Re: Improvement of checkpoint IO scheduler for stable transaction responses
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | KONDO Mitsumasa <kondo(dot)mitsumasa(at)lab(dot)ntt(dot)co(dot)jp> |
| Cc: | Andres Freund <andres(at)2ndquadrant(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Heikki Linnakangas <hlinnakangas(at)vmware(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Improvement of checkpoint IO scheduler for stable transaction responses |
| Date: | 2013-07-14 21:59:15 |
| Message-ID: | 51E31F33.2000300@2ndQuadrant.com |
| Views: | Raw Message | Whole Thread | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 7/11/13 8:29 AM, KONDO Mitsumasa wrote:
> I use linear combination method for considering about total checkpoint schedule
> which are write phase and fsync phase. V3 patch was considered about only fsync
> phase, V4 patch was considered about write phase and fsync phase, and v5 patch
> was considered about only fsync phase.
Your v5 now looks like my "Self-tuning checkpoint sync spread" series:
https://commitfest.postgresql.org/action/patch_view?id=514 which I did
after deciding write phase delays didn't help. It looks to me like
some, maybe all, of your gain is coming from how any added delays spread
out the checkpoints. The "self-tuning" part I aimed at was trying to
stay on exactly the same checkpoint end time even with the delays in
place. I got that part to work, but the performance gain went away once
the schedule was a fair comparison. You are trying to solve a very hard
problem.
How long are you running your dbt-2 tests for? I didn't see that listed
anywhere.
> ** Average checkpoint duration (sec) (Not include during loading time)
> | write_duration | sync_duration | total
> fsync v3-0.7 | 296.6 | 251.8898 | 548.48 | OK
> fsync v3-0.9 | 292.086 | 276.4525 | 568.53 | OK
> fsync v3-0.7_disabled| 303.5706 | 155.6116 | 459.18 | OK
> fsync v4-0.7 | 273.8338 | 355.6224 | 629.45 | OK
> fsync v4-0.9 | 329.0522 | 231.77 | 560.82 | OK
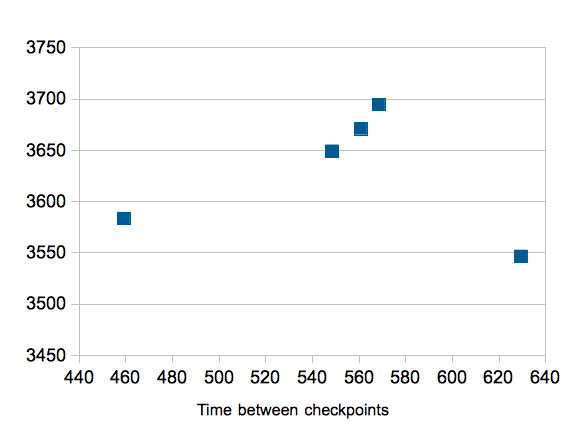
I graphed the total times against the resulting NOTPM values and
attached that. I expect transaction rate to increase along with time
time between checkpoints, and that's what I see here. The fsync v4-0.7
result is worse than the rest for some reason, but all the rest line up
nicely.
Notice how fsync v3-0.7_disabled has the lowest total time between
checkpoints, at 459.18. That is why it has the most I/O and therefore
runs more slowly than the rest. If you take your fsync v3-0.7_disabled
and increase checkpoint_segments and/or checkpoint_timeout until that
test is averaging about 550 seconds between checkpoints, NOTPM should
also increase. That's interesting to know, but you don't need any
change to Postgres for that. That's what always happens when you have
less checkpoints per run.
If you get a checkpoint time table like this where the total duration is
very close--within +/-20 seconds is the sort of noise I would expect
there--at that point I would say you have all your patches on the same
checkpoint schedule. And then you can compare the NOTPM numbers
usefully. When the checkpoint times are in a large range like 459.18 to
629.45 in this table, as my graph shows the associated NOTPM numbers are
going to be based on that time.
I would recommend taking a snapshot of pg_stat_bgwriter before and after
the test runs, and then showing the difference between all of those
numbers too. If the test runs for a while--say 30 minutes--the total
number of checkpoints should be very close too.
> * Test Server
> Server: HP Proliant DL360 G7
> CPU: Xeon E5640 2.66GHz (1P/4C)
> Memory: 18GB(PC3-10600R-9)
> Disk: 146GB(15k)*4 RAID1+0
> RAID controller: P410i/256MB
> (Add) Set off energy efficient function in BIOS and OS.
Excellent, here I have a DL160 G6 with 2 processors, 72GB of RAM, and
that same P410 controller + 4 disks. I've been meaning to get DBT-2
running on there usefully, your research gives me a reason to do that.
You seem to be in a rush due to the commitfest schedule. I have some
bad news for you there. You're not going to see a change here committed
in this CF based on where it's at, so you might as well think about the
best longer term plan. I would be shocked if anything came out of this
in less than 3 months really. That's the shortest amount of time I've
ever done something useful in this area. Each useful benchmarking run
takes me about 3 days of computer time, it's not a very fast development
cycle.
Even if all of your results were great, we'd need to get someone to
duplicate them on another server, and we'd need to make sure they didn't
make other workloads worse. DBT-2 is very useful, but no one is going
to get a major change to the write logic in the database committed based
on one benchmark. Past changes like this have used both DBT-2 and a
large number of pgbench tests to get enough evidence of improvement to
commit. I can help with that part when you get to something I haven't
tried already. I am very interesting in improving this area, it just
takes a lot of work to do it.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 25.5 KB |
In response to
- Re: Improvement of checkpoint IO scheduler for stable transaction responses at 2013-07-11 12:29:07 from KONDO Mitsumasa
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Greg Smith | 2013-07-14 22:46:41 | Re: Improvement of checkpoint IO scheduler for stable transaction responses |
| Previous Message | Fabien COELHO | 2013-07-14 21:42:41 | Re: [PATCH] pgbench --throttle (submission 7 - with lag measurement) |