Re: Parallel Aggregates for string_agg and array_agg
| Lists: | pgsql-hackers |
|---|
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Parallel Aggregates for string_agg and array_agg |
| Date: | 2017-12-17 14:30:55 |
| Message-ID: | CAKJS1f9sx_6GTcvd6TMuZnNtCh0VhBzhX6FZqw17TgVFH-ga_A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
While working on partial aggregation a few years ago, I didn't really
think it was worthwhile allowing partial aggregation of string_agg and
array_agg. I soon realised that I was wrong about that and allowing
parallelisation of these aggregates still could be very useful when
many rows are filtered out during the scan.
Some benchmarks that I've done locally show that parallel string_agg
and array_agg do actually perform better, despite the fact that the
aggregate state grows linearly with each aggregated item. Obviously,
the performance will get even better when workers are filtering out
rows before aggregation takes place, so it seems worthwhile doing
this. However, the main reason that I'm motivated to do this is that
there are more uses for partial aggregation other than just parallel
aggregation, and it seems a shame to disable all these features if a
single aggregate does not support partial mode.
I've attached a patch which implements all this. I've had most of it
stashed away for a while now, but I managed to get some time this
weekend to get it into a more completed state.
Things are now looking pretty good for the number of aggregates that
support partial mode.
Just a handful of aggregates now don't support partial aggregation;
postgres=# select aggfnoid from pg_aggregate where aggcombinefn=0 and
aggkind='n';
aggfnoid
------------------
xmlagg
json_agg
json_object_agg
jsonb_agg
jsonb_object_agg
(5 rows)
... and a good number do support it;
postgres=# select count(*) from pg_aggregate where aggcombinefn<>0 and
aggkind='n';
count
-------
122
(1 row)
There's probably no reason why the last 5 of those couldn't be done
either, it might just require shifting a bit more work into the final
functions, although, I'm not planning on that for this patch.
As for the patch; there's a bit of a quirk in the implementation of
string_agg. We previously always threw away the delimiter that belongs
to the first aggregated value, but we do now need to keep that around
so we can put it in between two states in the combine function. I
decided the path of least resistance to do this was just to borrow
StringInfo's cursor variable to use as a pointer to the state of the
first value and put the first delimiter before that. Both the
string_agg(text) and string_agg(bytea) already have a final function,
so we just need to skip over the bytes up until the cursor position to
get rid of the first delimiter. I could go and invent some new state
type to do the same, but I don't really see the trouble with what I've
done with StringInfo, but I'll certainly listen if someone else thinks
this is wrong.
Another thing that I might review later about this is seeing about
getting rid of some of the code duplication between
array_agg_array_combine and accumArrayResultArr.
I'm going to add this to PG11's final commitfest rather than the
January 'fest as it seems more like a final commitfest type of patch.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v1.patch | application/octet-stream | 31.4 KB |
| From: | David Steele <david(at)pgmasters(dot)net> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-01 19:33:17 |
| Message-ID: | 107aab8d-e7ed-e312-8b38-2005d0d4d9e0@pgmasters.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi David,
On 12/17/17 9:30 AM, David Rowley wrote:
>
> I'm going to add this to PG11's final commitfest rather than the
> January 'fest as it seems more like a final commitfest type of patch.
This patch applies but no longer builds:
$ make -C /home/vagrant/test/build
<...>
cd /postgres/src/include/catalog && '/usr/bin/perl' ./duplicate_oids
3419
3420
3421
3422
Looks like duplicate OIDs in pg_proc.h.
Thanks,
--
-David
david(at)pgmasters(dot)net
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-01 21:26:31 |
| Message-ID: | 20180301212631.kede4nyuttzxwoxq@alap3.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 2017-12-18 03:30:55 +1300, David Rowley wrote:
> While working on partial aggregation a few years ago, I didn't really
> think it was worthwhile allowing partial aggregation of string_agg and
> array_agg. I soon realised that I was wrong about that and allowing
> parallelisation of these aggregates still could be very useful when
> many rows are filtered out during the scan.
+1
> Some benchmarks that I've done locally show that parallel string_agg
> and array_agg do actually perform better, despite the fact that the
> aggregate state grows linearly with each aggregated item.
It also allows *other* aggregates with different space consumption to be
computed in parallel, that can be fairly huge.
> Just a handful of aggregates now don't support partial aggregation;
>
> postgres=# select aggfnoid from pg_aggregate where aggcombinefn=0 and
> aggkind='n';
> aggfnoid
> ------------------
> xmlagg
> json_agg
> json_object_agg
> jsonb_agg
> jsonb_object_agg
> (5 rows)
FWIW, I've heard numerous people yearn for json*agg
> I'm going to add this to PG11's final commitfest rather than the
> January 'fest as it seems more like a final commitfest type of patch.
Not sure I understand?
> +/*
> + * array_agg_serialize
> + * Serialize ArrayBuildState into bytea.
> + */
> +Datum
> +array_agg_serialize(PG_FUNCTION_ARGS)
> +{
> + /*
> + * dvalues -- this is very simple when the value type is byval, we can
> + * simply just send the Datums over, however, for non-byval types we must
> + * work a little harder.
> + */
> + if (state->typbyval)
> + pq_sendbytes(&buf, (char *) state->dvalues, sizeof(Datum) * state->nelems);
> + else
> + {
> + Oid typsend;
> + bool typisvarlena;
> + bytea *outputbytes;
> + int i;
> +
> + /* XXX is there anywhere to cache this to save calling each time? */
> + getTypeBinaryOutputInfo(state->element_type, &typsend, &typisvarlena);
Yes, you should be able to store this in fcinfo->flinfo->fn_extra. Or do
you see a problem doing so?
> +
> +Datum
> +array_agg_deserialize(PG_FUNCTION_ARGS)
> +{
> + /*
> + * dvalues -- this is very simple when the value type is byval, we can
> + * simply just get all the Datums at once, however, for non-byval types we
> + * must work a little harder.
> + */
> + if (result->typbyval)
> + {
> + temp = pq_getmsgbytes(&buf, sizeof(Datum) * nelems);
> + memcpy(result->dvalues, temp, sizeof(Datum) * nelems);
> + }
> + else
> + {
> + Oid typreceive;
> + Oid typioparam;
> + int i;
> +
> + getTypeBinaryInputInfo(element_type, &typreceive, &typioparam);
> +
> + for (i = 0; i < nelems; i++)
> + {
> + /* XXX? Surely this cannot be the way to do this? */
> + StringInfoData tmp;
> + tmp.cursor = 0;
> + tmp.maxlen = tmp.len = pq_getmsgint(&buf, 4);
> + tmp.data = (char *) pq_getmsgbytes(&buf, tmp.len);
> +
> + result->dvalues[i] = OidReceiveFunctionCall(typreceive, &tmp,
> + typioparam, -1);
Hm, doesn't look too bad to me? What's your concern here?
This isn't a real review, I was basically just doing a quick
scroll-through.
Greetings,
Andres Freund
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Steele <david(at)pgmasters(dot)net> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-01 21:27:42 |
| Message-ID: | CAKJS1f-=KY=XMf2wL6qWcVNH7n8rswBovVcq4zE2fcHz+cXs3g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Thanks for looking at the patch.
On 2 March 2018 at 08:33, David Steele <david(at)pgmasters(dot)net> wrote:
> This patch applies but no longer builds:
...
> Looks like duplicate OIDs in pg_proc.h.
Who stole my OIDs?!
Updated patch attached.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v2.patch | application/octet-stream | 31.4 KB |
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-02 00:48:00 |
| Message-ID: | CAKJS1f-T=Ryw9OVG6hUtJ4hJoBUtM3q3bZkbCko6nU9pv+vi4A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2 March 2018 at 10:26, Andres Freund <andres(at)anarazel(dot)de> wrote:
> On 2017-12-18 03:30:55 +1300, David Rowley wrote:
>> Just a handful of aggregates now don't support partial aggregation;
>>
>> postgres=# select aggfnoid from pg_aggregate where aggcombinefn=0 and
>> aggkind='n';
>> aggfnoid
>> ------------------
>> xmlagg
>> json_agg
>> json_object_agg
>> jsonb_agg
>> jsonb_object_agg
>> (5 rows)
>
> FWIW, I've heard numerous people yearn for json*agg
I guess it'll need to be PG12 for now. I'd imagine string_agg and
array_agg are more important ones to tick off for now, but I bet many
people would disagree with that.
>
>> I'm going to add this to PG11's final commitfest rather than the
>> January 'fest as it seems more like a final commitfest type of patch.
>
> Not sure I understand?
hmm, yeah. That was more of a consideration that I should be working
hard on + reviewing more complex and invasive patches before the final
'fest. I saw this more as something that would gain more interest once
patches such as partition-wise aggs gets in.
>> + /* XXX is there anywhere to cache this to save calling each time? */
>> + getTypeBinaryOutputInfo(state->element_type, &typsend, &typisvarlena);
>
> Yes, you should be able to store this in fcinfo->flinfo->fn_extra. Or do
> you see a problem doing so?
No, just didn't think of it.
>> + /* XXX? Surely this cannot be the way to do this? */
>> + StringInfoData tmp;
>> + tmp.cursor = 0;
>> + tmp.maxlen = tmp.len = pq_getmsgint(&buf, 4);
>> + tmp.data = (char *) pq_getmsgbytes(&buf, tmp.len);
>> +
>> + result->dvalues[i] = OidReceiveFunctionCall(typreceive, &tmp,
>> + typioparam, -1);
>
> Hm, doesn't look too bad to me? What's your concern here?
I was just surprised at having to fake up a StringInfoData.
> This isn't a real review, I was basically just doing a quick
> scroll-through.
Understood.
I've attached a delta patch which can be applied on top of the v2
patch which removes that XXX comment above and also implements the
fn_extra caching.
Thanks for looking!
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v3_delta.patch | application/octet-stream | 3.3 KB |
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-02 00:50:20 |
| Message-ID: | 20180302005020.ppmybylrjl2rowxg@alap3.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2018-03-02 13:48:00 +1300, David Rowley wrote:
> On 2 March 2018 at 10:26, Andres Freund <andres(at)anarazel(dot)de> wrote:
> > FWIW, I've heard numerous people yearn for json*agg
>
> I guess it'll need to be PG12 for now. I'd imagine string_agg and
> array_agg are more important ones to tick off for now, but I bet many
> people would disagree with that.
Oh, this was definitely not meant as an ask for something done together
with this submission.
Thanks for the quick update.
Greetings,
Andres Freund
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-03 09:47:21 |
| Message-ID: | CAKJS1f8cB3cc5AK=wPvByhU_jKkgd81iRt2kE6cru8uxx2HCuA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I've attached a rebased patch which fixes the conflicts caused by fd1a421.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v4.patch | application/octet-stream | 32.7 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-04 15:54:07 |
| Message-ID: | c302afa6-6415-27a5-336a-e1d4332fab09@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
I've looked at the rebased patch you sent yesterday, and I do have a
couple of comments.
1) There seems to be forgotten declaration of initArrayResultInternal in
arrayfuncs.c. I suppose you've renamed it to initArrayResultWithSize and
moved it to a header file, and forgotten to remove this bit.
2) bytea_string_agg_deserialize has this comment:
/*
* data: technically we could reuse the buf.data buffer, but that is
* slightly larger than we need due to the extra 4 bytes for the cursor
*/
I find the argument "it has 4 extra bytes, so we'll allocate new chunk"
somewhat weak. We do allocate the memory in 2^n chunks anyway, so the
new chunk is likely to be much larger anyway. I'm not saying we need to
reuse the buffer, IMHO the savings will be non-measurable.
3) string_agg_transfn and bytea_string_agg_transfn say this"
/*
* We always append the delimiter text before the value text, even
* with the first aggregated item. The reason for this is that if
* this state needs to be combined with another state using the
* aggregate's combine function, then we need to have the delimiter
* for the first aggregated item. The first delimiter will be
* stripped off in the final function anyway. We use a little cheat
* here and store the position of the actual first value (after the
* delimiter) using the StringInfo's cursor variable. This relies on
* the cursor not being used for any other purpose.
*/
How does this make the code any simpler, compared to not adding the
delimiter (as before) and adding it when combining the values (at which
point you should know when it's actually needed)?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-05 03:51:20 |
| Message-ID: | CAKJS1f9xEZdTaBbBEKY+TCKEoSZYaH1oSAtsEJHSYDJCCNnQPQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 5 March 2018 at 04:54, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> 1) There seems to be forgotten declaration of initArrayResultInternal in
> arrayfuncs.c. I suppose you've renamed it to initArrayResultWithSize and
> moved it to a header file, and forgotten to remove this bit.
Oops. Must be left over from trying things another way. Removed.
> 2) bytea_string_agg_deserialize has this comment:
>
> /*
> * data: technically we could reuse the buf.data buffer, but that is
> * slightly larger than we need due to the extra 4 bytes for the cursor
> */
>
> I find the argument "it has 4 extra bytes, so we'll allocate new chunk"
> somewhat weak. We do allocate the memory in 2^n chunks anyway, so the
> new chunk is likely to be much larger anyway. I'm not saying we need to
> reuse the buffer, IMHO the savings will be non-measurable.
Agreed. I've removed that part of the comment.
> 3) string_agg_transfn and bytea_string_agg_transfn say this"
>
> /*
> * We always append the delimiter text before the value text, even
> * with the first aggregated item. The reason for this is that if
> * this state needs to be combined with another state using the
> * aggregate's combine function, then we need to have the delimiter
> * for the first aggregated item. The first delimiter will be
> * stripped off in the final function anyway. We use a little cheat
> * here and store the position of the actual first value (after the
> * delimiter) using the StringInfo's cursor variable. This relies on
> * the cursor not being used for any other purpose.
> */
>
> How does this make the code any simpler, compared to not adding the
> delimiter (as before) and adding it when combining the values (at which
> point you should know when it's actually needed)?
The problem is that if we don't record the first delimiter then we
won't know what it is when it comes to combining the states.
Consider the following slightly backward-looking case;
select string_agg(',', x::text) from generate_Series(1,10)x;
string_agg
----------------------
,2,3,4,5,6,7,8,9,10,
Here the delimiter is the number, not the ','. Of course, the
delimiter for the first aggregated result is not shown. The previous
implementation of the transfn for this aggregate just threw away the
first delimiter, but that's no good for parallel aggregates as the
transfn may be getting called in a parallel worker, in which case
we'll need that delimiter in the combine function to properly join to
the other partial aggregated results matching the same group.
Probably I could improve the comment a bit. I understand that having a
variable delimiter is not commonplace in the normal world. I certainly
had never considered it before working on this. I scratched my head a
bit when doing this and thought about inventing a new trans type, but
I decided that the most efficient design for an aggregate state was to
store the delimiter and data all in one buffer and have a pointer to
the start of the actual data... StringInfo has exactly what's required
if you use the cursor as the pointer, so I didn't go and reinvent the
wheel.
I've now changed the comment to read:
/*
* It's important that we store the delimiter text for all aggregated
* items, even the first one, which at first thought you might think
* could just be discarded. The reason for this is that if this
* function is being called from a parallel worker, then we'll need
* the first delimiter in order to properly combine the partially
* aggregated state with the states coming from other workers. In the
* final output, the first delimiter will be stripped off of the final
* aggregate state, but in order to know where the actual first data
* is we must store the position of the first data value somewhere.
* Conveniently, StringInfo has a cursor property which can be used
* to serve our needs here.
*/
I've also updated an incorrect Assert in array_agg_array_serialize.
Please find attached the updated patch.
Many thanks for reviewing this.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v5.patch | application/octet-stream | 32.3 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-10 23:11:57 |
| Message-ID: | 24abe018-b3c6-2117-b5b9-39e660db00bd@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/05/2018 04:51 AM, David Rowley wrote:
> On 5 March 2018 at 04:54, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>> 1) There seems to be forgotten declaration of initArrayResultInternal in
>> arrayfuncs.c. I suppose you've renamed it to initArrayResultWithSize and
>> moved it to a header file, and forgotten to remove this bit.
>
> Oops. Must be left over from trying things another way. Removed.
>
>> 2) bytea_string_agg_deserialize has this comment:
>>
>> /*
>> * data: technically we could reuse the buf.data buffer, but that is
>> * slightly larger than we need due to the extra 4 bytes for the cursor
>> */
>>
>> I find the argument "it has 4 extra bytes, so we'll allocate new chunk"
>> somewhat weak. We do allocate the memory in 2^n chunks anyway, so the
>> new chunk is likely to be much larger anyway. I'm not saying we need to
>> reuse the buffer, IMHO the savings will be non-measurable.
>
> Agreed. I've removed that part of the comment.
>
>> 3) string_agg_transfn and bytea_string_agg_transfn say this"
>>
>> /*
>> * We always append the delimiter text before the value text, even
>> * with the first aggregated item. The reason for this is that if
>> * this state needs to be combined with another state using the
>> * aggregate's combine function, then we need to have the delimiter
>> * for the first aggregated item. The first delimiter will be
>> * stripped off in the final function anyway. We use a little cheat
>> * here and store the position of the actual first value (after the
>> * delimiter) using the StringInfo's cursor variable. This relies on
>> * the cursor not being used for any other purpose.
>> */
>>
>> How does this make the code any simpler, compared to not adding the
>> delimiter (as before) and adding it when combining the values (at which
>> point you should know when it's actually needed)?
>
> The problem is that if we don't record the first delimiter then we
> won't know what it is when it comes to combining the states.
>
> Consider the following slightly backward-looking case;
>
> select string_agg(',', x::text) from generate_Series(1,10)x;
> string_agg
> ----------------------
> ,2,3,4,5,6,7,8,9,10,
>
> Here the delimiter is the number, not the ','. Of course, the
> delimiter for the first aggregated result is not shown. The previous
> implementation of the transfn for this aggregate just threw away the
> first delimiter, but that's no good for parallel aggregates as the
> transfn may be getting called in a parallel worker, in which case
> we'll need that delimiter in the combine function to properly join to
> the other partial aggregated results matching the same group.
>
Hmmm, you're right I haven't considered the delimiter might be variable.
But isn't just yet another hint that while StringInfo was suitable for
aggregate state of non-parallel string_agg, it may not be for the
parallel version?
What if the parallel string_agg instead used something like this:
struct StringAggState
{
char *delimiter; /* first delimiter */
StringInfoData str; /* partial aggregate state */
} StringAggState;
I think that would make the code cleaner, compared to using the cursor
field for that purpose. But maybe it'd make it not possible to share
code with the non-parallel aggregate, not sure.
I always considered the cursor field to be meant for scanning through
StringInfo, so using it for this purpose seems a bit like a misuse.
> Probably I could improve the comment a bit. I understand that having a
> variable delimiter is not commonplace in the normal world. I certainly
> had never considered it before working on this. I scratched my head a
> bit when doing this and thought about inventing a new trans type, but
> I decided that the most efficient design for an aggregate state was to
> store the delimiter and data all in one buffer and have a pointer to
> the start of the actual data... StringInfo has exactly what's required
> if you use the cursor as the pointer, so I didn't go and reinvent the
> wheel.
>
I wonder why the variable delimiter is not mentioned in the docs ... (at
least I haven't found anything mentioning the behavior).
> I've now changed the comment to read:
>
> /*
> * It's important that we store the delimiter text for all aggregated
> * items, even the first one, which at first thought you might think
> * could just be discarded. The reason for this is that if this
> * function is being called from a parallel worker, then we'll need
> * the first delimiter in order to properly combine the partially
> * aggregated state with the states coming from other workers. In the
> * final output, the first delimiter will be stripped off of the final
> * aggregate state, but in order to know where the actual first data
> * is we must store the position of the first data value somewhere.
> * Conveniently, StringInfo has a cursor property which can be used
> * to serve our needs here.
> */
>
> I've also updated an incorrect Assert in array_agg_array_serialize.
>
> Please find attached the updated patch.
>
Seems fine to me. I plan to do a bit more testing/review next week, but
I plan to move it to RFC after that (unless I run into something during
the review, but I don't expect that).
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-11 06:31:49 |
| Message-ID: | CAKJS1f8LV7AT=AAhdYGKtGrGkSkEgO6C_SW2Ztz1sR3encisqw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 11 March 2018 at 12:11, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> On 03/05/2018 04:51 AM, David Rowley wrote:
>> On 5 March 2018 at 04:54, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>> Consider the following slightly backward-looking case;
>>
>> select string_agg(',', x::text) from generate_Series(1,10)x;
>> string_agg
>> ----------------------
>> ,2,3,4,5,6,7,8,9,10,
>>
>> Here the delimiter is the number, not the ','. Of course, the
>> delimiter for the first aggregated result is not shown. The previous
>> implementation of the transfn for this aggregate just threw away the
>> first delimiter, but that's no good for parallel aggregates as the
>> transfn may be getting called in a parallel worker, in which case
>> we'll need that delimiter in the combine function to properly join to
>> the other partial aggregated results matching the same group.
>>
>
> Hmmm, you're right I haven't considered the delimiter might be variable.
> But isn't just yet another hint that while StringInfo was suitable for
> aggregate state of non-parallel string_agg, it may not be for the
> parallel version?
>
> What if the parallel string_agg instead used something like this:
>
> struct StringAggState
> {
> char *delimiter; /* first delimiter */
> StringInfoData str; /* partial aggregate state */
> } StringAggState;
>
> I think that would make the code cleaner, compared to using the cursor
> field for that purpose. But maybe it'd make it not possible to share
> code with the non-parallel aggregate, not sure.
It would be possible to use something like that. The final function
would just need to take 'str' and ignore 'delimiter', whereas the
combine function would need both. However, you could optimize the
above to just have a single StringInfoData and have a pointer to the
start of the actual data (beyond the first delimiter), that would save
us a call to palloc and also allow the state's data to exist in one
contiguous block of memory, which will be more cache friendly when it
comes to reading it back again. The pointer here would, of course,
have to be an offset into the data array, since repallocs would cause
problems as the state grew.
This is kinda the option I was going for with using the cursor. I
didn't think that was going to be a problem. It seems that cursor was
invented so that users of StringInfo could store a marker somehow
along with the string. The comment for cursor read:
* cursor is initialized to zero by makeStringInfo or initStringInfo,
* but is not otherwise touched by the stringinfo.c routines.
* Some routines use it to scan through a StringInfo.
The use of the cursor field does not interfere with pqformat.c's use
of it as in the serialization functions we're creating a new
StringInfo for the 'result'. If anything tries to send the internal
state, then that's certainly broken. It needs to be serialized before
that can happen.
I don't quite see how inventing a new struct would make the code
cleaner. It would make the serialization and deserialization functions
have to write and read more fields for the lengths of the data
contained in the state.
I understand that the cursor field is used in pqformat.c quite a bit,
but I don't quite understand why it should get to use that field the
way it wants, but the serialization and deserialization functions
shouldn't. I'd understand that if we were trying to phase out the
cursor field from StringInfoData, but I can't imagine that's going to
happen.
Of course, with that all said. If you really strongly object to how
I've done this, then I'll change it to use a new struct type. I had
just tried to make the patch footprint as small as possible, and the
above text is me just explaining my reasoning behind this, not me
objecting to your request for me to change it. Let me know your
thoughts after reading the above.
In the meantime, I've attached an updated patch. The only change it
contains is updating the "Partial Mode" column in the docs from "No"
to "Yes".
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v6.patch | application/octet-stream | 33.3 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-11 11:10:00 |
| Message-ID: | 1b6ee15c-c218-761e-0120-c1ed438e2db2@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/11/2018 07:31 AM, David Rowley wrote:
> On 11 March 2018 at 12:11, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>> On 03/05/2018 04:51 AM, David Rowley wrote:
>>> On 5 March 2018 at 04:54, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>>> Consider the following slightly backward-looking case;
>>>
>>> select string_agg(',', x::text) from generate_Series(1,10)x;
>>> string_agg
>>> ----------------------
>>> ,2,3,4,5,6,7,8,9,10,
>>>
>>> Here the delimiter is the number, not the ','. Of course, the
>>> delimiter for the first aggregated result is not shown. The previous
>>> implementation of the transfn for this aggregate just threw away the
>>> first delimiter, but that's no good for parallel aggregates as the
>>> transfn may be getting called in a parallel worker, in which case
>>> we'll need that delimiter in the combine function to properly join to
>>> the other partial aggregated results matching the same group.
>>>
>>
>> Hmmm, you're right I haven't considered the delimiter might be variable.
>> But isn't just yet another hint that while StringInfo was suitable for
>> aggregate state of non-parallel string_agg, it may not be for the
>> parallel version?
>>
>> What if the parallel string_agg instead used something like this:
>>
>> struct StringAggState
>> {
>> char *delimiter; /* first delimiter */
>> StringInfoData str; /* partial aggregate state */
>> } StringAggState;
>>
>> I think that would make the code cleaner, compared to using the cursor
>> field for that purpose. But maybe it'd make it not possible to share
>> code with the non-parallel aggregate, not sure.
>
> It would be possible to use something like that. The final function
> would just need to take 'str' and ignore 'delimiter', whereas the
> combine function would need both. However, you could optimize the
> above to just have a single StringInfoData and have a pointer to the
> start of the actual data (beyond the first delimiter), that would save
> us a call to palloc and also allow the state's data to exist in one
> contiguous block of memory, which will be more cache friendly when it
> comes to reading it back again. The pointer here would, of course,
> have to be an offset into the data array, since repallocs would cause
> problems as the state grew.
>
> This is kinda the option I was going for with using the cursor. I
> didn't think that was going to be a problem. It seems that cursor was
> invented so that users of StringInfo could store a marker somehow
> along with the string. The comment for cursor read:
>
> * cursor is initialized to zero by makeStringInfo or initStringInfo,
> * but is not otherwise touched by the stringinfo.c routines.
> * Some routines use it to scan through a StringInfo.
>
> The use of the cursor field does not interfere with pqformat.c's use
> of it as in the serialization functions we're creating a new
> StringInfo for the 'result'. If anything tries to send the internal
> state, then that's certainly broken. It needs to be serialized before
> that can happen.
>
> I don't quite see how inventing a new struct would make the code
> cleaner. It would make the serialization and deserialization functions
> have to write and read more fields for the lengths of the data
> contained in the state.
>
> I understand that the cursor field is used in pqformat.c quite a bit,
> but I don't quite understand why it should get to use that field the
> way it wants, but the serialization and deserialization functions
> shouldn't. I'd understand that if we were trying to phase out the
> cursor field from StringInfoData, but I can't imagine that's going to
> happen.
>
> Of course, with that all said. If you really strongly object to how
> I've done this, then I'll change it to use a new struct type. I had
> just tried to make the patch footprint as small as possible, and the
> above text is me just explaining my reasoning behind this, not me
> objecting to your request for me to change it. Let me know your
> thoughts after reading the above.
>
Hmmm, I guess you're right, I didn't really thought that through. I
don't object to sticking to the current approach.
> In the meantime, I've attached an updated patch. The only change it
> contains is updating the "Partial Mode" column in the docs from "No"
> to "Yes".
>
Yeah, seems fine to me. I wonder what else would be needed before
switching the patch to RFC. I plan to do that after a bit more testing
sometime early next week, unless someone objects.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-16 00:46:39 |
| Message-ID: | 657be73a-a21d-0ae1-5c62-870afbdfddd4@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/11/2018 12:10 PM, Tomas Vondra wrote:
>
> ...
>
> Yeah, seems fine to me. I wonder what else would be needed before
> switching the patch to RFC. I plan to do that after a bit more
> testing sometime early next week, unless someone objects.
>
I've done more testing on this patch, and I haven't found any new issues
with it, so PFA I'm marking it as ready for committer.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-16 02:44:39 |
| Message-ID: | CAKJS1f-bKAD+s-CJetRQPjmrR-gF-kfvwfzhQm-A0PA-nsr1xw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 16 March 2018 at 13:46, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> I've done more testing on this patch, and I haven't found any new issues
> with it, so PFA I'm marking it as ready for committer.
Great! Many thanks for the review.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 02:26:47 |
| Message-ID: | 20180326022647.GL24540@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Greetings,
* David Rowley (david(dot)rowley(at)2ndquadrant(dot)com) wrote:
> On 16 March 2018 at 13:46, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> > I've done more testing on this patch, and I haven't found any new issues
> > with it, so PFA I'm marking it as ready for committer.
>
> Great! Many thanks for the review.
I read through the thread and started reviewing this, comments below.
diff --git a/src/backend/utils/adt/array_userfuncs.c b/src/backend/utils/adt/array_userfuncs.c
[...]
+ for (i = 0; i < state2->nelems; i++)
+ state1->dvalues[i] = datumCopy(state2->dvalues[i],
+ state1->typbyval, state1->typlen);
+
+ memcpy(state1->dnulls, state2->dnulls, sizeof(bool) * state2->nelems);
The header at the top of datumCopy() pretty clearly says that it's for
"non-NULL" datums, yet this function seems to be happily ignoring that
and just trying to use it to copy everything. Perhaps I'm missing
something, but I don't see anything obvious that would lead me to
conclude that what's being done here (or in other similar cases in this
patch) is acceptable.
[...]
+ for (i = 0; i < state->nelems; i++)
+ {
+ outputbytes = OidSendFunctionCall(iodata->typsend, state->dvalues[i]);
+ pq_sendint32(&buf, VARSIZE(outputbytes) - VARHDRSZ);
+ pq_sendbytes(&buf, VARDATA(outputbytes),
+ VARSIZE(outputbytes) - VARHDRSZ);
+ }
+ }
+
+ /* dnulls */
+ pq_sendbytes(&buf, (char *) state->dnulls, sizeof(bool) * state->nelems);
SendFunctionCall() has a similar "Do not call this on NULL datums"
comment.
+ for (i = 0; i < nelems; i++)
+ {
+ StringInfoData tmp;
+ tmp.cursor = 0;
+ tmp.maxlen = tmp.len = pq_getmsgint(&buf, 4);
+ tmp.data = (char *) pq_getmsgbytes(&buf, tmp.len);
+
+ result->dvalues[i] = OidReceiveFunctionCall(iodata->typreceive,
+ &tmp,
+ iodata->typioparam,
+ -1);
+ }
+ }
+
+ /* dnulls */
+ temp = pq_getmsgbytes(&buf, sizeof(bool) * nelems);
+ memcpy(result->dnulls, temp, sizeof(bool) * nelems);
And if we aren't sending them then we probably need to do something
different on the receive side...
I glanced through the rest and it seemed alright, but will want to still
go over it more carefully once the above comments are addressed.
Marking Waiting-for-Author.
Thanks!
Stephen
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Stephen Frost <sfrost(at)snowman(dot)net> |
| Cc: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 09:37:37 |
| Message-ID: | CAKJS1f-axkksX3XzduLJuTL=o8CSwf1NaQYO6=iHSXR_B3pCKQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26 March 2018 at 15:26, Stephen Frost <sfrost(at)snowman(dot)net> wrote:
> The header at the top of datumCopy() pretty clearly says that it's for
> "non-NULL" datums, yet this function seems to be happily ignoring that
> and just trying to use it to copy everything. Perhaps I'm missing
> something, but I don't see anything obvious that would lead me to
> conclude that what's being done here (or in other similar cases in this
> patch) is acceptable.
Thanks for looking at this.
You're right. I've overlooked this. The code should be checking for
NULL value Datums there. I've fixed this locally, but on testing, I
discovered another bug around string_agg. At the moment string_agg's
transfn only allocates the state when it gets a non-NULL string to
aggregate, whereas it seems other trans functions which return an
internal state allocate their state on the first call. e.g.
int8_avg_accum(). This NULL state is causing the serial function
segfault on a null pointer dereference. I think the fix is to always
allocate the state in the transfn, but I just wanted to point this out
before I go and do that.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 13:20:09 |
| Message-ID: | 20180326132009.GN24540@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Greetings,
* David Rowley (david(dot)rowley(at)2ndquadrant(dot)com) wrote:
> On 26 March 2018 at 15:26, Stephen Frost <sfrost(at)snowman(dot)net> wrote:
> > The header at the top of datumCopy() pretty clearly says that it's for
> > "non-NULL" datums, yet this function seems to be happily ignoring that
> > and just trying to use it to copy everything. Perhaps I'm missing
> > something, but I don't see anything obvious that would lead me to
> > conclude that what's being done here (or in other similar cases in this
> > patch) is acceptable.
>
> Thanks for looking at this.
>
> You're right. I've overlooked this. The code should be checking for
> NULL value Datums there. I've fixed this locally, but on testing, I
> discovered another bug around string_agg. At the moment string_agg's
> transfn only allocates the state when it gets a non-NULL string to
> aggregate, whereas it seems other trans functions which return an
> internal state allocate their state on the first call. e.g.
> int8_avg_accum(). This NULL state is causing the serial function
> segfault on a null pointer dereference. I think the fix is to always
> allocate the state in the transfn, but I just wanted to point this out
> before I go and do that.
Just to be clear- the segfault is just happening with your patch and
you're just contemplating having string_agg always allocate state on the
first call, similar to what int8_avg_accum() does?
If so, then, yes, that seems alright to me.
Thanks!
Stephen
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Stephen Frost <sfrost(at)snowman(dot)net> |
| Cc: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 14:04:29 |
| Message-ID: | CAKJS1f8JVpUUkYP2c+RyVRdpS1dnjB_DA5fbcDSL3qfMRqc81Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 02:20, Stephen Frost <sfrost(at)snowman(dot)net> wrote:
> Just to be clear- the segfault is just happening with your patch and
> you're just contemplating having string_agg always allocate state on the
> first call, similar to what int8_avg_accum() does?
>
> If so, then, yes, that seems alright to me.
I did write some code to do this, but I ended up having to invent a
new state type which contained an additional "gotvalue" bool flag. We
needed to know the difference between a new state and one that's just
not had any non-NULL values aggregated yet. This meant the transfn and
combinefn needed to track this extra flag, and the serial and deserial
functions had to send it too. It started to look pretty horrible so I
started wondering about modifying the serial and deserial functions to
allow NULL states instead, that's when I realised that the serial and
deserial functions were both strict, and should never have been called
with NULL states in the first place!
It turns out this is a bit of an existing bug, but perhaps one that is
pretty harmless without this patch. Basically, the string_agg trans
function was always returning PG_RETURN_POINTER(state), even when the
state was NULL. This meant that the fcinfo->isnull flag was not
properly set, which caused the nodeAgg.c code to call the strict
serial function regardless.
In the end, I just fixed this by changing the PG_RETURN_POINTER(state) into:
if (state)
PG_RETURN_POINTER(state);
PG_RETURN_NULL();
The final functions seem to have managed to escape this bug by the way
they check for NULL states:
state = PG_ARGISNULL(0) ? NULL : (StringInfo) PG_GETARG_POINTER(0);
if (state != NULL)
...
Which allows an SQL null, or a NULL pointer. These could probably now
be changed to become:
if (!PG_ARGISNULL(0))
{
state = (StringInfo) PG_GETARG_POINTER(0);
...
Or it may be possible to make the finalfn strict, but I didn't do
either of these things.
I did also wonder if PG_RETURN_POINTER should test for NULL pointers
and set fcinfo->isnull, but there might be valid cases where we'd want
to not set the flag... I just can't imagine a valid reason why right
now.
In the attached, I also got rid of the serial and deserial function
for string_agg(text). I realised that these were doing pq_sendtext()
instead of pq_sendbytes. This meant that text would be changed to the
client encoding which was not what we wanted as we were not sending
anything to the client. Fixing this meant that the string_agg(bytea)
and string_agg(text) aggregates had identical serial/deserial
functions, so they now share the functions instead.
I also looked at all the built-in aggregate trans functions which use
an internal aggregate state to verify they're also doing the right
thing in regards to NULLs. The following query returns 16 distinct
functions, all of these apart from the ones I've fixed in the attached
patch all allocate the internal state on first call, so it does not
appear that there's anything else to fix in this area:
select distinct aggtransfn from pg_aggregate where aggtranstype=2281 order by 1;
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v7.patch | application/octet-stream | 31.5 KB |
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 20:27:47 |
| Message-ID: | 6538.1522096067@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
> [ combinefn_for_string_and_array_aggs_v7.patch ]
I spent a fair amount of time hacking on this with intent to commit,
but just as I was getting to code that I liked, I started to have second
thoughts about whether this is a good idea at all. I quote from the fine
manual:
The aggregate functions array_agg, json_agg, jsonb_agg,
json_object_agg, jsonb_object_agg, string_agg, and xmlagg, as well as
similar user-defined aggregate functions, produce meaningfully
different result values depending on the order of the input
values. This ordering is unspecified by default, but can be controlled
by writing an ORDER BY clause within the aggregate call, as shown in
Section 4.2.7. Alternatively, supplying the input values from a sorted
subquery will usually work ...
I do not think it is accidental that these aggregates are exactly the ones
that do not have parallelism support today. Rather, that's because you
just about always have an interest in the order in which the inputs get
aggregated, which is something that parallel aggregation cannot support.
I fear that what will happen, if we commit this, is that something like
0.01% of the users of array_agg and string_agg will be pleased, another
maybe 20% will be unaffected because they wrote ORDER BY which prevents
parallel aggregation, and the remaining 80% will scream because we broke
their queries. Telling them they should've written ORDER BY isn't going
to cut it, IMO, when the benefit of that breakage will accrue only to some
very tiny fraction of use-cases.
In short, I think we ought to reject this.
Just in case I'm outvoted, attached is what I'd gotten done so far.
The main noncosmetic changes I'd made were to improve the caching logic
(it's silly to set up a lookup cache and then not cache the fmgr_info
lookup) and to not cheat quite as much on the StringInfo passed down to
the element typreceive function. There isn't any other place, I don't
think, where we don't honor the expectation that StringInfos have trailing
null bytes, and some places may depend on it --- array_recv does.
The main thing that remains undone is to get some test coverage ---
AFAICS, none of these new functions get exercised in the standard
regression tests.
I'm also a bit unhappy that the patch introduces code into
array_userfuncs.c that knows everything there is to know about the
contents of ArrayBuildState and ArrayBuildStateArr. Previously that
knowledge was pretty well localized in arrayfuncs.c. I wonder if it'd
be better to move the new combinefuncs and serial/deserial funcs into
arrayfuncs.c. Or perhaps export primitives from there that could be
used to build them.
regards, tom lane
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v8.patch | text/x-diff | 37.8 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 20:55:22 |
| Message-ID: | cd620e7f-a9dd-ad15-72a8-6c0ac10ea4c3@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/26/2018 10:27 PM, Tom Lane wrote:
> David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
>> [ combinefn_for_string_and_array_aggs_v7.patch ]
>
> I spent a fair amount of time hacking on this with intent to commit,
> but just as I was getting to code that I liked, I started to have second
> thoughts about whether this is a good idea at all. I quote from the fine
> manual:
>
> The aggregate functions array_agg, json_agg, jsonb_agg,
> json_object_agg, jsonb_object_agg, string_agg, and xmlagg, as well as
> similar user-defined aggregate functions, produce meaningfully
> different result values depending on the order of the input
> values. This ordering is unspecified by default, but can be controlled
> by writing an ORDER BY clause within the aggregate call, as shown in
> Section 4.2.7. Alternatively, supplying the input values from a sorted
> subquery will usually work ...
>
> I do not think it is accidental that these aggregates are exactly the ones
> that do not have parallelism support today. Rather, that's because you
> just about always have an interest in the order in which the inputs get
> aggregated, which is something that parallel aggregation cannot support.
>
I don't think that's quite true. I know plenty of people who do things
like this:
SELECT
a,
b,
avg(c),
sum(d),
array_agg(e),
array_agg(f),
string_agg(g)
FROM hugetable GROUP BY a,b HAVING avg(c) > 100.89;
and then do some additional processing on the result in some way
(subquery, matview, ...). They don't really care about ordering of
values in the arrays, as long as orderings of all the arrays match.
Currently queries like this can use parallelism at all, and the patch
fixes that I believe.
> I fear that what will happen, if we commit this, is that something like
> 0.01% of the users of array_agg and string_agg will be pleased, another
> maybe 20% will be unaffected because they wrote ORDER BY which prevents
> parallel aggregation, and the remaining 80% will scream because we broke
> their queries. Telling them they should've written ORDER BY isn't going
> to cut it, IMO, when the benefit of that breakage will accrue only to some
> very tiny fraction of use-cases.
>
Isn't the ordering unreliable *already*? It depends on ordering of
tuples on the input. So if the table is scanned by index scan or
sequential scan, that will affect the array_agg/string_agg results. If
the input is a join, it's even more volatile.
IMHO it's not like we're making the ordering unpredictable - it's been
like that since forever.
Also, how is this different from ORDER BY clause? If a user does not
specify an ORDER BY clause, I don't think we'd care very much about
changes to output ordering due to plan changes, for example.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 21:19:54 |
| Message-ID: | 18594.1522099194@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> On 03/26/2018 10:27 PM, Tom Lane wrote:
>> I fear that what will happen, if we commit this, is that something like
>> 0.01% of the users of array_agg and string_agg will be pleased, another
>> maybe 20% will be unaffected because they wrote ORDER BY which prevents
>> parallel aggregation, and the remaining 80% will scream because we broke
>> their queries. Telling them they should've written ORDER BY isn't going
>> to cut it, IMO, when the benefit of that breakage will accrue only to some
>> very tiny fraction of use-cases.
> Isn't the ordering unreliable *already*?
Not if the query is such that what gets chosen is, say, an indexscan or
mergejoin. It might be theoretically unreliable and yet work fine for
a given application.
I might be too pessimistic about the fraction of users who are depending
on ordered input without having written anything that explicitly forces
that ... but I stand by the theory that it substantially exceeds the
fraction of users who could get any benefit.
Your own example of assuming that separate aggregates are computed
in the same order reinforces my point, I think. In principle, anybody
who's doing that should write
array_agg(e order by x),
array_agg(f order by x),
string_agg(g order by x)
because otherwise they shouldn't assume that; the manual certainly doesn't
promise it. But nobody does that in production, because if they did
they'd get killed by the fact that the sorts are all done independently.
(We should improve that someday, but it hasn't been done yet.) So I think
there are an awful lot of people out there who are assuming more than a
lawyerly reading of the manual would allow. Their reaction to this will
be about like ours every time the GCC guys decide that some longstanding
behavior of C code isn't actually promised by the text of the C standard.
regards, tom lane
| From: | Stephen Frost <sfrost(at)snowman(dot)net> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 21:20:06 |
| Message-ID: | 20180326212006.GT24540@tamriel.snowman.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Greetings,
* Tomas Vondra (tomas(dot)vondra(at)2ndquadrant(dot)com) wrote:
> On 03/26/2018 10:27 PM, Tom Lane wrote:
> > I fear that what will happen, if we commit this, is that something like
> > 0.01% of the users of array_agg and string_agg will be pleased, another
> > maybe 20% will be unaffected because they wrote ORDER BY which prevents
> > parallel aggregation, and the remaining 80% will scream because we broke
> > their queries. Telling them they should've written ORDER BY isn't going
> > to cut it, IMO, when the benefit of that breakage will accrue only to some
> > very tiny fraction of use-cases.
>
> Isn't the ordering unreliable *already*? It depends on ordering of
> tuples on the input. So if the table is scanned by index scan or
> sequential scan, that will affect the array_agg/string_agg results. If
> the input is a join, it's even more volatile.
It's not even just that- for a seq scan, it'll also depend on if anyone
else is also scanning the table as we might not start at the beginning
of the table thanks to synchronize seq scans.
> IMHO it's not like we're making the ordering unpredictable - it's been
> like that since forever.
Yeah, there certainly seems like a lot of opportunity for the ordering
to end up being volatile already and queries depending on it not
changing really shouldn't be making that assumption. I do think it was
probably a bad move on our part to say that ordering a subquery will
"usually" work in the documentation but having that slip-up in the
documentation mean that we actually *are* going to guarantee it'll
always work to use a subquery ordering to feed an aggregate is a pretty
big stretch (and is it even really true today anyway? the documentation
certainly doesn't seem to be clear on that...).
> Also, how is this different from ORDER BY clause? If a user does not
> specify an ORDER BY clause, I don't think we'd care very much about
> changes to output ordering due to plan changes, for example.
This seems like it boils down to "well, everyone *knows* that rows can
come back in any order" combined with "our docs claim that an ordered
subquery will *usually* work".
In the end, I do tend to agree that we probably should add parallel
support to these aggregates, but it'd also be nice to hear from those
who had worked to add parallelism to the various aggregates as to if
there was some reason these were skipped.
Thanks!
Stephen
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Stephen Frost <sfrost(at)snowman(dot)net> |
| Cc: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 21:31:18 |
| Message-ID: | 19117.1522099878@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Stephen Frost <sfrost(at)snowman(dot)net> writes:
> Yeah, there certainly seems like a lot of opportunity for the ordering
> to end up being volatile already and queries depending on it not
> changing really shouldn't be making that assumption. I do think it was
> probably a bad move on our part to say that ordering a subquery will
> "usually" work in the documentation but having that slip-up in the
> documentation mean that we actually *are* going to guarantee it'll
> always work to use a subquery ordering to feed an aggregate is a pretty
> big stretch (and is it even really true today anyway? the documentation
> certainly doesn't seem to be clear on that...).
It's true as long as there's nothing in the outer query that would cause
re-ordering of the subquery output. I'd be the first to agree that the
wording is a bit sloppy, but I think there are lots of people depending
on that behavior, not least because that was the only way to do it before
we supported ORDER BY inside an aggregate call.
Now, that doesn't directly bear on the argument at hand, because if you're
aggregating over the result of an ORDER BY subquery then you aren't doing
parallel aggregation anyway. (Perhaps there's parallelism inside the
subquery, but that's irrelevant.) It is related in the sense that there
are lots of people depending on things other than ORDER-BY-in-the-
aggregate-call to get the results they expect.
regards, tom lane
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Stephen Frost <sfrost(at)snowman(dot)net> |
| Cc: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 21:54:32 |
| Message-ID: | CAKJS1f_n_Z+cGjG5SGeKxhCpRmpEifcoTgEqXkH2sra_ze8KJg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 10:20, Stephen Frost <sfrost(at)snowman(dot)net> wrote:
> In the end, I do tend to agree that we probably should add parallel
> support to these aggregates, but it'd also be nice to hear from those
> who had worked to add parallelism to the various aggregates as to if
> there was some reason these were skipped.
That was me. I originally skipped string_agg and array_agg as I
thought parallelism would not be much use due to the growth of the
size of the state. I thought the combine function could become very
expensive as it has to work on each aggregated value, instead of a
consolidated result, as the other aggregates provide. The reason for
adding this now and not back then is:
1. I was wrong, parallel aggregation can improve performance for these
aggregates, and;
2. It's annoying that a single non-partial aggregate in the query
disabled parallel aggregation, and;
3. When I originally considered the performance I didn't consider that
some queries may filter values before aggregation via a FILTER or a
WHERE clause.
4. It's not just parallel aggregation that uses partial aggregation,
we can now push aggregation below Append for partitioned tables in
some cases. Hopefully, we'll also have "group before join" one day
too.
While 2 is still true, there should be a reduction in the times this
happens. Just the json and xml aggs holding us back from the standard
set now.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 22:05:07 |
| Message-ID: | CAKJS1f9zUpF4Ntb4=2ba5cQ9YmHptnKUB4tuZZNDmv0OAZ2T4g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 09:27, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> I spent a fair amount of time hacking on this with intent to commit,
> but just as I was getting to code that I liked, I started to have second
> thoughts about whether this is a good idea at all. I quote from the fine
> manual:
>
> The aggregate functions array_agg, json_agg, jsonb_agg,
> json_object_agg, jsonb_object_agg, string_agg, and xmlagg, as well as
> similar user-defined aggregate functions, produce meaningfully
> different result values depending on the order of the input
> values. This ordering is unspecified by default, but can be controlled
> by writing an ORDER BY clause within the aggregate call, as shown in
> Section 4.2.7. Alternatively, supplying the input values from a sorted
> subquery will usually work ...
>
> I do not think it is accidental that these aggregates are exactly the ones
> that do not have parallelism support today. Rather, that's because you
> just about always have an interest in the order in which the inputs get
> aggregated, which is something that parallel aggregation cannot support.
This was not in my list of reasons for not adding them the first time
around. I mentioned these reasons in a response to Stephen.
> I fear that what will happen, if we commit this, is that something like
> 0.01% of the users of array_agg and string_agg will be pleased, another
> maybe 20% will be unaffected because they wrote ORDER BY which prevents
> parallel aggregation, and the remaining 80% will scream because we broke
> their queries. Telling them they should've written ORDER BY isn't going
> to cut it, IMO, when the benefit of that breakage will accrue only to some
> very tiny fraction of use-cases.
This very much reminds me of something that exists in the 8.4 release notes:
> SELECT DISTINCT and UNION/INTERSECT/EXCEPT no longer always produce sorted output (Tom)
> Previously, these types of queries always removed duplicate rows by means of Sort/Unique processing (i.e., sort then remove adjacent duplicates). Now they can be implemented by hashing, which will not produce sorted output. If an application relied on the output being in sorted order, the recommended fix is to add an ORDER BY clause. As a short-term workaround, the previous behavior can be restored by disabling enable_hashagg, but that is a very performance-expensive fix. SELECT DISTINCT ON never uses hashing, however, so its behavior is unchanged.
Seems we were happy enough then to tell users to add an ORDER BY.
However, this case is different, since before the results were always
ordered. This time they're possibly ordered. So we'll probably
surprise fewer people this time around.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 22:14:27 |
| Message-ID: | 13a2ab54-0d83-d2a2-faa2-963310d8f75f@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/26/2018 11:19 PM, Tom Lane wrote:
> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> On 03/26/2018 10:27 PM, Tom Lane wrote:
>>> I fear that what will happen, if we commit this, is that something like
>>> 0.01% of the users of array_agg and string_agg will be pleased, another
>>> maybe 20% will be unaffected because they wrote ORDER BY which prevents
>>> parallel aggregation, and the remaining 80% will scream because we broke
>>> their queries. Telling them they should've written ORDER BY isn't going
>>> to cut it, IMO, when the benefit of that breakage will accrue only to some
>>> very tiny fraction of use-cases.
>
>> Isn't the ordering unreliable *already*?
>
> Not if the query is such that what gets chosen is, say, an indexscan
> or mergejoin. It might be theoretically unreliable and yet work fine
> for a given application.
>
What about parallel versions of those plans, though? That is, what
prevents the planner from generating plans like this
Hash Aggregate
-> Gather
-> Partial Index Scan
AFAIK that's a valid plan, and it does not have the stable ordering
property of a non-parallel index scan. Similarly for Merge Join.
> I might be too pessimistic about the fraction of users who are depending
> on ordered input without having written anything that explicitly forces
> that ... but I stand by the theory that it substantially exceeds the
> fraction of users who could get any benefit.
>
Not sure, it's pretty much impossible to produce a number that would
meaningfully represent the whole user base. All I can say is that the
number of people I know, who would benefit from this is significant.
>
> Your own example of assuming that separate aggregates are computed
> in the same order reinforces my point, I think. In principle, anybody
> who's doing that should write
>
> array_agg(e order by x),
> array_agg(f order by x),
> string_agg(g order by x)
>
> because otherwise they shouldn't assume that; the manual certainly doesn't
> promise it. But nobody does that in production, because if they did
> they'd get killed by the fact that the sorts are all done independently.
Yes, the manual does not promise that. But I find that expectation way
more "natural" than deterministic ordering without ORDER BY clause. I
expect each tuple to be processed "at once" - that it's added to all
arrays in the same step, irrespectedly of the ordering of input tuples.
> (We should improve that someday, but it hasn't been done yet.) So I think
> there are an awful lot of people out there who are assuming more than a
> lawyerly reading of the manual would allow. Their reaction to this will
> be about like ours every time the GCC guys decide that some longstanding
> behavior of C code isn't actually promised by the text of the C standard.
>
But we're not *already* providing reliable ordering without an ORDER BY
clause (both for queries as a whole and array_agg/string_agg). It can
produce arbitrary ordering, depending on what plan you happen to get.
So I don't think we'd be changing any longstanding behavior, because
it's already unreliable. If it was semi-reliable before, assuming the
query only ever chose index scans or merge joins, it likely got broken
by introduction of parallel versions of those plans. If the users
disable parallel queries (to get the old plans), they're going to get
non-parallel semi-reliable plans again.
OTOH we are currently accumulating all the arrays in the same order, so
the results will match. (At least that's what I believe is the current
reliable behavior.) So following the GCC analogy, changing this seems
much more akin to GCC people changing some longstanding behavior.
Also, if the arrays were not accumulated in the same way reliably,
wouldn't this mean all the discussion about reliable ordering with
certain plans is pointless?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 22:28:46 |
| Message-ID: | 22068.1522103326@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
> On 27 March 2018 at 09:27, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> I do not think it is accidental that these aggregates are exactly the ones
>> that do not have parallelism support today. Rather, that's because you
>> just about always have an interest in the order in which the inputs get
>> aggregated, which is something that parallel aggregation cannot support.
> This very much reminds me of something that exists in the 8.4 release notes:
>> SELECT DISTINCT and UNION/INTERSECT/EXCEPT no longer always produce sorted output (Tom)
That's a completely false analogy: we got a significant performance
benefit for a significant fraction of users by supporting hashed
aggregation. My argument here is that only a very tiny fraction of
string_agg/array_agg users will not care about aggregation order, and thus
I don't believe that this patch can help very many people. Against that,
it's likely to hurt other people, by breaking their queries and forcing
them to insert expensive explicit sorts to fix it. Even discounting the
backwards-compatibility question, we don't normally adopt performance
features for which it's unclear that the net gain over all users is
positive.
Maybe what that says is that rather than giving up on this altogether,
we should shelve it till we have less stupid planner+executor behavior
for ORDER BY inside aggregates. That's been on the to-do list for
a long while, but not risen to the top ...
regards, tom lane
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-26 23:49:24 |
| Message-ID: | 25812.1522108164@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I wrote:
> The main thing that remains undone is to get some test coverage ---
> AFAICS, none of these new functions get exercised in the standard
> regression tests.
Oh, I thought of another thing that would need to get done, if we decide
to commit this. array_agg_serialize/deserialize only work if the array
element type has send/receive functions. The planner's logic to decide
whether partial aggregation is possible doesn't look any deeper than
whether the aggregate has serialize/deserialize, but I think we have to
teach it that if it's these particular serialize/deserialize functions,
it needs to check the array element type. Otherwise we'll get runtime
failures if partial aggregation is attempted on array_agg().
This would not matter for any core datatypes, since they all have
send/receive functions, but I imagine it's still pretty common for
extension types not to.
For my money it'd be sufficient to hard-code the test like
if ((aggserialfn == F_ARRAY_AGG_SERIALIZE ||
aggdeserialfn == F_ARRAY_AGG_DESERIALIZE) &&
!array_element_type_has_send_and_recv(exprType(aggregate input)))
Someday we might need more flexible testing, but that can be solved
some other time.
regards, tom lane
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 00:14:15 |
| Message-ID: | CAKJS1f-Qcv2FiUHKCS_2OT3Gb3bOW_yZw9mKSCj=SDwYMH85hA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 11:28, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
>> This very much reminds me of something that exists in the 8.4 release notes:
>>> SELECT DISTINCT and UNION/INTERSECT/EXCEPT no longer always produce sorted output (Tom)
>
> That's a completely false analogy: we got a significant performance
> benefit for a significant fraction of users by supporting hashed
> aggregation. My argument here is that only a very tiny fraction of
> string_agg/array_agg users will not care about aggregation order, and thus
> I don't believe that this patch can help very many people. Against that,
> it's likely to hurt other people, by breaking their queries and forcing
> them to insert expensive explicit sorts to fix it. Even discounting the
> backwards-compatibility question, we don't normally adopt performance
> features for which it's unclear that the net gain over all users is
> positive.
I don't believe you can go and claim this is a false analogy based on
your estimates on the number of cases in which each applies. The
analogy which I was pointing at was that we've been here before...
we've had versions of the planner which generated plans which would
have a deterministic sort order and we've later discovered that we can
improve performance by allowing the planner to have more flexibility
to do things in different ways which may no longer provide implicitly
sorted results. We've previously recognised that some users may have
become accustomed to the previous behaviour and we've mentioned a
workaround in the release notes so that those users are not out in the
cold. This seems exactly the same to me, and certainly not "false".
I have to say, it really would be a shame to have this concern block
us from future optimisations in aggregation.
I also think that anyone who expects string_agg to always aggregate in
the same order has not done a good job of looking at the docs. I see
you already quoted the "This ordering is unspecified by default, but
can be controlled by writing an ORDER BY clause within the aggregate
call, as shown in Section 4.2.7." part. This text appears in all
version of PostgreSQL that we currently support. We do sometimes
change things where the docs say something like "this works, but don't
rely on it, we might change in the future", in this case, we've never
even claimed that it worked in the first place!
Anyway, the options are not zero for anyone who is strongly affected
with no other workaround. They just need to disable parallel query,
which to me seems fairly similar to the 8.4 release note's "the
previous behavior can be restored by disabling enable_hashagg"
If we go by your argument then we should perhaps remove parallel
aggregation for all the floating point types too, since the order in
which such values are aggregated also can affect the result. I
mentioned this in [1], but nobody seemed too concerned at the time.
I see some other discussion on this whole topic in [2]. Looks like
parallel array_agg would please the PostGIS people.
[1] https://www.postgresql.org/message-id/CAKJS1f8QRDLvewk336SzUzxiXH1wBHG8rdKsqWEHbAraMXA2_Q%40mail.gmail.com
[2] https://www.postgresql.org/message-id/flat/CAFjFpRe9W5xvYai-QOs6RshrJf7gWFsiZEZtxnu8vD4qLQZ3LQ%40mail(dot)gmail(dot)com#CAFjFpRe9W5xvYai-QOs6RshrJf7gWFsiZEZtxnu8vD4qLQZ3LQ(at)mail(dot)gmail(dot)com
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 00:20:01 |
| Message-ID: | 20180327002001.nmu6ww6f2mk7wuny@alap3.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 2018-03-27 13:14:15 +1300, David Rowley wrote:
> I have to say, it really would be a shame to have this concern block
> us from future optimisations in aggregation.
Yea, I think that's an important point. By the dint of Tom's argument
we're never going to be able to provide parallelism for any aggregate
where input order matters. It's not like users are magically going to
stop depending on it, if they already do. Seems more likely that we'll
grow more users depending on it.
We could theoretically provide differently named aggregates where one
allows parallelism, the other doesn't, without duplicating the backing
code... Not pretty tho.
Greetings,
Andres Freund
| From: | Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 00:26:17 |
| Message-ID: | 20180327002617.fjgkgxmeojfkti7b@alvherre.pgsql |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
David Rowley wrote:
> Anyway, the options are not zero for anyone who is strongly affected
> with no other workaround. They just need to disable parallel query,
> which to me seems fairly similar to the 8.4 release note's "the
> previous behavior can be restored by disabling enable_hashagg"
synchronized_seqscans is another piece of precedent in the area, FWIW.
--
Álvaro Herrera https://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 00:38:42 |
| Message-ID: | CAKJS1f-1zxwY9-jWwdB47+24NwbUzgWAOAGhECnvQKSDXRP_wg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 13:26, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> wrote:
> David Rowley wrote:
>
>> Anyway, the options are not zero for anyone who is strongly affected
>> with no other workaround. They just need to disable parallel query,
>> which to me seems fairly similar to the 8.4 release note's "the
>> previous behavior can be restored by disabling enable_hashagg"
>
> synchronized_seqscans is another piece of precedent in the area, FWIW.
This is true. I guess the order of aggregation could be made more
certain if we remove the cost based optimiser completely, and just
rely on a syntax based optimiser. Unfortunately, even with that
UPDATE will still reuse free space created by DELETE+VACUUM, so we'd
need to get rid of VACUUM too. Of course, I'm not being serious, but I
was just trying to show there's a lot more to be done if we want to
make the aggregate input order deterministic without an ORDER BY in
the aggregate function.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 00:45:29 |
| Message-ID: | CAKJS1f87rFqL0=ksfs+3mmQvg_R0RRGEXyayxHkwYnFqeKpngQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 12:49, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> I wrote:
>> The main thing that remains undone is to get some test coverage ---
>> AFAICS, none of these new functions get exercised in the standard
>> regression tests.
>
> Oh, I thought of another thing that would need to get done, if we decide
> to commit this. array_agg_serialize/deserialize only work if the array
> element type has send/receive functions. The planner's logic to decide
> whether partial aggregation is possible doesn't look any deeper than
> whether the aggregate has serialize/deserialize, but I think we have to
> teach it that if it's these particular serialize/deserialize functions,
> it needs to check the array element type. Otherwise we'll get runtime
> failures if partial aggregation is attempted on array_agg().
>
> This would not matter for any core datatypes, since they all have
> send/receive functions, but I imagine it's still pretty common for
> extension types not to.
>
> For my money it'd be sufficient to hard-code the test like
>
> if ((aggserialfn == F_ARRAY_AGG_SERIALIZE ||
> aggdeserialfn == F_ARRAY_AGG_DESERIALIZE) &&
> !array_element_type_has_send_and_recv(exprType(aggregate input)))
I'd failed to consider this.
Would it not be cleaner to just reject trans types without a
send/receive function? Or do you think that would exclude other valid
cases?
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 02:51:08 |
| Message-ID: | CAKJS1f9oTWG4oc7B2WfDhT11KhxeV1miLQ+PzB6hY=iJeHM28A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 13:45, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> wrote:
> On 27 March 2018 at 12:49, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> Oh, I thought of another thing that would need to get done, if we decide
>> to commit this. array_agg_serialize/deserialize only work if the array
>> element type has send/receive functions. The planner's logic to decide
>> whether partial aggregation is possible doesn't look any deeper than
>> whether the aggregate has serialize/deserialize, but I think we have to
>> teach it that if it's these particular serialize/deserialize functions,
>> it needs to check the array element type. Otherwise we'll get runtime
>> failures if partial aggregation is attempted on array_agg().
>>
>> This would not matter for any core datatypes, since they all have
>> send/receive functions, but I imagine it's still pretty common for
>> extension types not to.
>>
>> For my money it'd be sufficient to hard-code the test like
>>
>> if ((aggserialfn == F_ARRAY_AGG_SERIALIZE ||
>> aggdeserialfn == F_ARRAY_AGG_DESERIALIZE) &&
>> !array_element_type_has_send_and_recv(exprType(aggregate input)))
>
> I'd failed to consider this.
>
> Would it not be cleaner to just reject trans types without a
> send/receive function? Or do you think that would exclude other valid
> cases?
Seems I didn't mean "trans types". I should have said aggregate
function argument types.
The attached I adds this check.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| no_parallel_agg_when_agg_args_dont_have_sendrecv.patch | application/octet-stream | 4.0 KB |
| From: | Magnus Hagander <magnus(at)hagander(dot)net> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 07:06:59 |
| Message-ID: | CABUevEzy6=AT3meQf7q4jfP65nWjEGjPT_8D9n+BxanEgVozWw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Mar 27, 2018 at 12:28 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
> > On 27 March 2018 at 09:27, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> >> I do not think it is accidental that these aggregates are exactly the
> ones
> >> that do not have parallelism support today. Rather, that's because you
> >> just about always have an interest in the order in which the inputs get
> >> aggregated, which is something that parallel aggregation cannot support.
>
> > This very much reminds me of something that exists in the 8.4 release
> notes:
> >> SELECT DISTINCT and UNION/INTERSECT/EXCEPT no longer always produce
> sorted output (Tom)
>
> That's a completely false analogy: we got a significant performance
> benefit for a significant fraction of users by supporting hashed
> aggregation. My argument here is that only a very tiny fraction of
> string_agg/array_agg users will not care about aggregation order, and thus
> I don't believe that this patch can help very many people. Against that,
> it's likely to hurt other people, by breaking their queries and forcing
> them to insert expensive explicit sorts to fix it. Even discounting the
> backwards-compatibility question, we don't normally adopt performance
> features for which it's unclear that the net gain over all users is
> positive.
>
I think you are quite wrong in claiming that only a tiny fraction of the
users are going to care.
This may, and quite probably does, hold true for string_agg(), but not for
array_agg(). I see a lot of cases where people use that to load it into an
unordered array/hashmap/set/whatever on the client side, which looses
ordering *anyway*,and they would definitely benefit from it.
--
Magnus Hagander
Me: https://www.hagander.net/ <http://www.hagander.net/>
Work: https://www.redpill-linpro.com/ <http://www.redpill-linpro.com/>
| From: | Andrew Dunstan <andrew(dot)dunstan(at)2ndquadrant(dot)com> |
|---|---|
| To: | Magnus Hagander <magnus(at)hagander(dot)net> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 07:22:39 |
| Message-ID: | CAA8=A7-OrZDOcRwZjqNv8nNEQzE8JSbjTsAjv2CK2zyq4jPe+A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Mar 27, 2018 at 5:36 PM, Magnus Hagander <magnus(at)hagander(dot)net> wrote:
> On Tue, Mar 27, 2018 at 12:28 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>>
>> David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
>> > On 27 March 2018 at 09:27, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> >> I do not think it is accidental that these aggregates are exactly the
>> >> ones
>> >> that do not have parallelism support today. Rather, that's because you
>> >> just about always have an interest in the order in which the inputs get
>> >> aggregated, which is something that parallel aggregation cannot
>> >> support.
>>
>> > This very much reminds me of something that exists in the 8.4 release
>> > notes:
>> >> SELECT DISTINCT and UNION/INTERSECT/EXCEPT no longer always produce
>> >> sorted output (Tom)
>>
>> That's a completely false analogy: we got a significant performance
>> benefit for a significant fraction of users by supporting hashed
>> aggregation. My argument here is that only a very tiny fraction of
>> string_agg/array_agg users will not care about aggregation order, and thus
>> I don't believe that this patch can help very many people. Against that,
>> it's likely to hurt other people, by breaking their queries and forcing
>> them to insert expensive explicit sorts to fix it. Even discounting the
>> backwards-compatibility question, we don't normally adopt performance
>> features for which it's unclear that the net gain over all users is
>> positive.
>
>
> I think you are quite wrong in claiming that only a tiny fraction of the
> users are going to care.
>
> This may, and quite probably does, hold true for string_agg(), but not for
> array_agg(). I see a lot of cases where people use that to load it into an
> unordered array/hashmap/set/whatever on the client side, which looses
> ordering *anyway*,and they would definitely benefit from it.
Agreed, I have seen lots of uses of array_agg where the order didn't matter.
cheers
andrew
--
Andrew Dunstan https://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 14:58:14 |
| Message-ID: | 13700.1522162694@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
> On 27 March 2018 at 13:26, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> wrote:
>> synchronized_seqscans is another piece of precedent in the area, FWIW.
> This is true. I guess the order of aggregation could be made more
> certain if we remove the cost based optimiser completely, and just
> rely on a syntax based optimiser.
None of this is responding to my point. I think the number of people
who actually don't care about aggregation order for these aggregates
is negligible, and none of you have argued against that; you've instead
selected straw men to attack.
regards, tom lane
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-27 17:31:46 |
| Message-ID: | 05f1e4ea-4c73-3ac8-6dd1-14e0a94aa005@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/27/2018 04:58 PM, Tom Lane wrote:
> David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
>> On 27 March 2018 at 13:26, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> wrote:
>>> synchronized_seqscans is another piece of precedent in the area, FWIW.
>
>> This is true. I guess the order of aggregation could be made more
>> certain if we remove the cost based optimiser completely, and just
>> rely on a syntax based optimiser.
>
> None of this is responding to my point. I think the number of people
> who actually don't care about aggregation order for these aggregates
> is negligible, and none of you have argued against that; you've
> instead selected straw men to attack.
>
I don't quite see what the straw men are, TBH. (And David's response was
obviously meant as a tongue-in-cheek.)
Let me try addressing your point, as stated in your earlier message.
On 03/27/2018 12:28 AM, Tom Lane wrote:
> My argument here is that only a very tiny fraction of
> string_agg/array_agg users will not care about aggregation order,
> and thus I don't believe that this patch can help very many people.
> Against that, it's likely to hurt other people, by breaking their
> queries and forcing them to insert expensive explicit sorts to fix
> it.
You're claiming this is a choice between "reliable aggregation order"
vs. "parallel aggregation." I find that dubious.
My argument is that we do not provide any reliable aggregation order,
unless the user supplies ORDER BY in the aggregate, or takes care about
input ordering (essentially doing a subquery with ORDER BY).
Users may rely on getting the "right" plan, but unless they take special
care (disabling some plans etc.) that's just pure luck. Not only is
there plenty of stuff that can trigger plan change (misestimates, data
growth, ...) but we also add new plans that don't produce the same
ordering (e.g. parallel versions of some plans).
And if they already take the extra care, they can disable parallel query
to get the same plan. It's true that's all or nothing, and they might be
benefiting from parallel query in different part of the query, in which
case they'll need to modify the query.
> Even discounting the backwards-compatibility question, we don't
> normally adopt performance features for which it's unclear that the
> net gain over all users is positive.
We only really have anecdotal data, both of us. We can make some
guesses, but that's about it.
I don't know anyone who would be relying on array_agg ordering without
the explicit ORDER BY somewhere (particularly not after major upgrades).
But obviously those issues only surface after the change is made.
I do however know people who are badly affected by array_agg() disabling
parallel aggregate for other aggregates. They don't care about aggregate
order (typically it's filtering + unnest or export).
> Maybe what that says is that rather than giving up on this
> altogether, we should shelve it till we have less stupid
> planner+executor behavior for ORDER BY inside aggregates. That's
> been on the to-do list for a long while, but not risen to the top
> ...
That would be a valid choice if there was a reliable aggregate order.
But AFAIK there isn't, as explained above.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-28 00:06:37 |
| Message-ID: | 452e8b7f-418b-4e61-c212-c0e4410b94ad@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/27/2018 04:51 AM, David Rowley wrote:
> On 27 March 2018 at 13:45, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> wrote:
>> On 27 March 2018 at 12:49, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>>> Oh, I thought of another thing that would need to get done, if we decide
>>> to commit this. array_agg_serialize/deserialize only work if the array
>>> element type has send/receive functions. The planner's logic to decide
>>> whether partial aggregation is possible doesn't look any deeper than
>>> whether the aggregate has serialize/deserialize, but I think we have to
>>> teach it that if it's these particular serialize/deserialize functions,
>>> it needs to check the array element type. Otherwise we'll get runtime
>>> failures if partial aggregation is attempted on array_agg().
>>>
>>> This would not matter for any core datatypes, since they all have
>>> send/receive functions, but I imagine it's still pretty common for
>>> extension types not to.
>>>
>>> For my money it'd be sufficient to hard-code the test like
>>>
>>> if ((aggserialfn == F_ARRAY_AGG_SERIALIZE ||
>>> aggdeserialfn == F_ARRAY_AGG_DESERIALIZE) &&
>>> !array_element_type_has_send_and_recv(exprType(aggregate input)))
>>
>> I'd failed to consider this.
>>
>> Would it not be cleaner to just reject trans types without a
>> send/receive function? Or do you think that would exclude other valid
>> cases?
>
> Seems I didn't mean "trans types". I should have said aggregate
> function argument types.
>
> The attached I adds this check.
>
I'm not sure that's better than the check proposed by Tom. An argument
type without send/receive function does not necessarily mean we can't
serialize/deserialize the trans value. Because who says the argument
value will be embedded in the trans value?
For example, I might create an aggregate to build a bloom filter,
accepting anyelement. That will hash the argument value, and obviously
has no issues with serializing/deserializing the trans value.
This check would effectively disable parallelism for all aggregates with
anyarray, anyelement, anynonarray, anyenum (and a few more) arguments.
That for example includes jsonb_agg, which some people already mentioned
as another candidate for enabling parallelism. Not great, I guess.
Tom's solution is much more focused - it recognizes that array_agg is a
fairly rare case where the (actual) argument type gets stored in the
trans type, and detects that.
PS: The function is misnamed - you're talking about argument types, yet
the function name refers to transtypes.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-28 03:28:19 |
| Message-ID: | 19216.1522207699@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> On 03/27/2018 04:51 AM, David Rowley wrote:
>> Seems I didn't mean "trans types". I should have said aggregate
>> function argument types.
> I'm not sure that's better than the check proposed by Tom. An argument
> type without send/receive function does not necessarily mean we can't
> serialize/deserialize the trans value. Because who says the argument
> value will be embedded in the trans value?
In general we would not know that, but *for these specific serial/
deserial functions*, we know exactly what they will do. Also, IIRC,
the trans type is declared as INTERNAL, so we don't really have any
hope of identifying the behavior by inspecting that type declaration.
Getting a solution that would work for other polymorphic serialization
functions seems like a bit of a research project to me. In the meantime,
I think David's right that what we need to look at is the actual input
type of the aggregate, and then assume that what's to be serialized is
an array of that. Conceivably an aggregate could be built that uses
these serial/deserial functions and yet its input type is something else
than what it constructs an array of ... but I find it a bit hard to
wrap my brain around what that would be exactly.
regards, tom lane
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-28 12:29:11 |
| Message-ID: | f1fc0953-93a9-41f3-ecd4-dbc0acd63f23@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/28/2018 05:28 AM, Tom Lane wrote:
> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> On 03/27/2018 04:51 AM, David Rowley wrote:
>>> Seems I didn't mean "trans types". I should have said aggregate
>>> function argument types.
>
>> I'm not sure that's better than the check proposed by Tom. An argument
>> type without send/receive function does not necessarily mean we can't
>> serialize/deserialize the trans value. Because who says the argument
>> value will be embedded in the trans value?
>
> In general we would not know that, but *for these specific serial/
> deserial functions*, we know exactly what they will do. Also, IIRC,
> the trans type is declared as INTERNAL, so we don't really have any
> hope of identifying the behavior by inspecting that type declaration.
>
Sure, which is why I thought your solution was better, as it was
targeted at those particular functions.
> Getting a solution that would work for other polymorphic serialization
> functions seems like a bit of a research project to me. In the meantime,
> I think David's right that what we need to look at is the actual input
> type of the aggregate, and then assume that what's to be serialized is
> an array of that. Conceivably an aggregate could be built that uses
> these serial/deserial functions and yet its input type is something else
> than what it constructs an array of ... but I find it a bit hard to
> wrap my brain around what that would be exactly.
>
But David's fix doesn't check the aggregate to produce an array of the
input type (or anyarray). It could easily be an aggregate computing a
bloom filter or something like that, which has no such issues in the
serial/deserial functions.
Also, if it's checking aggref->aggargtypes, it'll reject anyelement
parameters, no?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-28 13:54:38 |
| Message-ID: | 18741.1522245278@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> On 03/28/2018 05:28 AM, Tom Lane wrote:
>> Getting a solution that would work for other polymorphic serialization
>> functions seems like a bit of a research project to me. In the meantime,
>> I think David's right that what we need to look at is the actual input
>> type of the aggregate, and then assume that what's to be serialized is
>> an array of that. Conceivably an aggregate could be built that uses
>> these serial/deserial functions and yet its input type is something else
>> than what it constructs an array of ... but I find it a bit hard to
>> wrap my brain around what that would be exactly.
> But David's fix doesn't check the aggregate to produce an array of the
> input type (or anyarray). It could easily be an aggregate computing a
> bloom filter or something like that, which has no such issues in the
> serial/deserial functions.
Oh, if he's not restricting it to these serialization functions, I agree
that seems wrong. I thought the discussion was about what to do after
checking the functions.
> Also, if it's checking aggref->aggargtypes, it'll reject anyelement
> parameters, no?
I had in mind to look at exprType() of the argument.
regards, tom lane
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-28 13:57:30 |
| Message-ID: | CAKJS1f-MuzHQ=Em4J+xWC4bRXMJF99Hb-N0TmC=UrJCM9tAYVw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 28 March 2018 at 03:58, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
>> On 27 March 2018 at 13:26, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> wrote:
>>> synchronized_seqscans is another piece of precedent in the area, FWIW.
>
>> This is true. I guess the order of aggregation could be made more
>> certain if we remove the cost based optimiser completely, and just
>> rely on a syntax based optimiser.
>
> None of this is responding to my point. I think the number of people
> who actually don't care about aggregation order for these aggregates
> is negligible, and none of you have argued against that; you've instead
> selected straw men to attack.
I think what everyone else is getting at is that we're not offering to
improve the performance of the people who care about the order which
the values are aggregated. This patch only offers a possible
performance benefit to those who don't. I mentioned and linked to a
thread about someone from PostGIS asking for this, which as far as I
understand has quite a large user base. You've either ignored that or
think the number of people using PostGIS is negligible.
As far as I understand your argument, it's about there being a
possibility a group of people existing who rely on the aggregation
order being defined without an ORDER BY in the aggregate function.
Unfortunately, It appears from the responses from many of the other's
who voiced an opinion about this is that there is no shortage of other
reasons why relying on values being aggregated in a defined order
without an ORDER BY in the aggregate function arguments is a dangerous
assumption to make. Several reasons were listed why this is undefined
and I mentioned the great lengths we'd need to go to do make the order
more defined without an explicit ORDER BY, and I still imagine I'd
have missed some of the reasons. I imagine the number of people which
rely on the order being defined without an ORDER BY is diminishing
each release as we add parallelism support for more node types. Both
Andres and I agree that it's a shame to block useful optimisations due
to the needs of a small diminishing group of people who are not very
good at reading our carefully crafted documentation... for the past 8
years [1].
I imagine this small group of people, if they do exist, must slowly be
waking up to the fact that we've been devising new ways to ruin their
query results for many years now. It seems pretty strange for us to
call a truce now after we've been wreaking havoc on this group for so
many releases... I really do hope this part is not true, but if such a
person appeared in -novice or -general asking for help, we'd be
telling them to add an ORDER BY, and we'd be quoting the 8-year-old
line in the documents which states that we make no guarantees in this
area in the absence of an ORDER BY. If they truly have no other
choice then we might consider suggesting they may get what they want
if they disable parallel query, and we'd probably rhyme off a few
other reasons why it might suddenly break on them again.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-28 14:05:05 |
| Message-ID: | 1ffa699d-ff84-4c21-10cb-4d8b36017bab@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/28/2018 03:54 PM, Tom Lane wrote:
> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> On 03/28/2018 05:28 AM, Tom Lane wrote:
>>> Getting a solution that would work for other polymorphic serialization
>>> functions seems like a bit of a research project to me. In the meantime,
>>> I think David's right that what we need to look at is the actual input
>>> type of the aggregate, and then assume that what's to be serialized is
>>> an array of that. Conceivably an aggregate could be built that uses
>>> these serial/deserial functions and yet its input type is something else
>>> than what it constructs an array of ... but I find it a bit hard to
>>> wrap my brain around what that would be exactly.
>
>> But David's fix doesn't check the aggregate to produce an array of the
>> input type (or anyarray). It could easily be an aggregate computing a
>> bloom filter or something like that, which has no such issues in the
>> serial/deserial functions.
>
> Oh, if he's not restricting it to these serialization functions, I
> agree that seems wrong. I thought the discussion was about what to
> do after checking the functions.
>
Nope, David's patch does not check what the serial/deserial functions
are (and checks aggref->aggargtypes directly, not the exprType thing).
>> Also, if it's checking aggref->aggargtypes, it'll reject anyelement
>> parameters, no?
>
> I had in mind to look at exprType() of the argument.
>
Right, I'm fine with that.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-28 15:36:42 |
| Message-ID: | CAKJS1f9SN3ogB=n=DC4A7bv1PBqNuxPE_xcAKFC7dEWvU9F=oA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 March 2018 at 09:27, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> The main thing that remains undone is to get some test coverage ---
> AFAICS, none of these new functions get exercised in the standard
> regression tests.
I've attached a patch which implements some tests for the new functions.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| parallel_string_agg_array_agg_tests.patch | application/octet-stream | 7.8 KB |
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-29 03:49:02 |
| Message-ID: | CAKJS1f95uF3h0PdMj-zqnTcJXnF68bT4nUKgiXtAdEz44W5HWg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 29 March 2018 at 03:05, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> On 03/28/2018 03:54 PM, Tom Lane wrote:
>> I had in mind to look at exprType() of the argument.
>
> Right, I'm fine with that.
Attached is v9, which is based on Tom's v8 but includes the new tests
and I think the required fix to disable use of the serial/deserial
function for array_agg().
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v9.patch | application/octet-stream | 45.3 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-29 13:00:34 |
| Message-ID: | 13e3fd13-8152-72be-4e3c-8095e6ec0995@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/29/2018 05:49 AM, David Rowley wrote:
> On 29 March 2018 at 03:05, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>> On 03/28/2018 03:54 PM, Tom Lane wrote:
>>> I had in mind to look at exprType() of the argument.
>>
>> Right, I'm fine with that.
>
> Attached is v9, which is based on Tom's v8 but includes the new tests
> and I think the required fix to disable use of the serial/deserial
> function for array_agg().
>
I have only looked at the diff, but it seems fine to me (in the sense
that it's doing the right checks to disable parallelism only when really
needed).
FWIW I wonder if we might simply fallback to input/output functions when
the send/receive functions are not available. Not sure it's worth it.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-29 13:09:33 |
| Message-ID: | CAKJS1f-S493AXpKAiri7cSFfhy2vy5kLHzkTDXC5QzoxMJ5Lkg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 30 March 2018 at 02:00, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> On 03/29/2018 05:49 AM, David Rowley wrote:
>> Attached is v9, which is based on Tom's v8 but includes the new tests
>> and I think the required fix to disable use of the serial/deserial
>> function for array_agg().
>>
>
> I have only looked at the diff, but it seems fine to me (in the sense
> that it's doing the right checks to disable parallelism only when really
> needed).
>
> FWIW I wonder if we might simply fallback to input/output functions when
> the send/receive functions are not available. Not sure it's worth it.
I think it's a corner case to have a type without send/receive, but I
might just be lacking imagination.
I meant to mention earlier that I coded
agg_args_have_sendreceive_funcs() to only check for send/receive
functions. Really we could allow a byval types without send/receive
functions, since the serial/deserial just send the raw datums in that
case, but then the function becomes
agg_byref_args_have_sendreceive_funcs(), which seemed a bit obscure,
so I didn't do that. Maybe I should?
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-29 13:55:50 |
| Message-ID: | 73ea70fa-9ada-deb5-549e-02fa2f0969c6@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/29/2018 03:09 PM, David Rowley wrote:
> On 30 March 2018 at 02:00, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>> On 03/29/2018 05:49 AM, David Rowley wrote:
>>> Attached is v9, which is based on Tom's v8 but includes the new tests
>>> and I think the required fix to disable use of the serial/deserial
>>> function for array_agg().
>>>
>>
>> I have only looked at the diff, but it seems fine to me (in the sense
>> that it's doing the right checks to disable parallelism only when really
>> needed).
>>
>> FWIW I wonder if we might simply fallback to input/output functions when
>> the send/receive functions are not available. Not sure it's worth it.
>
> I think it's a corner case to have a type without send/receive, but I
> might just be lacking imagination.
>
Not sure, but it's a valid case. OTOH we probably don't need to obsess
about handling it perfectly.
> I meant to mention earlier that I coded
> agg_args_have_sendreceive_funcs() to only check for send/receive
> functions. Really we could allow a byval types without send/receive
> functions, since the serial/deserial just send the raw datums in that
> case, but then the function becomes
> agg_byref_args_have_sendreceive_funcs(), which seemed a bit obscure,
> so I didn't do that. Maybe I should?
>
I'd do that. Not sure the function name needs to change, but perhaps
agg_args_support_sendreceive() would be better - it covers both byref
types (which require send/receive functions) and byval (which don't).
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-03-31 14:42:12 |
| Message-ID: | CAKJS1f9jP_b=yoLa5bt9WPC5mtNgMKFgP6FH2ejZ_PqYyxbDAQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 30 March 2018 at 02:55, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> On 03/29/2018 03:09 PM, David Rowley wrote:
>> I meant to mention earlier that I coded
>> agg_args_have_sendreceive_funcs() to only check for send/receive
>> functions. Really we could allow a byval types without send/receive
>> functions, since the serial/deserial just send the raw datums in that
>> case, but then the function becomes
>> agg_byref_args_have_sendreceive_funcs(), which seemed a bit obscure,
>> so I didn't do that. Maybe I should?
>
> I'd do that. Not sure the function name needs to change, but perhaps
> agg_args_support_sendreceive() would be better - it covers both byref
> types (which require send/receive functions) and byval (which don't).
The attached patch implements this.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v10.patch | application/octet-stream | 45.3 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-04-04 19:12:54 |
| Message-ID: | ad2283b9-64bd-3016-da60-648ba9c13c5f@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03/31/2018 04:42 PM, David Rowley wrote:
> On 30 March 2018 at 02:55, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>> On 03/29/2018 03:09 PM, David Rowley wrote:
>>> I meant to mention earlier that I coded
>>> agg_args_have_sendreceive_funcs() to only check for send/receive
>>> functions. Really we could allow a byval types without send/receive
>>> functions, since the serial/deserial just send the raw datums in that
>>> case, but then the function becomes
>>> agg_byref_args_have_sendreceive_funcs(), which seemed a bit obscure,
>>> so I didn't do that. Maybe I should?
>>
>> I'd do that. Not sure the function name needs to change, but perhaps
>> agg_args_support_sendreceive() would be better - it covers both byref
>> types (which require send/receive functions) and byval (which don't).
>
> The attached patch implements this.
>
Seems fine to me, although we should handle the anyarray case too, I
guess. That is, get_agg_clause_costs_walker() should do this too:
/* Same thing for array_agg_array_(de)serialize. */
if ((aggserialfn == F_ARRAY_AGG_ARRAY_SERIALIZE ||
aggdeserialfn == F_ARRAY_AGG_ARRAY_DESERIALIZE) &&
!agg_args_support_sendreceive(aggref))
costs->hasNonSerial = true;
Other than that, the patch seems fine to me, and it's already marked as
RFC so I'll leave it at that.
The last obstacle seems to be the argument about the risks of the patch
breaking queries of people relying on the ordering. Not sure what's are
the right next steps in this regard ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-04-05 03:41:30 |
| Message-ID: | CAKJS1f_yDsOrSffHBqAN3Gx27R1vW6OHaKy_EwnhnLZJmo8+Mw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi Tomas,
Thanks for taking another look.
On 5 April 2018 at 07:12, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> Seems fine to me, although we should handle the anyarray case too, I
> guess. That is, get_agg_clause_costs_walker() should do this too:
>
> /* Same thing for array_agg_array_(de)serialize. */
> if ((aggserialfn == F_ARRAY_AGG_ARRAY_SERIALIZE ||
> aggdeserialfn == F_ARRAY_AGG_ARRAY_DESERIALIZE) &&
> !agg_args_support_sendreceive(aggref))
> costs->hasNonSerial = true;
hmm, array_agg_array_serialize and array_agg_array_deserialize don't
use the send/receive functions though, so not sure why that's
required?
> Other than that, the patch seems fine to me, and it's already marked as
> RFC so I'll leave it at that.
Thanks.
> The last obstacle seems to be the argument about the risks of the patch
> breaking queries of people relying on the ordering. Not sure what's are
> the right next steps in this regard ...
yeah, seems like a bit of a stalemate.
Personally, think if the group of people Tom mentions do exist, then
they've already been through some troubled times since Parallel Query
was born. I'd hope they've already put up their defenses due to the
advent of that feature. I stand by my thoughts that it's pretty
bizarre to draw the line here when we've probably been causing these
people issues for many years already. I said my piece on this already
so likely not much point in going on about it. These people are also
perfectly capable of sidestepping the whole issue with setting
max_parallel_workers_per_gather TO 0.
Perhaps one solution is to drop the string_agg and keep the array_agg.
Unsure if that would be good enough for Tom? More people seem to have
voiced that array_agg ordering is generally less of a concern, which I
imagine is probably true, but my opinion might not matter here as I'm
the sort of person who if I needed a specific ordering I'd have
written an ORDER BY clause.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | "Tels" <nospam-pg-abuse(at)bloodgate(dot)com> |
|---|---|
| To: | "David Rowley" <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | "Tomas Vondra" <tomas(dot)vondra(at)2ndquadrant(dot)com>, "Tom Lane" <tgl(at)sss(dot)pgh(dot)pa(dot)us>, "Stephen Frost" <sfrost(at)snowman(dot)net>, "Andres Freund" <andres(at)anarazel(dot)de>, "PostgreSQL-development" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-04-05 19:10:13 |
| Message-ID: | f459ffbfad91ece161b8dc6095f3475e.squirrel@sm.webmail.pair.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Moin,
On Wed, April 4, 2018 11:41 pm, David Rowley wrote:
> Hi Tomas,
>
> Thanks for taking another look.
>
> On 5 April 2018 at 07:12, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>
> wrote:
>> Other than that, the patch seems fine to me, and it's already marked as
>> RFC so I'll leave it at that.
>
> Thanks.
I have one more comment - sorry for not writing sooner, the flu got to me ...
Somewhere in the code there is a new allocation of memory when the string
grows beyond the current size - and that doubles the size. This can lead
to a lot of wasted space (think: constructing a string that is a bit over
1 Gbyte, which would presumable allocate 2 GByte).
The same issue happens when each worker allocated 512 MByte for a 256
Mbyte + 1 result.
IMHO a factor of like 1.4 or 1.2 would work better here - not sure what
the current standard in situations like this in PG is.
>> The last obstacle seems to be the argument about the risks of the patch
>> breaking queries of people relying on the ordering. Not sure what's are
>> the right next steps in this regard ...
>
> yeah, seems like a bit of a stalemate.
>
> Personally, think if the group of people Tom mentions do exist, then
> they've already been through some troubled times since Parallel Query
> was born. I'd hope they've already put up their defenses due to the
> advent of that feature. I stand by my thoughts that it's pretty
> bizarre to draw the line here when we've probably been causing these
> people issues for many years already. I said my piece on this already
> so likely not much point in going on about it. These people are also
> perfectly capable of sidestepping the whole issue with setting
> max_parallel_workers_per_gather TO 0.
Coming from the Perl side, this issue has popped up there a lot with the
ordering of hash keys (e.g. "for my $key (keys %$hash) { ... }") and even
tho there was never a guarantee, it often caught people by surprise.
Mostly in testsuites, tho, because real output often needs some ordering,
anyway.
However, changes where nevertheless done, and code had to be adapted. But
the world didn't end, so to speak.
For PG, I think the benefits greatly outweight the problems with the
sorting order - after all, if you have code that relies on an implicit
order, you've already got a problem, no?
So my favourite would be something along these lines:
* add the string_agg
* document it in the release notes, and document workaround/solutions (add
ORDER BY, disabled workers etc.)
* if not already done, stress in the documentation that if you don't ORDER
things, things might not come out in the order you expect - especially
with paralell queries, new processing nodes etc.
Best wishes,
Tels
PS: We use string_agg() in a case where we first agg each row, then
string_agg() all rows, and the resulting string is really huge. We did run
into the "out of memory"-problem, so we now use a LIMIT and assembly the
resulting parts on the client side. My wish here would be to better know
how large the LIMIT can be, I found it quite difficult to predict with how
many rows PG runs out of memory for the string buffer, even tho all rows
have almost the same length as text. But that aside, getting the parts
faster with parallel agg would be very cool, too.
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tels <nospam-pg-abuse(at)bloodgate(dot)com>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-04-05 20:46:26 |
| Message-ID: | fdbf52dc-2e80-f5bc-5d43-b66a2deba021@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04/05/2018 09:10 PM, Tels wrote:
> Moin,
>
> On Wed, April 4, 2018 11:41 pm, David Rowley wrote:
>> Hi Tomas,
>>
>> Thanks for taking another look.
>>
>> On 5 April 2018 at 07:12, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>
>> wrote:
>>> Other than that, the patch seems fine to me, and it's already marked as
>>> RFC so I'll leave it at that.
>>
>> Thanks.
>
> I have one more comment - sorry for not writing sooner, the flu got to me ...
>
> Somewhere in the code there is a new allocation of memory when the string
> grows beyond the current size - and that doubles the size. This can lead
> to a lot of wasted space (think: constructing a string that is a bit over
> 1 Gbyte, which would presumable allocate 2 GByte).
>
I don't think we support memory chunks above 1GB, so that's likely going
to fail anyway. See
#define MaxAllocSize ((Size) 0x3fffffff) /* 1 gigabyte - 1 */
#define AllocSizeIsValid(size) ((Size) (size) <= MaxAllocSize)
But I get your point - we may be wasting space here. But that's hardly
something this patch should mess with - that's a more generic allocation
question.
> The same issue happens when each worker allocated 512 MByte for a 256
> Mbyte + 1 result.
>
> IMHO a factor of like 1.4 or 1.2 would work better here - not sure what
> the current standard in situations like this in PG is.
>
With a 2x scale factor, we only waste 25% of the space on average.
Consider that you're growing because you've reached the current size,
and you double the size - say, from 1MB to 2MB. But the 1MB wasted space
is the worst case - in reality we'll use something between 1MB and 2MB,
so 1.5MB on average. At which point we've wasted just 0.5MB, i.e. 25%.
That sounds perfectly reasonable to me. Lower factor would be more
expensive in terms of repalloc, for example.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-04-05 20:49:03 |
| Message-ID: | 8f76820a-5d3a-bade-59c3-a3852b730826@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04/05/2018 05:41 AM, David Rowley wrote:
> Hi Tomas,
>
> Thanks for taking another look.
>
> On 5 April 2018 at 07:12, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
>> Seems fine to me, although we should handle the anyarray case too, I
>> guess. That is, get_agg_clause_costs_walker() should do this too:
>>
>> /* Same thing for array_agg_array_(de)serialize. */
>> if ((aggserialfn == F_ARRAY_AGG_ARRAY_SERIALIZE ||
>> aggdeserialfn == F_ARRAY_AGG_ARRAY_DESERIALIZE) &&
>> !agg_args_support_sendreceive(aggref))
>> costs->hasNonSerial = true;
>
> hmm, array_agg_array_serialize and array_agg_array_deserialize don't
> use the send/receive functions though, so not sure why that's
> required?
>
>> Other than that, the patch seems fine to me, and it's already marked as
>> RFC so I'll leave it at that.
>
> Thanks.
>
>> The last obstacle seems to be the argument about the risks of the patch
>> breaking queries of people relying on the ordering. Not sure what's are
>> the right next steps in this regard ...
>
> yeah, seems like a bit of a stalemate.
>
> Personally, think if the group of people Tom mentions do exist, then
> they've already been through some troubled times since Parallel Query
> was born. I'd hope they've already put up their defenses due to the
> advent of that feature. I stand by my thoughts that it's pretty
> bizarre to draw the line here when we've probably been causing these
> people issues for many years already. I said my piece on this already
> so likely not much point in going on about it. These people are also
> perfectly capable of sidestepping the whole issue with setting
> max_parallel_workers_per_gather TO 0.
>
> Perhaps one solution is to drop the string_agg and keep the array_agg.
> Unsure if that would be good enough for Tom? More people seem to have
> voiced that array_agg ordering is generally less of a concern, which I
> imagine is probably true, but my opinion might not matter here as I'm
> the sort of person who if I needed a specific ordering I'd have
> written an ORDER BY clause.
>
I don't really see how dropping string_agg would solve anything. Either
the risks apply to both these functions, or neither of them I think. If
anything, doing this only for one of them would be inconsistent and
surprising, considering how similar they are.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tels <nospam-pg-abuse(at)bloodgate(dot)com> |
| Cc: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-04-05 21:51:05 |
| Message-ID: | CAKJS1f8==VFrSkNEpFj4bTuOte=ijG8tdxcvnOEy+DGNLN+gLA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Thanks for your input on all this. It's good to some words from people
using the software rather than just writing it.
On 6 April 2018 at 07:10, Tels <nospam-pg-abuse(at)bloodgate(dot)com> wrote:
> PS: We use string_agg() in a case where we first agg each row, then
> string_agg() all rows, and the resulting string is really huge. We did run
> into the "out of memory"-problem, so we now use a LIMIT and assembly the
> resulting parts on the client side. My wish here would be to better know
> how large the LIMIT can be, I found it quite difficult to predict with how
> many rows PG runs out of memory for the string buffer, even tho all rows
> have almost the same length as text. But that aside, getting the parts
> faster with parallel agg would be very cool, too.
For this problem, if you're getting "Cannot enlarge string buffer
containing X bytes by Y more bytes.", then you're not actually hitting
an OOM error, it's more the required string length is above
MaxAllocSize, which as mentioned by Tomas is 1GB.
See enlargeStringInfo() in stringinfo.c
if (((Size) needed) >= (MaxAllocSize - (Size) str->len))
ereport(ERROR,
(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
errmsg("out of memory"),
errdetail("Cannot enlarge string buffer containing %d bytes by %d more bytes.",
str->len, needed)));
Allocating chunks in smaller increments won't help if you're getting this.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 20:16:02 |
| Message-ID: | CA+TgmoZL6-J-_EGWLKxFWjEu5_advC-59C1LnFOJQRgH+E=Q=g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 26, 2018 at 4:27 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> I do not think it is accidental that these aggregates are exactly the ones
> that do not have parallelism support today. Rather, that's because you
> just about always have an interest in the order in which the inputs get
> aggregated, which is something that parallel aggregation cannot support.
That's not the reason, as has been stated by the person who wrote the
code. As the person who committed the code, my recollection of the
reasoning involved matches his.
> I fear that what will happen, if we commit this, is that something like
> 0.01% of the users of array_agg and string_agg will be pleased, another
> maybe 20% will be unaffected because they wrote ORDER BY which prevents
> parallel aggregation, and the remaining 80% will scream because we broke
> their queries. Telling them they should've written ORDER BY isn't going
> to cut it, IMO, when the benefit of that breakage will accrue only to some
> very tiny fraction of use-cases.
I think your estimated percentages here are wildly inaccurate.
I am in favor of this patch, like everyone else who has voted with the
exception of you. I have not reviewed the code, but I firmly believe
that preventing parallel query is far more damaging than breaking
queries for whatever fraction of users are relying on behavior that
wasn't guaranteed in the first place. I do understand your concern
and I respect your opinion, so please do not take the fact that I do
not agree with you in this case as an indication of disrespect.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 20:59:35 |
| Message-ID: | 15683.1525208375@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> On Mon, Mar 26, 2018 at 4:27 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> I fear that what will happen, if we commit this, is that something like
>> 0.01% of the users of array_agg and string_agg will be pleased, another
>> maybe 20% will be unaffected because they wrote ORDER BY which prevents
>> parallel aggregation, and the remaining 80% will scream because we broke
>> their queries. Telling them they should've written ORDER BY isn't going
>> to cut it, IMO, when the benefit of that breakage will accrue only to some
>> very tiny fraction of use-cases.
> I think your estimated percentages here are wildly inaccurate.
My estimate for the number of people positively impacted could be off
by a factor of a thousand, and it still wouldn't change the conclusion
that this will hurt more people than it helps.
I see that I'm in the minority on this, so I'm prepared to accept defeat,
but I stand by that conclusion.
regards, tom lane
| From: | Mark Dilger <hornschnorter(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 21:09:39 |
| Message-ID: | 1C2959D0-56F2-4067-B2AC-DF9A3B1D0FB5@gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> On Mar 27, 2018, at 7:58 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>
> David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> writes:
>> On 27 March 2018 at 13:26, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org> wrote:
>>> synchronized_seqscans is another piece of precedent in the area, FWIW.
>
>> This is true. I guess the order of aggregation could be made more
>> certain if we remove the cost based optimiser completely, and just
>> rely on a syntax based optimiser.
>
> None of this is responding to my point. I think the number of people
> who actually don't care about aggregation order for these aggregates
> is negligible, and none of you have argued against that; you've instead
> selected straw men to attack.
I frequently care about the order, but only to the extent that the order
is stable between aggregates of several different columns, along the lines
of:
select array_agg(a) AS x, array_agg(b) AS y
from generate_a_b_func(foo);
I don't care which order the data is in, as long as x[i] and y[i] are
matched correctly. It sounds like this patch would force me to write
that as, for example:
select array_agg(a order by a, b) AS x, array_agg(b order by a, b) AS y
from generate_a_b_func(foo);
which I did not need to do before. I would expect a performance regression
from the two newly required sorts. So in that case I agree with Tom.
But I also agree with others that I want the parallel aggregation functionality.
Could we perhaps introduce some option for the aggregate to force it to be
stable? Something like:
select array_agg(a order undisturbed) AS x, array_agg(b order undisturbed) AS y
from generate_a_b_func(foo);
which would not perform an extra sort operation but would guarantee to not
disturb the pre-existing sort order coming from generate_a_b_func(foo)?
I don't care about the syntax / keywords in the example above. I'm just
looking to get the benefits of the parallel aggregation when I don't care
about ordering while preserving the order for these cases where it matters.
mark
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | Mark Dilger <hornschnorter(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 21:11:47 |
| Message-ID: | 20180501211147.3balprbggw3pdpxk@alap3.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 2018-05-01 14:09:39 -0700, Mark Dilger wrote:
> I don't care which order the data is in, as long as x[i] and y[i] are
> matched correctly. It sounds like this patch would force me to write
> that as, for example:
>
> select array_agg(a order by a, b) AS x, array_agg(b order by a, b) AS y
> from generate_a_b_func(foo);
>
> which I did not need to do before.
Why would it require that? Rows are still processed row-by-row even if
there's parallelism, no?
Greetings,
Andres Freund
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | Mark Dilger <hornschnorter(at)gmail(dot)com>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 21:16:16 |
| Message-ID: | 16902.1525209376@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Andres Freund <andres(at)anarazel(dot)de> writes:
> On 2018-05-01 14:09:39 -0700, Mark Dilger wrote:
>> I don't care which order the data is in, as long as x[i] and y[i] are
>> matched correctly. It sounds like this patch would force me to write
>> that as, for example:
>>
>> select array_agg(a order by a, b) AS x, array_agg(b order by a, b) AS y
>> from generate_a_b_func(foo);
>>
>> which I did not need to do before.
> Why would it require that? Rows are still processed row-by-row even if
> there's parallelism, no?
Yeah, as long as we distribute all the aggregates in the same way,
it seems like they'd all see the same random-ish input ordering.
I can vaguely conceive of future optimizations that might break
that, but not what we have today.
regards, tom lane
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Mark Dilger <hornschnorter(at)gmail(dot)com>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 21:21:27 |
| Message-ID: | 20180501212127.6rqw4wj6osxtjyvx@alap3.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2018-05-01 17:16:16 -0400, Tom Lane wrote:
> Andres Freund <andres(at)anarazel(dot)de> writes:
> > On 2018-05-01 14:09:39 -0700, Mark Dilger wrote:
> >> I don't care which order the data is in, as long as x[i] and y[i] are
> >> matched correctly. It sounds like this patch would force me to write
> >> that as, for example:
> >>
> >> select array_agg(a order by a, b) AS x, array_agg(b order by a, b) AS y
> >> from generate_a_b_func(foo);
> >>
> >> which I did not need to do before.
>
> > Why would it require that? Rows are still processed row-by-row even if
> > there's parallelism, no?
>
> Yeah, as long as we distribute all the aggregates in the same way,
> it seems like they'd all see the same random-ish input ordering.
> I can vaguely conceive of future optimizations that might break
> that, but not what we have today.
Yea, a column store would with a and b being in different column sets,
or a and b originating from different tables and processing the two
aggregates in independent parts of the query tree, or other similar
stuff could result in trouble for the above assumption. But that seems
pretty unrelated to the matter at hand...
Greetings,
Andres Freund
| From: | Mark Dilger <hornschnorter(at)gmail(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 21:35:46 |
| Message-ID: | ADEC5025-2BD4-42C8-B63F-004D89EEE8D4@gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
> On May 1, 2018, at 2:11 PM, Andres Freund <andres(at)anarazel(dot)de> wrote:
>
> Hi,
>
> On 2018-05-01 14:09:39 -0700, Mark Dilger wrote:
>> I don't care which order the data is in, as long as x[i] and y[i] are
>> matched correctly. It sounds like this patch would force me to write
>> that as, for example:
>>
>> select array_agg(a order by a, b) AS x, array_agg(b order by a, b) AS y
>> from generate_a_b_func(foo);
>>
>> which I did not need to do before.
>
> Why would it require that? Rows are still processed row-by-row even if
> there's parallelism, no?
I was responding in part to Tom's upthread statement:
Your own example of assuming that separate aggregates are computed
in the same order reinforces my point, I think. In principle, anybody
who's doing that should write
array_agg(e order by x),
array_agg(f order by x),
string_agg(g order by x)
because otherwise they shouldn't assume that;
It seems Tom is saying that you can't assume separate aggregates will be
computed in the same order. Hence my response. What am I missing here?
mark
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | Mark Dilger <hornschnorter(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 21:38:32 |
| Message-ID: | 20180501213832.h6dp5zjophkqdz4h@alap3.anarazel.de |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2018-05-01 14:35:46 -0700, Mark Dilger wrote:
>
> > On May 1, 2018, at 2:11 PM, Andres Freund <andres(at)anarazel(dot)de> wrote:
> >
> > Hi,
> >
> > On 2018-05-01 14:09:39 -0700, Mark Dilger wrote:
> >> I don't care which order the data is in, as long as x[i] and y[i] are
> >> matched correctly. It sounds like this patch would force me to write
> >> that as, for example:
> >>
> >> select array_agg(a order by a, b) AS x, array_agg(b order by a, b) AS y
> >> from generate_a_b_func(foo);
> >>
> >> which I did not need to do before.
> >
> > Why would it require that? Rows are still processed row-by-row even if
> > there's parallelism, no?
>
> I was responding in part to Tom's upthread statement:
>
> Your own example of assuming that separate aggregates are computed
> in the same order reinforces my point, I think. In principle, anybody
> who's doing that should write
>
> array_agg(e order by x),
> array_agg(f order by x),
> string_agg(g order by x)
>
> because otherwise they shouldn't assume that;
>
> It seems Tom is saying that you can't assume separate aggregates will be
> computed in the same order. Hence my response. What am I missing here?
Afaict Tom was just making a theoretical argument, and one that seems
largely independent of the form of parallelism we're discussing here.
Greetings,
Andres Freund
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-05-01 22:14:25 |
| Message-ID: | CAKJS1f-3fs_u235GKt0fC7D+9vJ9ApB-c1tDVTB_U0HUdGxw-Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2 May 2018 at 08:59, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Robert Haas <robertmhaas(at)gmail(dot)com> writes:
>> On Mon, Mar 26, 2018 at 4:27 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>>> I fear that what will happen, if we commit this, is that something like
>>> 0.01% of the users of array_agg and string_agg will be pleased, another
>>> maybe 20% will be unaffected because they wrote ORDER BY which prevents
>>> parallel aggregation, and the remaining 80% will scream because we broke
>>> their queries. Telling them they should've written ORDER BY isn't going
>>> to cut it, IMO, when the benefit of that breakage will accrue only to some
>>> very tiny fraction of use-cases.
>
>> I think your estimated percentages here are wildly inaccurate.
>
> My estimate for the number of people positively impacted could be off
> by a factor of a thousand, and it still wouldn't change the conclusion
> that this will hurt more people than it helps.
It's probably best to have this argument again in 6 months or so.
Someone might decide to put some effort into teaching the planner
about ordered aggregates so it can choose to provide pre-sorted input
to aggregate functions so that nodeAgg.c no longer has to perform the
costly explicit sorts. Windowing functions already do this for the
first window clause, so it might not be too hard to do it for the
first aggregate, and any subsequent aggregates which share the same
ORDER BY / DISTINCT clause. We'd probably need to add some sort of
evaluation order to the Aggref, but ... details need not be discussed
here ...
I think if we had that, then the current objection to the patch loses
quite a bit of traction.
I imagine Tom will give up his objection given that he wrote this:
On 27 March 2018 at 11:28, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Maybe what that says is that rather than giving up on this altogether,
> we should shelve it till we have less stupid planner+executor behavior
> for ORDER BY inside aggregates. That's been on the to-do list for
> a long while, but not risen to the top ...
So it seems there's probably room here to please everyone.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2018-06-20 07:07:54 |
| Message-ID: | CAKJS1f98yPkRMsE0JnDh72=AQEUuE3atiCJtPVCtjhFwzCRJHQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2 May 2018 at 10:14, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> wrote:
> On 2 May 2018 at 08:59, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> My estimate for the number of people positively impacted could be off
>> by a factor of a thousand, and it still wouldn't change the conclusion
>> that this will hurt more people than it helps.
>
> It's probably best to have this argument again in 6 months or so.
> Someone might decide to put some effort into teaching the planner
> about ordered aggregates so it can choose to provide pre-sorted input
> to aggregate functions so that nodeAgg.c no longer has to perform the
> costly explicit sorts.
It seems unlikely that ordered aggregates will be fixed in the July
'fest or even any time soon, so I'm going to mark this patch as
returned with feedback in aid of slightly reducing the patch list.
I'll submit it again when there more consensus that we want this.
Thanks for all the reviews.
--
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2022-08-02 23:45:31 |
| Message-ID: | CAApHDvpRddvXK=8b8YZAKa_UPseHwhkBFH+5UZVoeGwq7GmqSQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 20 Jun 2018 at 19:08, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com> wrote:
> I'll submit it again when there more consensus that we want this.
Waking up this old thread again. If you don't have a copy, the entire
thread is in [1].
The remaining item that seemed to cause this patch to be rejected was
raised in [2]. The summary of that was that it might not be a good
idea to allow parallel aggregation of string_agg() and array_agg() as
there might be some people who rely on the current ordering they get
without having an ORDER BY clause in the aggregate function call. Tom
mentioned in [3] that users might not want to add an ORDER BY to their
aggregate function because the performance of it is terrible. That
was true up until 1349d2790 [4], where I changed how ORDER BY /
DISTINCT aggregation worked to allow the planner to provide pre-sorted
input rather than always having nodeAgg.c do the sorting. I think
this removes quite a lot of the argument against the patch, but not
all of it. So here goes testing the water on seeing if any opinions
have changed over the past few years?
A rebased patch is attached.
David
[1] https://www.postgresql.org/message-id/flat/CAKJS1f98yPkRMsE0JnDh72%3DAQEUuE3atiCJtPVCtjhFwzCRJHQ%40mail.gmail.com#8bbce15b9279d2da2da99071f732a99d
[2] https://www.postgresql.org/message-id/6538.1522096067@sss.pgh.pa.us
[3] https://www.postgresql.org/message-id/18594.1522099194@sss.pgh.pa.us
[4] https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=1349d2790bf48a4de072931c722f39337e72055e
| Attachment | Content-Type | Size |
|---|---|---|
| combinefn_for_string_and_array_aggs_v11.patch | text/plain | 43.7 KB |
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | David Rowley <dgrowleyml(at)gmail(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2022-08-03 00:18:20 |
| Message-ID: | 2800168.1659485900@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
David Rowley <dgrowleyml(at)gmail(dot)com> writes:
> Waking up this old thread again. If you don't have a copy, the entire
> thread is in [1].
> The remaining item that seemed to cause this patch to be rejected was
> raised in [2].
Hmm. My estimate of the percentages of users who will be pleased or
not hasn't really changed since [2]. Also, realizing that you can't
apply these aggregates to extremely large input sets, I wonder just how
much it buys to be able to parallelize them. So I still put this patch
in the category of "just because we can doesn't mean we should".
Now as against that, if the underlying relation scan is parallelized
then you already have unpredictable input ordering and thus unpredictable
aggregate results. So anyone who cares about that has already had
to either disable parallelism or insert an ORDER BY somewhere, and
either of those fixes will still work if the aggregates support
parallelism. Hence, I'm not going to fight hard if you really want
to do it. But I remain unconvinced that the cost/benefit tradeoff
is attractive.
regards, tom lane
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2022-08-03 01:42:47 |
| Message-ID: | CAApHDvq71ssfOK1=dUsLPmf_cYntyC4PHR4C72+=UQmRsC3tTA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 3 Aug 2022 at 12:18, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Now as against that, if the underlying relation scan is parallelized
> then you already have unpredictable input ordering and thus unpredictable
> aggregate results. So anyone who cares about that has already had
> to either disable parallelism or insert an ORDER BY somewhere, and
> either of those fixes will still work if the aggregates support
> parallelism.
I think users relying on the transition order without an ORDER BY
clause in the aggregate function likely have become accustomed to
having to disable various GUCs before they run their query.
For example, they might have something like:
BEGIN;
SET LOCAL enable_hashagg = 0;
SET LOCAL enable_hashjoin = 0;
SET LOCAL enable_nestloop = 0;
SELECT col, string_agg(col2, ','), array_agg(col3) FROM tab1 INNER
JOIN tab2 ON ... ORDER BY ...
COMMIT;
and are relying on a Merge Join being chosen so that the final join
rel is ordered according to the ORDER BY clause which allows GroupAgg
to skip the Sort phase thus providing a pre-sorted path for
aggregation.
Here we're adding to the list of GUCs they'd need to disable as
they'll maybe want to add SET max_parallel_workers_per_gather = 0; now
too. I bet all those people knew they were on thin ice already.
I stand by the fact we can't let undefined behaviour stand in the way
of future optimisations. Not having these disables more than just
parallel query. There's other reasons to want combine functions, for
example partial aggregation done during partition-wise aggregation is
disabled for aggregates without a combine function too. I'm pretty
sure we must be nearing wanting a give-me-partial-aggregate-results
syntax so that we can have FDWs feed us with partial results so we can
harness the resources of an array of foreign servers to farm off the
aggregation work for us. We already have async Append. It feels (to
me) like we're on the cusp of needing that syntax.
> Hence, I'm not going to fight hard if you really want
> to do it. But I remain unconvinced that the cost/benefit tradeoff
> is attractive.
Perhaps we're early enough in the release cycle to give enough time
for people to realise and complain if they're in that 80% group,
according to your estimates.
David
| From: | Zhihong Yu <zyu(at)yugabyte(dot)com> |
|---|---|
| To: | David Rowley <dgrowleyml(at)gmail(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2022-08-03 02:46:47 |
| Message-ID: | CALNJ-vRr2jNFTjgZu3bbmsR5k3aQsVPvp6tQDo=QvJTqrTKzpQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Aug 2, 2022 at 4:46 PM David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> On Wed, 20 Jun 2018 at 19:08, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>
> wrote:
> > I'll submit it again when there more consensus that we want this.
>
> Waking up this old thread again. If you don't have a copy, the entire
> thread is in [1].
>
> The remaining item that seemed to cause this patch to be rejected was
> raised in [2]. The summary of that was that it might not be a good
> idea to allow parallel aggregation of string_agg() and array_agg() as
> there might be some people who rely on the current ordering they get
> without having an ORDER BY clause in the aggregate function call. Tom
> mentioned in [3] that users might not want to add an ORDER BY to their
> aggregate function because the performance of it is terrible. That
> was true up until 1349d2790 [4], where I changed how ORDER BY /
> DISTINCT aggregation worked to allow the planner to provide pre-sorted
> input rather than always having nodeAgg.c do the sorting. I think
> this removes quite a lot of the argument against the patch, but not
> all of it. So here goes testing the water on seeing if any opinions
> have changed over the past few years?
>
> A rebased patch is attached.
>
> David
>
> [1]
> https://www.postgresql.org/message-id/flat/CAKJS1f98yPkRMsE0JnDh72%3DAQEUuE3atiCJtPVCtjhFwzCRJHQ%40mail.gmail.com#8bbce15b9279d2da2da99071f732a99d
> [2] https://www.postgresql.org/message-id/6538.1522096067@sss.pgh.pa.us
> [3] https://www.postgresql.org/message-id/18594.1522099194@sss.pgh.pa.us
> [4]
> https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=1349d2790bf48a4de072931c722f39337e72055e
Hi,
For array_agg_combine():
+ if (state1->alen < reqsize)
+ {
+ /* Use a power of 2 size rather than allocating just reqsize */
+ state1->alen = pg_nextpower2_32(reqsize);
...
+ state1->nelems = reqsize;
I wonder why pg_nextpower2_32(reqsize) is used in the if block. It seems
reqsize should suffice.
Cheers
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Zhihong Yu <zyu(at)yugabyte(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2022-08-03 03:05:31 |
| Message-ID: | CAApHDvqbhp9F0pMA5Zc0ZU1urQe-ryYq=k-jH9SrVwkbitkB0Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 3 Aug 2022 at 14:40, Zhihong Yu <zyu(at)yugabyte(dot)com> wrote:
> For array_agg_combine():
>
> + if (state1->alen < reqsize)
> + {
> + /* Use a power of 2 size rather than allocating just reqsize */
> + state1->alen = pg_nextpower2_32(reqsize);
> ...
> + state1->nelems = reqsize;
>
> I wonder why pg_nextpower2_32(reqsize) is used in the if block. It seems reqsize should suffice.
It would suffice, but it's a question of trying to minimise the
reallocations. There might be many parallel workers to combine results
from. Nothing says this one is the last call to combine the given
aggregate state. As far as aset.c allocations, for small / medium
allocations, the actual memory is allocated in powers of 2 anyway. If
you request less, you'll maybe need to repalloc more often,
needlessly. The actual underlying allocation might be big enough
already, it's just that the palloc() caller does not have knowledge of
that.
David
| From: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
|---|---|
| To: | David Rowley <dgrowleyml(at)gmail(dot)com> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2022-12-27 07:48:11 |
| Message-ID: | CAFj8pRD12EyhXPZGs_q3D0HfzjxvXD4i9Wo5kGCj-3z41tmp7g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi
út 27. 12. 2022 v 6:26 odesílatel David Rowley <dgrowleyml(at)gmail(dot)com>
napsal:
> On Wed, 20 Jun 2018 at 19:08, David Rowley <david(dot)rowley(at)2ndquadrant(dot)com>
> wrote:
> > I'll submit it again when there more consensus that we want this.
>
> Waking up this old thread again. If you don't have a copy, the entire
> thread is in [1].
>
> The remaining item that seemed to cause this patch to be rejected was
> raised in [2]. The summary of that was that it might not be a good
> idea to allow parallel aggregation of string_agg() and array_agg() as
> there might be some people who rely on the current ordering they get
> without having an ORDER BY clause in the aggregate function call. Tom
> mentioned in [3] that users might not want to add an ORDER BY to their
> aggregate function because the performance of it is terrible. That
> was true up until 1349d2790 [4], where I changed how ORDER BY /
> DISTINCT aggregation worked to allow the planner to provide pre-sorted
> input rather than always having nodeAgg.c do the sorting. I think
> this removes quite a lot of the argument against the patch, but not
> all of it. So here goes testing the water on seeing if any opinions
> have changed over the past few years?
>
> A rebased patch is attached.
>
The technical part of this patch was discussed before, and there were no
objections against it.
I did some performance benchmarks and I agree with David. Sure - it can
change the ordering, but without the ORDER BY clause, the order depended
before too. And the performance with ORDER clause is not changed with and
without this patch.
I can confirm that all regress tests passed, and there are not any problems
with compilation.
I'll mark this patch as ready for committer
Regards
Pavel
>
> David
>
> [1]
> https://www.postgresql.org/message-id/flat/CAKJS1f98yPkRMsE0JnDh72%3DAQEUuE3atiCJtPVCtjhFwzCRJHQ%40mail.gmail.com#8bbce15b9279d2da2da99071f732a99d
> [2] https://www.postgresql.org/message-id/6538.1522096067@sss.pgh.pa.us
> [3] https://www.postgresql.org/message-id/18594.1522099194@sss.pgh.pa.us
> [4]
> https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=1349d2790bf48a4de072931c722f39337e72055e
>
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2023-01-19 07:44:08 |
| Message-ID: | CAApHDvpNuGFkjmQ4b3VWxo9MSYxsR6yGykemLRRNU8heYhiNTA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 3 Aug 2022 at 12:18, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Hmm. My estimate of the percentages of users who will be pleased or
> not hasn't really changed since [2]. Also, realizing that you can't
> apply these aggregates to extremely large input sets, I wonder just how
> much it buys to be able to parallelize them. So I still put this patch
> in the category of "just because we can doesn't mean we should".
It's a shame you categorised it without testing the actual
performance. That's disappointingly unscientific.
Here's a quick benchmark to let you see what we might expect and how
it compares to the existing aggregate functions which can already be
parallelised:
create table ab (a int, b int);
insert into ab select x,y from
generate_series(1,1000)x,generate_Series(1,1000)y;
In the attached agg_comparison_milliseconds.png, you can see the time
it took to execute "select a,sum(b) from ab group by a;" and "select
a,string_agg(b::text,',') from ab group by a;". Both queries seem to
increase in performance roughly the same amount when adding additional
parallel workers.
The attached agg_comparison_scalability.png shows the time it took to
execute the query with 0 workers divided by the time for N workers,
thus showing how many times the query was sped up with N workers. The
scalability of the string_agg() appears slightly better than the sum()
in this test due to the string_agg() query being slightly slower with
0 workers than the sum() version of the query. The sum query got 7.63x
faster with 32 workers whereas the string_agg query beat that slightly
with 7.67x faster than when the query was executed with parallelism
disabled.
I'd expect that scalability, especially the sum() version of the
query, to improve further with more rows.
Tested on an amd3990x machine with 64 cores / 128 threads.
> Now as against that, if the underlying relation scan is parallelized
> then you already have unpredictable input ordering and thus unpredictable
> aggregate results. So anyone who cares about that has already had
> to either disable parallelism or insert an ORDER BY somewhere, and
> either of those fixes will still work if the aggregates support
> parallelism.
I'm glad you're no longer worried about users skipping the ORDER BY to
increase performance and relying on luck for the input ordering.
I think, in addition to this now allowing parallel aggregation for
string_agg() and array_agg(), it's also important not to forget that
there are more reasons to have combine/serialize/deserialize functions
for all aggregates. Currently, a partition-wise aggregate can be
performed partially on the partition then if further grouping is
required at the top-level then we'll need the combine function to
perform the final grouping. No parallelism is required. Also, with
all the advancements that have been made in postgres_fdw of late, then
I imagine it surely can't be long until someone wants to invent some
syntax for requesting partially aggregated results at the SQL level.
It sure would be a shame if that worked for every aggregate but
string_agg and array_agg needed the foreign server to spit those
tuples out individually so that the aggregation could be performed
(painstakingly) on the local server.
> Hence, I'm not going to fight hard if you really want
> to do it. But I remain unconvinced that the cost/benefit tradeoff
> is attractive.
Thanks. Pending one last look, I'm planning to move ahead with it
unless there are any further objections or concerns.
David
| Attachment | Content-Type | Size |
|---|---|---|
| string_agg_scale_test.sh.txt | text/plain | 378 bytes |
| agg_comparison_milliseconds.png | image/png | 84.0 KB |
| agg_comparison_scalability.png | image/png | 113.3 KB |
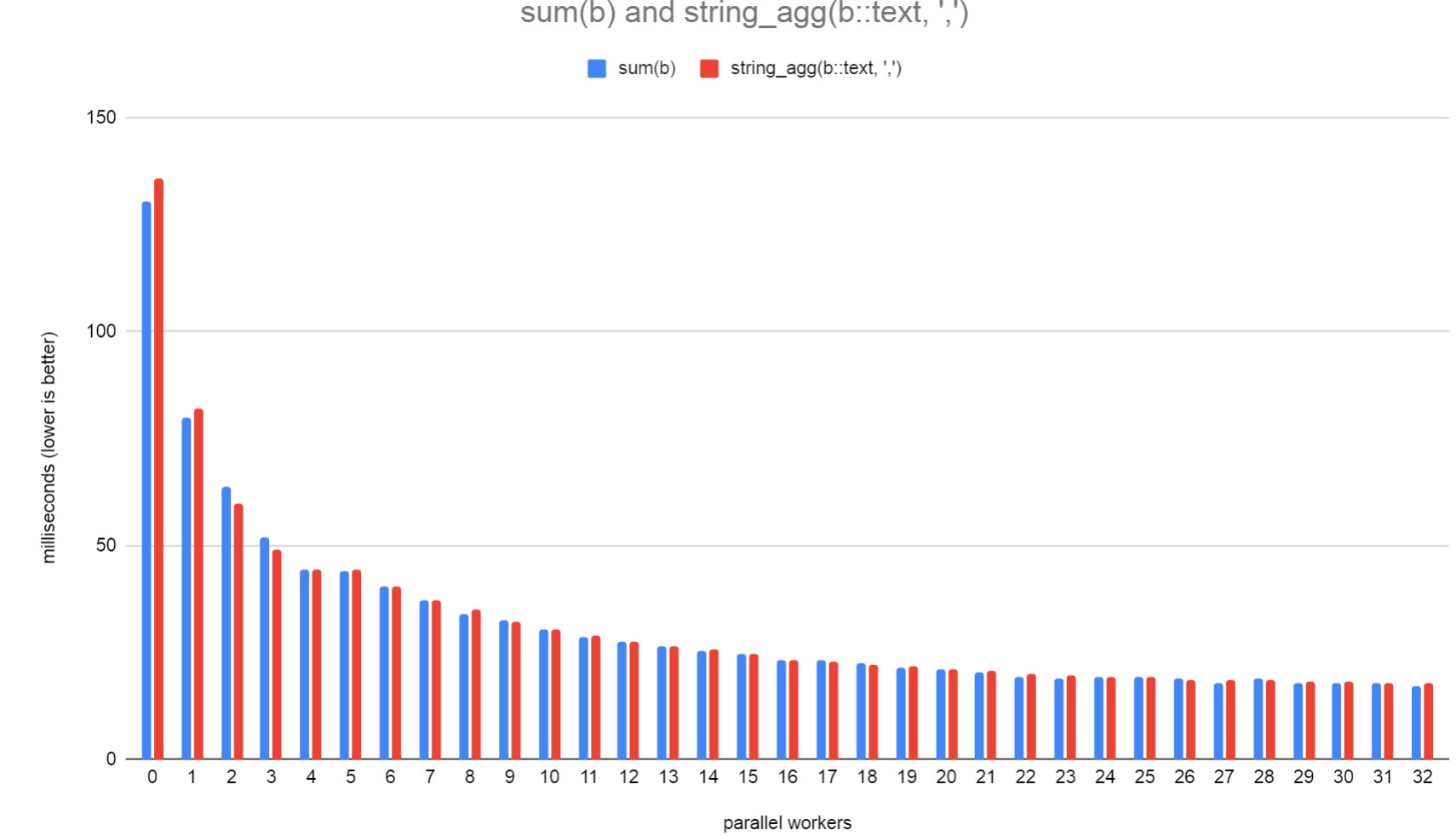{kind=link}
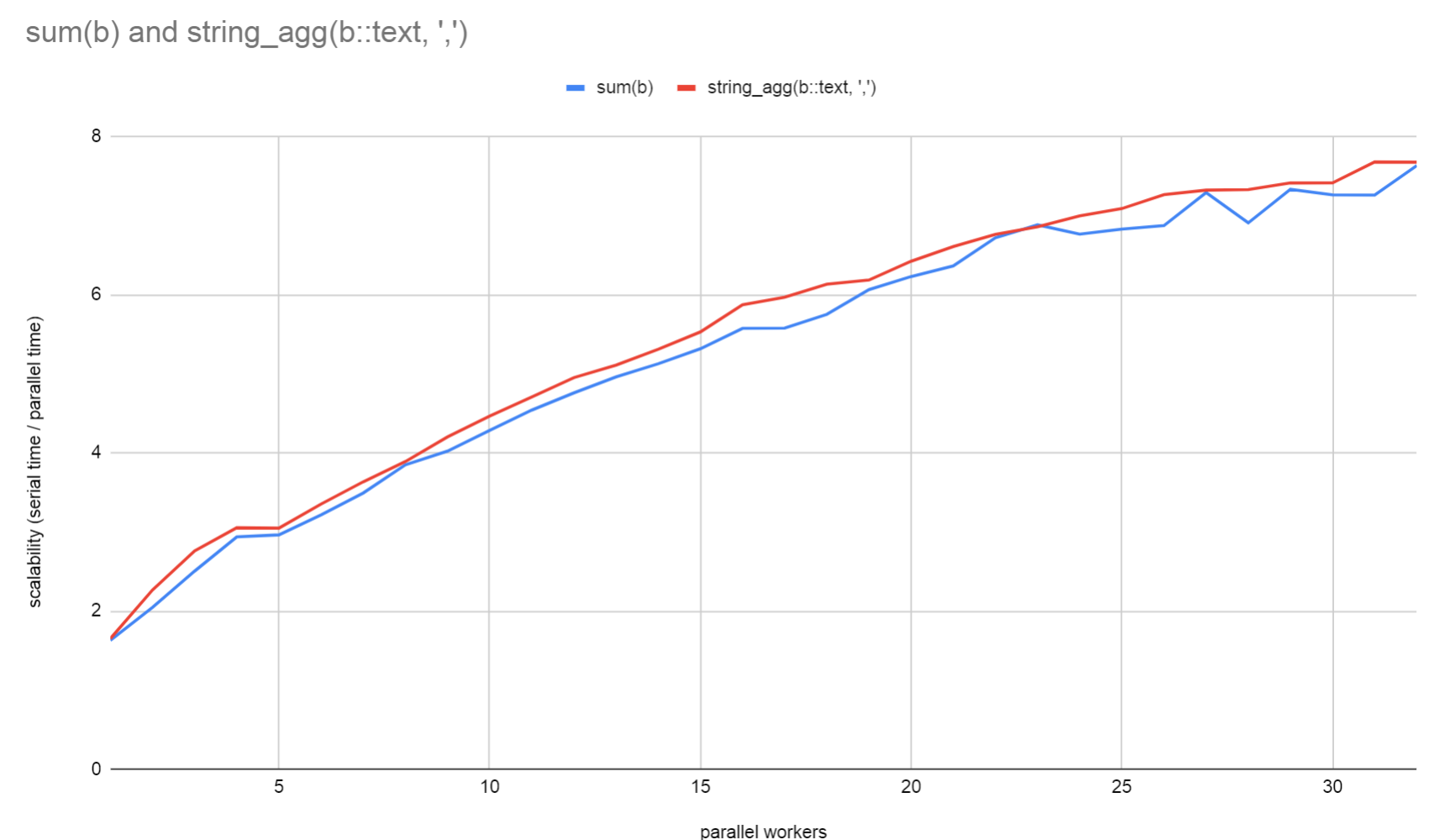{kind=link}
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2023-01-23 00:49:25 |
| Message-ID: | CAApHDvq7ChY83NaCw9e8rP1jUd_hgVj=jespHFY56gA4TynnfA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 19 Jan 2023 at 20:44, David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> The attached agg_comparison_scalability.png shows the time it took to
> execute the query with 0 workers divided by the time for N workers,
> thus showing how many times the query was sped up with N workers. The
> scalability of the string_agg() appears slightly better than the sum()
> in this test due to the string_agg() query being slightly slower with
> 0 workers than the sum() version of the query. The sum query got 7.63x
> faster with 32 workers whereas the string_agg query beat that slightly
> with 7.67x faster than when the query was executed with parallelism
> disabled.
I was just looking at this again today and I noticed I messed up the
script and used the sum(b) query twice instead of the
string_agg(b::text, ',') query. oops.
I've attached the correct graphs this time. The scalability of
string_agg() is not quite as good as I reported before, but it's still
good. sum(b) with 32 workers with a new benchmark run I found to be
7.15x faster than with 0 parallel workers and string_agg(b::text, ',')
I found to be 6.49x faster with 32 workers than with 0 parallel
workers. This test showed that the string_agg query scaled better with
up to 6 workers before the scalability dropped below that of the
sum(b) query.
David
| Attachment | Content-Type | Size |
|---|---|---|
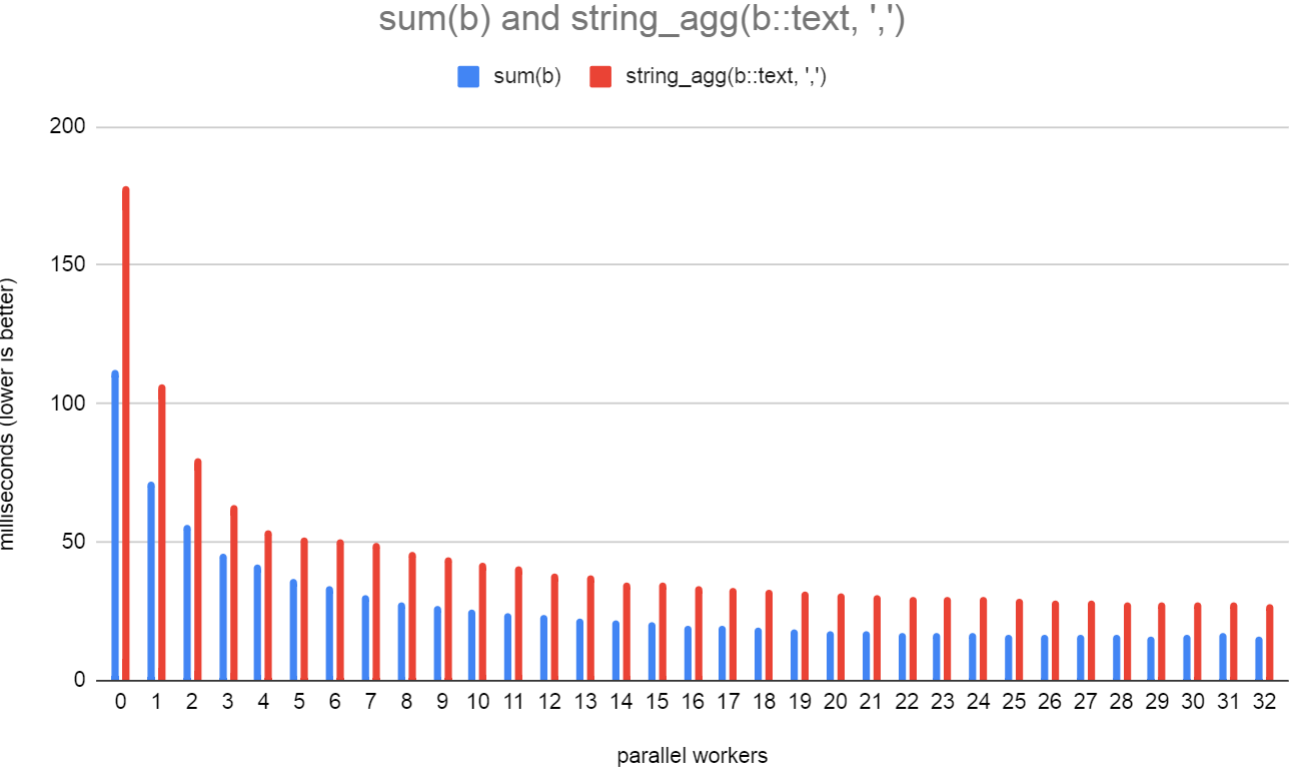
|
image/png | 71.3 KB |
| agg_comparison_scalability_v2.png | image/png | 77.8 KB |
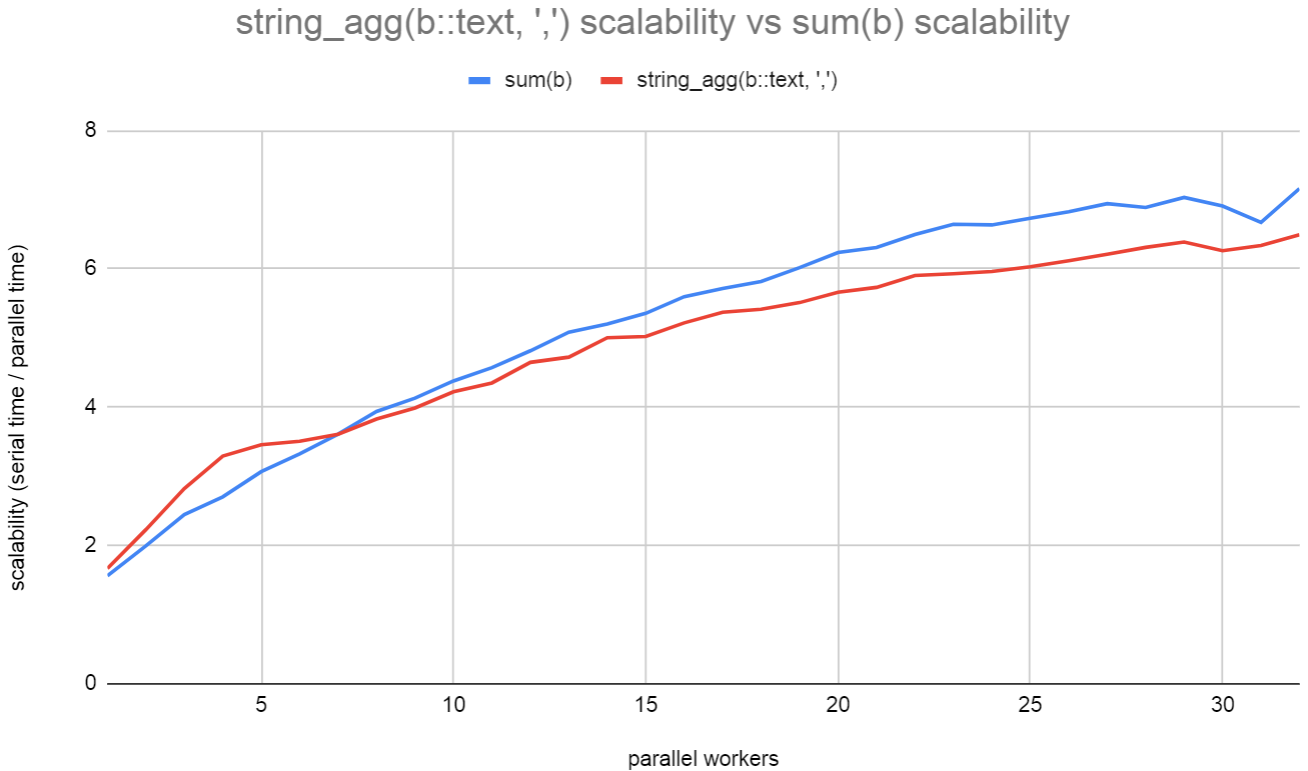{kind=link}
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Robert Haas <robertmhaas(at)gmail(dot)com>, Stephen Frost <sfrost(at)snowman(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2023-01-23 04:37:21 |
| Message-ID: | CAApHDvrKaB83BQQiS0PptWJYyccH0c9ZnYeCmTRSJ4TEwO5Ekg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, 19 Jan 2023 at 20:44, David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> Thanks. Pending one last look, I'm planning to move ahead with it
> unless there are any further objections or concerns.
I've now pushed this.
Thank you to everyone who reviewed or gave input on this patch.
David
| From: | Alexander Lakhin <exclusion(at)gmail(dot)com> |
|---|---|
| To: | David Rowley <dgrowleyml(at)gmail(dot)com>, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2024-03-26 14:00:00 |
| Message-ID: | d4493a28-589a-5328-fed5-250f2d7d3e2a@gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hello David,
23.01.2023 07:37, David Rowley wrote:
> I've now pushed this.
>
I've discovered that the test query:
-- Ensure parallel aggregation is actually being used.
explain (costs off) select * from v_pagg_test order by y;
added by 16fd03e95 fails sometimes. For instance:
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=urutu&dt=2024-03-19%2021%3A04%3A05
--- /home/bf/bf-build/urutu/HEAD/pgsql/src/test/regress/expected/aggregates.out 2024-02-24 06:42:47.039073180 +0000
+++ /home/bf/bf-build/urutu/HEAD/pgsql.build/src/test/regress/results/aggregates.out 2024-03-19 22:24:18.155876135 +0000
@@ -1993,14 +1993,16 @@
Sort Key: pagg_test.y, (((unnest(regexp_split_to_array((string_agg((pagg_test.x)::text, ','::text)),
','::text))))::integer)
-> Result
-> ProjectSet
- -> Finalize HashAggregate
+ -> Finalize GroupAggregate
...
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=phycodurus&dt=2024-02-28%2007%3A38%3A27
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=avocet&dt=2024-02-08%2008%3A47%3A45
I suspect that these failures caused by autovacuum.
I could reproduce this plan change when running multiple tests in
parallel, and also with the attached test patch applied (several sleeps are
needed for autovacuum/relation_needs_vacanalyze() to get a non-zero
mod_since_analyze value from pgstat):
TEMP_CONFIG=/tmp/temp.config TESTS="test_setup create_index create_aggregate aggregates" make -s check-tests
where /tmp/temp.config is:
autovacuum_naptime = 1
log_autovacuum_min_duration = 0
log_min_messages = INFO
log_min_error_statement = log
log_statement = 'all'
With EXPLAIN (VERBOSE), I see a slight change of the Seq Scan cost/rows
estimate:
... -> Parallel Seq Scan on public.pagg_test (cost=0.00..48.99 rows=2599 width=8)
vs
.. -> Parallel Seq Scan on public.pagg_test (cost=0.00..48.00 rows=2500 width=8)
(after automatic analyze of table "regression.public.pagg_test")
Best regards,
Alexander
| Attachment | Content-Type | Size |
|---|---|---|
| aggregates.patch | text/x-patch | 2.1 KB |
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Alexander Lakhin <exclusion(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Parallel Aggregates for string_agg and array_agg |
| Date: | 2024-03-27 11:19:06 |
| Message-ID: | CAApHDvoUPd+tVQOoWojSeksS=J=sAS6R3gRo4k0KbuPnoG4RAQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, 27 Mar 2024 at 03:00, Alexander Lakhin <exclusion(at)gmail(dot)com> wrote:
> I've discovered that the test query:
> -- Ensure parallel aggregation is actually being used.
> explain (costs off) select * from v_pagg_test order by y;
>
> added by 16fd03e95 fails sometimes. For instance:
> https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=urutu&dt=2024-03-19%2021%3A04%3A05
>
> --- /home/bf/bf-build/urutu/HEAD/pgsql/src/test/regress/expected/aggregates.out 2024-02-24 06:42:47.039073180 +0000
> +++ /home/bf/bf-build/urutu/HEAD/pgsql.build/src/test/regress/results/aggregates.out 2024-03-19 22:24:18.155876135 +0000
> @@ -1993,14 +1993,16 @@
> Sort Key: pagg_test.y, (((unnest(regexp_split_to_array((string_agg((pagg_test.x)::text, ','::text)),
> ','::text))))::integer)
> -> Result
> -> ProjectSet
> - -> Finalize HashAggregate
> + -> Finalize GroupAggregate
> ...
>
> https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=phycodurus&dt=2024-02-28%2007%3A38%3A27
>
> https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=avocet&dt=2024-02-08%2008%3A47%3A45
>
> I suspect that these failures caused by autovacuum.
I agree with this analysis. In hindsight, adding 5000 records to a
table without disabling autovacuum or vacuuming the table manually was
a bad idea.
I opted to fix by disabling autovacuum for the table as that allows us
to maintain the current plan. Vacuuming would result in the plan
changing, which I opted not to do as it's a bit more churn in the
expected output file.
Thanks for the report and the analysis.
David