Re: Group commit, revised
| Lists: | pgsql-hackers |
|---|
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Group commit, revised |
| Date: | 2012-01-15 22:42:11 |
| Message-ID: | CAEYLb_V5Q8Zdjnkb4+30_dpD3NrgfoXhEurney3HsrCQsyDLWw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Attached is a patch that myself and Simon Riggs collaborated on. I
took the group commit patch that Simon posted to the list back in
November, and partially rewrote it. Here is that original thread:
http://archives.postgresql.org/pgsql-hackers/2011-11/msg00802.php
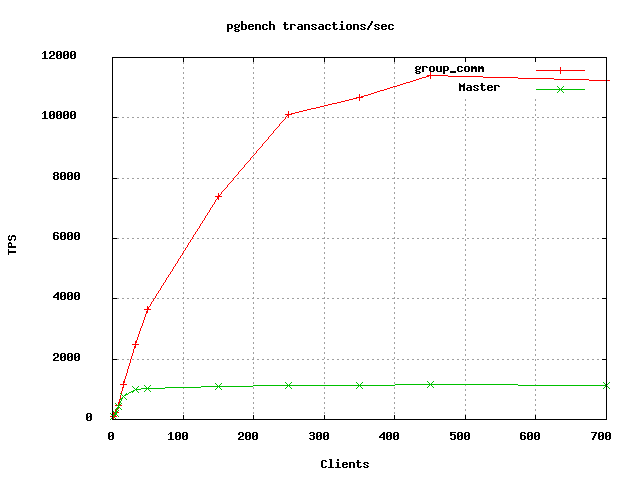
I've also attached the results of a pgbench-tools driven benchmark,
which are quite striking (Just the most relevant image - e-mail me
privately if you'd like a copy of the full report, as I don't want to
send a large PDF file to the list as a courtesy to others). Apart from
the obvious improvement in throughput, there is also a considerable
improvement in average and worst latency at all client counts.
To recap, the initial impetus to pursue this idea came from the
observation that with sync rep, we could get massive improvements in
the transactions-per-second throughput by simply adding clients. Greg
Smith performed a benchmark while in Amsterdam for the PgConf.EU
conference, which was discussed in a talk there. Over an
inter-continental connection from Amsterdam to his office in Baltimore
on the U.S. east coast, he saw TPS as reported by pgbench on what I
suppose was either an insert or update workload grow from a mere 10
TPS for a single connection to over 2000 TPS for about 300
connections. That was with the large, inherent latency imposed by
those sorts of distances (3822 miles/ 6150 km, about a 100ms ping time
on a decent connection). Quite obviously, as clients were added, the
server was able to batch increasing numbers of commits in each
confirmation message, resulting in this effect.
The main way that I've added value here is by refactoring and fixing
bugs. There were some tricky race conditions that caused the
regression tests to fail for that early draft patch, but there were a
few other small bugs too. There is an unprecedented latch pattern
introduced by this patch: Two processes (the WAL Writer and any given
connection backend) have a mutual dependency. Only one may sleep, in
which case the other is responsible for waking it. Much of the
difficulty in debugging this patch, and much of the complexity that
I've added, came from preventing both from simultaneously sleeping,
even in the face of various known failure modes like postmaster death.
If this happens, it does of course represent a denial-of-service, so
that's something that reviewers are going to want to heavily
scrutinise. I suppose that sync rep should be fine here, as it waits
on walsenders, but I haven't actually comprehensively tested the
patch, so there may be undiscovered unpleasant interactions with other
xlog related features. I can report that it passes the regression
tests successfully, and on an apparently consistently basis - I
battled with intermittent failures for a time.
Simon's original patch largely copied the syncrep.c code as an
expedient to prove the concept. Obviously this design was never
intended to get committed, and I've done some commonality and
variability analysis, refactoring to considerably slim down the new
groupcommit.c file by exposing some previously module-private
functions from syncrep.c .
I encourage others to reproduce my benchmark here. I attach a
pgbench-tools config. You can get the latest version of the tool at:
https://github.com/gregs1104/pgbench-tools
I also attach hdparm information for the disk that was used during
these benchmarks. Note that I have not disabled the write cache. It's
a Linux box, with ext4, running a recent kernel.
The benefits (and, admittedly, the controversies) of this patch go
beyond mere batching of commits: it also largely, though not entirely,
obviates the need for user backends to directly write/flush WAL, and
the WAL Writer may never sleep if it continually finds work to do -
wal_writer_delay is obsoleted, as are commit_siblings and
commit_delay. I suspect that they will not be missed. Of course, it
does all this to facilitate group commit itself. The group commit
feature does not have a GUC to control it, as this seems like
something that would be fairly pointless to turn off. FWIW, this is
currently the case for the recently introduced Maria DB group commit
implementation.
Auxiliary processes cannot use group commit. The changes made prevent
them from availing of commit_siblings/commit_delay parallelism,
because it doesn't exist anymore.
Group commit is sometimes throttled, which seems appropriate - if a
backend requests that the WAL Writer flush an LSN deemed too far from
the known flushed point, that request is rejected and the backend goes
through another path, where XLogWrite() is called. Currently the group
commit infrastructure decides that on the sole basis of there being a
volume of WAL that is equivalent in size to checkpoint_segments
between the two points. This is probably a fairly horrible heuristic,
not least since it overloads checkpoint_segments, but is of course
only a first-pass effort. Bright ideas are always welcome.
Thoughts?
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| Attachment | Content-Type | Size |
|---|---|---|
| hd_details.txt | text/plain | 3.1 KB |
|
image/png | 4.7 KB |
| group_commit_2012_01_15.patch.gz | application/x-gzip | 20.5 KB |
| config | application/octet-stream | 1.3 KB |
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
| Cc: | PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-16 08:11:53 |
| Message-ID: | 4F13DBC9.3070603@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 16.01.2012 00:42, Peter Geoghegan wrote:
> I've also attached the results of a pgbench-tools driven benchmark,
> which are quite striking (Just the most relevant image - e-mail me
> privately if you'd like a copy of the full report, as I don't want to
> send a large PDF file to the list as a courtesy to others). Apart from
> the obvious improvement in throughput, there is also a considerable
> improvement in average and worst latency at all client counts.
Impressive results. How about uploading the PDF to the community wiki?
> The main way that I've added value here is by refactoring and fixing
> bugs. There were some tricky race conditions that caused the
> regression tests to fail for that early draft patch, but there were a
> few other small bugs too. There is an unprecedented latch pattern
> introduced by this patch: Two processes (the WAL Writer and any given
> connection backend) have a mutual dependency. Only one may sleep, in
> which case the other is responsible for waking it. Much of the
> difficulty in debugging this patch, and much of the complexity that
> I've added, came from preventing both from simultaneously sleeping,
> even in the face of various known failure modes like postmaster death.
> If this happens, it does of course represent a denial-of-service, so
> that's something that reviewers are going to want to heavily
> scrutinise. I suppose that sync rep should be fine here, as it waits
> on walsenders, but I haven't actually comprehensively tested the
> patch, so there may be undiscovered unpleasant interactions with other
> xlog related features. I can report that it passes the regression
> tests successfully, and on an apparently consistently basis - I
> battled with intermittent failures for a time.
I think it might be simpler if it wasn't the background writer that's
responsible for "driving" the group commit queue, but the backends
themselves. When a flush request comes in, you join the queue, and if
someone else is already doing the flush, sleep until the driver wakes
you up. If no-one is doing the flush yet (ie. the queue is empty), start
doing it yourself. You'll need a state variable to keep track who's
driving the queue, but otherwise I think it would be simpler as there
would be no dependency on WAL writer.
I tend think of the group commit facility as a bus. Passengers can hop
on board at any time, and they take turns on who drives the bus. When
the first passengers hops in, there is no driver so he takes the driver
seat. When the next passenger hops in, he sees that someone is driving
the bus already, so he sits down, and places a big sign on his forehead
stating the bus stop where he wants to get off, and goes to sleep. When
the driver has reached his own bus stop, he wakes up all the passengers
who wanted to get off at the same stop or any of the earlier stops [1].
He also wakes up the passenger whose bus stop is the farthest from the
current stop, and gets off the bus. The woken-up passengers who have
already reached their stops can immediately get off the bus, and the one
who has not notices that no-one is driving the bus anymore, so he takes
the driver seat.
[1] in a real bus, a passenger would not be happy if he's woken up too
late and finds himself at the next stop instead of the one where he
wanted to go, but for group commit, that is fine.
In this arrangement, you could use the per-process semaphore for the
sleep/wakeups, instead of latches. I'm not sure if there's any
difference, but semaphores are more tried and tested, at least.
> The benefits (and, admittedly, the controversies) of this patch go
> beyond mere batching of commits: it also largely, though not entirely,
> obviates the need for user backends to directly write/flush WAL, and
> the WAL Writer may never sleep if it continually finds work to do -
> wal_writer_delay is obsoleted, as are commit_siblings and
> commit_delay.
wal_writer_delay is still needed for controlling how often asynchronous
commits are flushed to disk.
> Auxiliary processes cannot use group commit. The changes made prevent
> them from availing of commit_siblings/commit_delay parallelism,
> because it doesn't exist anymore.
Auxiliary processes have PGPROC entries too. Why can't they participate?
> Group commit is sometimes throttled, which seems appropriate - if a
> backend requests that the WAL Writer flush an LSN deemed too far from
> the known flushed point, that request is rejected and the backend goes
> through another path, where XLogWrite() is called.
Hmm, if the backend doing the big flush gets the WALWriteLock before a
bunch of group committers, the group committers will have to wait until
the big flush is finished, anyway. I presume the idea of the throttling
is to avoid the situation where a bunch of small commits need to wait
for a huge flush to finish.
Perhaps the big flusher should always join the queue, but use some
heuristic to first flush up to the previous commit request, to wake up
others quickly, and do another flush to flush its own request after that.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-17 14:35:28 |
| Message-ID: | CAEYLb_UqTYVZWUCRgSkVS99pRFdNaORSXaXnLXaUbpsTz-pumg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 16 January 2012 08:11, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> Impressive results. How about uploading the PDF to the community wiki?
Sure. http://wiki.postgresql.org/wiki/Group_commit .
> I think it might be simpler if it wasn't the background writer that's
> responsible for "driving" the group commit queue, but the backends
> themselves. When a flush request comes in, you join the queue, and if
> someone else is already doing the flush, sleep until the driver wakes you
> up. If no-one is doing the flush yet (ie. the queue is empty), start doing
> it yourself. You'll need a state variable to keep track who's driving the
> queue, but otherwise I think it would be simpler as there would be no
> dependency on WAL writer.
I think this replaces one problem with another. You've now effectively
elevated a nominated backend to the status of an auxiliary process -
do you intend to have the postmaster look after it, as with any other
auxiliary process? I'm not sure that that is a more difficult problem
to solve, but I suspect so. At least my proposal can have any one of
the backends, both currently participating in group commit and yet to,
wake up the WAL Writer.
> I tend think of the group commit facility as a bus. Passengers can hop on
> board at any time, and they take turns on who drives the bus. When the first
> passengers hops in, there is no driver so he takes the driver seat. When the
> next passenger hops in, he sees that someone is driving the bus already, so
> he sits down, and places a big sign on his forehead stating the bus stop
> where he wants to get off, and goes to sleep. When the driver has reached
> his own bus stop, he wakes up all the passengers who wanted to get off at
> the same stop or any of the earlier stops [1]. He also wakes up the
> passenger whose bus stop is the farthest from the current stop, and gets off
> the bus. The woken-up passengers who have already reached their stops can
> immediately get off the bus, and the one who has not notices that no-one is
> driving the bus anymore, so he takes the driver seat.
>
> [1] in a real bus, a passenger would not be happy if he's woken up too late
> and finds himself at the next stop instead of the one where he wanted to go,
> but for group commit, that is fine.
>
> In this arrangement, you could use the per-process semaphore for the
> sleep/wakeups, instead of latches. I'm not sure if there's any difference,
> but semaphores are more tried and tested, at least.
Yes, and I expect that this won't be the last time someone uses a bus
analogy in relation to this!
The proposed patch is heavily based on sync rep, which I'd have
imagined was more tried and tested than any proposed completely
alternative implementation, as it is basically a generalisation of
exactly the same principle, WAL Writer changes notwithstanding. I
would have imagined that that aspect would be particularly approved
of.
> wal_writer_delay is still needed for controlling how often asynchronous
> commits are flushed to disk.
That had occurred to me of course, but has anyone ever actually
tweaked wal_writer_delay with adjusting the behaviour of asynchronous
commits in mind? I'm pretty sure that the answer is no. I have a
slight preference for obsoleting it as a consequence of introducing
group commit, but I don't think that it matters that much.
>> Auxiliary processes cannot use group commit. The changes made prevent
>> them from availing of commit_siblings/commit_delay parallelism,
>> because it doesn't exist anymore.
>
> Auxiliary processes have PGPROC entries too. Why can't they participate?
It was deemed to be a poor design decision to effectively create a
dependency on the WAL Writer among other auxiliary processes, as to do
so would perhaps compromise the way in which the postmaster notices
and corrects isolated failures. Maybe I'll revisit that assessment,
but I am not convinced that it's worth the very careful analysis of
the implications of such an unprecedented dependency, without there
being some obvious advantage. It it's a question of their being
deprived of commit_siblings "group commit", well, we know from
experience that people didn't tend to touch it a whole lot anyway.
>> Group commit is sometimes throttled, which seems appropriate - if a
>> backend requests that the WAL Writer flush an LSN deemed too far from
>> the known flushed point, that request is rejected and the backend goes
>> through another path, where XLogWrite() is called.
>
> Hmm, if the backend doing the big flush gets the WALWriteLock before a bunch
> of group committers, the group committers will have to wait until the big
> flush is finished, anyway. I presume the idea of the throttling is to avoid
> the situation where a bunch of small commits need to wait for a huge flush
> to finish.
Exactly. Of course, you're never going to see that situation with
pgbench. I don't have much data to inform exactly what the right
trade-off is here, or some generic approximation of it across
platforms and hardware - other people will know more about this than I
do. While I have a general sense that the cost of flushing a single
page of data is the same as flushing a relatively much larger amount
of data, I cannot speak to much of an understanding of what that trade
off might be for larger amounts of data, where the question of
modelling some trade-off between throughput and latency arises,
especially with all the baggage that the implementation carries such
as whether or not we're using full_page_writes, hardware and so on.
Something simple will probably work well.
> Perhaps the big flusher should always join the queue, but use some heuristic
> to first flush up to the previous commit request, to wake up others quickly,
> and do another flush to flush its own request after that.
Maybe, but we should decide what a big flusher looks like first. That
way, if we can't figure out a way to do what you describe with it in
time for 9.2, we can at least do what I'm already doing.
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
| Cc: | PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-17 17:37:16 |
| Message-ID: | 4F15B1CC.6050900@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17.01.2012 16:35, Peter Geoghegan wrote:
> On 16 January 2012 08:11, Heikki Linnakangas
> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>> I think it might be simpler if it wasn't the background writer that's
>> responsible for "driving" the group commit queue, but the backends
>> themselves. When a flush request comes in, you join the queue, and if
>> someone else is already doing the flush, sleep until the driver wakes you
>> up. If no-one is doing the flush yet (ie. the queue is empty), start doing
>> it yourself. You'll need a state variable to keep track who's driving the
>> queue, but otherwise I think it would be simpler as there would be no
>> dependency on WAL writer.
>
> I think this replaces one problem with another. You've now effectively
> elevated a nominated backend to the status of an auxiliary process -
> do you intend to have the postmaster look after it, as with any other
> auxiliary process?
The GroupCommitWaitForLSN() call happens within a critical section. If
the process dies, you're screwed no matter what. It's not very different
from the current situation where if one backend flushes the WAL, another
backend will notice that once it gets the WALWriteLock, and returns quickly.
>> wal_writer_delay is still needed for controlling how often asynchronous
>> commits are flushed to disk.
>
> That had occurred to me of course, but has anyone ever actually
> tweaked wal_writer_delay with adjusting the behaviour of asynchronous
> commits in mind?
I found it very helpful to reduce wal_writer_delay in pgbench tests,
when running with synchronous_commit=off. The reason is that hint bits
don't get set until the commit record is flushed to disk, so making the
flushes more frequent reduces the contention on the clog. However, Simon
made async commits nudge WAL writer if the WAL page fills up, so I'm not
sure how relevant that experience is anymore.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-17 18:15:33 |
| Message-ID: | CAEYLb_UW6e0Xr4S4T=tTxr-XcQRuNu4PFi5Qja1fS5tKFi_56Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 17 January 2012 17:37, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> I found it very helpful to reduce wal_writer_delay in pgbench tests, when
> running with synchronous_commit=off. The reason is that hint bits don't get
> set until the commit record is flushed to disk, so making the flushes more
> frequent reduces the contention on the clog. However, Simon made async
> commits nudge WAL writer if the WAL page fills up, so I'm not sure how
> relevant that experience is anymore.
It's quite possible that the WAL Writer will spin continuously, if
given enough work to do, with this patch.
Although it's hard to tell from the graph I sent, there is a modest
improvement in TPS for even a single client. See the tables in the
PDF.
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| From: | Jim Nasby <jim(at)nasby(dot)net> |
|---|---|
| To: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
| Cc: | PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-18 00:21:57 |
| Message-ID: | 07C6E9E8-9F4D-44CA-96DB-75B0219AC7DA@nasby.net |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Jan 15, 2012, at 4:42 PM, Peter Geoghegan wrote:
> Attached is a patch that myself and Simon Riggs collaborated on. I
> took the group commit patch that Simon posted to the list back in
> November, and partially rewrote it.
Forgive me if this is a dumb question, but I noticed a few places doing things like:
if (...)
Blah();
else
{
...
}
Is that allowed PG formatting? I thought that if braces were required on one branch of an if they were supposed to go on both sides.
Also, I didn't see any README changes in the patch... perhaps this is big enough to warrant them?
--
Jim C. Nasby, Database Architect jim(at)nasby(dot)net
512.569.9461 (cell) http://jim.nasby.net
| From: | Alvaro Herrera <alvherre(at)commandprompt(dot)com> |
|---|---|
| To: | Jim Nasby <jim(at)nasby(dot)net> |
| Cc: | Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-18 00:31:06 |
| Message-ID: | 1326846575-sup-4645@alvh.no-ip.org |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
Excerpts from Jim Nasby's message of mar ene 17 21:21:57 -0300 2012:
> On Jan 15, 2012, at 4:42 PM, Peter Geoghegan wrote:
> > Attached is a patch that myself and Simon Riggs collaborated on. I
> > took the group commit patch that Simon posted to the list back in
> > November, and partially rewrote it.
>
> Forgive me if this is a dumb question, but I noticed a few places doing things like:
>
> if (...)
> Blah();
> else
> {
> ...
> }
>
> Is that allowed PG formatting? I thought that if braces were required on one branch of an if they were supposed to go on both sides.
Yeah, we even used to have pg_indent remove braces around single
statements, so if you had one statement in the "if" branch and more
around the other one, pg_indent would have left things like that anyway.
(This particular pg_indent behavior got removed because it messed up
PG_TRY blocks.)
--
Álvaro Herrera <alvherre(at)commandprompt(dot)com>
The PostgreSQL Company - Command Prompt, Inc.
PostgreSQL Replication, Consulting, Custom Development, 24x7 support
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-18 01:23:23 |
| Message-ID: | CA+TgmoZ7XCR-ZAqJ_1aZyPsHcXnX7w-M1CbqWhpOO-Vu_e8DNQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jan 17, 2012 at 12:37 PM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> I found it very helpful to reduce wal_writer_delay in pgbench tests, when
> running with synchronous_commit=off. The reason is that hint bits don't get
> set until the commit record is flushed to disk, so making the flushes more
> frequent reduces the contention on the clog. However, Simon made async
> commits nudge WAL writer if the WAL page fills up, so I'm not sure how
> relevant that experience is anymore.
There's still a small but measurable effect there in master. I think
we might be able to make it fully auto-tuning, but I don't think we're
fully there yet (not sure how much this patch changes that equation).
I suggested a design similar to the one you just proposed to Simon
when he originally suggested this feature. It seems that if the WAL
writer is the only one doing WAL flushes, then there must be some IPC
overhead - and context switching - involved whenever WAL is flushed.
But clearly we're saving something somewhere else, on the basis of
Peter's results, so maybe it's not worth worrying about. It does seem
pretty odd to have all the regular backends going through the WAL
writer and the auxiliary processes using a different mechanism,
though. If we got rid of that, maybe WAL writer wouldn't even require
a lock, if there's only one process that can be doing it at a time.
What happens in standalone mode?
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-18 22:38:30 |
| Message-ID: | CA+U5nM+Od94quNOsObo7gfiCRijwtJSWko8Gz9tyorHY5e96Sw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 18, 2012 at 1:23 AM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> On Tue, Jan 17, 2012 at 12:37 PM, Heikki Linnakangas
> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>> I found it very helpful to reduce wal_writer_delay in pgbench tests, when
>> running with synchronous_commit=off. The reason is that hint bits don't get
>> set until the commit record is flushed to disk, so making the flushes more
>> frequent reduces the contention on the clog. However, Simon made async
>> commits nudge WAL writer if the WAL page fills up, so I'm not sure how
>> relevant that experience is anymore.
Still completely relevant and orthogonal to this discussion. The patch
retains multi-modal behaviour.
> There's still a small but measurable effect there in master. I think
> we might be able to make it fully auto-tuning, but I don't think we're
> fully there yet (not sure how much this patch changes that equation).
>
> I suggested a design similar to the one you just proposed to Simon
> when he originally suggested this feature. It seems that if the WAL
> writer is the only one doing WAL flushes, then there must be some IPC
> overhead - and context switching - involved whenever WAL is flushed.
> But clearly we're saving something somewhere else, on the basis of
> Peter's results, so maybe it's not worth worrying about. It does seem
> pretty odd to have all the regular backends going through the WAL
> writer and the auxiliary processes using a different mechanism,
> though. If we got rid of that, maybe WAL writer wouldn't even require
> a lock, if there's only one process that can be doing it at a time.
When we did sync rep it made sense to have the WALSender do the work
and for others to just wait. It would be quite strange to require a
different design for essentially the same thing for normal commits and
WAL flushes to local disk. I should mention the original proposal for
streaming replication had each backend send data to standby
independently and that was recognised as a bad idea after some time.
Same for sync rep also.
The gain is that previously there was measurable contention for the
WALWriteLock, now there is none. Plus the gang effect continues to
work even when the database gets busy, which isn't true of piggyback
commits as we use now.
Not sure why its odd to have backends do one thing and auxiliaries do
another. The whole point of auxiliary processes is that they do a
specific thing different to normal backends. Anyway, the important
thing is to have auxiliary processes be independent of each other as
much as possible, which simplifies error handling and state logic in
the postmaster.
With regard to context switching, we're making a kernel call to fsync,
so we'll get a context switch anyway. The whole process is similar to
the way lwlock wake up works.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-19 17:40:08 |
| Message-ID: | CA+Tgmoa5LRCrCevAbqjAZxnqX7Qgv0sK9GpxsOwm2Yg3=srZ5Q@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 18, 2012 at 5:38 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> On Wed, Jan 18, 2012 at 1:23 AM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>> On Tue, Jan 17, 2012 at 12:37 PM, Heikki Linnakangas
>> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>>> I found it very helpful to reduce wal_writer_delay in pgbench tests, when
>>> running with synchronous_commit=off. The reason is that hint bits don't get
>>> set until the commit record is flushed to disk, so making the flushes more
>>> frequent reduces the contention on the clog. However, Simon made async
>>> commits nudge WAL writer if the WAL page fills up, so I'm not sure how
>>> relevant that experience is anymore.
>
> Still completely relevant and orthogonal to this discussion. The patch
> retains multi-modal behaviour.
I don't know what you mean by this. I think removing wal_writer_delay
is premature, because I think it still may have some utility, and the
patch removes it. That's a separate change that should be factored
out of this patch and discussed separately.
>> There's still a small but measurable effect there in master. I think
>> we might be able to make it fully auto-tuning, but I don't think we're
>> fully there yet (not sure how much this patch changes that equation).
>>
>> I suggested a design similar to the one you just proposed to Simon
>> when he originally suggested this feature. It seems that if the WAL
>> writer is the only one doing WAL flushes, then there must be some IPC
>> overhead - and context switching - involved whenever WAL is flushed.
>> But clearly we're saving something somewhere else, on the basis of
>> Peter's results, so maybe it's not worth worrying about. It does seem
>> pretty odd to have all the regular backends going through the WAL
>> writer and the auxiliary processes using a different mechanism,
>> though. If we got rid of that, maybe WAL writer wouldn't even require
>> a lock, if there's only one process that can be doing it at a time.
>
> When we did sync rep it made sense to have the WALSender do the work
> and for others to just wait. It would be quite strange to require a
> different design for essentially the same thing for normal commits and
> WAL flushes to local disk. I should mention the original proposal for
> streaming replication had each backend send data to standby
> independently and that was recognised as a bad idea after some time.
> Same for sync rep also.
I don't think those cases are directly comparable. SR is talking to
another machine, and I can't imagine that there is a terribly
convenient or portable way for every backend that needs one to get a
hold of the file descriptor for the socket. Even if it could, the
data is sent as a stream, so if multiple backends sent to the same
file descriptor you'd have to have some locking to prevent messages
from getting interleaved. Or else you could have multiple
connections, or use UDP, but that gets rather complex. Anyway, none
of this is an issue for file I/O: anybody can open the file, and if
two backends write data at different offsets at the same time - or the
same data at the same offset at the same time - there's no problem.
So the fact that it wasn't a good idea for SR doesn't convince me that
it's also a bad idea here.
On the other hand, I'm not saying we *should* do it that way, either -
i.e. I am not trying to "require a different design" just because it's
fun to make people change things. Rather, I am trying to figure out
whether the design you've chosen is in fact the best one, and part of
that involves reasoning about why it might or might not be. There are
obvious reasons to think that having process A kick process B and go
to sleep, then have process B do some work and wake up process A might
be less efficient than having process A just do the work itself, in
the uncontended case. The fact that that isn't happening seems
awfully strange to me; it's hard to understand why 3 system calls are
faster than one. That suggests that either the current system is
badly broken in some way that this patch fixes (in which case, it
would be nice to know what the broken thing is) or that there's an
opportunity for further optimization of the new patch (either now or
later, depending on how much work we're talking about). Just to be
clear, it makes perfect sense that the new system is faster in the
contended case, and the benchmark numbers are very impressive. It's a
lot harder to understand why it's not slower in the uncontended case.
> Not sure why its odd to have backends do one thing and auxiliaries do
> another. The whole point of auxiliary processes is that they do a
> specific thing different to normal backends. Anyway, the important
> thing is to have auxiliary processes be independent of each other as
> much as possible, which simplifies error handling and state logic in
> the postmaster.
Yeah, I guess the shutdown sequence could get a bit complex if we try
to make everyone go through the WAL writer all the time. But I wonder
if we could rejiggering things somehow so that everything goes through
WAL writer if its dead.
+ * Wait for group commit, and then return true, if group commit serviced the
+ * request (not necessarily successfully). Otherwise, return false
and fastpath
+ * out of here, allowing the backend to make alternative arrangements to flush
+ * its WAL in a more granular fashion. This can happen because the record that
+ * the backend requests to have flushed in so far into the future
that to group
+ * commit it would
This trails off in mid-sentence.
+ if (delta > XLOG_SEG_SIZE * CheckPointSegments ||
+ !ProcGlobal->groupCommitAvailable)
That seems like a gigantic value. I would think that we'd want to
forget about group commit any time we're behind by more than one
segment (maybe less).
+ if (ProcDiePending || QueryCancelPending)
+ {
+ GroupCommitCancelWait();
+
+ /*
+ * Let out-of-line interrupt handler take it
from here. Cannot raise
+ * an error here because we're in an enclosing
critical block.
+ */
+ break;
+ }
Presumably in this case we need to return false, not true. TBH, I
feel like this error handling is quite fragile, a fragility it
inherits from sync rep, on which it is based. I am not sure I have a
better idea, though.
+ /*
+ * Backends may still be waiting to have their transactions
committed in batch,
+ * but calling this function prevents any backend from using group commit, and
+ * thus from having a dependency on the WAL Writer.
+ *
+ * When the WAL Writer finishes servicing those remaining backends,
it will not
+ * have any additional work to do, and may shutdown.
+ */
+ void
+ GroupCommitDisable(void)
+ {
+ ProcGlobal->groupCommitAvailable = false;
+ }
I can't imagine that this is safe against memory ordering issues.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-20 03:46:54 |
| Message-ID: | CAEYLb_UcWD+EOYkat=ZF-SyZP=bhHJ2ciZTeVn6=K3RWvje6RQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 19 January 2012 17:40, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> I don't know what you mean by this. I think removing wal_writer_delay
> is premature, because I think it still may have some utility, and the
> patch removes it. That's a separate change that should be factored
> out of this patch and discussed separately.
FWIW, I don't really care too much if we keep wal_writer_delay,
provided it is only used in place of the patch's
WALWRITER_NORMAL_TIMEOUT constant. I will note in passing that I doubt
that the effect with asynchronous commits and hint bits is pronounced
enough to have ever transferred through to someone making a practical
recommendation to reduce wal_writer_delay to ameliorate clog
contention.
>> When we did sync rep it made sense to have the WALSender do the work
>> and for others to just wait. It would be quite strange to require a
>> different design for essentially the same thing for normal commits and
>> WAL flushes to local disk. I should mention the original proposal for
>> streaming replication had each backend send data to standby
>> independently and that was recognised as a bad idea after some time.
>> Same for sync rep also.
>
> I don't think those cases are directly comparable. SR is talking to
> another machine, and I can't imagine that there is a terribly
> convenient or portable way for every backend that needs one to get a
> hold of the file descriptor for the socket. Even if it could, the
> data is sent as a stream, so if multiple backends sent to the same
> file descriptor you'd have to have some locking to prevent messages
> from getting interleaved. Or else you could have multiple
> connections, or use UDP, but that gets rather complex. Anyway, none
> of this is an issue for file I/O: anybody can open the file, and if
> two backends write data at different offsets at the same time - or the
> same data at the same offset at the same time - there's no problem.
> So the fact that it wasn't a good idea for SR doesn't convince me that
> it's also a bad idea here.
>
> On the other hand, I'm not saying we *should* do it that way, either -
> i.e. I am not trying to "require a different design" just because it's
> fun to make people change things. Rather, I am trying to figure out
> whether the design you've chosen is in fact the best one, and part of
> that involves reasoning about why it might or might not be. There are
> obvious reasons to think that having process A kick process B and go
> to sleep, then have process B do some work and wake up process A might
> be less efficient than having process A just do the work itself, in
> the uncontended case. The fact that that isn't happening seems
> awfully strange to me; it's hard to understand why 3 system calls are
> faster than one. That suggests that either the current system is
> badly broken in some way that this patch fixes (in which case, it
> would be nice to know what the broken thing is) or that there's an
> opportunity for further optimization of the new patch (either now or
> later, depending on how much work we're talking about). Just to be
> clear, it makes perfect sense that the new system is faster in the
> contended case, and the benchmark numbers are very impressive. It's a
> lot harder to understand why it's not slower in the uncontended case.
>
>> Not sure why its odd to have backends do one thing and auxiliaries do
>> another. The whole point of auxiliary processes is that they do a
>> specific thing different to normal backends. Anyway, the important
>> thing is to have auxiliary processes be independent of each other as
>> much as possible, which simplifies error handling and state logic in
>> the postmaster.
>
> Yeah, I guess the shutdown sequence could get a bit complex if we try
> to make everyone go through the WAL writer all the time. But I wonder
> if we could rejiggering things somehow so that everything goes through
> WAL writer if its dead.
I'm not sure what you mean by this last bit. It sounds a bit hazardous.
My problem with nominating a backend to the status of an auxiliary is
that no matter what way you cut it, it increases the failure surface
area, so to speak.
I'm not sure why Heikki thinks that it follows that having a
dependency on some backend is simpler than having one on an auxiliary
process. As to the question of IPC and context switch overhead, I'd
speculate that protecting access to a data structure with book keeping
information regarding which backend is currently the driver and so on
might imply considerably more overhead than IPC and context switching.
It might also be that having WAL Writer almost solely responsible for
this might facilitate more effective use of CPU cache.
On most modern architectures, system calls don't actually cause a full
context switch. The kernel can just enter a "mode switch" (go from
user mode to kernel mode, and then back to user mode). You can observe
this effect with vmstat. That's how 3 system calls might not look much
more expensive than 1.
> + if (delta > XLOG_SEG_SIZE * CheckPointSegments ||
> + !ProcGlobal->groupCommitAvailable)
>
> That seems like a gigantic value. I would think that we'd want to
> forget about group commit any time we're behind by more than one
> segment (maybe less).
I'm sure that you're right - I myself described it as horrible in my
original mail. I think that whatever value we set this to ought to be
well reasoned. Right now, your magic number doesn't seem much better
than my bogus heuristic (which only ever served as a placeholder
implementation that hinted at a well-principled formula). What's your
basis for suggesting that that limit would always be close to optimal?
Once again, I ask the question: what does a big flusher look like?
> + if (ProcDiePending || QueryCancelPending)
> + {
> + GroupCommitCancelWait();
> +
> + /*
> + * Let out-of-line interrupt handler take it
> from here. Cannot raise
> + * an error here because we're in an enclosing
> critical block.
> + */
> + break;
> + }
>
> Presumably in this case we need to return false, not true.
No, that is not an error. As described in the comment above that
function, the return value indicates if group commit serviced the
request, not necessarily successfully. If we were to return false,
we'd be acting as if group commit just didn't want to flush that LSN,
necessitating making alternative arrangements (calling XLogWrite()).
However, we should just hurry up and get to the interrupt handler to
error and report failure to the client (though not before executing
the code immediately before "return true" at the end of the function).
Maybe you could argue that it would be better to do that anyway, but I
think that it could mask problems and unnecessarily complicate
matters.
> TBH, I feel like this error handling is quite fragile, a fragility it
> inherits from sync rep, on which it is based. I am not sure I have a
> better idea, though.
I agree with this analysis. However, since no better alternative
suggests itself, we may find that an XXX comment will go a long way.
> + void
> + GroupCommitDisable(void)
> + {
> + ProcGlobal->groupCommitAvailable = false;
> + }
>
> I can't imagine that this is safe against memory ordering issues.
That had occurred to me. Strictly speaking, it doesn't necessarily
have to be, provided that some architecture with weak memory ordering
is not inclined to take an inordinate amount of time, or even forever,
to notice that the variable has been set to false. WAL Writer calls
this to "turn the tap off" to allow it to finish its group commit
backlog (allowing those backends to shutdown) and shutdown itself, but
it doesn't actually assume that turning the tap off will be
immediately effective.
However, now that I think about it, even if my assumption about the
behaviour of all machines regarding memory ordering there doesn't fall
down, it does seem possible that GroupCommitShutdownReady() could
return true, but that status could immediately change because some
backend on Alpha or something didn't see that the flag was set, so
your point is well taken.
By the way, how goes the introduction of memory barriers to Postgres?
I'm aware that you committed an implementation back in September, but
am not sure what the plan is as regards using them in 9.2.
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-20 15:30:33 |
| Message-ID: | CA+Tgmoa+jrb_vXckcExZNOzJcLJBaXq-RVoJhMbRtyZdaQMSMg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Thu, Jan 19, 2012 at 10:46 PM, Peter Geoghegan <peter(at)2ndquadrant(dot)com> wrote:
> On 19 January 2012 17:40, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>> I don't know what you mean by this. I think removing wal_writer_delay
>> is premature, because I think it still may have some utility, and the
>> patch removes it. That's a separate change that should be factored
>> out of this patch and discussed separately.
>
> FWIW, I don't really care too much if we keep wal_writer_delay,
> provided it is only used in place of the patch's
> WALWRITER_NORMAL_TIMEOUT constant. I will note in passing that I doubt
> that the effect with asynchronous commits and hint bits is pronounced
> enough to have ever transferred through to someone making a practical
> recommendation to reduce wal_writer_delay to ameliorate clog
> contention.
It was very visible in some benchmarking Heikki did, and I was able to
reproduce it.
>> Yeah, I guess the shutdown sequence could get a bit complex if we try
>> to make everyone go through the WAL writer all the time. But I wonder
>> if we could rejiggering things somehow so that everything goes through
>> WAL writer if its dead.
>
> I'm not sure what you mean by this last bit. It sounds a bit hazardous.
That last "if" was supposed to say "unless", which may contribute to
the confusion.
> My problem with nominating a backend to the status of an auxiliary is
> that no matter what way you cut it, it increases the failure surface
> area, so to speak.
I think that's the wrong way of thinking about it. Imagine this: we
maintain a queue of people who are waiting on the current WAL flush,
the current-flush-to LSN, and a queue of people who are waiting on the
next WAL flush, and a leader. All this data is protected by a
spinlock. When you want to flush WAL, you grab the spinlock. If the
current-flush-to LSN is greater than the LSN you need, you add
yourself to the waiting-on-current-flush queue, release the spinlock,
and go to sleep. Otherwise, if there's no leader, you become the
leader, enter your flush LSN as the current-flush-to-LSN, and release
the spinlock. If there is a leader, you add yourself to the
waiting-on-next-flush queue, release the spinlock, and sleep.
If you become the leader, you perform the flush. Then you retake the
spinlock, dequeue anyone waiting on the current flush, move all of the
next flush waiters (or those within a certain LSN distance) to the
current flush list, remember who is at the head of that new queue, and
release the spinlock. You then set a flag in the PGPROC of the
backend now at the head of the next-flush queue and wake him up; he
checks that flag on waking to know whether he is the leader or whether
he's just been woken because his flush is done. After waking him so
the next flush can get started, you wake all the people who were
waiting on the flush you already did.
This may or may not be a good design, but I don't think it has any
more failure surface area than what you have here. In particular,
whether or not the WAL writer is running doesn't matter; the system
can run just fine without it, and can even still do group commit. To
look at it another way, it's not a question of whether we're treating
a regular backend as an auxiliary process; there's no rule anywhere
that backends can't be dependent on the proper operation of other
backends for proper functioning - there are MANY places that have that
property, including LWLockAcquire() and LWLockRelease(). Nor is there
any rule that background processes are more reliable than foreground
processes, nor do I believe they are. Much of the existing patch's
failure surface seems to me to come from the coordination it requires
between ordinary backends and the background writer, and possible race
conditions appertaining thereto: WAL writer dies, backend dies,
postmaster dies, postmaster and WAL writer die together, etc.
>> + if (delta > XLOG_SEG_SIZE * CheckPointSegments ||
>> + !ProcGlobal->groupCommitAvailable)
>>
>> That seems like a gigantic value. I would think that we'd want to
>> forget about group commit any time we're behind by more than one
>> segment (maybe less).
>
> I'm sure that you're right - I myself described it as horrible in my
> original mail. I think that whatever value we set this to ought to be
> well reasoned. Right now, your magic number doesn't seem much better
> than my bogus heuristic (which only ever served as a placeholder
> implementation that hinted at a well-principled formula). What's your
> basis for suggesting that that limit would always be close to optimal?
It's probably not - I suspect even a single WAL segment still too
large. I'm pretty sure that it would be safe to always flush up to
the next block boundary, because we always write the whole block
anyway even if it's only partially filled. So there's no possible
regression there. Anything larger than "the end of the current 8kB
block" is going to be a trade-off between latency and throughput, and
it seems to me that there's probably only one way to figure out what's
reasonable: test a bunch of different values and see which ones
perform well in practice. Maybe we could answer part of the question
by writing a test program which does repeated sequential writes of
increasingly-large chunks of data. We might find out for example that
64kB is basically the same as 8kB because most of the overhead is in
the system call anyway, but beyond that the curve kinks. Or it may be
that 16kB is already twice as slow as 8kB, or that you can go up to
1MB without a problem. I don't see a way to know that without testing
it on a couple different pieces of hardware and seeing what happens.
>> + if (ProcDiePending || QueryCancelPending)
>> + {
>> + GroupCommitCancelWait();
>> +
>> + /*
>> + * Let out-of-line interrupt handler take it
>> from here. Cannot raise
>> + * an error here because we're in an enclosing
>> critical block.
>> + */
>> + break;
>> + }
>>
>> Presumably in this case we need to return false, not true.
>
> No, that is not an error. As described in the comment above that
> function, the return value indicates if group commit serviced the
> request, not necessarily successfully. If we were to return false,
> we'd be acting as if group commit just didn't want to flush that LSN,
> necessitating making alternative arrangements (calling XLogWrite()).
> However, we should just hurry up and get to the interrupt handler to
> error and report failure to the client (though not before executing
> the code immediately before "return true" at the end of the function).
> Maybe you could argue that it would be better to do that anyway, but I
> think that it could mask problems and unnecessarily complicate
> matters.
Ugh. Our current system doesn't even require this code to be
interruptible, I think: you can't receive cancel or die interrupts
either while waiting for an LWLock or while holding it.
> By the way, how goes the introduction of memory barriers to Postgres?
> I'm aware that you committed an implementation back in September, but
> am not sure what the plan is as regards using them in 9.2.
Well, I was expecting a few patches to go in that needed them, but so
far that hasn't happened. I think it would be a fine thing if we had
a good reason to commit some code that uses them, so that we can watch
the buildfarm turn pretty colors.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-20 22:30:06 |
| Message-ID: | 4F19EAEE.2050501@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I spent some time cleaning this up. Details below, but here are the
highlights:
* Reverted the removal of wal_writer_delay
* Doesn't rely on WAL writer. Any process can act as the "leader" now.
* Removed heuristic on big flushes
* Uses PGSemaphoreLock/Unlock instead of latches
On 20.01.2012 17:30, Robert Haas wrote:
> On Thu, Jan 19, 2012 at 10:46 PM, Peter Geoghegan<peter(at)2ndquadrant(dot)com> wrote:
>>> + if (delta> XLOG_SEG_SIZE * CheckPointSegments ||
>>> + !ProcGlobal->groupCommitAvailable)
>>>
>>> That seems like a gigantic value. I would think that we'd want to
>>> forget about group commit any time we're behind by more than one
>>> segment (maybe less).
>>
>> I'm sure that you're right - I myself described it as horrible in my
>> original mail. I think that whatever value we set this to ought to be
>> well reasoned. Right now, your magic number doesn't seem much better
>> than my bogus heuristic (which only ever served as a placeholder
>> implementation that hinted at a well-principled formula). What's your
>> basis for suggesting that that limit would always be close to optimal?
>
> It's probably not - I suspect even a single WAL segment still too
> large. I'm pretty sure that it would be safe to always flush up to
> the next block boundary, because we always write the whole block
> anyway even if it's only partially filled. So there's no possible
> regression there. Anything larger than "the end of the current 8kB
> block" is going to be a trade-off between latency and throughput, and
> it seems to me that there's probably only one way to figure out what's
> reasonable: test a bunch of different values and see which ones
> perform well in practice. Maybe we could answer part of the question
> by writing a test program which does repeated sequential writes of
> increasingly-large chunks of data. We might find out for example that
> 64kB is basically the same as 8kB because most of the overhead is in
> the system call anyway, but beyond that the curve kinks. Or it may be
> that 16kB is already twice as slow as 8kB, or that you can go up to
> 1MB without a problem. I don't see a way to know that without testing
> it on a couple different pieces of hardware and seeing what happens.
I ripped away that heuristic for a flush that's "too large". After
pondering it for a while, I came to the conclusion that as implemented
in the patch, it was pointless. The thing is, if the big flush doesn't
go through the group commit machinery, it's going to grab the
WALWriteLock straight away. Before any smaller commits can proceed, they
will need to grab that lock anyway, so the effect is the same as if the
big flush had just joined the queue.
Maybe we should have a heuristic to split a large flush into smaller
chunks. The WAL segment boundary would be a quite natural split point,
for example, because when crossing the file boundary you have to issue
separate fsync()s for the files anyway. But I'm happy with leaving that
out for now, it's not any worse than it used to be without group commit
anyway.
> Ugh. Our current system doesn't even require this code to be
> interruptible, I think: you can't receive cancel or die interrupts
> either while waiting for an LWLock or while holding it.
Right. Or within HOLD/RESUME_INTERRUPTS blocks.
The patch added some CHECK_FOR_INTERRUPTS() calls into various places in
the commit/abort codepaths, but that's all dead code; they're all within
a HOLD/RESUME_INTERRUPTS blocks.
I replaced the usage of latches with the more traditional
PGSemaphoreLock/Unlock. It semaphore model works just fine in this case,
where we have a lwlock to guard the wait queue, and when a process is
waiting we know it will be woken up or something messed up at a pretty
low level. We don't need a timeout or to wake up at other signals while
waiting. Furthermore, the WAL writer didn't have a latch before this
patch; it's not many lines of code to initialize the latch and set up
the signal handler for it, but it already has a semaphore that's ready
to use.
I wonder if we should rename the file into "xlogflush.c" or something
like that, to make it clear that this works with any XLOG flushes, not
just commits? Group commit is the usual term for this feature, so we
should definitely mention that in the comments, but it might be better
to rename the files/functions to emphasize that this is about WAL
flushing in general.
This probably needs some further cleanup to fix things I've broken, and
I haven't done any performance testing, but it's progress. Do you have a
shell script or something that you used for the performance tests that I
could run? Or would you like to re-run the tests you did earlier with
this patch?
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| group_commit_2012_01_21.patch | text/x-diff | 42.1 KB |
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-21 03:13:56 |
| Message-ID: | CAEYLb_XfjM2qQtdo9oRHJ+SnTaBteevTq=v6guFRRDffE1Fh6A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 20 January 2012 22:30, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> Maybe we should have a heuristic to split a large flush into smaller chunks.
> The WAL segment boundary would be a quite natural split point, for example,
> because when crossing the file boundary you have to issue separate fsync()s
> for the files anyway. But I'm happy with leaving that out for now, it's not
> any worse than it used to be without group commit anyway.
Let's quantify how much of a problem that is first.
> The patch added some CHECK_FOR_INTERRUPTS() calls into various places in the
> commit/abort codepaths, but that's all dead code; they're all within a
> HOLD/RESUME_INTERRUPTS blocks.
Fair enough, but do you think it's acceptable to say "well, we can't
have errors within critical blocks anyway, and nor can the driver, so
just assume that the driver will successfully service the request"?
> Furthermore, the WAL writer didn't have a latch before this patch; it's not
> many lines of code to initialize the latch and set up the signal handler for
> it, but it already has a semaphore that's ready to use.
Uh, yes it did - WalWriterDelay is passed to WaitLatch(). It didn't
use the process latch as I did (which is initialised anyway), though I
believe it should have (on general principal, to avoid invalidation
issues when generic handlers are registered, plus because the process
latch is already initialised and available), which is why I changed
it. Whatever you do with group commit, you're going to want to look at
the changes made to the WAL Writer in my original patch outside of the
main loop, because there are one or two fixes for it included
(registering a usr1 signal handler and saving errno in existing
handlers), and because we need an alternative way of power saving if
you're not going to include the mechanism originally proposed - maybe
something similar to what has been done for the BGWriter in my patch
for that. At 5 wake-ups per second by default, the process is by a
wide margin the biggest culprit (except BGWriter, which is also 5 by
default, but that is addressed by my other patch that you're
reviewing). I want to fix that problem too, and possibly investigate
if there's something to be done about the checkpointer (though that
only has a 5 second timeout, so it's not a major concern). In any
case, we should encourage the idea that auxiliary processes will use
the proc latch, unless perhaps they only use a local latch like the
avlauncher does, imho.
Why did you remove the new assertions in unix_latch.c/win32_latch.c? I
think you should keep them, as well as my additional comments on latch
timeout invalidation issues in latch.h which are untouched in your
revision (though this looks to be a rough revision, so I shouldn't
read anything into that either way I suppose). In general, we should
try and use the process latch whenever we can.
> I wonder if we should rename the file into "xlogflush.c" or something like
> that, to make it clear that this works with any XLOG flushes, not just
> commits? Group commit is the usual term for this feature, so we should
> definitely mention that in the comments, but it might be better to rename
> the files/functions to emphasize that this is about WAL flushing in general.
Okay.
> This probably needs some further cleanup to fix things I've broken, and I
> haven't done any performance testing, but it's progress. Do you have a shell
> script or something that you used for the performance tests that I could
> run? Or would you like to re-run the tests you did earlier with this patch?
No, I'm using pgbench-tools, and there's no reason to think that you
couldn't get similar results on ordinary hardware, which is all I used
- obviously you'll want to make sure that you're using a file system
that supports granular fsyncs, like ext4. All of the details,
including the config for pgbench-tools, are in my original e-mail. I
have taken the time to re-run the benchmark and update the wiki with
that new information - I'd call it a draw.
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-21 03:37:22 |
| Message-ID: | CAEYLb_UjzGO9axc7x-ONeCy8HdqfDCTo2bnAxCMQnGbPwb+Tsg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 21 January 2012 03:13, Peter Geoghegan <peter(at)2ndquadrant(dot)com> wrote:
> I have taken the time to re-run the benchmark and update the wiki with
> that new information - I'd call it a draw.
On second though, the occasional latency spikes that we see with my
patch (which uses the poll() based latch in the run that is
benchmarked) might be significant - difficult to say. The averages are
about the same though.
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| From: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-25 03:50:22 |
| Message-ID: | CA+U5nMLG91oFao4=O_WoMSgQ8ELEGxqTqqmXLzADt5XV-rAUpw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Jan 20, 2012 at 10:30 PM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> I spent some time cleaning this up. Details below, but here are the
> highlights:
>
> * Reverted the removal of wal_writer_delay
> * Removed heuristic on big flushes
No contested viewpoints on anything there.
> * Doesn't rely on WAL writer. Any process can act as the "leader" now.
> * Uses PGSemaphoreLock/Unlock instead of latches
Thanks for producing an alternate version, it will allow us to comment
on various approaches.
There is much yet to discuss so please don't think about committing
anything yet.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-25 08:11:00 |
| Message-ID: | 4F1FB914.2060003@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
I've been thinking, what exactly is the important part of this group
commit patch that gives the benefit? Keeping the queue sorted isn't all
that important - XLogFlush() requests for commits will come in almost
the correct order anyway.
I also don't much like the division of labour between groupcommit.c and
xlog.c. XLogFlush() calls GroupCommitWaitForLSN(), which calls back
DoXLogFlush(), which is a bit hard to follow. (that's in my latest
version; the original patch had similar division but it also cut across
processes, with the wal writer actually doing the flush)
It occurs to me that the WALWriteLock already provides much of the same
machinery we're trying to build here. It provides FIFO-style queuing,
with the capability to wake up the next process or processes in the
queue. Perhaps all we need is some new primitive to LWLock, to make it
do exactly what we need.
Attached is a patch to do that. It adds a new mode to
LWLockConditionalAcquire(), LW_EXCLUSIVE_BUT_WAIT. If the lock is free,
it is acquired and the function returns immediately. However, unlike
normal LWLockConditionalAcquire(), if the lock is not free it goes to
sleep until it is released. But unlike normal LWLockAcquire(), when the
lock is released, the function returns *without* acquiring the lock.
I modified XLogFlush() to use that new function for WALWriteLock. It
tries to get WALWriteLock, but if it's not immediately free, it waits
until it is released. Then, before trying to acquire the lock again, it
rechecks LogwrtResult to see if the record was already flushed by the
process that released the lock.
This is a much smaller patch than the group commit patch, and in my
pgbench-tools tests on my laptop, it has the same effect on performance.
The downside is that it touches lwlock.c, which is a change at a lower
level. Robert's flexlocks patch probably would've been useful here.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| groupcommit-with-special-lwlockmode-1.patch | text/x-diff | 7.6 KB |
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-26 02:10:47 |
| Message-ID: | CA+TgmoaPyQKEaoFz8HkDGvRDbOmRpkGo69zjODB5=7Jh3hbPQA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Wed, Jan 25, 2012 at 3:11 AM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> I've been thinking, what exactly is the important part of this group commit
> patch that gives the benefit? Keeping the queue sorted isn't all that
> important - XLogFlush() requests for commits will come in almost the correct
> order anyway.
>
> I also don't much like the division of labour between groupcommit.c and
> xlog.c. XLogFlush() calls GroupCommitWaitForLSN(), which calls back
> DoXLogFlush(), which is a bit hard to follow. (that's in my latest version;
> the original patch had similar division but it also cut across processes,
> with the wal writer actually doing the flush)
>
> It occurs to me that the WALWriteLock already provides much of the same
> machinery we're trying to build here. It provides FIFO-style queuing, with
> the capability to wake up the next process or processes in the queue.
> Perhaps all we need is some new primitive to LWLock, to make it do exactly
> what we need.
>
> Attached is a patch to do that. It adds a new mode to
> LWLockConditionalAcquire(), LW_EXCLUSIVE_BUT_WAIT. If the lock is free, it
> is acquired and the function returns immediately. However, unlike normal
> LWLockConditionalAcquire(), if the lock is not free it goes to sleep until
> it is released. But unlike normal LWLockAcquire(), when the lock is
> released, the function returns *without* acquiring the lock.
>
> I modified XLogFlush() to use that new function for WALWriteLock. It tries
> to get WALWriteLock, but if it's not immediately free, it waits until it is
> released. Then, before trying to acquire the lock again, it rechecks
> LogwrtResult to see if the record was already flushed by the process that
> released the lock.
>
> This is a much smaller patch than the group commit patch, and in my
> pgbench-tools tests on my laptop, it has the same effect on performance. The
> downside is that it touches lwlock.c, which is a change at a lower level.
> Robert's flexlocks patch probably would've been useful here.
I think you should break this off into a new function,
LWLockWaitUntilFree(), rather than treating it as a new LWLockMode.
Also, instead of adding lwWaitOnly, I would suggest that we generalize
lwWaiting and lwExclusive into a field lwWaitRequest, which can be set
to 1 for exclusive, 2 for shared, 3 for wait-for-free, etc. That way
we don't have to add another boolean every time someone invents a new
type of wait - not that that should hopefully happen very often. A
side benefit of this is that you can simplify the test in
LWLockRelease(): keep releasing waiters until you come to an exclusive
waiter, then stop. This possibly saves one shared memory fetch and
subsequent test instruction, which might not be trivial - all of this
code is extremely hot. We probably want to benchmark this carefully
to make sure that it doesn't cause a performance regression even just
from this:
+ if (!proc->lwWaitOnly)
+ lock->releaseOK = false;
I know it sounds crazy, but I'm not 100% sure that that additional
test there is cheap enough not to matter. Assuming it is, though, I
kind of like the concept: I think there must be other places where
these semantics are useful.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-27 13:35:26 |
| Message-ID: | 4F22A81E.2060005@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 26.01.2012 04:10, Robert Haas wrote:
> On Wed, Jan 25, 2012 at 3:11 AM, Heikki Linnakangas
> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>> Attached is a patch to do that. It adds a new mode to
>> LWLockConditionalAcquire(), LW_EXCLUSIVE_BUT_WAIT. If the lock is free, it
>> is acquired and the function returns immediately. However, unlike normal
>> LWLockConditionalAcquire(), if the lock is not free it goes to sleep until
>> it is released. But unlike normal LWLockAcquire(), when the lock is
>> released, the function returns *without* acquiring the lock.
>> ...
>
> I think you should break this off into a new function,
> LWLockWaitUntilFree(), rather than treating it as a new LWLockMode.
> Also, instead of adding lwWaitOnly, I would suggest that we generalize
> lwWaiting and lwExclusive into a field lwWaitRequest, which can be set
> to 1 for exclusive, 2 for shared, 3 for wait-for-free, etc. That way
> we don't have to add another boolean every time someone invents a new
> type of wait - not that that should hopefully happen very often. A
> side benefit of this is that you can simplify the test in
> LWLockRelease(): keep releasing waiters until you come to an exclusive
> waiter, then stop. This possibly saves one shared memory fetch and
> subsequent test instruction, which might not be trivial - all of this
> code is extremely hot.
Makes sense. Attached is a new version, doing exactly that.
> We probably want to benchmark this carefully
> to make sure that it doesn't cause a performance regression even just
> from this:
>
> + if (!proc->lwWaitOnly)
> + lock->releaseOK = false;
>
> I know it sounds crazy, but I'm not 100% sure that that additional
> test there is cheap enough not to matter. Assuming it is, though, I
> kind of like the concept: I think there must be other places where
> these semantics are useful.
Yeah, we have to be careful with any overhead in there, it can be a hot
spot. I wouldn't expect any measurable difference from the above,
though. Could I ask you to rerun the pgbench tests you did recently with
this patch? Or can you think of a better test for this?
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| groupcommit-with-lwlockwaituntilfree-2.patch | text/x-diff | 12.8 KB |
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-27 13:38:57 |
| Message-ID: | CA+TgmoY2_q5BmgxO5TttjTt_dLa=ExO7MQJr7_4TTLOSwo5N2A@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Jan 27, 2012 at 8:35 AM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> Yeah, we have to be careful with any overhead in there, it can be a hot
> spot. I wouldn't expect any measurable difference from the above, though.
> Could I ask you to rerun the pgbench tests you did recently with this patch?
> Or can you think of a better test for this?
I can't do so immediately, because I'm waiting for Nate Boley to tell
me I can go ahead and start testing on that machine again. But I will
do it once I get the word.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-29 00:48:53 |
| Message-ID: | CAMkU=1yYxMj640TfyxPfx+Qk=Xt60nB0M4fDjDLZE9zrxcRgFg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Fri, Jan 27, 2012 at 5:35 AM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> On 26.01.2012 04:10, Robert Haas wrote:
>
>>
>> I think you should break this off into a new function,
>> LWLockWaitUntilFree(), rather than treating it as a new LWLockMode.
>> Also, instead of adding lwWaitOnly, I would suggest that we generalize
>> lwWaiting and lwExclusive into a field lwWaitRequest, which can be set
>> to 1 for exclusive, 2 for shared, 3 for wait-for-free, etc. That way
>> we don't have to add another boolean every time someone invents a new
>> type of wait - not that that should hopefully happen very often. A
>> side benefit of this is that you can simplify the test in
>> LWLockRelease(): keep releasing waiters until you come to an exclusive
>> waiter, then stop. This possibly saves one shared memory fetch and
>> subsequent test instruction, which might not be trivial - all of this
>> code is extremely hot.
>
>
> Makes sense. Attached is a new version, doing exactly that.
Others are going to test this out on high-end systems. I wanted to
try it out on the other end of the scale. I've used a Pentium 4,
3.2GHz,
with 2GB of RAM and with a single IDE drive running ext4. ext4 is
amazingly bad on IDE, giving about 25 fsync's per second (and it lies
about fdatasync, but apparently not about fsync)
I ran three modes, head, head with commit_delay, and the group_commit patch
shared_buffers = 600MB
wal_sync_method=fsync
optionally with:
commit_delay=5
commit_siblings=1
pgbench -i -s40
for clients in 1 5 10 15 20 25 30
pgbench -T 30 -M prepared -c $clients -j $clients
ran 5 times each, taking maximum tps from the repeat runs.
The results are impressive.
clients head head_commit_delay group_commit
1 23.9 23.0 23.9
5 31.0 51.3 59.9
10 35.0 56.5 95.7
15 35.6 64.9 136.4
20 34.3 68.7 159.3
25 36.5 64.1 168.8
30 37.2 83.8 71.5
I haven't inspected that deep fall off at 30 clients for the patch.
By way of reference, if I turn off synchronous commit, I get
tps=1245.8 which is 100% CPU limited. This sets an theoretical upper
bound on what could be achieved by the best possible group committing
method.
If the group_commit patch goes in, would we then rip out commit_delay
and commit_siblings?
Cheers,
Jeff
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 13.2 KB |
| From: | Jesper Krogh <jesper(at)krogh(dot)cc> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-29 19:53:01 |
| Message-ID: | 4F25A39D.5080801@krogh.cc |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 2012-01-29 01:48, Jeff Janes wrote:
> I ran three modes, head, head with commit_delay, and the group_commit patch
>
> shared_buffers = 600MB
> wal_sync_method=fsync
>
> optionally with:
> commit_delay=5
> commit_siblings=1
>
> pgbench -i -s40
>
> for clients in 1 5 10 15 20 25 30
> pgbench -T 30 -M prepared -c $clients -j $clients
>
> ran 5 times each, taking maximum tps from the repeat runs.
>
> The results are impressive.
>
> clients head head_commit_delay group_commit
> 1 23.9 23.0 23.9
> 5 31.0 51.3 59.9
> 10 35.0 56.5 95.7
> 15 35.6 64.9 136.4
> 20 34.3 68.7 159.3
> 25 36.5 64.1 168.8
> 30 37.2 83.8 71.5
>
> I haven't inspected that deep fall off at 30 clients for the patch.
>
> By way of reference, if I turn off synchronous commit, I get
> tps=1245.8 which is 100% CPU limited. This sets an theoretical upper
> bound on what could be achieved by the best possible group committing
> method.
>
> If the group_commit patch goes in, would we then rip out commit_delay
> and commit_siblings?
Adding to the list of tests that isn't excactly a real-world system I
decided
to repeat Jeff's tests on a Intel(R) Core(TM)2 Duo CPU E7500 @ 2.93GHz
with 4GB of memory and an Intel X25-M 160GB SSD drive underneath.
Baseline Commitdelay Group commit
1 1168.67 1233.33 1212.67
5 2611.33 3022.00 2647.67
10 3044.67 3333.33 3296.33
15 3153.33 3177.00 3456.67
20 3087.33 3126.33 3618.67
25 2715.00 2359.00 3309.33
30 2736.33 2831.67 2737.67
Numbers are average over 3 runs.
I have set checkpoint_segments to 30 .. otherwise same configuration as
Jeff.
Attached is a graph.
Nice conclusion is.. group commit outperforms baseline in all runs (on
this system).
My purpose was actual more to try to quantify the difference between a
single SSD and
a single rotating disk.
--
Jesper
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 24.5 KB |
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-29 21:20:07 |
| Message-ID: | 4F25B807.5020103@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 01/28/2012 07:48 PM, Jeff Janes wrote:
> Others are going to test this out on high-end systems. I wanted to
> try it out on the other end of the scale. I've used a Pentium 4,
> 3.2GHz,
> with 2GB of RAM and with a single IDE drive running ext4. ext4 is
> amazingly bad on IDE, giving about 25 fsync's per second (and it lies
> about fdatasync, but apparently not about fsync)
Fantastic, I had to stop for a minute to check the date on your message
for a second there, make sure it hadn't come from some mail server
that's been backed up on delivery the last five years. I'm cleaning
house toward testing this out here, and I was going to test on the same
system using both fast and horribly slow drives. Both ends of the scale
are important, and they benefit in a very different way from these changes.
> I haven't inspected that deep fall off at 30 clients for the patch.
> By way of reference, if I turn off synchronous commit, I get
> tps=1245.8 which is 100% CPU limited. This sets an theoretical upper
> bound on what could be achieved by the best possible group committing
> method.
This sort of thing is why I suspect that to completely isolate some
results, we're going to need a moderately high end server--with lots of
cores--combined with an intentionally mismatched slow drive. It's too
easy to get pgbench and/or PostgreSQL to choke on something other than
I/O when using smaller core counts. I don't think I have anything where
the floor is 24 TPS per client though. Hmmm...I think I can connect an
IDE drive to my MythTV box and format it with ext4. Thanks for the test
idea.
One thing you could try on this system is using the -N "Do not update
pgbench_tellers and pgbench_branches". That eliminates a lot of the
contention that might be pulling down your higher core count tests,
while still giving a completely valid test of whether the group commit
mechanism works. Not sure whether that will push up the top-end
usefully for you, worth a try if you have time to test again.
> If the group_commit patch goes in, would we then rip out commit_delay
> and commit_siblings?
The main reason those are still hanging around at all are to allow
pushing on the latency vs. throughput trade-off on really busy systems.
The use case is that you expect, say, 10 clients to constantly be
committing at a high rate. So if there's just one committing so far,
assume it's the leading edge of a wave and pause a bit for the rest to
come in. I don't think the cases where this is useful behavior--people
both want it and the current mechanism provides it--are very common in
the real world. It can be useful for throughput oriented benchmarks
though, which is why I'd say it hasn't killed off yet.
We'll have to see whether the final form this makes sense in will
usefully replace that sort of thing. I'd certainly be in favor of
nuking commit_delay and commit_siblings with a better option; it would
be nice if we don't eliminate this tuning option in the process though.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-30 14:57:27 |
| Message-ID: | 4F26AFD7.8040808@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 27.01.2012 15:38, Robert Haas wrote:
> On Fri, Jan 27, 2012 at 8:35 AM, Heikki Linnakangas
> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>> Yeah, we have to be careful with any overhead in there, it can be a hot
>> spot. I wouldn't expect any measurable difference from the above, though.
>> Could I ask you to rerun the pgbench tests you did recently with this patch?
>> Or can you think of a better test for this?
>
> I can't do so immediately, because I'm waiting for Nate Boley to tell
> me I can go ahead and start testing on that machine again. But I will
> do it once I get the word.
I committed this. I ran pgbench test on an 8-core box and didn't see any
slowdown. It would still be good if you get a chance to rerun the bigger
test, but I feel confident that there's no measurable slowdown.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-30 15:18:32 |
| Message-ID: | CA+U5nMLvNCL0BTU9ZPnFzVYwB5W_s0pXGYq26qHHXjk0GGp5nQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jan 30, 2012 at 2:57 PM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> I committed this. I ran pgbench test on an 8-core box and didn't see any
> slowdown. It would still be good if you get a chance to rerun the bigger
> test, but I feel confident that there's no measurable slowdown.
I asked clearly and specifically for you to hold back committing
anything. Not sure why you would ignore that and commit without
actually asking myself or Peter. On a point of principle alone, I
think you should revert. Working together is difficult if
communication channels are openly ignored and disregarded.
Peter and I have been working on a new version that seems likely to
improve performance over your suggestions. We should be showing
something soon.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-30 15:32:01 |
| Message-ID: | 4F26B7F1.2000004@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 30.01.2012 17:18, Simon Riggs wrote:
> On Mon, Jan 30, 2012 at 2:57 PM, Heikki Linnakangas
> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>
>> I committed this. I ran pgbench test on an 8-core box and didn't see any
>> slowdown. It would still be good if you get a chance to rerun the bigger
>> test, but I feel confident that there's no measurable slowdown.
>
> I asked clearly and specifically for you to hold back committing
> anything. Not sure why you would ignore that and commit without
> actually asking myself or Peter. On a point of principle alone, I
> think you should revert. Working together is difficult if
> communication channels are openly ignored and disregarded.
You must be referring to this:
http://archives.postgresql.org/pgsql-hackers/2012-01/msg01406.php
What I committed in the end was quite different from the version that
was in reply to, too. If you have a specific objection to the patch as
committed, please let me know.
> Peter and I have been working on a new version that seems likely to
> improve performance over your suggestions. We should be showing
> something soon.
Please post those ideas, and let's discuss them. If it's something
simple, maybe we can still sneak them into this release. Otherwise,
let's focus on the existing patches that are pending review or commit.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Greg Smith <greg(at)2ndquadrant(dot)com> |
| Cc: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-30 16:48:51 |
| Message-ID: | CAMkU=1whmdC+o7RP-Lc3Gd_7OS2LM4S6Ltk5jc2ZrsNjvL4gvg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Sun, Jan 29, 2012 at 1:20 PM, Greg Smith <greg(at)2ndquadrant(dot)com> wrote:
> On 01/28/2012 07:48 PM, Jeff Janes wrote:
>>
>
>> I haven't inspected that deep fall off at 30 clients for the patch.
>> By way of reference, if I turn off synchronous commit, I get
>> tps=1245.8 which is 100% CPU limited. This sets an theoretical upper
>> bound on what could be achieved by the best possible group committing
>> method.
>
>
> This sort of thing is why I suspect that to completely isolate some results,
> we're going to need a moderately high end server--with lots of
> cores--combined with an intentionally mismatched slow drive. It's too easy
> to get pgbench and/or PostgreSQL to choke on something other than I/O when
> using smaller core counts. I don't think I have anything where the floor is
> 24 TPS per client though. Hmmm...I think I can connect an IDE drive to my
> MythTV box and format it with ext4. Thanks for the test idea.
>
> One thing you could try on this system is using the -N "Do not update
> pgbench_tellers and pgbench_branches". That eliminates a lot of the
> contention that might be pulling down your higher core count tests, while
> still giving a completely valid test of whether the group commit mechanism
> works. Not sure whether that will push up the top-end usefully for you,
> worth a try if you have time to test again.
Adding the -N did eliminate the fall-off at 30 clients for
group_commit patch. But, I still want to explore why the fall off
occurs when I get a chance. I know why the curve would stop going up
without using -N (with -s of 40 and -c of 30, many connections will be
waiting on row locks for updates to pgbench_branches) but that should
cause a leveling off, not a collapse.
Other than the lack of drop off at 30 clients, -N didn't meaningfully
change anything. Everyone got slightly faster except at -c1.
>> If the group_commit patch goes in, would we then rip out commit_delay
>> and commit_siblings?
>
>
> The main reason those are still hanging around at all are to allow pushing
> on the latency vs. throughput trade-off on really busy systems. The use
> case is that you expect, say, 10 clients to constantly be committing at a
> high rate. So if there's just one committing so far, assume it's the
> leading edge of a wave and pause a bit for the rest to come in. I don't
> think the cases where this is useful behavior--people both want it and the
> current mechanism provides it--are very common in the real world.
The tests I did are exactly that environment where commit_delay might
be expected to help. And it did help, but just not all that much. One
of the problems is that while it does wait for those others to come in
and then it does flush them in one fsync; but often the others never
get woken up successfully to realize that they have already been
flushed. They continue to block.
The group_commit patch, on the other hand, accomplishes exactly what
commit_delay was intended to accomplish but doesn't do a very good job
of.
With the -N option, I also used commit_delay on top of group_commit,
and the difference between the two look like it was within the margin
of error. So commit_delay did not obviously cause further
improvement.
> It can be
> useful for throughput oriented benchmarks though, which is why I'd say it
> hasn't killed off yet.
>
> We'll have to see whether the final form this makes sense in will usefully
> replace that sort of thing. I'd certainly be in favor of nuking
> commit_delay and commit_siblings with a better option; it would be nice if
> we don't eliminate this tuning option in the process though.
But I'm pretty sure that group_commit has stolen that thunder.
Obviously a few benchmarks on one system isn't enough to prove that,
though.
The only use case I see left for commit_delay is where it is set on a
per-connection basis rather than system-wide. Once you start a fsync,
everyone who missed the bus is locked out until the next one. So
low-priority connections can set commit_delay so as not to trigger the
bus to leave before the high priority process gets on. But that seems
like a pretty tenuous use case with better ways to do it.
Cheers,
Jeff
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-30 19:55:07 |
| Message-ID: | CA+U5nM+LWnBfVUSJv+r3aGDrRp7aaRZefVUBv39TQhH_qOg8Jw@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jan 30, 2012 at 3:32 PM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> On 30.01.2012 17:18, Simon Riggs wrote:
>> I asked clearly and specifically for you to hold back committing
>> anything. Not sure why you would ignore that and commit without
>> actually asking myself or Peter. On a point of principle alone, I
>> think you should revert. Working together is difficult if
>> communication channels are openly ignored and disregarded.
>
>
> You must be referring to this:
>
> http://archives.postgresql.org/pgsql-hackers/2012-01/msg01406.php
>
> What I committed in the end was quite different from the version that was in
> reply to, too. If you have a specific objection to the patch as committed,
> please let me know.
I said "There is much yet to discuss so please don't think about committing
anything yet."
There's not really any way you could misinterpret them.
>> Peter and I have been working on a new version that seems likely to
>> improve performance over your suggestions. We should be showing
>> something soon.
>
>
> Please post those ideas, and let's discuss them. If it's something simple,
> maybe we can still sneak them into this release. Otherwise, let's focus on
> the existing patches that are pending review or commit.
If you really did want to discuss it, it would have taken you 5
minutes to check whether there was consensus on the patch before
committing it. Your actions betray the opposite of a willingness to
discuss anything.
Yes, I'd like to discuss ideas, not just ram home a half-discussed and
half-finished patch that happens to do things the way you personally
prefer, overriding all inputs.
Especially when you know we're working on another version.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-30 20:04:24 |
| Message-ID: | 4F26F7C8.1020404@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 30.01.2012 21:55, Simon Riggs wrote:
> On Mon, Jan 30, 2012 at 3:32 PM, Heikki Linnakangas
> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>> On 30.01.2012 17:18, Simon Riggs wrote:
>
>>> Peter and I have been working on a new version that seems likely to
>>> improve performance over your suggestions. We should be showing
>>> something soon.
>>
>> Please post those ideas, and let's discuss them. If it's something simple,
>> maybe we can still sneak them into this release. Otherwise, let's focus on
>> the existing patches that are pending review or commit.
>
> If you really did want to discuss it, it would have taken you 5
> minutes to check whether there was consensus on the patch before
> committing it. Your actions betray the opposite of a willingness to
> discuss anything.
>
> Yes, I'd like to discuss ideas, not just ram home a half-discussed and
> half-finished patch that happens to do things the way you personally
> prefer, overriding all inputs.
>
> Especially when you know we're working on another version.
Sorry. So, what's the approach you're working on?
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-30 23:35:53 |
| Message-ID: | CA+U5nM+Yj7scbELbftqPi=Zn1Q6SDM+PDgM0npkiRRrc_tS-xg@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jan 30, 2012 at 8:04 PM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> So, what's the approach you're working on?
I've had a few days leave at end of last week, so no time to fully
discuss the next steps with the patch. That's why you were requested
not to commit anything.
You've suggested there was no reason to have the WALwriter be
involved, which isn't the case and made other comments about latches
that weren't correct also.
The plan here is to allow WAL flush and clog updates to occur
concurrently. Which allows the clog contention and update time to be
completely hidden behind the wait for the WAL flush. That is only
possible if we have the WALwriter involved since we need two processes
to be actively involved.
It's a relatively minor change and uses code that is already committed
and working, not some just invented low level stuff that might not
work right. You might then ask, why the delay? Just simply because my
absence has prevented moving forwards. We'll have a patch tomorrow.
The theory behind this is clear, but needs some explanation.
There are 5 actions that need to occur at commit
1) insert WAL record
2) optionally flush WAL record
3) mark the clog AND set LSN from (1) if we skipped (2)
4) optionally wait for sync rep
5) remove the proc from the procarray
Dependencies between those actions are these
Step (3) must always happen before (5) otherwise we get race
conditions in visibility checking.
Step (4) must always happen before (5) otherwise we also get race
conditions in disaster cases.
Step (1) must always happen before (2) if it happens
Step (1) must always happen before (3) if we skipped (2)
Notice that step (2) and step (3) are actually independent of each other.
So an improved design for commit is to
2) request flush up to LSN, but don't wait
3) mark the clog and set LSN
4) wait for LSN once, either for walwriter or walsender to release us
This is free of race conditions as long as step (3) marks each clog
page with a valid LSN, just as we would do for asynchronous commit.
Marking the clog with an LSN ensures that we issue XLogFlush(LSN) on
the clog page before it is written, so we always get WAL flushed to
the desired LSN before the clog mark appears on disk.
Does this cause any other behaviour? No, because the LSN marked on the
clog is always flushed by the time we hit step (5), so there is no
delay in any hint bit setting, or any other effect.
So step (2) requests the flush, which is then performed by WALwriter.
Backend then performs (3) while the flush takes place and then waits
at step (4) to be woken
We only wait once in step 4, rather than waiting for flush at step (2)
and then waiting again at step (4).
So we use the existing code path for TransactionIdAsyncCommitTree()
yet we wait at step (4) using the SyncRep code.
Step 5 happens last, as always.
There are two benefits to this approach
* The clog update happens "for free" since it is hidden behind a
longer running task
* The implementation uses already tested and robust code for SyncRep
and AsyncCommit
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-31 07:43:30 |
| Message-ID: | 4F279BA2.2080807@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 31.01.2012 01:35, Simon Riggs wrote:
> The plan here is to allow WAL flush and clog updates to occur
> concurrently. Which allows the clog contention and update time to be
> completely hidden behind the wait for the WAL flush. That is only
> possible if we have the WALwriter involved since we need two processes
> to be actively involved.
>
> ...
>
> The theory behind this is clear, but needs some explanation.
>
> There are 5 actions that need to occur at commit
> 1) insert WAL record
> 2) optionally flush WAL record
> 3) mark the clog AND set LSN from (1) if we skipped (2)
> 4) optionally wait for sync rep
> 5) remove the proc from the procarray
>
> ...
>
> Notice that step (2) and step (3) are actually independent of each other.
>
> So an improved design for commit is to
> 2) request flush up to LSN, but don't wait
> 3) mark the clog and set LSN
> 4) wait for LSN once, either for walwriter or walsender to release us
That seems like a pretty marginal gain. If you're bound by the speed of
fsyncs, this will reduce the latency by the time it takes to mark the
clog, which is tiny in comparison to all the other stuff that needs to
happen, like, flushing the WAL. And that's ignoring any additional
overhead caused by the signaling between processes. If you're bound by
CPU capacity, this doesn't help at all because it just moves the work
around.
Anyway, this is quite different from the original goal and patch for
group commit, so can we please leave this for 9.3, and move on with the
review of pending 9.2 patches.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| From: | Simon Riggs <simon(at)2ndQuadrant(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-31 08:02:24 |
| Message-ID: | CA+U5nMKC2WeRKLn=vGiBQMsygbtL=5Ywoz24zUeVaM=M7oZCGQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jan 31, 2012 at 7:43 AM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> That seems like a pretty marginal gain. If you're bound by the speed of
> fsyncs, this will reduce the latency by the time it takes to mark the clog,
> which is tiny in comparison to all the other stuff that needs to happen,
> like, flushing the WAL. And that's ignoring any additional overhead caused
> by the signaling between processes. If you're bound by CPU capacity, this
> doesn't help at all because it just moves the work around.
We're not bound by CPU capacity. Latency is an issue, especially when
contention drives it higher with occasional spikes.
I expect this to have a good measurable impact, as well as a
stabilising effect on the latency.
> Anyway, this is quite different from the original goal and patch for group
> commit, so can we please leave this for 9.3, and move on with the review of
> pending 9.2 patches.
Actually, there is very little change here from the original patch.
But I would note that your own changes were also quite different, and
had no noticeable gain. They were also based on a brand new and
radical set of thoughts.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
| From: | Robert Haas <robertmhaas(at)gmail(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-31 14:24:45 |
| Message-ID: | CA+TgmoYROv-9+fcaizehz7JPYO0D8FGXMBb+jxcM2ueSod+rNQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Tue, Jan 31, 2012 at 3:02 AM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> On Tue, Jan 31, 2012 at 7:43 AM, Heikki Linnakangas
> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>
>> That seems like a pretty marginal gain. If you're bound by the speed of
>> fsyncs, this will reduce the latency by the time it takes to mark the clog,
>> which is tiny in comparison to all the other stuff that needs to happen,
>> like, flushing the WAL. And that's ignoring any additional overhead caused
>> by the signaling between processes. If you're bound by CPU capacity, this
>> doesn't help at all because it just moves the work around.
>
> We're not bound by CPU capacity. Latency is an issue, especially when
> contention drives it higher with occasional spikes.
>
> I expect this to have a good measurable impact, as well as a
> stabilising effect on the latency.
>
>> Anyway, this is quite different from the original goal and patch for group
>> commit, so can we please leave this for 9.3, and move on with the review of
>> pending 9.2 patches.
>
> Actually, there is very little change here from the original patch.
>
> But I would note that your own changes were also quite different, and
> had no noticeable gain. They were also based on a brand new and
> radical set of thoughts.
I think you're trying to muddy the waters. Heikki's implementation
was different than yours, and there are some things about it I'm not
100% thrilled with, but it's fundamentally the same concept. The new
idea you're describing here is something else entirely. Instead of
focusing on a technical critique of one implementation vs. another
(out of the three we have to choose from), you're looking at cramming
more optimizations into the implementation you prefer. I'm pretty
sure that Heikki's implementation could support that optimization,
too, if we actually want to do it that way. But there might be good
reasons not to do it that way: for example, every transaction commit
will have to bump the CLOG page LSN, which will delay setting hint
bits on other transactions on the page in cases where they can now be
set immediately. In any event, trying to slip it into the group
commit patch will serve only to prevent it from getting the separate
scrutiny which it doubtless deserves.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | Robert Haas <robertmhaas(at)gmail(dot)com> |
| Cc: | Simon Riggs <simon(at)2ndquadrant(dot)com>, Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-01-31 14:44:19 |
| Message-ID: | CAEYLb_W9xpVO-qxLiWDU3-7UDFzMBTVEX-zMeAfJBXUDYuFzoQ@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 31 January 2012 14:24, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
> I think you're trying to muddy the waters. Heikki's implementation
> was different than yours, and there are some things about it I'm not
> 100% thrilled with, but it's fundamentally the same concept. The new
> idea you're describing here is something else entirely. Instead of
> focusing on a technical critique of one implementation vs. another
> (out of the three we have to choose from), you're looking at cramming
> more optimizations into the implementation you prefer. I'm pretty
> sure that Heikki's implementation could support that optimization,
> too, if we actually want to do it that way. But there might be good
> reasons not to do it that way: for example, every transaction commit
> will have to bump the CLOG page LSN, which will delay setting hint
> bits on other transactions on the page in cases where they can now be
> set immediately. In any event, trying to slip it into the group
> commit patch will serve only to prevent it from getting the separate
> scrutiny which it doubtless deserves.
Well, I also think it deserves separate scrutiny, but it's not as if
it can be reasonably argued that it can be isolated from 1 of those 3
implementations. Our immediate goal is to produce a benchmark of a new
patch, that operates on the same fundamental principle as the original
patch, though with a much reduced code footprint. We then have a
reasonable basis for comparison: The original benchmark (or possibly a
new benchmark on the original patch, which has seemingly identical
performance characteristics to Heikki's anyway), and the new patch.
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| From: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
|---|---|
| To: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-02-04 05:24:04 |
| Message-ID: | CAMkU=1xV75o_5hf7kBPJDahaNn8gmaohKtajaTzm5me69K6iEA@mail.gmail.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On Mon, Jan 30, 2012 at 6:57 AM, Heikki Linnakangas
<heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
> On 27.01.2012 15:38, Robert Haas wrote:
>>
>> On Fri, Jan 27, 2012 at 8:35 AM, Heikki Linnakangas
>> <heikki(dot)linnakangas(at)enterprisedb(dot)com> wrote:
>>>
>>> Yeah, we have to be careful with any overhead in there, it can be a hot
>>> spot. I wouldn't expect any measurable difference from the above, though.
>>> Could I ask you to rerun the pgbench tests you did recently with this
>>> patch?
>>> Or can you think of a better test for this?
>>
>>
>> I can't do so immediately, because I'm waiting for Nate Boley to tell
>> me I can go ahead and start testing on that machine again. But I will
>> do it once I get the word.
>
>
> I committed this. I ran pgbench test on an 8-core box and didn't see any
> slowdown. It would still be good if you get a chance to rerun the bigger
> test, but I feel confident that there's no measurable slowdown.
Is it safe to assume that, under "#ifdef LWLOCK_STATS", a call to
LWLockAcquire will always precede any calls to LWLockWaitUntilFree
when a new process is started, to calloc the stats assays?
I guess it is right now, because the only user is WALWrite, which
would never be acquired before WALInsert is at least once. But this
doesn't seem very future proof.
I guess the same complain could be logged against LWLockConditionalAcquire.
Since people wouldn't be expected to define LWLOCK_STATS on production
builds, perhaps this issue is ignorable.
Cheers,
Jeff
| From: | Heikki Linnakangas <heikki(dot)linnakangas(at)enterprisedb(dot)com> |
|---|---|
| To: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Peter Geoghegan <peter(at)2ndquadrant(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Group commit, revised |
| Date: | 2012-02-07 08:15:08 |
| Message-ID: | 4F30DD8C.9090400@enterprisedb.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Lists: | pgsql-hackers |
On 04.02.2012 07:24, Jeff Janes wrote:
> Is it safe to assume that, under "#ifdef LWLOCK_STATS", a call to
> LWLockAcquire will always precede any calls to LWLockWaitUntilFree
> when a new process is started, to calloc the stats assays?
>
> I guess it is right now, because the only user is WALWrite, which
> would never be acquired before WALInsert is at least once. But this
> doesn't seem very future proof.
Agreed, we can't count on that. There's no clear single point after a
process startup where the first lwlock is acquired. Out of curiosity, I
added an elog(LOG, ...) to that initialization code, to log which lwlock
is acquired first in a process. It depends on the process and
circumstances - here's the list I got:
BufFreeListLock
ShmemIndexLock
XidGenLock
ProcArrayLock
BgWriterCommLock
AutoVacuumLock
And that's probably not all, I bet you would acquire different locks
first with recovery, streaming replication etc.. I didn't test those.
Anyway, I added the initialization to LWLockWaitUntilFree now. Thanks!
> I guess the same complain could be logged against LWLockConditionalAcquire.
LWLockConditionalAcquire doesn't update the stats, so it's ok.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com