiver process
> due to administrator command
> 2013-07-16 02:22:06 JST sby1 LOG: redo done at 0/20000F0
> 2013-07-16 02:22:06 JST sby1 LOG: selected new timeline ID: 2
> hrk:head-pgsql postgres$ 2013-07-16 02:22:06 JST sby1 LOG: archive
> recovery complete
> TRAP: FailedAssertion("!(readOff == (XLogCtl->xlblocks[firstIdx] -
> 8192) % ((uint32) (16 * 1024 * 1024)))", File: "xlog.c", Line: 7048)
> 2013-07-16 02:22:12 JST sby1 LOG: startup process (PID 37115) was
> terminated by signal 6: Abort trap
> 2013-07-16 02:22:12 JST sby1 LOG: terminating any other active server processes
Note that this is also reproducible even when trying to recover only
from archives without strrep.
Regards,
--
Michael
| From: | Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
|---|---|
| To: | "'Heikki Linnakangas'" <hlinnakangas(at)vmware(dot)com>, "'Andres Freund'" <andres(at)2ndquadrant(dot)com> |
| Cc: | "'Jeff Janes'" <jeff(dot)janes(at)gmail(dot)com>, "'Alvaro Herrera'" <alvherre(at)2ndquadrant(dot)com>, "'PostgreSQL-development'" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-17 10:16:00 |
| Message-ID: | 008c01ce82d6$a38a86e0$ea9f94a0$@kapila@huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Monday, July 08, 2013 2:47 PM Heikki Linnakangas wrote:
> Ok, I've committed this patch now. Finally, phew!
Few doubts while reading the code:
1. Why in function WALInsertSlotAcquireOne(int slotno), it does
START_CRIT_SECTION() to
Lock out cancel/die interrupts, whereas other places call
HOLD_INTERRUPTS()
2. In function GetXLogBuffer(), why the logic to wakeup waiters is
different when expectedEndPtr != endptr;
When the wakeupwaiters is done in case expectedEndPtr == endptr?
3.
static bool
ReserveXLogSwitch(..)
In above function header, why EndPos_p/StartPos_p is used when
function arguments are EndPos/StartPos?
With Regards,
Amit Kapila.
| From: | Andres Freund <andres(at)2ndquadrant(dot)com> |
|---|---|
| To: | Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
| Cc: | 'Heikki Linnakangas' <hlinnakangas(at)vmware(dot)com>, 'Jeff Janes' <jeff(dot)janes(at)gmail(dot)com>, 'Alvaro Herrera' <alvherre(at)2ndquadrant(dot)com>, 'PostgreSQL-development' <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-17 12:24:59 |
| Message-ID: | 20130717122459.GC12343@alap2.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2013-07-17 15:46:00 +0530, Amit Kapila wrote:
> On Monday, July 08, 2013 2:47 PM Heikki Linnakangas wrote:
> > Ok, I've committed this patch now. Finally, phew!
>
> Few doubts while reading the code:
>
> 1. Why in function WALInsertSlotAcquireOne(int slotno), it does
> START_CRIT_SECTION() to
> Lock out cancel/die interrupts, whereas other places call
> HOLD_INTERRUPTS()
A crit section does more than just stopping interrupts. They also ensure
that errors that occur while inside one get converted to a PANIC. That
seems apt for SlotAcquire/Release. Although the comments could possibly
improved a bit.
> 2. In function GetXLogBuffer(), why the logic to wakeup waiters is
> different when expectedEndPtr != endptr;
> When the wakeupwaiters is done in case expectedEndPtr == endptr?
I am not sure what you're asking here. We wakeup waiters if
expectedEndPtr != endptr because that means the wal buffer page the
'ptr' fits on currently has different content. Which in turn means we've
finished with the last page and progressed to a new one. So we wake up
everyone waiting for us.
WakeupWaiters() doesn't get passed expectedEndPtr but expectedEndPtr -
XLOG_BLCKSZ (up to there we are guaranteed to have inserted
successfully). And we're comparing with the xlogInsertingAt value which
basically measures up to where we've successfully inserted.
> 3.
> static bool
> ReserveXLogSwitch(..)
>
> In above function header, why EndPos_p/StartPos_p is used when
> function arguments are EndPos/StartPos?
I guess that's bitrot...
Greetings,
Andres Freund
--
Andres Freund http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Michael Paquier <michael(dot)paquier(at)gmail(dot)com> |
| Cc: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com>, Andres Freund <andres(at)2ndquadrant(dot)com>, Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-17 20:24:03 |
| Message-ID: | 51E6FD63.6000407@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17.07.2013 02:18, Michael Paquier wrote:
> On Tue, Jul 16, 2013 at 2:24 AM, Fujii Masao<masao(dot)fujii(at)gmail(dot)com> wrote:
>> On Mon, Jul 8, 2013 at 6:16 PM, Heikki Linnakangas
>> <hlinnakangas(at)vmware(dot)com> wrote:
>>> Ok, I've committed this patch now. Finally, phew!
>>
>> I found that this patch causes the assertion failure. When I set up simple
>> replication environment and promoted the standby before executing any
>> transaction on the master, I got the following assertion failure.
>>
>> 2013-07-16 02:22:06 JST sby1 LOG: received promote request
>> 2013-07-16 02:22:06 JST sby1 FATAL: terminating walreceiver process
>> due to administrator command
>> 2013-07-16 02:22:06 JST sby1 LOG: redo done at 0/20000F0
>> 2013-07-16 02:22:06 JST sby1 LOG: selected new timeline ID: 2
>> hrk:head-pgsql postgres$ 2013-07-16 02:22:06 JST sby1 LOG: archive
>> recovery complete
>> TRAP: FailedAssertion("!(readOff == (XLogCtl->xlblocks[firstIdx] -
>> 8192) % ((uint32) (16 * 1024 * 1024)))", File: "xlog.c", Line: 7048)
>> 2013-07-16 02:22:12 JST sby1 LOG: startup process (PID 37115) was
>> terminated by signal 6: Abort trap
>> 2013-07-16 02:22:12 JST sby1 LOG: terminating any other active server processes
> Note that this is also reproducible even when trying to recover only
> from archives without strrep.
Fixed, thanks for the report. While at it, I slightly refactored the way
the buffer bookkeeping works. Instead of keeping track of the index of
the last initialized buffer, keep track how far the buffer cache has
been initialized in an XLogRecPtr variable (called
XLogCtl->InitializedUpTo). That made the code slightly more readable IMO.
- Heikki
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)2ndquadrant(dot)com>, Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
| Cc: | 'Jeff Janes' <jeff(dot)janes(at)gmail(dot)com>, 'Alvaro Herrera' <alvherre(at)2ndquadrant(dot)com>, 'PostgreSQL-development' <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: XLogInsert scaling, revisited |
| Date: | 2013-07-17 20:37:39 |
| Message-ID: | 51E70093.1040907@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17.07.2013 15:24, Andres Freund wrote:
> On 2013-07-17 15:46:00 +0530, Amit Kapila wrote:
>> Few doubts while reading the code:
>>
>> 1. Why in function WALInsertSlotAcquireOne(int slotno), it does
>> START_CRIT_SECTION() to
>> Lock out cancel/die interrupts, whereas other places call
>> HOLD_INTERRUPTS()
>
> A crit section does more than just stopping interrupts. They also ensure
> that errors that occur while inside one get converted to a PANIC. That
> seems apt for SlotAcquire/Release. Although the comments could possibly
> improved a bit.
Agreed. The comment was copied from LWLockAcquire(), which only does
HOLD_INTERRUPTS(). The crucial difference between LWLockAcquire() and
WALInsertSlotAcquire() is that there is no automatic cleanup mechanism
on abort for the WAL insertion slots like there is for lwlocks. Added a
sentence to the comment to mention that.
>> 3.
>> static bool
>> ReserveXLogSwitch(..)
>>
>> In above function header, why EndPos_p/StartPos_p is used when
>> function arguments are EndPos/StartPos?
>
> I guess that's bitrot...
Yep, fixed.
Thanks for the review!
- Heikki