PATCH: Split stats file per database WAS: autovacuum stress-testing our system
| Lists: | pgsql-hackers |
|---|
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | autovacuum stress-testing our system |
| Date: | 2012-09-26 12:43:30 |
| Message-ID: | 1718942738eb65c8407fcd864883f4c8@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
I've been struggling with autovacuum generating a lot of I/O and CPU on
some of our
systems - after a night spent analyzing this behavior, I believe the
current
autovacuum accidentally behaves a bit like a stress-test in some corner
cases (but
I may be seriously wrong, after all it was a long night).
First - our system really is not a "common" one - we do have ~1000 of
databases of
various size, each containing up to several thousands of tables
(several user-defined
tables, the rest serve as caches for a reporting application - yes,
it's a bit weird
design but that's life). This all leads to pgstat.stat significantly
larger than 60 MB.
Now, the two main pieces of information from the pgstat.c are the timer
definitions
---------------------------------- pgstat.c : 80
----------------------------------
#define PGSTAT_STAT_INTERVAL 500 /* Minimum time between stats
file
* updates; in milliseconds. */
#define PGSTAT_RETRY_DELAY 10 /* How long to wait between
checks for
* a new file; in milliseconds.
*/
#define PGSTAT_MAX_WAIT_TIME 10000 /* Maximum time to wait for a
stats
* file update; in milliseconds.
*/
#define PGSTAT_INQ_INTERVAL 640 /* How often to ping the
collector for
* a new file; in milliseconds.
*/
#define PGSTAT_RESTART_INTERVAL 60 /* How often to attempt to
restart a
* failed statistics collector;
in
* seconds. */
#define PGSTAT_POLL_LOOP_COUNT (PGSTAT_MAX_WAIT_TIME /
PGSTAT_RETRY_DELAY)
#define PGSTAT_INQ_LOOP_COUNT (PGSTAT_INQ_INTERVAL /
PGSTAT_RETRY_DELAY)
-----------------------------------------------------------------------------------
and then this loop (the current HEAD does this a bit differently, but
the 9.2 code
is a bit readable and suffers the same issue):
---------------------------------- pgstat.c : 3560
--------------------------------
/*
* Loop until fresh enough stats file is available or we ran out of
time.
* The stats inquiry message is sent repeatedly in case collector
drops
* it; but not every single time, as that just swamps the collector.
*/
for (count = 0; count < PGSTAT_POLL_LOOP_COUNT; count++)
{
TimestampTz file_ts = 0;
CHECK_FOR_INTERRUPTS();
if (pgstat_read_statsfile_timestamp(false, &file_ts) &&
file_ts >= min_ts)
break;
/* Not there or too old, so kick the collector and wait a bit */
if ((count % PGSTAT_INQ_LOOP_COUNT) == 0)
pgstat_send_inquiry(min_ts);
pg_usleep(PGSTAT_RETRY_DELAY * 1000L);
}
if (count >= PGSTAT_POLL_LOOP_COUNT)
elog(WARNING, "pgstat wait timeout");
/* Autovacuum launcher wants stats about all databases */
if (IsAutoVacuumLauncherProcess())
pgStatDBHash = pgstat_read_statsfile(InvalidOid, false);
else
pgStatDBHash = pgstat_read_statsfile(MyDatabaseId, false);
-----------------------------------------------------------------------------------
What this code does it that it checks the statfile, and if it's not
stale (the
timestamp of the write start is not older than PGSTAT_RETRY_DELAY
milliseconds),
the loop is terminated and the file is read.
Now, let's suppose the write takes >10 ms, which is the
PGSTAT_RETRY_DELAY values.
With our current pgstat.stat filesize/num of relations, this is quite
common.
Actually the common write time in our case is ~100 ms, even if we move
the file
into tmpfs. That means that almost all the calls to
backend_read_statsfile (which
happen in all pgstat_fetch_stat_*entry calls) result in continuous
stream of
inquiries from the autovacuum workers, writing/reading of the file.
We're not getting 'pgstat wait timeout' though, because it finally gets
written
before PGSTAT_MAX_WAIT_TIME.
By moving the file to a tmpfs we've minimized the I/O impact, but now
the collector
and autovacuum launcher consume ~75% of CPU (i.e. ~ one core) and do
nothing except
burning power because the database is almost read-only. Not a good
thing in the
"green computing" era I guess.
First, I'm interested in feedback - did I get all the details right, or
am I
missing something important?
Next, I'm thinking about ways to solve this:
1) turning of autovacuum, doing regular VACUUM ANALYZE from cron -
certainly an
option, but it's rather a workaround than a solution and I'm not
very fond of
it. Moreover it fixes only one side of the problem - triggering the
statfile
writes over and over. The file will be written anyway, although not
that
frequently.
2) tweaking the timer values, especially increasing PGSTAT_RETRY_DELAY
and so on
to consider several seconds to be fresh enough - Would be nice to
have this
as a GUC variables, although we can do another private patch on our
own. But
more knobs is not always better.
3) logic detecting the proper PGSTAT_RETRY_DELAY value - based mostly
on the time
it takes to write the file (e.g. 10x the write time or something).
4) keeping some sort of "dirty flag" in stat entries - and then writing
only info
about objects were modified enough to be eligible for vacuum/analyze
(e.g.
increasing number of index scans can't trigger autovacuum while
inserting
rows can). Also, I'm not worried about getting a bit older num of
index scans,
so 'clean' records might be written less frequently than 'dirty'
ones.
5) splitting the single stat file into multiple pieces - e.g. per
database,
written separately, so that the autovacuum workers don't need to
read all
the data even for databases that don't need to be vacuumed. This
might be
combined with (4).
Ideas? Objections? Preferred options?
I kinda like (4+5), although that'd be a pretty big patch and I'm not
entirely
sure it can be done without breaking other things.
regards
Tomas
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 14:47:01 |
| Message-ID: | 1348670702-sup-1884@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Really, as far as autovacuum is concerned, it would be much more useful
to be able to reliably detect that a table has been recently vacuumed,
without having to request a 10ms-recent pgstat snapshot. That would
greatly reduce the amount of time autovac spends on pgstat requests.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 14:51:03 |
| Message-ID: | CAMkU=1ymG8tR=xEjwLOKbSQNagA7VRs-TApQTxmCzeu5pPp2ww@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Sep 26, 2012 at 5:43 AM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> First - our system really is not a "common" one - we do have ~1000 of
> databases of
> various size, each containing up to several thousands of tables (several
> user-defined
> tables, the rest serve as caches for a reporting application - yes, it's a
> bit weird
> design but that's life). This all leads to pgstat.stat significantly larger
> than 60 MB.
>
...
> Now, let's suppose the write takes >10 ms, which is the PGSTAT_RETRY_DELAY
> values.
> With our current pgstat.stat filesize/num of relations, this is quite
> common.
> Actually the common write time in our case is ~100 ms, even if we move the
> file
> into tmpfs. That means that almost all the calls to backend_read_statsfile
> (which
> happen in all pgstat_fetch_stat_*entry calls) result in continuous stream of
> inquiries from the autovacuum workers, writing/reading of the file.
I don't think it actually does. What you are missing is the same
thing I was missing a few weeks ago when I also looked into something
like this.
3962:
* We don't recompute min_ts after sleeping, except in the
* unlikely case that cur_ts went backwards.
That means the file must have been written within 10 ms of when we
*first* asked for it.
What is generating the endless stream you are seeing is that you have
1000 databases so if naptime is one minute you are vacuuming 16 per
second. Since every database gets a new process, that process needs
to read the file as it doesn't inherit one.
...
>
> First, I'm interested in feedback - did I get all the details right, or am I
> missing something important?
>
> Next, I'm thinking about ways to solve this:
>
> 1) turning of autovacuum, doing regular VACUUM ANALYZE from cron
Increasing autovacuum_naptime seems like a far better way to do
effectively the same thing.
>
> 2) tweaking the timer values, especially increasing PGSTAT_RETRY_DELAY and
> so on
> to consider several seconds to be fresh enough - Would be nice to have
> this
> as a GUC variables, although we can do another private patch on our own.
> But
> more knobs is not always better.
I think forking it off to to another value would be better. If you
are an autovacuum worker which is just starting up and so getting its
initial stats, you can tolerate a stats file up to "autovacuum_naptime
/ 5.0" stale. If you are already started up and are just about to
vacuum a table, then keep the staleness at PGSTAT_RETRY_DELAY as it
currently is, so as not to redundantly vacuum a table.
>
> 3) logic detecting the proper PGSTAT_RETRY_DELAY value - based mostly on the
> time
> it takes to write the file (e.g. 10x the write time or something).
This is already in place.
> 5) splitting the single stat file into multiple pieces - e.g. per database,
> written separately, so that the autovacuum workers don't need to read all
> the data even for databases that don't need to be vacuumed. This might be
> combined with (4).
I think this needs to happen eventually.
Cheers,
Jeff
| From: | Euler Taveira <euler(at)timbira(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 14:53:27 |
| Message-ID: | 506316E7.7060303@timbira.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26-09-2012 09:43, Tomas Vondra wrote:
> I've been struggling with autovacuum generating a lot of I/O and CPU on some
> of our
> systems - after a night spent analyzing this behavior, I believe the current
> autovacuum accidentally behaves a bit like a stress-test in some corner cases
> (but
> I may be seriously wrong, after all it was a long night).
>
It is known that statistic collector doesn't scale for a lot of databases. It
wouldn't be a problem if we don't have automatic maintenance (aka autovacuum).
> Next, I'm thinking about ways to solve this:
>
> 1) turning of autovacuum, doing regular VACUUM ANALYZE from cron - certainly an
> option, but it's rather a workaround than a solution and I'm not very fond of
> it. Moreover it fixes only one side of the problem - triggering the statfile
> writes over and over. The file will be written anyway, although not that
> frequently.
>
It solves your problem if you combine scheduled VA with pgstat.stat in a
tmpfs. I don't see it as a definitive solution if we want to scale auto
maintenance for several hundreds or even thousands databases in a single
cluster (Someone could think it is not that common but in hosting scenarios
this is true. DBAs don't want to run several VMs or pg servers just to
minimize the auto maintenance scalability problem).
> 2) tweaking the timer values, especially increasing PGSTAT_RETRY_DELAY and so on
> to consider several seconds to be fresh enough - Would be nice to have this
> as a GUC variables, although we can do another private patch on our own. But
> more knobs is not always better.
>
It doesn't solve the problem. Also it could be a problem for autovacuum (that
make assumptions based in those fixed values).
> 3) logic detecting the proper PGSTAT_RETRY_DELAY value - based mostly on the time
> it takes to write the file (e.g. 10x the write time or something).
>
Such adaptive logic would be good only iff it takes a small time fraction to
execute. It have to pay attention to the limits. It appears to be a candidate
for exploration.
> 4) keeping some sort of "dirty flag" in stat entries - and then writing only info
> about objects were modified enough to be eligible for vacuum/analyze (e.g.
> increasing number of index scans can't trigger autovacuum while inserting
> rows can). Also, I'm not worried about getting a bit older num of index scans,
> so 'clean' records might be written less frequently than 'dirty' ones.
>
It minimizes your problem but harms collector tools (that want fresh
statistics about databases).
> 5) splitting the single stat file into multiple pieces - e.g. per database,
> written separately, so that the autovacuum workers don't need to read all
> the data even for databases that don't need to be vacuumed. This might be
> combined with (4).
>
IMHO that's the definitive solution. It would be one file per database plus a
global one. That way, the check would only read the global.stat and process
those database that were modified. Also, an in-memory map could store that
information to speed up the checks. The only downside I can see is that you
will increase the number of opened file descriptors.
> Ideas? Objections? Preferred options?
>
I prefer to attack 3, sort of 4 (explained in 5 -- in-memory map) and 5.
Out of curiosity, did you run perf (or some other performance analyzer) to
verify if some (stats and/or autovac) functions pop up in the report?
--
Euler Taveira de Oliveira - Timbira http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 15:25:58 |
| Message-ID: | 1c9a6358f18915d74e375746b0f6e311@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Dne 26.09.2012 16:51, Jeff Janes napsal:
> On Wed, Sep 26, 2012 at 5:43 AM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>
>> First - our system really is not a "common" one - we do have ~1000
>> of
>> databases of
>> various size, each containing up to several thousands of tables
>> (several
>> user-defined
>> tables, the rest serve as caches for a reporting application - yes,
>> it's a
>> bit weird
>> design but that's life). This all leads to pgstat.stat significantly
>> larger
>> than 60 MB.
>>
> ...
>> Now, let's suppose the write takes >10 ms, which is the
>> PGSTAT_RETRY_DELAY
>> values.
>> With our current pgstat.stat filesize/num of relations, this is
>> quite
>> common.
>> Actually the common write time in our case is ~100 ms, even if we
>> move the
>> file
>> into tmpfs. That means that almost all the calls to
>> backend_read_statsfile
>> (which
>> happen in all pgstat_fetch_stat_*entry calls) result in continuous
>> stream of
>> inquiries from the autovacuum workers, writing/reading of the file.
>
> I don't think it actually does. What you are missing is the same
> thing I was missing a few weeks ago when I also looked into something
> like this.
>
> 3962:
>
> * We don't recompute min_ts after sleeping, except in
> the
> * unlikely case that cur_ts went backwards.
>
> That means the file must have been written within 10 ms of when we
> *first* asked for it.
Yeah, right - I've missed the first "if (pgStatDBHash)" check right at
the beginning.
> What is generating the endless stream you are seeing is that you have
> 1000 databases so if naptime is one minute you are vacuuming 16 per
> second. Since every database gets a new process, that process needs
> to read the file as it doesn't inherit one.
Right. But that makes the 10ms timeout even more strange, because the
worker is then using the data for very long time (even minutes).
>
> ...
>>
>> First, I'm interested in feedback - did I get all the details right,
>> or am I
>> missing something important?
>>
>> Next, I'm thinking about ways to solve this:
>>
>> 1) turning of autovacuum, doing regular VACUUM ANALYZE from cron
>
> Increasing autovacuum_naptime seems like a far better way to do
> effectively the same thing.
Agreed. One of my colleagues turned autovacuum off a few years back and
that
was a nice lesson how not to solve this kind of issues.
>> 2) tweaking the timer values, especially increasing
>> PGSTAT_RETRY_DELAY and
>> so on
>> to consider several seconds to be fresh enough - Would be nice to
>> have
>> this
>> as a GUC variables, although we can do another private patch on
>> our own.
>> But
>> more knobs is not always better.
>
> I think forking it off to to another value would be better. If you
> are an autovacuum worker which is just starting up and so getting its
> initial stats, you can tolerate a stats file up to
> "autovacuum_naptime
> / 5.0" stale. If you are already started up and are just about to
> vacuum a table, then keep the staleness at PGSTAT_RETRY_DELAY as it
> currently is, so as not to redundantly vacuum a table.
I always thought there's a "no more than one worker per database"
limit,
and that the file is always reloaded when switching to another
database.
So I'm not sure how could a worker see such a stale table info? Or are
the workers keeping the stats across multiple databases?
>> 3) logic detecting the proper PGSTAT_RETRY_DELAY value - based
>> mostly on the
>> time
>> it takes to write the file (e.g. 10x the write time or
>> something).
>
> This is already in place.
Really? Where?
I've checked the current master, and the only thing I see in
pgstat_write_statsfile
is this (line 3558):
last_statwrite = globalStats.stats_timestamp;
https://github.com/postgres/postgres/blob/master/src/backend/postmaster/pgstat.c#L3558
I don't think that's doing what I meant. That really doesn't scale the
timeout
according to write time. What happens right now is that when the stats
file is
written at time 0 (starts at zero, write finishes at 100 ms), and a
worker asks
for the file at 99 ms (i.e. 1ms before the write finishes), it will set
the time
of the inquiry to last_statrequest and then do this
if (last_statwrite < last_statrequest)
pgstat_write_statsfile(false);
i.e. comparing it to the start of the write. So another write will
start right
after the file is written out. And over and over.
Moreover there's the 'rename' step making the new file invisible for
the worker
processes, which makes the thing a bit more complicated.
What I'm suggesting it that there should be some sort of tracking the
write time
and then deciding whether the file is fresh enough using 10x that
value. So when
a file is written in 100 ms, it's be considered OK for the next 900 ms,
i.e. 1 sec
in total. Sure, we could use 5x or other coefficient, doesn't really
matter.
>> 5) splitting the single stat file into multiple pieces - e.g. per
>> database,
>> written separately, so that the autovacuum workers don't need to
>> read all
>> the data even for databases that don't need to be vacuumed. This
>> might be
>> combined with (4).
>
> I think this needs to happen eventually.
Yes, a nice patch idea ;-)
thanks for the feedback
Tomas
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Euler Taveira <euler(at)timbira(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 15:27:44 |
| Message-ID: | 1348673153-sup-4361@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Excerpts from Euler Taveira's message of mié sep 26 11:53:27 -0300 2012:
> On 26-09-2012 09:43, Tomas Vondra wrote:
> > 5) splitting the single stat file into multiple pieces - e.g. per database,
> > written separately, so that the autovacuum workers don't need to read all
> > the data even for databases that don't need to be vacuumed. This might be
> > combined with (4).
> >
> IMHO that's the definitive solution. It would be one file per database plus a
> global one. That way, the check would only read the global.stat and process
> those database that were modified. Also, an in-memory map could store that
> information to speed up the checks.
+1
> The only downside I can see is that you
> will increase the number of opened file descriptors.
Note that most users of pgstat will only have two files open (instead of
one as currently) -- one for shared, one for their own database. Only
pgstat itself and autovac launcher would need to open pgstat files for
all databases; but both do not have a need to open other files
(arbitrary tables) so this shouldn't be a major problem.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 15:29:22 |
| Message-ID: | 1348673324-sup-4711@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Excerpts from Tomas Vondra's message of mié sep 26 12:25:58 -0300 2012:
> Dne 26.09.2012 16:51, Jeff Janes napsal:
> > I think forking it off to to another value would be better. If you
> > are an autovacuum worker which is just starting up and so getting its
> > initial stats, you can tolerate a stats file up to
> > "autovacuum_naptime
> > / 5.0" stale. If you are already started up and are just about to
> > vacuum a table, then keep the staleness at PGSTAT_RETRY_DELAY as it
> > currently is, so as not to redundantly vacuum a table.
>
> I always thought there's a "no more than one worker per database"
> limit,
There is no such limitation.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 15:35:02 |
| Message-ID: | 66087d1adc6b71732628a025e970de7c@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Dne 26.09.2012 17:29, Alvaro Herrera napsal:
> Excerpts from Tomas Vondra's message of mié sep 26 12:25:58 -0300
> 2012:
>> Dne 26.09.2012 16:51, Jeff Janes napsal:
>
>> > I think forking it off to to another value would be better. If
>> you
>> > are an autovacuum worker which is just starting up and so getting
>> its
>> > initial stats, you can tolerate a stats file up to
>> > "autovacuum_naptime
>> > / 5.0" stale. If you are already started up and are just about to
>> > vacuum a table, then keep the staleness at PGSTAT_RETRY_DELAY as
>> it
>> > currently is, so as not to redundantly vacuum a table.
>>
>> I always thought there's a "no more than one worker per database"
>> limit,
>
> There is no such limitation.
OK, thanks. Still, reading/writing the small (per-database) files would
be
much faster so it would be easy to read/write them more often on
demand.
Tomas
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 16:14:15 |
| Message-ID: | CAMkU=1yPAmQJOXT+kNuv=QCRePjZkLJ=gJOLPv+QSD9AQ+=-Ag@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Sep 26, 2012 at 8:25 AM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> Dne 26.09.2012 16:51, Jeff Janes napsal:
>
>
>> What is generating the endless stream you are seeing is that you have
>> 1000 databases so if naptime is one minute you are vacuuming 16 per
>> second. Since every database gets a new process, that process needs
>> to read the file as it doesn't inherit one.
>
>
> Right. But that makes the 10ms timeout even more strange, because the
> worker is then using the data for very long time (even minutes).
On average that can't happen, or else your vacuuming would fall way
behind. But I agree, there is no reason to have very fresh statistics
to start with. naptime/5 seems like a good cutoff for me for the
start up reading. If a table only becomes eligible for vacuuming in
the last 20% of the naptime, I see no reason that it can't wait
another round. But that just means the statistics collector needs to
write the file less often, the workers still need to read it once per
database since each one only vacuums one database and don't inherit
the data from the launcher.
>> I think forking it off to to another value would be better. If you
>> are an autovacuum worker which is just starting up and so getting its
>> initial stats, you can tolerate a stats file up to "autovacuum_naptime
>> / 5.0" stale. If you are already started up and are just about to
>> vacuum a table, then keep the staleness at PGSTAT_RETRY_DELAY as it
>> currently is, so as not to redundantly vacuum a table.
>
>
> I always thought there's a "no more than one worker per database" limit,
> and that the file is always reloaded when switching to another database.
> So I'm not sure how could a worker see such a stale table info? Or are
> the workers keeping the stats across multiple databases?
If you only have one "active" database, then all the workers will be
in it. I don't how likely it is that they will leap frog each other
and collide. But anyway, if you 1000s of databases, then each one
will generally require zero vacuums per naptime (as you say, it is
mostly read only), so it is the reads upon start-up, not the reads per
table that needs vacuuming, which generates most of the traffic. Once
you separate those two parameters out, playing around with the
PGSTAT_RETRY_DELAY one seems like a needless risk.
>
>>> 3) logic detecting the proper PGSTAT_RETRY_DELAY value - based mostly on
>>> the
>>> time
>>> it takes to write the file (e.g. 10x the write time or something).
>>
>>
>> This is already in place.
>
>
> Really? Where?
I had thought that this part was effectively the same thing:
* We don't recompute min_ts after sleeping, except in the
* unlikely case that cur_ts went backwards.
But I think I did not understand your proposal.
>
> I've checked the current master, and the only thing I see in
> pgstat_write_statsfile
> is this (line 3558):
>
> last_statwrite = globalStats.stats_timestamp;
>
> https://github.com/postgres/postgres/blob/master/src/backend/postmaster/pgstat.c#L3558
>
>
> I don't think that's doing what I meant. That really doesn't scale the
> timeout
> according to write time. What happens right now is that when the stats file
> is
> written at time 0 (starts at zero, write finishes at 100 ms), and a worker
> asks
> for the file at 99 ms (i.e. 1ms before the write finishes), it will set the
> time
> of the inquiry to last_statrequest and then do this
>
> if (last_statwrite < last_statrequest)
> pgstat_write_statsfile(false);
>
> i.e. comparing it to the start of the write. So another write will start
> right
> after the file is written out. And over and over.
Ah. I had wondered about this before too, and wondered if it would be
a good idea to have it go back to the beginning of the stats file, and
overwrite the timestamp with the current time (rather than the time it
started writing it), as the last action it does before the rename. I
think that would automatically make it adaptive to the time it takes
to write out the file, in a fairly simple way.
>
> Moreover there's the 'rename' step making the new file invisible for the
> worker
> processes, which makes the thing a bit more complicated.
I think renames are assumed to be atomic. Either it sees the old one,
or the new one, but never sees neither.
Cheers,
Jeff
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Euler Taveira <euler(at)timbira(dot)com>, Tomas Vondra <tv(at)fuzzy(dot)cz>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 16:29:17 |
| Message-ID: | 26698.1348676957@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
> Excerpts from Euler Taveira's message of mi sep 26 11:53:27 -0300 2012:
>> On 26-09-2012 09:43, Tomas Vondra wrote:
>>> 5) splitting the single stat file into multiple pieces - e.g. per database,
>>> written separately, so that the autovacuum workers don't need to read all
>>> the data even for databases that don't need to be vacuumed. This might be
>>> combined with (4).
>> IMHO that's the definitive solution. It would be one file per database plus a
>> global one. That way, the check would only read the global.stat and process
>> those database that were modified. Also, an in-memory map could store that
>> information to speed up the checks.
> +1
That would help for the case of hundreds of databases, but how much
does it help for lots of tables in a single database?
I'm a bit suspicious of the idea that we should encourage people to use
hundreds of databases per installation anyway: the duplicated system
catalogs are going to be mighty expensive, both in disk space and in
their cache footprint in shared buffers. There was some speculation
at the last PGCon about how we might avoid the duplication, but I think
we're years away from any such thing actually happening.
What seems to me like it could help more is fixing things so that the
autovac launcher needn't even launch a child process for databases that
haven't had any updates lately. I'm not sure how to do that, but it
probably involves getting the stats collector to produce some kind of
summary file.
regards, tom lane
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Euler Taveira <euler(at)timbira(dot)com>, Tomas Vondra <tv(at)fuzzy(dot)cz>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 17:18:51 |
| Message-ID: | CAMkU=1w5vG6eREnwmPiNJ6tsKoJKa67tuYCCqd9wNDoLh-Ankw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Sep 26, 2012 at 9:29 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
>> Excerpts from Euler Taveira's message of mié sep 26 11:53:27 -0300 2012:
>>> On 26-09-2012 09:43, Tomas Vondra wrote:
>>>> 5) splitting the single stat file into multiple pieces - e.g. per database,
>>>> written separately, so that the autovacuum workers don't need to read all
>>>> the data even for databases that don't need to be vacuumed. This might be
>>>> combined with (4).
>
>>> IMHO that's the definitive solution. It would be one file per database plus a
>>> global one. That way, the check would only read the global.stat and process
>>> those database that were modified. Also, an in-memory map could store that
>>> information to speed up the checks.
>
>> +1
>
> That would help for the case of hundreds of databases, but how much
> does it help for lots of tables in a single database?
It doesn't help that case, but that case doesn't need much help. If
you have N statistics-kept objects in total spread over M databases,
of which T objects need vacuuming per naptime, the stats file traffic
is proportional to N*(M+T). If T is low, then there is generally is
no problem if M is also low. Or at least, the problem is much smaller
than when M is high for a fixed value of N.
> I'm a bit suspicious of the idea that we should encourage people to use
> hundreds of databases per installation anyway:
I agree with that, but we could still do a better job of tolerating
it; without encouraging it. If someone volunteers to write the code
to do this, what trade-offs would there be?
Cheers,
Jeff
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 22:48:34 |
| Message-ID: | 50638642.2080606@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26.9.2012 18:29, Tom Lane wrote:
> Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
>> Excerpts from Euler Taveira's message of miĂŠ sep 26 11:53:27 -0300 2012:
>>> On 26-09-2012 09:43, Tomas Vondra wrote:
>>>> 5) splitting the single stat file into multiple pieces - e.g. per database,
>>>> written separately, so that the autovacuum workers don't need to read all
>>>> the data even for databases that don't need to be vacuumed. This might be
>>>> combined with (4).
>
>>> IMHO that's the definitive solution. It would be one file per database plus a
>>> global one. That way, the check would only read the global.stat and process
>>> those database that were modified. Also, an in-memory map could store that
>>> information to speed up the checks.
>
>> +1
>
> That would help for the case of hundreds of databases, but how much
> does it help for lots of tables in a single database?
Well, it wouldn't, but it wouldn't make it worse either. Or at least
that's how I understand it.
> I'm a bit suspicious of the idea that we should encourage people to use
> hundreds of databases per installation anyway: the duplicated system
> catalogs are going to be mighty expensive, both in disk space and in
> their cache footprint in shared buffers. There was some speculation
> at the last PGCon about how we might avoid the duplication, but I think
> we're years away from any such thing actually happening.
You don't need to encourage us to do that ;-) We know it's not perfect
and considering a good alternative - e.g. several databases (~10) with
schemas inside, replacing the current database-only approach. This way
we'd get multiple stat files (thus gaining the benefits) with less
overhead (shared catalogs).
And yes, using tens of thousands of tables (serving as "caches") for a
reporting solution is "interesting" (as in the old Chinese curse) too.
> What seems to me like it could help more is fixing things so that the
> autovac launcher needn't even launch a child process for databases that
> haven't had any updates lately. I'm not sure how to do that, but it
> probably involves getting the stats collector to produce some kind of
> summary file.
Yes, I've proposed something like this in my original mail - setting a
"dirty" flag on objects (a database in this case) whenever a table in it
gets eligible for vacuum/analyze.
Tomas
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-26 23:53:50 |
| Message-ID: | 5063958E.1080606@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26.9.2012 18:14, Jeff Janes wrote:
> On Wed, Sep 26, 2012 at 8:25 AM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>> Dne 26.09.2012 16:51, Jeff Janes napsal:
>>
>>
>>> What is generating the endless stream you are seeing is that you have
>>> 1000 databases so if naptime is one minute you are vacuuming 16 per
>>> second. Since every database gets a new process, that process needs
>>> to read the file as it doesn't inherit one.
>>
>>
>> Right. But that makes the 10ms timeout even more strange, because the
>> worker is then using the data for very long time (even minutes).
>
> On average that can't happen, or else your vacuuming would fall way
> behind. But I agree, there is no reason to have very fresh statistics
> to start with. naptime/5 seems like a good cutoff for me for the
> start up reading. If a table only becomes eligible for vacuuming in
> the last 20% of the naptime, I see no reason that it can't wait
> another round. But that just means the statistics collector needs to
> write the file less often, the workers still need to read it once per
> database since each one only vacuums one database and don't inherit
> the data from the launcher.
So what happens if there are two workers vacuuming the same database?
Wouldn't that make it more probable that were already vacuumed by the
other worker?
See the comment at the beginning of autovacuum.c, where it also states
that the statfile is reloaded before each table (probably because of the
calls to autovac_refresh_stats which in turn calls clear_snapshot).
>>> I think forking it off to to another value would be better. If you
>>> are an autovacuum worker which is just starting up and so getting its
>>> initial stats, you can tolerate a stats file up to "autovacuum_naptime
>>> / 5.0" stale. If you are already started up and are just about to
>>> vacuum a table, then keep the staleness at PGSTAT_RETRY_DELAY as it
>>> currently is, so as not to redundantly vacuum a table.
>>
>>
>> I always thought there's a "no more than one worker per database" limit,
>> and that the file is always reloaded when switching to another database.
>> So I'm not sure how could a worker see such a stale table info? Or are
>> the workers keeping the stats across multiple databases?
>
> If you only have one "active" database, then all the workers will be
> in it. I don't how likely it is that they will leap frog each other
> and collide. But anyway, if you 1000s of databases, then each one
> will generally require zero vacuums per naptime (as you say, it is
> mostly read only), so it is the reads upon start-up, not the reads per
> table that needs vacuuming, which generates most of the traffic. Once
> you separate those two parameters out, playing around with the
> PGSTAT_RETRY_DELAY one seems like a needless risk.
OK, right. My fault.
Yes, our databases are mostly readable - more precisely whenever we load
data, we immediately do VACUUM ANALYZE on the tables, so autovacuum
never kicks in on them. The only thing it works on are system catalogs
and such stuff.
>>>> 3) logic detecting the proper PGSTAT_RETRY_DELAY value - based mostly on
>>>> the
>>>> time
>>>> it takes to write the file (e.g. 10x the write time or something).
>>>
>>>
>>> This is already in place.
>>
>>
>> Really? Where?
>
> I had thought that this part was effectively the same thing:
>
> * We don't recompute min_ts after sleeping, except in the
> * unlikely case that cur_ts went backwards.
>
> But I think I did not understand your proposal.
>
>>
>> I've checked the current master, and the only thing I see in
>> pgstat_write_statsfile
>> is this (line 3558):
>>
>> last_statwrite = globalStats.stats_timestamp;
>>
>> https://github.com/postgres/postgres/blob/master/src/backend/postmaster/pgstat.c#L3558
>>
>>
>> I don't think that's doing what I meant. That really doesn't scale the
>> timeout
>> according to write time. What happens right now is that when the stats file
>> is
>> written at time 0 (starts at zero, write finishes at 100 ms), and a worker
>> asks
>> for the file at 99 ms (i.e. 1ms before the write finishes), it will set the
>> time
>> of the inquiry to last_statrequest and then do this
>>
>> if (last_statwrite < last_statrequest)
>> pgstat_write_statsfile(false);
>>
>> i.e. comparing it to the start of the write. So another write will start
>> right
>> after the file is written out. And over and over.
>
> Ah. I had wondered about this before too, and wondered if it would be
> a good idea to have it go back to the beginning of the stats file, and
> overwrite the timestamp with the current time (rather than the time it
> started writing it), as the last action it does before the rename. I
> think that would automatically make it adaptive to the time it takes
> to write out the file, in a fairly simple way.
Yeah, I was thinking about that too.
>> Moreover there's the 'rename' step making the new file invisible for the
>> worker
>> processes, which makes the thing a bit more complicated.
>
> I think renames are assumed to be atomic. Either it sees the old one,
> or the new one, but never sees neither.
I'm not quite sure what I meant, but not this - I know the renames are
atomic. I probably haven't noticed that inquiries are using min_ts, so I
though that an inquiry sent right after the write starts (with min_ts
before the write) would trigger another write, but that's not the case.
regards
Tomas
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-27 09:51:28 |
| Message-ID: | CA+U5nMJMibhhnDf3sh+UzWE5RyniZrR0cuQaj=byjMpdJYUVyQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26 September 2012 15:47, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> wrote:
>
> Really, as far as autovacuum is concerned, it would be much more useful
> to be able to reliably detect that a table has been recently vacuumed,
> without having to request a 10ms-recent pgstat snapshot. That would
> greatly reduce the amount of time autovac spends on pgstat requests.
VACUUMing generates a relcache invalidation. Can we arrange for those
invalidations to be received by autovac launcher, so it gets immediate
feedback of recent activity without polling?
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-27 14:57:24 |
| Message-ID: | 1348757745-sup-1839@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Excerpts from Simon Riggs's message of jue sep 27 06:51:28 -0300 2012:
> On 26 September 2012 15:47, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> wrote:
> >
> > Really, as far as autovacuum is concerned, it would be much more useful
> > to be able to reliably detect that a table has been recently vacuumed,
> > without having to request a 10ms-recent pgstat snapshot. That would
> > greatly reduce the amount of time autovac spends on pgstat requests.
>
> VACUUMing generates a relcache invalidation. Can we arrange for those
> invalidations to be received by autovac launcher, so it gets immediate
> feedback of recent activity without polling?
Hmm, this is an interesting idea worth exploring, I think. Maybe we
should sort tables in the autovac worker to-do list by age of last
invalidation messages received, or something like that. Totally unclear
on the details, but as I said, worth exploring.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-09-27 20:06:56 |
| Message-ID: | CA+U5nMJpa2FVUVa0wwjnK1nEZ42u+TiQvT5nZd0Q51FAVGRm-g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27 September 2012 15:57, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> wrote:
> Excerpts from Simon Riggs's message of jue sep 27 06:51:28 -0300 2012:
>> On 26 September 2012 15:47, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> wrote:
>> >
>> > Really, as far as autovacuum is concerned, it would be much more useful
>> > to be able to reliably detect that a table has been recently vacuumed,
>> > without having to request a 10ms-recent pgstat snapshot. That would
>> > greatly reduce the amount of time autovac spends on pgstat requests.
>>
>> VACUUMing generates a relcache invalidation. Can we arrange for those
>> invalidations to be received by autovac launcher, so it gets immediate
>> feedback of recent activity without polling?
>
> Hmm, this is an interesting idea worth exploring, I think. Maybe we
> should sort tables in the autovac worker to-do list by age of last
> invalidation messages received, or something like that. Totally unclear
> on the details, but as I said, worth exploring.
Just put them to back of queue if an inval is received.
There is already support for listening and yet never generating to
relcache inval messages.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-11-18 22:49:19 |
| Message-ID: | 50A965EF.50708@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi!
On 26.9.2012 19:18, Jeff Janes wrote:
> On Wed, Sep 26, 2012 at 9:29 AM, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
>> Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> writes:
>>> Excerpts from Euler Taveira's message of mié sep 26 11:53:27 -0300 2012:
>>>> On 26-09-2012 09:43, Tomas Vondra wrote:
>>>>> 5) splitting the single stat file into multiple pieces - e.g. per database,
>>>>> written separately, so that the autovacuum workers don't need to read all
>>>>> the data even for databases that don't need to be vacuumed. This might be
>>>>> combined with (4).
>>
>>>> IMHO that's the definitive solution. It would be one file per database plus a
>>>> global one. That way, the check would only read the global.stat and process
>>>> those database that were modified. Also, an in-memory map could store that
>>>> information to speed up the checks.
>>
>>> +1
>>
>> That would help for the case of hundreds of databases, but how much
>> does it help for lots of tables in a single database?
>
> It doesn't help that case, but that case doesn't need much help. If
> you have N statistics-kept objects in total spread over M databases,
> of which T objects need vacuuming per naptime, the stats file traffic
> is proportional to N*(M+T). If T is low, then there is generally is
> no problem if M is also low. Or at least, the problem is much smaller
> than when M is high for a fixed value of N.
I've done some initial hacking on splitting the stat file into multiple
smaller pieces over the weekend, and it seems promising (at least with
respect to the issues we're having).
See the patch attached, but be aware that this is a very early WIP (or
rather a proof of concept), so it has many rough edges (read "sloppy
coding"). I haven't even added it to the commitfest yet ...
The two main changes are these:
(1) The stats file is split into a common "db" file, containing all the
DB Entries, and per-database files with tables/functions. The common
file is still called "pgstat.stat", the per-db files have the
database OID appended, so for example "pgstat.stat.12345" etc.
This was a trivial hack pgstat_read_statsfile/pgstat_write_statsfile
functions, introducing two new functions:
pgstat_read_db_statsfile
pgstat_write_db_statsfile
that do the trick of reading/writing stat file for one database.
(2) The pgstat_read_statsfile has an additional parameter "onlydbs" that
says that you don't need table/func stats - just the list of db
entries. This is used for autovacuum launcher, which does not need
to read the table/stats (if I'm reading the code in autovacuum.c
correctly - it seems to be working as expected).
So what are the benefits?
(a) When a launcher asks for info about databases, something like this
is called in the end:
pgstat_read_db_statsfile(InvalidOid, false, true)
which means all databases (InvalidOid) and only db info (true). So
it reads only the one common file with db entries, not the
table/func stats.
(b) When a worker asks for stats for a given DB, something like this is
called in the end:
pgstat_read_db_statsfile(MyDatabaseId, false, false)
which reads only the common stats file (with db entries) and only
one file for the one database.
The current implementation (with the single pgstat.stat file), all
the data had to be read (and skipped silently) in both cases.
That's a lot of CPU time, and we're seeing ~60% of CPU spent on
doing just this (writing/reading huge statsfile).
So with a lot of databases/objects, this "pgstat.stat split" saves
us a lot of CPU ...
(c) This should lower the space requirements too - with a single file,
you actually need at least 2x the disk space (or RAM, if you're
using tmpfs as we are), because you need to keep two versions of
the file at the same time (pgstat.stat and pgstat.tmp).
Thanks to this split you only need additional space for a copy of
the largest piece (with some reasonable safety reserve).
Well, it's very early patch, so there are rough edges too
(a) It does not solve the "many-schema" scenario at all - that'll need
a completely new approach I guess :-(
(b) It does not solve the writing part at all - the current code uses a
single timestamp (last_statwrite) to decide if a new file needs to
be written.
That clearly is not enough for multiple files - there should be one
timestamp for each database/file. I'm thinking about how to solve
this and how to integrate it with pgstat_send_inquiry etc.
One way might be adding the timestamp(s) into PgStat_StatDBEntry
and the other one is using an array of inquiries for each database.
And yet another one I'm thinking about is using a fixed-length
array of timestamps (e.g. 256), indexed by mod(dboid,256). That
would mean stats for all databases with the same mod(oid,256) would
be written at the same time. Seems like an over-engineering though.
(c) I'm a bit worried about the number of files - right now there's one
for each database and I'm thinking about splitting them by type
(one for tables, one for functions) which might make it even faster
for some apps with a lot of stored procedures etc.
But is the large number of files actually a problem? After all,
we're using one file per relation fork in the "base" directory, so
this seems like a minor issue.
And if really an issue, this might be solved by the mod(oid,256) to
combine multiple files into one (which would work neatly with the
fixed-length array of timestamps).
kind regards
Tomas
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split.patch | text/plain | 11.3 KB |
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-11-18 23:13:21 |
| Message-ID: | 50A96B91.1050409@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26.9.2012 18:29, Tom Lane wrote:
> What seems to me like it could help more is fixing things so that the
> autovac launcher needn't even launch a child process for databases that
> haven't had any updates lately. I'm not sure how to do that, but it
> probably involves getting the stats collector to produce some kind of
> summary file.
Couldn't we use the PgStat_StatDBEntry for this? By splitting the
pgstat.stat file into multiple pieces (see my other post in this thread)
there's a file with StatDBEntry items only, so maybe it could be used as
the summary file ...
I've been thinking about this:
(a) add "needs_autovacuuming" flag to PgStat_(TableEntry|StatDBEntry)
(b) when table stats are updated, run quick check to decide whether
the table needs to be processed by autovacuum (vacuumed or
analyzed), and if yes then set needs_autovacuuming=true and both
for table and database
The worker may read the DB entries from the file and act only on those
that need to be processed (those with needs_autovacuuming=true).
Maybe the DB-level field might be a counter of tables that need to be
processed, and the autovacuum daemon might act on those first? Although
the simpler the better I guess.
Or did you mean something else?
regards
Tomas
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-11-21 18:02:56 |
| Message-ID: | CA+TgmoZr3xUQq_OM2V1nmEN6NScVBFkpYJrpFFmbyOPJKvZdzQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Nov 18, 2012 at 5:49 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> The two main changes are these:
>
> (1) The stats file is split into a common "db" file, containing all the
> DB Entries, and per-database files with tables/functions. The common
> file is still called "pgstat.stat", the per-db files have the
> database OID appended, so for example "pgstat.stat.12345" etc.
>
> This was a trivial hack pgstat_read_statsfile/pgstat_write_statsfile
> functions, introducing two new functions:
>
> pgstat_read_db_statsfile
> pgstat_write_db_statsfile
>
> that do the trick of reading/writing stat file for one database.
>
> (2) The pgstat_read_statsfile has an additional parameter "onlydbs" that
> says that you don't need table/func stats - just the list of db
> entries. This is used for autovacuum launcher, which does not need
> to read the table/stats (if I'm reading the code in autovacuum.c
> correctly - it seems to be working as expected).
I'm not an expert on the stats system, but this seems like a promising
approach to me.
> (a) It does not solve the "many-schema" scenario at all - that'll need
> a completely new approach I guess :-(
We don't need to solve every problem in the first patch. I've got no
problem kicking this one down the road.
> (b) It does not solve the writing part at all - the current code uses a
> single timestamp (last_statwrite) to decide if a new file needs to
> be written.
>
> That clearly is not enough for multiple files - there should be one
> timestamp for each database/file. I'm thinking about how to solve
> this and how to integrate it with pgstat_send_inquiry etc.
Presumably you need a last_statwrite for each file, in a hash table or
something, and requests need to specify which file is needed.
> And yet another one I'm thinking about is using a fixed-length
> array of timestamps (e.g. 256), indexed by mod(dboid,256). That
> would mean stats for all databases with the same mod(oid,256) would
> be written at the same time. Seems like an over-engineering though.
That seems like an unnecessary kludge.
> (c) I'm a bit worried about the number of files - right now there's one
> for each database and I'm thinking about splitting them by type
> (one for tables, one for functions) which might make it even faster
> for some apps with a lot of stored procedures etc.
>
> But is the large number of files actually a problem? After all,
> we're using one file per relation fork in the "base" directory, so
> this seems like a minor issue.
I don't see why one file per database would be a problem. After all,
we already have on directory per database inside base/. If the user
has so many databases that dirent lookups in a directory of that size
are a problem, they're already hosed, and this will probably still
work out to a net win.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: autovacuum stress-testing our system |
| Date: | 2012-12-03 02:07:43 |
| Message-ID: | 50BC096F.3010502@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21.11.2012 19:02, Robert Haas wrote:
> On Sun, Nov 18, 2012 at 5:49 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>> The two main changes are these:
>>
>> (1) The stats file is split into a common "db" file, containing all the
>> DB Entries, and per-database files with tables/functions. The common
>> file is still called "pgstat.stat", the per-db files have the
>> database OID appended, so for example "pgstat.stat.12345" etc.
>>
>> This was a trivial hack pgstat_read_statsfile/pgstat_write_statsfile
>> functions, introducing two new functions:
>>
>> pgstat_read_db_statsfile
>> pgstat_write_db_statsfile
>>
>> that do the trick of reading/writing stat file for one database.
>>
>> (2) The pgstat_read_statsfile has an additional parameter "onlydbs" that
>> says that you don't need table/func stats - just the list of db
>> entries. This is used for autovacuum launcher, which does not need
>> to read the table/stats (if I'm reading the code in autovacuum.c
>> correctly - it seems to be working as expected).
>
> I'm not an expert on the stats system, but this seems like a promising
> approach to me.
>
>> (a) It does not solve the "many-schema" scenario at all - that'll need
>> a completely new approach I guess :-(
>
> We don't need to solve every problem in the first patch. I've got no
> problem kicking this one down the road.
>
>> (b) It does not solve the writing part at all - the current code uses a
>> single timestamp (last_statwrite) to decide if a new file needs to
>> be written.
>>
>> That clearly is not enough for multiple files - there should be one
>> timestamp for each database/file. I'm thinking about how to solve
>> this and how to integrate it with pgstat_send_inquiry etc.
>
> Presumably you need a last_statwrite for each file, in a hash table or
> something, and requests need to specify which file is needed.
>
>> And yet another one I'm thinking about is using a fixed-length
>> array of timestamps (e.g. 256), indexed by mod(dboid,256). That
>> would mean stats for all databases with the same mod(oid,256) would
>> be written at the same time. Seems like an over-engineering though.
>
> That seems like an unnecessary kludge.
>
>> (c) I'm a bit worried about the number of files - right now there's one
>> for each database and I'm thinking about splitting them by type
>> (one for tables, one for functions) which might make it even faster
>> for some apps with a lot of stored procedures etc.
>>
>> But is the large number of files actually a problem? After all,
>> we're using one file per relation fork in the "base" directory, so
>> this seems like a minor issue.
>
> I don't see why one file per database would be a problem. After all,
> we already have on directory per database inside base/. If the user
> has so many databases that dirent lookups in a directory of that size
> are a problem, they're already hosed, and this will probably still
> work out to a net win.
Attached is a v2 of the patch, fixing some of the issues and unclear
points from the initial version.
The main improvement is that it implements writing only stats for the
requested database (set when sending inquiry). There's a dynamic array
of request - for each DB only the last request is kept.
I've done a number of changes - most importantly:
- added a stats_timestamp field to PgStat_StatDBEntry, keeping the last
write of the database (i.e. a per-database last_statwrite), which is
used to decide whether the file is stale or not
- handling of the 'permanent' flag correctly (used when starting or
stopping the cluster) for per-db files
- added a very simple header to the per-db files (basically just a
format ID and a timestamp) - this is needed for checking of the
timestamp of the last write from workers (although maybe we could
just read the pgstat.stat, which is now rather small)
- a 'force' parameter (true - write all databases, even if they weren't
specifically requested)
So with the exception of 'multi-schema' case (which was not the aim of
this effort), it should solve all the issues of the initial version.
There are two blocks of code dealing with clock glitches. I haven't
fixed those yet, but that can wait I guess. I've also left there some
logging I've used during development (printing inquiries and which file
is written and when).
The main unsolved problem I'm struggling with is what to do when a
database is dropped? Right now, the statfile remains in pg_stat_tmp
forewer (or until the restart) - is there a good way to remove the
file? I'm thinking about adding a message to be sent to the collector
from the code that handles DROP TABLE.
I've done some very simple performance testing - I've created 1000
databases with 1000 tables each, done ANALYZE on all of them. With only
autovacum running, I've seen this:
Without the patch
-----------------
%CPU %MEM TIME+ COMMAND
18 3.0 0:10.10 postgres: autovacuum launcher process
17 2.6 0:11.44 postgres: stats collector process
The I/O was seriously bogged down, doing ~150 MB/s (basically what the
drive can handle) - with less dbs, or when the statfiles are placed on
tmpfs filesystem, we usually see ~70% of one core doing just this.
With the patch
--------------
Then, the typical "top" for PostgreSQL processes looked like this:
%CPU %MEM TIME+ COMMAND
2 0.3 1:16.57 postgres: autovacuum launcher process
2 3.1 0:25.34 postgres: stats collector process
and the average write speed from the stats collector was ~3.5MB/s
(measured using iotop), and even when running the ANALYZE etc. I was
getting rather light IO usage (like ~15 MB/s or something).
With both cases, the total size was ~150MB, but without the space
requirements are actually 2x that (because of writing a copy and then
renaming).
I'd like to put this into 2013-01 commit fest, but if we can do some
prior testing / comments, that'd be great.
regards
Tomas
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v2.patch | text/plain | 26.8 KB |
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-01-02 23:15:45 |
| Message-ID: | 50E4BFA1.7000404@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
attached is a version of the patch that I believe is ready for the
commitfest. As the patch was discussed over a large number of messages,
I've prepared a brief summary for those who did not follow the thread.
Issue
=====
The patch aims to improve the situation in deployments with many tables
in many databases (think for example 1000 tables in 1000 databases).
Currently all the stats for all the objects (dbs, tables and functions)
are written in a single file (pgstat.stat), which may get quite large
and that consequently leads to various issues:
1) I/O load - the file is frequently written / read, which may use a
significant part of the I/O bandwidth. For example we'have to deal with
cases when the pgstat.stat size is >150MB, and it's written (and read)
continuously (once it's written, a new write starts) and utilizes 100%
bandwidth on that device.
2) CPU load - a common solution to the previous issue is moving the file
into RAM, using a tmpfs filesystem. That "fixes" the I/O bottleneck but
causes high CPU load because the system is serializing and deserializing
large amounts of data. We often see ~1 CPU core "lost" due to this (and
causing higher power consumption, but that's Amazon's problem ;-)
3) disk space utilization - the pgstat.stat file is updated in two
steps, i.e. a new version is written to another file (pgstat.tmp) and
then it's renamed to pgstat.stat, which means the device (amount of RAM,
if using tmpfs device) needs to be >2x the actual size of the file.
(Actually more, because there may be descriptors open to multiple
versions of the file.)
This patch does not attempt to fix a "single DB with multiple schemas"
scenario, although it should not have a negative impact on it.
What the patch does
===================
1) split into global and per-db files
-------------------------------------
The patch "splits" the huge pgstat.stat file into smaller pieces - one
"global" one (global.stat) with database stats, and one file for each of
the databases (oid.stat) with table.
This makes it possible to write/read much smaller amounts of data, because
a) autovacuum launcher does not need to read the whole file - it needs
just the list of databases (and not the table/func stats)
b) autovacuum workers do request a fresh copy of a single database, so
the stats collector may write just the global.stat + one of the per-db files
and that consequently leads to much lower I/O and CPU load. During our
tests we've seen the I/O to drop from ~150MB/s to less than 4MB/s, and
much lower CPU utilization.
2) a new global/stat directory
------------------------------
The pgstat.stat file was originally saved into the "global" directory,
but with so many files that would get rather messy so I've created a new
global/stat directory and all the files are stored there.
This also means we can do a simple "delete files in the dir" when
pgstat_reset_all is called.
3) pgstat_(read|write)_statsfile split
--------------------------------------
These two functions were moved into a global and per-db functions, so
now there's
pgstat_write_statsfile -- global.stat
pgstat_write_db_statsfile -- oid.stat
pgstat_read_statsfile -- global.stat
pgstat_read_db_statsfile -- oid.stat
There's a logic to read/write only those files that are actually needed.
4) list of (OID, timestamp) inquiries, last db-write
----------------------------------------------------
Originally there was a single pair of request/write timestamps for the
whole file, updated whenever a worker requested a fresh file or when the
file was written.
With the split, this had to be replaced by two lists - a timestamp of
the last inquiry (per DB), and a timestamp when each database file was
written for the last time.
The timestamp of the last DB write was added to the PgStat_StatDBEntry
and the list of inquiries is kept in last_statrequests. The fields are
used at several places, so it's probably best to see the code.
Handling the timestamps is a rather complex stuff because of the clock
skews. One of those checks is not needed as the list of inquiries is
freed right after writing all the databases. But I wouldn't be surprised
if there was something I missed, as splitting the file into multiple
pieces made this part more complex.
So please, if you're going to review this patch this is one of the
tricky places.
5) dummy file
-------------
A special handling is necessary when an inquiry arrives for a database
without a PgStat_StatDBEntry - this happens for example right after
initdb, when there are no stats for template0 and template1, yet the
autovacuum workers do send inqiries for them.
The backend_read_statsfile now uses the timestamp stored in the header
of the per-db file (not in the global one), and the easies way to handle
this for new databases is writing an empty 'dummy file' (just a header
with timestamp). Without this, this would result in 'pgstat wait
timeout' errors.
This is what pgstat_write_db_dummyfile (used in pgstat_write_statsfile)
is for.
6) format ID
------------
I've bumped PGSTAT_FILE_FORMAT_ID to a new random value, although the
filenames changed to so we could live with the old ID just fine.
We've done a fair amount of testing so far, and if everything goes fine
we plan to deploy a back-ported version of this patch (to 9.1) on a
production in ~2 weeks.
Then I'll be able to provide some numbers from a real-world workload
(although our deployment and workload is not quite usual I guess).
regards
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v4.patch | text/plain | 37.3 KB |
| From: | Heikki Linnakangas <hlinnakangas(at)vmware(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-01-03 17:47:40 |
| Message-ID: | 50E5C43C.5040309@vmware.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 03.01.2013 01:15, Tomas Vondra wrote:
> 2) a new global/stat directory
> ------------------------------
>
> The pgstat.stat file was originally saved into the "global" directory,
> but with so many files that would get rather messy so I've created a new
> global/stat directory and all the files are stored there.
>
> This also means we can do a simple "delete files in the dir" when
> pgstat_reset_all is called.
How about creating the new directory as a direct subdir of $PGDATA,
rather than buried in global? "global" is supposed to contain data
related to shared catalog relations (plus pg_control), so it doesn't
seem like the right location for per-database stat files. Also, if we're
going to have admins manually zapping the directory (hopefully when the
system is offline), that's less scary if the directory is not buried as
deep.
- Heikki
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-01-03 19:31:32 |
| Message-ID: | 50E5DC94.4000205@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3.1.2013 18:47, Heikki Linnakangas wrote:
> On 03.01.2013 01:15, Tomas Vondra wrote:
>> 2) a new global/stat directory
>> ------------------------------
>>
>> The pgstat.stat file was originally saved into the "global" directory,
>> but with so many files that would get rather messy so I've created a new
>> global/stat directory and all the files are stored there.
>>
>> This also means we can do a simple "delete files in the dir" when
>> pgstat_reset_all is called.
>
> How about creating the new directory as a direct subdir of $PGDATA,
> rather than buried in global? "global" is supposed to contain data
> related to shared catalog relations (plus pg_control), so it doesn't
> seem like the right location for per-database stat files. Also, if we're
> going to have admins manually zapping the directory (hopefully when the
> system is offline), that's less scary if the directory is not buried as
> deep.
That's clearly possible and it's a trivial change. I was thinking about
that actually, but then I placed the directory into "global" because
that's where the "pgstat.stat" originally was.
Tomas
| From: | Magnus Hagander <magnus(at)hagander(dot)net> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-01-03 19:33:35 |
| Message-ID: | CABUevEyzr6urZS7fcEDTGAJE0inUSQdcd=r49nkr2xaQoxrj_A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Jan 3, 2013 at 8:31 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> On 3.1.2013 18:47, Heikki Linnakangas wrote:
>> On 03.01.2013 01:15, Tomas Vondra wrote:
>>> 2) a new global/stat directory
>>> ------------------------------
>>>
>>> The pgstat.stat file was originally saved into the "global" directory,
>>> but with so many files that would get rather messy so I've created a new
>>> global/stat directory and all the files are stored there.
>>>
>>> This also means we can do a simple "delete files in the dir" when
>>> pgstat_reset_all is called.
>>
>> How about creating the new directory as a direct subdir of $PGDATA,
>> rather than buried in global? "global" is supposed to contain data
>> related to shared catalog relations (plus pg_control), so it doesn't
>> seem like the right location for per-database stat files. Also, if we're
>> going to have admins manually zapping the directory (hopefully when the
>> system is offline), that's less scary if the directory is not buried as
>> deep.
>
> That's clearly possible and it's a trivial change. I was thinking about
> that actually, but then I placed the directory into "global" because
> that's where the "pgstat.stat" originally was.
Yeah, +1 for a separate directory not in global.
--
Magnus Hagander
Me: http://www.hagander.net/
Work: http://www.redpill-linpro.com/
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-01-06 04:03:38 |
| Message-ID: | 50E8F79A.9040008@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3.1.2013 20:33, Magnus Hagander wrote:
> On Thu, Jan 3, 2013 at 8:31 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>> On 3.1.2013 18:47, Heikki Linnakangas wrote:
>>> How about creating the new directory as a direct subdir of $PGDATA,
>>> rather than buried in global? "global" is supposed to contain data
>>> related to shared catalog relations (plus pg_control), so it doesn't
>>> seem like the right location for per-database stat files. Also, if we're
>>> going to have admins manually zapping the directory (hopefully when the
>>> system is offline), that's less scary if the directory is not buried as
>>> deep.
>>
>> That's clearly possible and it's a trivial change. I was thinking about
>> that actually, but then I placed the directory into "global" because
>> that's where the "pgstat.stat" originally was.
>
> Yeah, +1 for a separate directory not in global.
OK, I moved the files from "global/stat" to "stat".
Tomas
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v5.patch | text/plain | 37.3 KB |
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-01 16:19:26 |
| Message-ID: | 20130201161926.GF4918@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra wrote:
> diff --git a/src/backend/postmaster/pgstat.c b/src/backend/postmaster/pgstat.c
> index be3adf1..4ec485e 100644
> --- a/src/backend/postmaster/pgstat.c
> +++ b/src/backend/postmaster/pgstat.c
> @@ -64,10 +64,14 @@
>
> /* ----------
> * Paths for the statistics files (relative to installation's $PGDATA).
> + * Permanent and temprorary, global and per-database files.
Note typo in the line above.
> -#define PGSTAT_STAT_PERMANENT_FILENAME "global/pgstat.stat"
> -#define PGSTAT_STAT_PERMANENT_TMPFILE "global/pgstat.tmp"
> +#define PGSTAT_STAT_PERMANENT_DIRECTORY "stat"
> +#define PGSTAT_STAT_PERMANENT_FILENAME "stat/global.stat"
> +#define PGSTAT_STAT_PERMANENT_TMPFILE "stat/global.tmp"
> +#define PGSTAT_STAT_PERMANENT_DB_FILENAME "stat/%d.stat"
> +#define PGSTAT_STAT_PERMANENT_DB_TMPFILE "stat/%d.tmp"
> +char *pgstat_stat_directory = NULL;
> char *pgstat_stat_filename = NULL;
> char *pgstat_stat_tmpname = NULL;
> +char *pgstat_stat_db_filename = NULL;
> +char *pgstat_stat_db_tmpname = NULL;
I don't like the quoted parts very much; it seems awkward to have the
snprintf patterns in one place and have them be used in very distant
places. Is there a way to improve that? Also, if I understand clearly,
the pgstat_stat_db_filename value needs to be an snprintf pattern too,
right? What if it doesn't contain the required % specifier?
Also, if you can filter this through pgindent, that would be best. Make
sure to add DBWriteRequest to src/tools/pgindent/typedefs_list.
> + /*
> + * There's no request for this DB yet, so lets create it (allocate a
> + * space for it, set the values).
> + */
> + if (last_statrequests == NULL)
> + last_statrequests = palloc(sizeof(DBWriteRequest));
> + else
> + last_statrequests = repalloc(last_statrequests,
> + (num_statrequests + 1)*sizeof(DBWriteRequest));
> +
> + last_statrequests[num_statrequests].databaseid = msg->databaseid;
> + last_statrequests[num_statrequests].request_time = msg->clock_time;
> + num_statrequests += 1;
Having to repalloc this array each time seems wrong. Would a list
instead of an array help? see ilist.c/h; I vote for a dlist because you
can easily delete elements from the middle of it, if required (I think
you'd need that.)
> + char db_statfile[strlen(pgstat_stat_db_filename) + 11];
> + snprintf(db_statfile, strlen(pgstat_stat_db_filename) + 11,
> + pgstat_stat_filename, dbentry->databaseid);
This pattern seems rather frequent. Can we use a macro or similar here?
Encapsulating the "11" better would be good. Magic numbers are evil.
> diff --git a/src/include/pgstat.h b/src/include/pgstat.h
> index 613c1c2..b3467d2 100644
> --- a/src/include/pgstat.h
> +++ b/src/include/pgstat.h
> @@ -205,6 +205,7 @@ typedef struct PgStat_MsgInquiry
> PgStat_MsgHdr m_hdr;
> TimestampTz clock_time; /* observed local clock time */
> TimestampTz cutoff_time; /* minimum acceptable file timestamp */
> + Oid databaseid; /* requested DB (InvalidOid => all DBs) */
> } PgStat_MsgInquiry;
Do we need to support the case that somebody requests stuff from the
"shared" DB? IIRC that's what InvalidOid means in pgstat ...
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-02 22:33:10 |
| Message-ID: | CAMkU=1wBEhC0RMnkYcqeKTwwKZCfZjcFMHB=CuEtd4LbdgHWWg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Jan 5, 2013 at 8:03 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> On 3.1.2013 20:33, Magnus Hagander wrote:
>>
>> Yeah, +1 for a separate directory not in global.
>
> OK, I moved the files from "global/stat" to "stat".
This has a warning:
pgstat.c:5132: warning: 'pgstat_write_statsfile_needed' was used with
no prototype before its definition
I plan to do some performance testing, but that will take a while so I
wanted to post this before I get distracted.
Cheers,
Jeff
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-03 19:46:39 |
| Message-ID: | CAMkU=1yrkPe8KRaGSt+E03Y7M_W+gyO6Gwy9fh9MHNX60js7kg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Jan 5, 2013 at 8:03 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> On 3.1.2013 20:33, Magnus Hagander wrote:
>>
>> Yeah, +1 for a separate directory not in global.
>
> OK, I moved the files from "global/stat" to "stat".
Why "stat" rather than "pg_stat"?
The existence of "global" and "base" as exceptions already annoys me.
(Especially when I do a tar -xf in my home directory without
remembering the -C flag). Unless there is some unstated rule behind
what gets a pg_ and what doesn't, I think we should have the "pg_".
Cheers,
Jeff
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-03 20:54:02 |
| Message-ID: | CAMkU=1zQUi9Yh9jNxjNnQWsPgoXrth3Mz_4QFD6fuf9ru8NGJA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sat, Feb 2, 2013 at 2:33 PM, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> wrote:
> On Sat, Jan 5, 2013 at 8:03 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>> On 3.1.2013 20:33, Magnus Hagander wrote:
>>>
>>> Yeah, +1 for a separate directory not in global.
>>
>> OK, I moved the files from "global/stat" to "stat".
>
> This has a warning:
>
> pgstat.c:5132: warning: 'pgstat_write_statsfile_needed' was used with
> no prototype before its definition
>
> I plan to do some performance testing, but that will take a while so I
> wanted to post this before I get distracted.
Running "vacuumdb -a" on a cluster with 1000 db with 200 tables (x
serial primary key) in each, I get log messages like this:
last_statwrite 23682-06-18 22:36:52.960194-07 is later than
collector's time 2013-02-03 12:49:19.700629-08 for db 16387
Note the bizarre year in the first time stamp.
If it matters, I got this after shutting down the cluster, blowing
away $DATA/stat/*, then restarting it and invoking vacuumdb.
Cheers,
Jeff
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-04 00:49:07 |
| Message-ID: | 510F0583.2020809@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3.2.2013 20:46, Jeff Janes wrote:
> On Sat, Jan 5, 2013 at 8:03 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>> On 3.1.2013 20:33, Magnus Hagander wrote:
>>>
>>> Yeah, +1 for a separate directory not in global.
>>
>> OK, I moved the files from "global/stat" to "stat".
>
> Why "stat" rather than "pg_stat"?
>
> The existence of "global" and "base" as exceptions already annoys me.
> (Especially when I do a tar -xf in my home directory without
> remembering the -C flag). Unless there is some unstated rule behind
> what gets a pg_ and what doesn't, I think we should have the "pg_".
I don't think there's a clear naming rule. But I think your suggestion
makes perfect sense, especially because we have pg_stat_tmp directory.
So now we'd have pg_stat and pg_stat_tmp, which is quite elegant.
Tomas
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-04 00:50:33 |
| Message-ID: | 510F05D9.7000802@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2.2.2013 23:33, Jeff Janes wrote:
> On Sat, Jan 5, 2013 at 8:03 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>> On 3.1.2013 20:33, Magnus Hagander wrote:
>>>
>>> Yeah, +1 for a separate directory not in global.
>>
>> OK, I moved the files from "global/stat" to "stat".
>
> This has a warning:
>
> pgstat.c:5132: warning: 'pgstat_write_statsfile_needed' was used with
> no prototype before its definition
I forgot to add "void" into the method prototype ... Thanks!
Tomas
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-04 00:51:59 |
| Message-ID: | 510F062F.1080001@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 3.2.2013 21:54, Jeff Janes wrote:
> On Sat, Feb 2, 2013 at 2:33 PM, Jeff Janes <jeff(dot)janes(at)gmail(dot)com> wrote:
>> On Sat, Jan 5, 2013 at 8:03 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>>> On 3.1.2013 20:33, Magnus Hagander wrote:
>>>>
>>>> Yeah, +1 for a separate directory not in global.
>>>
>>> OK, I moved the files from "global/stat" to "stat".
>>
>> This has a warning:
>>
>> pgstat.c:5132: warning: 'pgstat_write_statsfile_needed' was used with
>> no prototype before its definition
>>
>> I plan to do some performance testing, but that will take a while so I
>> wanted to post this before I get distracted.
>
> Running "vacuumdb -a" on a cluster with 1000 db with 200 tables (x
> serial primary key) in each, I get log messages like this:
>
> last_statwrite 23682-06-18 22:36:52.960194-07 is later than
> collector's time 2013-02-03 12:49:19.700629-08 for db 16387
>
> Note the bizarre year in the first time stamp.
>
> If it matters, I got this after shutting down the cluster, blowing
> away $DATA/stat/*, then restarting it and invoking vacuumdb.
I somehow expected that hash_search zeroes all the fields of a new
entry, but looking at pgstat_get_db_entry that obviously is not the
case. So stats_timestamp (which tracks timestamp of the last write for a
DB) was random - that's where the bizarre year values came from.
I've added a proper initialization (to 0), and now it works as expected.
Although the whole sequence of errors I was getting was this:
LOG: last_statwrite 11133-08-28 19:22:31.711744+02 is later than
collector's time 2013-02-04 00:54:21.113439+01 for db 19093
WARNING: pgstat wait timeout
LOG: last_statwrite 39681-12-23 18:48:48.9093+01 is later than
collector's time 2013-02-04 00:54:31.424681+01 for db 46494
FATAL: could not find block containing chunk 0x2af4a60
LOG: statistics collector process (PID 10063) exited with exit code 1
WARNING: pgstat wait timeout
WARNING: pgstat wait timeout
I'm not entirely sure where the FATAL came from, but it seems it was
somehow related to the issue - it was quite reproducible, although I
don't see how exactly could this happen. There relevant block of code
looks like this:
char *writetime;
char *mytime;
/* Copy because timestamptz_to_str returns a static buffer */
writetime = pstrdup(timestamptz_to_str(dbentry->stats_timestamp));
mytime = pstrdup(timestamptz_to_str(cur_ts));
elog(LOG, "last_statwrite %s is later than collector's time %s for "
"db %d", writetime, mytime, dbentry->databaseid);
pfree(writetime);
pfree(mytime);
which seems quite fine to mee. I'm not sure how one of the pfree calls
could fail?
Anyway, attached is a patch that fixes all three issues, i.e.
1) the un-initialized timestamp
2) the "void" ommited from the signature
3) rename to "pg_stat" instead of just "stat"
Tomas
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v6.patch | text/x-diff | 37.5 KB |
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-04 02:21:18 |
| Message-ID: | 510F1B1E.8080307@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 1.2.2013 17:19, Alvaro Herrera wrote:
> Tomas Vondra wrote:
>
>> diff --git a/src/backend/postmaster/pgstat.c b/src/backend/postmaster/pgstat.c
>> index be3adf1..4ec485e 100644
>> --- a/src/backend/postmaster/pgstat.c
>> +++ b/src/backend/postmaster/pgstat.c
>> @@ -64,10 +64,14 @@
>>
>> /* ----------
>> * Paths for the statistics files (relative to installation's $PGDATA).
>> + * Permanent and temprorary, global and per-database files.
>
> Note typo in the line above.
>
>> -#define PGSTAT_STAT_PERMANENT_FILENAME "global/pgstat.stat"
>> -#define PGSTAT_STAT_PERMANENT_TMPFILE "global/pgstat.tmp"
>> +#define PGSTAT_STAT_PERMANENT_DIRECTORY "stat"
>> +#define PGSTAT_STAT_PERMANENT_FILENAME "stat/global.stat"
>> +#define PGSTAT_STAT_PERMANENT_TMPFILE "stat/global.tmp"
>> +#define PGSTAT_STAT_PERMANENT_DB_FILENAME "stat/%d.stat"
>> +#define PGSTAT_STAT_PERMANENT_DB_TMPFILE "stat/%d.tmp"
>
>> +char *pgstat_stat_directory = NULL;
>> char *pgstat_stat_filename = NULL;
>> char *pgstat_stat_tmpname = NULL;
>> +char *pgstat_stat_db_filename = NULL;
>> +char *pgstat_stat_db_tmpname = NULL;
>
> I don't like the quoted parts very much; it seems awkward to have the
> snprintf patterns in one place and have them be used in very distant
I don't see that as particularly awkward, but that's a matter of taste.
I still see that as a bunch of constants that are sprintf patterns at
the same time.
> places. Is there a way to improve that? Also, if I understand clearly,
> the pgstat_stat_db_filename value needs to be an snprintf pattern too,
> right? What if it doesn't contain the required % specifier?
Ummmm, yes - it needs to be a pattern too, but the user specifies the
directory (stats_temp_directory) and this is used to derive all the
other values - see assign_pgstat_temp_directory() in guc.c.
> Also, if you can filter this through pgindent, that would be best. Make
> sure to add DBWriteRequest to src/tools/pgindent/typedefs_list.
Will do.
>
>> + /*
>> + * There's no request for this DB yet, so lets create it (allocate a
>> + * space for it, set the values).
>> + */
>> + if (last_statrequests == NULL)
>> + last_statrequests = palloc(sizeof(DBWriteRequest));
>> + else
>> + last_statrequests = repalloc(last_statrequests,
>> + (num_statrequests + 1)*sizeof(DBWriteRequest));
>> +
>> + last_statrequests[num_statrequests].databaseid = msg->databaseid;
>> + last_statrequests[num_statrequests].request_time = msg->clock_time;
>> + num_statrequests += 1;
>
> Having to repalloc this array each time seems wrong. Would a list
> instead of an array help? see ilist.c/h; I vote for a dlist because you
> can easily delete elements from the middle of it, if required (I think
> you'd need that.)
Thanks. I'm not very familiar with the list interface, so I've used
plain array. But yes, there are better ways than doing repalloc all the
time.
>
>> + char db_statfile[strlen(pgstat_stat_db_filename) + 11];
>> + snprintf(db_statfile, strlen(pgstat_stat_db_filename) + 11,
>> + pgstat_stat_filename, dbentry->databaseid);
>
> This pattern seems rather frequent. Can we use a macro or similar here?
> Encapsulating the "11" better would be good. Magic numbers are evil.
Yes, this needs to be cleaned / improved.
>> diff --git a/src/include/pgstat.h b/src/include/pgstat.h
>> index 613c1c2..b3467d2 100644
>> --- a/src/include/pgstat.h
>> +++ b/src/include/pgstat.h
>> @@ -205,6 +205,7 @@ typedef struct PgStat_MsgInquiry
>> PgStat_MsgHdr m_hdr;
>> TimestampTz clock_time; /* observed local clock time */
>> TimestampTz cutoff_time; /* minimum acceptable file timestamp */
>> + Oid databaseid; /* requested DB (InvalidOid => all DBs) */
>> } PgStat_MsgInquiry;
>
> Do we need to support the case that somebody requests stuff from the
> "shared" DB? IIRC that's what InvalidOid means in pgstat ...
Frankly, I don't know, but I guess we do because it was in the original
code, and there are such inquiries right after the database starts
(that's why I had to add pgstat_write_db_dummyfile).
Tomas
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-05 18:23:27 |
| Message-ID: | CAMkU=1w2zdfSzmm796ZhsaDH56_yrN2+9v_A367tAB7--XZX6g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Feb 3, 2013 at 4:51 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> LOG: last_statwrite 11133-08-28 19:22:31.711744+02 is later than
> collector's time 2013-02-04 00:54:21.113439+01 for db 19093
> WARNING: pgstat wait timeout
> LOG: last_statwrite 39681-12-23 18:48:48.9093+01 is later than
> collector's time 2013-02-04 00:54:31.424681+01 for db 46494
> FATAL: could not find block containing chunk 0x2af4a60
> LOG: statistics collector process (PID 10063) exited with exit code 1
> WARNING: pgstat wait timeout
> WARNING: pgstat wait timeout
>
> I'm not entirely sure where the FATAL came from, but it seems it was
> somehow related to the issue - it was quite reproducible, although I
> don't see how exactly could this happen. There relevant block of code
> looks like this:
>
> char *writetime;
> char *mytime;
>
> /* Copy because timestamptz_to_str returns a static buffer */
> writetime = pstrdup(timestamptz_to_str(dbentry->stats_timestamp));
> mytime = pstrdup(timestamptz_to_str(cur_ts));
> elog(LOG, "last_statwrite %s is later than collector's time %s for "
> "db %d", writetime, mytime, dbentry->databaseid);
> pfree(writetime);
> pfree(mytime);
>
> which seems quite fine to mee. I'm not sure how one of the pfree calls
> could fail?
I don't recall seeing the FATAL errors myself, but didn't keep the
logfile around. (I do recall seeing the pgstat wait timeout).
Are you using windows? pstrdup seems to be different there.
I'm afraid I don't have much to say on the code. Indeed I never even
look at it (other than grepping for pstrdup just now). I am taking a
purely experimental approach, Since Alvaro and others have looked at
the code.
>
> Anyway, attached is a patch that fixes all three issues, i.e.
>
> 1) the un-initialized timestamp
> 2) the "void" ommited from the signature
> 3) rename to "pg_stat" instead of just "stat"
Thanks.
If I shutdown the server and blow away the stats with "rm
data/pg_stat/*", it recovers gracefully when I start it back up. If a
do "rm -r data/pg_stat" then it has problems the next time I shut it
down, but I have no right to do that in the first place. If I initdb
a database without this patch, then shut it down and restart with
binaries that include this patch, and need to manually make the
pg_stat directory. Does that mean it needs a catalog bump in order to
force an initdb?
A review:
It applies cleanly (some offsets, no fuzz), builds without warnings,
and passes make check including with cassert.
The final test done in "make check" inherently tests this code, and it
passes. If I intentionally break the patch by making
pgstat_read_db_statsfile add one to the oid it opens, then the test
fails. So the existing test is at least plausible as a test.
doc/src/sgml/monitoring.sgml needs to be changed: "a permanent copy of
the statistics data is stored in the global subdirectory". I'm not
aware of any other needed changes to the docs.
The big question is whether we want this. I think we do. While
having hundreds of databases in a cluster is not recommended, that is
no reason not to handle it better than we do. I don't see any
down-sides, other than possibly some code uglification. Some file
systems might not deal well with having lots of small stats files
being rapidly written and rewritten, but it is hard to see how the
current behavior would be more favorable for those systems.
We do not already have this. There is no relevant spec. I can't see
how this could need pg_dump support (but what about pg_upgrade?)
I am not aware of any dangers.
I have a question about its completeness. When I first start up the
cluster and have not yet touched it, there is very little stats
collector activity, either with or without this patch. When I kick
the cluster sufficiently (I've been using vacuumdb -a to do that) then
there is a lot of stats collector activity. Even once the vacuumdb
has long finished, this high level of activity continues even though
the database is otherwise completely idle, and this seems to happen
for every. This patch makes that high level of activity much more
efficient, but it does not reduce the activity. I don't understand
why an idle database cannot get back into the state right after
start-up.
I do not think that the patch needs to solve this problem in order to
be accepted, but if it can be addressed while the author and reviewers
are paying attention to this part of the system, that would be ideal.
And if not, then we should at least remember that there is future work
that could be done here.
I created 1000 databases each with 200 single column tables (x serial
primary key).
After vacuumdb -a, I let it idle for a long time to see what steady
state was reached.
without the patch:
vacuumdb -a real 11m2.624s
idle steady state: 48.17% user, 39.24% system, 11.78% iowait, 0.81% idle.
with the patch:
vacuumdb -a real 6m41.306s
idle steady state: 7.86% user, 5.00% system 0.09% iowait 87% idle,
I also ran pgbench on a scale that fits in memory with fsync=off, on a
singe CPU machine. With the same above-mentioned 1000 databases as
unused decoys to bloat the stats file.
pgbench_tellers and branches undergo enough turn over that they should
get vacuumed every minuted (nap time).
Without the patch, they only get vacuumed every 40 minutes or so as
the autovac workers are so distracted by reading the bloated stats
file. and the TPS is ~680.
With the patch, they get vacuumed every 1 to 2 minutes and TPS is ~940
So this seems to be effective at it intended goal.
I have not done a review of the code itself, only the performance.
Cheers,
Jeff
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-05 22:31:21 |
| Message-ID: | 51118839.3020908@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 5.2.2013 19:23, Jeff Janes wrote:
> On Sun, Feb 3, 2013 at 4:51 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>
>> LOG: last_statwrite 11133-08-28 19:22:31.711744+02 is later than
>> collector's time 2013-02-04 00:54:21.113439+01 for db 19093
>> WARNING: pgstat wait timeout
>> LOG: last_statwrite 39681-12-23 18:48:48.9093+01 is later than
>> collector's time 2013-02-04 00:54:31.424681+01 for db 46494
>> FATAL: could not find block containing chunk 0x2af4a60
>> LOG: statistics collector process (PID 10063) exited with exit code 1
>> WARNING: pgstat wait timeout
>> WARNING: pgstat wait timeout
>>
>> I'm not entirely sure where the FATAL came from, but it seems it was
>> somehow related to the issue - it was quite reproducible, although I
>> don't see how exactly could this happen. There relevant block of code
>> looks like this:
>>
>> char *writetime;
>> char *mytime;
>>
>> /* Copy because timestamptz_to_str returns a static buffer */
>> writetime = pstrdup(timestamptz_to_str(dbentry->stats_timestamp));
>> mytime = pstrdup(timestamptz_to_str(cur_ts));
>> elog(LOG, "last_statwrite %s is later than collector's time %s for "
>> "db %d", writetime, mytime, dbentry->databaseid);
>> pfree(writetime);
>> pfree(mytime);
>>
>> which seems quite fine to mee. I'm not sure how one of the pfree calls
>> could fail?
>
> I don't recall seeing the FATAL errors myself, but didn't keep the
> logfile around. (I do recall seeing the pgstat wait timeout).
>
> Are you using windows? pstrdup seems to be different there.
Nope. I'll repeat the test with the original patch to find out what went
wrong, just to be sure it was fixed.
> I'm afraid I don't have much to say on the code. Indeed I never even
> look at it (other than grepping for pstrdup just now). I am taking a
> purely experimental approach, Since Alvaro and others have looked at
> the code.
Thanks for finding the issue with unitialized timestamp!
> If I shutdown the server and blow away the stats with "rm
> data/pg_stat/*", it recovers gracefully when I start it back up. If a
> do "rm -r data/pg_stat" then it has problems the next time I shut it
> down, but I have no right to do that in the first place. If I initdb
> a database without this patch, then shut it down and restart with
> binaries that include this patch, and need to manually make the
> pg_stat directory. Does that mean it needs a catalog bump in order to
> force an initdb?
Ummmm, what you mean by "catalog bump"?
Anyway, messing with files in the "base" directory is a bad idea in
general, and I don't think that's a reason to treat the pg_stat
directory differently. If you remove it by hand, you'll be rightfully
punished by various errors.
> A review:
>
> It applies cleanly (some offsets, no fuzz), builds without warnings,
> and passes make check including with cassert.
>
> The final test done in "make check" inherently tests this code, and it
> passes. If I intentionally break the patch by making
> pgstat_read_db_statsfile add one to the oid it opens, then the test
> fails. So the existing test is at least plausible as a test.
>
> doc/src/sgml/monitoring.sgml needs to be changed: "a permanent copy of
> the statistics data is stored in the global subdirectory". I'm not
> aware of any other needed changes to the docs.
Yeah, that should be "in the global/pg_stat subdirectory".
> The big question is whether we want this. I think we do. While
> having hundreds of databases in a cluster is not recommended, that is
> no reason not to handle it better than we do. I don't see any
> down-sides, other than possibly some code uglification. Some file
> systems might not deal well with having lots of small stats files
> being rapidly written and rewritten, but it is hard to see how the
> current behavior would be more favorable for those systems.
If the filesystem has issues with that many entries, it's already hosed
by contents of the "base" directory (one per directory) or in the
database directories (multiple files per table).
Moreover, it's still possible to use tmpfs to handle this at runtime
(which is often the recommended solution with the current code), and use
the actual filesystem only for keeping the data across restarts.
> We do not already have this. There is no relevant spec. I can't see
> how this could need pg_dump support (but what about pg_upgrade?)
pg_dump - no
pg_upgrage - IMHO it should create the pg_stat directory. I don't think
it could "convert" statfile into the new format (by splitting it into
the pieces). I haven't checked but I believe the default behavior is to
delete it as there might be new fields / slight changes of meaning etc.
> I am not aware of any dangers.
>
> I have a question about its completeness. When I first start up the
> cluster and have not yet touched it, there is very little stats
> collector activity, either with or without this patch. When I kick
> the cluster sufficiently (I've been using vacuumdb -a to do that) then
> there is a lot of stats collector activity. Even once the vacuumdb
> has long finished, this high level of activity continues even though
> the database is otherwise completely idle, and this seems to happen
> for every. This patch makes that high level of activity much more
> efficient, but it does not reduce the activity. I don't understand
> why an idle database cannot get back into the state right after
> start-up.
What do you mean by "stats collector activity"? Is it reading/writing a
lot of data, or is it just using a lot of CPU?
Isn't that just a natural and expected behavior because the database
needs to actually perform ANALYZE to actually collect the data. Although
the tables are empty, it costs some CPU / IO and there's a lot of them
(1000 dbs, each with 200 tables).
I don't think there's a way around this. You may increase the autovacuum
naptime, but that's about all.
> I do not think that the patch needs to solve this problem in order to
> be accepted, but if it can be addressed while the author and reviewers
> are paying attention to this part of the system, that would be ideal.
> And if not, then we should at least remember that there is future work
> that could be done here.
If I understand that correctly, you see the same behaviour even without
the patch, right? In that case I'd vote not to make the patch more
complex, and try to improve that separately (if it's even possible).
> I created 1000 databases each with 200 single column tables (x serial
> primary key).
>
> After vacuumdb -a, I let it idle for a long time to see what steady
> state was reached.
>
> without the patch:
> vacuumdb -a real 11m2.624s
> idle steady state: 48.17% user, 39.24% system, 11.78% iowait, 0.81% idle.
>
> with the patch:
> vacuumdb -a real 6m41.306s
> idle steady state: 7.86% user, 5.00% system 0.09% iowait 87% idle,
Nice. Another interesting numbers would be device utilization, average
I/O speed and required space (which should be ~2x the pgstat.stat size
without the patch).
> I also ran pgbench on a scale that fits in memory with fsync=off, on a
> singe CPU machine. With the same above-mentioned 1000 databases as
> unused decoys to bloat the stats file.
>
> pgbench_tellers and branches undergo enough turn over that they should
> get vacuumed every minuted (nap time).
>
> Without the patch, they only get vacuumed every 40 minutes or so as
> the autovac workers are so distracted by reading the bloated stats
> file. and the TPS is ~680.
>
> With the patch, they get vacuumed every 1 to 2 minutes and TPS is ~940
Great, I haven't really aimed to improve pgbench results, but it seems
natural that the decreased CPU utilization can go somewhere else. Not bad.
Have you moved the stats somewhere to tmpfs, or have you used the
default location (on disk)?
Tomas
| From: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-06 06:31:50 |
| Message-ID: | CAFj8pRC+Gcskcgd+ifB8VZT9Z0hk-rX6NZXRAJLM_z8FZHfc+Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
>>
>> with the patch:
>> vacuumdb -a real 6m41.306s
>> idle steady state: 7.86% user, 5.00% system 0.09% iowait 87% idle,
>
> Nice. Another interesting numbers would be device utilization, average
> I/O speed and required space (which should be ~2x the pgstat.stat size
> without the patch).
>
this point is important - with large warehouse with lot of databases
and tables you have move stat file to some ramdisc - without it you
lost lot of IO capacity - and it is very important if you need only
half sized ramdisc
Regards
Pavel
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-06 15:40:50 |
| Message-ID: | 5616.1360165250@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> writes:
>> Nice. Another interesting numbers would be device utilization, average
>> I/O speed and required space (which should be ~2x the pgstat.stat size
>> without the patch).
> this point is important - with large warehouse with lot of databases
> and tables you have move stat file to some ramdisc - without it you
> lost lot of IO capacity - and it is very important if you need only
> half sized ramdisc
[ blink... ] I confess I'd not been paying close attention to this
thread, but if that's true I'd say the patch is DOA. Why should we
accept 2x bloat in the already-far-too-large stats file? I thought
the idea was just to split up the existing data into multiple files.
regards, tom lane
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com>, Tomas Vondra <tv(at)fuzzy(dot)cz>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-06 15:53:17 |
| Message-ID: | 20130206155317.GF4299@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tom Lane escribió:
> Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> writes:
> >> Nice. Another interesting numbers would be device utilization, average
> >> I/O speed and required space (which should be ~2x the pgstat.stat size
> >> without the patch).
>
> > this point is important - with large warehouse with lot of databases
> > and tables you have move stat file to some ramdisc - without it you
> > lost lot of IO capacity - and it is very important if you need only
> > half sized ramdisc
>
> [ blink... ] I confess I'd not been paying close attention to this
> thread, but if that's true I'd say the patch is DOA. Why should we
> accept 2x bloat in the already-far-too-large stats file? I thought
> the idea was just to split up the existing data into multiple files.
I think they are saying just the opposite: maximum disk space
utilization is now half of the unpatched code. This is because when we
need to write the temporary file to rename on top of the other one, the
temporary file is not of the size of the complete pgstat data collation,
but just that for the requested database.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Tomas Vondra <tv(at)fuzzy(dot)cz>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-06 15:59:55 |
| Message-ID: | CAFj8pRD4sr-nX7AFWCN2paquRPU1xSDW=PwXirrBUZSF3VUHUg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
2013/2/6 Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>:
> Tom Lane escribió:
>> Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> writes:
>> >> Nice. Another interesting numbers would be device utilization, average
>> >> I/O speed and required space (which should be ~2x the pgstat.stat size
>> >> without the patch).
>>
>> > this point is important - with large warehouse with lot of databases
>> > and tables you have move stat file to some ramdisc - without it you
>> > lost lot of IO capacity - and it is very important if you need only
>> > half sized ramdisc
>>
>> [ blink... ] I confess I'd not been paying close attention to this
>> thread, but if that's true I'd say the patch is DOA. Why should we
>> accept 2x bloat in the already-far-too-large stats file? I thought
>> the idea was just to split up the existing data into multiple files.
>
> I think they are saying just the opposite: maximum disk space
> utilization is now half of the unpatched code. This is because when we
> need to write the temporary file to rename on top of the other one, the
> temporary file is not of the size of the complete pgstat data collation,
> but just that for the requested database.
+1
Pavel
>
> --
> Álvaro Herrera http://www.2ndQuadrant.com/
> PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-06 16:26:29 |
| Message-ID: | bbb96a9c14928f0c9204d42a9d86aa45@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Dne 06.02.2013 16:53, Alvaro Herrera napsal:
> Tom Lane escribió:
>> Pavel Stehule <pavel(dot)stehule(at)gmail(dot)com> writes:
>> >> Nice. Another interesting numbers would be device utilization,
>> average
>> >> I/O speed and required space (which should be ~2x the pgstat.stat
>> size
>> >> without the patch).
>>
>> > this point is important - with large warehouse with lot of
>> databases
>> > and tables you have move stat file to some ramdisc - without it
>> you
>> > lost lot of IO capacity - and it is very important if you need
>> only
>> > half sized ramdisc
>>
>> [ blink... ] I confess I'd not been paying close attention to this
>> thread, but if that's true I'd say the patch is DOA. Why should we
>> accept 2x bloat in the already-far-too-large stats file? I thought
>> the idea was just to split up the existing data into multiple files.
>
> I think they are saying just the opposite: maximum disk space
> utilization is now half of the unpatched code. This is because when
> we
> need to write the temporary file to rename on top of the other one,
> the
> temporary file is not of the size of the complete pgstat data
> collation,
> but just that for the requested database.
Exactly. And I suspect the current (unpatched) code ofter requires more
than
twice the space because of open file descriptors to already deleted
files.
Tomas
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-06 23:16:02 |
| Message-ID: | CAMkU=1xzNhxtCQ98u7unPu3YmD2Ku7edBvujg3ACvOP4+tSuEA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Feb 5, 2013 at 2:31 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
> On 5.2.2013 19:23, Jeff Janes wrote:
>
>> If I shutdown the server and blow away the stats with "rm
>> data/pg_stat/*", it recovers gracefully when I start it back up. If a
>> do "rm -r data/pg_stat" then it has problems the next time I shut it
>> down, but I have no right to do that in the first place. If I initdb
>> a database without this patch, then shut it down and restart with
>> binaries that include this patch, and need to manually make the
>> pg_stat directory. Does that mean it needs a catalog bump in order to
>> force an initdb?
>
> Ummmm, what you mean by "catalog bump"?
There is a catalog number in src/include/catalog/catversion.h, which
when changed forces one to redo initdb.
Formally I guess it is only for system catalog changes, but I thought
it was used for any on-disk changes during development cycles. I like
it the way it is, as I can use the same data directory for both
versions of the binary (patched and unpatched), and just manually
create or remove the directory pg_stat directory when changing modes.
That is ideal for testing this patch, probably not ideal for being
committed into the tree along with all the other ongoing devel work.
But I think this is something the committer has to worry about.
>> I have a question about its completeness. When I first start up the
>> cluster and have not yet touched it, there is very little stats
>> collector activity, either with or without this patch. When I kick
>> the cluster sufficiently (I've been using vacuumdb -a to do that) then
>> there is a lot of stats collector activity. Even once the vacuumdb
>> has long finished, this high level of activity continues even though
>> the database is otherwise completely idle, and this seems to happen
>> for every. This patch makes that high level of activity much more
>> efficient, but it does not reduce the activity. I don't understand
>> why an idle database cannot get back into the state right after
>> start-up.
>
> What do you mean by "stats collector activity"? Is it reading/writing a
> lot of data, or is it just using a lot of CPU?
Basically, the launching of new autovac workers and the work that that
entails. Your patch reduces the size of data that needs to be
written, read, and parsed for every launch, but not the number of
times that that happens.
> Isn't that just a natural and expected behavior because the database
> needs to actually perform ANALYZE to actually collect the data. Although
> the tables are empty, it costs some CPU / IO and there's a lot of them
> (1000 dbs, each with 200 tables).
It isn't touching the tables at all, just the stats files.
I was wrong about the cluster opening quiet. It only does that if,
while the cluster was shutdown, you remove the statistics files which
I was doing, as I was switching back and forth between patched and
unpatched.
When the cluster opens, any databases that don't have statistics in
the stat file(s) will not get an autovacuum worker process spawned.
They only start getting spawned once someone asks for statistics for
that database. But then once that happens, that database then gets a
worker spawned for it every naptime (or, at least, as close to that as
the server can keep up with) for eternity, even if that database is
never used again. The only way to stop this is the unsupported way of
blowing away the permanent stats files.
>
> I don't think there's a way around this. You may increase the autovacuum
> naptime, but that's about all.
>
>> I do not think that the patch needs to solve this problem in order to
>> be accepted, but if it can be addressed while the author and reviewers
>> are paying attention to this part of the system, that would be ideal.
>> And if not, then we should at least remember that there is future work
>> that could be done here.
>
> If I understand that correctly, you see the same behaviour even without
> the patch, right? In that case I'd vote not to make the patch more
> complex, and try to improve that separately (if it's even possible).
OK. I just thought that while digging through the code, you might
have a good idea for fixing this part as well. If so, it would be a
shame for that idea to be lost when you move on to other things.
>
>
>> I created 1000 databases each with 200 single column tables (x serial
>> primary key).
>>
>> After vacuumdb -a, I let it idle for a long time to see what steady
>> state was reached.
>>
>> without the patch:
>> vacuumdb -a real 11m2.624s
>> idle steady state: 48.17% user, 39.24% system, 11.78% iowait, 0.81% idle.
>>
>> with the patch:
>> vacuumdb -a real 6m41.306s
>> idle steady state: 7.86% user, 5.00% system 0.09% iowait 87% idle,
>
> Nice. Another interesting numbers would be device utilization, average
> I/O speed
I didn't gather that data, as I never figured out how to interpret
those numbers and so don't have much faith in them. (But I am pretty
impressed with the numbers I do understand)
> and required space (which should be ~2x the pgstat.stat size
> without the patch).
I didn't study this in depth, but the patch seems to do what it should
(that is, take less space, not more). If I fill the device up so
that there is less than 3x the size of the stats file available for
use (i.e. space for the file itself and for 1 temp copy version of it
but not space for a complete second temp copy), I occasionally get
out-of-space warning with unpatched. But never get those errors with
patched. Indeed, with patch I never get warnings even with only 1.04
times the aggregate size of the stats files available for use. (That
is, size for all the files, plus just 1/25 that amount to spare.
Obviously this limit is specific to having 1000 databases of equal
size.)
>
>> I also ran pgbench on a scale that fits in memory with fsync=off, on a
>> singe CPU machine. With the same above-mentioned 1000 databases as
>> unused decoys to bloat the stats file.
>>
>> pgbench_tellers and branches undergo enough turn over that they should
>> get vacuumed every minuted (nap time).
>>
>> Without the patch, they only get vacuumed every 40 minutes or so as
>> the autovac workers are so distracted by reading the bloated stats
>> file. and the TPS is ~680.
>>
>> With the patch, they get vacuumed every 1 to 2 minutes and TPS is ~940
>
> Great, I haven't really aimed to improve pgbench results, but it seems
> natural that the decreased CPU utilization can go somewhere else. Not bad.
My goal there was to prove to myself that the correct tables were
getting vacuumed. The TPS measurements were just a by-product of
that, but since I had them I figured I'd post them.
> Have you moved the stats somewhere to tmpfs, or have you used the
> default location (on disk)?
All the specific work I reported was with them on disk, except the
part about running out of space, which was done on /dev/shm. But even
with the data theoretically going to disk, the kernel caches it well
enough that I wouldn't expect things to change very much.
Two more questions I've come up with:
If I invoke pg_stat_reset() from a database, the corresponding file
does not get removed from the pg_stat_tmp directory. And when the
database is shut down, a file for the reset database does get created
in pg_stat. Is this OK?
Cheers,
Jeff
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-06 23:40:12 |
| Message-ID: | 18453.1360194012@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Janes <jeff(dot)janes(at)gmail(dot)com> writes:
> On Tue, Feb 5, 2013 at 2:31 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>> Ummmm, what you mean by "catalog bump"?
> There is a catalog number in src/include/catalog/catversion.h, which
> when changed forces one to redo initdb.
> Formally I guess it is only for system catalog changes, but I thought
> it was used for any on-disk changes during development cycles.
Yeah, it would be appropriate to bump the catversion if we're creating a
new PGDATA subdirectory.
I'm not excited about keeping code to take care of the lack of such a
subdirectory at runtime, as I gather there is in the current state of
the patch. Formally, if there were such code, we'd not need a
catversion bump --- the rule of thumb is to change catversion if the new
postgres executable would fail regression tests without a run of the new
initdb. But it's pretty dumb to keep such code indefinitely, when it
would have no more possible use after the next catversion bump (which is
seldom more than a week or two away during devel phase).
>> What do you mean by "stats collector activity"? Is it reading/writing a
>> lot of data, or is it just using a lot of CPU?
> Basically, the launching of new autovac workers and the work that that
> entails. Your patch reduces the size of data that needs to be
> written, read, and parsed for every launch, but not the number of
> times that that happens.
It doesn't seem very reasonable to ask this patch to redesign the
autovacuum algorithms, which is essentially what it'll take to improve
that. That's a completely separate layer of code.
regards, tom lane
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-07 00:28:28 |
| Message-ID: | 5112F52C.8090904@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 7.2.2013 00:40, Tom Lane wrote:
> Jeff Janes <jeff(dot)janes(at)gmail(dot)com> writes:
>> On Tue, Feb 5, 2013 at 2:31 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>>> Ummmm, what you mean by "catalog bump"?
>
>> There is a catalog number in src/include/catalog/catversion.h, which
>> when changed forces one to redo initdb.
>
>> Formally I guess it is only for system catalog changes, but I thought
>> it was used for any on-disk changes during development cycles.
>
> Yeah, it would be appropriate to bump the catversion if we're creating a
> new PGDATA subdirectory.
>
> I'm not excited about keeping code to take care of the lack of such a
> subdirectory at runtime, as I gather there is in the current state of
> the patch. Formally, if there were such code, we'd not need a
No, there is nothing to handle that at runtime. The directory is created
at initdb and the patch expects that (and fails if it's gone).
> catversion bump --- the rule of thumb is to change catversion if the new
> postgres executable would fail regression tests without a run of the new
> initdb. But it's pretty dumb to keep such code indefinitely, when it
> would have no more possible use after the next catversion bump (which is
> seldom more than a week or two away during devel phase).
>
>>> What do you mean by "stats collector activity"? Is it reading/writing a
>>> lot of data, or is it just using a lot of CPU?
>
>> Basically, the launching of new autovac workers and the work that that
>> entails. Your patch reduces the size of data that needs to be
>> written, read, and parsed for every launch, but not the number of
>> times that that happens.
>
> It doesn't seem very reasonable to ask this patch to redesign the
> autovacuum algorithms, which is essentially what it'll take to improve
> that. That's a completely separate layer of code.
My opinion, exactly.
Tomas
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-09 20:40:43 |
| Message-ID: | CAMkU=1yTh2ogYmMkEwGT6uGQ4tktrCXCg8dXpeerURSxMwTsRg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Feb 5, 2013 at 2:31 PM, Tomas Vondra <tv(at)fuzzy(dot)cz> wrote:
>
>> We do not already have this. There is no relevant spec. I can't see
>> how this could need pg_dump support (but what about pg_upgrade?)
>
> pg_dump - no
>
> pg_upgrage - IMHO it should create the pg_stat directory. I don't think
> it could "convert" statfile into the new format (by splitting it into
> the pieces). I haven't checked but I believe the default behavior is to
> delete it as there might be new fields / slight changes of meaning etc.
Right, I have no concerns with pg_upgrade any more. The pg_stat will
inherently get created by the initdb of the new cluster (because the
initdb will done with the new binaries with your patch in place them).
pg_upgrade currently doesn't copy over global/pgstat.stat. So that
means the new cluster doesn't have the activity stats either way,
patch or unpatched. So if it is not currently a problem it will not
become one under the proposed patch.
Cheers,
Jeff
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-13 21:29:08 |
| Message-ID: | 20130213212908.GH4546@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Here's an updated version of this patch that takes care of the issues I
reported previously: no more repalloc() of the requests array; it's now
an slist, which makes the code much more natural IMV. And no more
messing around with doing sprintf to create a separate sprintf pattern
for the per-db stats file; instead have a function to return the name
that uses just the pgstat dir as stored by GUC. I think this can be
further simplified still.
I haven't reviewed the rest yet; please do give this a try to confirm
that the speedups previously reported are still there (i.e. I didn't
completely blew it).
Thanks
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v7.patch | text/x-diff | 41.6 KB |
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 19:23:58 |
| Message-ID: | 20130214192358.GE4747@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Here's a ninth version of this patch. (version 8 went unpublished). I
have simplified a lot of things and improved some comments; I think I
understand much of it now. I think this patch is fairly close to
committable, but one issue remains, which is this bit in
pgstat_write_statsfiles():
/* In any case, we can just throw away all the db requests, but we need to
* write dummy files for databases without a stat entry (it would cause
* issues in pgstat_read_db_statsfile_timestamp and pgstat wait timeouts).
* This may happen e.g. for shared DB (oid = 0) right after initdb.
*/
if (!slist_is_empty(&last_statrequests))
{
slist_mutable_iter iter;
slist_foreach_modify(iter, &last_statrequests)
{
DBWriteRequest *req = slist_container(DBWriteRequest, next,
iter.cur);
/*
* Create dummy files for requested databases without a proper
* dbentry. It's much easier this way than dealing with multiple
* timestamps, possibly existing but not yet written DBs etc.
* */
if (!pgstat_get_db_entry(req->databaseid, false))
pgstat_write_db_dummyfile(req->databaseid);
pfree(req);
}
slist_init(&last_statrequests);
}
The problem here is that creating these dummy entries will cause a
difference in autovacuum behavior. Autovacuum will skip processing
databases with no pgstat entry, and the intended reason is that if
there's no pgstat entry it's because the database doesn't have enough
activity. Now perhaps we want to change that, but it should be an
explicit decision taken after discussion and thought, not side effect
from an unrelated patch.
Hm, and I now also realize another bug in this patch: the global stats
only include database entries for requested databases; but perhaps the
existing files can serve later requestors just fine for databases that
already had files; so the global stats file should continue to carry
entries for them, with the old timestamps.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v9.patch | text/x-diff | 41.9 KB |
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 19:27:55 |
| Message-ID: | 20130214192755.GA10260@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Alvaro Herrera escribió:
> Hm, and I now also realize another bug in this patch: the global stats
> only include database entries for requested databases; but perhaps the
> existing files can serve later requestors just fine for databases that
> already had files; so the global stats file should continue to carry
> entries for them, with the old timestamps.
Actually the code already do things that way -- apologies.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Josh Berkus <josh(at)agliodbs(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 19:43:21 |
| Message-ID: | 511D3E59.6090502@agliodbs.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I saw discussion about this on this thread, but I'm not able to figure
out what the answer is: how does this work with moving the stats file,
for example to a RAMdisk? Specifically, if the user sets
stats_temp_directory, does it continue to work the way it does now?
--
Josh Berkus
PostgreSQL Experts Inc.
http://pgexperts.com
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Josh Berkus <josh(at)agliodbs(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 19:51:53 |
| Message-ID: | 20130214195153.GF4747@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Josh Berkus wrote:
> I saw discussion about this on this thread, but I'm not able to figure
> out what the answer is: how does this work with moving the stats file,
> for example to a RAMdisk? Specifically, if the user sets
> stats_temp_directory, does it continue to work the way it does now?
Of course. You get more files than previously, but yes.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 20:05:41 |
| Message-ID: | 20130214200540.GG4747@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Alvaro Herrera escribió:
> Here's a ninth version of this patch. (version 8 went unpublished). I
> have simplified a lot of things and improved some comments; I think I
> understand much of it now. I think this patch is fairly close to
> committable, but one issue remains, which is this bit in
> pgstat_write_statsfiles():
>
> /* In any case, we can just throw away all the db requests, but we need to
> * write dummy files for databases without a stat entry (it would cause
> * issues in pgstat_read_db_statsfile_timestamp and pgstat wait timeouts).
> * This may happen e.g. for shared DB (oid = 0) right after initdb.
> */
I think the real way to handle this is to fix backend_read_statsfile().
It's using the old logic of considering existance of the file, but of
course now the file might not exist at all and that doesn't mean we need
to continue kicking the collector to write it. We need a mechanism to
figure that the collector is just not going to write the file no matter
how hard we kick it ...
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 21:24:50 |
| Message-ID: | 20130214212450.GJ4747@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Alvaro Herrera escribió:
> Here's a ninth version of this patch. (version 8 went unpublished). I
> have simplified a lot of things and improved some comments; I think I
> understand much of it now. I think this patch is fairly close to
> committable, but one issue remains, which is this bit in
> pgstat_write_statsfiles():
I've marked this as Waiting on author for the time being. I'm going to
review/work on other patches now, hoping that Tomas will post an updated
version in time for it to be considered for 9.3.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 23:41:52 |
| Message-ID: | 511D7640.3020803@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 14.2.2013 20:43, Josh Berkus wrote:
> I saw discussion about this on this thread, but I'm not able to figure
> out what the answer is: how does this work with moving the stats file,
> for example to a RAMdisk? Specifically, if the user sets
> stats_temp_directory, does it continue to work the way it does now?
No change in this respect - you can still use RAMdisk, and you'll
actually need less space because the space requirements decreased due to
breaking the single file into multiple pieces.
We're using it this way (on a tmpfs filesystem) and it works like a charm.
regards
Tomas
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-14 23:48:02 |
| Message-ID: | 511D77B2.2070602@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
First of all, big thanks for working on this patch and not only
identifying the issues but actually fixing them.
On 14.2.2013 20:23, Alvaro Herrera wrote:
> Here's a ninth version of this patch. (version 8 went unpublished). I
> have simplified a lot of things and improved some comments; I think I
> understand much of it now. I think this patch is fairly close to
> committable, but one issue remains, which is this bit in
> pgstat_write_statsfiles():
>
...
>
> The problem here is that creating these dummy entries will cause a
> difference in autovacuum behavior. Autovacuum will skip processing
> databases with no pgstat entry, and the intended reason is that if
> there's no pgstat entry it's because the database doesn't have enough
> activity. Now perhaps we want to change that, but it should be an
> explicit decision taken after discussion and thought, not side effect
> from an unrelated patch.
I don't see how that changes the autovacuum behavior. Can you explain
that a bit more?
As I see it, with the old (single-file version) the autovacuum worker
would get exacly the same thing, i.e. no stats at all.
Which is exacly what autovacuum worker gets with the new code, except
that the check for last statfile timestamp uses the "per-db" file, so we
need to write it. This way the worker is able to read the timestamp, is
happy about it because it gets a fresh file although it gets no stats later.
Where is the behavior change? Can you provide an example?
kind regards
Tomas
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-15 00:02:28 |
| Message-ID: | 511D7B14.2020906@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 14.2.2013 22:24, Alvaro Herrera wrote:
> Alvaro Herrera escribió:
>> Here's a ninth version of this patch. (version 8 went unpublished). I
>> have simplified a lot of things and improved some comments; I think I
>> understand much of it now. I think this patch is fairly close to
>> committable, but one issue remains, which is this bit in
>> pgstat_write_statsfiles():
>
> I've marked this as Waiting on author for the time being. I'm going to
> review/work on other patches now, hoping that Tomas will post an updated
> version in time for it to be considered for 9.3.
Sadly I have no idea how to fix that, and I think the solution you
suggested in the previous messages does not actually do the trick :-(
Tomas
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-15 04:02:58 |
| Message-ID: | 20130215040258.GL4747@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra escribió:
> I don't see how that changes the autovacuum behavior. Can you explain
> that a bit more?
It might be that I'm all wet on this. I'll poke at it some more.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-15 15:38:58 |
| Message-ID: | 20130215153858.GA6155@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra escribió:
> On 14.2.2013 20:23, Alvaro Herrera wrote:
> > The problem here is that creating these dummy entries will cause a
> > difference in autovacuum behavior. Autovacuum will skip processing
> > databases with no pgstat entry, and the intended reason is that if
> > there's no pgstat entry it's because the database doesn't have enough
> > activity. Now perhaps we want to change that, but it should be an
> > explicit decision taken after discussion and thought, not side effect
> > from an unrelated patch.
>
> I don't see how that changes the autovacuum behavior. Can you explain
> that a bit more?
>
> As I see it, with the old (single-file version) the autovacuum worker
> would get exacly the same thing, i.e. no stats at all.
See in autovacuum.c the calls to pgstat_fetch_stat_dbentry(). Most of
them check for NULL result and act differently depending on that.
Returning a valid (not NULL) entry full of zeroes is not the same.
I didn't actually try to reproduce a problem.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-15 18:57:27 |
| Message-ID: | 511E8517.6070806@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 15.2.2013 16:38, Alvaro Herrera wrote:
> Tomas Vondra escribió:
>
>> On 14.2.2013 20:23, Alvaro Herrera wrote:
>
>>> The problem here is that creating these dummy entries will cause a
>>> difference in autovacuum behavior. Autovacuum will skip processing
>>> databases with no pgstat entry, and the intended reason is that if
>>> there's no pgstat entry it's because the database doesn't have enough
>>> activity. Now perhaps we want to change that, but it should be an
>>> explicit decision taken after discussion and thought, not side effect
>>> from an unrelated patch.
>>
>> I don't see how that changes the autovacuum behavior. Can you explain
>> that a bit more?
>>
>> As I see it, with the old (single-file version) the autovacuum worker
>> would get exacly the same thing, i.e. no stats at all.
>
> See in autovacuum.c the calls to pgstat_fetch_stat_dbentry(). Most of
> them check for NULL result and act differently depending on that.
> Returning a valid (not NULL) entry full of zeroes is not the same.
> I didn't actually try to reproduce a problem.
Errrr, but why would the patched code return entry full of zeroes and
not NULL as before? The dummy files serve single purpose - confirm that
the collector attempted to write info for the particular database (and
did not found any data for that).
All it contains is a timestamp of the write - nothing else. So the
worker will read the global file (containing list of stats for dbs) and
then will get NULL just like the old code. Because the database is not
there and the patch does not change that at all.
Tomas
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-16 15:41:56 |
| Message-ID: | 511FA8C4.5090406@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 15.2.2013 01:02, Tomas Vondra wrote:
> On 14.2.2013 22:24, Alvaro Herrera wrote:
>> Alvaro Herrera escribió:
>>> Here's a ninth version of this patch. (version 8 went unpublished). I
>>> have simplified a lot of things and improved some comments; I think I
>>> understand much of it now. I think this patch is fairly close to
>>> committable, but one issue remains, which is this bit in
>>> pgstat_write_statsfiles():
>>
>> I've marked this as Waiting on author for the time being. I'm going to
>> review/work on other patches now, hoping that Tomas will post an updated
>> version in time for it to be considered for 9.3.
>
> Sadly I have no idea how to fix that, and I think the solution you
> suggested in the previous messages does not actually do the trick :-(
I've been thinking about this (actually I had a really weird dream about
it this night) and I think it might work like this:
(1) check the timestamp of the global file -> if it's too old, we need
to send an inquiry or wait a bit longer
(2) if it's new enough, we need to read it a look for that particular
database - if it's not found, we have no info about it yet (this is
the case handled by the dummy files)
(3) if there's a database stat entry, we need to check the timestamp
when it was written for the last time -> if it's too old, send an
inquiry and wait a bit longer
(4) well, we have a recent global file, it contains the database stat
entry and it's fresh enough -> tadaaaaaa, we're done
At least that's my idea - I haven't tried to implement it yet.
I see a few pros and cons of this approach:
pros:
* no dummy files
* no timestamps in the per-db files (and thus no sync issues)
cons:
* the backends / workers will have to re-read the global file just to
check that the per-db file is there and is fresh enough
So far it was sufficient just to peek at the timestamp at the beginning
of the per-db stat file - minimum data read, no CPU-expensive processing
etc. Sadly the more DBs there are, the larger the file get (thus more
overhead to read it).
OTOH it's not that much data (~180B per entry, so with a 1000 of dbs
it's just ~180kB) so I don't expect this to be a tremendous issue. And
the pros seem to be quite compelling.
Tomas
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-17 05:46:54 |
| Message-ID: | 20130217054654.GB6000@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra wrote:
> I've been thinking about this (actually I had a really weird dream about
> it this night) and I think it might work like this:
>
> (1) check the timestamp of the global file -> if it's too old, we need
> to send an inquiry or wait a bit longer
>
> (2) if it's new enough, we need to read it a look for that particular
> database - if it's not found, we have no info about it yet (this is
> the case handled by the dummy files)
>
> (3) if there's a database stat entry, we need to check the timestamp
> when it was written for the last time -> if it's too old, send an
> inquiry and wait a bit longer
>
> (4) well, we have a recent global file, it contains the database stat
> entry and it's fresh enough -> tadaaaaaa, we're done
Hmm, yes, I think this is what I was imagining. I had even considered
that the timestamp would be removed from the per-db file as you suggest
here.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-17 20:19:54 |
| Message-ID: | 51213B6A.4060405@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17.2.2013 06:46, Alvaro Herrera wrote:
> Tomas Vondra wrote:
>
>> I've been thinking about this (actually I had a really weird dream about
>> it this night) and I think it might work like this:
>>
>> (1) check the timestamp of the global file -> if it's too old, we need
>> to send an inquiry or wait a bit longer
>>
>> (2) if it's new enough, we need to read it a look for that particular
>> database - if it's not found, we have no info about it yet (this is
>> the case handled by the dummy files)
>>
>> (3) if there's a database stat entry, we need to check the timestamp
>> when it was written for the last time -> if it's too old, send an
>> inquiry and wait a bit longer
>>
>> (4) well, we have a recent global file, it contains the database stat
>> entry and it's fresh enough -> tadaaaaaa, we're done
>
> Hmm, yes, I think this is what I was imagining. I had even considered
> that the timestamp would be removed from the per-db file as you suggest
> here.
So, here's v10 of the patch (based on the v9+v9a), that implements the
approach described above.
It turned out to be much easier than I expected (basically just a
rewrite of the pgstat_read_db_statsfile_timestamp() function.
I've done a fair amount of testing (and will do some more next week) but
it seems to work just fine - no errors, no measurable decrease of
performance etc.
regards
Tomas Vondra
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v10.patch | text/x-diff | 31.9 KB |
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-17 23:49:17 |
| Message-ID: | 51216C7D.8070006@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
just a few charts from our production system, illustrating the impact of
this patch. We've deployed this patch on January 12 on our systems
running 9.1 (i.e. a backpatch), so we do have enough data to do some
nice pics from it. I don't expect the changes made to the patch since
then to affect the impact significantly.
I've chosen two systems with large numbers of databases (over 1000 on
each), each database contains multiple (possibly hundreds or more).
The "cpu" first charts show quantiles of CPU usage, and assuming that
the system usage did not change, there's a clear drop by about 15%
percent in both cases. This is a 8-core system (on AWS), so this means a
save of about 120% of one core.
The "disk usage" charts show how much space was needed for the stats
(placed on tmpfs filesystem, mounted at /mnt/pg_tmp). The filesystem max
size is 400MB and the files require ~100MB. With the unpatched code the
space required was actually ~200MB because of the copying.
regards
Tomas
| Attachment | Content-Type | Size |
|---|---|---|
| system-a-cpu.png | image/png | 92.8 KB |
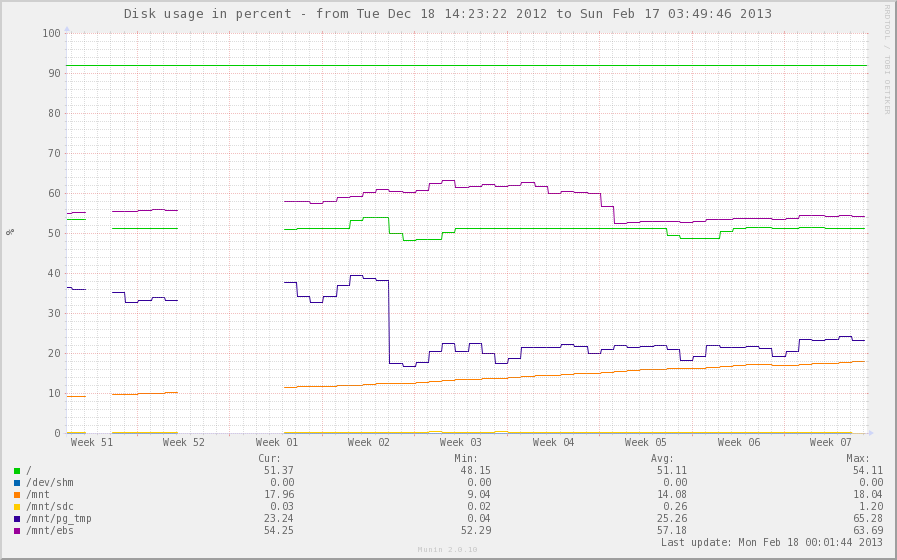
|
image/png | 43.7 KB |
| system-b-cpu.png | image/png | 80.8 KB |

|
image/png | 47.2 KB |
{kind=link}
{kind=link}
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-18 15:50:44 |
| Message-ID: | 20130218155043.GB4739@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra wrote:
> So, here's v10 of the patch (based on the v9+v9a), that implements the
> approach described above.
>
> It turned out to be much easier than I expected (basically just a
> rewrite of the pgstat_read_db_statsfile_timestamp() function.
Thanks. I'm giving this another look now. I think the new code means
we no longer need the first_write logic; just let the collector idle
until we get the first request. (If for some reason we considered that
we should really be publishing initial stats as early as possible, we
could just do a write_statsfiles(allDbs) call before entering the main
loop. But I don't see any reason to do this. If you do, please speak
up.)
Also, it seems to me that the new pgstat_db_requested() logic is
slightly bogus (in the "inefficient" sense, not the "incorrect" sense):
we should be comparing the timestamp of the request vs. what's already
on disk instead of blindly returning true if the list is nonempty. If
the request is older than the file, we don't need to write anything and
can discard the request. For example, suppose that backend A sends a
request for a DB; we write the file. If then quickly backend B also
requests stats for the same DB, with the current logic we'd go write the
file, but perhaps backend B would be fine with the file we already
wrote.
Another point is that I think there's a better way to handle nonexistant
files, instead of having to read the global file and all the DB records
to find the one we want. Just try to read the database file, and only
if that fails try to read the global file and compare the timestamp (so
there might be two timestamps for each DB, one in the global file and
one in the DB-specific file. I don't think this is a problem). The
point is avoid having to read the global file if possible.
So here's v11. I intend to commit this shortly. (I wanted to get it
out before lunch, but I introduced a silly bug that took me a bit to
fix.)
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| stats-split-v11.patch | text/x-diff | 39.0 KB |
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-18 18:43:14 |
| Message-ID: | 51227642.8080200@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 18.2.2013 16:50, Alvaro Herrera wrote:
> Tomas Vondra wrote:
>
>> So, here's v10 of the patch (based on the v9+v9a), that implements the
>> approach described above.
>>
>> It turned out to be much easier than I expected (basically just a
>> rewrite of the pgstat_read_db_statsfile_timestamp() function.
>
> Thanks. I'm giving this another look now. I think the new code means
> we no longer need the first_write logic; just let the collector idle
> until we get the first request. (If for some reason we considered that
> we should really be publishing initial stats as early as possible, we
> could just do a write_statsfiles(allDbs) call before entering the main
> loop. But I don't see any reason to do this. If you do, please speak
> up.)
>
> Also, it seems to me that the new pgstat_db_requested() logic is
> slightly bogus (in the "inefficient" sense, not the "incorrect" sense):
> we should be comparing the timestamp of the request vs. what's already
> on disk instead of blindly returning true if the list is nonempty. If
> the request is older than the file, we don't need to write anything and
> can discard the request. For example, suppose that backend A sends a
> request for a DB; we write the file. If then quickly backend B also
> requests stats for the same DB, with the current logic we'd go write the
> file, but perhaps backend B would be fine with the file we already
> wrote.
Hmmm, you're probably right.
> Another point is that I think there's a better way to handle nonexistant
> files, instead of having to read the global file and all the DB records
> to find the one we want. Just try to read the database file, and only
> if that fails try to read the global file and compare the timestamp (so
> there might be two timestamps for each DB, one in the global file and
> one in the DB-specific file. I don't think this is a problem). The
> point is avoid having to read the global file if possible.
I don't think that's a good idea. Keeping the timestamps at one place is
a significant simplification, and I don't think it's worth the
additional complexity. And the overhead is minimal.
So my vote on this change is -1.
>
> So here's v11. I intend to commit this shortly. (I wanted to get it
> out before lunch, but I introduced a silly bug that took me a bit to
> fix.)
;-)
Tomas
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-18 21:19:12 |
| Message-ID: | 20130218211912.GE4739@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra wrote:
> On 18.2.2013 16:50, Alvaro Herrera wrote:
> > Also, it seems to me that the new pgstat_db_requested() logic is
> > slightly bogus (in the "inefficient" sense, not the "incorrect" sense):
> > we should be comparing the timestamp of the request vs. what's already
> > on disk instead of blindly returning true if the list is nonempty. If
> > the request is older than the file, we don't need to write anything and
> > can discard the request. For example, suppose that backend A sends a
> > request for a DB; we write the file. If then quickly backend B also
> > requests stats for the same DB, with the current logic we'd go write the
> > file, but perhaps backend B would be fine with the file we already
> > wrote.
>
> Hmmm, you're probably right.
I left it as is for now; I think it warrants revisiting.
> > Another point is that I think there's a better way to handle nonexistant
> > files, instead of having to read the global file and all the DB records
> > to find the one we want. Just try to read the database file, and only
> > if that fails try to read the global file and compare the timestamp (so
> > there might be two timestamps for each DB, one in the global file and
> > one in the DB-specific file. I don't think this is a problem). The
> > point is avoid having to read the global file if possible.
>
> I don't think that's a good idea. Keeping the timestamps at one place is
> a significant simplification, and I don't think it's worth the
> additional complexity. And the overhead is minimal.
>
> So my vote on this change is -1.
Fair enough.
I have pushed it now. Further testing, of course, is always welcome.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-19 04:46:09 |
| Message-ID: | 20130219044609.GG4739@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Alvaro Herrera wrote:
> I have pushed it now. Further testing, of course, is always welcome.
Mastodon failed:
http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2013-02-19%2000%3A00%3A01
probably worth investigating a bit; we might have broken something.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-19 10:08:34 |
| Message-ID: | 7af5e415c3a459e1c85c5c1db033772a@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Dne 19.02.2013 05:46, Alvaro Herrera napsal:
> Alvaro Herrera wrote:
>
>> I have pushed it now. Further testing, of course, is always
>> welcome.
>
> Mastodon failed:
>
> http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2013-02-19%2000%3A00%3A01
>
> probably worth investigating a bit; we might have broken something.
Hmmm, interesting. A single Windows machine, while the other Windows
machines seem to work fine (although some of them were not built for a
few weeks).
I'll look into that, but I have no clue why this might happen. Except
maybe for some unexpected timing issue or something ...
Tomas
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-19 10:27:14 |
| Message-ID: | 23532.1361269634@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tv(at)fuzzy(dot)cz> writes:
> Dne 19.02.2013 05:46, Alvaro Herrera napsal:
>> Mastodon failed:
>> http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2013-02-19%2000%3A00%3A01
>>
>> probably worth investigating a bit; we might have broken something.
> Hmmm, interesting. A single Windows machine, while the other Windows
> machines seem to work fine (although some of them were not built for a
> few weeks).
Could be random chance --- we've seen the same failure before, eg
http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2012-11-25%2006%3A00%3A00
regards, tom lane
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-19 16:58:28 |
| Message-ID: | 9e6e1731b4e8b2a4fe028986a5b4f1d6@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Dne 19.02.2013 11:27, Tom Lane napsal:
> Tomas Vondra <tv(at)fuzzy(dot)cz> writes:
>> Dne 19.02.2013 05:46, Alvaro Herrera napsal:
>>> Mastodon failed:
>>>
>>> http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2013-02-19%2000%3A00%3A01
>>>
>>> probably worth investigating a bit; we might have broken something.
>
>> Hmmm, interesting. A single Windows machine, while the other Windows
>> machines seem to work fine (although some of them were not built for
>> a
>> few weeks).
>
> Could be random chance --- we've seen the same failure before, eg
>
>
> http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2012-11-25%2006%3A00%3A00
Maybe. But why does random chance happens to me only with regression
tests and not lottery, like to normal people?
Tomas
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-19 21:42:43 |
| Message-ID: | 5123F1D3.30303@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 19.2.2013 11:27, Tom Lane wrote:
> Tomas Vondra <tv(at)fuzzy(dot)cz> writes:
>> Dne 19.02.2013 05:46, Alvaro Herrera napsal:
>>> Mastodon failed:
>>> http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2013-02-19%2000%3A00%3A01
>>>
>>> probably worth investigating a bit; we might have broken something.
>
>> Hmmm, interesting. A single Windows machine, while the other Windows
>> machines seem to work fine (although some of them were not built for a
>> few weeks).
>
> Could be random chance --- we've seen the same failure before, eg
>
> http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=mastodon&dt=2012-11-25%2006%3A00%3A00
>
> regards, tom lane
I'm looking at that test, and I'm not really sure about a few details.
First, this function seems pretty useless to me:
=======================================================================
create function wait_for_stats() returns void as $$
declare
start_time timestamptz := clock_timestamp();
updated bool;
begin
-- we don't want to wait forever; loop will exit after 30 seconds
for i in 1 .. 300 loop
-- check to see if indexscan has been sensed
SELECT (st.idx_scan >= pr.idx_scan + 1) INTO updated
FROM pg_stat_user_tables AS st, pg_class AS cl, prevstats AS pr
WHERE st.relname='tenk2' AND cl.relname='tenk2';
exit when updated;
-- wait a little
perform pg_sleep(0.1);
-- reset stats snapshot so we can test again
perform pg_stat_clear_snapshot();
end loop;
-- report time waited in postmaster log (where it won't change test
output)
raise log 'wait_for_stats delayed % seconds',
extract(epoch from clock_timestamp() - start_time);
end
$$ language plpgsql;
=======================================================================
AFAIK the stats remain the same within a transaction, and as a function
runs within a transaction, it will either get new data on the first
iteration, or it will run all 300 of them. I've checked several
buildfarm members and I'm yet to see a single duration between 12ms and
30sec.
So IMHO we can replace the function call with pg_sleep(30) and we'll get
about the same effect.
But this obviously does not answer the question why it failed, although
on both occasions there's this log message:
[50b1b7fa.0568:14] LOG: wait_for_stats delayed 34.75 seconds
which essentialy means the stats were not updated before the call to
wait_for_stats().
Anyway, there are these two failing queries:
=======================================================================
-- check effects
SELECT st.seq_scan >= pr.seq_scan + 1,
st.seq_tup_read >= pr.seq_tup_read + cl.reltuples,
st.idx_scan >= pr.idx_scan + 1,
st.idx_tup_fetch >= pr.idx_tup_fetch + 1
FROM pg_stat_user_tables AS st, pg_class AS cl, prevstats AS pr
WHERE st.relname='tenk2' AND cl.relname='tenk2';
?column? | ?column? | ?column? | ?column?
----------+----------+----------+----------
t | t | t | t
(1 row)
SELECT st.heap_blks_read + st.heap_blks_hit >= pr.heap_blks + cl.relpages,
st.idx_blks_read + st.idx_blks_hit >= pr.idx_blks + 1
FROM pg_statio_user_tables AS st, pg_class AS cl, prevstats AS pr
WHERE st.relname='tenk2' AND cl.relname='tenk2';
?column? | ?column?
----------+----------
t | t
(1 row)
=======================================================================
The first one returns just falses, the second one retuns either (t,f) or
(f,f) - for the two failures posted by Alvaro and TL earlier today.
I'm really wondering how that could happen. The only thing that I can
think of is some strange timing issue, causing lost requests to write
the stats or maybe some of the stats updates. Hmmm, IIRC the stats are
sent over UDP - couldn't that be related?
Tomas
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-19 22:31:17 |
| Message-ID: | 20130219223116.GA4158@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra wrote:
> AFAIK the stats remain the same within a transaction, and as a function
> runs within a transaction, it will either get new data on the first
> iteration, or it will run all 300 of them. I've checked several
> buildfarm members and I'm yet to see a single duration between 12ms and
> 30sec.
No, there's a call to pg_stat_clear_snapshot() that takes care of that.
> I'm really wondering how that could happen. The only thing that I can
> think of is some strange timing issue, causing lost requests to write
> the stats or maybe some of the stats updates. Hmmm, IIRC the stats are
> sent over UDP - couldn't that be related?
yes, UDP packet drops can certainly happen. This is considered a
feature (do not cause backends to block when the network socket to stat
collector is swamped; it's better to lose some stat messages instead).
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-19 22:43:27 |
| Message-ID: | 5124000F.6090704@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 19.2.2013 23:31, Alvaro Herrera wrote:> Tomas Vondra wrote:
>
>> AFAIK the stats remain the same within a transaction, and as a
>> function runs within a transaction, it will either get new data on
>> the first iteration, or it will run all 300 of them. I've checked
>> several buildfarm members and I'm yet to see a single duration
>> between 12ms and 30sec.
>
> No, there's a call to pg_stat_clear_snapshot() that takes care of
> that.
Aha! Missed that for some reason. Thanks.
>
>> I'm really wondering how that could happen. The only thing that I
>> can think of is some strange timing issue, causing lost requests to
>> write the stats or maybe some of the stats updates. Hmmm, IIRC the
>> stats are sent over UDP - couldn't that be related?
>
> yes, UDP packet drops can certainly happen. This is considered a
> feature (do not cause backends to block when the network socket to
> stat collector is swamped; it's better to lose some stat messages
> instead).
Is there anything we could add to the test to identify this? Something
that either shows "stats were sent" and "stats arrived" (maybe in the
log only), or that some UPD packets were dropped?
Tomas
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-20 03:59:45 |
| Message-ID: | CAMkU=1w+BGDzBX0B5CSwijxJjK6twrnnFdeeZ96OXuA32DZtQQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Feb 18, 2013 at 7:50 AM, Alvaro Herrera
<alvherre(at)2ndquadrant(dot)com> wrote:
>
> So here's v11. I intend to commit this shortly. (I wanted to get it
> out before lunch, but I introduced a silly bug that took me a bit to
> fix.)
On Windows with Mingw I get this:
pgstat.c:4389:8: warning: variable 'found' set but not used
[-Wunused-but-set-variable]
I don't get that on Linux, but I bet that is just the gcc version
(4.6.2 vs 4.4.6) rather than the OS. It looks like it is just a
useless variable, rather than any possible cause of the Windows "make
check" failure (which I can't reproduce).
Cheers,
Jeff
| From: | Kevin Grittner <kgrittn(at)ymail(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-20 16:47:03 |
| Message-ID: | 1361378823.63444.YahooMailNeo@web162904.mail.bf1.yahoo.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Janes <jeff(dot)janes(at)gmail(dot)com> wrote:
> Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> wrote:
>>
>> So here's v11. I intend to commit this shortly. (I wanted to get it
>> out before lunch, but I introduced a silly bug that took me a bit to
>> fix.)
>
> On Windows with Mingw I get this:
>
> pgstat.c:4389:8: warning: variable 'found' set but not used
> [-Wunused-but-set-variable]
>
> I don't get that on Linux, but I bet that is just the gcc version
> (4.6.2 vs 4.4.6) rather than the OS.
I get it on Linux with gcc version 4.7.2.
> It looks like it is just a useless variable
Agreed.
--
Kevin Grittner
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Tomas Vondra <tv(at)fuzzy(dot)cz>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2013-02-20 21:42:09 |
| Message-ID: | 20130220214209.GA9507@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Jeff Janes escribió:
> On Mon, Feb 18, 2013 at 7:50 AM, Alvaro Herrera
> <alvherre(at)2ndquadrant(dot)com> wrote:
> >
> > So here's v11. I intend to commit this shortly. (I wanted to get it
> > out before lunch, but I introduced a silly bug that took me a bit to
> > fix.)
>
> On Windows with Mingw I get this:
>
> pgstat.c:4389:8: warning: variable 'found' set but not used
> [-Wunused-but-set-variable]
>
> I don't get that on Linux, but I bet that is just the gcc version
> (4.6.2 vs 4.4.6) rather than the OS. It looks like it is just a
> useless variable, rather than any possible cause of the Windows "make
> check" failure (which I can't reproduce).
Hm, I remember looking at that code and thinking that the "return" there
might not be the best idea because it'd miss running the code that
checks for clock skew; and so the "found" was necessary because the
return was to be taken out. But on second thought, a database for which the
loop terminates early has already run the clock-skew detection code
recently, so that's probably not worth worrying about.
IOW I will just remove that variable. Thanks for the notice.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Noah Misch <noah(at)leadboat(dot)com> |
|---|---|
| To: | Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Tomas Vondra <tv(at)fuzzy(dot)cz> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2015-12-22 14:49:50 |
| Message-ID: | 20151222144950.GA2553834@tornado.leadboat.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Feb 18, 2013 at 06:19:12PM -0300, Alvaro Herrera wrote:
> I have pushed it now. Further testing, of course, is always welcome.
While investigating stats.sql buildfarm failures, mostly on animals axolotl
and shearwater, I found that this patch (commit 187492b) inadvertently removed
the collector's ability to coalesce inquiries. Every PGSTAT_MTYPE_INQUIRY
received now causes one stats file write. Before, pgstat_recv_inquiry() did:
if (msg->inquiry_time > last_statrequest)
last_statrequest = msg->inquiry_time;
and pgstat_write_statsfile() did:
globalStats.stats_timestamp = GetCurrentTimestamp();
... (work of writing a stats file) ...
last_statwrite = globalStats.stats_timestamp;
last_statrequest = last_statwrite;
If the collector entered pgstat_write_statsfile() with more inquiries waiting
in its socket receive buffer, it would ignore them as being too old once it
finished the write and resumed message processing. Commit 187492b converted
last_statrequest to a "last_statrequests" list that we wipe after each write.
I modeled a machine with slow stats writes using the attached diagnostic patch
(not for commit). It has pgstat_write_statsfiles() sleep just before renaming
the temporary file, and it logs each stats message received. A three second
delay causes stats.sql to fail the way it did on shearwater[1] and on
axolotl[2]. Inquiries accumulate until the socket receive buffer overflows,
at which point the socket drops stats messages whose effects we later test
for. The 3s delay makes us drop some 85% of installcheck stats messages.
Logs from a single VACUUM show receipt of five inquiries ("stats 1:") with 3s
between them:
24239 2015-12-10 04:21:03.439 GMT LOG: connection authorized: user=nmisch database=test
24236 2015-12-10 04:21:03.454 GMT LOG: stats 2: 1888 + 936 = 2824
24236 2015-12-10 04:21:03.454 GMT LOG: stats 2: 2824 + 376 = 3200
24236 2015-12-10 04:21:03.454 GMT LOG: stats 2: 3200 + 824 = 4024
24239 2015-12-10 04:21:03.455 GMT LOG: statement: vacuum pg_class
24236 2015-12-10 04:21:03.455 GMT LOG: stats 1: 4024 + 32 = 4056
24236 2015-12-10 04:21:06.458 GMT LOG: stats 12: 4056 + 88 = 4144
24236 2015-12-10 04:21:06.458 GMT LOG: stats 1: 4144 + 32 = 4176
24239 2015-12-10 04:21:06.463 GMT LOG: disconnection: session time: 0:00:03.025 user=nmisch database=test host=[local]
24236 2015-12-10 04:21:09.486 GMT LOG: stats 1: 4176 + 32 = 4208
24236 2015-12-10 04:21:12.503 GMT LOG: stats 1: 4208 + 32 = 4240
24236 2015-12-10 04:21:15.519 GMT LOG: stats 1: 4240 + 32 = 4272
24236 2015-12-10 04:21:18.535 GMT LOG: stats 9: 4272 + 48 = 4320
24236 2015-12-10 04:21:18.535 GMT LOG: stats 2: 4320 + 936 = 5256
24236 2015-12-10 04:21:18.535 GMT LOG: stats 2: 5256 + 376 = 5632
24236 2015-12-10 04:21:18.535 GMT LOG: stats 2: 5632 + 264 = 5896
24236 2015-12-10 04:21:18.535 GMT LOG: stats 12: 5896 + 88 = 5984
As for how to fix this, the most direct translation of the old logic is to
retain last_statrequests entries that could help coalesce inquiries. I lean
toward that for an initial, back-patched fix. It would be good, though, to
process two closely-spaced, different-database inquiries in one
pgstat_write_statsfiles() call. We do one-database writes and all-databases
writes, but we never write "1 < N < all" databases despite the code prepared
to do so. I tried calling pgstat_write_statsfiles() only when the socket
receive buffer empties. That's dead simple to implement and aggressively
coalesces inquiries (even a 45s sleep did not break stats.sql), but it starves
inquirers if the socket receive buffer stays full persistently. Ideally, I'd
want to process inquiries when the buffer empties _or_ when the oldest inquiry
is X seconds old. I don't have a more-specific design in mind, though.
Thanks,
nm
[1] http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=shearwater&dt=2015-09-23%2002%3A08%3A31
[2] http://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=axolotl&dt=2015-08-04%2019%3A31%3A22
| Attachment | Content-Type | Size |
|---|---|---|
| stat-coalesce-v1.patch | text/plain | 1.9 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Noah Misch <noah(at)leadboat(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-02-01 18:03:45 |
| Message-ID: | 56AF9E01.8010405@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 12/22/2015 03:49 PM, Noah Misch wrote:
> On Mon, Feb 18, 2013 at 06:19:12PM -0300, Alvaro Herrera wrote:
>> I have pushed it now. Further testing, of course, is always welcome.
>
> While investigating stats.sql buildfarm failures, mostly on animals axolotl
> and shearwater, I found that this patch (commit 187492b) inadvertently removed
> the collector's ability to coalesce inquiries. Every PGSTAT_MTYPE_INQUIRY
> received now causes one stats file write. Before, pgstat_recv_inquiry() did:
>
> if (msg->inquiry_time > last_statrequest)
> last_statrequest = msg->inquiry_time;
>
> and pgstat_write_statsfile() did:
>
> globalStats.stats_timestamp = GetCurrentTimestamp();
> ... (work of writing a stats file) ...
> last_statwrite = globalStats.stats_timestamp;
> last_statrequest = last_statwrite;
>
> If the collector entered pgstat_write_statsfile() with more inquiries waiting
> in its socket receive buffer, it would ignore them as being too old once it
> finished the write and resumed message processing. Commit 187492b converted
> last_statrequest to a "last_statrequests" list that we wipe after each write.
So essentially we remove the list of requests, and thus on the next
round we don't know the timestamp of the last request and write the file
again unnecessarily. Do I get that right?
What if we instead kept the list but marked the requests as 'invalid' so
that we know the timestamp? In that case we'd be able to do pretty much
exactly what the original code did (but at per-db granularity).
We'd have to cleanup the list once in a while not to grow excessively
large, but something like removing entries older than
PGSTAT_STAT_INTERVAL should be enough.
Actually, I think that was the idea when I wrote the patch, but
apparently I got distracted and it did not make it into the code.
>
> I modeled a machine with slow stats writes using the attached diagnostic patch
> (not for commit). It has pgstat_write_statsfiles() sleep just before renaming
> the temporary file, and it logs each stats message received. A three second
> delay causes stats.sql to fail the way it did on shearwater[1] and on
> axolotl[2]. Inquiries accumulate until the socket receive buffer overflows,
> at which point the socket drops stats messages whose effects we later test
> for. The 3s delay makes us drop some 85% of installcheck stats messages.
> Logs from a single VACUUM show receipt of five inquiries ("stats 1:") with 3s
> between them:
>
> 24239 2015-12-10 04:21:03.439 GMT LOG: connection authorized: user=nmisch database=test
> 24236 2015-12-10 04:21:03.454 GMT LOG: stats 2: 1888 + 936 = 2824
> 24236 2015-12-10 04:21:03.454 GMT LOG: stats 2: 2824 + 376 = 3200
> 24236 2015-12-10 04:21:03.454 GMT LOG: stats 2: 3200 + 824 = 4024
> 24239 2015-12-10 04:21:03.455 GMT LOG: statement: vacuum pg_class
> 24236 2015-12-10 04:21:03.455 GMT LOG: stats 1: 4024 + 32 = 4056
> 24236 2015-12-10 04:21:06.458 GMT LOG: stats 12: 4056 + 88 = 4144
> 24236 2015-12-10 04:21:06.458 GMT LOG: stats 1: 4144 + 32 = 4176
> 24239 2015-12-10 04:21:06.463 GMT LOG: disconnection: session time: 0:00:03.025 user=nmisch database=test host=[local]
> 24236 2015-12-10 04:21:09.486 GMT LOG: stats 1: 4176 + 32 = 4208
> 24236 2015-12-10 04:21:12.503 GMT LOG: stats 1: 4208 + 32 = 4240
> 24236 2015-12-10 04:21:15.519 GMT LOG: stats 1: 4240 + 32 = 4272
> 24236 2015-12-10 04:21:18.535 GMT LOG: stats 9: 4272 + 48 = 4320
> 24236 2015-12-10 04:21:18.535 GMT LOG: stats 2: 4320 + 936 = 5256
> 24236 2015-12-10 04:21:18.535 GMT LOG: stats 2: 5256 + 376 = 5632
> 24236 2015-12-10 04:21:18.535 GMT LOG: stats 2: 5632 + 264 = 5896
> 24236 2015-12-10 04:21:18.535 GMT LOG: stats 12: 5896 + 88 = 5984
>
>
> As for how to fix this, the most direct translation of the old logic is to
> retain last_statrequests entries that could help coalesce inquiries.I lean
> toward that for an initial, back-patched fix.
That seems reasonable and I believe it's pretty much the idea I came up
with above, right? Depending on how you define "entries that could help
coalesce inquiries".
> It would be good, though, to
> process two closely-spaced, different-database inquiries in one
> pgstat_write_statsfiles() call. We do one-database writes and all-databases
> writes, but we never write "1 < N < all" databases despite the code prepared
> to do so. I tried calling pgstat_write_statsfiles() only when the socket
> receive buffer empties. That's dead simple to implement and aggressively
> coalesces inquiries (even a 45s sleep did not break stats.sql), but it starves
> inquirers if the socket receive buffer stays full persistently. Ideally, I'd
> want to process inquiries when the buffer empties _or_ when the oldest inquiry
> is X seconds old. I don't have a more-specific design in mind, though.
That's a nice idea, but I agree that binding the coalescing to buffer
like this seems like a pretty bad idea exactly because of the starving.
What might work though is if we could look at how much data is there in
the buffer, process only those requests and then write the stats files.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Noah Misch <noah(at)leadboat(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-02-03 05:46:59 |
| Message-ID: | 20160203054659.GA4135993@tornado.leadboat.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Feb 01, 2016 at 07:03:45PM +0100, Tomas Vondra wrote:
> On 12/22/2015 03:49 PM, Noah Misch wrote:
> >On Mon, Feb 18, 2013 at 06:19:12PM -0300, Alvaro Herrera wrote:
> >>I have pushed it now. Further testing, of course, is always welcome.
> >
> >While investigating stats.sql buildfarm failures, mostly on animals axolotl
> >and shearwater, I found that this patch (commit 187492b) inadvertently removed
> >the collector's ability to coalesce inquiries. Every PGSTAT_MTYPE_INQUIRY
> >received now causes one stats file write. Before, pgstat_recv_inquiry() did:
> >
> > if (msg->inquiry_time > last_statrequest)
> > last_statrequest = msg->inquiry_time;
> >
> >and pgstat_write_statsfile() did:
> >
> > globalStats.stats_timestamp = GetCurrentTimestamp();
> >... (work of writing a stats file) ...
> > last_statwrite = globalStats.stats_timestamp;
> > last_statrequest = last_statwrite;
> >
> >If the collector entered pgstat_write_statsfile() with more inquiries waiting
> >in its socket receive buffer, it would ignore them as being too old once it
> >finished the write and resumed message processing. Commit 187492b converted
> >last_statrequest to a "last_statrequests" list that we wipe after each write.
>
> So essentially we remove the list of requests, and thus on the next round we
> don't know the timestamp of the last request and write the file again
> unnecessarily. Do I get that right?
Essentially right. Specifically, for each database, we must remember the
globalStats.stats_timestamp of the most recent write. It could be okay to
forget the last request timestamp. (I now doubt I picked the best lines to
quote, above.)
> What if we instead kept the list but marked the requests as 'invalid' so
> that we know the timestamp? In that case we'd be able to do pretty much
> exactly what the original code did (but at per-db granularity).
The most natural translation of the old code would be to add a write_time
field to struct DBWriteRequest. One can infer "invalid" from write_time and
request_time. There are other reasonable designs, though.
> We'd have to cleanup the list once in a while not to grow excessively large,
> but something like removing entries older than PGSTAT_STAT_INTERVAL should
> be enough.
Specifically, if you assume the socket delivers messages in the order sent,
you may as well discard entries having write_time at least
PGSTAT_STAT_INTERVAL older than the most recent cutoff_time seen in a
PgStat_MsgInquiry. That delivery order assumption does not hold in general,
but I expect it's close enough for this purpose.
> >As for how to fix this, the most direct translation of the old logic is to
> >retain last_statrequests entries that could help coalesce inquiries.I lean
> >toward that for an initial, back-patched fix.
>
> That seems reasonable and I believe it's pretty much the idea I came up with
> above, right? Depending on how you define "entries that could help coalesce
> inquiries".
Yes.
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Noah Misch <noah(at)leadboat(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-02-03 10:23:40 |
| Message-ID: | 56B1D52C.8000107@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 02/03/2016 06:46 AM, Noah Misch wrote:
> On Mon, Feb 01, 2016 at 07:03:45PM +0100, Tomas Vondra wrote:
>> On 12/22/2015 03:49 PM, Noah Misch wrote:
...
>>> If the collector entered pgstat_write_statsfile() with more
>>> inquiries waiting in its socket receive buffer, it would ignore
>>> them as being too old once it finished the write and resumed
>>> message processing. Commit 187492b converted last_statrequest to
>>> a "last_statrequests" list that we wipe after each write.
>>
>> So essentially we remove the list of requests, and thus on the next
>> round we don't know the timestamp of the last request and write the
>> file again unnecessarily. Do I get that right?
>
> Essentially right. Specifically, for each database, we must remember
> the globalStats.stats_timestamp of the most recent write. It could be
> okay to forget the last request timestamp. (I now doubt I picked the
> best lines to quote, above.)
>
>> What if we instead kept the list but marked the requests as
>> 'invalid' so that we know the timestamp? In that case we'd be able
>> to do pretty much exactly what the original code did (but at per-db
>> granularity).
>
> The most natural translation of the old code would be to add a
> write_time field to struct DBWriteRequest. One can infer "invalid"
> from write_time and request_time. There are other reasonable designs,
> though.
OK, makes sense. I'll look into that.
>
>> We'd have to cleanup the list once in a while not to grow
>> excessively large, but something like removing entries older than
>> PGSTAT_STAT_INTERVAL should be enough.
>
> Specifically, if you assume the socket delivers messages in the order
> sent, you may as well discard entries having write_time at least
> PGSTAT_STAT_INTERVAL older than the most recent cutoff_time seen in a
> PgStat_MsgInquiry. That delivery order assumption does not hold in
> general, but I expect it's close enough for this purpose.
Agreed. If I get that right, it might result in some false negatives (in
the sense that we'll remove a record too early, forcing us to write the
database file again). But I expect that to be a rare case.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Noah Misch <noah(at)leadboat(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-03-03 05:08:07 |
| Message-ID: | 56D7C6B7.2000600@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 02/03/2016 06:46 AM, Noah Misch wrote:
> On Mon, Feb 01, 2016 at 07:03:45PM +0100, Tomas Vondra wrote:
>> On 12/22/2015 03:49 PM, Noah Misch wrote:
>>> On Mon, Feb 18, 2013 at 06:19:12PM -0300, Alvaro Herrera wrote:
>>>> I have pushed it now. Further testing, of course, is always welcome.
>>>
>>> While investigating stats.sql buildfarm failures, mostly on animals
>>> axolotl and shearwater, I found that this patch (commit 187492b)
>>> inadvertently removed the collector's ability to coalesce inquiries.
>>> Every PGSTAT_MTYPE_INQUIRY received now causes one stats file write.
>>> Before, pgstat_recv_inquiry() did:
>>>
>>> if (msg->inquiry_time > last_statrequest)
>>> last_statrequest = msg->inquiry_time;
>>>
>>> and pgstat_write_statsfile() did:
>>>
>>> globalStats.stats_timestamp = GetCurrentTimestamp();
>>> ... (work of writing a stats file) ...
>>> last_statwrite = globalStats.stats_timestamp;
>>> last_statrequest = last_statwrite;
>>>
>>> If the collector entered pgstat_write_statsfile() with more inquiries
>>> waiting in its socket receive buffer, it would ignore them as being too
>>> old once it finished the write and resumed message processing. Commit
>>> 187492b converted last_statrequest to a "last_statrequests" list that we
>>> wipe after each write.
So I've been looking at this today, and I think the attached patch should do
the trick. I can't really verify it, because I've been unable to reproduce the
non-coalescing - I presume it requires much slower system (axolotl is RPi, not
sure about shearwater).
The patch simply checks DBEntry,stats_timestamp in pgstat_recv_inquiry() and
ignores requests that are already resolved by the last write (maybe this should
accept a file written up to PGSTAT_STAT_INTERVAL in the past).
The required field is already in DBEntry (otherwise it'd be impossible to
determine if backends need to send inquiries or not), so this is pretty trivial
change. I can't think of a simpler patch.
Can you try applying the patch on a machine where the problem is reproducible?
I might have some RPi machines laying around (for other purposes).
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| pgstat-coalesce-v1.patch | binary/octet-stream | 1.3 KB |
| From: | Noah Misch <noah(at)leadboat(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-03-13 22:46:41 |
| Message-ID: | 20160313224641.GA1054873@tornado.leadboat.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Mar 03, 2016 at 06:08:07AM +0100, Tomas Vondra wrote:
> On 02/03/2016 06:46 AM, Noah Misch wrote:
> >On Mon, Feb 01, 2016 at 07:03:45PM +0100, Tomas Vondra wrote:
> >>On 12/22/2015 03:49 PM, Noah Misch wrote:
> >>>On Mon, Feb 18, 2013 at 06:19:12PM -0300, Alvaro Herrera wrote:
> >>>>I have pushed it now. Further testing, of course, is always welcome.
> >>>
> >>>While investigating stats.sql buildfarm failures, mostly on animals
> >>>axolotl and shearwater, I found that this patch (commit 187492b)
> >>>inadvertently removed the collector's ability to coalesce inquiries.
> >>>Every PGSTAT_MTYPE_INQUIRY received now causes one stats file write.
> >>>Before, pgstat_recv_inquiry() did:
> >>>
> >>> if (msg->inquiry_time > last_statrequest)
> >>> last_statrequest = msg->inquiry_time;
> >>>
> >>>and pgstat_write_statsfile() did:
> >>>
> >>> globalStats.stats_timestamp = GetCurrentTimestamp();
> >>>... (work of writing a stats file) ...
> >>> last_statwrite = globalStats.stats_timestamp;
> >>> last_statrequest = last_statwrite;
> >>>
> >>>If the collector entered pgstat_write_statsfile() with more inquiries
> >>>waiting in its socket receive buffer, it would ignore them as being too
> >>>old once it finished the write and resumed message processing. Commit
> >>>187492b converted last_statrequest to a "last_statrequests" list that we
> >>>wipe after each write.
>
> So I've been looking at this today, and I think the attached patch should do
> the trick. I can't really verify it, because I've been unable to reproduce the
> non-coalescing - I presume it requires much slower system (axolotl is RPi, not
> sure about shearwater).
>
> The patch simply checks DBEntry,stats_timestamp in pgstat_recv_inquiry() and
> ignores requests that are already resolved by the last write (maybe this
> should accept a file written up to PGSTAT_STAT_INTERVAL in the past).
>
> The required field is already in DBEntry (otherwise it'd be impossible to
> determine if backends need to send inquiries or not), so this is pretty
> trivial change. I can't think of a simpler patch.
>
> Can you try applying the patch on a machine where the problem is
> reproducible? I might have some RPi machines laying around (for other
> purposes).
I've not attempted to study the behavior on slow hardware. Instead, my report
used stat-coalesce-v1.patch[1] to simulate slow writes. (That diagnostic
patch no longer applies cleanly, so I'm attaching a rebased version. I've
changed the patch name from "stat-coalesce" to "slow-stat-simulate" to
more-clearly distinguish it from the "pgstat-coalesce" patch.) Problems
remain after applying your patch; consider "VACUUM pg_am" behavior:
9.2 w/ stat-coalesce-v1.patch:
VACUUM returns in 3s, stats collector writes each file 1x over 3s
HEAD w/ slow-stat-simulate-v2.patch:
VACUUM returns in 3s, stats collector writes each file 5x over 15s
HEAD w/ slow-stat-simulate-v2.patch and your patch:
VACUUM returns in 10s, stats collector writes no files over 10s
[1] http://www.postgresql.org/message-id/20151222144950.GA2553834@tornado.leadboat.com
| Attachment | Content-Type | Size |
|---|---|---|
| slow-stat-simulate-v2.patch | text/plain | 2.0 KB |
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Noah Misch <noah(at)leadboat(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-03-14 01:00:03 |
| Message-ID: | 1457917203.10232.2.camel@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, 2016-03-13 at 18:46 -0400, Noah Misch wrote:
> On Thu, Mar 03, 2016 at 06:08:07AM +0100, Tomas Vondra wrote:
> >
> > On 02/03/2016 06:46 AM, Noah Misch wrote:
> > >
> > > On Mon, Feb 01, 2016 at 07:03:45PM +0100, Tomas Vondra wrote:
> > > >
> > > > On 12/22/2015 03:49 PM, Noah Misch wrote:
> > > > >
> > > > > On Mon, Feb 18, 2013 at 06:19:12PM -0300, Alvaro Herrera
> > > > > wrote:
> > > > > >
> > > > > > I have pushed it now. Further testing, of course, is
> > > > > > always welcome.
> > > > > While investigating stats.sql buildfarm failures, mostly on
> > > > > animals
> > > > > axolotl and shearwater, I found that this patch (commit
> > > > > 187492b)
> > > > > inadvertently removed the collector's ability to coalesce
> > > > > inquiries.
> > > > > Every PGSTAT_MTYPE_INQUIRY received now causes one stats file
> > > > > write.
> > > > > Before, pgstat_recv_inquiry() did:
> > > > >
> > > > > if (msg->inquiry_time > last_statrequest)
> > > > > last_statrequest = msg->inquiry_time;
> > > > >
> > > > > and pgstat_write_statsfile() did:
> > > > >
> > > > > globalStats.stats_timestamp = GetCurrentTimestamp();
> > > > > ... (work of writing a stats file) ...
> > > > > last_statwrite = globalStats.stats_timestamp;
> > > > > last_statrequest = last_statwrite;
> > > > >
> > > > > If the collector entered pgstat_write_statsfile() with more
> > > > > inquiries
> > > > > waiting in its socket receive buffer, it would ignore them as
> > > > > being too
> > > > > old once it finished the write and resumed message
> > > > > processing. Commit
> > > > > 187492b converted last_statrequest to a "last_statrequests"
> > > > > list that we
> > > > > wipe after each write.
> > So I've been looking at this today, and I think the attached patch
> > should do
> > the trick. I can't really verify it, because I've been unable to
> > reproduce the
> > non-coalescing - I presume it requires much slower system (axolotl
> > is RPi, not
> > sure about shearwater).
> >
> > The patch simply checks DBEntry,stats_timestamp in
> > pgstat_recv_inquiry() and
> > ignores requests that are already resolved by the last write (maybe
> > this
> > should accept a file written up to PGSTAT_STAT_INTERVAL in the
> > past).
> >
> > The required field is already in DBEntry (otherwise it'd be
> > impossible to
> > determine if backends need to send inquiries or not), so this is
> > pretty
> > trivial change. I can't think of a simpler patch.
> >
> > Can you try applying the patch on a machine where the problem is
> > reproducible? I might have some RPi machines laying around (for
> > other
> > purposes).
> I've not attempted to study the behavior on slow hardware. Instead,
> my report
> used stat-coalesce-v1.patch[1] to simulate slow writes. (That
> diagnostic
> patch no longer applies cleanly, so I'm attaching a rebased
> version. I've
> changed the patch name from "stat-coalesce" to "slow-stat-simulate"
> to
> more-clearly distinguish it from the "pgstat-coalesce"
> patch.) Problems
> remain after applying your patch; consider "VACUUM pg_am" behavior:
>
> 9.2 w/ stat-coalesce-v1.patch:
> VACUUM returns in 3s, stats collector writes each file 1x over 3s
> HEAD w/ slow-stat-simulate-v2.patch:
> VACUUM returns in 3s, stats collector writes each file 5x over 15s
> HEAD w/ slow-stat-simulate-v2.patch and your patch:
> VACUUM returns in 10s, stats collector writes no files over 10s
Oh damn, the timestamp comparison in pgstat_recv_inquiry should be in
the opposite direction. After fixing that "VACUUM pg_am" completes in 3
seconds and writes each file just once.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| pgstat-coalesce-v2.patch | text/x-patch | 1.3 KB |
| From: | Noah Misch <noah(at)leadboat(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-03-14 06:14:20 |
| Message-ID: | 20160314061420.GA1064464@tornado.leadboat.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
[Aside: your new mail editor is rewrapping lines in quoted material, and the
result is messy. I have rerewrapped one paragraph below.]
On Mon, Mar 14, 2016 at 02:00:03AM +0100, Tomas Vondra wrote:
> On Sun, 2016-03-13 at 18:46 -0400, Noah Misch wrote:
> > I've not attempted to study the behavior on slow hardware. Instead, my
> > report used stat-coalesce-v1.patch[1] to simulate slow writes. (That
> > diagnostic patch no longer applies cleanly, so I'm attaching a rebased
> > version. I've changed the patch name from "stat-coalesce" to
> > "slow-stat-simulate" to more-clearly distinguish it from the
> > "pgstat-coalesce" patch.) Problems remain after applying your patch;
> > consider "VACUUM pg_am" behavior:
> >
> > 9.2 w/ stat-coalesce-v1.patch:
> > VACUUM returns in 3s, stats collector writes each file 1x over 3s
> > HEAD w/ slow-stat-simulate-v2.patch:
> > VACUUM returns in 3s, stats collector writes each file 5x over 15s
> > HEAD w/ slow-stat-simulate-v2.patch and your patch:
> > VACUUM returns in 10s, stats collector writes no files over 10s
>
> Oh damn, the timestamp comparison in pgstat_recv_inquiry should be in
> the opposite direction. After fixing that "VACUUM pg_am" completes in 3
> seconds and writes each file just once.
That fixes things. "make check" passes under an 8s stats write time.
> --- a/src/backend/postmaster/pgstat.c
> +++ b/src/backend/postmaster/pgstat.c
> @@ -4836,6 +4836,20 @@ pgstat_recv_inquiry(PgStat_MsgInquiry *msg, int len)
> }
>
> /*
> + * Ignore requests that are already resolved by the last write.
> + *
> + * We discard the queue of requests at the end of pgstat_write_statsfiles(),
> + * so the requests already waiting on the UDP socket at that moment can't
> + * be discarded in the previous loop.
> + *
> + * XXX Maybe this should also care about the clock skew, just like the
> + * block a few lines down.
Yes, it should. (The problem is large (>~100s), backward clock resets, not
skew.) A clock reset causing "msg->clock_time < dbentry->stats_timestamp"
will usually also cause "msg->cutoff_time < dbentry->stats_timestamp". Such
cases need the correction a few lines down.
The other thing needed here is to look through and update comments about
last_statrequests. For example, this loop is dead code due to us writing
files as soon as we receive one inquiry:
/*
* Find the last write request for this DB. If it's older than the
* request's cutoff time, update it; otherwise there's nothing to do.
*
* Note that if a request is found, we return early and skip the below
* check for clock skew. This is okay, since the only way for a DB
* request to be present in the list is that we have been here since the
* last write round.
*/
slist_foreach(iter, &last_statrequests) ...
I'm okay keeping the dead code for future flexibility, but the comment should
reflect that.
Thanks,
nm
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Noah Misch <noah(at)leadboat(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-03-14 12:33:08 |
| Message-ID: | 7552def8-c6bf-88b7-b028-549038a24798@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 03/14/2016 07:14 AM, Noah Misch wrote:
> [Aside: your new mail editor is rewrapping lines in quoted material, and the
> result is messy. I have rerewrapped one paragraph below.]
Thanks, I've noticed that too. I've been testing Evolution in the past
few days, and apparently the line wrapping algorithm is broken. I've
switched back to Thunderbird, so hopefully that'll fix it.
>
> On Mon, Mar 14, 2016 at 02:00:03AM +0100, Tomas Vondra wrote:
>> On Sun, 2016-03-13 at 18:46 -0400, Noah Misch wrote:
>>> I've not attempted to study the behavior on slow hardware. Instead, my
>>> report used stat-coalesce-v1.patch[1] to simulate slow writes. (That
>>> diagnostic patch no longer applies cleanly, so I'm attaching a rebased
>>> version. I've changed the patch name from "stat-coalesce" to
>>> "slow-stat-simulate" to more-clearly distinguish it from the
>>> "pgstat-coalesce" patch.) Problems remain after applying your patch;
>>> consider "VACUUM pg_am" behavior:
>>>
>>> 9.2 w/ stat-coalesce-v1.patch:
>>> VACUUM returns in 3s, stats collector writes each file 1x over 3s
>>> HEAD w/ slow-stat-simulate-v2.patch:
>>> VACUUM returns in 3s, stats collector writes each file 5x over 15s
>>> HEAD w/ slow-stat-simulate-v2.patch and your patch:
>>> VACUUM returns in 10s, stats collector writes no files over 10s
>>
>> Oh damn, the timestamp comparison in pgstat_recv_inquiry should be in
>> the opposite direction. After fixing that "VACUUM pg_am" completes in 3
>> seconds and writes each file just once.
>
> That fixes things. "make check" passes under an 8s stats write time.
OK, good.
>
>> --- a/src/backend/postmaster/pgstat.c
>> +++ b/src/backend/postmaster/pgstat.c
>> @@ -4836,6 +4836,20 @@ pgstat_recv_inquiry(PgStat_MsgInquiry *msg, int len)
>> }
>>
>> /*
>> + * Ignore requests that are already resolved by the last write.
>> + *
>> + * We discard the queue of requests at the end of pgstat_write_statsfiles(),
>> + * so the requests already waiting on the UDP socket at that moment can't
>> + * be discarded in the previous loop.
>> + *
>> + * XXX Maybe this should also care about the clock skew, just like the
>> + * block a few lines down.
>
> Yes, it should. (The problem is large (>~100s), backward clock resets, not
> skew.) A clock reset causing "msg->clock_time < dbentry->stats_timestamp"
> will usually also cause "msg->cutoff_time < dbentry->stats_timestamp". Such
> cases need the correction a few lines down.
I'll look into that. I have to admit I have a hard time reasoning about
the code handling clock skew, so it might take some time, though.
>
> The other thing needed here is to look through and update comments about
> last_statrequests. For example, this loop is dead code due to us writing
> files as soon as we receive one inquiry:
>
> /*
> * Find the last write request for this DB. If it's older than the
> * request's cutoff time, update it; otherwise there's nothing to do.
> *
> * Note that if a request is found, we return early and skip the below
> * check for clock skew. This is okay, since the only way for a DB
> * request to be present in the list is that we have been here since the
> * last write round.
> */
> slist_foreach(iter, &last_statrequests) ...
>
> I'm okay keeping the dead code for future flexibility, but the comment should
> reflect that.
Yes, that's another thing that I'd like to look into. Essentially the
problem is that we always process the inquiries one by one, so we never
actually see a list with more than a single element. Correct?
I think the best way to address that is to peek is to first check how
much data is in the UDP queue, and then fetching all of that before
actually doing the writes. Peeking at the number of requests first (or
even some reasonable hard-coded limit) should should prevent starving
the inquirers in case of a steady stream or inquiries.
regards
Tomas
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Noah Misch <noah(at)leadboat(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-03-15 02:04:41 |
| Message-ID: | 20160315020441.GB1092972@tornado.leadboat.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Mar 14, 2016 at 01:33:08PM +0100, Tomas Vondra wrote:
> On 03/14/2016 07:14 AM, Noah Misch wrote:
> >On Mon, Mar 14, 2016 at 02:00:03AM +0100, Tomas Vondra wrote:
> >>+ * XXX Maybe this should also care about the clock skew, just like the
> >>+ * block a few lines down.
> >
> >Yes, it should. (The problem is large (>~100s), backward clock resets, not
> >skew.) A clock reset causing "msg->clock_time < dbentry->stats_timestamp"
> >will usually also cause "msg->cutoff_time < dbentry->stats_timestamp". Such
> >cases need the correction a few lines down.
>
> I'll look into that. I have to admit I have a hard time reasoning about the
> code handling clock skew, so it might take some time, though.
No hurry; it would be no problem to delay this several months.
> >The other thing needed here is to look through and update comments about
> >last_statrequests. For example, this loop is dead code due to us writing
> >files as soon as we receive one inquiry:
> >
> > /*
> > * Find the last write request for this DB. If it's older than the
> > * request's cutoff time, update it; otherwise there's nothing to do.
> > *
> > * Note that if a request is found, we return early and skip the below
> > * check for clock skew. This is okay, since the only way for a DB
> > * request to be present in the list is that we have been here since the
> > * last write round.
> > */
> > slist_foreach(iter, &last_statrequests) ...
> >
> >I'm okay keeping the dead code for future flexibility, but the comment should
> >reflect that.
>
> Yes, that's another thing that I'd like to look into. Essentially the
> problem is that we always process the inquiries one by one, so we never
> actually see a list with more than a single element. Correct?
Correct.
> I think the best way to address that is to peek is to first check how much
> data is in the UDP queue, and then fetching all of that before actually
> doing the writes. Peeking at the number of requests first (or even some
> reasonable hard-coded limit) should should prevent starving the inquirers in
> case of a steady stream or inquiries.
Now that you mention it, a hard-coded limit sounds good: write the files for
pending inquiries whenever the socket empties or every N messages processed,
whichever comes first. I don't think the amount of pending UDP data is
portably available, and I doubt it's important. Breaking every, say, one
thousand messages will make the collector predictably responsive to inquiries,
and that is the important property.
I would lean toward making this part 9.7-only; it would be a distinct patch
from the one previously under discussion.
Thanks,
nm
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Noah Misch <noah(at)leadboat(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-03-19 00:38:30 |
| Message-ID: | 24f09c2d-e5bf-1f73-db54-8255c1280d32@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 03/15/2016 03:04 AM, Noah Misch wrote:
> On Mon, Mar 14, 2016 at 01:33:08PM +0100, Tomas Vondra wrote:
>> On 03/14/2016 07:14 AM, Noah Misch wrote:
>>> On Mon, Mar 14, 2016 at 02:00:03AM +0100, Tomas Vondra wrote:
>>>> + * XXX Maybe this should also care about the clock skew, just like the
>>>> + * block a few lines down.
>>>
>>> Yes, it should. (The problem is large (>~100s), backward clock resets, not
>>> skew.) A clock reset causing "msg->clock_time < dbentry->stats_timestamp"
>>> will usually also cause "msg->cutoff_time < dbentry->stats_timestamp". Such
>>> cases need the correction a few lines down.
>>
>> I'll look into that. I have to admit I have a hard time reasoning about the
>> code handling clock skew, so it might take some time, though.
>
> No hurry; it would be no problem to delay this several months.
Attached is a patch that should fix the coalescing, including the clock
skew detection. In the end I reorganized the code a bit, moving the
check at the end, after the clock skew detection. Otherwise I'd have to
do the clock skew detection on multiple places, and that seemed ugly.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| pgstat-coalesce-v3.patch | binary/octet-stream | 1.7 KB |
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-26 20:10:32 |
| Message-ID: | 24502.1464293432@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> Attached is a patch that should fix the coalescing, including the clock
> skew detection. In the end I reorganized the code a bit, moving the
> check at the end, after the clock skew detection. Otherwise I'd have to
> do the clock skew detection on multiple places, and that seemed ugly.
I hadn't been paying any attention to this thread, I must confess.
But I rediscovered this no-coalescing problem while pursuing the poor
behavior for shared catalogs that Peter complained of in
https://www.postgresql.org/message-id/56AD41AC.1030509@gmx.net
I posted a patch at
https://www.postgresql.org/message-id/13023.1464213041@sss.pgh.pa.us
which I think is functionally equivalent to what you have here, but
it goes to some lengths to make the code more readable, whereas this
is just adding another layer of complication to something that's
already a mess (eg, the request_time field is quite useless as-is).
So I'd like to propose pushing that in place of this patch ... do you
care to review it first?
Reacting to the thread overall:
I see Noah's concern about wanting to merge the write work for requests
about different databases. I've got mixed feelings about that: it's
arguable that any such change would make things worse not better.
In particular, it's inevitable that trying to merge writes will result
in delaying the response to the first request, whether or not we are
able to merge anything. That's not good in itself, and it means that
we can't hope to merge requests over any very long interval, which very
possibly will prevent any merging from happening in real situations.
Also, considering that we know the stats collector can be pretty slow
to respond at all under load, I'm worried that this would result in
more outright failures.
Moreover, what we'd hope to gain from merging is fewer writes of the
global stats file and the shared-catalog stats file; but neither of
those are very big, so I'm skeptical of what we'd win.
In view of 52e8fc3e2, there's more or less no case in which we'd be
writing stats without writing stats for the shared catalogs. So I'm
tempted to propose that we try to reduce the overhead by merging the
shared-catalog stats back into the global-stats file, thereby halving
the filesystem metadata traffic for updating those.
regards, tom lane
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-27 01:43:35 |
| Message-ID: | 983f784e-994a-2445-6276-6fe128e82766@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 05/26/2016 10:10 PM, Tom Lane wrote:
> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> Attached is a patch that should fix the coalescing, including the clock
>> skew detection. In the end I reorganized the code a bit, moving the
>> check at the end, after the clock skew detection. Otherwise I'd have to
>> do the clock skew detection on multiple places, and that seemed ugly.
>
> I hadn't been paying any attention to this thread, I must confess.
> But I rediscovered this no-coalescing problem while pursuing the poor
> behavior for shared catalogs that Peter complained of in
> https://www.postgresql.org/message-id/56AD41AC.1030509@gmx.net
>
> I posted a patch at
> https://www.postgresql.org/message-id/13023.1464213041@sss.pgh.pa.us
> which I think is functionally equivalent to what you have here, but
> it goes to some lengths to make the code more readable, whereas this
> is just adding another layer of complication to something that's
> already a mess (eg, the request_time field is quite useless as-is).
> So I'd like to propose pushing that in place of this patch ... do
> you care to review it first?
I do care and I'll look at it over the next few days. FWIW when writing
that patch I intentionally refrained from major changes, as I think the
plan was to backpatch it. But +1 for more readable code from me.
>
> Reacting to the thread overall:
>
> I see Noah's concern about wanting to merge the write work for
> requests about different databases. I've got mixed feelings about
> that: it's arguable that any such change would make things worse not
> better. In particular, it's inevitable that trying to merge writes
> will result in delaying the response to the first request, whether
> or not we are able to merge anything. That's not good in itself, and
> it means that we can't hope to merge requests over any very long
> interval, which very possibly will prevent any merging from
> happening in real situations. Also, considering that we know the
> stats collector can be pretty slow to respond at all under load, I'm
> worried that this would result in more outright failures.
>
> Moreover, what we'd hope to gain from merging is fewer writes of the
> global stats file and the shared-catalog stats file; but neither of
> those are very big, so I'm skeptical of what we'd win.
Yep. Clearly there's a trade-off between slowing down response to the
first request vs. speeding-up the whole process, but as you point out we
probably can't gain enough to justify that.
I wonder if that's still true on clusters with many databases (say,
shared systems with thousands of dbs). Perhaps walking the list just
once would save enough CPU to make this a win.
In any case, if we decide to abandon the idea of merging requests for
multiple databases, that probably means we can further simplify the
code. last_statrequests is a list but it actually never contains more
than just a single request. We kept it that way because of the plan to
add the merging. But if that's not worth it ...
>
> In view of 52e8fc3e2, there's more or less no case in which we'd be
> writing stats without writing stats for the shared catalogs. So I'm
> tempted to propose that we try to reduce the overhead by merging the
> shared-catalog stats back into the global-stats file, thereby
> halving the filesystem metadata traffic for updating those.
I find this a bit contradictory with the previous paragraph. If you
believe that reducing the filesystem metadata traffic will have a
measurable benefit, then surely merging writes for multiple dbs (thus
not writing the global/shared files multiple times) will have even
higher impact, no?
E.g. let's assume we're still writing the global+shared+db files for
each database. If there are requests for 10 databases, we'll write 30
files. If we merge those requests first, we're writing only 12 files.
So I'm not sure about the metadata traffic argument, we'd need to see
some numbers showing it really makes a difference.
That being said, I'm not opposed to merging the shared catalog into the
global-stats file - it's not really a separate database so having it in
a separate file is a bit weird.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Michael Paquier <michael(dot)paquier(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Noah Misch <noah(at)leadboat(dot)com>, PostgreSQL mailing lists <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-27 01:55:17 |
| Message-ID: | CAB7nPqTV4SD12qT3ru=Z7gt0vvWzGn22y_YyHOyRHHd1OGSD8g@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, May 26, 2016 at 6:43 PM, Tomas Vondra
<tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> On 05/26/2016 10:10 PM, Tom Lane wrote:
>> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> In view of 52e8fc3e2, there's more or less no case in which we'd be
>> writing stats without writing stats for the shared catalogs. So I'm
>> tempted to propose that we try to reduce the overhead by merging the
>> shared-catalog stats back into the global-stats file, thereby
>> halving the filesystem metadata traffic for updating those.
>
> [...]
>
> That being said, I'm not opposed to merging the shared catalog into the
> global-stats file - it's not really a separate database so having it in a
> separate file is a bit weird.
While looking at this stuff, to be honest I got surprised that shared
relation stats are in located in a file whose name depends on
InvalidOid, so +1 from here as well to merge that into the global
stats file.
--
Michael
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-27 02:25:04 |
| Message-ID: | 9300.1464315904@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> On 05/26/2016 10:10 PM, Tom Lane wrote:
>> In view of 52e8fc3e2, there's more or less no case in which we'd be
>> writing stats without writing stats for the shared catalogs. So I'm
>> tempted to propose that we try to reduce the overhead by merging the
>> shared-catalog stats back into the global-stats file, thereby
>> halving the filesystem metadata traffic for updating those.
> I find this a bit contradictory with the previous paragraph. If you
> believe that reducing the filesystem metadata traffic will have a
> measurable benefit, then surely merging writes for multiple dbs (thus
> not writing the global/shared files multiple times) will have even
> higher impact, no?
Well, my thinking is that this is something we could get "for free"
without any penalty in response time. Going further will require
some sort of tradeoff.
regards, tom lane
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-31 13:54:32 |
| Message-ID: | c3b0568c-3877-2a6e-97eb-fadd2e164460@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Hi,
On 05/26/2016 10:10 PM, Tom Lane wrote:
> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> Attached is a patch that should fix the coalescing, including the clock
>> skew detection. In the end I reorganized the code a bit, moving the
>> check at the end, after the clock skew detection. Otherwise I'd have to
>> do the clock skew detection on multiple places, and that seemed ugly.
>
> I hadn't been paying any attention to this thread, I must confess.
> But I rediscovered this no-coalescing problem while pursuing the poor
> behavior for shared catalogs that Peter complained of in
> https://www.postgresql.org/message-id/56AD41AC.1030509@gmx.net
>
> I posted a patch at
> https://www.postgresql.org/message-id/13023.1464213041@sss.pgh.pa.us
> which I think is functionally equivalent to what you have here, but
> it goes to some lengths to make the code more readable, whereas this
> is just adding another layer of complication to something that's
> already a mess (eg, the request_time field is quite useless as-is).
> So I'd like to propose pushing that in place of this patch ... do you
> care to review it first?
I've reviewed the patch today, and it seems fine to me - correct and
achieving the same goal as the patch posted to this thread (plus fixing
the issue with shared catalogs and fixing many comments).
FWIW do you still plan to back-patch this? Minimizing the amount of
changes was one of the things I had in mind when writing "my" patch,
which is why I ended up with parts that are less readable.
The one change I'm not quite sure about is the removal of clock skew
detection in pgstat_recv_inquiry(). You've removed the first check on
the inquiry, replacing it with this comment:
It seems sufficient to check for clock skew once per write round.
But the first check was comparing msg/req, while the second check looks
at dbentry/cur_ts. I don't see how those two clock skew check are
redundant - if they are, the comment should explain that I guess.
Another thing is that if you believe merging requests across databases
is a silly idea, maybe we should bite the bullet and replace the list of
requests with a single item. I'm not convinced about this, though.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-31 16:59:35 |
| Message-ID: | 8540.1464713975@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> On 05/26/2016 10:10 PM, Tom Lane wrote:
>> I posted a patch at
>> https://www.postgresql.org/message-id/13023.1464213041@sss.pgh.pa.us
>> which I think is functionally equivalent to what you have here, but
>> it goes to some lengths to make the code more readable, whereas this
>> is just adding another layer of complication to something that's
>> already a mess (eg, the request_time field is quite useless as-is).
>> So I'd like to propose pushing that in place of this patch ... do you
>> care to review it first?
> I've reviewed the patch today, and it seems fine to me - correct and
> achieving the same goal as the patch posted to this thread (plus fixing
> the issue with shared catalogs and fixing many comments).
Thanks for reviewing!
> FWIW do you still plan to back-patch this? Minimizing the amount of
> changes was one of the things I had in mind when writing "my" patch,
> which is why I ended up with parts that are less readable.
Yeah, I think it's a bug fix and should be back-patched. I'm not in
favor of making things more complicated just to reduce the number of
lines a patch touches.
> The one change I'm not quite sure about is the removal of clock skew
> detection in pgstat_recv_inquiry(). You've removed the first check on
> the inquiry, replacing it with this comment:
> It seems sufficient to check for clock skew once per write round.
> But the first check was comparing msg/req, while the second check looks
> at dbentry/cur_ts. I don't see how those two clock skew check are
> redundant - if they are, the comment should explain that I guess.
I'm confused here --- are you speaking of having removed
if (msg->cutoff_time > req->request_time)
req->request_time = msg->cutoff_time;
? That is not a check for clock skew, it's intending to be sure that
req->request_time reflects the latest request for this DB when we've seen
more than one request. But since req->request_time isn't actually being
used anywhere, it's useless code.
I reformatted the actual check for clock skew, but I do not think I
changed its behavior.
> Another thing is that if you believe merging requests across databases
> is a silly idea, maybe we should bite the bullet and replace the list of
> requests with a single item. I'm not convinced about this, though.
No, I don't want to do that either. We're not spending much code by
having pending_write_requests be a list rather than a single entry,
and we might eventually figure out a reasonable way to time the flushes
so that we can merge requests.
regards, tom lane
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-31 17:19:20 |
| Message-ID: | 046a9e6f-2170-a68e-31ae-805771d0228b@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 05/31/2016 06:59 PM, Tom Lane wrote:
> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> On 05/26/2016 10:10 PM, Tom Lane wrote:
>>> I posted a patch at
>>> https://www.postgresql.org/message-id/13023.1464213041@sss.pgh.pa.us
>>> which I think is functionally equivalent to what you have here, but
>>> it goes to some lengths to make the code more readable, whereas this
>>> is just adding another layer of complication to something that's
>>> already a mess (eg, the request_time field is quite useless as-is).
>>> So I'd like to propose pushing that in place of this patch ... do you
>>> care to review it first?
>
>> I've reviewed the patch today, and it seems fine to me - correct and
>> achieving the same goal as the patch posted to this thread (plus fixing
>> the issue with shared catalogs and fixing many comments).
>
> Thanks for reviewing!
>
>> FWIW do you still plan to back-patch this? Minimizing the amount of
>> changes was one of the things I had in mind when writing "my" patch,
>> which is why I ended up with parts that are less readable.
>
> Yeah, I think it's a bug fix and should be back-patched. I'm not in
> favor of making things more complicated just to reduce the number of
> lines a patch touches.
>
>> The one change I'm not quite sure about is the removal of clock skew
>> detection in pgstat_recv_inquiry(). You've removed the first check on
>> the inquiry, replacing it with this comment:
>> It seems sufficient to check for clock skew once per write round.
>> But the first check was comparing msg/req, while the second check looks
>> at dbentry/cur_ts. I don't see how those two clock skew check are
>> redundant - if they are, the comment should explain that I guess.
>
> I'm confused here --- are you speaking of having removed
>
> if (msg->cutoff_time > req->request_time)
> req->request_time = msg->cutoff_time;
>
> ? That is not a check for clock skew, it's intending to be sure that
> req->request_time reflects the latest request for this DB when we've
> seen more than one request. But since req->request_time isn't
> actually being used anywhere, it's useless code.
Ah, you're right. I've made the mistake of writing the e-mail before
drinking any coffee today, and I got distracted by the comment change.
> I reformatted the actual check for clock skew, but I do not think I
> changed its behavior.
I'm not sure it does not change the behavior, though. request_time only
became unused after you removed the two places that set the value (one
of them in the clock skew check).
I'm not sure this is a bad change, though. But there was a dependency
between the new request and the preceding one.
>
>> Another thing is that if you believe merging requests across databases
>> is a silly idea, maybe we should bite the bullet and replace the list of
>> requests with a single item. I'm not convinced about this, though.
>
> No, I don't want to do that either. We're not spending much code by
> having pending_write_requests be a list rather than a single entry,
> and we might eventually figure out a reasonable way to time the flushes
> so that we can merge requests.
>
+1
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-31 17:24:45 |
| Message-ID: | 9580.1464715485@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> On 05/31/2016 06:59 PM, Tom Lane wrote:
>> I'm confused here --- are you speaking of having removed
>> if (msg->cutoff_time > req->request_time)
>> req->request_time = msg->cutoff_time;
>> ? That is not a check for clock skew, it's intending to be sure that
>> req->request_time reflects the latest request for this DB when we've
>> seen more than one request. But since req->request_time isn't
>> actually being used anywhere, it's useless code.
> Ah, you're right. I've made the mistake of writing the e-mail before
> drinking any coffee today, and I got distracted by the comment change.
>> I reformatted the actual check for clock skew, but I do not think I
>> changed its behavior.
> I'm not sure it does not change the behavior, though. request_time only
> became unused after you removed the two places that set the value (one
> of them in the clock skew check).
Well, it's unused in the sense that the if-test quoted above is the only
place in HEAD that examines the value of request_time. And since that
if-test only controls whether we change the value, and not whether we
proceed to make the clock skew check, I don't see how it's related
to clock skew or indeed anything else at all.
regards, tom lane
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-31 18:55:08 |
| Message-ID: | 10072f2b-74d5-861e-4249-8db48f0b653a@2ndquadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 05/31/2016 07:24 PM, Tom Lane wrote:
> Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
>> On 05/31/2016 06:59 PM, Tom Lane wrote:
>>> I'm confused here --- are you speaking of having removed
>>> if (msg->cutoff_time > req->request_time)
>>> req->request_time = msg->cutoff_time;
>>> ? That is not a check for clock skew, it's intending to be sure that
>>> req->request_time reflects the latest request for this DB when we've
>>> seen more than one request. But since req->request_time isn't
>>> actually being used anywhere, it's useless code.
>
>> Ah, you're right. I've made the mistake of writing the e-mail before
>> drinking any coffee today, and I got distracted by the comment change.
>
>>> I reformatted the actual check for clock skew, but I do not think I
>>> changed its behavior.
>
>> I'm not sure it does not change the behavior, though. request_time only
>> became unused after you removed the two places that set the value (one
>> of them in the clock skew check).
>
> Well, it's unused in the sense that the if-test quoted above is the only
> place in HEAD that examines the value of request_time. And since that
> if-test only controls whether we change the value, and not whether we
> proceed to make the clock skew check, I don't see how it's related
> to clock skew or indeed anything else at all.
I see, in that case it indeed is useless.
I've checked how this worked in 9.2 (before the 9.3 patch that split the
file per db), and back then last_statsrequest (transformed to
request_time) was used to decide whether we need to write something. But
now we do that by simply checking whether the list is empty.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| From: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Noah Misch <noah(at)leadboat(dot)com>, pgsql-hackers(at)postgresql(dot)org, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com> |
| Subject: | Re: Re: PATCH: Split stats file per database WAS: autovacuum stress-testing our system |
| Date: | 2016-05-31 19:12:00 |
| Message-ID: | 23827.1464721920@sss.pgh.pa.us |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> writes:
> I've checked how this worked in 9.2 (before the 9.3 patch that split the
> file per db), and back then last_statsrequest (transformed to
> request_time) was used to decide whether we need to write something. But
> now we do that by simply checking whether the list is empty.
Right. In effect, 9.3 moved the decision about "do we need to write stats
because of this request" from the main loop to pgstat_recv_inquiry()
... but we forgot to incorporate any check for whether the request was
already satisfied into pgstat_recv_inquiry(). We can do that, though,
as per either of the patches under discussion --- and once we do so,
maintaining DBWriteRequest.request_time seems a bit pointless.
It's conceivable that we'd try to implement merging of close-together
requests in a way that would take account of how far back the oldest
unsatisfied request is. But I think that a global oldest-request time
would be sufficient for that; we don't need to track it per-database.
In any case, it's hard to see exactly how to make that work without
putting a gettimeofday() call into the inner message handling loop,
which I believe we won't want to do on performance grounds. The previous
speculation about doing writes every N messages or when we have no input
to process seems more likely to lead to a useful answer.
regards, tom lane