tweaking NTUP_PER_BUCKET
| From: | Tomas Vondra <tv(at)fuzzy(dot)cz> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | tweaking NTUP_PER_BUCKET |
| Date: | 2014-07-03 00:13:51 |
| Message-ID: | 53B4A03F.3070409@fuzzy.cz |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
while hacking on the 'dynamic nbucket' patch, scheduled for the next CF
(https://commitfest.postgresql.org/action/patch_view?id=1494) I was
repeatedly stumbling over NTUP_PER_BUCKET. I'd like to propose a change
in how we handle it.
TL;DR; version
--------------
I propose dynamic increase of the nbuckets (up to NTUP_PER_BUCKET=1)
once the table is built and there's free space in work_mem. The patch
mentioned above makes implementing this possible / rather simple.
Long version
------------
I've seen discussions in the list in the past, but I don't recall any
numbers comparing impact of different values. So I did a simple test,
measuring the duration of a simple hashjoin with different hashtable
sizes and NTUP_PER_BUCKET values. In short, something like this:
CREATE TABLE outer_table (id INT);
CREATE TABLE inner_table (id INT, val_int INT, val_txt TEXT);
INSERT INTO outer_table SELECT i
FROM generate_series(1,50000000) s(i);
INSERT INTO inner_table SELECT i, mod(i,10000), md5(i::text)
FROM generate_series(1,10000000) s(i);
ANALYZE outer_table;
ANALYZE inner_table;
-- force hash join with a single batch
set work_mem = '1GB';
set enable_sort = off;
set enable_indexscan = off;
set enable_bitmapscan = off;
set enable_mergejoin = off;
set enable_nestloop = off;
-- query with various values in the WHERE condition, determining
-- the size of the hash table (single batch, thanks to work_mem)
SELECT COUNT(i.val_txt)
FROM outer_table o LEFT JOIN inner_table i ON (i.id = o.id)
WHERE val_int < 1000;
which leads to plans like this: http://explain.depesz.com/s/i7W
I've repeated this with with NTUP_PER_BUCKET between 1 and 10, and
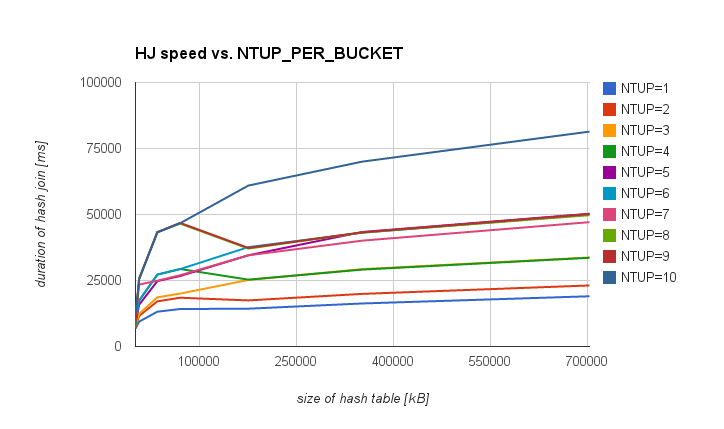
various values in the WHERE condition, and I got this table,
illustrating impact of various NTUP_PER_BUCKET values for various
hashtable sizes:
kB NTUP=1 NTUP=2 NTUP=4 NTUP=5 NTUP=9 NTUP=10
1407 6753 7218 7890 9324 9488 12574
7032 9417 11586 17417 15820 25732 25402
35157 13179 17101 27225 24763 43323 43175
70313 14203 18475 29354 26690 46840 46676
175782 14319 17458 25325 34542 37342 60949
351563 16297 19928 29124 43364 43232 70014
703125 19027 23125 33610 50283 50165 81398
(I've skipped columns for NTUP values that are almost exactly the same
as the adjacent columns due to the fact bucket count grows by doubling).
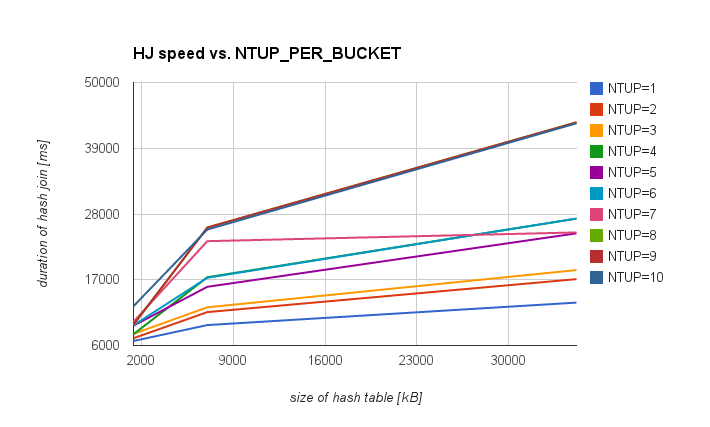
If you prefer charts to tables, attached are two showing the same data
(complete and "small hashtables"). Also, attached is a CSV with the
results, tracking number of buckets and durations for each hashtable
size / NTUP_PER_BUCKET combination.
I'm aware that the numbers and exact behaviour depends on the hardware
(e.g. L1/L2 cache, RAM etc.), and the query used to get these values is
somewhat simple (at least compared to some real-world values). But I
believe the general behaviour won't vary too much.
The first observation is that for large hashtables the difference
between NTUP=1 and NTUP=10 is much larger than for small ones. Not
really surprising - probably due to better hit ratios for CPU caches.
For the large hashtable the difference is significant, easily beating
price for the rebuild of the hashtable (increasing the nbuckets).
Therefore I'd like to propose dynamic increase of bucket count. The
patch mentioned at the beginning does pretty much exactly this for plans
with significantly underestimated cardinality of the hashtable (thus
causing inappropriately low bucket count and poor performance of the
join). However it allows dynamic approach to NTUP_PER_BUCKET too, so I
propose a change along these lines:
1) consider lowering the NTUP_PER_BUCKET (see measurements below)
2) do the initial nbucket/nbatch estimation as today (with whatever
NTUP_PER_BUCKET value we end up using) and build the hashtable
3) while building the hashtable, include space for buckets into
spaceUsed while deciding whether to increase number of batches
(the fact it's not already included seems wrong), but instead of
using initial bucket count, do this:
if (hashtable->spaceUsed + BUCKET_SPACE(hashtable)
> hashtable->spaceAllowed)
ExecHashIncreaseNumBatches(hashtable);
where BUCKET_SPACE is 'how many buckets would be appropriate, given
current tuples per batch'.
4) consider what is the "appropriate" number of buckets and rebuild
the table if appropriate
This is where the patch fixes the underestimated nbuckets value, but
what we can do is look at how much free space remains in work_mem
and use as many buckets as fit into work_mem (capped with tuples
per batch, of course) if there's free space. Even if the initial
cardinality estimate was correct (so we're below NTUP_PER_BUCKET)
this may be a significant speedup.
Say for example we have 10M tuples in the table - with the default
NTUP_PER_BUCKET this means ~1M buckets. But there's significant
performance difference between hashtable with 1 or 10 tuples per
bucket (see below), and if we have 80MB in work_mem (instead of the
default 8MB) this may be a huge gain.
Any comments / objections welcome.
regards
Tomas
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 27.5 KB |
|
image/png | 27.5 KB |
| hashtable.csv | text/csv | 1.2 KB |
Responses
- Re: tweaking NTUP_PER_BUCKET at 2014-07-03 18:03:08 from Tomas Vondra
- Re: tweaking NTUP_PER_BUCKET at 2014-07-08 12:49:50 from Robert Haas
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Peter Geoghegan | 2014-07-03 00:24:06 | Re: Stating the significance of Lehman & Yao in the nbtree README |
| Previous Message | Peter Geoghegan | 2014-07-02 23:27:13 | Re: Ancient bug in formatting.c/to_char() |