wal_buffers
| Lists: | pgsql-hackers |
|---|
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | wal_buffers |
| Date: | 2012-02-19 05:24:12 |
| Message-ID: | CA+TgmoZ0gyvE1ouWkmSovm9aDNppMD7ExAMO59h_3qBHX8Rv4A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
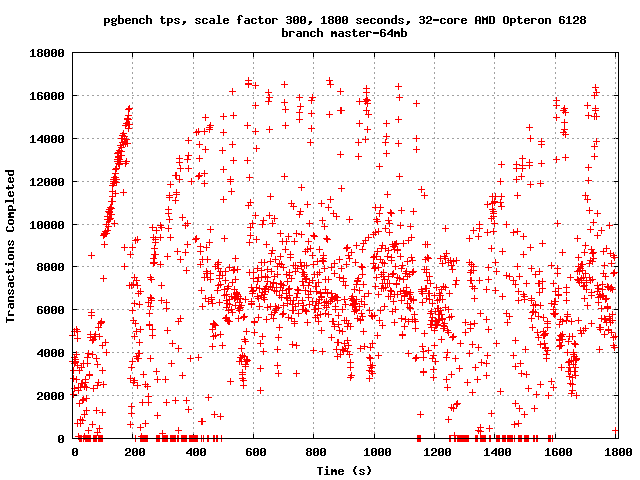
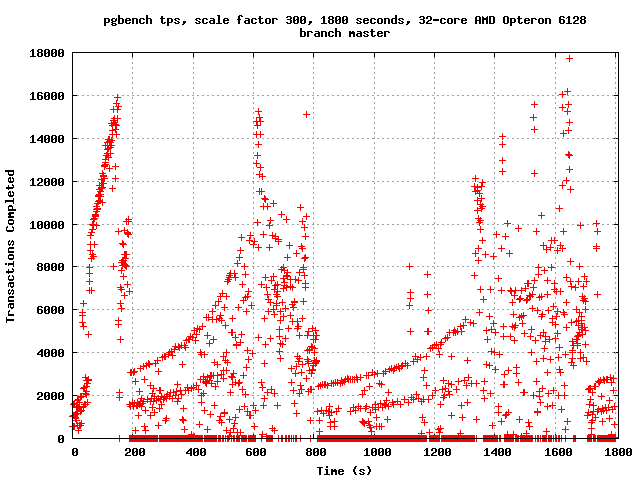
Just for kicks, I ran two 30-minute pgbench tests at scale factor 300
tonight on Nate Boley's machine, with -n -l -c 32 -j 32. The
configurations were identical, except that on one of them, I set
wal_buffers=64MB. It seemed to make quite a lot of difference:
wal_buffers not set (thus, 16MB):
tps = 3162.594605 (including connections establishing)
wal_buffers=64MB:
tps = 6164.194625 (including connections establishing)
Rest of config: shared_buffers = 8GB, maintenance_work_mem = 1GB,
synchronous_commit = off, checkpoint_segments = 300,
checkpoint_timeout = 15min, checkpoint_completion_target = 0.9,
wal_writer_delay = 20ms
I have attached tps scatterplots. The obvious conclusion appears to
be that, with only 16MB of wal_buffers, the buffer "wraps around" with
some regularity: we can't insert more WAL because the buffer we need
to use still contains WAL that hasn't yet been fsync'd, leading to
long stalls. More buffer space ameliorates the problem. This is not
very surprising, when you think about it: it's clear that the peak tps
rate approaches 18k/s on these tests; right after a checkpoint, every
update will force a full page write - that is, a WAL record > 8kB. So
we'll fill up a 16MB WAL segment in about a tenth of a second. That
doesn't leave much breathing room. I think we might want to consider
adjusting our auto-tuning formula for wal_buffers to allow for a
higher cap, although this is obviously not enough data to draw any
firm conclusions.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 14.4 KB |
|
image/png | 12.0 KB |
| From: | Euler Taveira de Oliveira <euler(at)timbira(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-19 14:46:33 |
| Message-ID: | 4F410B49.8060702@timbira.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 19-02-2012 02:24, Robert Haas wrote:
> I have attached tps scatterplots. The obvious conclusion appears to
> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
> some regularity
>
Isn't it useful to print some messages on the log when we have "wrap around"?
In this case, we have an idea that wal_buffers needs to be increased.
--
Euler Taveira de Oliveira - Timbira http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Euler Taveira de Oliveira <euler(at)timbira(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-19 18:08:28 |
| Message-ID: | CA+TgmoYL6GsPdpBbjhfj8xeCLdXmFBZCW1s9ZGxDv+efj=E2dA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Feb 19, 2012 at 9:46 AM, Euler Taveira de Oliveira
<euler(at)timbira(dot)com> wrote:
> On 19-02-2012 02:24, Robert Haas wrote:
>> I have attached tps scatterplots. The obvious conclusion appears to
>> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
>> some regularity
>>
> Isn't it useful to print some messages on the log when we have "wrap around"?
> In this case, we have an idea that wal_buffers needs to be increased.
I was thinking about that. I think that what might be more useful
than a log message is a counter somewhere in shared memory. Logging
imposes a lot of overhead, which is exactly what we don't want here,
and the volume might be quite high on a system that is bumping up
against this problem. Of course then the question is... how would we
expose the counter value?
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Euler Taveira de Oliveira <euler(at)timbira(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-19 18:33:11 |
| Message-ID: | 28916.1329676391@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> On Sun, Feb 19, 2012 at 9:46 AM, Euler Taveira de Oliveira
> <euler(at)timbira(dot)com> wrote:
>> Isn't it useful to print some messages on the log when we have "wrap around"?
>> In this case, we have an idea that wal_buffers needs to be increased.
> I was thinking about that. I think that what might be more useful
> than a log message is a counter somewhere in shared memory. Logging
> imposes a lot of overhead, which is exactly what we don't want here,
> and the volume might be quite high on a system that is bumping up
> against this problem. Of course then the question is... how would we
> expose the counter value?
Why do you need a counter, other than the current LSN? Surely the
number of WAL buffer ring cycles can be deduced directly from that.
regards, tom lane
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Euler Taveira de Oliveira <euler(at)timbira(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-19 18:40:00 |
| Message-ID: | CA+U5nMKNSXzCtqYdkPxxK+-obAyrMwu068ShTT08HciWODrtqQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Feb 19, 2012 at 6:33 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Robert Haas <robertmhaas(at)gmail(dot)com> writes:
>> On Sun, Feb 19, 2012 at 9:46 AM, Euler Taveira de Oliveira
>> <euler(at)timbira(dot)com> wrote:
>>> Isn't it useful to print some messages on the log when we have "wrap around"?
>>> In this case, we have an idea that wal_buffers needs to be increased.
>
>> I was thinking about that. I think that what might be more useful
>> than a log message is a counter somewhere in shared memory. Logging
>> imposes a lot of overhead, which is exactly what we don't want here,
>> and the volume might be quite high on a system that is bumping up
>> against this problem. Of course then the question is... how would we
>> expose the counter value?
>
> Why do you need a counter, other than the current LSN? Surely the
> number of WAL buffer ring cycles can be deduced directly from that.
The problem isn't how many times its cycled, the issue is whether
there was a wait induced by needing to flush wal buffers because of
too many writes. You can't count those waits in the way you suggest,
though you can calculate an upper limit on them, but that's not very
useful.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Euler Taveira de Oliveira <euler(at)timbira(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-20 04:10:21 |
| Message-ID: | CAHGQGwFFx_sFEbM_Mhc7jSs59q1Gw8AXBkJqC4v=bzcfg1Tz0A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Feb 20, 2012 at 3:08 AM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> On Sun, Feb 19, 2012 at 9:46 AM, Euler Taveira de Oliveira
> <euler(at)timbira(dot)com> wrote:
>> On 19-02-2012 02:24, Robert Haas wrote:
>>> I have attached tps scatterplots. The obvious conclusion appears to
>>> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
>>> some regularity
>>>
>> Isn't it useful to print some messages on the log when we have "wrap around"?
>> In this case, we have an idea that wal_buffers needs to be increased.
>
> I was thinking about that. I think that what might be more useful
> than a log message is a counter somewhere in shared memory. Logging
> imposes a lot of overhead, which is exactly what we don't want here,
> and the volume might be quite high on a system that is bumping up
> against this problem. Of course then the question is... how would we
> expose the counter value?
There is no existing statistics view suitable to include such information.
What about defining pg_stat_xlog or something?
Regards,
--
Fujii Masao
NIPPON TELEGRAPH AND TELEPHONE CORPORATION
NTT Open Source Software Center
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-20 04:26:10 |
| Message-ID: | 4F41CB62.3030002@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 02/19/2012 12:24 AM, Robert Haas wrote:
> I think we might want to consider
> adjusting our auto-tuning formula for wal_buffers to allow for a
> higher cap, although this is obviously not enough data to draw any
> firm conclusions.
That's an easy enough idea to throw into my testing queue. The 16MB
auto-tuning upper bound was just the easiest number to suggest that was
obviously useful and unlikely to be wasteful. One of the reasons
wal_buffers remains a user-visible parameter was that no one every
really did an analysis at what its useful upper bound was--and that
number might move up as other bottlenecks are smashed too.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Euler Taveira de Oliveira <euler(at)timbira(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-20 08:59:25 |
| Message-ID: | CA+U5nM+VDFfya_Xj1Nau13mGBaGsw-LPzN_JtMtcZpcLdUAGkw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Feb 20, 2012 at 4:10 AM, Fujii Masao <masao(dot)fujii(at)gmail(dot)com> wrote:
> On Mon, Feb 20, 2012 at 3:08 AM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>> On Sun, Feb 19, 2012 at 9:46 AM, Euler Taveira de Oliveira
>> <euler(at)timbira(dot)com> wrote:
>>> On 19-02-2012 02:24, Robert Haas wrote:
>>>> I have attached tps scatterplots. The obvious conclusion appears to
>>>> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
>>>> some regularity
>>>>
>>> Isn't it useful to print some messages on the log when we have "wrap around"?
>>> In this case, we have an idea that wal_buffers needs to be increased.
>>
>> I was thinking about that. I think that what might be more useful
>> than a log message is a counter somewhere in shared memory. Logging
>> imposes a lot of overhead, which is exactly what we don't want here,
>> and the volume might be quite high on a system that is bumping up
>> against this problem. Of course then the question is... how would we
>> expose the counter value?
>
> There is no existing statistics view suitable to include such information.
> What about defining pg_stat_xlog or something?
Perhaps pg_stat_perf so we don't need to find a new home every time.
Thinking about it, I think renaming pg_stat_bgwriter would make more sense.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Fujii Masao <masao(dot)fujii(at)gmail(dot)com>, Euler Taveira de Oliveira <euler(at)timbira(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-02-20 19:23:31 |
| Message-ID: | CA+Tgmob6h_0D8Qtn1+sqjSFHEQRgJeTVtg4CKASNve-+djk_Tw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Feb 20, 2012 at 3:59 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
>> There is no existing statistics view suitable to include such information.
>> What about defining pg_stat_xlog or something?
>
> Perhaps pg_stat_perf so we don't need to find a new home every time.
>
> Thinking about it, I think renaming pg_stat_bgwriter would make more sense.
When we created pg_stat_reset_shared(text), we seemed to be
contemplating the idea of multiple sets of shared counters identified
by names -- bgwriter for the background writer, and maybe other things
for other subsystems. So we'd have to think about how to adjust that.
I do agree with you that it seems a shame to invent a whole new view
for one counter...
Another thought is that I'm not sure it makes sense to run this
through the stats system at all. We could regard it as a shared
memory counter protected by one of the LWLocks involved, which would
probably be quite a bit cheaper - just one machine instruction to
increment it at need.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-08-27 19:38:20 |
| Message-ID: | 20120827193820.GV11088@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Added to TODO:
Allow reporting of stalls due to wal_buffer wrap-around
http://archives.postgresql.org/pgsql-hackers/2012-02/msg00826.php
---------------------------------------------------------------------------
On Sun, Feb 19, 2012 at 12:24:12AM -0500, Robert Haas wrote:
> Just for kicks, I ran two 30-minute pgbench tests at scale factor 300
> tonight on Nate Boley's machine, with -n -l -c 32 -j 32. The
> configurations were identical, except that on one of them, I set
> wal_buffers=64MB. It seemed to make quite a lot of difference:
>
> wal_buffers not set (thus, 16MB):
> tps = 3162.594605 (including connections establishing)
>
> wal_buffers=64MB:
> tps = 6164.194625 (including connections establishing)
>
> Rest of config: shared_buffers = 8GB, maintenance_work_mem = 1GB,
> synchronous_commit = off, checkpoint_segments = 300,
> checkpoint_timeout = 15min, checkpoint_completion_target = 0.9,
> wal_writer_delay = 20ms
>
> I have attached tps scatterplots. The obvious conclusion appears to
> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
> some regularity: we can't insert more WAL because the buffer we need
> to use still contains WAL that hasn't yet been fsync'd, leading to
> long stalls. More buffer space ameliorates the problem. This is not
> very surprising, when you think about it: it's clear that the peak tps
> rate approaches 18k/s on these tests; right after a checkpoint, every
> update will force a full page write - that is, a WAL record > 8kB. So
> we'll fill up a 16MB WAL segment in about a tenth of a second. That
> doesn't leave much breathing room. I think we might want to consider
> adjusting our auto-tuning formula for wal_buffers to allow for a
> higher cap, although this is obviously not enough data to draw any
> firm conclusions.
>
> --
> Robert Haas
> EnterpriseDB: http://www.enterprisedb.com
> The Enterprise PostgreSQL Company
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
|---|---|
| To: | "'Bruce Momjian'" <bruce(at)momjian(dot)us>, "'Robert Haas'" <robertmhaas(at)gmail(dot)com> |
| Cc: | <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: wal_buffers |
| Date: | 2012-08-28 04:10:33 |
| Message-ID: | 002701cd84d3$12688ce0$3739a6a0$@kapila@huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
From: pgsql-hackers-owner(at)postgresql(dot)org
[mailto:pgsql-hackers-owner(at)postgresql(dot)org] On Behalf Of Bruce Momjian
> Added to TODO:
> Allow reporting of stalls due to wal_buffer wrap-around
>
http://archives.postgresql.org/pgsql-hackers/2012-02/msg00826.php
Isn't this indicates that while writing XLOG, it needs some tuning such that
when some thresh hold buffers(2/3) are full, then trigger LOGWriter.
---------------------------------------------------------------------------
On Sun, Feb 19, 2012 at 12:24:12AM -0500, Robert Haas wrote:
> Just for kicks, I ran two 30-minute pgbench tests at scale factor 300
> tonight on Nate Boley's machine, with -n -l -c 32 -j 32. The
> configurations were identical, except that on one of them, I set
> wal_buffers=64MB. It seemed to make quite a lot of difference:
>
> wal_buffers not set (thus, 16MB):
> tps = 3162.594605 (including connections establishing)
>
> wal_buffers=64MB:
> tps = 6164.194625 (including connections establishing)
>
> Rest of config: shared_buffers = 8GB, maintenance_work_mem = 1GB,
> synchronous_commit = off, checkpoint_segments = 300,
> checkpoint_timeout = 15min, checkpoint_completion_target = 0.9,
> wal_writer_delay = 20ms
>
> I have attached tps scatterplots. The obvious conclusion appears to
> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
> some regularity: we can't insert more WAL because the buffer we need
> to use still contains WAL that hasn't yet been fsync'd, leading to
> long stalls. More buffer space ameliorates the problem. This is not
> very surprising, when you think about it: it's clear that the peak tps
> rate approaches 18k/s on these tests; right after a checkpoint, every
> update will force a full page write - that is, a WAL record > 8kB. So
> we'll fill up a 16MB WAL segment in about a tenth of a second. That
> doesn't leave much breathing room. I think we might want to consider
> adjusting our auto-tuning formula for wal_buffers to allow for a
> higher cap, although this is obviously not enough data to draw any
> firm conclusions.
>
> --
> Robert Haas
> EnterpriseDB: http://www.enterprisedb.com
> The Enterprise PostgreSQL Company
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Bruce Momjian <bruce(at)momjian(dot)us> |
|---|---|
| To: | Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
| Cc: | 'Robert Haas' <robertmhaas(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-08-28 16:03:19 |
| Message-ID: | 20120828160319.GB16116@momjian.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Aug 28, 2012 at 09:40:33AM +0530, Amit Kapila wrote:
> From: pgsql-hackers-owner(at)postgresql(dot)org
> [mailto:pgsql-hackers-owner(at)postgresql(dot)org] On Behalf Of Bruce Momjian
>
> > Added to TODO:
>
> > Allow reporting of stalls due to wal_buffer wrap-around
>
> >
> http://archives.postgresql.org/pgsql-hackers/2012-02/msg00826.php
>
> Isn't this indicates that while writing XLOG, it needs some tuning such that
> when some thresh hold buffers(2/3) are full, then trigger LOGWriter.
I assumed the LOGWriter was already working as fast as it could, but
couldn't keep up.
---------------------------------------------------------------------------
>
> On Sun, Feb 19, 2012 at 12:24:12AM -0500, Robert Haas wrote:
> > Just for kicks, I ran two 30-minute pgbench tests at scale factor 300
> > tonight on Nate Boley's machine, with -n -l -c 32 -j 32. The
> > configurations were identical, except that on one of them, I set
> > wal_buffers=64MB. It seemed to make quite a lot of difference:
> >
> > wal_buffers not set (thus, 16MB):
> > tps = 3162.594605 (including connections establishing)
> >
> > wal_buffers=64MB:
> > tps = 6164.194625 (including connections establishing)
> >
> > Rest of config: shared_buffers = 8GB, maintenance_work_mem = 1GB,
> > synchronous_commit = off, checkpoint_segments = 300,
> > checkpoint_timeout = 15min, checkpoint_completion_target = 0.9,
> > wal_writer_delay = 20ms
> >
> > I have attached tps scatterplots. The obvious conclusion appears to
> > be that, with only 16MB of wal_buffers, the buffer "wraps around" with
> > some regularity: we can't insert more WAL because the buffer we need
> > to use still contains WAL that hasn't yet been fsync'd, leading to
> > long stalls. More buffer space ameliorates the problem. This is not
> > very surprising, when you think about it: it's clear that the peak tps
> > rate approaches 18k/s on these tests; right after a checkpoint, every
> > update will force a full page write - that is, a WAL record > 8kB. So
> > we'll fill up a 16MB WAL segment in about a tenth of a second. That
> > doesn't leave much breathing room. I think we might want to consider
> > adjusting our auto-tuning formula for wal_buffers to allow for a
> > higher cap, although this is obviously not enough data to draw any
> > firm conclusions.
> >
> > --
> > Robert Haas
> > EnterpriseDB: http://www.enterprisedb.com
> > The Enterprise PostgreSQL Company
>
>
>
> >
> > --
> > Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> > To make changes to your subscription:
> > http://www.postgresql.org/mailpref/pgsql-hackers
>
>
> --
> Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
> EnterpriseDB http://enterprisedb.com
>
> + It's impossible for everything to be true. +
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
>
--
Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
EnterpriseDB http://enterprisedb.com
+ It's impossible for everything to be true. +
| From: | Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
|---|---|
| To: | "'Bruce Momjian'" <bruce(at)momjian(dot)us> |
| Cc: | "'Robert Haas'" <robertmhaas(at)gmail(dot)com>, <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: wal_buffers |
| Date: | 2012-08-29 10:08:12 |
| Message-ID: | 004301cd85ce$337909e0$9a6b1da0$@kapila@huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tuesday, August 28, 2012 9:33 PM Bruce Momjian wrote:
On Tue, Aug 28, 2012 at 09:40:33AM +0530, Amit Kapila wrote:
> From: pgsql-hackers-owner(at)postgresql(dot)org
> [mailto:pgsql-hackers-owner(at)postgresql(dot)org] On Behalf Of Bruce Momjian
>
>>> Added to TODO:
>
>>> Allow reporting of stalls due to wal_buffer wrap-around
>
>>>
>>> http://archives.postgresql.org/pgsql-hackers/2012-02/msg00826.php
>
>> Isn't this indicates that while writing XLOG, it needs some tuning such
that
>> when some thresh hold buffers(2/3) are full, then trigger LOGWriter.
> I assumed the LOGWriter was already working as fast as it could, but
> couldn't keep up.
I have doubt that in some cases it might not, for example
1. Assume 16M Xlog buffers
2. 6M or less than that is filled.
3. Background writer decides how much to flush and starts writing and at the
same time backends start filling
remaining 10M of the buffers.
4. Background writer goes to sleep after flushing 6M.
5. Backends have filled all 16M, in this case it may so happen that some
backends might need to do I/O.
Some other cases where I think it can be useful to wake LogWriter
Case-1
-------
1. Log writer delay is default 200ms or set to some higher value by user.
2. All the configured buffers got filled, backend might need to do I/O.
Case-2
-------
The case-1 scenario can also happen even if user has set wal_buffers = -1
(Auto tuning of wal buffers),
Because it reserves XLog buffers equivalent to one segment file and in high
load if that gets filled, backends might need
to do I/O.
---------------------------------------------------------------------------
>
> On Sun, Feb 19, 2012 at 12:24:12AM -0500, Robert Haas wrote:
> > Just for kicks, I ran two 30-minute pgbench tests at scale factor 300
> > tonight on Nate Boley's machine, with -n -l -c 32 -j 32. The
> > configurations were identical, except that on one of them, I set
> > wal_buffers=64MB. It seemed to make quite a lot of difference:
> >
> > wal_buffers not set (thus, 16MB):
> > tps = 3162.594605 (including connections establishing)
> >
> > wal_buffers=64MB:
> > tps = 6164.194625 (including connections establishing)
> >
> > Rest of config: shared_buffers = 8GB, maintenance_work_mem = 1GB,
> > synchronous_commit = off, checkpoint_segments = 300,
> > checkpoint_timeout = 15min, checkpoint_completion_target = 0.9,
> > wal_writer_delay = 20ms
> >
> > I have attached tps scatterplots. The obvious conclusion appears to
> > be that, with only 16MB of wal_buffers, the buffer "wraps around" with
> > some regularity: we can't insert more WAL because the buffer we need
> > to use still contains WAL that hasn't yet been fsync'd, leading to
> > long stalls. More buffer space ameliorates the problem. This is not
> > very surprising, when you think about it: it's clear that the peak tps
> > rate approaches 18k/s on these tests; right after a checkpoint, every
> > update will force a full page write - that is, a WAL record > 8kB. So
> > we'll fill up a 16MB WAL segment in about a tenth of a second. That
> > doesn't leave much breathing room. I think we might want to consider
> > adjusting our auto-tuning formula for wal_buffers to allow for a
> > higher cap, although this is obviously not enough data to draw any
> > firm conclusions.
> >
> > --
> > Robert Haas
> > EnterpriseDB: http://www.enterprisedb.com
> > The Enterprise PostgreSQL Company
>
>
>
> >
> > --
> > Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> > To make changes to your subscription:
> > http://www.postgresql.org/mailpref/pgsql-hackers
>
>
> --
> Bruce Momjian <bruce(at)momjian(dot)us> http://momjian.us
> EnterpriseDB http://enterprisedb.com
>
> + It's impossible for everything to be true. +
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers(at)postgresql(dot)org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
>
With Regards,
Amit Kapila.
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-08-30 02:25:57 |
| Message-ID: | CAEYLb_WEVYdar7n+F4VVhJL-pPEGD_hS1BCKfV-FiZykwJF21A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 19 February 2012 05:24, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> I have attached tps scatterplots. The obvious conclusion appears to
> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
> some regularity: we can't insert more WAL because the buffer we need
> to use still contains WAL that hasn't yet been fsync'd, leading to
> long stalls. More buffer space ameliorates the problem.
Incidentally, I wondered if we could further improve group commit
performance by implementing commit_delay with a WaitLatch call, and
setting the latch in the event of WAL buffers wraparound (or rather, a
queued wraparound request - a segment switch needs WALWriteLock, which
the group commit leader holds for a relatively long time during the
delay). I'm not really sure how significant a win this might be,
though. There could be other types of contention, which could be
considerably more significant. I'll try and take a look at it next
week.
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: wal_buffers |
| Date: | 2012-08-30 13:44:07 |
| Message-ID: | CA+TgmoZNT35aCRHRBcPDRNtExkrd4KaNbOB1D7cG95CBH_Gcsg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Aug 29, 2012 at 10:25 PM, Peter Geoghegan <peter(at)2ndquadrant(dot)com> wrote:
> On 19 February 2012 05:24, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>> I have attached tps scatterplots. The obvious conclusion appears to
>> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
>> some regularity: we can't insert more WAL because the buffer we need
>> to use still contains WAL that hasn't yet been fsync'd, leading to
>> long stalls. More buffer space ameliorates the problem.
>
> Incidentally, I wondered if we could further improve group commit
> performance by implementing commit_delay with a WaitLatch call, and
> setting the latch in the event of WAL buffers wraparound (or rather, a
> queued wraparound request - a segment switch needs WALWriteLock, which
> the group commit leader holds for a relatively long time during the
> delay). I'm not really sure how significant a win this might be,
> though. There could be other types of contention, which could be
> considerably more significant. I'll try and take a look at it next
> week.
I have a feeling that one of the big bottlenecks here is that we force
an immediate fsync when we reach the end of a segment. I think it was
originally done that way to keep the code simple, and it does
accomplish that, but it's not so hot for performance. More generally,
I think we really need to split WALWriteLock into two locks, one to
protect the write position and the other to protect the flush
position. I think we're often ending up with a write (which is
usually fast) waiting for a flush (which is often much slower) when in
fact those things ought to be able to happen in parallel.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Amit Kapila <amit(dot)kapila(at)huawei(dot)com> |
|---|---|
| To: | "'Robert Haas'" <robertmhaas(at)gmail(dot)com>, "'Peter Geoghegan'" <peter(at)2ndquadrant(dot)com> |
| Cc: | <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: wal_buffers |
| Date: | 2012-08-31 05:12:20 |
| Message-ID: | 003301cd8737$333bcac0$99b36040$@kapila@huawei.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thursday, August 30, 2012 7:14 PM Robert Haas wrote:
On Wed, Aug 29, 2012 at 10:25 PM, Peter Geoghegan <peter(at)2ndquadrant(dot)com>
wrote:
> On 19 February 2012 05:24, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>>> I have attached tps scatterplots. The obvious conclusion appears to
>>> be that, with only 16MB of wal_buffers, the buffer "wraps around" with
>>> some regularity: we can't insert more WAL because the buffer we need
>>> to use still contains WAL that hasn't yet been fsync'd, leading to
>>> long stalls. More buffer space ameliorates the problem.
>
>> Incidentally, I wondered if we could further improve group commit
>> performance by implementing commit_delay with a WaitLatch call, and
>> setting the latch in the event of WAL buffers wraparound (or rather, a
>> queued wraparound request - a segment switch needs WALWriteLock, which
>> the group commit leader holds for a relatively long time during the
>> delay). I'm not really sure how significant a win this might be,
>> though. There could be other types of contention, which could be
>> considerably more significant. I'll try and take a look at it next
>> week.
> I have a feeling that one of the big bottlenecks here is that we force
> an immediate fsync when we reach the end of a segment. I think it was
> originally done that way to keep the code simple, and it does
> accomplish that, but it's not so hot for performance. More generally,
> I think we really need to split WALWriteLock into two locks, one to
> protect the write position and the other to protect the flush
> position. I think we're often ending up with a write (which is
> usually fast) waiting for a flush (which is often much slower) when in
> fact those things ought to be able to happen in parallel.
This is really good idea for splitting WALWriteLock into two locks,
but in that case do we need separate handling for OPEN_SYNC method where
write and flush happens together?
And more about WAL, do you have any suggestions regarding the idea of
triggering
WALWriter in case Xlog buffers are nearly full?
With Regards,
Amit Kapila.
With Regards,
Amit Kapila.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company