Re: 100% failover + replication solution
| Lists: | pgsql-admin |
|---|
| From: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
|---|---|
| To: | pgsql-admin(at)postgresql(dot)org |
| Subject: | 100% failover + replication solution |
| Date: | 2006-10-30 09:47:53 |
| Message-ID: | 82e1a9bd0610300147m7e214893ue1306f1637bb489f@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Guys,
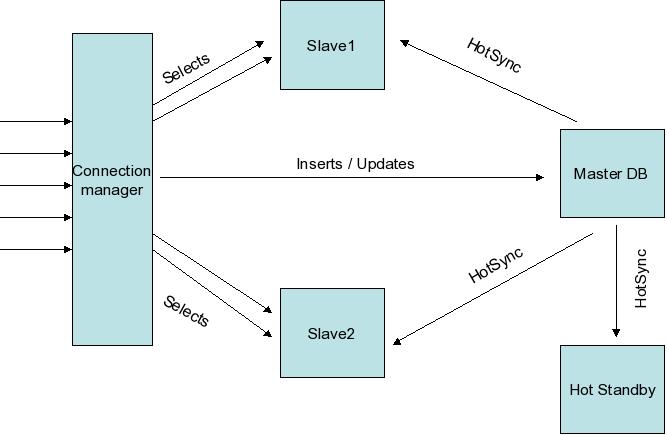
I have been thinking about this and wanted to see if it can be achived. I
wanted to make a 100% failover solution for my postgres databases. The first
thing that comes to my mind is doing it using WAL logs. Am attaching the
diagram for which i will write more here.
I was thinking if i can have Hotsync the databases using the WAL logs. If
you see the architecture, the select goes to the SLAVE nodes and the INSERTS
goes to the MASTER database, that means there should be no transactions
happening on SLAVES (pure select). not even using "plpgsql". In this
archecture i wont even mind restarting the SLAVE nodes if i need to.
I was reading on PIT recovery on postgres, the only current problem i am
facing with that is, i need to backup the database and move the slaves and
the apply WAL logs to it. That could be huge amount of transfer and hence a
longer downtime then moving 16mb WAL log files.
Can someone help me out here, what i want is a continuous applying of WAL
logs once i have brought the database up. I want to elimiate the backup of
master to be restored to the slaves everytime i want to apply WAL to slaves.
It would be real help if someone can tell me if it is possible to apply WAL
logs to the slaves continously as soon as they are created on MASTER. I
checked other tools available and thougth this would be best approach if it
works.
Awaiting reply soon.
Regards,
Moiz Kothari
| Attachment | Content-Type | Size |
|---|---|---|
|
image/jpeg | 24.7 KB |
| From: | Ben Suffolk <ben(at)vanilla(dot)net> |
|---|---|
| To: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
| Cc: | pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 10:09:54 |
| Message-ID: | 7CA68A94-ED1E-49C9-ACF2-2A34936333DC@vanilla.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
> Guys,
>
> I have been thinking about this and wanted to see if it can be
> achived. I wanted to make a 100% failover solution for my postgres
> databases. The first thing that comes to my mind is doing it using
> WAL logs. Am attaching the diagram for which i will write more here.
While its not the solution you were looking at, have you seen
PGCluser :-
http://pgcluster.projects.postgresql.org/index.html
I have not tried it, but was looking the other week at various fail-
over type solutions and came across it. It seems to be able to do
what you want.
Ben
| From: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
|---|---|
| To: | "Ben Suffolk" <ben(at)vanilla(dot)net> |
| Cc: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 10:23:07 |
| Message-ID: | bf54be870610300223u1a2d78b5j47525531bd5ce0a0@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
There is this project which actually is not released yet, but something that
you want to achieve :)
http://pgfoundry.org/projects/pgpitrha
Regards,
-------
Shoaib Mir
EnterpriseDB (www.enterprisedb.com)
On 10/30/06, Ben Suffolk <ben(at)vanilla(dot)net> wrote:
>
> > Guys,
> >
> > I have been thinking about this and wanted to see if it can be
> > achived. I wanted to make a 100% failover solution for my postgres
> > databases. The first thing that comes to my mind is doing it using
> > WAL logs. Am attaching the diagram for which i will write more here.
>
> While its not the solution you were looking at, have you seen
> PGCluser :-
>
> http://pgcluster.projects.postgresql.org/index.html
>
> I have not tried it, but was looking the other week at various fail-
> over type solutions and came across it. It seems to be able to do
> what you want.
>
> Ben
>
>
>
>
>
>
> ---------------------------(end of broadcast)---------------------------
> TIP 9: In versions below 8.0, the planner will ignore your desire to
> choose an index scan if your joining column's datatypes do not
> match
>
| From: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
|---|---|
| To: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
| Cc: | "Ben Suffolk" <ben(at)vanilla(dot)net>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 10:53:35 |
| Message-ID: | 82e1a9bd0610300253y1c999f31k5ba6ac086bcfb802@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Shoaib,
It sure does, i saw PGCLUSTER, but 3 reasons for having a postgres specific
solution.
1) If pgcluster stops further development, it would be lot more hassel when
upgrading to a different version of postgres.
2) Postgres specific solution would help alot going ahead in future.
3) Also architecture of pgcluster might make things slower as it updates
complete cluster before confirming the request.
There are lots of them available in market, but i think WAL solution should
be available, if not then the thought process should be there going ahead. I
am expecting a solution out of WAL logs. Let me know if you have any
thoughts about it.
Regards,
Moiz Kothari
On 10/30/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
>
> There is this project which actually is not released yet, but something
> that you want to achieve :)
>
> http://pgfoundry.org/projects/pgpitrha
>
> Regards,
> -------
> Shoaib Mir
> EnterpriseDB (www.enterprisedb.com)
>
> On 10/30/06, Ben Suffolk < ben(at)vanilla(dot)net> wrote:
>
> > > Guys,
> > >
> > > I have been thinking about this and wanted to see if it can be
> > > achived. I wanted to make a 100% failover solution for my postgres
> > > databases. The first thing that comes to my mind is doing it using
> > > WAL logs. Am attaching the diagram for which i will write more here.
> >
> > While its not the solution you were looking at, have you seen
> > PGCluser :-
> >
> > http://pgcluster.projects.postgresql.org/index.html
> >
> > I have not tried it, but was looking the other week at various fail-
> > over type solutions and came across it. It seems to be able to do
> > what you want.
> >
> > Ben
> >
> >
> >
> >
> >
> >
> > ---------------------------(end of broadcast)---------------------------
> > TIP 9: In versions below 8.0, the planner will ignore your desire to
> > choose an index scan if your joining column's datatypes do not
> > match
> >
>
>
| From: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
|---|---|
| To: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
| Cc: | "Ben Suffolk" <ben(at)vanilla(dot)net>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 12:49:04 |
| Message-ID: | bf54be870610300449uc1aa708mf4cecb7c3fe16ecc@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Hi Moiz,
If I had to choose for your case where you want to direct your selects to
slave node and inserts/updates on master, I would have opted for Slony or
PGCluster.
Using PITR for HA can be a good option if you want to switch between primary
and secondary server, where you can store the archive files on a shared disk
and place a recovery file with in $PGDATA and automate the process where it
can run the process of recovery on each primary and seconday like for
example 5 times a day as it all depends on the number of transactions
happening on the db server. I have seen a few users doing this for routine
VACUUM FULL process as a maintanence activity.
Thanks,
---------
Shoaib Mir
EnterpriseDB (www.enterprisedb.com)
On 10/30/06, Moiz Kothari <moizpostgres(at)gmail(dot)com> wrote:
>
> Shoaib,
>
> It sure does, i saw PGCLUSTER, but 3 reasons for having a postgres
> specific solution.
>
> 1) If pgcluster stops further development, it would be lot more hassel
> when upgrading to a different version of postgres.
> 2) Postgres specific solution would help alot going ahead in future.
> 3) Also architecture of pgcluster might make things slower as it updates
> complete cluster before confirming the request.
>
> There are lots of them available in market, but i think WAL solution
> should be available, if not then the thought process should be there going
> ahead. I am expecting a solution out of WAL logs. Let me know if you have
> any thoughts about it.
>
> Regards,
> Moiz Kothari
>
> On 10/30/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
> >
> > There is this project which actually is not released yet, but something
> > that you want to achieve :)
> >
> > http://pgfoundry.org/projects/pgpitrha
> >
> > Regards,
> > -------
> > Shoaib Mir
> > EnterpriseDB (www.enterprisedb.com)
> >
> > On 10/30/06, Ben Suffolk < ben(at)vanilla(dot)net> wrote:
> >
> > > > Guys,
> > > >
> > > > I have been thinking about this and wanted to see if it can be
> > > > achived. I wanted to make a 100% failover solution for my postgres
> > > > databases. The first thing that comes to my mind is doing it using
> > > > WAL logs. Am attaching the diagram for which i will write more here.
> > >
> > >
> > > While its not the solution you were looking at, have you seen
> > > PGCluser :-
> > >
> > > http://pgcluster.projects.postgresql.org/index.html
> > >
> > > I have not tried it, but was looking the other week at various fail-
> > > over type solutions and came across it. It seems to be able to do
> > > what you want.
> > >
> > > Ben
> > >
> > >
> > >
> > >
> > >
> > >
> > > ---------------------------(end of
> > > broadcast)---------------------------
> > > TIP 9: In versions below 8.0, the planner will ignore your desire to
> > > choose an index scan if your joining column's datatypes do not
> > > match
> > >
> >
> >
>
| From: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
|---|---|
| To: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
| Cc: | "Ben Suffolk" <ben(at)vanilla(dot)net>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 13:11:54 |
| Message-ID: | 82e1a9bd0610300511u35a3e156u22b3c600c69edd24@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Shoaib,
I agree that PGCluster might be a better option, i dont want to go with
Slony because of primary key constraints. But PGCluster is a good option,
the only concerns are :
1) It might slow down the process a bit. as confirmation happens after
transaction gets comitted to all the nodes.
2) Its difficult to convince, as it is an external project and if support
for the same stops or future versions of postgres does not work, it might be
a problem.
Can you elaborate more the way PITR for HA being used for primary and
secondary servers, maybe u can light a bulb in me for me to go ahead with
the approach. I like the idea of using WAL logs because its postgres
internal and secondly it would be fastest way of keeping databases in sync
without slowing down other servers.
Awaiting your reply.
Regards,
Moiz Kothari
On 10/30/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
>
> Hi Moiz,
>
> If I had to choose for your case where you want to direct your selects to
> slave node and inserts/updates on master, I would have opted for Slony or
> PGCluster.
>
> Using PITR for HA can be a good option if you want to switch between
> primary and secondary server, where you can store the archive files on a
> shared disk and place a recovery file with in $PGDATA and automate the
> process where it can run the process of recovery on each primary and
> seconday like for example 5 times a day as it all depends on the number of
> transactions happening on the db server. I have seen a few users doing this
> for routine VACUUM FULL process as a maintanence activity.
>
> Thanks,
> ---------
> Shoaib Mir
> EnterpriseDB (www.enterprisedb.com)
>
> On 10/30/06, Moiz Kothari < moizpostgres(at)gmail(dot)com> wrote:
> >
> > Shoaib,
> >
> > It sure does, i saw PGCLUSTER, but 3 reasons for having a postgres
> > specific solution.
> >
> > 1) If pgcluster stops further development, it would be lot more hassel
> > when upgrading to a different version of postgres.
> > 2) Postgres specific solution would help alot going ahead in future.
> > 3) Also architecture of pgcluster might make things slower as it updates
> > complete cluster before confirming the request.
> >
> > There are lots of them available in market, but i think WAL solution
> > should be available, if not then the thought process should be there going
> > ahead. I am expecting a solution out of WAL logs. Let me know if you have
> > any thoughts about it.
> >
> > Regards,
> > Moiz Kothari
> >
> > On 10/30/06, Shoaib Mir < shoaibmir(at)gmail(dot)com> wrote:
> > >
> > > There is this project which actually is not released yet, but
> > > something that you want to achieve :)
> > >
> > > http://pgfoundry.org/projects/pgpitrha
> > >
> > > Regards,
> > > -------
> > > Shoaib Mir
> > > EnterpriseDB (www.enterprisedb.com)
> > >
> > > On 10/30/06, Ben Suffolk < ben(at)vanilla(dot)net> wrote:
> > >
> > > > > Guys,
> > > > >
> > > > > I have been thinking about this and wanted to see if it can be
> > > > > achived. I wanted to make a 100% failover solution for my postgres
> > > > > databases. The first thing that comes to my mind is doing it using
> > > > > WAL logs. Am attaching the diagram for which i will write more
> > > > here.
> > > >
> > > > While its not the solution you were looking at, have you seen
> > > > PGCluser :-
> > > >
> > > > http://pgcluster.projects.postgresql.org/index.html
> > > >
> > > > I have not tried it, but was looking the other week at various fail-
> > > >
> > > > over type solutions and came across it. It seems to be able to do
> > > > what you want.
> > > >
> > > > Ben
> > > >
> > > >
> > > >
> > > >
> > > >
> > > >
> > > > ---------------------------(end of
> > > > broadcast)---------------------------
> > > > TIP 9: In versions below 8.0, the planner will ignore your desire to
> > > > choose an index scan if your joining column's datatypes do
> > > > not
> > > > match
> > > >
> > >
> > >
> >
>
| From: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
|---|---|
| To: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
| Cc: | "Ben Suffolk" <ben(at)vanilla(dot)net>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 13:33:00 |
| Message-ID: | bf54be870610300533l47a115aexd2a47f7c0a6da897@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Moiz,
Have you tried PGPool? as that comes with a built-in load balancer as well.
For PITR in HA scenario, I dont remember where I read but some one did it
like this:
- Make base backup for the primary server say five time a day (depends on
the transactions happening on the db server)
- Automate these base backups in a way that these backup are always made on
the secondary server
- Keep the archiving enabled with your archives been saved directly to a
shared disk
- Now have the recovery.conf placed in the $PGDATA of secondary server
- When you want to switch servers just run the postmaster with recovery file
and that way it will make it come up to date with the primary server
- Once you have switched to seconday now mark it primary and the primary as
seconday and keep on doing the same in a loop
You can automate this easily with a few scripts.
There is a new feature in 8.2 that let you set the archive_timeout so that
after a specific amount of time a new WAL archive is made which makes it
easy for low transaction systems where the WAL archive size is not reached
that easily so it can be copied it to the archive folder.
Hope this helps in your case....
Thank you,
----------
Shoaib Mir
EnterpriseDB (www.enterprisedb.com)
On 10/30/06, Moiz Kothari <moizpostgres(at)gmail(dot)com> wrote:
>
> Shoaib,
>
> I agree that PGCluster might be a better option, i dont want to go with
> Slony because of primary key constraints. But PGCluster is a good option,
> the only concerns are :
>
> 1) It might slow down the process a bit. as confirmation happens after
> transaction gets comitted to all the nodes.
> 2) Its difficult to convince, as it is an external project and if support
> for the same stops or future versions of postgres does not work, it might be
> a problem.
>
> Can you elaborate more the way PITR for HA being used for primary and
> secondary servers, maybe u can light a bulb in me for me to go ahead with
> the approach. I like the idea of using WAL logs because its postgres
> internal and secondly it would be fastest way of keeping databases in sync
> without slowing down other servers.
>
> Awaiting your reply.
>
> Regards,
> Moiz Kothari
>
> On 10/30/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
> >
> > Hi Moiz,
> >
> > If I had to choose for your case where you want to direct your selects
> > to slave node and inserts/updates on master, I would have opted for Slony or
> > PGCluster.
> >
> > Using PITR for HA can be a good option if you want to switch between
> > primary and secondary server, where you can store the archive files on a
> > shared disk and place a recovery file with in $PGDATA and automate the
> > process where it can run the process of recovery on each primary and
> > seconday like for example 5 times a day as it all depends on the number of
> > transactions happening on the db server. I have seen a few users doing this
> > for routine VACUUM FULL process as a maintanence activity.
> >
> > Thanks,
> > ---------
> > Shoaib Mir
> > EnterpriseDB (www.enterprisedb.com)
> >
> > On 10/30/06, Moiz Kothari < moizpostgres(at)gmail(dot)com> wrote:
> > >
> > > Shoaib,
> > >
> > > It sure does, i saw PGCLUSTER, but 3 reasons for having a postgres
> > > specific solution.
> > >
> > > 1) If pgcluster stops further development, it would be lot more hassel
> > > when upgrading to a different version of postgres.
> > > 2) Postgres specific solution would help alot going ahead in future.
> > > 3) Also architecture of pgcluster might make things slower as it
> > > updates complete cluster before confirming the request.
> > >
> > > There are lots of them available in market, but i think WAL solution
> > > should be available, if not then the thought process should be there going
> > > ahead. I am expecting a solution out of WAL logs. Let me know if you have
> > > any thoughts about it.
> > >
> > > Regards,
> > > Moiz Kothari
> > >
> > > On 10/30/06, Shoaib Mir < shoaibmir(at)gmail(dot)com> wrote:
> > > >
> > > > There is this project which actually is not released yet, but
> > > > something that you want to achieve :)
> > > >
> > > > http://pgfoundry.org/projects/pgpitrha
> > > >
> > > > Regards,
> > > > -------
> > > > Shoaib Mir
> > > > EnterpriseDB (www.enterprisedb.com)
> > > >
> > > > On 10/30/06, Ben Suffolk < ben(at)vanilla(dot)net> wrote:
> > > >
> > > > > > Guys,
> > > > > >
> > > > > > I have been thinking about this and wanted to see if it can be
> > > > > > achived. I wanted to make a 100% failover solution for my
> > > > > postgres
> > > > > > databases. The first thing that comes to my mind is doing it
> > > > > using
> > > > > > WAL logs. Am attaching the diagram for which i will write more
> > > > > here.
> > > > >
> > > > > While its not the solution you were looking at, have you seen
> > > > > PGCluser :-
> > > > >
> > > > > http://pgcluster.projects.postgresql.org/index.html
> > > > >
> > > > > I have not tried it, but was looking the other week at various
> > > > > fail-
> > > > > over type solutions and came across it. It seems to be able to do
> > > > > what you want.
> > > > >
> > > > > Ben
> > > > >
> > > > >
> > > > >
> > > > >
> > > > >
> > > > >
> > > > > ---------------------------(end of
> > > > > broadcast)---------------------------
> > > > > TIP 9: In versions below 8.0, the planner will ignore your desire
> > > > > to
> > > > > choose an index scan if your joining column's datatypes do
> > > > > not
> > > > > match
> > > > >
> > > >
> > > >
> > >
> >
>
| From: | Andrew Sullivan <ajs(at)crankycanuck(dot)ca> |
|---|---|
| To: | pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 13:38:06 |
| Message-ID: | 20061030133806.GA16730@phlogiston.dyndns.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
On Mon, Oct 30, 2006 at 06:41:54PM +0530, Moiz Kothari wrote:
> I agree that PGCluster might be a better option, i dont want to go with
> Slony because of primary key constraints.
I don't know what the "primary key constraints" issue you have is,
but Slony would be inappropriate for a "100% failover" system anyway:
you can't know you haven't trapped data on the origin. This is in
fact true for the WAL shipping you suggested, also. The only way to
achieve 100% reliable failover today, with guaranteed no data loss,
is to use a system that commits all the data on two machines at the
same time in the same transaction. I haven't seen any argument so
far that there is any such system "out of the box", although with two
phase commit support available, it would seem that some systems could
be extended in that direction.
The other answer for all of this is to do it with hardware, but
that's a shared-disk system, so if your disk blows up, you have a
problem. Or, if you're using the operating system of people who
don't know how fsck works. I don't know anyone who has that problem;
certainly not any vendors whose name starts with 'I' and ends with
'M'.
> 1) It might slow down the process a bit. as confirmation happens after
> transaction gets comitted to all the nodes.
Anyone who tells you that you can have completely reliable data
replication with no performance hit is trying to sell you a bridge in
Brooklyn. If you want reliable data replication that guarantees you
can have automatic failover, you are going to pay for it somehow; the
question is which compromise you want to make. That seems to be
something you'll need to decide.
> 2) Its difficult to convince, as it is an external project and if support
> for the same stops or future versions of postgres does not work, it might be
> a problem.
If you have this problem, probably free software isn't for you.
PostgreSQL is a modular system, and people use different components
together in deployed systems. This happens to be true of commercial
offerings too (if not, you could buy the cheapest version of, say,
Oracle and get RAC in the bargain), but they _sell_ it to you as
though it were one big package. To the extent your managers don't
understand this, you're always going to have a problem using free
software.
A
--
Andrew Sullivan | ajs(at)crankycanuck(dot)ca
In the future this spectacle of the middle classes shocking the avant-
garde will probably become the textbook definition of Postmodernism.
--Brad Holland
| From: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
|---|---|
| To: | "Andrew Sullivan" <ajs(at)crankycanuck(dot)ca> |
| Cc: | pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-30 14:29:11 |
| Message-ID: | bf54be870610300629w4ebcecb0p435e729995677841@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Hi Moiz,
This might help you :) -->
http://developer.postgresql.org/pgdocs/postgres/warm-standby.html
Thanks,
-------
Shoaib Mir
EnterpriseDB (www.enterprisedb.com)
On 10/30/06, Andrew Sullivan <ajs(at)crankycanuck(dot)ca> wrote:
>
> On Mon, Oct 30, 2006 at 06:41:54PM +0530, Moiz Kothari wrote:
> > I agree that PGCluster might be a better option, i dont want to go with
> > Slony because of primary key constraints.
>
> I don't know what the "primary key constraints" issue you have is,
> but Slony would be inappropriate for a "100% failover" system anyway:
> you can't know you haven't trapped data on the origin. This is in
> fact true for the WAL shipping you suggested, also. The only way to
> achieve 100% reliable failover today, with guaranteed no data loss,
> is to use a system that commits all the data on two machines at the
> same time in the same transaction. I haven't seen any argument so
> far that there is any such system "out of the box", although with two
> phase commit support available, it would seem that some systems could
> be extended in that direction.
>
> The other answer for all of this is to do it with hardware, but
> that's a shared-disk system, so if your disk blows up, you have a
> problem. Or, if you're using the operating system of people who
> don't know how fsck works. I don't know anyone who has that problem;
> certainly not any vendors whose name starts with 'I' and ends with
> 'M'.
>
> > 1) It might slow down the process a bit. as confirmation happens after
> > transaction gets comitted to all the nodes.
>
> Anyone who tells you that you can have completely reliable data
> replication with no performance hit is trying to sell you a bridge in
> Brooklyn. If you want reliable data replication that guarantees you
> can have automatic failover, you are going to pay for it somehow; the
> question is which compromise you want to make. That seems to be
> something you'll need to decide.
>
> > 2) Its difficult to convince, as it is an external project and if
> support
> > for the same stops or future versions of postgres does not work, it
> might be
> > a problem.
>
> If you have this problem, probably free software isn't for you.
> PostgreSQL is a modular system, and people use different components
> together in deployed systems. This happens to be true of commercial
> offerings too (if not, you could buy the cheapest version of, say,
> Oracle and get RAC in the bargain), but they _sell_ it to you as
> though it were one big package. To the extent your managers don't
> understand this, you're always going to have a problem using free
> software.
>
> A
> --
> Andrew Sullivan | ajs(at)crankycanuck(dot)ca
> In the future this spectacle of the middle classes shocking the avant-
> garde will probably become the textbook definition of Postmodernism.
> --Brad Holland
>
> ---------------------------(end of broadcast)---------------------------
> TIP 9: In versions below 8.0, the planner will ignore your desire to
> choose an index scan if your joining column's datatypes do not
> match
>
| From: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
|---|---|
| To: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
| Cc: | "Andrew Sullivan" <ajs(at)crankycanuck(dot)ca>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-31 09:42:08 |
| Message-ID: | 82e1a9bd0610310142s22ce7d1ahdb7ccd5357a18b65@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Shoaib,
This sounds really like what i need, but again 8.2 is in beta.
Just one question, i dunno if i am thinking in right direction, but is there
anyway of finding out the END XID, transaction id and OID of last archived
WAL log applied to the database. I was thinking if i can get that value then
i can reset XLOGs using pg_resetxlog to that point and then start applying
the new WAL logs. Am i thinking it correctly or there is some flaw here.
Also if i am thinking it right, then how can i find the details i asked
above.
Regards,
Moiz Kothari
On 10/30/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
>
> Hi Moiz,
>
> This might help you :) --> http://developer.postgresql.org/pgdocs/postgres/warm-standby.html
>
>
> Thanks,
> -------
> Shoaib Mir
> EnterpriseDB (www.enterprisedb.com)
>
> On 10/30/06, Andrew Sullivan < ajs(at)crankycanuck(dot)ca> wrote:
> >
> > On Mon, Oct 30, 2006 at 06:41:54PM +0530, Moiz Kothari wrote:
> > > I agree that PGCluster might be a better option, i dont want to go
> > with
> > > Slony because of primary key constraints.
> >
> > I don't know what the "primary key constraints" issue you have is,
> > but Slony would be inappropriate for a "100% failover" system anyway:
> > you can't know you haven't trapped data on the origin. This is in
> > fact true for the WAL shipping you suggested, also. The only way to
> > achieve 100% reliable failover today, with guaranteed no data loss,
> > is to use a system that commits all the data on two machines at the
> > same time in the same transaction. I haven't seen any argument so
> > far that there is any such system "out of the box", although with two
> > phase commit support available, it would seem that some systems could
> > be extended in that direction.
> >
> > The other answer for all of this is to do it with hardware, but
> > that's a shared-disk system, so if your disk blows up, you have a
> > problem. Or, if you're using the operating system of people who
> > don't know how fsck works. I don't know anyone who has that problem;
> > certainly not any vendors whose name starts with 'I' and ends with
> > 'M'.
> >
> > > 1) It might slow down the process a bit. as confirmation happens after
> >
> > > transaction gets comitted to all the nodes.
> >
> > Anyone who tells you that you can have completely reliable data
> > replication with no performance hit is trying to sell you a bridge in
> > Brooklyn. If you want reliable data replication that guarantees you
> > can have automatic failover, you are going to pay for it somehow; the
> > question is which compromise you want to make. That seems to be
> > something you'll need to decide.
> >
> > > 2) Its difficult to convince, as it is an external project and if
> > support
> > > for the same stops or future versions of postgres does not work, it
> > might be
> > > a problem.
> >
> > If you have this problem, probably free software isn't for you.
> > PostgreSQL is a modular system, and people use different components
> > together in deployed systems. This happens to be true of commercial
> > offerings too (if not, you could buy the cheapest version of, say,
> > Oracle and get RAC in the bargain), but they _sell_ it to you as
> > though it were one big package. To the extent your managers don't
> > understand this, you're always going to have a problem using free
> > software.
> >
> > A
> > --
> > Andrew Sullivan | ajs(at)crankycanuck(dot)ca
> > In the future this spectacle of the middle classes shocking the avant-
> > garde will probably become the textbook definition of Postmodernism.
> > --Brad Holland
> >
> > ---------------------------(end of broadcast)---------------------------
> > TIP 9: In versions below 8.0, the planner will ignore your desire to
> > choose an index scan if your joining column's datatypes do not
> > match
> >
>
>
| From: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
|---|---|
| To: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
| Cc: | "Andrew Sullivan" <ajs(at)crankycanuck(dot)ca>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-10-31 13:24:12 |
| Message-ID: | bf54be870610310524u892b16bp3b8edb6e124d22ce@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Moiz,
Hmmmm, I think pg_controldata output might help you there to get these
stats.
pg_controldata can be found in the PostgreSQL /bin folder.
Thank you,
---------
Shoaib Mir
EnterpriseDB (www.enterprisedb.com)
On 10/31/06, Moiz Kothari <moizpostgres(at)gmail(dot)com> wrote:
>
> Shoaib,
>
> This sounds really like what i need, but again 8.2 is in beta.
>
> Just one question, i dunno if i am thinking in right direction, but is
> there anyway of finding out the END XID, transaction id and OID of last
> archived WAL log applied to the database. I was thinking if i can get that
> value then i can reset XLOGs using pg_resetxlog to that point and then start
> applying the new WAL logs. Am i thinking it correctly or there is some flaw
> here.
>
> Also if i am thinking it right, then how can i find the details i asked
> above.
>
> Regards,
> Moiz Kothari
>
> On 10/30/06, Shoaib Mir < shoaibmir(at)gmail(dot)com> wrote:
> >
> > Hi Moiz,
> >
> > This might help you :) --> http://developer.postgresql.org/pgdocs/postgres/warm-standby.html
> >
> >
> > Thanks,
> > -------
> > Shoaib Mir
> > EnterpriseDB (www.enterprisedb.com)
> >
> > On 10/30/06, Andrew Sullivan < ajs(at)crankycanuck(dot)ca> wrote:
> > >
> > > On Mon, Oct 30, 2006 at 06:41:54PM +0530, Moiz Kothari wrote:
> > > > I agree that PGCluster might be a better option, i dont want to go
> > > with
> > > > Slony because of primary key constraints.
> > >
> > > I don't know what the "primary key constraints" issue you have is,
> > > but Slony would be inappropriate for a "100% failover" system anyway:
> > > you can't know you haven't trapped data on the origin. This is in
> > > fact true for the WAL shipping you suggested, also. The only way to
> > > achieve 100% reliable failover today, with guaranteed no data loss,
> > > is to use a system that commits all the data on two machines at the
> > > same time in the same transaction. I haven't seen any argument so
> > > far that there is any such system "out of the box", although with two
> > > phase commit support available, it would seem that some systems could
> > > be extended in that direction.
> > >
> > > The other answer for all of this is to do it with hardware, but
> > > that's a shared-disk system, so if your disk blows up, you have a
> > > problem. Or, if you're using the operating system of people who
> > > don't know how fsck works. I don't know anyone who has that problem;
> > > certainly not any vendors whose name starts with 'I' and ends with
> > > 'M'.
> > >
> > > > 1) It might slow down the process a bit. as confirmation happens
> > > after
> > > > transaction gets comitted to all the nodes.
> > >
> > > Anyone who tells you that you can have completely reliable data
> > > replication with no performance hit is trying to sell you a bridge in
> > > Brooklyn. If you want reliable data replication that guarantees you
> > > can have automatic failover, you are going to pay for it somehow; the
> > > question is which compromise you want to make. That seems to be
> > > something you'll need to decide.
> > >
> > > > 2) Its difficult to convince, as it is an external project and if
> > > support
> > > > for the same stops or future versions of postgres does not work, it
> > > might be
> > > > a problem.
> > >
> > > If you have this problem, probably free software isn't for you.
> > > PostgreSQL is a modular system, and people use different components
> > > together in deployed systems. This happens to be true of commercial
> > > offerings too (if not, you could buy the cheapest version of, say,
> > > Oracle and get RAC in the bargain), but they _sell_ it to you as
> > > though it were one big package. To the extent your managers don't
> > > understand this, you're always going to have a problem using free
> > > software.
> > >
> > > A
> > > --
> > > Andrew Sullivan | ajs(at)crankycanuck(dot)ca
> > > In the future this spectacle of the middle classes shocking the avant-
> > >
> > > garde will probably become the textbook definition of Postmodernism.
> > > --Brad Holland
> > >
> > > ---------------------------(end of
> > > broadcast)---------------------------
> > > TIP 9: In versions below 8.0, the planner will ignore your desire to
> > > choose an index scan if your joining column's datatypes do not
> > > match
> > >
> >
> >
>
| From: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
|---|---|
| To: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
| Cc: | "Andrew Sullivan" <ajs(at)crankycanuck(dot)ca>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-11-01 13:16:59 |
| Message-ID: | 82e1a9bd0611010516q3540ce5eo5bf8b9baedd84d8d@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Shoaib,
I see you are with enterprise DB, does enterpriseDB support clustering? if
it does then probably i can think in terms of it to be an option to go for.
I need to come to a decision soon on it as we have to decide on what
Database to go for.
Thanks for all your help.
Regards,
Moiz Kothari
On 10/31/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
>
> Moiz,
>
> Hmmmm, I think pg_controldata output might help you there to get these
> stats.
>
> pg_controldata can be found in the PostgreSQL /bin folder.
>
> Thank you,
> ---------
> Shoaib Mir
> EnterpriseDB ( www.enterprisedb.com)
>
> On 10/31/06, Moiz Kothari < moizpostgres(at)gmail(dot)com> wrote:
> >
> > Shoaib,
> >
> > This sounds really like what i need, but again 8.2 is in beta.
> >
> > Just one question, i dunno if i am thinking in right direction, but is
> > there anyway of finding out the END XID, transaction id and OID of last
> > archived WAL log applied to the database. I was thinking if i can get that
> > value then i can reset XLOGs using pg_resetxlog to that point and then start
> > applying the new WAL logs. Am i thinking it correctly or there is some flaw
> > here.
> >
> > Also if i am thinking it right, then how can i find the details i asked
> > above.
> >
> > Regards,
> > Moiz Kothari
> >
> > On 10/30/06, Shoaib Mir < shoaibmir(at)gmail(dot)com> wrote:
> > >
> > > Hi Moiz,
> > >
> > > This might help you :) --> http://developer.postgresql.org/pgdocs/postgres/warm-standby.html
> > >
> > >
> > > Thanks,
> > > -------
> > > Shoaib Mir
> > > EnterpriseDB (www.enterprisedb.com)
> > >
> > > On 10/30/06, Andrew Sullivan < ajs(at)crankycanuck(dot)ca> wrote:
> > > >
> > > > On Mon, Oct 30, 2006 at 06:41:54PM +0530, Moiz Kothari wrote:
> > > > > I agree that PGCluster might be a better option, i dont want to go
> > > > with
> > > > > Slony because of primary key constraints.
> > > >
> > > > I don't know what the "primary key constraints" issue you have is,
> > > > but Slony would be inappropriate for a "100% failover" system
> > > > anyway:
> > > > you can't know you haven't trapped data on the origin. This is in
> > > > fact true for the WAL shipping you suggested, also. The only way to
> > > > achieve 100% reliable failover today, with guaranteed no data loss,
> > > > is to use a system that commits all the data on two machines at the
> > > > same time in the same transaction. I haven't seen any argument so
> > > > far that there is any such system "out of the box", although with
> > > > two
> > > > phase commit support available, it would seem that some systems
> > > > could
> > > > be extended in that direction.
> > > >
> > > > The other answer for all of this is to do it with hardware, but
> > > > that's a shared-disk system, so if your disk blows up, you have a
> > > > problem. Or, if you're using the operating system of people who
> > > > don't know how fsck works. I don't know anyone who has that
> > > > problem;
> > > > certainly not any vendors whose name starts with 'I' and ends with
> > > > 'M'.
> > > >
> > > > > 1) It might slow down the process a bit. as confirmation happens
> > > > after
> > > > > transaction gets comitted to all the nodes.
> > > >
> > > > Anyone who tells you that you can have completely reliable data
> > > > replication with no performance hit is trying to sell you a bridge
> > > > in
> > > > Brooklyn. If you want reliable data replication that guarantees you
> > > >
> > > > can have automatic failover, you are going to pay for it somehow;
> > > > the
> > > > question is which compromise you want to make. That seems to be
> > > > something you'll need to decide.
> > > >
> > > > > 2) Its difficult to convince, as it is an external project and if
> > > > support
> > > > > for the same stops or future versions of postgres does not work,
> > > > it might be
> > > > > a problem.
> > > >
> > > > If you have this problem, probably free software isn't for you.
> > > > PostgreSQL is a modular system, and people use different components
> > > > together in deployed systems. This happens to be true of commercial
> > > > offerings too (if not, you could buy the cheapest version of, say,
> > > > Oracle and get RAC in the bargain), but they _sell_ it to you as
> > > > though it were one big package. To the extent your managers don't
> > > > understand this, you're always going to have a problem using free
> > > > software.
> > > >
> > > > A
> > > > --
> > > > Andrew Sullivan | ajs(at)crankycanuck(dot)ca
> > > > In the future this spectacle of the middle classes shocking the
> > > > avant-
> > > > garde will probably become the textbook definition of Postmodernism.
> > > > --Brad Holland
> > > >
> > > > ---------------------------(end of
> > > > broadcast)---------------------------
> > > > TIP 9: In versions below 8.0, the planner will ignore your desire to
> > > >
> > > > choose an index scan if your joining column's datatypes do
> > > > not
> > > > match
> > > >
> > >
> > >
> >
>
| From: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
|---|---|
| To: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
| Cc: | "Andrew Sullivan" <ajs(at)crankycanuck(dot)ca>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-11-01 13:22:55 |
| Message-ID: | 82e1a9bd0611010522i1a65ab15ve61017dc91c19e43@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Shoaib,
Also just so you know, we plan to use SLES 10 OS. so also let me know the
compatibility of EnterpriseDB to the OS.
Regards,
Moiz
On 10/31/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
>
> Moiz,
>
> Hmmmm, I think pg_controldata output might help you there to get these
> stats.
>
> pg_controldata can be found in the PostgreSQL /bin folder.
>
> Thank you,
> ---------
> Shoaib Mir
> EnterpriseDB ( www.enterprisedb.com)
>
> On 10/31/06, Moiz Kothari <moizpostgres(at)gmail(dot)com> wrote:
> >
> > Shoaib,
> >
> > This sounds really like what i need, but again 8.2 is in beta.
> >
> > Just one question, i dunno if i am thinking in right direction, but is
> > there anyway of finding out the END XID, transaction id and OID of last
> > archived WAL log applied to the database. I was thinking if i can get that
> > value then i can reset XLOGs using pg_resetxlog to that point and then start
> > applying the new WAL logs. Am i thinking it correctly or there is some flaw
> > here.
> >
> > Also if i am thinking it right, then how can i find the details i asked
> > above.
> >
> > Regards,
> > Moiz Kothari
> >
> > On 10/30/06, Shoaib Mir < shoaibmir(at)gmail(dot)com> wrote:
> > >
> > > Hi Moiz,
> > >
> > > This might help you :) --> http://developer.postgresql.org/pgdocs/postgres/warm-standby.html
> > >
> > >
> > > Thanks,
> > > -------
> > > Shoaib Mir
> > > EnterpriseDB (www.enterprisedb.com)
> > >
> > > On 10/30/06, Andrew Sullivan < ajs(at)crankycanuck(dot)ca> wrote:
> > > >
> > > > On Mon, Oct 30, 2006 at 06:41:54PM +0530, Moiz Kothari wrote:
> > > > > I agree that PGCluster might be a better option, i dont want to go
> > > > with
> > > > > Slony because of primary key constraints.
> > > >
> > > > I don't know what the "primary key constraints" issue you have is,
> > > > but Slony would be inappropriate for a "100% failover" system
> > > > anyway:
> > > > you can't know you haven't trapped data on the origin. This is in
> > > > fact true for the WAL shipping you suggested, also. The only way to
> > > > achieve 100% reliable failover today, with guaranteed no data loss,
> > > > is to use a system that commits all the data on two machines at the
> > > > same time in the same transaction. I haven't seen any argument so
> > > > far that there is any such system "out of the box", although with
> > > > two
> > > > phase commit support available, it would seem that some systems
> > > > could
> > > > be extended in that direction.
> > > >
> > > > The other answer for all of this is to do it with hardware, but
> > > > that's a shared-disk system, so if your disk blows up, you have a
> > > > problem. Or, if you're using the operating system of people who
> > > > don't know how fsck works. I don't know anyone who has that
> > > > problem;
> > > > certainly not any vendors whose name starts with 'I' and ends with
> > > > 'M'.
> > > >
> > > > > 1) It might slow down the process a bit. as confirmation happens
> > > > after
> > > > > transaction gets comitted to all the nodes.
> > > >
> > > > Anyone who tells you that you can have completely reliable data
> > > > replication with no performance hit is trying to sell you a bridge
> > > > in
> > > > Brooklyn. If you want reliable data replication that guarantees you
> > > >
> > > > can have automatic failover, you are going to pay for it somehow;
> > > > the
> > > > question is which compromise you want to make. That seems to be
> > > > something you'll need to decide.
> > > >
> > > > > 2) Its difficult to convince, as it is an external project and if
> > > > support
> > > > > for the same stops or future versions of postgres does not work,
> > > > it might be
> > > > > a problem.
> > > >
> > > > If you have this problem, probably free software isn't for you.
> > > > PostgreSQL is a modular system, and people use different components
> > > > together in deployed systems. This happens to be true of commercial
> > > > offerings too (if not, you could buy the cheapest version of, say,
> > > > Oracle and get RAC in the bargain), but they _sell_ it to you as
> > > > though it were one big package. To the extent your managers don't
> > > > understand this, you're always going to have a problem using free
> > > > software.
> > > >
> > > > A
> > > > --
> > > > Andrew Sullivan | ajs(at)crankycanuck(dot)ca
> > > > In the future this spectacle of the middle classes shocking the
> > > > avant-
> > > > garde will probably become the textbook definition of Postmodernism.
> > > > --Brad Holland
> > > >
> > > > ---------------------------(end of
> > > > broadcast)---------------------------
> > > > TIP 9: In versions below 8.0, the planner will ignore your desire to
> > > >
> > > > choose an index scan if your joining column's datatypes do
> > > > not
> > > > match
> > > >
> > >
> > >
> >
>
| From: | "Shoaib Mir" <shoaibmir(at)gmail(dot)com> |
|---|---|
| To: | "Moiz Kothari" <moizpostgres(at)gmail(dot)com> |
| Cc: | "Andrew Sullivan" <ajs(at)crankycanuck(dot)ca>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-11-01 14:06:53 |
| Message-ID: | bf54be870611010606i36712ebbn276e62733167700d@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Moiz,
Yes, EnterpriseDB is compatible with SLES 10.
Thank you,
---------
Shoaib Mir
EnterpriseDB (www.enterprisedb.com)
On 11/1/06, Moiz Kothari <moizpostgres(at)gmail(dot)com> wrote:
>
> Shoaib,
>
> Also just so you know, we plan to use SLES 10 OS. so also let me know the
> compatibility of EnterpriseDB to the OS.
>
> Regards,
> Moiz
>
> On 10/31/06, Shoaib Mir <shoaibmir(at)gmail(dot)com> wrote:
> >
> > Moiz,
> >
> > Hmmmm, I think pg_controldata output might help you there to get these
> > stats.
> >
> > pg_controldata can be found in the PostgreSQL /bin folder.
> >
> > Thank you,
> > ---------
> > Shoaib Mir
> > EnterpriseDB ( www.enterprisedb.com)
> >
> > On 10/31/06, Moiz Kothari < moizpostgres(at)gmail(dot)com> wrote:
> > >
> > > Shoaib,
> > >
> > > This sounds really like what i need, but again 8.2 is in beta.
> > >
> > > Just one question, i dunno if i am thinking in right direction, but is
> > > there anyway of finding out the END XID, transaction id and OID of last
> > > archived WAL log applied to the database. I was thinking if i can get that
> > > value then i can reset XLOGs using pg_resetxlog to that point and then start
> > > applying the new WAL logs. Am i thinking it correctly or there is some flaw
> > > here.
> > >
> > > Also if i am thinking it right, then how can i find the details i
> > > asked above.
> > >
> > > Regards,
> > > Moiz Kothari
> > >
> > > On 10/30/06, Shoaib Mir < shoaibmir(at)gmail(dot)com> wrote:
> > > >
> > > > Hi Moiz,
> > > >
> > > > This might help you :) --> http://developer.postgresql.org/pgdocs/postgres/warm-standby.html
> > > >
> > > >
> > > > Thanks,
> > > > -------
> > > > Shoaib Mir
> > > > EnterpriseDB (www.enterprisedb.com)
> > > >
> > > > On 10/30/06, Andrew Sullivan < ajs(at)crankycanuck(dot)ca> wrote:
> > > > >
> > > > > On Mon, Oct 30, 2006 at 06:41:54PM +0530, Moiz Kothari wrote:
> > > > > > I agree that PGCluster might be a better option, i dont want to
> > > > > go with
> > > > > > Slony because of primary key constraints.
> > > > >
> > > > > I don't know what the "primary key constraints" issue you have is,
> > > > > but Slony would be inappropriate for a "100% failover" system
> > > > > anyway:
> > > > > you can't know you haven't trapped data on the origin. This is in
> > > > > fact true for the WAL shipping you suggested, also. The only way
> > > > > to
> > > > > achieve 100% reliable failover today, with guaranteed no data
> > > > > loss,
> > > > > is to use a system that commits all the data on two machines at
> > > > > the
> > > > > same time in the same transaction. I haven't seen any argument so
> > > > > far that there is any such system "out of the box", although with
> > > > > two
> > > > > phase commit support available, it would seem that some systems
> > > > > could
> > > > > be extended in that direction.
> > > > >
> > > > > The other answer for all of this is to do it with hardware, but
> > > > > that's a shared-disk system, so if your disk blows up, you have a
> > > > > problem. Or, if you're using the operating system of people who
> > > > > don't know how fsck works. I don't know anyone who has that
> > > > > problem;
> > > > > certainly not any vendors whose name starts with 'I' and ends with
> > > > > 'M'.
> > > > >
> > > > > > 1) It might slow down the process a bit. as confirmation happens
> > > > > after
> > > > > > transaction gets comitted to all the nodes.
> > > > >
> > > > > Anyone who tells you that you can have completely reliable data
> > > > > replication with no performance hit is trying to sell you a bridge
> > > > > in
> > > > > Brooklyn. If you want reliable data replication that guarantees
> > > > > you
> > > > > can have automatic failover, you are going to pay for it somehow;
> > > > > the
> > > > > question is which compromise you want to make. That seems to be
> > > > > something you'll need to decide.
> > > > >
> > > > > > 2) Its difficult to convince, as it is an external project and
> > > > > if support
> > > > > > for the same stops or future versions of postgres does not work,
> > > > > it might be
> > > > > > a problem.
> > > > >
> > > > > If you have this problem, probably free software isn't for you.
> > > > > PostgreSQL is a modular system, and people use different
> > > > > components
> > > > > together in deployed systems. This happens to be true of
> > > > > commercial
> > > > > offerings too (if not, you could buy the cheapest version of, say,
> > > > > Oracle and get RAC in the bargain), but they _sell_ it to you as
> > > > > though it were one big package. To the extent your managers don't
> > > > >
> > > > > understand this, you're always going to have a problem using free
> > > > > software.
> > > > >
> > > > > A
> > > > > --
> > > > > Andrew Sullivan | ajs(at)crankycanuck(dot)ca
> > > > > In the future this spectacle of the middle classes shocking the
> > > > > avant-
> > > > > garde will probably become the textbook definition of
> > > > > Postmodernism.
> > > > > --Brad Holland
> > > > >
> > > > > ---------------------------(end of
> > > > > broadcast)---------------------------
> > > > > TIP 9: In versions below 8.0, the planner will ignore your desire
> > > > > to
> > > > > choose an index scan if your joining column's datatypes do
> > > > > not
> > > > > match
> > > > >
> > > >
> > > >
> > >
> >
>
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Moiz Kothari <moizpostgres(at)gmail(dot)com> |
| Cc: | pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-11-14 20:11:54 |
| Message-ID: | 200611142011.kAEKBse00586@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
I wrote this for the 8.2 documentation. Let me know if it helps or you
have other suggestions:
http://developer.postgresql.org/pgdocs/postgres/failover.html
---------------------------------------------------------------------------
Moiz Kothari wrote:
> Guys,
>
> I have been thinking about this and wanted to see if it can be achived. I
> wanted to make a 100% failover solution for my postgres databases. The first
> thing that comes to my mind is doing it using WAL logs. Am attaching the
> diagram for which i will write more here.
>
> I was thinking if i can have Hotsync the databases using the WAL logs. If
> you see the architecture, the select goes to the SLAVE nodes and the INSERTS
> goes to the MASTER database, that means there should be no transactions
> happening on SLAVES (pure select). not even using "plpgsql". In this
> archecture i wont even mind restarting the SLAVE nodes if i need to.
>
> I was reading on PIT recovery on postgres, the only current problem i am
> facing with that is, i need to backup the database and move the slaves and
> the apply WAL logs to it. That could be huge amount of transfer and hence a
> longer downtime then moving 16mb WAL log files.
>
> Can someone help me out here, what i want is a continuous applying of WAL
> logs once i have brought the database up. I want to elimiate the backup of
> master to be restored to the slaves everytime i want to apply WAL to slaves.
> It would be real help if someone can tell me if it is possible to apply WAL
> logs to the slaves continously as soon as they are created on MASTER. I
> checked other tools available and thougth this would be best approach if it
> works.
>
> Awaiting reply soon.
>
> Regards,
> Moiz Kothari
[ Attachment, skipping... ]
>
> ---------------------------(end of broadcast)---------------------------
> TIP 5: don't forget to increase your free space map settings
--
Bruce Momjian bruce(at)momjian(dot)us
EnterpriseDB http://www.enterprisedb.com
+ If your life is a hard drive, Christ can be your backup. +
| From: | Brad Nicholson <bnichols(at)ca(dot)afilias(dot)info> |
|---|---|
| To: | Bruce Momjian <bruce(at)momjian(dot)us> |
| Cc: | Moiz Kothari <moizpostgres(at)gmail(dot)com>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-11-15 17:24:48 |
| Message-ID: | 1163611488.5789.90.camel@dba5.int.libertyrms.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Excellent addition. I suggest in 24.1 - Shared Disk Failover something
about the risk of having two postmasters come up on the same data
directory, which is entirely possible if the old master doesn't release
the disk in time.
On Tue, 2006-11-14 at 15:11 -0500, Bruce Momjian wrote:
> I wrote this for the 8.2 documentation. Let me know if it helps or you
> have other suggestions:
>
> http://developer.postgresql.org/pgdocs/postgres/failover.html
>
> ---------------------------------------------------------------------------
>
> Moiz Kothari wrote:
> > Guys,
> >
> > I have been thinking about this and wanted to see if it can be achived. I
> > wanted to make a 100% failover solution for my postgres databases. The first
> > thing that comes to my mind is doing it using WAL logs. Am attaching the
> > diagram for which i will write more here.
> >
> > I was thinking if i can have Hotsync the databases using the WAL logs. If
> > you see the architecture, the select goes to the SLAVE nodes and the INSERTS
> > goes to the MASTER database, that means there should be no transactions
> > happening on SLAVES (pure select). not even using "plpgsql". In this
> > archecture i wont even mind restarting the SLAVE nodes if i need to.
> >
> > I was reading on PIT recovery on postgres, the only current problem i am
> > facing with that is, i need to backup the database and move the slaves and
> > the apply WAL logs to it. That could be huge amount of transfer and hence a
> > longer downtime then moving 16mb WAL log files.
> >
> > Can someone help me out here, what i want is a continuous applying of WAL
> > logs once i have brought the database up. I want to elimiate the backup of
> > master to be restored to the slaves everytime i want to apply WAL to slaves.
> > It would be real help if someone can tell me if it is possible to apply WAL
> > logs to the slaves continously as soon as they are created on MASTER. I
> > checked other tools available and thougth this would be best approach if it
> > works.
> >
> > Awaiting reply soon.
> >
> > Regards,
> > Moiz Kothari
>
> [ Attachment, skipping... ]
>
> >
> > ---------------------------(end of broadcast)---------------------------
> > TIP 5: don't forget to increase your free space map settings
>
--
Brad Nicholson 416-673-4106
Database Administrator, Afilias Canada Corp.
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Brad Nicholson <bnichols(at)ca(dot)afilias(dot)info> |
| Cc: | Moiz Kothari <moizpostgres(at)gmail(dot)com>, pgsql-admin(at)postgresql(dot)org |
| Subject: | Re: 100% failover + replication solution |
| Date: | 2006-11-18 00:30:53 |
| Message-ID: | 200611180030.kAI0UrS15276@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-admin |
Brad Nicholson wrote:
> Excellent addition. I suggest in 24.1 - Shared Disk Failover something
> about the risk of having two postmasters come up on the same data
> directory, which is entirely possible if the old master doesn't release
> the disk in time.
I have added a mention of this.
---------------------------------------------------------------------------
>
>
>
> On Tue, 2006-11-14 at 15:11 -0500, Bruce Momjian wrote:
> > I wrote this for the 8.2 documentation. Let me know if it helps or you
> > have other suggestions:
> >
> > http://developer.postgresql.org/pgdocs/postgres/failover.html
> >
> > ---------------------------------------------------------------------------
> >
> > Moiz Kothari wrote:
> > > Guys,
> > >
> > > I have been thinking about this and wanted to see if it can be achived. I
> > > wanted to make a 100% failover solution for my postgres databases. The first
> > > thing that comes to my mind is doing it using WAL logs. Am attaching the
> > > diagram for which i will write more here.
> > >
> > > I was thinking if i can have Hotsync the databases using the WAL logs. If
> > > you see the architecture, the select goes to the SLAVE nodes and the INSERTS
> > > goes to the MASTER database, that means there should be no transactions
> > > happening on SLAVES (pure select). not even using "plpgsql". In this
> > > archecture i wont even mind restarting the SLAVE nodes if i need to.
> > >
> > > I was reading on PIT recovery on postgres, the only current problem i am
> > > facing with that is, i need to backup the database and move the slaves and
> > > the apply WAL logs to it. That could be huge amount of transfer and hence a
> > > longer downtime then moving 16mb WAL log files.
> > >
> > > Can someone help me out here, what i want is a continuous applying of WAL
> > > logs once i have brought the database up. I want to elimiate the backup of
> > > master to be restored to the slaves everytime i want to apply WAL to slaves.
> > > It would be real help if someone can tell me if it is possible to apply WAL
> > > logs to the slaves continously as soon as they are created on MASTER. I
> > > checked other tools available and thougth this would be best approach if it
> > > works.
> > >
> > > Awaiting reply soon.
> > >
> > > Regards,
> > > Moiz Kothari
> >
> > [ Attachment, skipping... ]
> >
> > >
> > > ---------------------------(end of broadcast)---------------------------
> > > TIP 5: don't forget to increase your free space map settings
> >
> --
> Brad Nicholson 416-673-4106
> Database Administrator, Afilias Canada Corp.
>
>
> ---------------------------(end of broadcast)---------------------------
> TIP 5: don't forget to increase your free space map settings
--
Bruce Momjian bruce(at)momjian(dot)us
EnterpriseDB http://www.enterprisedb.com
+ If your life is a hard drive, Christ can be your backup. +