Re: spinlocks on powerpc
| Lists: | pgsql-hackers |
|---|
| From: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | spinlocks on powerpc |
| Date: | 2011-12-30 05:47:23 |
| Message-ID: | CADWW1HF5oU_=Yxwmw_Wzr=iWr2jyNfH_yY0ySjMapPirgfqYZA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2011/12/30 Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>
> Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> writes:
> > The Linux kernel does this (arch/powerpc/include/asm/ppc-opcode.h):
>
> Yeah, I was looking at that too.
>
> > We can't copy-paste code from Linux directly, and I'm not sure I like
> > that particular phrasing of the macro, but perhaps we should steal the
> > idea and only use the hint on 64-bit PowerPC processors?
>
> The info that I've found says that the hint exists beginning in POWER6,
> and there were certainly 64-bit Power machines before that. However,
> it might be that the only machines that actually spit up on the hint bit
> (rather than ignore it) were 32-bit, in which case this would be a
> usable heuristic. Not sure how we can research that ... do we want to
> just assume the kernel guys know what they're doing?
I'm a bit confused and might miss the point, but...
If we can decide whether to use the hint operand when we build
postgres, I think it's better to check if we can compile and run
a sample code with lwarx hint operand than to refer to some
arbitrary defines, such as FOO_PPC64 or something.
I still wonder when to judge the hint availability, compile time
or runtime.
I don't have any idea how to decide that on runtime, though.
P.S.
I changed the subject since it's no longer related to HPUX.
Regards,
Manabu Ori
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2011-12-30 16:23:14 |
| Message-ID: | 17831.1325262194@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Manabu Ori <manabu(dot)ori(at)gmail(dot)com> writes:
> 2011/12/30 Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>
>> The info that I've found says that the hint exists beginning in POWER6,
>> and there were certainly 64-bit Power machines before that. However,
>> it might be that the only machines that actually spit up on the hint bit
>> (rather than ignore it) were 32-bit, in which case this would be a
>> usable heuristic. Not sure how we can research that ... do we want to
>> just assume the kernel guys know what they're doing?
> I'm a bit confused and might miss the point, but...
> If we can decide whether to use the hint operand when we build
> postgres, I think it's better to check if we can compile and run
> a sample code with lwarx hint operand than to refer to some
> arbitrary defines, such as FOO_PPC64 or something.
Well, there are two different conditions we have to deal with:
(1) does gcc+assembler understand the hint operand for lwarx?
This we can reasonably check with configure, since it's a property
of the build environment.
(2) does the machine where the executable will run understand the
hint bit, or failing that at least treat it as a no-op? We cannot
determine that at configure time, unless we can fall back on some
approximate proxy condition like testing 64-bit vs 32-bit.
(I see that the kernel boys dodged point 1 by writing the lwarx
instruction as a numeric constant, but that seems far too ugly
and fragile for my taste. In any case point 2 is the big issue.)
If you don't like the 64-bit hack or something much like it,
I think we have got three other alternatives:
* Do nothing, ie reject the patch.
* Push the problem onto the user by offering a configure option.
I don't care for this in the least, notably because packagers
such as Linux distros couldn't safely enable the option, so in
practice it would be unavailable to a large fraction of users.
* Perform a runtime test. I'm not sure if there's a better way,
but if nothing else we could fork a subprocess during postmaster
start, have it try an lwarx with hint bit, observe whether it dumps
core, and set a flag to tell future TAS calls whether to use the hint
bit. Ick. In any case, adding a conditional branch to the TAS code
would lose some of the performance benefit of the patch. Given that
you don't get any benefit at all until you have a large number of
cores, this would be a net loss for a lot of people.
None of those look better than an approximate proxy condition
to me.
regards, tom lane
| From: | Peter Eisentraut <peter_e(at)gmx(dot)net> |
|---|---|
| To: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2011-12-30 16:26:42 |
| Message-ID: | 1325262402.11282.3.camel@vanquo.pezone.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On fre, 2011-12-30 at 14:47 +0900, Manabu Ori wrote:
> If we can decide whether to use the hint operand when we build
> postgres, I think it's better to check if we can compile and run
> a sample code with lwarx hint operand than to refer to some
> arbitrary defines, such as FOO_PPC64 or something.
>
But you can't be sure that the host you are running this on has the same
capability as the build system. Packaging systems only classify
architectures on broad categories such as "i386" or "powerpc" or maybe
"powerpc64". So a package built for "powerpc64" has to run on all
powerpc64 hosts.
Imagine you are using some Pentium instruction and run the program on a
80486. It's the same architecture as far as kernel, package management,
etc. are concerned, but your program will break.
| From: | Andrew Dunstan <andrew(at)dunslane(dot)net> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2011-12-30 16:43:05 |
| Message-ID: | 4EFDEA19.5040201@dunslane.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 12/30/2011 11:23 AM, Tom Lane wrote:
> Manabu Ori<manabu(dot)ori(at)gmail(dot)com> writes:
>> 2011/12/30 Tom Lane<tgl(at)sss(dot)pgh(dot)pa(dot)us>
>>> The info that I've found says that the hint exists beginning in POWER6,
>>> and there were certainly 64-bit Power machines before that. However,
>>> it might be that the only machines that actually spit up on the hint bit
>>> (rather than ignore it) were 32-bit, in which case this would be a
>>> usable heuristic. Not sure how we can research that ... do we want to
>>> just assume the kernel guys know what they're doing?
>> I'm a bit confused and might miss the point, but...
>> If we can decide whether to use the hint operand when we build
>> postgres, I think it's better to check if we can compile and run
>> a sample code with lwarx hint operand than to refer to some
>> arbitrary defines, such as FOO_PPC64 or something.
> Well, there are two different conditions we have to deal with:
>
> (1) does gcc+assembler understand the hint operand for lwarx?
> This we can reasonably check with configure, since it's a property
> of the build environment.
>
> (2) does the machine where the executable will run understand the
> hint bit, or failing that at least treat it as a no-op? We cannot
> determine that at configure time, unless we can fall back on some
> approximate proxy condition like testing 64-bit vs 32-bit.
>
> (I see that the kernel boys dodged point 1 by writing the lwarx
> instruction as a numeric constant, but that seems far too ugly
> and fragile for my taste. In any case point 2 is the big issue.)
>
> If you don't like the 64-bit hack or something much like it,
> I think we have got three other alternatives:
>
> * Do nothing, ie reject the patch.
>
> * Push the problem onto the user by offering a configure option.
> I don't care for this in the least, notably because packagers
> such as Linux distros couldn't safely enable the option, so in
> practice it would be unavailable to a large fraction of users.
>
> * Perform a runtime test. I'm not sure if there's a better way,
> but if nothing else we could fork a subprocess during postmaster
> start, have it try an lwarx with hint bit, observe whether it dumps
> core, and set a flag to tell future TAS calls whether to use the hint
> bit. Ick. In any case, adding a conditional branch to the TAS code
> would lose some of the performance benefit of the patch. Given that
> you don't get any benefit at all until you have a large number of
> cores, this would be a net loss for a lot of people.
>
> None of those look better than an approximate proxy condition
> to me.
>
>
#3 in particular is unspeakably ugly.
cheers
andrew
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2011-12-31 18:39:12 |
| Message-ID: | 15103.1325356752@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I wrote:
> it might be that the only machines that actually spit up on the hint bit
> (rather than ignore it) were 32-bit, in which case this would be a
> usable heuristic. Not sure how we can research that ... do we want to
> just assume the kernel guys know what they're doing?
I did a bit of research on this. The EH hint bit for LWARX was
introduced in Power ISA 2.05 of 2007,
https://www.power.org/resources/reading/PowerISA_V2.05.pdf
which states:
Warning: On some processors that comply with versions of the
architecture that precede Version 2.00, executing a Load And Reserve
instruction in which EH = 1 will cause the illegal instruction error
handler to be invoked.
According to wikipedia and some other sites, 2.00 corresponds to POWER4
(introduced in 2001), which was *not* the first 64-bit POWER
architecture; before that there was POWER3 (used in IBM RS/6000 for a
couple of years) and PPC 620 (not commercially successful, in particular
never used by Apple). However I could not find anything definitive as
to whether those particular chips would give SIGILL for the hint bit
being set. So there may or may not be a small population of old 64-bit
PPC chips on which the hint bit would cause trouble. Certainly it
should be safe on the vast majority of currently operational PPC64
machines.
In the other direction, it's at least possible that someone would want
to build PG as 32-bit on a PPC machine that is new enough to support the
hint bit.
What I suggest we should do about this is provide an overridable option
in pg_config_manual.h, along the lines of
#if defined(__ppc64__) || defined(__powerpc64__)
#define USE_PPC_LWARX_MUTEX_HINT
#endif
and then test that symbol in s_lock.h. This will provide an escape
hatch for anyone who doesn't want the decision tied to 64-bit-ness,
while still enabling the option automatically for the majority of
people who could use it.
BTW, while reading the ISA document I couldn't help noticing that LWARX
is clearly specified to operate on 4-byte quantities (there's LDARX if
you want to use 8-byte). Which seems to mean that this bit in s_lock.h
just represents bogus waste of space:
#if defined(__ppc64__) || defined(__powerpc64__)
typedef unsigned long slock_t;
#else
typedef unsigned int slock_t;
#endif
Shouldn't we just make slock_t be "int" for both PPC and PPC64?
regards, tom lane
| From: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-01 11:37:32 |
| Message-ID: | 892AF2DE-F6DC-463B-A9D2-87FC8B748E61@gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tom, thank you for your advise.
On 2012/01/01, at 3:39, Tom Lane wrote:
> What I suggest we should do about this is provide an overridable option
> in pg_config_manual.h, along the lines of
>
> #if defined(__ppc64__) || defined(__powerpc64__)
> #define USE_PPC_LWARX_MUTEX_HINT
> #endif
>
> and then test that symbol in s_lock.h. This will provide an escape
> hatch for anyone who doesn't want the decision tied to 64-bit-ness,
> while still enabling the option automatically for the majority of
> people who could use it.
Fair enough.
I recreated the patch as you advised.
| Attachment | Content-Type | Size |
|---|---|---|
| ppc-TAS_SPIN-20120101.diff | application/octet-stream | 1.6 KB |
| unknown_filename | text/plain | 702 bytes |
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-02 05:03:54 |
| Message-ID: | 29367.1325480634@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Manabu Ori <manabu(dot)ori(at)gmail(dot)com> writes:
> I recreated the patch as you advised.
Hmm, guess I wasn't clear --- we still need a configure test, since even
if we are on PPC64 there's no guarantee that the assembler will accept
the hint bit.
I revised the patch to include a configure test and committed it.
However, I omitted the part that added an unlocked test in TAS_SPIN,
because (1) that's logically a separate change, and (2) in my testing
the unlocked test produces a small but undeniable performance loss
(see numbers below). We need to investigate a bit more to understand
why I'm getting results different from yours. If the bottom line is
that the unlocked test loses for smaller numbers of processors and only
helps with lots of them, I have to question whether it's a good idea to
apply it.
>> Shouldn't we just make slock_t be "int" for both PPC and PPC64?
> I'd like it to be untouched for this TAS_SPIN for powerpc
> discussion, since it seems it remainds like this for several
> years and maybe it needs some more careful consideration
I ran a test and could not see any consistent performance difference
between 4-byte and 8-byte slock_t, so I've committed that change too.
Obviously that can be revisited if anyone comes up with evidence in
the other direction.
While I was looking at this, I noticed that PPC ISA 2.03 and later
recommend use of "lwsync" rather than "isync" and "sync" in lock
acquisition and release, and sure enough I can measure improvement
from making that change too. So again the problem is to know whether
it's safe to use that instruction. Googling shows that there's at
least one current 32-bit PPC chip that gives SIGILL (Freescale's
E500 ... thanks for nothing, Freescale ...); but at least some projects
are using 64-bitness as a proxy test for whether it's safe to use
lwsync. So for the moment I've also committed a patch that switches
to using lwsync on PPC64. We can perhaps improve on that too, but
it's got basically the same issues as the hint bit with respect to
how to know at compile time whether the instruction is safe at run time.
I would be interested to see results from your 750 Express machine
as to the performance impact of each of these successive patches,
and then perhaps the TAS_SPIN change on top of that.
While working on this, I repeated the tests I did in
http://archives.postgresql.org/message-id/8292.1314641721@sss.pgh.pa.us
With current git head, I get:
pgbench -c 1 -j 1 -S -T 300 bench tps = 8703.264346 (including connections establishing)
pgbench -c 2 -j 1 -S -T 300 bench tps = 12207.827348 (including connections establishing)
pgbench -c 8 -j 4 -S -T 300 bench tps = 48593.999965 (including connections establishing)
pgbench -c 16 -j 8 -S -T 300 bench tps = 91155.555180 (including connections establishing)
pgbench -c 32 -j 16 -S -T 300 bench tps = 124648.093971 (including connections establishing)
pgbench -c 64 -j 32 -S -T 300 bench tps = 129488.449355 (including connections establishing)
pgbench -c 96 -j 48 -S -T 300 bench tps = 124958.553086 (including connections establishing)
pgbench -c 128 -j 64 -S -T 300 bench tps = 134195.370726 (including connections establishing)
(It's depressing that these numbers have hardly moved since August ---
at least on this test, the work that Robert's done has not made any
difference.) These numbers are repeatable in the first couple of
digits, but there's some noise in the third digit.
With your patch (hint bit and TAS_SPIN change) I get:
pgbench -c 1 -j 1 -S -T 300 bench tps = 8751.930270 (including connections establishing)
pgbench -c 2 -j 1 -S -T 300 bench tps = 12211.160964 (including connections establishing)
pgbench -c 8 -j 4 -S -T 300 bench tps = 48608.877131 (including connections establishing)
pgbench -c 16 -j 8 -S -T 300 bench tps = 90827.234014 (including connections establishing)
pgbench -c 32 -j 16 -S -T 300 bench tps = 123267.062954 (including connections establishing)
pgbench -c 64 -j 32 -S -T 300 bench tps = 128951.585059 (including connections establishing)
pgbench -c 96 -j 48 -S -T 300 bench tps = 126551.870909 (including connections establishing)
pgbench -c 128 -j 64 -S -T 300 bench tps = 133311.793735 (including connections establishing)
With the TAS_SPIN change only, no hint bit:
pgbench -c 1 -j 1 -S -T 300 bench tps = 8764.703599 (including connections establishing)
pgbench -c 2 -j 1 -S -T 300 bench tps = 12163.321040 (including connections establishing)
pgbench -c 8 -j 4 -S -T 300 bench tps = 48580.673497 (including connections establishing)
pgbench -c 16 -j 8 -S -T 300 bench tps = 90672.227488 (including connections establishing)
pgbench -c 32 -j 16 -S -T 300 bench tps = 121604.634146 (including connections establishing)
pgbench -c 64 -j 32 -S -T 300 bench tps = 129088.387379 (including connections establishing)
pgbench -c 96 -j 48 -S -T 300 bench tps = 126291.854733 (including connections establishing)
pgbench -c 128 -j 64 -S -T 300 bench tps = 133386.394587 (including connections establishing)
With the hint bit only:
pgbench -c 1 -j 1 -S -T 300 bench tps = 8737.175661 (including connections establishing)
pgbench -c 2 -j 1 -S -T 300 bench tps = 12208.715035 (including connections establishing)
pgbench -c 8 -j 4 -S -T 300 bench tps = 48655.181597 (including connections establishing)
pgbench -c 16 -j 8 -S -T 300 bench tps = 91365.152223 (including connections establishing)
pgbench -c 32 -j 16 -S -T 300 bench tps = 124867.442389 (including connections establishing)
pgbench -c 64 -j 32 -S -T 300 bench tps = 129795.644368 (including connections establishing)
pgbench -c 96 -j 48 -S -T 300 bench tps = 126515.035998 (including connections establishing)
pgbench -c 128 -j 64 -S -T 300 bench tps = 134551.825202 (including connections establishing)
So it looks to me like the TAS_SPIN change is a loser either by itself
or with the hint bit.
I then tried substituting LWSYNC for SYNC in S_UNLOCK(lock):
pgbench -c 1 -j 1 -S -T 300 bench tps = 8807.059517 (including connections establishing)
pgbench -c 2 -j 1 -S -T 300 bench tps = 12204.028897 (including connections establishing)
pgbench -c 8 -j 4 -S -T 300 bench tps = 49051.003729 (including connections establishing)
pgbench -c 16 -j 8 -S -T 300 bench tps = 91904.111604 (including connections establishing)
pgbench -c 32 -j 16 -S -T 300 bench tps = 125049.367820 (including connections establishing)
pgbench -c 64 -j 32 -S -T 300 bench tps = 130259.490608 (including connections establishing)
pgbench -c 96 -j 48 -S -T 300 bench tps = 125581.037607 (including connections establishing)
pgbench -c 128 -j 64 -S -T 300 bench tps = 135143.761032 (including connections establishing)
and finally LWSYNC for both SYNC and ISYNC:
pgbench -c 1 -j 1 -S -T 300 bench tps = 8865.769698 (including connections establishing)
pgbench -c 2 -j 1 -S -T 300 bench tps = 12278.078258 (including connections establishing)
pgbench -c 8 -j 4 -S -T 300 bench tps = 49172.415634 (including connections establishing)
pgbench -c 16 -j 8 -S -T 300 bench tps = 92229.289211 (including connections establishing)
pgbench -c 32 -j 16 -S -T 300 bench tps = 125466.790383 (including connections establishing)
pgbench -c 64 -j 32 -S -T 300 bench tps = 129422.631959 (including connections establishing)
pgbench -c 96 -j 48 -S -T 300 bench tps = 124240.447533 (including connections establishing)
pgbench -c 128 -j 64 -S -T 300 bench tps = 133892.054917 (including connections establishing)
That last is clearly a winner for reasonable numbers of processes,
so I committed it that way, but I'm a little worried by the fact that it
looks like it might be a marginal loss when the system is overloaded.
I would like to see results from your machine.
regards, tom lane
| From: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-02 16:44:59 |
| Message-ID: | CADWW1HEK5ZvsJOk6BBYQH1Ts5=5yFz+LD6hQh8irH54COY5=CA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2012/1/2 Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>
> I revised the patch to include a configure test and committed it.
Thank you very much for committing the patch.
> However, I omitted the part that added an unlocked test in TAS_SPIN,
> because (1) that's logically a separate change, and (2) in my testing
> the unlocked test produces a small but undeniable performance loss
> (see numbers below). We need to investigate a bit more to understand
> why I'm getting results different from yours.
I ran pgbench again on git head, comparing with and without the
TAS_SPIN unlocked test, and got clearly better performance with
the unlocked test. In your test the unlocked test loss a bit for
sure, but the delta from git head is not so big. On the other
hand, in my test the unlockted test showed significant
win (please find numbers below and attached png file).
With current git head:
(Note that Power750 generates executables with hint bit from
current git head.)
pgbench -c 1 -j 1 -S -T 300 tps = 11436.679064 (including ...
pgbench -c 2 -j 1 -S -T 300 tps = 21922.031158 (including ...
pgbench -c 4 -j 2 -S -T 300 tps = 41801.573397 (including ...
pgbench -c 8 -j 4 -S -T 300 tps = 76581.573285 (including ...
pgbench -c 16 -j 8 -S -T 300 tps = 154154.380180 (including ...
pgbench -c 32 -j 16 -S -T 300 tps = 280654.751280 (including ...
pgbench -c 64 -j 32 -S -T 300 tps = 263800.861178 (including ...
pgbench -c 96 -j 48 -S -T 300 tps = 212199.887237 (including ...
pgbench -c 128 -j 64 -S -T 300 tps = 170627.652759 (including ...
With current git head with TAS_SPIN patch:
(executables have hint bit and TAS_SPIN change)
pgbench -c 1 -j 1 -S -T 300 tps = 11323.652326 (including ...
pgbench -c 2 -j 1 -S -T 300 tps = 22123.674189 (including ...
pgbench -c 4 -j 2 -S -T 300 tps = 43616.374433 (including ...
pgbench -c 8 -j 4 -S -T 300 tps = 86350.153176 (including ...
pgbench -c 16 -j 8 -S -T 300 tps = 166122.891575 (including ...
pgbench -c 32 -j 16 -S -T 300 tps = 269379.747507 (including ...
pgbench -c 64 -j 32 -S -T 300 tps = 361657.417319 (including ...
pgbench -c 96 -j 48 -S -T 300 tps = 333483.557846 (including ...
pgbench -c 128 -j 64 -S -T 300 tps = 299554.099510 (including ...
I'm running another cases includes LWARX stuff etc and send the
results later.
> If the bottom line is
> that the unlocked test loses for smaller numbers of processors and only
> helps with lots of them, I have to question whether it's a good idea to
> apply it.
So such is the case with my result.
I don't have a clear answer to your question but how about adding
a tunable in postgresql.conf named "tas_spin_with_unlocked_test"
so that we can use the unlocked test in TAS_SPIN explicitly on
larger SMP systems?
Regards,
Manabu Ori
| Attachment | Content-Type | Size |
|---|---|---|
| pgbench-Power750-20120102.png | image/png | 96.5 KB |
{kind=link}
| From: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-02 17:10:31 |
| Message-ID: | CADWW1HGMPf2+21JkU7AXcXEYhY8ASZW8E=B1JwPnRb5-5MzJSg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
By the way...
2012/1/2 Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>
> (It's depressing that these numbers have hardly moved since August ---
> at least on this test, the work that Robert's done has not made any
> difference.)
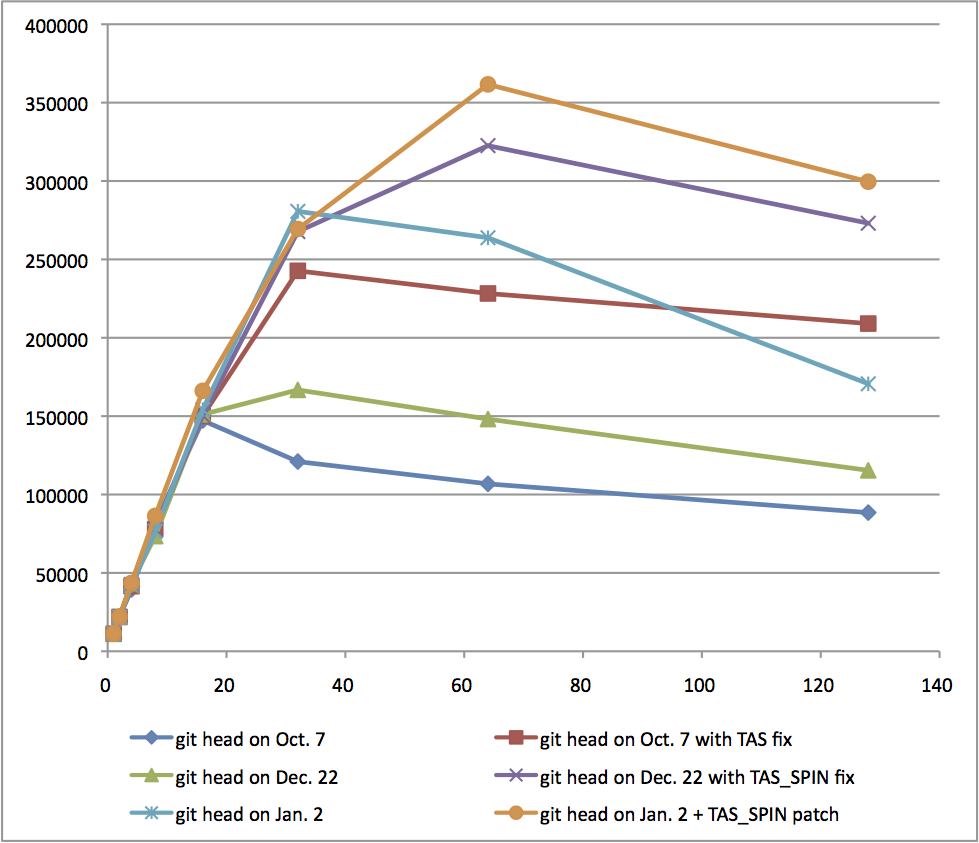
I merged some results and created another graph.
Please find an attached png file and you'll see obvious
performance improvement...
All the results are run on the same system:
Power 750 (32 physical cores, virtually 128 cores using SMT4)
mem: 256GB
OS: RHEL6.1 kernel 2.6.32-131.0.15.el6.ppc64
gcc version 4.4.5 20110214 (Red Hat 4.4.5-6)
| Attachment | Content-Type | Size |
|---|---|---|
| pgbench-Power750-20120102-2.png | image/png | 121.8 KB |
{kind=link}
| From: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, robertmhaas(at)gmail(dot)com, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-02 23:59:15 |
| Message-ID: | CADWW1HGzHTBLJ2Hnwmywn5T3TLTwHpPivWpQkaYOKxrFW+rLRw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2012/1/3 Manabu Ori <manabu(dot)ori(at)gmail(dot)com>
> With current git head:
> (Note that Power750 generates executables with hint bit from
> current git head.)
>
> pgbench -c 1 -j 1 -S -T 300 tps = 11436.679064 (including ...
> pgbench -c 2 -j 1 -S -T 300 tps = 21922.031158 (including ...
> pgbench -c 4 -j 2 -S -T 300 tps = 41801.573397 (including ...
> pgbench -c 8 -j 4 -S -T 300 tps = 76581.573285 (including ...
> pgbench -c 16 -j 8 -S -T 300 tps = 154154.380180 (including ...
> pgbench -c 32 -j 16 -S -T 300 tps = 280654.751280 (including ...
> pgbench -c 64 -j 32 -S -T 300 tps = 263800.861178 (including ...
> pgbench -c 96 -j 48 -S -T 300 tps = 212199.887237 (including ...
> pgbench -c 128 -j 64 -S -T 300 tps = 170627.652759 (including ...
>
> With current git head with TAS_SPIN patch:
> (executables have hint bit and TAS_SPIN change)
>
> pgbench -c 1 -j 1 -S -T 300 tps = 11323.652326 (including ...
> pgbench -c 2 -j 1 -S -T 300 tps = 22123.674189 (including ...
> pgbench -c 4 -j 2 -S -T 300 tps = 43616.374433 (including ...
> pgbench -c 8 -j 4 -S -T 300 tps = 86350.153176 (including ...
> pgbench -c 16 -j 8 -S -T 300 tps = 166122.891575 (including ...
> pgbench -c 32 -j 16 -S -T 300 tps = 269379.747507 (including ...
> pgbench -c 64 -j 32 -S -T 300 tps = 361657.417319 (including ...
> pgbench -c 96 -j 48 -S -T 300 tps = 333483.557846 (including ...
> pgbench -c 128 -j 64 -S -T 300 tps = 299554.099510 (including ...
>
> I'm running another cases includes LWARX stuff etc and send the
> results later.
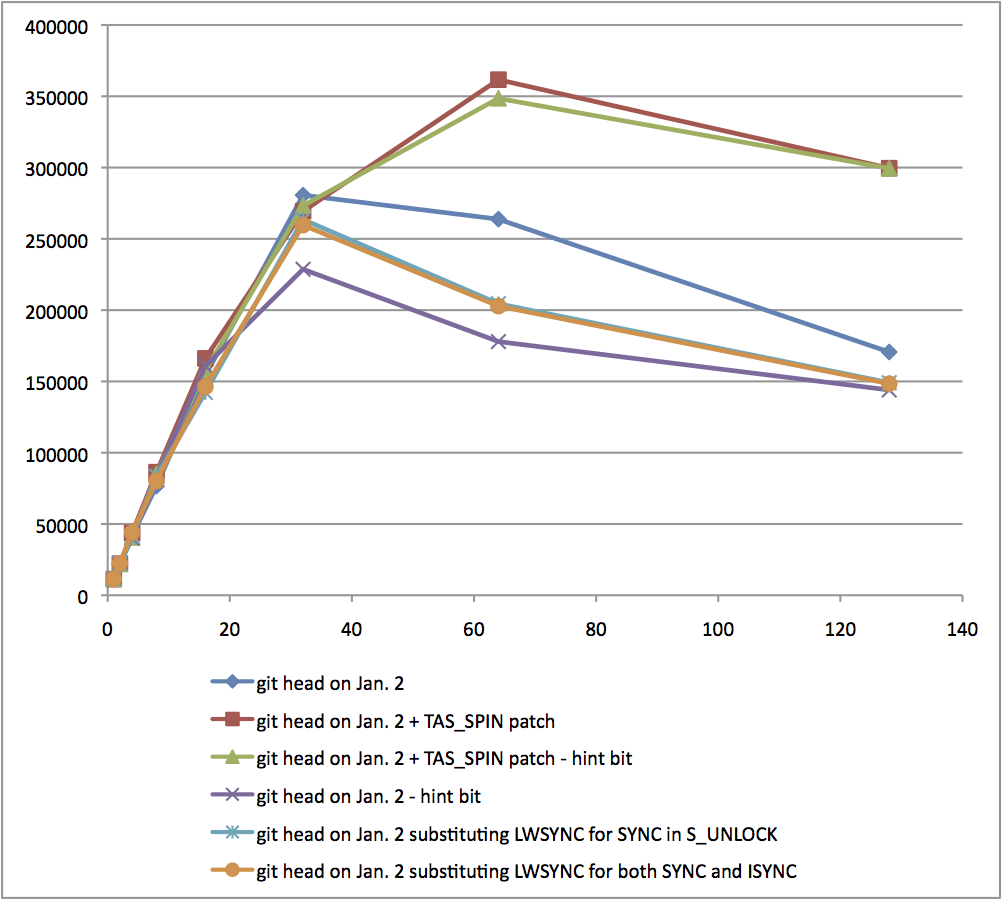
I got additional results.
I've been using current git head of commit 631beeac35 in all the
tests, so that git head already have hint bit in LWARX and
SYNC/ISYNC are replaced with LWSYNC.
Note that in my graph legend "+ TAS_SPIN path" means including
TAS_SPIN patch and "- hint bit" means undefining
USE_PPC_LWARX_MUTEX_HINT.
With current git head without hint bit and with TAS_SPIN patch:
(executables have only TAS_SPIN change)
pgbench -c 1 -j 1 -S -T 300 tps = 11516.896929 (including ...
pgbench -c 2 -j 1 -S -T 300 tps = 21992.169336 (including ...
pgbench -c 4 -j 2 -S -T 300 tps = 40533.578654 (including ...
pgbench -c 8 -j 4 -S -T 300 tps = 84993.346937 (including ...
pgbench -c 16 -j 8 -S -T 300 tps = 157629.680382 (including ...
pgbench -c 32 -j 16 -S -T 300 tps = 273234.960592 (including ...
pgbench -c 64 -j 32 -S -T 300 tps = 348557.006484 (including ...
pgbench -c 96 -j 48 -S -T 300 tps = 326664.510722 (including ...
pgbench -c 128 -j 64 -S -T 300 tps = 299446.708323 (including ...
With current git head without hint bit:
(executables have neither hint bit nor TAS_SPIN change)
pgbench -c 1 -j 1 -S -T 300 tps = 11531.003861 (including ...
pgbench -c 2 -j 1 -S -T 300 tps = 22510.372046 (including ...
pgbench -c 4 -j 2 -S -T 300 tps = 40116.804994 (including ...
pgbench -c 8 -j 4 -S -T 300 tps = 83516.160169 (including ...
pgbench -c 16 -j 8 -S -T 300 tps = 160835.396856 (including ...
pgbench -c 32 -j 16 -S -T 300 tps = 228697.183575 (including ...
pgbench -c 64 -j 32 -S -T 300 tps = 177939.580160 (including ...
pgbench -c 96 -j 48 -S -T 300 tps = 160282.234748 (including ...
pgbench -c 128 -j 64 -S -T 300 tps = 143993.382895 (including ...
We can see LWARX hint bit and TAS_SPIN patch have meaningful
benefit on Power750, and having both get best performance.
Substituing LWSYNC for SYNC in S_UNLOCK:
(executables have hint bit)
pgbench -c 1 -j 1 -S -T 300 tps = 11387.633820 (including ...
pgbench -c 2 -j 1 -S -T 300 tps = 22270.036504 (including ...
pgbench -c 4 -j 2 -S -T 300 tps = 41268.705101 (including ...
pgbench -c 8 -j 4 -S -T 300 tps = 83487.940761 (including ...
pgbench -c 16 -j 8 -S -T 300 tps = 142243.077283 (including ...
pgbench -c 32 -j 16 -S -T 300 tps = 263584.870238 (including ...
pgbench -c 64 -j 32 -S -T 300 tps = 204520.685955 (including ...
pgbench -c 96 -j 48 -S -T 300 tps = 174361.369468 (including ...
pgbench -c 128 -j 64 -S -T 300 tps = 149120.192708 (including ...
Substituing LWSYNC for both SYNC and ISYNC:
(executables have hint bit)
pgbench -c 1 -j 1 -S -T 300 tps = 11470.622346 (including ...
pgbench -c 2 -j 1 -S -T 300 tps = 22403.955716 (including ...
pgbench -c 4 -j 2 -S -T 300 tps = 43919.047680 (including ...
pgbench -c 8 -j 4 -S -T 300 tps = 80186.836149 (including ...
pgbench -c 16 -j 8 -S -T 300 tps = 146265.129834 (including ...
pgbench -c 32 -j 16 -S -T 300 tps = 259638.888656 (including ...
pgbench -c 64 -j 32 -S -T 300 tps = 202791.211830 (including ...
pgbench -c 96 -j 48 -S -T 300 tps = 173524.291680 (including ...
pgbench -c 128 -j 64 -S -T 300 tps = 148385.991706 (including ...
In my test, replacing both SYNC and ISYNC with LWSYNC is
effective even when tye system is overloaded.
Test environment:
Power 750 (32 physical cores, virtually 128 cores using SMT4)
mem: 256GB
OS: RHEL6.1 kernel 2.6.32-131.0.15.el6.ppc64
gcc version 4.4.5 20110214 (Red Hat 4.4.5-6)
PostgreSQL git head (631beeac3598a73dee2c2afa38fa2e734148031b)
Regards,
Manabu Ori
| Attachment | Content-Type | Size |
|---|---|---|
| pgbench-Power750-20120102-3.png | image/png | 135.8 KB |
{kind=link}
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-03 04:44:49 |
| Message-ID: | CA+TgmoaO-L9rABu9y43=4zrNTtbyVCzmkUcZBc1hiP-Esc08NQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jan 2, 2012 at 12:03 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> (It's depressing that these numbers have hardly moved since August ---
> at least on this test, the work that Robert's done has not made any
> difference.)
Most of the scalability work that's been committed since August has
really been about ProcArrayLock, which does have an impact on read
scalability, but is a much more serious problem on write workloads.
On read-only workloads, you get spinlock contention, because everyone
who wants a snapshot has to take the LWLock mutex to increment the
shared lock count and again (just a moment later) to decrement it.
But on write workloads, transactions must take need ProcArrayLock in
exclusive mode to commit, so you have the additional problem of
snapshot-taking forcing committers to wait and (probably to a lesser
degree) visca versa. Most of the benefit we've gotten so far has come
from shortening the time for which ProcArrayLock is held in shared
mode while taking snapshots, which is going to primarily benefit write
workloads. I'm a bit surprised that you haven't seen any benefit at
all on read workloads - I would have expected a small but measurable
gain - but I'm not totally shocked if there isn't one.
The architecture may play into it, too. Most of the testing that I
have done has been on AMD64 or Itanium, and those have significantly
different performance characteristics. The Itanium machine I've used
for testing is faster in absolute terms than the AMD64 box, but it
seems to also suffer more severely in the presence of spinlock
contention. This means that, on current sources, ProcArrayLock is a
bigger problem on Itanium than it is on AMD64. I don't have a PPC64
box to play with ATM, so I can't speculate on what the situation is
there. It's occurred to me to wonder whether the Itanium vs. AMD64
effects are specific to those architectures or general characteristics
of strong memory ordering architectures vs. weak memory architectures,
but I don't really have enough data to know. I'm concerned by this
whole issue of spinlocks, since the previous round of testing on
Itanium pretty much proves that getting the spinlock implementation
wrong is a death sentence. If PPC64 is going to require specific
tweaks for every subarchitecture, that's going to be a colossal
nuisance, but probably a necessary one if we don't want to suck there.
For Itanium, I was able to find some fairly official-looking
documentation that said "this is how you should do it". It would be
nice to find something similar for PPC64, instead of testing every
machine and reinventing the wheel ourselves. I wonder whether the gcc
folks have done any meaningful thinking about this in their builtin
atomics; if so, that might be an argument for using that as more than
just a fallback. If not, it's a pretty good argument against it, at
least IMHO.
All that having been said...
> That last is clearly a winner for reasonable numbers of processes,
> so I committed it that way, but I'm a little worried by the fact that it
> looks like it might be a marginal loss when the system is overloaded.
> I would like to see results from your machine.
I'm unconvinced by these numbers. There is a measurable change but it
is pretty small. The Itanium changes resulted in an enormous gain at
higher concurrency levels. I've seen several cases where improving
one part of the code actually makes performance worse, because of
things like: once lock A is less contented, lock B becomes more
contended, and for some reason the effect on lock B is greater than
the effect on lock A. It was precisely this sort of effect that lead
to the sinval optimizations commited as
b4fbe392f8ff6ff1a66b488eb7197eef9e1770a4; the lock manager
optimizations improved things with moderate numbers of processes but
were much worse at high numbers of processes precisely because the
lock manager (which is partitioned) wasn't there to throttle the
beating on SInvalReadLock *which isn't). I'd be inclined to say we
should optimize for architectures where either of both of these
techniques make the sort of big splash Manabu Ori is seeing on his
machine, and assume that the much smaller changes you're seeing on
your machines are as likely to be artifacts as real effects. When and
if enough evidence emerges to say otherwise, we can decide whether to
rethink.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Jeremy Harris <jgh(at)wizmail(dot)org> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-03 20:05:33 |
| Message-ID: | 4F035F8D.6050709@wizmail.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2012-01-03 04:44, Robert Haas wrote:
> On read-only workloads, you get spinlock contention, because everyone
> who wants a snapshot has to take the LWLock mutex to increment the
> shared lock count and again (just a moment later) to decrement it.
Does the LWLock protect anything but the shared lock count? If not
then the usually quickest manipulation is along the lines of:
loop: lwarx r5,0,r3 #load and reserve
add r0,r4,r5 #increment word
stwcx. r0,0,r3 #store new value if still reserved
bne- loop #loop if lost reservation
(per IBM's software ref manual,
https://www-01.ibm.com/chips/techlib/techlib.nsf/techdocs/852569B20050FF778525699600719DF2
)
The same sort of thing generally holds on other instruction-sets also.
Also, heavy-contention locks should be placed in cache lines away from other
data (to avoid thrashing the data cache lines when processors are fighting
over the lock cache lines).
--
Jeremy
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Jeremy Harris <jgh(at)wizmail(dot)org> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-03 20:18:41 |
| Message-ID: | CA+TgmoYJhfyRR28ASt-FgB7ubDrdWmZ+m722XcDYdv4mEwUEBQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jan 3, 2012 at 3:05 PM, Jeremy Harris <jgh(at)wizmail(dot)org> wrote:
> On 2012-01-03 04:44, Robert Haas wrote:
>> On read-only workloads, you get spinlock contention, because everyone
>> who wants a snapshot has to take the LWLock mutex to increment the
>> shared lock count and again (just a moment later) to decrement it.
>
> Does the LWLock protect anything but the shared lock count? If not
> then the usually quickest manipulation is along the lines of:
>
> loop: lwarx r5,0,r3 #load and reserve
> add r0,r4,r5 #increment word
> stwcx. r0,0,r3 #store new value if still reserved
> bne- loop #loop if lost reservation
>
> (per IBM's software ref manual,
> https://www-01.ibm.com/chips/techlib/techlib.nsf/techdocs/852569B20050FF778525699600719DF2
> )
>
> The same sort of thing generally holds on other instruction-sets also.
Sure, but the actual critical section is not that simple. You might
look at the code for LWLockAcquire() if you're curious.
> Also, heavy-contention locks should be placed in cache lines away from other
> data (to avoid thrashing the data cache lines when processors are fighting
> over the lock cache lines).
Yep. This is possibly a problem, and has been discussed before, but I
don't think we have any firm evidence that it's a problem, or how much
padding helps. The heavily contended LWLocks are mostly
non-consecutive, except perhaps for the buffer mapping locks.
It's been suggested to me that we should replace our existing LWLock
implementation with a CAS-based implementation that crams all the
relevant details into a single 8-byte word. The pointer to the head
of the wait queue, for example, could be stored as an offset into the
allProcs array rather than a pointer value, which would allow it to be
stored in 24 bits rather than 8 bytes. But there's not quite enough
bit space to make it work without making compromises -- most likely,
reducing the theoretical upper limit on MaxBackends from 2^24 to, say,
2^22. Even if we were willing to do that, the performance benefits of
using atomics here are so far unproven... which doesn't mean they
don't exist, but someone's going to have to do some work to show that
they do.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Jeremy Harris <jgh(at)wizmail(dot)org>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-03 20:48:58 |
| Message-ID: | 25841.1325623738@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> On Tue, Jan 3, 2012 at 3:05 PM, Jeremy Harris <jgh(at)wizmail(dot)org> wrote:
>> Also, heavy-contention locks should be placed in cache lines away from other
>> data (to avoid thrashing the data cache lines when processors are fighting
>> over the lock cache lines).
> Yep. This is possibly a problem, and has been discussed before, but I
> don't think we have any firm evidence that it's a problem, or how much
> padding helps. The heavily contended LWLocks are mostly
> non-consecutive, except perhaps for the buffer mapping locks.
We are in fact already padding and aligning LWLocks on (if memory
serves) 16 or 32 byte boundaries depending on platform. So there
might be 2 to 4 LWLocks in the same cache line, depending on platform.
It's been suggested before that we pad more to reduce this number,
but nobody's demonstrated any performance win from doing so.
> It's been suggested to me that we should replace our existing LWLock
> implementation with a CAS-based implementation that crams all the
> relevant details into a single 8-byte word.
I'm under the impression that the main costs are associated with trading
cache line ownership between CPUs, which makes me think that this'd be
essentially a waste of effort, quite aside from the portability problems
involved.
regards, tom lane
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-03 21:17:16 |
| Message-ID: | 26496.1325625436@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Robert Haas <robertmhaas(at)gmail(dot)com> writes:
> I'm unconvinced by these numbers. There is a measurable change but it
> is pretty small. The Itanium changes resulted in an enormous gain at
> higher concurrency levels.
Yeah, that was my problem with it also: I couldn't measure enough gain
to convince me it was a real effect, and not an artifact of the specific
machine being tested. It occurred to me though that we already know that
pgbench itself is a bottleneck in tests like this, and there's an easy
way to take it out of the picture: move the selects into a plpgsql
function that iterates multiple times per client query. The attached
testing script reduces the client interaction costs by a thousandfold
compared to plain "pgbench -S", and also takes parse/plan time out of
the loop, so that it becomes easier to see the effects of contention.
With this script, I still see a loss of 1% or so from adding the
unlocked test in TAS_SPIN at moderate contention levels, but there's a
very clear jump when the machine is saturated. So this convinces me
that Manabu-san's results are reproducible, and I've committed the
TAS_SPIN addition.
git head as of this morning, on 8-core IBM 8406-71Y:
pgbench -c 1 -j 1 -f bench.script -T 300 bench tps = 50.142878 (including connections establishing)
pgbench -c 2 -j 1 -f bench.script -T 300 bench tps = 97.179234 (including connections establishing)
pgbench -c 8 -j 4 -f bench.script -T 300 bench tps = 341.731982 (including connections establishing)
pgbench -c 16 -j 8 -f bench.script -T 300 bench tps = 402.114111 (including connections establishing)
pgbench -c 32 -j 16 -f bench.script -T 300 bench tps = 371.338156 (including connections establishing)
pgbench -c 64 -j 32 -f bench.script -T 300 bench tps = 359.785087 (including connections establishing)
pgbench -c 96 -j 48 -f bench.script -T 300 bench tps = 363.879950 (including connections establishing)
pgbench -c 128 -j 64 -f bench.script -T 300 bench tps = 376.794934 (including connections establishing)
after re-adding TAS_SPIN macro:
pgbench -c 1 -j 1 -f bench.script -T 300 bench tps = 50.182676 (including connections establishing)
pgbench -c 2 -j 1 -f bench.script -T 300 bench tps = 96.751910 (including connections establishing)
pgbench -c 8 -j 4 -f bench.script -T 300 bench tps = 327.108510 (including connections establishing)
pgbench -c 16 -j 8 -f bench.script -T 300 bench tps = 395.425611 (including connections establishing)
pgbench -c 32 -j 16 -f bench.script -T 300 bench tps = 444.291852 (including connections establishing)
pgbench -c 64 -j 32 -f bench.script -T 300 bench tps = 486.151168 (including connections establishing)
pgbench -c 96 -j 48 -f bench.script -T 300 bench tps = 496.379981 (including connections establishing)
pgbench -c 128 -j 64 -f bench.script -T 300 bench tps = 494.058124 (including connections establishing)
> For Itanium, I was able to find some fairly official-looking
> documentation that said "this is how you should do it". It would be
> nice to find something similar for PPC64, instead of testing every
> machine and reinventing the wheel ourselves.
You are aware that our spinlock code is pretty much verbatim from the
PPC ISA spec, no? The issue here is that the "official documentation"
has been a moving target over the decades the ISA has been in existence.
regards, tom lane
| Attachment | Content-Type | Size |
|---|---|---|
| benchmark.sh | text/x-patch | 1.4 KB |
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-03 22:21:36 |
| Message-ID: | CA+TgmoYAw+VN_XKGFO6qCJg-5TxK5u0nrtsGDr=kzB3DO1Co_w@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jan 3, 2012 at 4:17 PM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> For Itanium, I was able to find some fairly official-looking
>> documentation that said "this is how you should do it". It would be
>> nice to find something similar for PPC64, instead of testing every
>> machine and reinventing the wheel ourselves.
>
> You are aware that our spinlock code is pretty much verbatim from the
> PPC ISA spec, no? The issue here is that the "official documentation"
> has been a moving target over the decades the ISA has been in existence.
I wasn't aware of that, but I think my basic point still stands: it's
gonna be painful if we have to test large numbers of different PPC
boxes to figure all this out...
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Manabu Ori <manabu(dot)ori(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Tatsuo Ishii <ishii(at)postgresql(dot)org>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: spinlocks on powerpc |
| Date: | 2012-01-05 12:40:56 |
| Message-ID: | CADWW1HHGYC+FCj5o+np2818uQHsjJb7r2=MWK0db1WM4M912vg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2012/1/4 Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>
> I've committed the TAS_SPIN addition.
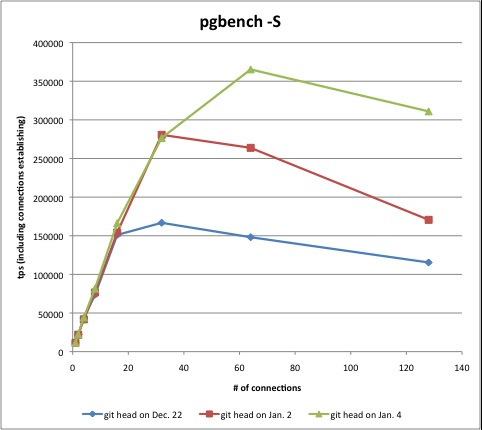
Tom, thank you for committing the fix.
I confirmed it's effective with git head on Power750 just in case, see
attached graph.
I hope PPC guys will be happier thanks to these commits.
Regards,
Manabu Ori
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 69.6 KB |